Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3518–3527 3518
Tree Communication Models for Sentiment Analysis
Yuan Zhang and Yue Zhang
School of Engineering, Westlake University, China
Institute of Advanced Technology, Westlake Institute for Advanced Study
[email protected],[email protected]
Abstract
Tree-LSTMs have been used for tree-based sentiment analysis over Stanford Sentiment Treebank, which allows the sentiment signals over hierarchical phrase structures to be cal-culated simultaneously. However, traditional tree-LSTMs capture only the bottom-up de-pendencies between constituents. In this pa-per, we propose a tree communication model using graph convolutional neural network and graph recurrent neural network, which allows rich information exchange between phrases constituent tree. Experiments show that our model outperforms existing work on bidirec-tional tree-LSTMs in both accuracy and effi-ciency, providing more consistent predictions on phrase-level sentiments.
1 Introduction
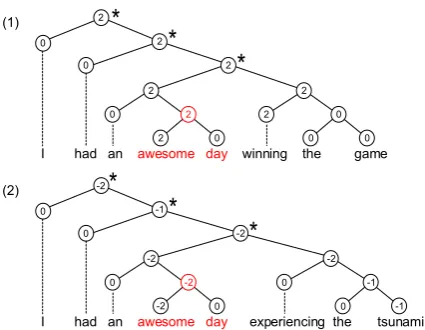
There has been increasing research interest inves-tigating sentiment classification over hierarchical phrases (Tai et al., 2015;Zhu et al.,2015;Looks et al.,2017;Teng and Zhang,2017). As shown in Figure1, the goal is to predict the sentiment class over a sentence and each phrase in its constituent tree. There have been methods that classify each
phrase independently (Li et al., 2015; McCann
et al.,2017). However, sentiments over hierarchi-cal phrases can have dependencies. For example, in Figure1, both sentences have a phrase “an awe-some day”, but the polarities of which are different according to their sentence level contexts.
To better represent such sentiment dependen-cies, one can encode a constituency tree holisti-cally using a neural encoder. To this end, tree-structured LSTMs have been investigated as a dominant approach (Tai et al., 2015; Zhu et al.,
2015;Gan and Gong, 2017; Yu et al., 2017; Liu et al., 2016). Such methods work by encoding hierarchical phrases bottom-up, so that sub con-stituents can be used as inputs for representing a
2
(1) 2
2
0 2
2
I had an awesome day winning the game
0
0 2 2
2 0
(2)
I had an awesome day experiencing the tsunami
*
0 0
0
0 0
0
0 0
*
0 -2
-1
-2
-2 -1
-1 -2
-2 -2
*
*
[image:1.595.309.522.220.385.2]*
*
Figure 1: Examples of tree-based sentiment.
constituent. However, they cannot pass informa-tion from a constituent node to its children, which can be necessary for cases similar to Figure1. In this example, sentence level information from top-level nodes is useful for disambiguating “an awe-some day”. Bi-directional tree LSTMs provide a solution, using a separate top-down LSTM to
aug-ment a tree-LSTM (Teng and Zhang,2017). This
method has achieved highly competitive accura-cies, at the cost of doubling the runtime.
Intuitively, information exchange between tree nodes can happen beyond bottom-up and top-down directions. For example, direct communica-tion between sibling nodes, such as (“an awesome day”, “winning the game”) and (“an awesome day”, “experiencing the tsunami”) can also bring benefits to tree representation. Recent advances of graph neural networks, such as graph
convolu-tional neural network (GCN) (Kipf and Welling,
2016; Marcheggiani and Titov, 2017) and graph
recurrent neural network (GRN) (Beck et al.,
been shown superior to tree LSTMs for encoding a dependency tree (Zhang et al.,2018c)
We investigate both GCNs and GRNs as tree communication models for tree sentiment classi-fication. In particular, initialized with a vanilla tree LSTM representation, each node repeatedly exchanges information with its neighbours using graph neural networks. Such multi-pass informa-tion exchange can allow each node to be more in-formed about its sentence-level context through
rich communication patterns. In addition, the
number of time steps does not scale with the height of the tree. To allow better interaction, we fur-ther propose a novel time-wise attention mecha-nism over GRN, which summarizes the represen-tation after each communication step.
Experiments on Stanford Sentiment Treebank
(SST; Socher et al. 2013) show that our model
outperforms standard bottom-up tree-LSTM (Zhu
et al., 2015; Looks et al., 2017) and also
re-cent work on bidirectional tree-LSTM (Teng and
Zhang, 2017). In addition, our model allows a more holistic prediction of phase-level sentiments over the tree with a high degree of node
sen-timent consistency. To our knowledge, we are
the first to investigate graph NNs for tree senti-ment classification, and the first to discuss phrase level sentiment consistency over a constituent tree for SST. We release our code and models at https://github.com/fred2008/TCMSA.
2 Related Work
Bi-directional Tree-LSTM Paulus et al. (2014) capture bidirectional information over a binary tree by propagating global belief down from
the tree root to leaf nodes. Miwa and Bansal
(2016) adopt a bidirectional dependency
tree-LSTM model by introducing a top-down tree-LSTM path. Teng and Zhang(2017) propose a first bidi-rectional tree-LSTM for constituent structures, by building a top-down tree-LSTM with estimations of head lexicons. Compared with their work, we achieve information interaction using an asymp-totically more efficient algorithm, which per-forms node communication simultaneously across a whole tree.
Graph Neural NetworkScarselli et al.(2009) propose graph neural network (GNN) for encod-ing an arbitrary graph structure. Kipf and Welling
(2016) use graph convolutional network to learn node representation for graph structure.
Marcheg-giani and Titov(2017) andBastings et al. (2017) extend the use of graph convolutional network (GCN) to NLP tasks. In particular, they use GCN to learn dependency-syntactic word representation for semantic role labeling and machine translation, respectively. Zhang et al.(2018b) use a graph
re-current network (GRN) to model sentences. Beck
et al.(2018) andSong et al.(2018) use a graph re-current network for learning representation of ab-stract meaning representation (AMR) graphs. Our work is similar in utilizing graph neural network for NLP. Compared with their work, we apply GNN to constituent trees. In addition, we propose a novel time-wise attention mechanism on GRN to combine recurrent time steps dynamically.
3 Baseline
We take standard bottom-up tree-LSTMs as our baseline. Tree-LSTM extends sequence-LSTM by utilizing 2 previous states for modeling a left child node and a right child node, respectively, in a re-current state transition process. Formally, a tree-LSTM calculates a cell state through an input gate, an output gate and two forget gates at each time step. In particular, at time stept, the input gateit
and the output gate ot are calculated respectively
as follows:
it=σ WhiLhLt−1+WhiRhRt−1
+WciLcLt−1+WciRcRt−1+bi,
ot=σ WhoLhLt−1+WhoRhRt−1
+WcoLcLt−1+WcoRcRt−1+bo,
whereWhiL, WhiR,WciL,WciR, bi, WhoL, WhoR,WcoL,
WR
co andbo are parameters of the input gate and
the output gate, respectively.
The forget gates of the left nodeftLand the right nodefR
t are calculated respectively as:
ftL=σ WhfLLhLt−1+WhfRLhRt−1
+WcfLLcLt−1+WcfRLcRt−1+bfL
,
ftR=σ WhfLRhLt−1+WhfRRhRt−1
+WcfLRcLt−1+WcfRRcRt−1+bfR
,
where WL
hfL, W R hfL, W
L cfL, W
R
cfL, bfL, W L hfR,
WR
hfR,W L cfR,W
R
cfR andbfRare parameters.
The cell candidateC˜tis dependent on bothcLt−1
andcRt−1:
˜
Ct= tanh WhCL hLt−1+W
R
hChRt−1+bC
Word Node Interaction
w0 w1 w2 w3
[image:3.595.328.505.62.184.2]Constinuent Inference
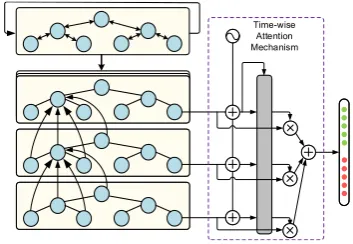
Figure 2: Tree communication model.
whereWhC,WhCR andbC are model parameters.
Based on the two previous cell states cLt−1 and
cRt−1, the cell state of the current nodectis
calcu-lated as:
ct=ftl⊗cLt−1+ftR⊗cRt−1+it⊗C˜t,
whereftl is the forget gate of the left child node,
ftRis the forget gate of the right child node,C˜tis
the cell candidate.
Finally, the hidden state ht of the current node
is calculated based on the current cellct and the
output gateot:
ht=ot⊗tanh(ct)
Limitation Tree-LSTM models capture only bottom-up node dependencies. Specifically, for a nodej, the hidden representationhtree
j is
depen-dent on the descendant nodes only. Formally,
htreej =f(hdj0, hdj1,· · ·, hdjk),
wheredjis the set of descendant nodes of nodej.
Bi-directional Solution A bidirectional LSTM (Bi-LSTM) takes a bottom-up tree-LSTM as a first step, performing a top-down tree
communication process. Teng and Zhang(2017)
is one example.
4 Tree Communication Models
Our tree communication models (TCM) take a trained tree LSTM as an initial state, performing information exchange using graph neural network (GNN). Thushj is dependent on all related
neigh-borhood nodes rather than only descendant nodes:
hj =f(hrj0, hrj1,· · ·, hrjk),
where rj is the set of all relevant nodes of node
j. Such node can be the full tree with sufficient communication.
[image:3.595.106.258.67.159.2]Time-wise Attention Mechanism
Figure 3: Recurrent tree communication model.
In particular, given a constituent tree, for each constituent nodej, the initial stateh′
j is obtained
using a tree-LSTM:
h′
j =treeLSTM(h′left(j), c′left(j), h′right(j), c′right(j)),
whereh′
jis the hidden state of the nodej,c′j is the
cell state of nodej,left(j)denote the left child of nodej,right(j)denotes the right child of nodej.
As shown in Figure 2, a TCM performs
in-formation exchange between a constituent nodej
with its neighbor nodes in three channels:
• Aself-to-self channel transfers information from nodejto itself. The input for the chan-nel is represented asxselfj = h′
j,whereh′j is
the initial state of tree communication model.
• Abottom-up channeltransfers information from lower level nodes to upper-level nodes. The inputs for the channel are represented as
xleftj =h′ left(j),x
right
j =h′right(j),whereleft(j)
andright(j)denote the left child and the right child of nodej, respectively. xupj is the sum
of inputs from bottom up:xupj =xleftj +xrightj .
• A top-down channel transfers information from parent nodes to child nodes. The input for the channel is represented as: xdown
j =
h′
prt(j),whereprt(j)denotes the parent node
of nodej.
When tree communications are executed repeat-edly, each node receives information from an in-creasingly larger context. We explore a convo-lutional tree communication model (CTCM) and a recurrent tree communication model (RTCM),
which are based on GCN (Marcheggiani and
computationally efficient. The time complexity to achieve additional interaction of TCMs are O(1), in contrast to O(n) by top-down tree-LSTM.
4.1 Convolutional Tree Communication Model
We apply the strategy ofMarcheggiani and Titov
(2017), where multiple convolutional layers can be used for information combination. In particular, for thek-th layer, transformed inputs are obtained by linear transformation for each channel:
xk,selfj =Wk,selfhk−1,self
j +bk,self,
xk,dj =Wk,uphk−1,d
j +bk,up, d∈ {left, right},
xk,downj =Wk,downhk−1,down
j +bk,down,
where Wk,e and be (e ∈ {self, up, down})
are model parameters, and hk−1,e
j (e ∈
{self, left, right, down}) is the hidden state
of last layer for node e(j). The initialh−1,e
j are
the inputs of three channelsxe
j defined earlier.
Following Marcheggiani and Titov (2017), for
each edge type e ∈ {self, left, right, down}, we apply edge-wise gate to all inputs:
gk,ej =σ(Wgk,ehk,ej +bk,eg ),
whereWgk,eandbk,eg are model parameters.
The final representation of nodejis:
hkj =f(X
e
xk,ej ⊗gjk,e).
4.2 Recurrent Tree Communication Model
We take the stategy of Song et al. (2018). The
structure of RTCM shows in Figure 3. For each
recurrent stept, the hidden states from the last re-current step are taken to calculate the cell state of the current state. In particular, for nodej, the hid-den state of the previous step can be divided into the last hidden state hselfj from self-to-self chan-nel, the last hidden state hupt−1,j from bottom-up channel and the last hidden statehdown
t−1,j from the
top-down channel:
hselft−1,j =ht−1,j,
hupt−1,j =ht−1,left(j)+ht−1,right(j),
hdownt−1,j =ht−1,prt(j).
We calculate gate and state values based on the inputs and last hidden states from the three infor-mation channels. The input gateijt and the forget
gateftj are defined as:
itj =σWiselfxselfj +Wiupxupj +Widownxdownj
+Uiselfhselft−1,j+Uiuphtup−1,j+Uidownhdownt−1,j+bi
,
fjt=σWfselfxselfj +Wfupxupj +Wfdownxdownj
+Ufselfhselft−1,j+Ufuphtup−1,j+Ufdownhdownt−1,j+bf
,
whereWiself, Wiup, Wdown
i , U
self i , U
up
i , Uidown, bi,
Wfself, Wfup,Wdown
f ,U
self f ,U
up
f ,Ufdown andbf are
parameters of input and forget gate. The cell candidateC˜tj is defined as:
˜
Cjt=σWCselfxselfj +WCupxupj +WCdownxdownj
+UCselfhselft−1,j+UCuphupt−1,j+UCdownhdownt−1,j+bC
,
whereWCself, WCup, Wdown
C , U
self C , U
up
C, UCdown and
bC are parameters of cell candidate.
The current cell state is calculated as:
ctj =fjt⊗ct−1
j +itj ⊗C˜jt,
The output gateojt is defined as:
otj =σWoselfxselfj +Wup o x
up
j +Wodownxdownj
+Uoselfhselft−1,j+Uouphtup−1,j+Uodownhdownt−1,j+bo
,
whereWoself, Woup, Wodown, Uoself, Uoup, Uodown and
boare model parameters.
The final hidden htj is calculated through the current cell statectj and the output gateotj:
htj =otj ⊗tanh(ctj).
4.2.1 Time-wise attention
Both GRN and GCN calculate a sequence of incre-mentally more abstract representationsc1j, c2j, ...ctj
for each nodecj. We further introduce a novel
at-tention scheme to GRN. Intuitively, each recurrent step in RTCM learns a different level of abstrac-tion. For a constituent node higher in the tree or on the leaf, more recurrent steps may be needed to learn the interaction between nodes. Accordingly, we use an adaptive recurrence mechanism to learn a dynamic node representation through attention structure (Bahdanau et al.,2014).
Our method first encodes a recurrent-step-sensitive hidden state with positional embedding:
where hj,deptht is the recurrent-step-sensitive hid-den state for nodej on t-th step,ep is positional
encoding of the recurrence steps.
Inspired byVaswani et al.(2017), a static repre-sentation is used for the positional encodingep(t),
which does not require training:
ept,2k= sin(t/100002k/demb),
ept,2k+1 = cos(t/100002k/demb),
tis the index of recurrent steps, et,m is the m-th
dimension of positional embedding, and demb is
the dimension of embedding.
We learn the weight wt for the t-th
recur-rent step by the relationship between hj,depthT and
hj,deptht :
w′
j,t=hj,depthT ·h j,depth
t ,
wj,t=
exp(w′
j,i)
PT−1
t=0 exp(w′j,t)
.
The final state can be represented as a weighted sum of the hidden states obtained after different recurrent steps:
hj =
T−1
X
t=0
wthjt.
5 Decoding and Training
FollowingLooks et al.(2017) andTeng and Zhang
(2017), we perform softmax classification on each node according to the last hidden state:
o= softmax(M h+b)
whereM andbare model parameters. For
train-ing, negative log-likelihood loss is computed over eacholocally, and accumulated over the tree.
6 Experiments
We test the effectiveness of TCM by comparing
its performance with a standard tree-LSTM (Zhu
et al.,2015) as well as a state-of-the-art bidirec-tional tree-LSTM (Teng and Zhang,2017). A se-ries of analysis is conducted for measuring the holistic representation of sentiment in a tree via phrase-level sentiments consistency.
6.1 Data
We use the Stanford Sentiment Treebank (SST;
Socher et al. 2013), which is a dataset of movie
Corpus SST-5 SST-2
Classes 5 2
Sentences 11,855 9,613
Phrases 442,629 137,988
[image:5.595.325.511.61.132.2]Tokens 227,242 185,621
Table 1: Data statistics.
reviews originally fromPang and Lee (2005) an-notated at both the clause level and the sentence level. Following Zhu et al.(2015) andTeng and Zhang(2017), we perform both fine-grained sen-timent classification and binary classification. For the former, the dataset was annotated for 5 lev-els of sentiment: strong negative, negative, neu-tral, positive, and strong positive. For the latter, the data was labeled with positive sentiment and negative sentiment. We adopt a standard dataset split followingTai et al.(2015);Teng and Zhang
(2017). Table1lists the data statistics.
6.2 Experimental Settings
Hyper-parameters We initialize word embed-dings using GloVe (Pennington et al.,2014) 300-dimensional embeddings. Embeddings are fine-tuned during training. The size of LSTM hidden states are set to 300. We thus fix the number to 9.
TrainingIn order to obtain a good representa-tion for an initial constituent state, we first train an independent bottom-up tree-LSTM, over which we train our tree communication models. To avoid over-fitting, we adopt dropout on the embedding layer, with a rate of 0.5. Training is done on mini-batches through Adagrad (Duchi et al.,2011) with a learning rate of 0.05. We adopt gradient clipping with a threshold of 1.0. The L2 regularization pa-rameter is set to 0.001.
6.3 Development Experiments
Hyper-parameters We investigate the effect of recurrent steps of RTCM as shown in Block A of
Table 2. As the number of steps increases from
1, the accuracy increases, showing the effective-ness of tree node communication. A recurrent step of9 gives the best accuracies, and a larger num-ber of steps does not give further improvements. This is consistent with observations ofSong et al.
(2018), which shows that sufficient context infor-mation can be collected over a small number of iterations.
Block Model SST-5 SST-2
A
3 Step RTCM 83.1 92.3
6 Step RTCM 83.2 92.7
9 Step RTCM 83.4 92.9
18 Step RTCM 83.2 92.8
B
Tree-LSTM 82.9 92.4
CTCM 83.3 92.8
RTCM 83.4 92.9
[image:6.595.78.287.62.186.2]RTCM+attention 83.5 93.3
Table 2: Phrase level performances on the dev set.
shows the performance of different models. Tree-LSTMs with different TCMs outperform the base-line tree-LSTM on both datasets. In addition, the
time-wise attention mechanism in Section 4.2.1
improves performance on both SST-5 and SST-2. In the remaining experiments, we use RTCM with time wise-attention.
6.4 Final Results
Table3shows the overall performances for senti-ment classification on both SST-5 and SST-2. We report accuracies on both the sentence level and the phrase level. Compared with previous methods based on constituent tree-LSTM, our model im-proves the preformance on different datasets and
settings. In particular, it outperforms
BiConL-STM (Teng and Zhang,2017), which use bidirec-tional tree-LSTM. This demostrates the advantage of graph neural networks compared to a top-down LSTM for tree communication. Our model gives the state-of-the-art accuracies on phrase-level set-tings. Note that we do not leverage character rep-resentation or external resources such as sentiment lexicons and large-scale corpuses.
There has also been work using large-scale
ex-ternal datasets to improve performance. McCann
et al. (2017) pretrain their model on large par-allel bilingual datasets and exploit character n-gram features. They report an accuracy of 53.7 on sentence-level SST-5 and an accuracy of 90.3 on sentence-level SST-2, which are lower than our model. Peters et al. (2018) pretrain a language model with character convolutions on a large-scale corpus and report an accuracy of 54.7 on sentence-level SST-5, which is slightly higher than our model. Large-scale pretraining is orthogonal to our method. For a fair comparison, we do not list their results on Table3.
We further analyze the performance with
re-Model SST-5 SST-2
R P R P
RNTN (S13) 45.7 80.7 85.4 87.6
BiLSTM (L15) 49.8 83.3 86.7
-ConTree (LZ15) 49.9 - 88.0
-ConTree (Z15) 50.1 - -
-ConTree (L15) 50.4 83.4 86.7
-ConTree (T15) 51.0 - 88.0
-Disan (S18) 51.7 - -
-RL LD/HS-LSTM (Z18) 50.0 - 87.8
-NTI-SLSTM (MY17) 53.1 - 89.3
-ConTree(Fold) (L17) 52.3 - 89.4
-BiConTree (TZ17) 53.5 83.5 90.3 92.8
RTC + attention 54.3 83.6 90.3 93.4
Table 3: Final results (R-Root, P-Phrase). S13 –Socher et al.(2013); L15 –Li et al. (2015); LZ15 – Le and Zuidema(2015); Z15 – Zhu et al.(2015); T15 – Tai et al.(2015); S18 – Shen et al.(2018); Z18 –Zhang et al.(2018a); MY17 –Munkhdalai and Yu(2017); L17 –Looks et al.(2017); TZ17 –Teng and Zhang(2017)
5 10 15 20 25 30
Length
82.0 82.5 83.0 83.5 84.0 84.5 85.0 85.5
SST-5 Accurancy(%)
SST-5 Tree-LSTM SST-5 Tree Communication SST-2 Tree-LSTM SST-2 Tree Communication
91.5 92.0 92.5 93.0 93.5 94.0 94.5 95.0
SST-2 Accurancy(%)
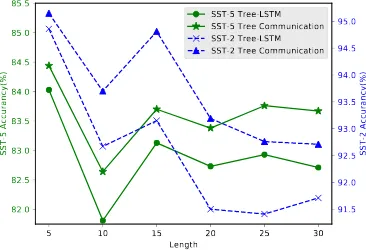
Figure 4: Sentiment classification accuracies against the sentence length. The accuracy for each lengthlis calculated on the test set sentences length in the bin
[l, l+ 5].
spect to different sentence lengths. Figure4shows the results. On both datasets, the performance of tree-LSTM on sentences of lengths less than 10 (l = 5 in the figure) is much better than that of longer sentences. There is a tendency of decreas-ing accuracies as the sentence length increases. As the length of sentences increases, there are longer-range dependencies along the depth of tree struc-ture, which is more difficult to model than short sentences.
[image:6.595.311.523.62.254.2] [image:6.595.325.508.359.484.2]40 50 60 70 80 90 100 Tree-LSTM
40 50 60 70 80 90 100
Tree Communication
(a) SST-5
40 50 60 70 80 90 100 Tree-LSTM
40 50 60 70 80 90 100
Tree Communication
[image:7.595.72.289.62.183.2](b) SST-2
Figure 5: Sentence-level phrase accuracy (SPAcc) scat-ter plot. Each dot represents a sentence in the test dataset. Its x-coordinate and y-coordinate are SPAcc
for predicted phrase label sequence of the baseline model and TCM respectively. The blue line is a linear regression line of all dots.
Dataset α Baseline Our Model Diff.
SST-5
1.0 3.5 3.7 +0.2
0.9 18.9 21.2 +2.3
0.8 67.6 71.4 +3.8
SST-2
1.0 56.0 61.4 +5.4
0.9 18.9 21.2 +4.6
0.8 67.6 71.4 +2.0
Table 4: Rates of holistically-labeled sentences with sentence-level phrase accuracySPAcc>α.
6.5 Disscusion
Sentence-level performanceTo further compare performances of holistic phrase sentiment classifi-cation on the sentence level, we measure the accu-racy on the sentence level. We define sentence-level phrase accuracy (SPAcc) of a sentence as:
SPAcc = ncorrect/ntotal, where ntotal is the total
number of phrases in the sentence, and ncorrect is
the number of correct sentiment predictions in the sentence. For each sentence of test dataset, taking
SPAccof the corresponding label sequence
result-ing from the baseline model as the x-coordinate
andSPAccof the corresponding label sequence
re-sulting from TCM as they-coordinate, we draw a
scatter plot with a regression line as shown in Fig-ure5. The regression line is inclined towards the top-left, indicating that TCM can improve the per-formance on holistic phrase classifications over a whole sentence.
If theSPAccof a sentence is high, the sentence
is more holistically-labeled. Table 4 shows the
statistics on the rate of holistically-labeled sen-tences with SPAcc > α (SPAcc-α). The rate of holistically-labeled sentences for TCM is higher
SST-5 SST-2
Dataset
10 0 10 20 30 40 50 60
Phrase error deviation (PEDev)
Tree-LSTM Tree Communication
Figure 6: Deviation of node errors for each tree.
Dataset Metric Baseline TCM Diff.
SST-5 mean 36.9 35.7 -1.2
median 38.1 37.0 -1.1
SST-2 mean 31.4 21.8 -9.6
[image:7.595.341.489.63.166.2]median 34.3 25.8 -8.3
Table 5: Deviation statistics. Values in units of×10−2
than that for tree-LSTM on both 5 and SST-2 for different values of α. It demonstrates that TCM labels the constituent nodes of the whole tree better than the tree-LSTM model, thanks to more information exchange between phrases in a tree.
Consistency between nodes To compare the sentiment classification consistency of phrases in each sentence, we define a metric, phrase error de-viation (PEDev), to measure the deviation among the error of labels for one sentence:
PEDev(ˆy, y) = r
1 N
XN−1
i=0
d( ˆyi, yi)−d¯2,
whered( ˆyi, yi)is the Hamming distance between
the i-th predicted label and the i-th ground truth label. d¯is the mean value of d( ˆyi, yi). Since
d( ˆyi, yi)∈[0,1],PEDev(ˆy, y)∈[0,0.5].
For an input sentence, if all the predicted labels are the same as the ground truth, or all the pre-dicted labels are different from the ground truth,
PEDev(ˆy, y) = 0, which means that the
sen-tence is labeled with the maximum consistency. On the contrary, if the predicted labels of some phrases are the same as ground truth while oth-ers are not, PEDev(ˆy, y) is high. Table 5 lists the statistics onPEDev(ˆy, y)of the baseline model and our model for all the test sentences on SST-5
and SST-2. The mean and median ofPEDev(ˆy, y)
of TCM are much less than those of the baseline
tree-LSTM model. In addition, as Figure6shows,
[image:7.595.71.292.278.378.2]0 0
(2) +2
0
One of the greatest romantic comedies
+2 +1 0 0 0 0 0 0
This is art paying homage to art
0
0+1+1 0+1+1
0 0
+1 0
0
Though everything might be literate and smart , it never took off and always seemed static
+1 0
0-1-1 0 -1 0 0 0 0 0 0 0 +1 0 +1 -1 +2 +2 -1 -1 (3)
(1) M B T
G G
Diff. labels
Same labels
M - Tree-LSTM Model B - Bi-tree-LSTM T - TCM; G - Gold
A fascinating and fun film .
0 +2 +2 0 0 +2 +2 +2 0 +1 (4) 0 0 1 ++2+2
Black grid – gold label
k Black cell shows incorrect label
1 + 0 0 1 + 0 0 1 + 0 0 1 - -2 2
-1 - -2 2
-1 - -2 2 -1 - 0 0 0-1 1
-0 1 +1
1 ++1+2
1 ++1+2
2 ++1+2
2 ++1+2
[image:8.595.73.523.71.209.2]+
Figure 7: Sentiment classification samples.
-2 -1 0 1 2 Predicted Label -2 -1 0 1 2 Ground Truth
767 1024 180 34 3 385 6204 2414 244 8 72 2260523731784 59
6 341 2936 7151 564 0 64 206 1609 1912
-2 -1 0 1 2 Predicted Label -2 -1 0 1 2 Ground Truth
844 974 148 37 5 477 6378 2104 261 35
85 2252522191904 88 9 302 2468 7359 860 4 37 143 1381 2226
[image:8.595.323.512.256.340.2]0 2000 4000 6000 8000
Figure 8: Confusion matrix on SST-5 phrase-level test dataset for tree-LSTM (left) and TCM (right).
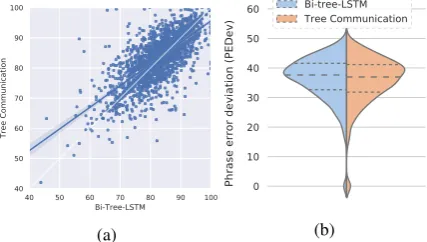
40 50 60 70 80 90 100 Bi-Tree-LSTM 40 50 60 70 80 90 100 Tree Communication (a) 0 10 20 30 40 50 60
Phrase error deviation (PEDev)
Bi-tree-LSTM Tree Communication
(b)
Figure 9: Sentence-level phrase accuracy (a) and devi-ation of node errors (b) comparison on SST-5 between bi-tree-LSTM and TCM.
improves the consistency of phrase classification for each sentence.
Confusion matrix Figure 8 shows the confu-sion matrix on the SST-5 phrase-level test set for
tree-LSTM (left) and TCM (right). Compared
with tree-LSTM, the accuracies of most sentiment labels by TCM increase (the accuracy of the neu-tral label slightly decreases by 0.3%), indicating that TCM is strong in differentiating fine-grained sentiments in global and local contexts.
Metrics BTL TCM Diff.
SPAcc,α= 1.0 3.2 3.7 +0.5
SPAcc,α= 0.9 20.0 21.2 +1.2
SPAcc,α= 0.8 70.7 71.4 +0.7
PEDev-mean 36.4 35.7 -0.7
PEDev-median 37.6 37.0 -0.6
Table 6: Sentence-level phrase accuracy (SPAcc) and phrase error deviation (PEDev) comparison on SST-5 between bi-tree-LSTM and TCM.
6.6 Comparison with Bi-tree-LSTM
Table 6 shows the sentence-level phrase
accu-racy (SPAcc) and phrase error deviation (PEDev) comparison on SST-5 between bi-tree-LSTM and
TCM, respectively. TCM outperforms
bi-tree-LSTM on all the metrics, which demonstrates that TCM gives more consistent predictions of senti-ments over different phrases in a tree, compared to top-down communication. This shows the ben-efit of rich node communication.
Figure 9 shows a scatter chart and a deviation
chart comparision between the two models, in the
same format as Figure 5 and Figure 6,
respec-tively. As shown in Figure 9a, the errors of TCM and bitree-LSTM are scattered, which shows that different communication patterns influence senti-ment prediction. The final observation is consis-tent with Table6.
6.7 Case Study
[image:8.595.80.280.259.345.2] [image:8.595.72.286.416.537.2]con-trast, TCM considers larger contexts by repeated node interaction. The phrase “seemed static” re-ceives information from the constituents “never took off” and “Though everything might be lit-erate and smart” through their common ancestor nodes, leading to the correct result. Although bi-tree-LSTM predicts these sentiments of the phrase “seemed static” and the whole sentence correctly, it gives more incorrect results on the phrase level.
The other sentences in Figure 7 show similar
trends. From the samples we can find that TCM provides more consistent predictions on phrase-level sentiments thanks to its better understanding of different contexts.
7 Conclusion
We investigated two tree communication mod-els for sentiment analysis, leveraging recent ad-vances in graph neural networks for information exchange between nodes in a baseline tree-LSTM model. Both GCNs and GRNs are explored and compared, with GRNs showing better accuracies. We additionally propose a novel time-wise atten-tion mechanism to further improve GRNs. Re-sults on standard benchmark show that graph NNs give better results compared to bi-directional tree LSTMs, providing more consistent predictions over phrases in one sentence. To our knowledge, we are the first to leverage graph neural network structures for enhancing tree-LSTMs, and the first to discuss tree-level sentiment consistency using a set of novel metrics.
8 Acknowledgments
The corresponding author is Yue Zhang. We thank the anonymous reviewers for their valuable com-ments and suggestions. We thank Zhiyang Teng and Linfeng Song for their work and discussion. This work is supported by a grant from Rxhui Inc1.
References
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-gio. 2014. Neural machine translation by jointly learning to align and translate. InICLR.
Joost Bastings, Ivan Titov, Wilker Aziz, Diego Marcheggiani, and Khalil Sima’an. 2017. Graph convolutional encoders for syntax-aware neural ma-chine translation. InEMNLP.
1https://rxhui.com
Daniel Beck, Gholamreza Haffari, and Trevor Cohn. 2018. Graph-to-sequence learning using gated graph neural networks. InACL.
John Duchi, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine
Learning Research.
Ling Gan and Houyu Gong. 2017. Text sentiment anal-ysis based on fusion of structural information and serialization information. InIJCNLP.
Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. InICLR.
Phong Le and Willem Zuidema. 2015. Compositional distributional semantics with long short term mem-ory. In*SEM.
Jiwei Li, Minh-Thang Luong, Dan Jurafsky, and Eu-dard Hovy. 2015. When are tree structures necessary for deep learning of representations? InEMNLP.
Pengfei Liu, Xipeng Qiu, and Xuanjing Huang. 2016. Deep multi-task learning with shared memory. In
EMNLP.
Moshe Looks, Marcello Herreshoff, DeLesley Hutchins, and Peter Norvig. 2017. Deep learning with dynamic computation graphs. InICLR.
Diego Marcheggiani and Ivan Titov. 2017. Encoding sentences with graph convolutional networks for se-mantic role labeling. InEMNLP.
Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. 2017. Learned in translation: Con-textualized word vectors. InNIPS.
Makoto Miwa and Mohit Bansal. 2016. End-to-end re-lation extraction using lstms on sequences and tree structures. InACL.
Tsendsuren Munkhdalai and Hong Yu. 2017. Neural tree indexers for text understanding. InACL.
Bo Pang and Lillian Lee. 2005. Seeing stars: Exploit-ing class relationships for sentiment categorization with respect to rating scales. InACL.
Romain Paulus, Richard Socher, and Christopher D Manning. 2014. Global belief recursive neural net-works. InNIPS.
Jeffrey Pennington, Richard Socher, and Christo-pher D. Manning. 2014. Glove: Global vectors for word representation. InEMNLP.
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. 2009. The graph neural network model. IEEE Transactions on
Neural Networks.
Tao Shen, Tianyi Zhou, Guodong Long, Jing Jiang, Shirui Pan, and Chengqi Zhang. 2018. Disan: Di-rectional self-attention network for rnn/cnn-free lan-guage understanding. InAAAI.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment tree-bank. InEMNLP.
Linfeng Song, Yue Zhang, Zhiguo Wang, and Daniel Gildea. 2018. A graph-to-sequence model for amr-to-text generation. InACL.
Kai Sheng Tai, Richard Socher, and Christopher D Manning. 2015. Improved semantic representations from tree-structured long short-term memory net-works. InACL.
Zhiyang Teng and Yue Zhang. 2017. Head-lexicalized bidirectional tree lstms.TACL.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InNIPS.
Liang-Chih Yu, Jin Wang, K Robert Lai, and Xuejie Zhang. 2017. Refining word embeddings for senti-ment analysis. InEMNLP.
Tianyang Zhang, Minlie Huang, and Li Zhao. 2018a. Learning structured representation for text classifi-cation via reinforcement learning. InAAAI.
Yue Zhang, Qi Liu, and Linfeng Song. 2018b. Sentence-state lstm for text representation. InACL.
Yuhao Zhang, Peng Qi, and Christopher D Manning. 2018c. Graph convolution over pruned dependency trees improves relation extraction. arXiv preprint
arXiv:1809.10185.