Hindi-to-Urdu Machine Translation Through Transliteration
Nadir Durrani Hassan Sajjad Alexander Fraser Helmut Schmid Institute for Natural Language Processing
University of Stuttgart
{durrani,sajjad,fraser,schmid}@ims.uni-stuttgart.de
Abstract
We present a novel approach to integrate transliteration into Hindi-to-Urdu statisti-cal machine translation. We propose two probabilistic models, based on conditional and joint probability formulations, that are novel solutions to the problem. Our mod-els consider both transliteration and trans-lation when translating a particular Hindi word given the context whereas in pre-vious work transliteration is only used for translating OOV (out-of-vocabulary) words. We use transliteration as a tool for disambiguation of Hindi homonyms which can be both translated or translit-erated or translittranslit-erated differently based on different contexts. We obtain final BLEU scores of 19.35 (conditional prob-ability model) and 19.00 (joint probprob-ability model) as compared to 14.30 for a base-line phrase-based system and 16.25 for a system which transliterates OOV words in the baseline system. This indicates that transliteration is useful for more than only translating OOV words for language pairs like Hindi-Urdu.
1 Introduction
Hindi is an official language of India and is writ-ten in Devanagari script. Urdu is the national guage of Pakistan, and also one of the state lan-guages in India, and is written in Perso-Arabic script. Hindi inherits its vocabulary from Sanskrit while Urdu descends from several languages in-cluding Arabic, Farsi (Persian), Turkish and San-skrit. Hindi and Urdu share grammatical structure and a large proportion of vocabulary that they both inherited from Sanskrit. Most of the verbs and closed-class words (pronouns, auxiliaries, case-markers, etc) are the same. Because both lan-guages have lived together for centuries, some
Urdu words which originally came from Arabic and Farsi have also mixed into Hindi and are now part of the Hindi vocabulary. The spoken form of the two languages is very similar.
The extent of overlap between Hindi and Urdu vocabulary depends upon the domain of the text. Text coming from the literary domain like novels or history tend to have more Sanskrit (for Hindi) and Persian/Arabic (for Urdu) vocabulary. How-ever, news wire that contains text related to me-dia, sports and politics, etc., is more likely to have common vocabulary.
In an initial study on a small news corpus of 5000 words, randomly selected from BBC1News, we found that approximately 62% of the Hindi types are also part of Urdu vocabulary and thus can be transliterated while only 38% have to be translated. This provides a strong motivation to implement an end-to-end translation system which strongly relies on high quality transliteration from Hindi to Urdu.
Hindi and Urdu have similar sound systems but transliteration from Hindi to Urdu is still very hard because some phonemes in Hindi have several or-thographic equivalents in Urdu. For example the “z” sound2 can only be written as whenever it occurs in a Hindi word but can be written as , , and in an Urdu word. Transliteration becomes non-trivial in cases where the multiple orthographic equivalents for a Hindi word are all valid Urdu words. Context is required to resolve ambiguity in such cases. Our transliterator (de-scribed in sections 3.1.2 and 4.1.3) gives an accu-racy of 81.6% and a 25-best accuaccu-racy of 92.3%.
Transliteration has been previously used only as a back-off measure to translate NEs (Name Enti-ties) and OOV words in a pre- or post-processing step. The problem we are solving is more difficult than techniques aimed at handling OOV words,
1
http://www.bbc.co.uk/hindi/index.shtml
2All sounds are represented using SAMPA notation.
Hindi Urdu SAMPA Gloss
/ Am Mango/Ordinary
/ d ZAli Fake/Net
[image:2.595.77.296.63.131.2]/ Ser Lion/Verse
Table 1: Hindi Words That Can Be Transliterated Differently in Different Contexts
Hindi Urdu SAMPA Gloss
/ simA Border/Seema
/ Amb@r Sky/Ambar
/ vId Ze Victory/Vijay
Table 2: Hindi Words That Can Be Translated or Transliterated in Different Contexts
which focus primarily on name transliteration, be-cause we need different transliterations in differ-ent contexts; in their case context is irrelevant. For example: consider the problem of transliterating the English word “read” to a phoneme represen-tation in the context “I will read” versus the con-text “I have read”. An example of this for Hindi to Urdu transliteration: the two Urdu words (face/condition) and (chapter of the Koran) are both written as (sur@t d) in Hindi. The two are pronounced identically in Urdu but writ-ten differently. In such cases we hope to choose the correct transliteration by using context. Some other examples are shown in Table 1.
Sometimes there is also an ambiguity of whether to translate or transliterate a particular word. The Hindi word , for example, will be translated to (peace, s@kun) when it is a common noun but transliterated to (Shanti, SAnt di) when it is a proper name. We try to model whether to translate or transliterate in a given situation. Some other examples are shown in Table 2.
The remainder of this paper is organized as fol-lows. Section 2 provides a review of previous work. Section 3 introduces two probabilistic mod-els for integrating translations and transliterations into a translation model which are based on condi-tional and joint probability distributions. Section 4 discusses the training data, parameter optimization and the initial set of experiments that compare our two models with a baseline Hindi-Urdu phrase-based system and with two transliteration-aided phrase-based systems in terms of BLEU scores
(Papineni et al., 2001). Section 5 performs an er-ror analysis showing interesting weaknesses in the initial formulations. We remedy the problems by adding some heuristics and modifications to our models which show improvements in the results as discussed in section 6. Section 7 gives two exam-ples illustrating how our model decides whether to translate or transliterate and how it is able to choose among different valid transliterations given the context. Section 8 concludes the paper.
2 Previous Work
There has been a significant amount of work on transliteration. We can break down previous work into three groups. The first group is generic transliteration work, which is evaluated outside of the context of translation. This work uses either grapheme or phoneme based models to translit-erate words lists (Knight and Graehl, 1998; Li et al., 2004; Ekbal et al., 2006; Malik et al., 2008). The work by Malik et al. addresses Hindi to Urdu transliteration using hand-crafted rules and a phonemic representation; it ignores translation context.
on the fly whereas transliterations in Kashani et al. do not compete with internal phrase tables. They only compete amongst themselves during a sec-ond pass of decoding. Hermjakob et al. (2008) use a tagger to identify good candidates for translit-eration (which are mostly NEs) in input text and add transliterations to the SMT phrase table dy-namically such that they can directly compete with translations during decoding. This is closer to our approach except that we use transliteration as an alternative to translation for all Hindi words. Our focus is disambiguation of Hindi homonyms whereas they are concentrating only on translit-erating NE’s. Moreover, they are working with a large bitext so they can rely on their transla-tion model and only need to transliterate NEs and OOVs. Our translation model is based on data which is both sparse and noisy. Therefore we pit transliterations against translations for every input word. Sinha (2009) presents a rule-based MT sys-tem that uses Hindi as a pivot to translate from En-glish to Urdu. This work also uses transliteration only for the translation of unknown words. Their work can not be used for direct translation from Hindi to Urdu (independently of English) “due to various ambiguous mappings that have to be re-solved”.
The third group uses transliteration models in-side of a cross-lingual IR system (AbdulJaleel and Larkey, 2003; Virga and Khudanpur, 2003; Pirkola et al., 2003). Picking a single best transliteration or translation in context is not important in an IR system. Instead, all the options are used by giv-ing them weights and context is typically not taken into account.
3 Our Approach
Both of our models combine a character-based transliteration model with a word-based transla-tion model. Our models look for the most probable Urdu token sequenceun1 for a given Hindi token sequencehn
1. We assume that each Hindi token is mapped to exactly one Urdu token and that there is no reordering. The assumption of no reordering is reasonable given the fact that Hindi and Urdu have identical grammar structure and the same word or-der. An Urdu token might consist of more than one Urdu word3. The following sections give a
math-3This occurs frequently in case markers with nouns, derivational affixes and compounds etc. These are written as single words in Hindi as opposed to Urdu where they are
ematical formulation of our two models, Model-1 and Model-2.
3.1 Model-1 : Conditional Probability Model
Applying a noisy channel model to compute the most probable translationuˆn
1, we get:
arg max
un
1
p(un1|hn1) = arg max
un
1
p(un1)p(hn1|un1)
(1)
3.1.1 Language Model
Thelanguage model (LM)p(un1)is implemented as an n-gram model using the SRILM-Toolkit (Stolcke, 2002) with Kneser-Ney smoothing. The parameters of the language model are learned from a monolingual Urdu corpus. The language model is defined as:
p(un1) =
n
Y
i=1
pLM(ui|uii−−1k) (2)
where k is a parameter indicating the amount of context used (e.g., k = 4means 5-gram model). ui can be a single or a multi-word token. A
multi-word token consists of two or more Urdu words. For a multi-wordui we do multiple
lan-guage model look-ups, one for each uix inui =
ui1, . . . , uim and take their product to obtain the
valuepLM(ui|uii−−1k).
Language Model for Unknown Words: Our model generates transliterations that can be known or unknown to the language model and the trans-lation model. We refer to the words known to the language model and to the translation model as LM-known and TM-known words respectively and to words that are unknown as LM-unknown and TM-unknown respectively.
We assign a special valueψto the LM-unknown words. If one or moreuix in a multi-wordui are
LM-unknown we assign a language model score pLM(ui|uii−−1k) = ψ for the entire ui, meaning
that we consider partially known transliterations to be as bad as fully unknown transliterations. The parameter ψ controls the trade-off between LM-known and LM-unLM-known transliterations. It does not influence translation options because they are always LM-known in our case. This is because our monolingual corpus also contains the Urdu part of translation corpus. The optimization ofψ is de-scribed in section 4.2.1.
3.1.2 Translation Model
Thetranslation model (TM)p(hn1|un1)is approx-imated with a context-independent model:
p(hn1|un1) =
n
Y
i=1
p(hi|ui) (3)
where hi and ui are Hindi and Urdu tokens
re-spectively. Our model estimates the conditional probability p(hi|ui) by interpolating a
word-based model and a character-word-based (translitera-tion) model.
p(hi|ui) =λpw(hi|ui) + (1−λ)pc(hi|ui) (4)
The parameters of theword-based translation modelpw(h|u)are estimated from the word
align-ments of a small parallel corpus. We only retain 1-1/1-N (1 Hindi word, 1 or more Urdu words) alignments and throw away N-1 and M-N align-ments for our models. This is further discussed in section 4.1.1.
The character-based transliteration model pc(h|u) is computed in terms ofpc(h, u), a joint
character model, which is also used for Chinese-English back-transliteration (Li et al., 2004) and Bengali-English name transliteration (Ekbal et al., 2006). The character-based transliteration proba-bility is defined as follows:
pc(h, u) =
X
an
1∈align(h,u)
p(an1)
= X
an1∈align(h,u)
n
Y
i=1
p(ai|aii−−1k) (5)
whereaiis a pair consisting of the i-th Hindi
char-acterhi and the sequence of 0 or more Urdu
char-acters that it is aligned with. A sample alignment is shown in Table 3(b) in section 4.1.3. Our best results are obtained with a 5-gram model. The parametersp(ai|aii−−1k)are estimated from a small
transliteration corpus which we automatically ex-tracted from the translation corpus. The extrac-tion details are also discussed in secextrac-tion 4.1.3. Be-cause our overall model is a conditional probabil-ity model, joint-probabilities are marginalized us-ing character-based prior probabilities:
pc(h|u) =
pc(h, u)
pc(u)
(6)
Theprior probabilitypc(u)of the character
se-quenceu = cm1 is defined with a character-based
language model:
pc(u) = m
Y
i=1
p(ci|cii−−1k) (7)
The parameters p(ci|cii−−1k) are estimated from
the Urdu part of the character-aligned translitera-tion corpus. Replacing (6) in (4) we get:
p(hi|ui) =λpw(hi|ui) + (1−λ)
pc(hi, ui)
pc(ui)
(8)
Having all the components of our model defined we insert (8) and (2) in (1) to obtain the final equa-tion:
ˆ
un1 = arg max
un
1
n
Y
i=1
pLM(ui|uii−−1k)[λpw(hi|ui)
+ (1−λ)pc(hi, ui)
pc(ui)
] (9)
The optimization of the interpolating factorλis discussed in section 4.2.1.
3.2 Model-2 : Joint Probability Model
This section briefly defines a variant of our model where we interpolate joint probabilities instead of conditional probabilities. Again, the translation modelp(hn1|un1) is approximated with a context-independent model:
p(hn1|un1) =
n
Y
i=1
p(hi|ui) = n
Y
i=1
p(hi, ui)
p(ui)
(10)
The joint probabilityp(hi, ui) of a Hindi and an
Urdu word is estimated by interpolating a word-based model and a character-word-based model.
p(hi, ui) =λpw(hi, ui) + (1−λ)pc(hi, ui) (11)
and the prior probabilityp(ui)is estimated as:
p(ui) =λpw(ui) + (1−λ)pc(ui) (12)
The parameters of the translation modelpw(hi, ui)
and the word-based prior probabilitiespw(ui)are
estimated from the 1-1/1-N word-aligned corpus (the one that we also used to estimate translation probabilitiespw(hi|ui)previously).
The character-based transliteration probability pc(hi, ui) and the character-based prior
the previous section. Putting (11) and (12) in (10) we get
p(hn1|un1) =
n
Y
i=1
λpw(hi, ui) + (1−λ)pc(hi, ui)
λpw(ui) + (1−λ)pc(ui)
(13) The idea is to interpolate joint probabilities and di-vide them by the interpolated marginals. The final equation for Model-2 is given as:
ˆ
un1 = arg max
un
1
n
Y
i=1
pLM(ui|uii−−1k)×
λpw(hi, ui) + (1−λ)pc(hi, ui)
λpw(ui) + (1−λ)pc(ui)
(14)
3.3 Search
The decoder performs a stack-based search using a beam-search algorithm similar to the one used in Pharoah (Koehn, 2004a). It searches for an Urdu string that maximizes the product of trans-lation probability and the language model proba-bility (equation 1) by translating one Hindi word at a time. It is implemented as a two-level pro-cess. At the lower level, it computes n-best transliterations for each Hindi word hi
accord-ing to pc(h, u). The joint probabilities given by
pc(h, u)are marginalized for each Urdu
transliter-ation to givepc(h|u). At the higher level,
translit-eration probabilities are interpolated withpw(h|u)
and then multiplied with language model probabil-ities to give the probability of a hypothesis. We use 20-best translations and 25-best transliterations for pw(h|u) and pc(h|u) respectively and a 5-gram
language model.
To keep the search space manageable and time complexity polynomial we apply pruning and re-combination. Since our model uses monotonic de-coding we only need to recombine hypotheses that have the same context (last n-1 words). Next we do histogram-based pruning, maintaining the 100-best hypotheses for each stack.
4 Evaluation
4.1 Training
This section discusses the training of the different model components.
4.1.1 Translation Corpus
We used the freely available EMILLE Corpus as our bilingual resource which contains roughly 13,000 Urdu and 12,300 Hindi sentences. From
these we were able to sentence-align 7000 sen-tence pairs using the sensen-tence alignment algorithm given by Moore (2002).
The word alignments for this task were ex-tracted by using GIZA++ (Och and Ney, 2003) in both directions. We extracted a total of 107323 alignment pairs (5743 N-1 alignments, 8404 M-N alignments and 93176 1-1/1-M-N alignments). Of these alignments M-N and N-1 alignment pairs were ignored. We manually inspected a sample of 1000 instances of M-N/N-1 alignments and found that more than 70% of these were (totally or par-tially) wrong. Of the 30% correct alignments, roughly one-third constitute N-1 alignments. Most of these are cases where the Urdu part of the align-ment actually consists of two (or three) words but was written without space because of lack of standard writing convention in Urdu. For exam-ple (can go ; d ZA s@kt de) is
alterna-tively written as (can go ; d ZAs@kt de) i.e. without space. We learned that these N-1 translations could be safely dropped because we can generate a separate Urdu word for each Hindi word. For valid M-N alignments we observed that these could be broken into 1-1/1-N alignments in most of the cases. We also observed that we usu-ally have coverage of the resulting 1-1 and 1-N alignments in our translation corpus. Looking at the noise in the incorrect alignments we decided to drop N-1 and M-N cases. We do not model deletions and insertions so we ignored null align-ments. Also 1-N alignments with gaps were ig-nored. Only the alignments with contiguous words were kept.
4.1.2 Monolingual Corpus
Our monolingual Urdu corpus consists of roughly 114K sentences. This comprises 108K sentences from the data made available by the University of Leipzig4 + 5600 sentences from the training data of each fold during cross validation.
4.1.3 Transliteration Corpus
The training corpus for transliteration is extracted from the 1-1/1-N word-alignments of the EMILLE corpus discussed in section 4.1.1. We use an edit distance algorithm to align this training corpus at the character level and we eliminate translation pairs with high edit distance which are unlikely to be transliterations.
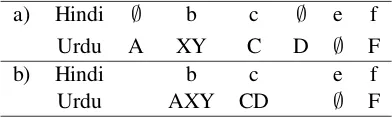
We used our knowledge of the Hindi and Urdu scripts to define the initial character mapping. The mapping was further extended by looking into available Hindi-Urdu transliteration systems[5,6] and other resources (Gupta, 2004; Malik et al., 2008; Jawaid and Ahmed, 2009). Each pair in the character map is assigned a cost. A Hindi charac-ter that always map to only one Urdu characcharac-ter is assigned a cost of0whereas the Hindi characters that map to different Urdu characters are assigned a cost of 0.2. The edit distance metric allows insert, delete and replace operations. The hand-crafted pairs define the cost of replace operations. We set a cost of 0.6 for deletions and insertions. These costs were optimized on held out data. The details of optimization are not mentioned due to limited space. Using this metric we filter out the word pairs with high edit-distance to extract our transliteration corpus. We were able to extract roughly 2100 unique pairs along with their align-ments. The resulting alignments are modified by merging unaligned∅ →1(no character on source side, 1 character on target side) or∅ → N align-ments with the preceding alignment pair. If there is no preceding alignment pair then it is merged with the following pair. Table 3 gives an example showing initial alignment (a) and the final align-ment (b) after applying the merge operation. Our model retains 1 → ∅andN → ∅alignments as deletion operations.
a) Hindi ∅ b c ∅ e f
Urdu A XY C D ∅ F
b) Hindi b c e f
[image:6.595.83.279.481.540.2]Urdu AXY CD ∅ F
Table 3: Alignment (a) Before (b) After Merge
The parameters pc(h, u) and pc(u) are trained
on the aligned corpus using the SRILM toolkit. We use Add-1 smoothing for unigrams and Kneser-Ney smoothing for higher n-grams.
4.1.4 Diacritic Removal and Normalization
In Urdu, short vowels are represented with diacrit-ics but these are rarely written in practice. In or-der to keep the data consistent, all diacritics are removed. This loss of information is not harm-ful when transliterating/translating from Hindi to Urdu because undiacritized text is equally
read-5
CRULP: http://www.crulp.org/software/langproc.htm 6Malerkotla.org: http://translate.malerkotla.co.in
able to native speakers as its diacritized counter part. However leaving occasional diacritics in the corpus can worsen the problem of data sparsity by creating spurious ambiguity7.
There are a few Urdu characters that have mul-tiple equivalent Unicodes. All such forms are nor-malized to have only one representation8.
4.2 Experimental Setup
We perform a 5-fold cross validation taking 4/5 of the data as training and 1/5 as test data. Each fold comprises roughly 1400 test sentences and 5600 training sentences.
4.2.1 Parameter Optimization
Our model contains two parameters λ(the inter-polating factor between translation and transliter-ation modules) andψ (the factor that controls the trade-off between LM-known and LM-unknown transliterations). The interpolating factorλis ini-tialized, inspired by Written-Bell smoothing, with a value of NN+B9. We chose a very low value
1e−40 for the factor ψ initially, favoring LM-known transliterations very strongly. Both of these parameters are optimized as described below.
Because our training data is very sparse we do not use held-out data for parameter optimization. Instead we optimize these parameters by perform-ing a 2-fold optimization for each of the 5 folds. Each fold is divided into two halves. The param-etersλ andψ are optimized on the first half and the other half is used for testing, then optimiza-tion is done on the second half and the first half is used for testing. The optimal value for parameter λoccurs between 0.7-0.84 and for the parameter ψbetween1e−5and1e−10.
4.2.2 Results
BaselineP b0: We ran Moses (Koehn et al., 2007) using Koehn’s training scripts10, doing a 5-fold cross validation with no reordering11. For the other parameters we use the default values i.e. 5-gram language model and maximum phrase-length= 6. Again, the language model is
imple-7It should be noted though that diacritics play a very im-portant role when transliterating in the reverse direction be-cause these are virtually always written in Hindi as dependent vowels.
8www.crulp.org/software/langproc/urdunormalization.htm 9
Nis the number of aligned word pairs (tokens) andBis the number of different aligned word pairs (types).
10
M Pb0 Pb1 Pb2 M1 M2
BLEU 14.3 16.25 16.13 18.6 17.05
Table 4: Comparing Model-1 and Model-2 with Phrase-based Systems
mented as an n-gram model using the SRILM-Toolkit with Kneser-Ney smoothing. Each fold comprises roughly 1400 test sentences, 5000 in training and 600 in dev12. We also used two meth-ods to incorporate transliterations in the phrase-based system:
Post-process P b1: All the OOV words in the phrase-based output are replaced with their top-candidate transliteration as given by our translit-eration system.
Pre-process P b2: Instead of adding translit-erations as a post process we do a second pass by adding the unknown words with their top-candidate transliteration to the training corpus and rerun Koehn’s training script with the new training corpus. Table 4 shows results (taking arithmetic average over 5 folds) from 1 and Model-2 in comparison with three baselines discussed above.
Both our systems (Model-1 and Model-2) beat the baseline phrase-based system with a BLEU point difference of 4.30 and 2.75 respectively. The transliteration aided phrase-based systems P b1 andP b2 are closer to our Model-2 results but are way below Model-1 results. The difference of 2.35 BLEU points betweenM1andP b1indicates that transliteration is useful for more than only translating OOV words for language pairs like Hindi-Urdu. Our models choose between trans-lations and transliterations based on context un-like the phrase-based systemsP b1andP b2which use transliteration only as a tool to translate OOV words.
5 Error Analysis
Based on preliminary experiments we found three major flaws in our initial formulations. This sec-tion discusses each one of them and provides some heuristics and modifications that we employ to try to correct deficiencies we found in the two models described in section 3.1 and 3.2.
12
After having the MERT parameters, we add the 600 dev sentences back into the training corpus, retrain GIZA, and then estimate a new phrase table on all 5600 sentences. We then use the MERT parameters obtained before together with the newer (larger) phrase-table set.
5.1 Heuristic-1
A lot of errors occur because our translation model is built on very sparse and noisy data. The moti-vation for this heuristic is to counter wrong align-ments at least in the case of verbs and functional words (which are often transliterations). This heuristic favors translations that also appear in the n-best transliteration list over only-translation and only-transliteration options. We modify the trans-lation model for both the conditional and the joint model by adding another factor which strongly weighs translation+transliteration options by tak-ing the square-root of the product of the translation and transliteration probabilities. Thus modifying equations (8) and (11) in Model-1 and Model-2 we obtain equations (15) and (16) respectively:
p(hi|ui) =λ1pw(hi|ui) +λ2
pc(hi, ui)
pc(ui)
+λ3 s
pw(hi|ui)
pc(hi, ui)
pc(ui)
(15)
p(hi, ui) =λ1pw(hi, ui) +λ2pc(hi, ui)
+λ3 p
pw(hi, ui)pc(hi, ui) (16)
For the optimization of lambda parameters we hold the value of the translation coefficient λ113 and the transliteration coefficientλ2 constant (us-ing the optimized values as discussed in section 4.2.1) and optimize λ3 again using 2-fold opti-mization on all the folds as described above14.
5.2 Heuristic-2
When an unknown Hindi word occurs for which all transliteration options are LM-unknown then the best transliteration should be selected. The problem in our original models is that a fixed LM probabilityψis used for LM-unknown transliter-ations. Hence our model selects the translitera-tion that has the best pc(hi,ui)
pc(ui) score i.e. we
max-imize pc(hi|ui) instead of pc(ui|hi) (or
equiva-lentlypc(hi, ui)). The reason is an inconsistency
in our models. The language model probabil-ity of unknown words is uniform (and equal to ψ) whereas the translation model uses the non-uniform prior probability pc(ui) for these words.
There is another reason why we can not use the
13
The translation coefficientλ1is same asλused in previ-ous models and the transliteration coefficientλ2= 1−λ
valueψin this case. Our transliterator model also produces space inserted words. The value ofψis very small because of which transliterations that are actually LM-unknown, but are mistakenly bro-ken into constituents that are LM-known, will al-ways be preferred over their counter parts. An ex-ample of this is (America) for which two possible transliterations as given by our model are (AmerIkA, without space) and (AmerI kA, with space). The latter version is LM-known as its constituents are LM-known. Our models al-ways favor the latter version. Space insertion is an important feature of our transliteration model. We want our transliterator to tackle compound words, derivational affixes, case-markers with nouns that are written as one word in Hindi but as two or more words in Urdu. Examples were already shown in section 3’s footnote.
We eliminate the inconsistency by usingpc(ui)
as the 0-gram back-off probability distribution in the language model. For an LM-unknown translit-erations we now get in Model-1:
p(ui|uii−−1k)[λpw(hi|ui) + (1−λ)
pc(hi, ui)
pc(ui)
]
=p(ui|uii−−1k)[(1−λ)
pc(hi, ui)
pc(ui)
]
=
k
Y
j=0
α(uii−−1j)pc(ui)[(1−λ)
pc(hi, ui)
pc(ui)
]
=
k
Y
j=0
α(uii−−1j)[(1−λ)pc(hi, ui)]
where Qk
j=0α(u
i−1
i−j) is just the constant that
SRILM returns for unknown words. The last line of the calculation shows that we simply drop pc(ui) ifui is LM-unknown and use the constant
Qk
j=0α(ui −1
i−j)instead ofψ. A similar calculation
for Model-2 givesQk
j=0α(u
i−1
i−j)pc(hi, ui).
5.3 Heuristic-3
This heuristic discusses a flaw in Model-2. For transliteration options that are TM-unknown, the pw(h, u)andpw(u)factors becomes zero and the
translation model probability as given by equation (13) becomes:
(1−λ)pc(hi, ui)
(1−λ)pc(ui)
= pc(hi, ui)
pc(ui)
In such cases the λ factor cancels out and no weighting of word translation vs. transliteration
H1 H2 H12
M1 18.86 18.97 19.35
[image:8.595.312.441.63.103.2]M2 17.56 17.85 18.34
Table 5: Applying Heuristics 1 and 2 and their Combinations to Model-1 and Model-2
H3 H13 H23 H123
M2 18.52 18.93 18.55 19.00
Table 6: Applying Heuristic 3 and its Combina-tions with other Heuristics to Model-2
occurs anymore. As a result of this, translitera-tions are sometimes incorrectly favored over their translation alternatives.
In order to remedy this problem we assign a minimal probability β to the word-based prior pw(ui) in case of TM-unknown transliterations,
which prevents it from ever being zero. Because of this addition the translation model probability for LM-unknown words becomes:
(1−λ)pc(hi, ui)
λβ+ (1−λ)pc(ui)
whereβ = 1
Urdu Types in TM
6 Final Results
This section shows the improvement in BLEU score by applying heuristics and combinations of heuristics in both the models. Tables 5 and 6 show the improvements achieved by using the differ-ent heuristics and modifications discussed in sec-tion 5. We refer to the results asMxHy wherex
denotes the model number, 1 for the conditional probability model and 2 for the joint probability model andydenotes a heuristic or a combination of heuristics applied to that model15.
Both heuristics (H1 and H2) show improve-ments over their base models M1 and M2. Heuristic-1 shows notable improvement for both models in parts of test data which has high num-ber of common vocabulary words. Using heuris-tic 2 we were able to properly score LM-unknown transliterations against each other. Using these heuristics together we obtain a gain of 0.75 over M-1 and a gain of 1.29 over M-2.
Heuristic-3 remedies the flaw inM2 by assign-ing a special value to the word-based priorpw(ui)
for TM-unknown words which prevents the can-celation of interpolating parameter λ. M2 com-bined with heuristic 3 (M2H3) results in a 1.47
BLEU point improvement and combined with all the heuristics (M2H123) gives an overall gain of 1.95 BLEU points and is close to our best results (M1H12). We also performed significance test by concatenating all the fold results. Both our best systemsM1H12andM2H123 are statistically sig-nificant (p < 0.05)16 over all the baselines
dis-cussed in section 4.2.2.
One important issue that has not been investi-gated yet is that BLEU has not yet been shown to have good performance in morphologically rich target languages like Urdu, but there is no metric known to work better. We observed that some-times on data where the translators preferred to translate rather than doing transliteration our sys-tem is penalized by BLEU even though our out-put string is a valid translation. For other parts of the data where the translators have heavily used transliteration, the system may receive a higher BLEU score. We feel that this is an interesting area of research for automatic metric developers, and that a large scale task of translation to Urdu which would involve a human evaluation cam-paign would be very interesting.
7 Sample Output
This section gives two examples showing how our model (M1H2) performs disambiguation. Given below are some test sentences that have Hindi homonyms (underlined in the examples) along with Urdu output given by our system. In the first
example (given in Figure 1) Hindi word can be transliterated to ( Lion) or (Verse) depend-ing upon the context. Our model correctly identi-fies which transliteration to choose given the con-text.
In the second example (shown in Figure 2) Hindi word can be translated to (peace, s@kun) when it is a common noun but transliter-ated to (Shanti, SAnt di) when it is a proper name. Our model successfully decides whether to translate or transliterate given the context.
8 Conclusion
We have presented a novel way to integrate transliterations into machine translation. In closely related language pairs such as Hindi-Urdu with a significant amount of vocabulary overlap,
16We used Kevin Gimpel’s tester (http://www.ark.cs.cmu.edu/MT/) which uses bootstrap resampling (Koehn, 2004b), with 1000 samples.
Ser d Z@ngl kA rAd ZA he “Lion is the king of jungle”
[image:9.595.332.505.59.188.2]AIqbAl kA Aek xub sur@t d Ser he “There is a beautiful verse from Iqbal”
Figure 1: Different Transliterations in Different Contexts
p hIr b hi vh s@kun se n@he˜rh s@kt dA “Even then he can’t live peacefully”
Aom SAnt di Aom frhA xAn ki d dusri fIl@m he “Om Shanti Om is Farah Khan’s second film”
Figure 2: Translation or Transliteration
transliteration can be very effective in machine translation for more than just translating OOV words. We have addressed two problems. First, transliteration helps overcome the problem of data sparsity and noisy alignments. We are able to gen-erate word translations that are unseen in the trans-lation corpus but known to the language model. Additionally, we can generate novel translitera-tions (that are LM-Unknown). Second, generat-ing multiple transliterations for homograph Hindi words and using language model context helps us solve the problem of disambiguation. We found that the joint probability model performs almost as well as the conditional probability model but that it was more complex to make it work well.
Acknowledgments
References
Nasreen AbdulJaleel and Leah S. Larkey. 2003. Sta-tistical transliteration for English-Arabic cross lan-guage information retrieval. InCIKM 03: Proceed-ings of the twelfth international conference on In-formation and knowledge management, pages 139– 146.
Yaser Al-Onaizan and Kevin Knight. 2002. Translat-ing named entities usTranslat-ing monolTranslat-ingual and bilTranslat-ingual resources. InProceedings of the 40th Annual Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics, pages 400–408.
Asif Ekbal, Sudip Kumar Naskar, and Sivaji Bandy-opadhyay. 2006. A modified joint source-channel model for transliteration. In Proceedings of the COLING/ACL poster sessions, pages 191–198, Syd-ney, Australia. Association for Computational Lin-guistics.
Swati Gupta. 2004. Aligning Hindi and Urdu bilin-gual corpora for robust projection. Masters project dissertation, Department of Computer Science, Uni-versity of Sheffield.
Ulf Hermjakob, Kevin Knight, and Hal Daum´e III. 2008. Name translation in statistical machine trans-lation - learning when to transliterate. In Proceed-ings of ACL-08: HLT, pages 389–397, Columbus, Ohio. Association for Computational Linguistics.
Bushra Jawaid and Tafseer Ahmed. 2009. Hindi to Urdu conversion: beyond simple transliteration. In
Conference on Language and Technology 2009, La-hore, Pakistan.
Mehdi M. Kashani, Eric Joanis, Roland Kuhn, George Foster, and Fred Popowich. 2007. Integration of an Arabic transliteration module into a statistical ma-chine translation system. InProceedings of the Sec-ond Workshop on Statistical Machine Translation, pages 17–24, Prague, Czech Republic. Association for Computational Linguistics.
Kevin Knight and Jonathan Graehl. 1998. Ma-chine transliteration. Computational Linguistics, 24(4):599–612.
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, and Evan Herbst. 2007. Moses: Open source toolkit for statistical machine translation. In
Proceedings of the 45th Annual Meeting of the Asso-ciation for Computational Linguistics, Demonstra-tion Program, Prague, Czech Republic.
Philipp Koehn. 2004a. Pharaoh: A beam search de-coder for phrase-based statistical machine transla-tion models. InAMTA, pages 115–124.
Philipp Koehn. 2004b. Statistical significance tests for machine translation evaluation. In Dekang Lin and
Dekai Wu, editors, Proceedings of EMNLP 2004, pages 388–395, Barcelona, Spain, July. Association for Computational Linguistics.
Haizhou Li, Zhang Min, and Su Jian. 2004. A joint source-channel model for machine transliteration. InACL ’04: Proceedings of the 42nd Annual Meet-ing on Association for Computational LMeet-inguistics, pages 159–166, Barcelona, Spain. Association for Computational Linguistics.
M G Abbas Malik, Christian Boitet, and Pushpak Bhat-tacharyya. 2008. Hindi Urdu machine translitera-tion using finite-state transducers. In Proceedings of the 22nd International Conference on Computa-tional Linguistics, Manchester, UK.
Robert C. Moore. 2002. Fast and accurate sentence alignment of bilingual corpora. InConference of the Association for Machine Translation in the Ameri-cas (AMTA).
Franz J. Och and Hermann Ney. 2003. A systematic comparison of various statistical alignment models.
Computational Linguistics, 29(1):19–51.
Kishore A. Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2001. BLEU: a method for auto-matic evaluation of machine translation. Technical Report RC22176 (W0109-022), IBM Research Di-vision, Thomas J. Watson Research Center, York-town Heights, NY.
Ari Pirkola, Jarmo Toivonen, Heikki Keskustalo, Kari Visala, and Kalervo J¨arvelin. 2003. Fuzzy trans-lation of cross-lingual spelling variants. In SIGIR ’03: Proceedings of the 26th annual international ACM SIGIR conference on Research and develop-ment in informaion retrieval, pages 345–352, New York, NY, USA. ACM.
R. Mahesh K. Sinha. 2009. Developing English-Urdu machine translation via Hindi. InThird Workshop on Computational Approaches to Arabic Script-based Languages (CAASL3), MT Summit XII, Ot-tawa, Canada.
Andreas Stolcke. 2002. SRILM - an extensible lan-guage modeling toolkit. InIntl. Conf. Spoken Lan-guage Processing, Denver, Colorado.
Paola Virga and Sanjeev Khudanpur. 2003. Translit-eration of proper names in cross-lingual information retrieval. InProceedings of the ACL 2003 workshop on Multilingual and mixed-language named entity recognition, pages 57–64, Morristown, NJ, USA. Association for Computational Linguistics.