1
Distantly Supervised Biomedical Knowledge Acquisition via Knowledge
Graph Based Attention
Qin Dai1, Naoya Inoue1,2, Paul Reisert2, Ryo Takahashi1 and Kentaro Inui1,2
1Tohoku University, Japan
2RIKEN Center for Advanced Intelligence Project, Japan
{daiqin, naoya-i, preisert, ryo.t, inui}@ecei.tohoku.ac.jp
Abstract
The increased demand for structured scientific knowledge has attracted considerable attention in extracting scientific relation from the ever growing scientific publications. Distant su-pervision is widely applied approach to auto-matically generate large amounts of labelled data for Relation Extraction (RE). However, distant supervision inevitably accompanies the wrong labelling problem, which will nega-tively affect the RE performance. To address this issue, (Han et al.,2018) proposes a novel framework for jointly training RE model and Knowledge Graph Completion (KGC) model to extract structured knowledge from non-scientific dataset. In this work, we firstly in-vestigate the feasibility of this framework on scientific dataset, specifically on biomedical dataset. Secondly, to achieve better perfor-mance on the biomedical dataset, we extend the framework with other competitive KGC models. Moreover, we proposed a new end-to-end KGC model to extend the framework. Experimental results not only show the fea-sibility of the framework on the biomedical dataset, but also indicate the effectiveness of our extensions, because our extended model achieves significant and consistent improve-ments on distantly supervised RE as compared with baselines.
1 Introduction
Scientific Knowledge Graph (KG), such as Uni-fied Medical Language System (UMLS)1, is ex-tremely crucial for many scientific Natural Lan-guage Processing (NLP) tasks such as Question Answering (QA), Information Retrieval (IR), Re-lation Extraction (RE), etc. Scientific KG provides large collections of relations between entities, typ-ically stored as (h,r,t) triplets, whereh =head
1https://www.nlm.nih.gov/research/
umls/
entity, r =relation andt =tail entity, e.g., ( ac-etaminophen, may treat,pain). However, as with general KGs such as Freebase (Bollacker et al., 2008) and DBpedia (Lehmann et al., 2015), sci-entific KGs are far from complete and this would impede their usefulness in real-world applications. Scientific KGs, on the one hand, face the data spar-sity problem. On the other hand, scientific pub-lications have become the largest repository ever for scientific KGs and continue to increase at an unprecedented rate (Munroe,2013). Therefore, it is an essential and fundamental task to turn the unstructured scientific publications into well orga-nized KG, and it belongs to the task of RE.
In RE, one obstacle that is encountered when building a RE system is the generation of training instances. For coping with this difficulty, (Mintz et al., 2009) proposes distant supervision to au-tomatically generate training samples via leverag-ing the alignment between KGs and texts. They assumes that if two entities are connected by a relation in a KG, then all sentences that contain these entity pairs will express the relation. For in-stance, (aspirin, may treat, pain) is a fact triplet in UMLS. Distant supervision will automatically label all sentences, such as Example 1, Exam-ple2and Example3, as positive instances for the relation may treat. Although distant supervision could provide a large amount of training data at low cost, it always suffers from wrong labelling problem. For instance, comparing to Example1, Example2 and Example 3should not be seen as the evidences to support themay treatrelationship betweenaspirin and pain, but will still be anno-tated as positive instances by the distant supervi-sion.
(2) The tumor was remarkably large in size , and
painunrelieved byaspirin.
(3) The level ofpaindid not change significantly with eitheraspirinor pentoxifylline , but the walking distance was farther with the pentox-ifylline group .
To automatically alleviate the wrong labelling problem, (Riedel et al., 2010; Hoffmann et al., 2011) apply multi-instance learning. In order to avoid the handcrafted features and errors propa-gated from NLP tools, (Zeng et al.,2015) proposes a Convolutional Neural Network (CNN), which incorporate mutli-instance learning with neural network model, and achieves significant improve-ment in distantly supervised RE. Despite the im-pressive achievement in RE, this model still has the limitation that it only selects the most infor-mative sentence and ignores the rest, thereby loses the rich information stored in those neglected sen-tences, For instance, among Example 1, Exam-ple 2 and Example 3, Example 1 is undoubtedly the most informative one for detecting relation may treat, but it unnecessarily means other sen-tences such as Example3could not contribute to the relation detection. In Example3, entityaspirin and entitypentoxifyllinehave alternative relation, and the latter is a drug to treat muscle pain, there-fore the former is also likely to be a pain-killing drug. To address this issue, recently, attention mechanism is applied to extract features from all collected sentences. (Lin et al.,2016) proposes a relation vector based attention mechanism for dis-tantly supervised RE. (Han et al.,2018) proposes a novel joint model that leverages the KG-based attention mechanism and achieves better perfor-mance than (Lin et al., 2016) on distantly super-vised RE from New York Times (NYT) corpus.
The success that the joint model (Han et al., 2018) has attained in the newswire domain (or non-scientific domain) inspires us to choose the strong model as our base model and assess its feasibility on biomedical domain. Specifically, the first question of this research is how the joint model behaves when the system is trained on biomedical KG (e.g., UMLS) and biomeical cor-pus (e.g., Medline corcor-pus). (Han et al., 2018) indicates that the performance of the base model could be affected the representation ability of KGC model. The representation ability of a KGC model also varies with dataset (Wang et al.,2017).
Therefore, given a new dataset (e.g., a biomedical dataset), it is necessary to extend the base model with other competitive KGC models, and choose the best fit for the given dataset. However, the base model only implements two KGC models, which are based on TransE (Bordes et al., 2013) and TransD (Ji et al.,2015) respectively. Thus, the second question of this work is how other com-petitive KGC models such as ComplEx (Trouil-lon et al., 2016) and SimplE (Kazemi and Poole, 2018) influence the performance of the base model on biomedical dataset. At last but not least, in biomedical KG, a relation is scientifically re-stricted by entity type (ET). For instance, in the relation (h, may treat, t), the ET of t should be
Disease or Syndrome. Therefore, ET in-formation is an important feature for biomedical RE and KGC. For leveraging the ET information, which the base model lacks, in this work, we pro-pose an end-to-end KGC model to enhance the base model. The proposed KGC model is capable of identifying ET via the word embedding of tar-get entity and incorporating the predicted ET into a state-of-to-art KGC model to evaluate the plau-sibility of potential fact triplets.
We conduct evaluation on biomedical datasets in which KG is collected from UMLS and textual data is extracted from Medline corpus. The ex-perimental results not only show the feasibility of the base model on the biomedical domain, but also prove the effectiveness of our proposed extensions for the base model.
2 Related Work
RE.
Although remarkably good performances are achieved by the models mentioned above, they still train and extract relations on sentence-level and thus need a large amount of annotation data, which is expensive and time-consuming. To ad-dress this issue, distant supervision is proposed by (Mintz et al., 2009). To alleviate the noisy data from the distant supervision, many studies model distant supervision for RE as a Multiple Instance Learning (MIL) problem (Riedel et al., 2010;Hoffmann et al.,2011;Zeng et al.,2015), in which all sentences containing a target entity pair (e.g.,aspirinandpain) are seen as a bag to be clas-sified. To make full use of all the sentences in the bag, rather than just the most informative one, (Lin et al.,2016) proposes a relation vector based atten-tion mechanism to extract feature from the entire bag and outperforms the prior approaches. (Han et al.,2018) proposes a joint model that adopts a KG-based attention mechanism and achieves bet-ter performance than (Lin et al.,2016) on distantly supervised RE from NYT corpus.
In this work, we are primarily interested in ap-plying distant supervision techniques to extract biomedical fact triplets from scientific publica-tions. To validate and enhance the efficacy of the previous techniques in biomedical domain, we choose the strong joint model proposed by (Han et al., 2018) as the base model and make some necessary extension for our scientific RE task. Since from the two main groups of KGC models (Wang et al., 2017): translational dis-tance models and semantic matching models, the base model only implements the translational dis-tance models, TransE (Bordes et al., 2013) and TransD (Ji et al., 2015), we thus extend the base model with the semantic matching models, Com-plEx (Trouillon et al.,2016) and SimplE (Kazemi and Poole,2018), for selecting the best fit for our task. In addition, the base model has not incor-porated the ET information, which we assume is crucial for scientific RE. Therefore, we propose an end-to-end KGC model to enhance the base model. Different from the work (Xie et al.,2016), which utilizes an ET look-up dictionary to obtain ET, the end-to-end KGC is capable of identifying ET via the word embedding of a target entity and thus is free of the attachment to an incomplete ET look-up dictionary.
...
C&P
...
× a1
...
C&P
...
× a2
...
C&P
...
× a3
...
C&P
...
× am
...
+ RC
... ... ...
KGS
(e1, e2) (e1, r, e2)
s1 s2 s3 sm
s1 s2 s3 sm
h r t
ATS
sfinal
RE Part KGC Part
RC
C&P ATS
KGS Knowledge Graph Scoring
Attention Scoring
Pointwise Operation
Relation Classification
Convolution & Pooling
...
...
[image:3.595.308.527.61.259.2]...
Figure 1: Overview of the base model.
3 Base Model
The architecture of the base model is illustrated in Figure1. In this section, we will introduce the base model proposed by (Han et al.,2018) in two main parts: KGC part, RE part.
3.1 KGC Part
Suppose we have a KG containing a set of fact tripletsO = {(e1, r, e2)}, where each fact triplet consists of two entities e1, e2 ∈ E and their re-lation r ∈ R. Here E and R stand for the set of entities and relations respectively. KGC model then encodese1, e2 ∈ E and their relationr ∈ R
into low-dimensional vectors h, t ∈ Rd and r
∈ Rd respectively, where d is the dimensional-ity of the embedding space. As mentioned above, the base model adopts two representative trans-lational distance models TransE and Prob-TransD, which are based on TransE (Bordes et al., 2013) and TransD (Ji et al.,2015) repectively, to score a fact triplet. Specifically, given an entity pair (e1, e2), Prob-TransE defines its latent rela-tion embeddingrhtvia the Equation1.
rht =t−h (1)
Prob-TransD is an extension of Prob-TransE and introduces additional mapping vectors hp, tp ∈
Rd and rp ∈ Rd for e1, e2 and r respectively. Prob-TransD encodes the latent relation embed-ding via the Equation 2, where Mrh and Mrt
are projection matrices for mapping entity embed-dings into relation spaces.
hr=Mrhh,
tr =Mrtt,
Mrh =rph>p +Id
×d,
Mrt=rpt>p +Id×d
The conditional probability can be formalized over all fact triplets O via the Equations 3 and 4, where fr(e1, e2) is the KG scoring function, which is used to evaluate the plausibility of a given fact triplet. For instance, the score for (aspirin, may treat,pain) would be higher than the one for (aspirin,has ingredient,pain), because the former is more plausible than the latter.θEandθRare pa-rameters for entities and relations respectively,bis a bias constant.
P(r|(e1, e2), θE, θR) =
exp(fr(e1, e2))
P
r0∈Rexp(fr0(e1, e2))
(3)
fr(e1, e2) =b− krht−rk (4)
3.2 RE Part
Sentence Representation Learning.Given a sen-tence s with n words s = {w1, ..., wn}
includ-ing a target entity pair (e1, e2), CNN is used to generate a distributed representation s for the sentence. Specifically, vector representation vt
for each word wt is calculated via Equation 5,
whereWwembis a word embedding projection ma-trix (Mikolov et al.,2013),Wwpembis a word posi-tion embedding projecposi-tion matrix,xwt is a one-hot word representation andxwpt is a one-hot word po-sition representation. The word popo-sition describes the relative distance between the current word and the target entity pair (Zeng et al.,2014). For in-stance, in the sentence “Patients recorded pain
e2
and aspirin
e1 consumption in a daily diary”, the
relative distance of the word“and”is[1, -1].
vt= [vtw;v wp1
t ;v wp2
t ], (5)
vwt =Wembw xwt,
vwpt 1 =Wwpembxwpt 1,
vwpt 2=Wwpembxwpt 2
The distributed representationsis formulated via the Equation 6, where, [s]i and[ht]i are the i-th
value of s andht, M is the dimensionality of s,
W is the convolution kernal, b is a bias vector, andkis the convolutional window size.
[s]i = max
t {[ht]i}, ∀i= 1, ..., M (6)
ht= tanh(Wzt+b),
zt= [vt−(k−1)/2;...;vt+(k−1)/2]
KG-based Attention. Suppose for each fact triplet (e1, r, e2), there might be multiple sen-tencesSr = {s1, ..., sm} in which each sentence
contains the entity pair(e1, e2)and is assumed to imply the relationr, mis the size ofSr. As
dis-cussed before, the distant supervision inevitably collect noisy sentences, the base model adopts a KG-based attention mechanism to discriminate the informative sentences from the noisy ones. Specif-ically, the base model use the latent relation em-bedding rht from Equation 1 (or Equation 2) as
the attention overSrto generate its final
represen-tation sf inal. sf inal is calculated via Equation 7,
whereWsis the weight matrix,bsis the bias
vec-tor,aiis the weight forsi, which is the distributed
representation for thei-th sentence inSr.
sf inal = m
X
i=1
aisi, (7)
ai=
exp(hrht,xii)
Pm
k=1exp(hrht,xki) ,
xi = tanh(Wssi+bs)
Finally, the conditional probability P(r|Sr, θ)
is formulated via Equation 8 and Equation 9, where,θis the parameters for RE, which includes
{Wwemb,Wwpemb,W,b,Ws,bs,M,d}, M is the
representation matrix of relations,dis a bias vec-tor, o is the output vector containing the predic-tion probabilities of all target relapredic-tions for the in-put sentences setSr, andnris the total number of
relations.
P(r|Sr, θ) =
exp(or)
Pnr
c=1exp(oc)
(8)
o=Msf inal+d (9)
4 Extensions
to find the optimal combination for our biomedi-cal dataset. However, the base model only imple-ments translational distance models: TransE and TransD, but not the semantic matching models, and this, we assume, might hinder its performance in the new dataset. To address this, we select two representative semantic matching models: Com-plEx (Trouillon et al.,2016) and SimplE (Kazemi and Poole,2018) as the alternative KGC part.
As discussed in Section 1, in scientific KGs, a fact triplet is severely restricted by ET information (e.g., ET of e2 should be
Disease or Syndrome in the fact triplet
(e1, may treat, e2)). Therefore, for leveraging ET information, which the base model lacks, we also propose an end-to-end KGC model to extend the base model. Since the proposed KGC model is build on SimplE and is capable of Named Entity Recognition (NER), we call it SimplE NER.
4.1 ComplEx based Attention
Given a fact triplet(e1, r, e2), ComplEx then en-codes entitiese1,e2and relationrinto a complex-valued vector e1 ∈ Cd, e2 ∈ Cd andr ∈ Cd respectively, wheredis the dimensionality of the embedding space. Since entities and relations are represented as complex-valued vector, each x ∈
Cd consists of a real vector component Re(x)
and imaginary vector componentIm(x), namely
x=Re(x)+iIm(x). The KG scoring function of ComplEx for a fact triplet(e1, r, e2)is calculated via Equation10, where¯e2 is the conjugate ofe2; Re(·)(orIm(·)) means taking the real (or imagi-nary) part of a complex value. hu, v, wiis defined via Equation11, where[·]n is then-th entry of a
vector.
fr(e1, e2) =Re(he1,r,e¯2i) =
hRe(r), Re(e1), Re(e2)i
+hRe(r), Im(e1), Im(e2)i
+hIm(r), Re(e1), Im(e2)i
−hIm(r), Im(e1), Re(e2)i
(10)
hu,v,wi= d
X
n=1
[u]n[v]n[w]n (11)
Since the asymmetry of this scoring function, namelyfr(e1, e2) =6 fr(e2, e1), ComplEx can ef-fectively encode asymmetric relations (Trouillon et al.,2016). For calculating the attention, therht
in Equation7is defined via Equation12, where
represents the element-wise multiplication.
rht=Re(e1)Re(e2)+Im(e1)Im(e2) (12)
4.2 SimplE based Attention
Given a fact triplet (e1, r, e2), SimplE then en-codes each entity e ∈ E into two vectors he, te ∈ Rd and each relation r ∈ R into two vectors
vr, vr−1 ∈ Rd respectively, where d is the
di-mensionality of the embedding space.hecaptures
the entitye’s behaviour as thehead entityof a fact triplet andtecapturese’s behaviour as thetail
en-tity. vr represents r in a fact triplet (e1, r, e2), while vr−1 represents its inverse relation r−1 in
the triplet(e2, r−1, e1). The KG scoring function of SimplE for a fact triplet(e1, r, e2)is defined via Equation13.
fr(e1, e2) = 1
2(hhe1,vr,te2i+hhe2,vr−1,te1i)
(13) Similar to the attention from ComplEx, therht in
Equation7is defined via Equation14.
rht =
1
2(he1 he2+te1 te2) (14)
4.3 SimplE NER based Attention
The proposed end-to-end KGC model is based on SimplE, because SimplE outperforms sev-eral state-of-the-art models including Com-plEx (Kazemi and Poole, 2018). The proposed model is illustrated in Figure 2. It includes ET classification part (below) and KG Scoring part (above). In ET classification part, a multi-layer perceptron (MLP) with two hidden layers are applied to identify ET based on word embedding of target entity. In KG Scoring part, head entity andtail entityalong with their predicted ETs and their relation are projected into corresponding KG embeddings, which are then fed to a KG scoring function.
ET Classification Part. In this work, we use a MLP network to classify ET forhead entityand tail entity. The architecture of our MLP network is as bellow:
hw = tanh(Wwembxw),
h1 =sigmoid(W1hw+b1),
h2 =sigmoid(W2h1+b2), y=sigmoid(WETh2+bET)
(15)
... ...
MLP MLP
Entity Type Entity Type
KG Scoring
Knowledge Graph Scoring
Part
Entity Type Classification
Part
KG embedding Word embedding
Knowledge
Fact Head Entity Relation Tail Entity e.g.,"dopamine" e.g.,"may be treated by"
e.g.,"hypotension"
e.g.,Disease or Syndrome e.g.,Biologically Active Substance
Figure 2: Overview of the proposed end-to-end KGC model.
embedding that is trained on Medline corpus via Gensim word2vec tool,xwis a one-hot entity rep-resentation, yis the output vector containing the prediction probabilities of all target ETs.W1,b1, W2, b2, WET andbET are parameters to
opti-mize.
KG Scoring Part. Given fact triplet and pre-dicted ET pair ET1 (for e1) and ET2 (for e2), the proposed model project them into their cor-responding KG embeddings namelyhe1, te1, vr, vr−1,he2,te2,hET1,tET1,hET2andtET2
respec-tively, where hET1 (or tET1) represents the KG
embedding of ET fore1whene1 acts as thehead entity(ortail entity) in a fact triplet. The KG scor-ing function is defined via Equation16. Since the proposed KGC model is build on SimplE, we ap-ply Equation14to calculaterht.
fr(e1, e2) = 1
4(hhe1,vr,te2i
+hhe2,vr−1,te1i
+hhET1,vr,tET2i
+hhET2,vr−1,tET1i)
(16)
5 Experiments
Our experiments aim to demonstrate that, (1) the base model proposed by (Han et al.,2018) is fea-sible for biomedical dataset, such as UMLS and Medline corpus, and (2) in order to improve the performance on the given biomedical dataset, it is necessary to extend the base model with other competitive KGC models, such as ComplEx and SimplE, and (3) the proposed end-to-end KGC model is effective for distantly supervised RE from biomedical dataset.
#Entity #Relation #Train #Test
[image:6.595.73.291.62.203.2]25,080 360 53,036 11,810
Table 1: Statistics of KG in this work.
5.1 Data
The biomedical datasets used for evaluation con-sist of biomedical knowledge graph and biomedi-cal textual data, which will be detailed as follows.
Knowledge Graph. We choose the UMLS as the KG. UMLS is a large biomedical knowledge base developed at the U.S. National Library of Medicine. UMLS contains millions of biomedi-cal concepts and relations between them. We fol-low (Wang et al.,2014), and only collect the fact triplet with RO relation category (RO stands for “has Relationship Other than synonymous, nar-rower, or broader”), which covers the interesting relations likemay treat,my prevent, etc. From the UMLS 2018 release, we extract about60thousand such RO fact triplets (i.e., (e1, r, e2)) under the restriction that their entity pairs (i.e., e1 and e2) should coexist within a sentence in Medline cor-pus. They are then randomly divided into train-ing and testtrain-ing sets for KGC. Followtrain-ing (Weston et al.,2013), we keep high entity overlap between training and testing set, but zero fact triplet over-lap. The statistics of the extracted KG is shown in Table 1. For training the ET Classification Part in Section4.3, we also collect about 35 thou-sand entity-ET pairs (e.g.,heart rates-Clinical Attribute) from the UMLS 2018 release.
Textual Data. Medline corpus is a collection of bimedical abstracts maintained by the National Library of Medicine. From the Medline corpus, by applying a string matching model2, we extract
732,771 sentences that contain the entity pairs (i.e.,e1ande2) in the KG mentioned above as our textual data, in which 592,605sentences are for training and 140,166 sentences for testing. For identifying the NA relation, besides the “related” sentences, we also extract the “unrelated” sen-tences based on a closed world assumption: pairs of entities not listed in the KG are regarded to have NA relation and sentences containing them con-sidered to be the “unrelated” sentences. By this way, we extract1,738,801“unrelated” sentences for the training data, and431,212“unrelated” sen-tences for the testing data. Table2presents some
2We adopt the NER model that is available athttps:
0.0 0.2 0.4 0.6 0.8 1.0 Recall
0.0 0.2 0.4 0.6 0.8 1.0
Precision
[image:7.595.77.285.65.284.2]CNN+ATT CNN+AVE JointD+KATT JointE+KATT JointComplEx+KATT JointSimplE+KATT JointSimplE_NER+KATT
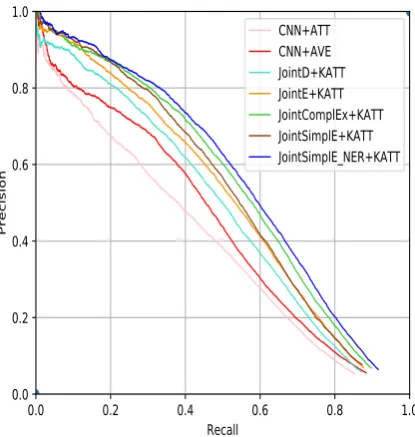
Figure 3: Aggregate precision/recall curves for differ-ent RE models.
sample sentences in the training data.
5.2 Parameter Settings
We base our work on (Han et al., 2018) and ex-tend their implementation available athttps://
github.com/thunlp/JointNRE, and thus
adopt identical optimization process. We use the default settings of parameters 3 provided by the base model. Since we address the distantly super-vised RE in biomedical domain, we use the Med-line corpus to train the domain specific word em-bedding projection matrixWwemb.
5.3 Result and Discussion
(Han et al.,2018) evaluates the base model on non-scientific dataset. In this work, we firstly plan to assess its feasibility on scientific dataset, and sec-ondly, to investigate the effectiveness of our exten-sions, which is discussed in Section4, with respect to enhancing the distantly supervised RE from sci-entific dataset.
Relation Extraction We follow (Mintz et al., 2009;Weston et al., 2013; Lin et al., 2016;Han et al.,2018) and conduct the held-out evaluation, in which the model for distantly supervised RE is evaluated by comparing the fact triplets identi-fied from textual data (i.e., the bag of sentences containing the target entity pairs) with those in
3As a preliminary study, we only adopt the default hyper-parameters, but we will tune them in the furture.
KG. We report precision-recall curves and Preci-sion@N (P@N) as well in our evaluation.
The precision-recall curves are shown
in Figure 3, where “JointD+KATT” and
“JointE+KATT” represent the RE model with the KG-based attention obtained from Prob-TransD and Prob-TransE respectively, which are our base models and trained on both KG and textual data. Similarly, “JointComplEx+KATT”,
“JointSim-plE+KATT” and “JointSimplE NER+KATT”
represent the RE model with the KG-based attention obtained from ComplEx, SimplE and SimplE NER respectively, which are our exten-sions. “CNN+AVE” and “CNN+ATT” represent the RE model with average attention and relation vector based attention (Lin et al., 2016) respec-tively, which are not joint models and only trained on textual data. The results show that:
(1) All RE models with KG-based attention, such as “JointE+KATT”, outperform those models without it, such as “CNN+ATT”. This observation is in line with (Han et al., 2018). This demon-strates that not just for non-scientific dataset , jointly training a KGC model with a RE model is also an effective approach to improve the per-formance of distantly supervised RE for biomed-ical dataset. In other words, the outperformance proves the feasibility of the base model proposed by (Han et al.,2018) on biomedical dataset. The comparison between (Han et al.,2018)’s results on non-scientific dataset and ours on scientific dataset also indicates that the performance of base model could differ according to the dataset. Specifically, on scientific dataset, “JointE+KATT” performs better than “JointD+KATT” but in non-scientific dataset the latter outperforms the former.
(2) Our extended models,
“JointCom-plEx+KATT”, “JointSimplE+KATT” and
“JointSimplE NER+KATT”, achieve better
Fact Triplet Textual Data
(insulin,
gene plays role in process, lipid metabolism)
s1:It is unknown whether short - term angiotensin receptor blocker therapy
can improve glucose and lipid metabolisme2in insuline1- resistant subjects. s2:Adipocyte lipid metabolisme2is primarily regulated by insuline1and the
catecholamines norepinephrine and epinephrine.
s3:...
(insulin, NA, TPA)
s1:M wortmannin resulted in 80% and 20% decreases of glucose uptake
stimulated by insuline1and TPAe2, respectively.
s2:The effects of insuline1, IGF1 and TPAe2were also observed in the
presence of cycloheximide.
[image:8.595.81.515.62.201.2]s3:...
Table 2: Examples of textual data extracted from Medline corpus.
such as ComplEx and SimplE, for increasing the performance of distantly supervised RE. The effect of different KGC models on the distantly supervised RE will be discussed later.
(3) The model enhanced by our proposed KGC model, “JointSimplE NER+KATT”, achieves the highest precision over almost entire range of recall compared with the models that apply the existing KGC models. This proves the effectiveness of our proposed KGC model for the distantly supervised RE. Additionally, different from the exiting KGC models, the proposed end-to-end KGC model is capable of identifying ET information from word embedding of target entity. This indicates that the incorporation of semantic information of entity, such as ET, is a promising approach for enhanc-ing the base model.
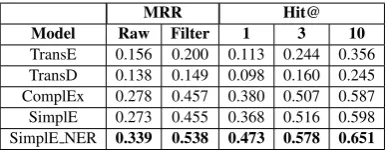
Effect of KGC on RE. (Han et al., 2018) in-dicates that KGC models could affect the perfor-mance of distantly supervised RE. For investigat-ing the influence of KGC models on our specific RE task, we compare their link prediction results on our KG with their corresponding Precision@N (P@N) results on our RE task. Link prediction is the task that predictstail entitytgiven bothhead entity h and relation r, e.g., (h, r,∗), or predict head entity hgiven (∗, r, t). We report the mean reciprocal rank (MRR) and mean Hit@N scores for evaluating the KGC models. MRR is defined as: M RR = 2∗|1tt|P
(h,r,t)∈tt(rank1 h +
1
rankt), wherettrepresents the test triplets. Hit@N is the proportion of the correctly predicted entities (hor t) in top N ranked entities. Table3and Table4 rep-resent the RE precision@N and link prediction re-sults respectively. This comparison indicates that given a biomedical dataset, the performance of a KGC model on the link prediction task could pre-dict its effectiveness on its corresponding distantly
supervised RE task. This observation also instruct us how to select the best KGC model for the base model. In addition, Table3and Table 4 indicate that ET is not only effective for distantly super-vised RE task, but also for KGC task, and this ob-servation will inspire us to explore other useful se-mantic feature of entity, such as the definition of entity, for our task.
Model P@2k P@4k P@6k Mean
JointE+KATT 0.876 0.786 0.698 0.786 JointD+KATT 0.848 0.725 0.528 0.700 JointComplEx+KATT 0.892 0.819 0.741 0.817 JointSimplE+KATT 0.900 0.808 0.721 0.809 JointSimplE NER+KATT 0.913 0.829 0.753 0.831
Table 3: P@N for different RE models, where k=1000.
MRR Hit@ Model Raw Filter 1 3 10
TransE 0.156 0.200 0.113 0.244 0.356 TransD 0.138 0.149 0.098 0.160 0.245 ComplEx 0.278 0.457 0.380 0.507 0.587 SimplE 0.273 0.455 0.368 0.516 0.598 SimplE NER 0.339 0.538 0.473 0.578 0.651
Table 4: Link prediction results for different KGC models.
6 Conclusion and Future Work
[image:8.595.320.516.466.541.2]model on the biomedical domain, but also indicate the effectiveness of our extensions. Our extended model achieves significant and consistent im-provements on the biomedical dataset as compared with baselines. Since the semantic information of target entity, such as ET information, is effective for our task, in the future, we will explore other useful semantic features, such as the definition of target entity and fact triplet chain between enti-ties (e.g., cancer→disease has associated gene→
Ku86→gene plays role in process→NHEJ), for our task.
Acknowledgement
This work was supported by JST CREST Grant Number JPMJCR1513, Japan and KAKENHI Grant Number 16H06614.
References
Waleed Ammar, Matthew Peters, Chandra Bhagavat-ula, and Russell Power. 2017. The ai2 system at semeval-2017 task 10 (scienceie): semi-supervised end-to-end entity and relation extraction. In Pro-ceedings of the 11th International Workshop on Se-mantic Evaluation (SemEval-2017), pages 592–596.
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collab-oratively created graph database for structuring hu-man knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 1247–1250. AcM.
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems, pages 2787–2795.
Jinghang Gu, Fuqing Sun, Longhua Qian, and Guodong Zhou. 2017. Chemical-induced disease re-lation extraction via convolutional neural network.
Database, 2017.
Gus Hahn-Powell, Dane Bell, Marco A Valenzuela-Esc´arcega, and Mihai Surdeanu. 2016. This before that: Causal precedence in the biomedical domain.
arXiv preprint arXiv:1606.08089.
Xu Han, Zhiyuan Liu, and Maosong Sun. 2018. Neural knowledge acquisition via mutual attention between knowledge graph and text. InThirty-Second AAAI Conference on Artificial Intelligence.
Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer, and Daniel S Weld. 2011. Knowledge-based weak supervision for information extraction of overlapping relations. InProceedings of the 49th
Annual Meeting of the Association for Computa-tional Linguistics: Human Language Technologies-Volume 1, pages 541–550. Association for Compu-tational Linguistics.
Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, and Jun Zhao. 2015. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Compu-tational Linguistics and the 7th International Joint Conference on Natural Language Processing (Vol-ume 1: Long Papers), volume 1, pages 687–696.
Seyed Mehran Kazemi and David Poole. 2018. Simple embedding for link prediction in knowledge graphs. InAdvances in Neural Information Processing Sys-tems, pages 4289–4300.
Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas, Pablo N Mendes, Sebastian Hellmann, Mohamed Morsey, Patrick Van Kleef, S¨oren Auer, et al. 2015. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semantic Web, 6(2):167–195.
Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances. In Proceed-ings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa-pers), volume 1, pages 2124–2133.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Cor-rado, and Jeff Dean. 2013. Distributed representa-tions of words and phrases and their compositional-ity. InAdvances in neural information processing systems, pages 3111–3119.
Mike Mintz, Steven Bills, Rion Snow, and Dan Juraf-sky. 2009. Distant supervision for relation extrac-tion without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Vol-ume 2-VolVol-ume 2, pages 1003–1011. Association for Computational Linguistics.
Makoto Miwa and Mohit Bansal. 2016. End-to-end re-lation extraction using lstms on sequences and tree structures.arXiv preprint arXiv:1601.00770.
Randall Munroe. 2013. The rise of open access. Sci-ence, 342(6154):58–59.
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions with-out labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 148–163. Springer.
Th´eo Trouillon, Johannes Welbl, Sebastian Riedel, ´Eric Gaussier, and Guillaume Bouchard. 2016. Com-plex embeddings for simple link prediction. In In-ternational Conference on Machine Learning, pages 2071–2080.
Quan Wang, Zhendong Mao, Bin Wang, and Li Guo. 2017. Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge and Data Engineering, 29(12):2724– 2743.
Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by trans-lating on hyperplanes. In AAAI, volume 14, pages 1112–1119.
Jason Weston, Antoine Bordes, Oksana Yakhnenko, and Nicolas Usunier. 2013. Connecting language and knowledge bases with embedding models for re-lation extraction. arXiv preprint arXiv:1307.7973.
Ruobing Xie, Zhiyuan Liu, and Maosong Sun. 2016. Representation learning of knowledge graphs with hierarchical types. InIJCAI, pages 2965–2971.
Kun Xu, Yansong Feng, Songfang Huang, and Dongyan Zhao. 2015. Semantic relation clas-sification via convolutional neural networks with simple negative sampling. arXiv preprint arXiv:1506.07650.
Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Pro-ceedings of the 2015 Conference on Empirical Meth-ods in Natural Language Processing, pages 1753– 1762.
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, Jun Zhao, et al. 2014. Relation classification via convolutional deep neural network. In COLING, pages 2335–2344.
Dongxu Zhang and Dong Wang. 2015. Relation classi-fication via recurrent neural network.arXiv preprint arXiv:1508.01006.