ISSN: 2394-2231
http://www.ijctjournal.org
Page 81
Quality Assessment of Soil Moisture Observation by
Support Vector Machine and Particle Swarm
Optimization Algorithm with Environment Prediction
1
P.Karthik,
2R.Mani
1
Assistant professor, Dept.of.Computer science , Ponnaiyah Ramajayam institute of Science and Technology (PRIST) Thanjavur
2
Research Scholar, Dept.of.Computer science, Ponnaiyah Ramajayam institute of Science and Technology (PRIST) Thanjavur
Abstract
This project present a survey of the experiential literature on the effects of typical weather change and weather circumstances on the convey sector. in spite of mixed confirmation on numerous issues, several pattern can be observed. On a worldwide scale particularly shifts in sightseeing and undeveloped production due to augmented temperatures may lead to shifts in passenger and shipment transport. Weather change connected shifts in weather patterns power also cause communications disruptions. Clear patterns are that rainfall affects road safety by increasing accident frequency but declining sternness. Precipitation also amplify overcrowding, especially during peak hours. Additionally, an improved frequency of low water levels may drastically increase costs of inland watercourse transport. In ill feeling of this future, the net impact of climate change on prevalent costs of the various transport modes is uncertain and hazy, with a probable exception for Inland River bring.
Keywords-Climate Change and Weather Condition, Transport, Infrastructure Disruptions, Weather Patterns, Uncertain Transport.
I.INTRODUCTION
Climate change is almost perpetually considered an issue of global attention. However, the extent to which climate change represents a problem is still a heavily deliberate issue; calculations on future damages associated with climate change, and therefore also judgment about alleviation and adaptation costs to be made now, differ widely. For example, the influential Stern report claims that ‘the reimbursement of strong, early action considerably outweigh the costs’. Although the report has conventional wide attention, considerable criticism has arisen. For instance, argues that for ‘water, crop growing, health and indemnity, the Stern review every time selects the most negative study in the literature’. Another point of disparagement comes from, who focus on the unusually low social reduction rate of 0.1% used in the report. Ever since a near-zero reduction rate gives a large weight to climate change damages in the remote future, losses are large even when distant expectations damages are small. Using a discount rate that is more normally accepted, Nordhaus shows that the extremely low discount rate used in the Stern report is the main reason for the abnormally large damage estimates.
The disaster is the unwanted natural proceedings that produce a significant amount of losses in terms of human life and the revenue. In this context the disaster administration techniques are deployed to reduce or control the loss. According to the disaster organization techniques the entire process is handled in three major phases before disaster attentiveness that helps to aware about the target disaster and their complexities. Secondly during the disaster relief, which provides the help to handle current situation of disasters finally the recuperation in this phase the social, economic and support based recovery is performed. According to proposed hypothesis if the disasters are predicted before its happening then a lot of wounded can be prevented. Therefore in this obtainable work a new data mining based model is presented that helps to predict the unnecessary natural events. Thus the following transitional objectives are incorporated for work.
ISSN: 2394-2231
http://www.ijctjournal.org
Page 82
1. Study about the different kinds of disaster in India: in this phase the dissimilar natural disasters are studied that normally affect the human life much commonly.2. Study the prognostic data mining techniques: in this phase the different data mining and forecast technique are studied that are help to intend an accurate data representation.
3. Design and accomplishment of new data model by which forecast of disaster becomes feasible: in this phase a new data model using the understanding of the study is proposed and implement for prediction of the disasters prediction system is perform.
4. Performance investigation of the proposed data model: in this phase the projected data models evaluated on different performance parameters. Therefore the correctness and the resource expenditure are measured as presentation parameter.
Climate is the long-term effect of the sun's emission on the rotating earth's varied surface and ambiance. The Day-by-day variations in a given area comprise the weather, whereas type of weather is the long-term synthesis of such variation. Weather is premeditated by thermometers, rain measure, barometer, and other apparatus, but the study of climate relies on statistics. Nowadays, such figures are handled professionally by computers. A straightforward, long-term summing up of weather change, however, is still not a true demonstration of climate. To obtain this requires the analysis of daily, monthly, and yearly pattern.
II. LITERATURE SURVEY
E. G. Petre [1] obtainable a small capitulation of CART decision tree algorithm for climate calculation. The data collected is register over Hong Kong. The data is documentation between 2002 and 2005. The data used for creating the dataset include constraint year, month, average heaviness, relative dampness, clouds quantity, precipitation and average temperature. WEKA, open source data mining software, is used for the completion of CART decision tree algorithm. The decision tree, results and statistical in sequence about the data are used to generate the decision model for forecast of weather. The way the data is store about past events is decorated. The data transformation is compulsory according to the decision tree algorithm in order to be used by WEKA proficiently for weather prediction.
M. A. Kalyankar and S. J. Alaspurkar [2] used data withdrawal method to obtain conditions data and find the hidden patterns inside the large dataset so as to transfer the retrieved information into usable knowledge for classification and calculation of weather condition. Data mining procedure is applied to take out acquaintance from Gaza city climate dataset. This information can be used to obtain useful prediction and support the decision making process. Dynamic data mining method are required to build, that can learn animatedly to match the nature of rapidly unpredictable weather nature and unexpected events.
F. Oliya and A. B. Adeyemo [3] inspect the use of data mining modus operandi in predicting maximum temperature, rainfall, vanishing and wind speed. C4.5 decision tree algorithm and imitation neural networks are used for prediction. The meteorological data is composed between 2000 and 2009 from the city Ibadan, Nigeria. A data model for the meteorological data is urbanized and is used to train the classifier algorithms. The performance of each algorithm is compare with the standard performance metrics and the algorithm with the best result is used to generate categorization rules for the mean weather variables. A prognostic neural network model is also urbanized for weather forecast and the results are compared with the actual weather conditions data for the predicted period. The consequences shows that given enough leadership data, data mining method can be ingeniously used for weather predict and climate change studies.
AbhishekSaxena et al. [4] obtainable the review of weather prediction using reproduction neural networks and studied the benefit of using it. It yields good results and can be well thought-out as an alternative to traditional meteorological approach. The study expressed the capability of artificial neural system in predicting various weather phenomena such as temperature, thunderstorms, rainfall, wind momentum and concluded that major architecture like BP, MLP are suitable to predict weather conditions phenomenon. But due to the nonlinear conventional world of the weather conditions dataset, forecast correctness obtained by this method is still underneath the satisfactory level.
ISSN: 2394-2231
http://www.ijctjournal.org
Page 83
Classification performance is used to classify the motivation for rainfall in the earth level. Clustering technique is used to group the element that is demanding area occupied by rainfall region and the rainfall is envisaged in a particular region. Multiple linear regression models are adopt for prediction but the consequences give the rainfall data having some approximate value not a forecaster value.Gaurav J. Sawale and Sunil R. Gupta [6] proposed an artificial neural network technique for the prediction of weather for future in a given position. Back Propagation Neural Network is used for initial model. Then Hopfield Networks are fed with the result outputted by BPN model. The attributes include hotness, humidity and wind speed. Three years data of weather is collected comprise of 15000 instances. The forecast error is very less and scholarship process is quick. This can be well thought-out as an alternative to the long-established meteorological approaches. Both algorithms are combined efficiently. It is able to determine non- linear association that exists between the historical data attribute and predicts the weather conditions in future.
III. SYSTEM ANALYSIS
3.1 Existing System
The disasters are the superfluous natural events that manufacture a significant amount of losses in terms of human life and the revenue. In this context the disaster management technique are deployed to diminish or control the loss. According to the disaster organization techniques the entire process is handle in three major phases before disaster preparedness that helps to aware about the target disaster and their complexities. Secondly during the disaster relief, which provide the help to handle current situations of disaster finally the recuperation in this phase the social, economic and support based recuperation is performed. According to proposed supposition if the disasters are predicted before its occurrence then a lot of losses can be banned.
• No big data psychoanalysis and error detection.
• In existing system all method done manually.
• Errors may occur during labor-intensive process.
• In existing classification security is less.
• The data may lose throughout the process.
3.2 Proposed System
The main aim of the work is to take out the web data and NEWS in sequence from web. After data withdrawal need to refine data using pre-processing technique, cluster them in similar data group and train the predictive algorithm. After preparation the subsequent patterns are shaped as input to estimate the new upcoming natural event prediction. In order to perform the entire task first the Google News API is used to extract the data from web data source. In further the pre-processing technique are employed on the red data for attack and strain. In next step the K-means algorithm is implementing for bunch the data and recognizes the watch matrix for the prediction algorithm. Finally the hidden Markov model is applied on the new trend for judgment the most likely natural event among promising one.
3.3 Methodology
Data collection
The main aim is to design this module, is to find the text data from the web data source. This web data help us to maintain the fresh knowledge base from real world data.
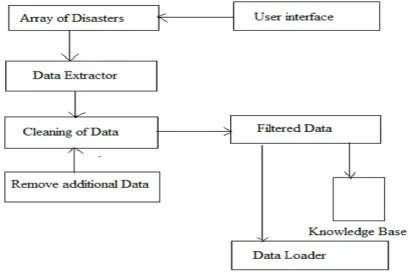
Component model: the proposed data model for collection of data from real world and for creating a strong database to manage different patterns of disasters an incessantly growing database is prepared. Furthermore it reduces the time by utilize data loader at the same time. To make available the purposeful aspects and the responsibilities the individual mechanism are described as:
ISSN: 2394-2231
http://www.ijctjournal.org
Page 84
2. Array of disasters: using the provide user interface, the stipulation is made to provide preliminary input to the system. Consequently user here put come widespread names of disasters. This adversity list is variable according to the needs. For example deficiency, flash overflow, cyclones, landslide, earthquake.3. Data extractor: that constituent is urbanized using the Google search API (application programming interface). That performs two significant tasks:
a. Take out the data from keyword record and put them into a search engine
b. Implement the data from search locomotive, and collect the results obtain by the Google investigates API.
Figure 3.1 Data Collection
4. Remove Additional Data: The extract data form also various noisy inside as the special typescript. This in this phase additional data is detached from the extracted text and the data is maintained in a three editorial data structure. In first article the title of search, inside of search (only text), and source URL is stored.
5. advanced data: after completion the complete process of data modification here the ending available as the three column data bargain.
6. Knowledge Base: that is the storage unit of the organization which contains some data table. This knowledge base is equipped in order to store newly here data or fresh data from the internet and also used load the preceding data during new experiment.
7. Data loader: in this step the preceding database and current extract data is combined. This collective data forwarded to next phase for preprocessing and feature removal.
ISSN: 2394-2231
http://www.ijctjournal.org
Page 85
After completion of the proposed hazard forecast performance are identifies the climate change while transport. Additionally the well thought-out presentation of the implement system is established using the line graph. The details of obtained presentation are reported through this chapter.Accuracy is the measurement of the rightness of predictive or categorization data model. According to the accuracy evaluation the total correctly predict values are results as the correctness of the data model. The accuracy of the system can be computed using the subsequent formula.
Accuracy = Total correctly classified patterns/Total patterns produced to classify*100
For these assessment 2500 data features has been used. In all steps, the SVM-PSO algorithm was almost the best ever algorithm. In other words, far removed from data which have been used in each step of irritated verification do not change the algorithm accurateness. In order to evaluate the collision of different topographies on the performance, we have divided facial appearance into groups. The computation of the presentation is performed during the experimentation with the dissimilar size of datasets. According to the acquire results the presentation of the system is enhanced as the amount of good characteristic data is captured. Thus the planned data model is adoptable and efficient for forecast of natural vulnerability.
V. CONCLUSION
Recently machine learning performance has also become well-known in this field. The aim of this investigation was to analyze dissimilar machine erudition techniques for shaking prediction. It was seen that for latitudes are modeled with smallest amount errors using linear weakening models. All polynomial deterioration and Gaussian process models. SVM shaped the best penalty for amount and neural agreement for depth. These results could be used as reference for further studies for predication of earthquakes. The results using real earth tremble data demonstrations that support vector machine algorithm and particle swarm optimization (SVM-PSO) is the wildest and also has the highest correctness. It provides better correctness in the working out of setting prediction based upon earth quake data. The settlement of particle crowd optimization algorithm comprises memories operation, sharing structure, and express recipe. carry vector machine optimized using unit crowd optimization algorithm has the main precision connected to other.
Future work in the area could focus on numerous research instructions. The study will be improved with more compound models on crustal self-motivated charting analysis that guarantee the opportunity of a large earthquake being activate by another conspicuous strain proclamation event.
REFERENCE
[1]. I.Aydin, M. Karakose and E.Akin, The Prediction Algorithm Based on Fuzzy Logic Using Time Series Data Mining Method.
[2]. J. Han and M. Kamber, Data Mining: Concepts and Techniques, San Francisco: Academic Press, 800 p., 2005
[3]. R. J. Povinelli, “Time Series Data Mining: Identifying Temporal Patterns for Characterization and Prediction of Time Series Events”, Ph.D. Dissertation, Marquette University, 180 p., 1999.
[4] Fairbridge R. W., 2007, "Climate" Microsoft® Student 2008 [DVD], Redmond, WA: Microsoft Corporation, 2007.
[5]. G. V. Otari, Dr. R. V. Kulkarni, “A Review of Application of Data Mining in Earthquake Prediction”, International Journal of Computer Science and Information Technologies, Vol. 3 (2), 2012, 3570-3574
[6]. Dave A.Yuen1, Benjamin J Kadlec1, Evan F Bollig1, Witold Dzwinel2, Zachary A.Garbow1, Cesar da Silva3, “Clustering and Visualization of Earthquake data in a Grid Environment“.
[7]. Kyle Springer, Atsushi Inoue, “Novel Visualization Scheme for Reasoning With data mining”, the 28th North American Fuzzy Information ,Processing Society Annual Conference(NAFIPS2009) Cincinnati, Ohio, USA - June – 2009.
ISSN: 2394-2231
http://www.ijctjournal.org
Page 86
[9]. A. Morales- Esteban, F. Martinez-Alvarez, A. Troncoso, J.L.Justo, C. Rubio-Escudero, Pattern recognition to forecast seismic time series, Elsevier, Experts System with Application 37(2010) 8333 – 8342[10]. Kabiesz, J., B. Sikora, M. Sikora, and L. Wrobell, 2013. Application of rule-based models for seismic hazard prediction in coal mines, ActaMontanisticaSlovaca, 18 (4): 262-277.
[11]. Ahumada, A., A. Altunkaynak and A. Ayoub, 2015. Fuzzy logic-based attenuation relationships of strong motion earthquake records. Expert Systems with Applications, 42 (3): 1287-1297.
[12]. Siler, W. and J.J. Buckley, 2005. Fuzzy expert system and fuzzy reasoning, John Wiley & Sons, Inc. [13]. Ikram, A. and U. Qamar, 2014. A rule-based expert system for earthquake prediction, J Intel InfSyst, 43 (2): 205-230.
[14]. Ikram, A. and U. Qamar, 2015. Developing and expert system based on association rules and predicate logic for earthquake prediction, Knowledge-Based Systems, 75, 87-103.