Available Online at www.ijpret.com 1513
INTERNATIONAL JOURNAL OF PURE AND
APPLIED RESEARCH IN ENGINEERING AND
TECHNOLOGY
A PATH FOR HORIZING YOUR INNOVATIVE WORK
A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA
USING HDFS
MS. S. A. DHAWALE1, PROF. G. D. GULHANE2, DR. H. R. DESHMUKH3, PROF. O. A. JAISINGHANI4, PROF. S. V. KHEDKAR4
1.PG Scholar, Dept. of Information Technology, IBSS COE, Amravati. 2.Dept. of CSE, IBSS COE, Amravati.
3.HOD, CSE & IT, IBSS COE, Amravati.
4.Dept. of IT, IBSS COE, Amravati.
Accepted Date: 05/03/2015; Published Date: 01/05/2015
Abstract: Apache Hadoop is a set of algorithms written in Java for distributed storage and distributed processing of very large data sets (Big Data). Hadoop is an open-source software framework for storing and processing huge data sets. Hadoop supplements to the existing data warehouse & conventional data source. It is the cost-effective and efficient way of data storage, processing and analyzing structured as well as unstructured data. Hadoop is written in java and runs on large cluster of industry standard servers. It can store petabytes of data in the form of blocks on tens of thousands of servers. Hadoop distributed file system (HDFS) is a base component of the Hadoop framework that actually manages the data storage on the cluster. It stores data in the form of data blocks (default size: 64MB) on the local hard disk. It uses block size of 128MB for a large file set.
Keywords:Big data, Hadoop, framework, cluster
Corresponding Author: MS. S. A. DHAWALE
Access Online On:
www.ijpret.com
How to Cite This Article:
S. A. Dhawale, IJPRET, 2015; Volume 3 (9): 1513-1519
Available Online at www.ijpret.com 1514
INTRODUCTION
Hadoop is a freeware framework developed for efficient and effective way of storing, distributed processing and analyzing the data set using cluster .It was designed for a purpose of processing the large dataset using cluster with high performance file system termed as “Hadoop Distributed File System (HDFS)”.Hadoop also contain framework for job scheduling Hadoop does not replace enterprise data warehouses, data marts and other conventional data stores. It supplements those enterprise data architectures by providing an efficient and cost-effective way to store, process and analyze the daily flood of structured and unstructured data
Apache Hadoop is an open source distributed software platform for storing and processing data. Written in Java, it runs on a cluster of industry-standard servers configured with direct-attached storage. Using Hadoop, you can store petabytes of data reliably on tens of thousands of servers while scaling performance cost-effectively by merely adding inexpensive nodes to the cluster.
Hadoop is a free software framework developed with the purpose of distributed processing of large data sets using clusters of commodity hardware, implementing simple programming models. It is a middleware platform that manages a cluster of computers that was developed in Java and although Java is main programming language for Hadoop other languages could be used to: R, Python or Ruby.
Literature survey:
1) The Bottleneck in Big Data Analysis:
Big Data refers to the large amounts, at least terabytes, of poly-structured data that flows continuously through and around organizations. When Yahoo, Google, Facebook, and other companies extended their services to web-scale, the amount of data they collected routinely from user interactions online would have overwhelmed the capabilities of traditional IT architectures. So they built their own. Apache Hadoop is an open source distributed software platform for storing and processing data.
2) The Hadoop framework includes:
• Hadoop Distributed File System (HDFS) – It is a high performance distributed file system in a Hadoop architecture.
Available Online at www.ijpret.com 1515
• Hadoop Map-Reduce – a system for parallel processing of large data sets.
3) Architecture:
Hadoop is a 3 tier Architecture where first Layer is called as Hardware Layer Which consist of data nodes and the computers the general structure of the analytics tools integrated with Hadoop can be viewed as a layered architecture presented in figure The second layer is the middleware layer – Hadoop. It manages the distributions of the files by using HDFS and the Map-Reduce jobs. Then it comes this layer that provides an interface for data analysis. At this level we can have a tool like Pig which is a high-level platform for creating Map-Reduce programs using a language called Pig-Latin. We can also have Hive which is a data warehouse infrastructure developed by Apache and built on top of Hadoop. Hive provides facilities for running queries and data analysis using an SQL-like language called HiveQL and it also provides support for implementing Map-Reduce tasks.
4) Map-Reduce:
Mapreduce is the heart of Hadoop. It is used to Process data parallely on the cluster. Hadoop MapReduce (Hadoop Map/Reduce) is a software framework for distributed processing of large data sets on compute clusters of commodity hardware. The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform. The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). The reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
Available Online at www.ijpret.com 1516
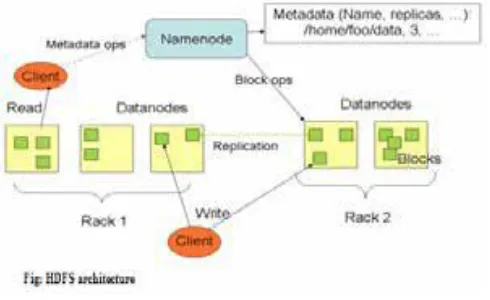
The Apache Hadoop platform also includes the Hadoop Distributed File System (HDFS), which is designed for scalability and fault tolerance. HDFS stores large files by dividing them into blocks (usually 64 or 128 MB) and replicating the blocks on three or more servers.
Fig 1. HDFS Architecture
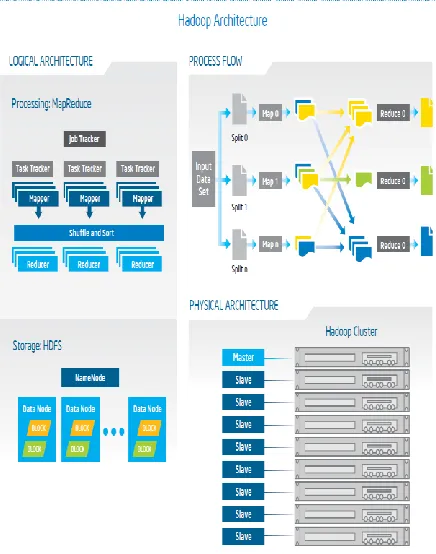
6) Working process of Hadoop Architecture:
Available Online at www.ijpret.com 1517
on the compute nodes, providing very high aggregate bandwidth across the cluster. Both Map/Reduce and the distributed file system are designed so that node failures are automatically handled by the framework. Hadoop Common is a set of utilities that support the other Hadoop subprojects
Fig. 2: Hadoop Architecture.
Applications:
The main features of the Hadoop framework can be summarized as follows:
• High degree of scalability: new nodes can be added to a Hadoop cluster as needed without changing data formats, or application that runs on top of the FS;
• Cost effective: it allows for massively parallel computing using commodity hardware;
• Flexibility: Hadoop differs from RDBMS, being able to use any type of data, structured or not;
Available Online at www.ijpret.com 1518
CONCLUSION:
Using Hadoop in this way, the organization gains an additional ability to store and access data that they “might” need, data that may never be loaded into the data warehouse. The Hadoop Distributed File System (HDFS) is a distributed file system
designed to run on commodity hardware. Hadoop is designed to run on cheap commodity hardware, It automatically handles data replication and node failure, It does the hard work – you can focus on processing data, Cost Saving and efficient and reliable data processing.[1]
A cost-effective and massively scalable platform for ingesting big data and preparing it for analysis. Using Hadoop to offload the traditional ETL processes can reduce time to analysis by hours or even days. Running the Hadoop cluster efficiently means selecting an optimal infrastructure of servers, storage, networking, and software.
REFERENCE:
1. Impetus white paper, March, 2011, “Planning Hadoop/NoSQL Projects for 2011” by Technologies, Available:
2. http://www.techrepublic.com/whitepapers/planninghadoopnosql-projects-for-2011/2923717, March, 2011.
3. McKinsey Global Institute, 2011, Big Data: The next frontier for innovation, competition,
and productivity,
Available:www.mckinsey.com/~/media/McKinsey/dotcom/Insights%20and%20pubs/MGI/Rese arch/Technology%20and%20Innovation/Big%20Data/MGI_big_data_full_report.ashx, Aug, 2012.
4. Thomas Herzog, Associate Commissioner, New York State, Thomas Kooy, IJIS Institute Big Data and the Cloud, IJIS Institute Emerging Technologies, Available:http://www.correctionstech.org/meeting/2012/Presentations/Red_01.pdf, Aug, 2012.
5. Jacobs, A., The Pathologies of Big Data, ACM Queue,Available: http://queue.acm.org/detail.cfm?id=1563874,6th July 2009.
Available Online at www.ijpret.com 1519
7. The Hadoop Architecture and Design,
Available:http://hadoop.apache.org/common/docs/r0.16.4/hdfs_design.html, Aug, 2012
8. Hung-Chih Yang, Ali Dasdan, Ruey-Lung Hsiao, and D.Stott Parker from Yahoo and UCLA, "Map-Reduce-Merge: Simplified Data Processing on Large Clusters",paper published in Proc. of ACM SIGMOD, pp. 1029–1040, 2007.
9. White, Tom. Hadoop The Definitive Guide 2nd Edition.United States : O'Reilly Media, Inc., 2010.P. Zadrozny and R. Kodali, Big Data Analytics using Splunk, Berkeley, CA, USA: Apress, 2013.
10.F. Ohlhorst, Big Data Analytics: Turning Big Data into Big Money, Hoboken, N.J, USA: Wiley, 2013.
11.J. Dean and S. Ghemawat, "MapReduce: Simplified data processing on large clusters," Commun ACM, 51(1), pp. 107-113, 2008.
12.Apache Hadoop, http://hadoop.apache.org.
13.F. Li, B. C. Ooi, M. T. Özsu and S. Wu, "Distributed data management using MapReduce," ACM Computing Surveys, 46(3), pp. 1-42, 2014.
14.C. Doulkeridis and K. Nørvåg, "A survey of large-scale analytical query processing in MapReduce," The VLDB Journal, pp. 1-26, 2013.
15.S. Sakr, A. Liu and A. Fayoumi, "The family of mapreduce and largescale data processing systems," ACM Computing Surveys, 46(1), pp. 1-44, 2013.