_____________________________________________________________
__________
Personal Data Sensitivity in Japan
An Exploratory study
Fukuta, Yasunori
Meiji University, School of Commerce.
Murata, Kiyoshi
Meiji University, Centre for Business Information Ethics.
Adams, Andrew A.
Meiji University, Centre for Business Information Ethics.
Orito, Yohko
Ehime University, Faculty of Collaborative Regional Innovation.
Lara Palma, Ana María
Universidad de Burgos, Department of Civil Engineering.
Corresponding Author: Yasunori Fukuta, [email protected]
Abstract
The purpose of this study was to investigate how ordinary Japanese people perceive and understand data sensitivity and sensitive data. Although the concept of sensitive data is described in an article of Japan’s revised personal data act, following the EU Data Protection Directive and the new data protection rule, there has been little research on whether this legally defined concept conforms to the general public’s perception of sensitive data in Japan and, if not, what differences exist between them. Using empirical data acquired through a questionnaire survey and appropriate statistical methods, we sought to clarify empirically the features of data sensitivity as perceived by ordinary Japanese people. This exploratory research revealed that ordinary Japanese tended to feel relatively low sensitivity to personal data related to their civic activities, which are typically mentioned in the official explanation of sensitive data, but they tended to feel a higher degree of sensitivity regarding financial-related personal data, which were not ordinarily considered sensitive data.
Keywords: sensitive data, data sensitivity, personal information, privacy, Japan
The IT Strategic Headquarters of the Japanese government1 formulated a new IT strategy
entitled “Declaration to be the World’s Most Advanced IT Nation” in June 2013 (revised in June 2014, June 2015 and May 2016). This strategy regards IT as a core component of structural reforms in Abenomics and aims to achieve the effective use of the vast quantities of personal data in various contexts such as medical care, disaster prevention, and stimulation of regional economies and business activities (Ministry of Internal Affairs and Communications, 2013). The increased need for the development of laws related to use of personal information for business resulted in a revision to Japan’s Act on the Protection of Personal Information (APPI; Act No. 57 of 2003), which was passed by the congress in September 2015.
In the third paragraph of Article two of the revised act, sensitive data were given a unified definition for the first time in Japan. The act defines sensitive data as personal data with which special care must be taken to avoid unjust discrimination, prejudice, or other detriment. This definition also includes a non-exhaustive list of what constitutes sensitive data. Information related to race, creed, social status, medical records, criminal records, and damages suffered in crimes are included in this list.
The concepts of data sensitivity have been discussed actively, mainly in Europe, and it is obvious that the legally defined concept of data sensitivity in Japan was made based on the European view such as the definition of sensitive data in EC Directive 95 (Itakura, 2016). However, for ordinary Japanese people, data sensitivity or sensitive data seem to be unfamiliar concepts and, thus, it may be hard for them to understand what types of personal data will be granted this extra protection. Additionally, the perception of, and attitudes toward, the sensitivity of personal data may vary among different cultures. Given that the kind of personal data that leads to discrimination and prejudice will vary from culture to culture, it seems that cultural differences will arise as to what kinds of data should be given special consideration.
This background would seem to imply the need to understand the perception of data sensitivity among ordinary Japanese people. Unfortunately, little research has been done to investigate this perception using empirical evidence in Japan. The purpose of this study was to clarify features of data sensitivity perceived by ordinary Japanese people using survey data and statistical analyses. The contents of this study are as follows. First, we briefly review changes in, and the current situation of, the politico-economic and social environment surrounding sensitive data in Japan. In the following section, showing the contents and procedures of the empirical study, features of data sensitivity in Japan are discussed based on the results of the study. Implications of, and future directions for, this study are provided in the final section.
Overview of environment surrounding sensitive data in
Japan
As mentioned before, in Japan, there had not been a clear legal definition of sensitive data and no comprehensive and unified rule to protect such data before the revised APPI was enacted. However, the original APPI indicated a way of thinking about data sensitivity; in Article six, the existence of a personal data category in which the strict implementation of appropriate handling is required to further protect the rights and interests of individuals and the need for measures to protect data belonging to that category are mentioned. As a legal measure, guidelines to govern the use of such personal data at incorporated administrative agencies were established in their relevant fields, including medical, financial, information, and telecommunications fields, which were mentioned as fields where such measures were required in Diet deliberations (Okamura, 2010). For example, Article six of the Guidelines for Personal Information Protection in the Financial Field, established by the Japan Financial Services Agency, defines sensitive information as information on political views, religion (including thoughts and creed), participation in union activities, race, family origin and registered domicile, healthcare, sex life, and past criminal records, and prohibits acquisition, use, and third-party provision of such information unless specific conditions are satisfied (Financial Service Agency, 2009).
Sensitive data is also defined in JIS Q 15001:2006, Personal Information Protection Management Systems-Requirements (JIS, 2006). JIS Q 15001:2006 JISX is one of the Japanese Industrial Standards formulated through the discussions of the Japanese Industrial Standards Committee, based on a draft prepared by the Japanese Standards Association as a standard for safe and appropriate management of personal information handled by business entities. In Section 4.4.2.3 of this standard, sensitive information is defined as the personal information related to a) thought, creed, and religion, b) race, ethnicity, family origin, domicile, physical and mental disability, criminal record, and other matters that cause social discrimination, c) matters concerning the right of workers to organize and to bargain and act collectively, d) matters concerning participation in collective demonstration acts, exercise of petition rights, and exercise of other political rights, and e) healthcare and sex life. The standard stipulates that the acquisition, use, or provision of these data is forbidden except for cases expressed in the standard.
Through an analysis of the content of deliberations in the Diet, Itakura (2016) found out that the revision of APPI was undertaken by keeping these requirements in mind and that the introduction of the unified concept of sensitive data was an attempt to meet these requirements by the government.
Given this background, it is plausible that ordinary Japanese people are not familiar with the newly introduced concept of sensitive data. Indeed, the sensitivity of data may be a matter of little concern for the general public in Japan, and many of them did not necessarily desire legislation regarding this concept. In fact, the results of a brief survey conducted by the Cabinet Public Relations Office in 2015 showed that many Japanese people did not understand the concept well (Cabinet Public Relations Office, 2015). Additionally, because a focus had been placed on whether Japan’s revised data protection law complied with the EU directives and rules at the stage of law design, it is hard to say that sufficient consideration had been given to the characteristics of Japanese society and features of Japanese people’s perception of data sensitivity. Even academic research on sensitive data in Japan has focused largely on the positioning and interpretation of sensitive data in the legal system, on the influence of legislation on sensitive data in relation to business activities, and on technologies and skills for protecting sensitive data. Consequently, little attention has been paid to how ordinary Japanese people understand sensitive data.
Empirical research
Overview of the survey
Table 1. Sample size and attributes of respondents Age
20-29 30-39 40-49 50-59 Over 60 Total
Gender
Male 87 (9.3) 89 (9.6) 93 (10.0) 94 (10.1) 94 (10.1) 457 (49.1) Femal
e 96 (10.3) 90 (9.6) 95 (10.2) 95 (10.3) 97 (10.4) 474 (50.9) Total 183 (19.7) 179 (19.2) 188 (20.2) 190 (20.4) 191 (20.5) 931 (100.0)
Procedure and results of the empirical analysis
First, the suitability of the data for factor analysis was checked using two methods: Bartlett’s test of sphericity and the KMO index. Bartlett’s test of sphericity tests the null hypothesis that the correlation matrix calculated based on the data is proportional to an identity matrix in which all the diagonal elements are 1 and all off diagonal elements are 0, and this test should be significant for considering that the data are appropriate for factor analysis (Field, 2013). Results of the test showed our correlation matrix was significantly different from an identity matrix and significant correlations were observed between scores of each item (χ2 (4095) = 79676.52, p < 0.01). The Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy was also used to check the suitability of the data. This indicates the ratio of the squared correlation between variables to the squared partial correlation between variables (Field, 2013). According to Kaiser (1974), the recommended level of this index is > 0.5. In the evaluation categories proposed by Hutcheson and Sofroniou (1999), > 0.9 means “marvellous”. The calculated current KMO index was 0.966 and this was sufficient to conclude that the data were adequate for factor analysis. In sum, according to criteria adopted in many previous studies, the test and index indicated that the data were suitable for factor analysis.
Table 2. List of personal data items analyzed Category name Items of personal data Basic personal data
(number of items=9) Family name; Given name(s); DOB, Place of birth (town); Home address; Mobile number; Home phone number; School/place of employment; Marital status/history Financial data
(7)
Personal income; Tax paid; Pension received; Family income; Bank account balance; Ownership of shares of companies; Real estate
Association
(7) Communication meta-data; Communication content data; Relationships with other individuals; Social network connections; Friends; Lovers; Partners
Personal records (12)
Library borrowing record; Video/game/music/(e)books usage record; Web browsing history; Search keyword record; Location data record; Shopping record; Educational institution attendance; Academic achievement record; Employment record; Criminal record; Record of being a victim of crimes; Record of drug addiction
Health information (13)
Minor physical illness; Cancer; Cardiac illness; Cerebral stroke; Venereal disease; Lifestyle-related disease; History of mental illness; History of injury; Physical disability; Mental disability; Degenerative conditions; Long-term infection; Genetic pre-disposition to cancer, heart disease or genetic-linked degenerative conditions
Personal numbers (9)
Driving licence number; Health insurance number; Basic pension number/social security number; Citizen/resident identification number; Taxpayer number; Other government ID number; Bank account number; Credit card number; Employee/student number
Family information (11)
Racial/ethnic background; Nationality; Family lineage; Family register information; Registered address; Resident register information; Family configuration; Parents’/ancestors’/spouse’ employment records; Parents’/ancestors’ health records; Domestic violence; Child adoption
Personal orientation (8)
Philosophical/moral beliefs; Political orientation; Religious orientation; Sexual orientation; Trade union membership; History of participating in labour activities/engaging in collective bargaining; History of executing political rights; Voting history
Biometrics (9) DNA/gene; Fingerprint; Iris scan; Finger vein; Palm vein; Blood type; Ear shape; Foot shape; Dental record
Online life (6) User ID; Password; Handle/nickname/user name; Email address; Contact address in other communication systems; Content of social networking services
principal axis factoring method, promax rotation, and Kaiser’s criterion for factor extraction. As a result of the analysis, the following six items had factor loadings to each factor < 0.4: Educational institution attendance, Academic achievement record, Marital status/history, Employment record, Communication meta-data, and Communication Content. After eliminating these items from the original list of personal information, the second factor analysis (principal axis factoring method, promax rotation, and Kaiser’s criterion) was applied to the data of the remaining 85 items.
Factors Personal
dataitems
Health and Wellbe ing
ID
number Civics Social catego ries
Financ
ial Dsahtaadow PaelrsIoDn Sensit ive biomet rics
Digita l person a
Non -sensit ive biomet rics
Social relati onship s
Crimes Contac t number s Cerebralstroke 1.043 .002 -.054 .020 .056 .011 .018 -.009 .032 -.011 -.034 -.129 -.098 Cardiacillness 1.036 .006 -.060 .010 .068 .024 .016 -.011 .031 .002 -.040 -.117 -.104 Cancer 1.034 -.028 -.029 -.019 .057 .004 .031 .021 .038 -.021 -.055 -.114 -.069 Lifestyle-relateddiseases .974 -.003 -.011 .016 .036 .038 .042 -.019 .041 .010 -.034 -.103 -.112 Degenerativeconditions .908 .027 -.021 .001 -.059 -.048 .000 .029 -.018 -.002 .051 .025 .071 Venerealdisease .903 -.022 .031 -.044 -.025 .020 -.034 .001 -.038 -.091 -.022 .067 .093 PhysicalDisability .861 .018 .012 .017 -.071 -.047 -.002 -.042 -.032 .017 .032 .072 .127 MentalDisability .829 .001 .001 -.029 -.066 -.020 -.030 -.001 -.063 -.039 .038 .163 .171 Long-terminfection .825 -.011 .018 -.017 -.029 -.044 -.038 -.015 -.040 -.049 -.005 .176 .154 Geneticpre-disposition .798 -.017 -.012 -.093 -.049 -.014 .015 .148 -.011 -.032 .073 .094 -.003 Historyofmentalillness .786 -.041 .062 -.074 .002 -.004 .004 .010 -.041 -.047 -.012 .185 .122 Minorphysicalillness .677 .038 .015 .050 .002 .097 .074 -.054 .075 .065 .002 -.119 -.189 Historyofinjury .650 .068 .087 .005 .046 .045 .025 -.021 .038 .167 -.006 -.076 -.166 Basic pension number/social
securitynumber .022 .984 .027 -.002 -.033 -.022 .008 -.029 -.061 -.023 .014 -.058 .036 Healthinsurancenumber .057 .973 .056 -.007 -.022 -.045 .031 -.081 -.018 .014 -.017 -.069 .029 Taxpayernumber -.018 .936 .018 .081 .009 .037 -.005 .061 -.123 -.016 -.015 .036 -.093 OthergovernmentIDnumber -.017 .921 -.005 .109 -.026 -.018 -.030 .022 -.037 -.006 .038 .009 -.046 Citizen/resident
identificationnumber -.027 .868 -.059 -.004 -.018 .062 -.030 .076 -.088 -.015 -.022 .031 .028 Drivinglicencenumber .031 .850 .014 .015 -.037 -.022 .089 -.036 .037 .033 -.023 -.033 .004 Creditcardnumber -.034 .736 -.015 -.118 .126 .003 -.041 -.010 .093 -.009 -.053 .064 .054 Bankaccountnumber -.039 .694 .039 -.093 .135 -.071 -.053 -.001 .106 -.004 .033 .046 .080 Employee/studentnumber -.014 .500 -.010 .039 -.050 .068 .058 -.076 .185 .093 .105 .095 -.084 Politicalorientation -.017 -.028 .934 -.029 .024 -.023 .007 .070 -.023 -.017 .047 -.055 -.026 Religiousorientation .024 -.073 .930 .001 .009 -.052 -.008 .078 -.024 -.061 .008 -.011 .017 History of participating in
labour activities/ engaging
incollectivebargaining -.036 .082 .913 .034 -.022 .033 .034 -.086 .034 .002 -.034 .008 .014 History of executing your
politicalrights .009 .094 .912 .002 -.054 .033 .005 -.050 -.003 .005 -.028 .031 .023 Tradeunionmembership -.020 .042 .853 .071 -.032 .024 .049 -.087 .065 .045 -.022 -.034 .015 Philosophical/moralbeliefs .000 -.071 .848 .011 .037 -.028 .003 .094 -.006 .017 .058 -.114 -.041 Votinghistory -.012 .116 .751 .010 .052 .096 -.036 -.017 -.010 .061 -.044 -.007 -.059 Sexualorientation .158 -.112 .636 .015 .004 .026 -.083 .075 -.016 -.066 .012 .089 .093 Familyregisterinformation -.082 .053 -.116 .982 .014 -.004 .042 .099 .017 -.095 -.032 -.024 -.051 Registeredaddress -.095 .076 -.075 .923 -.002 .026 .075 .120 -.026 -.065 -.034 -.003 -.099 Familylineage .020 -.091 .130 .851 -.010 .001 .007 -.039 -.003 -.052 .036 -.030 -.078 Parents’/ ancestors’/
spouse'employmentrecord .084 .004 -.037 .825 .047 .064 -.104 -.027 .064 .060 -.007 -.084 .010 Nationality -.003 -.029 .175 .785 .005 -.062 .088 -.117 -.004 -.012 -.034 .031 -.121 Racial/ethnicbackground .024 -.095 .140 .747 -.030 -.029 .018 -.045 -.023 -.020 -.023 .100 -.039 Familyconfiguration .013 .051 -.011 .730 .015 -.051 -.008 -.068 .078 .145 .004 -.065 .075 Residentregisterinformation -.008 .169 -.021 .696 -.039 -.007 -.021 .042 .086 -.039 -.026 -.084 .183 Parents/ancestors’ healthrecords .228 -.031 .071 .668 .033 .047 -.130 -.011 -.016 .050 -.007 -.055 .035 Childadoption .185 -.006 .046 .520 -.001 -.079 -.083 .004 .030 .005 .030 .205 .062 Domesticviolence .226 -.032 .094 .448 -.022 -.040 -.112 -.023 .001 .043 -.014 .255 .070 Familyincome -.048 -.020 -.022 .043 .916 .044 -.019 -.028 -.031 .040 -.023 -.007 .050 Taxpaid .002 -.030 -.058 .084 .899 .043 -.006 -.004 -.004 .004 -.050 .008 .017 Personalincome .039 .002 -.024 .052 .899 .012 .027 -.080 -.078 .004 -.018 -.043 .101 Pensionreceived .014 -.029 -.039 .082 .846 -.010 -.028 -.030 .015 .055 .003 -.001 .054 Ownership of shares of companies -.014 .059 .096 -.091 .843 -.047 .000 .063 .021 -.056 .041 .054 -.074 Realestate .001 .067 .055 -.046 .786 -.083 .014 .042 .003 -.015 .073 .080 -.076 Bankaccountbalance .007 .165 .034 -.142 .737 -.052 -.015 .068 .029 -.089 .003 .022 .077 Webbrowsinghistory -.021 -.005 .012 -.043 -.054 .942 -.058 -.030 .016 -.021 -.011 .050 .074 Searchkeywordrecord -.012 -.007 .063 -.089 -.017 .874 -.008 -.011 .018 -.012 -.013 .008 .047 Video/ game/ music/ (e)books
usagerecord -.028 -.051 .019 .052 .003 .866 .020 -.001 -.032 .008 .026 .025 -.099 Libraryborrowingrecord .048 -.059 .028 .020 -.026 .739 .090 .006 -.031 .017 .031 .037 -.140 Shoppingrecord .079 .089 .018 .003 .085 .650 -.039 -.070 -.038 .025 .048 -.008 .083 Locationaldatarecord .002 .122 -.104 .071 -.009 .601 -.048 .063 -.050 -.033 .091 -.007 .175 Givenname .034 .023 -.006 -.018 -.064 -.033 .889 .032 .000 -.050 -.005 .068 .180 Familyname .021 .025 -.006 .007 -.028 -.075 .867 -.002 -.032 -.031 .003 .089 .149 DOB .028 -.019 .019 .012 .064 .053 .647 .086 .007 -.038 -.067 .020 .199 POB -.134 -.117 .038 .370 .025 .145 .403 .119 -.121 -.061 .001 .026 .090 Fingervein -.014 -.004 .017 -.011 .013 -.005 .016 .960 -.011 .090 -.007 -.026 -.074 Palmvein .010 -.005 .001 -.011 .024 -.024 -.003 .923 -.003 .114 -.014 -.021 -.089 Irisscan .024 -.007 .008 -.033 .020 .024 .044 .897 -.010 .055 .015 .004 -.103 Finger-print .022 .172 .011 .084 -.106 -.039 .050 .662 .014 -.051 .092 .030 .040 DNA/gene .193 -.015 .056 .132 -.015 -.046 .018 .628 .027 -.082 .023 -.043 .025 Contactaddress .013 .021 -.005 .054 -.045 -.070 -.058 -.060 .883 .033 .052 .022 .063 Emailaddress -.006 .073 .009 -.025 -.039 -.064 .061 -.024 .778 -.014 .044 -.005 .145 Content of social networking
services .059 -.043 .005 .038 -.079 -.022 -.002 -.066 .753 .057 .171 .052 -.014 UserID -.017 .114 -.039 .023 .062 .102 -.048 .153 .671 -.140 -.136 -.032 .092 Handle/Nickname/UserName -.074 .030 .066 .064 .086 .004 .044 -.011 .663 .063 -.011 .089 -.164 Password -.018 .190 -.022 -.114 .040 .105 -.100 .215 .560 -.139 -.142 -.010 .182 Earshape -.066 -.013 .019 -.063 -.004 -.012 -.055 .026 -.025 1.042 -.021 .028 .136 Footshape -.068 -.019 .018 -.069 -.002 -.010 -.040 .053 -.021 1.021 -.004 .037 .106 Dentalrecord .089 -.016 .093 -.037 .018 .079 -.006 .173 -.006 .635 -.042 .014 .067 Bloodtype .011 .026 -.024 .170 -.047 -.036 .055 .100 .084 .616 .006 .033 -.071 Lovers .045 -.027 .019 -.096 -.005 .059 -.117 .075 -.039 -.020 .927 -.079 .118 Friends -.064 -.006 .019 -.051 -.005 .070 .013 .002 .078 -.019 .912 -.022 -.082 Partners .042 .012 -.027 .086 .001 -.045 -.014 .025 -.064 .025 .770 -.028 .120 Socialnetworkconnections -.048 -.037 .008 -.021 .046 .100 .114 -.077 .260 -.040 .620 .037 -.175 Relationships with other
individuals .074 .111 -.046 .211 .205 -.043 .026 -.008 -.111 -.008 .405 .054 .001 Recordofdrugaddiction .099 -.009 -.031 -.026 .019 .046 .053 -.026 .069 .033 -.015 .919 -.129 Criminalrecord .105 -.013 -.058 .012 .011 .024 .070 -.035 .055 .047 -.048 .915 -.111 Record of being a victim of
crimes .192 .084 -.025 .011 .068 .044 .001 .034 -.050 .013 -.035 .700 -.065 Mobilenumber .070 .095 -.013 -.132 .072 .009 .226 -.090 .037 .106 .030 -.117 .753 Homephonenumber .033 .057 -.005 -.102 .058 -.003 .248 -.096 .093 .102 .006 -.062 .738 Homeaddress -.023 .039 .012 .091 .051 .013 .347 -.031 .006 .021 -.047 -.111 .677 School/placeofemployment -.008 -.104 .010 .117 .125 .048 .266 -.020 .026 .067 .066 -.017 .464 Cronbach’sα 0.974 0.958 0.961 0.949 0.956 0.912 0.852 0.946 0.907 0.934 0.897 0.939 0.907 MinimumCI-Tcorrelation 0.674 0.635 0.743 0.72 0.802 0.659 0.476 0.775 0.664 0.763 0.619 0.825 0.644
with data items such as income, tax, pension, and bank account balance. Factor six had strong relationships with records of web browsing, search keywords, library borrowing, and shopping, so it was named “Data shadow”. The seventh factor was named “Personal ID” because of high factor loadings with ID information such as name, day of birth, and place of birth. Factors eight and ten related highly to biometrics. Factor eight had a strong relationship with data on finger veins, palm veins, iris scans, fingerprints, and DNA. Some of these items are used to identify individuals when they try to use bank/credit cards or to enter a building/room, so we gave the name of “Sensitive biometrics” to the seventh factor. Similarly, we named factor ten as “Non-sensitive biometrics”. Because personal data related to online life such as user ID, User name, Password, and E-mail address had high factor loadings on factor nine, it was named “Digital persona”. Factor eleven related highly to the data representing networks or relationships in social life and was named “Social relationships”. Personal data including records of drug addiction, criminal records, and records of being a victim of crimes showed high factor loadings with factor twelve and we gave it the name “Crimes”. The last factor showed strong correlations with home address, mobile/home phone number, and school/place of employment, and we named it “Contact numbers”.
Internal consistency and the unidimensionality of each factor were confirmed using Cronbach’s α coefficient and the corrected item-total (CI-T) correlation coefficient. These coefficients are shown in the bottom rows of each factor in the pattern matrix. Generally, it is considered that the α coefficient should be > 0.7 for sufficient internal consistency (Leech et al., 2015). CI-T correlation coefficient shows the correlations between each item included in a set of items that have high factor loadings on a factor and the total score of the items. It is considered that if the correlation is > 0.4, the item will be a good component of the factor, and if all the items related to the factor can be regarded as good components, the factor will have high unidimensionality (Field, 2013). Thus, if the minimum value of CI-T correlation on a factor is > 0.4, it can be considered that the factor has high unidimensionality. As shown in Table 3, the analyses showed that the 13 extracted factors had sufficient internal consistency and high unidimensionality. Based on these results, this 13-factor structure was adopted for further analyses.
contact numbers (factor 13) are personal data categories not normally regarded as sensitive data.
Figure 1 shows how much sensitivity was registered by ordinary Japanese people about these 13 factors. The degree of sensitivity for each factor was measured by the average score of all items included in each factor. As shown in the figure, factors such as ID numbers, financial, sensitive biometrics, and crimes had relatively high mean scores, while the means of civics, data shadow, personal ID, and non-sensitive biometrics were relatively low. The factors in the red box are those mentioned frequently in descriptions relating to sensitive data and those that have particular relevance to the concept. Two features regarding data sensitivity, as perceived by ordinary Japanese people, can be detected from the figure.
Figure 1. Degree of sensitivity of each factor
First, ordinary Japanese people tended not to feel high data sensitivity with regard to some of the factors mentioned specifically in the legally defined concept of sensitive data. The factor of civics had high factor loadings, with data on political orientation, history of exercising political rights, voting history, history of participating in labour activities or collective bargaining, trade union membership, philosophical orientation, religious orientation, and sexual orientation, all of which are frequently used to explain what sensitive data are. However, the ordinary Japanese questioned tended to feel
relatively low sensitivity in relation to this factor (Mciv = 1.787). They also felt relatively
low sensitivity to the data shadow factor, through which the orientation or activities
mentioned in the civics factor seem to be readily inferable and predictable (Mdat = 1.773).
Second, the ordinary Japanese people questioned tended to feel a high degree of sensitivity to financial factors or factors readily associated with economic damage. The financial factor, consisting of personal data on family/personal income, taxes paid, pension received, ownership of shares of companies, real estate owned, and bank account
balances, had a relatively high average score for sensitivity (Mfin = 2.423). Additionally,
ordinary Japanese tended to regard the ID number factor, consisting of data on basic pension/social security number, health insurance number, taxpayer number, other government ID number, citizen/resident identification number, driving licence number, credit card number, bank account number, and employee/student number, as highly
sensitive data (MIDn = 2.460). Most of such ID numbers are not inherently ‘financial’ data
but, in Japan, as in other countries, they are sometimes abused to commit fraud. Although these two factors received the highest sensitivity scores among the 13 factors, generally, such financial-related factors have not been included in definitions of sensitive data.
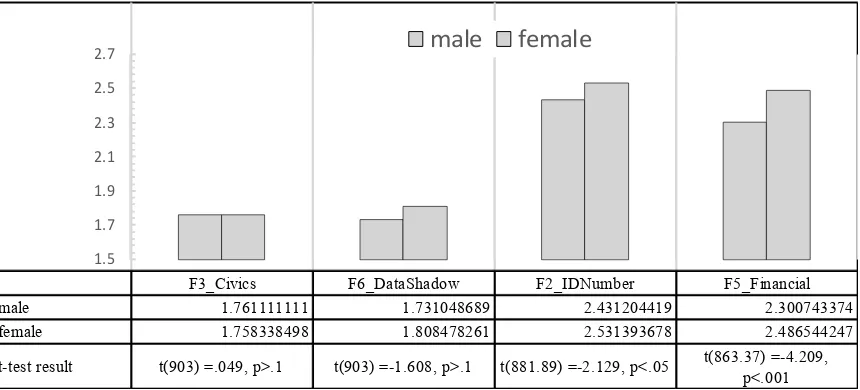
factors, females tended to have a higher sensitivity than men; the difference was statistically significant at the 5% significance level for ID number and the 0.1% level for the financial factor. Thus, ordinary Japanese people felt a high degree of sensitivity to these factors, which are not typically mentioned in explanations of sensitive data, and the tendency was stronger in the female group.
F3_Civics F6_DataShadow F2_IDNumber F5_Financial male 1.761111111 1.731048689 2.431204419 2.300743374 female 1.758338498 1.808478261 2.531393678 2.486544247
t-test result t(903) =.049, p>.1 t(903) =-1.608, p>.1 t(881.89) =-2.129, p<.05 t(863.37) =-4.209, p<.001
1.5 1.7 1.9 2.1 2.3 2.5
2.7 male female
Figure 2. Gender-based comparison of the degree of sensitivity to the factors
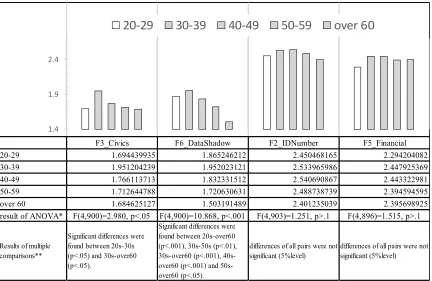
Figure 3 shows age-dependent differences in the degree of sensitivity to these four factors. The statistical significance of the differences was assessed using one-way ANOVA. Although gender differences were confirmed in the financial-related factor, the results of the ANOVA indicated that the high sensitivity score of these factors tended to be common in all age groups and there was no significant difference between them. However, in the civics and data shadow factors, which showed no difference between genders, there was a significant difference according to age. To assess which pairs of age
groups had significant differences, multiple comparisons were conducted as a post hoc
F3_Civics F6_DataShadow F2_IDNumber F5_Financial 20-29 1.694439935 1.865246212 2.450468165 2.294204082 30-39 1.951204239 1.952023121 2.533965986 2.447925369 40-49 1.766113713 1.832331512 2.540690867 2.443322981 50-59 1.712644788 1.720630631 2.488738739 2.394594595 over 60 1.684625127 1.503191489 2.401235039 2.395698925 result of ANOVA* F(4,900)=2.980, p<.05 F(4,900)=10.868, p<.001 F(4,903)=1.251, p>.1 F(4,896)=1.515, p>.1
Results of multiple comparisons**
Significant differences were found between 20s-30s (p<.05) and 30s-over60 (p<.05).
Significant differences were found between 20s-over60 (p<.001), 30s-50s (p<.01), 30s-over60 (p<.001), 40s-over60 (p<.001) and 50s-over60 (p<.05).
differences of all pairs were not significant (5%level)
differences of all pairs were not significant (5%level)
1.4 1.9 2.4
20-29 30-39 40-49 50-59 over 60
* Based on the Levene's test of homogeneity of variances, the test was conducted using the normal ANOVA statistics. ** Tukey's HSD was used for the multiple comparisons.
Figure 3. Age-based comparison of the degree of sensitivity to four factors
Conclusions
unfounded prejudices due to civics-related personal data abuse. In contrast, “YŌ-HAIRYO” seems to be readily associated with monetary and financial damage.
This research was an exploratory study on data sensitivity in Japan and is positioned as the first step of our research project. This research will be developed in two directions in the future. To deepen our understanding of Japanese people’s recognition of sensitive data, we plan to continue empirical research on Japanese data sensitivity. For example, confirmatory statistical methods, like structural equation modelling, will be used to confirm the relationship between factors and to understand the high-order factor structure of data sensitivity in Japan. Additionally, follow-up interviews will be conducted to explore why the Japanese think the way they do. The research outcome would seem to be an empirical base for effective implementation of the new Japanese legislation. We also plan to conduct an international comparison study on data sensitivity. By conducting surveys on data sensitivity in various countries and regions to clarify local uniqueness of perceptions of sensitive data, and a cross-cultural study to compare such uniqueness, we will attempt to clarify the possibility of establishing a globally acceptable standard for sensitive data protection. The outcome of such a comparative study would seem to be beneficial in the field of data protection because, in the current networked world, personal data are distributed throughout the world, much like a currency.
References
Cabinet Public Relations Office. (2015). Summary of Public Opinion Survey on the
revision of the Act on Protection of Personal Information. Japan. Retrieved from
http://survey.gov-online.go.jp/tokubetu/h27/h27-kojing.pdf
European Parliament. (1995). Directive 95/46/EC of the European Parliament and of the Council of 24 October 1995 on the protection of individuals with regard to the
processing of personal data and on the free movement of such data. Official Journal
of the European Union, 31–50.
European Parliament. (2016). Regulation (EU) 2016/679 of the European Parliament and
of the Council of 27 April 2016. Official Journal of the European Union. Retrieved
from http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?
uri=CELEX:32016R0679&from=EN
Field, A. (2013). Discovering Statistics using IBM SPSS Statistics. London: SAGE
Publications Ltd.
Financial Service Agency. (2009). Guidelines for Personal Information Protection in the
Financial Field. Japan. Retrieved from http://www.fsa.go.jp/common/law/kj-hogo/01.pdf
Hutcheson, G. D., & Sofroniou, N. (1999). The Multivariate Social Scientist. London:
SAGE Publications Ltd.
Iizuka, S., & Ogawa, K. (2005). A Survey of Sensitivity of Handling Personal Information
Itakura, Y. (2016). Japanese Reform of Data Protection Regime and European Adequacy
Decision. Information Network Law Review, 14, 156–183.
JIS. (2006). Personal Information Protection Management Systems (No. JIS Q
15001:2006). Japan. Retrieved from
http://www.meti.go.jp/policy/it_policy/privacy/jis_shian.pdf
Kaiser, H. F. (1974). An Index of Factorial Simplicity. Psychometrika, 39, 31–36.
Leech, N. L., Barrett, K. C., & Morgan, G. A. (2015). IBM SPSS for Intermediate
Statistics (5th ed.). New York: Routeledge.
Ministry of Internal Affairs and Communications. (2013). White Paper on Information
and Communications in Japan. Japan: Ministry of Internal Affairs.
Oguma, E. (1995). The origin on the myth of a homogeneous society. In Tanʾitsu
minzoku shinwa no kigen: “Nihonjin” no jigazō no keifu = The myth of the homogeneous nation (Shohan, p. 454). Tōkyō: Shinʾyōsha.
Okamura, H. (2010). Knowledge of the Act of Protection of Personal Information (2nd