Neural Network based Clustering using Visual
Features of Characters‟ Shape in Image
Safdar Zaman, Wolfgang Slany, S. Nadeem Ahsan, Farhan Hyder , Farukh Nadeem
{szaman,wsi, sahsan,fsahito}@ist.tugraz.at1,[email protected]
Institute of Software Technology, Graz University of Technology, Austria1
Institute of Broadband Communications, Graz University of Technology, Austria2
Abstract
--
Clustering gathers similar objects. A Character can also be treated as object and can be recognized in the image through its visual features. In this work, characters of the Urdu script are clustered on the basis of 18 different visual features. A Kohonen Self Organizing Map is used for clustering with four different topologies of sizes 6x5, 8x7, 9x8, and 10x10. Each topology is checked under 75, 100, 150 and 200 numbers of epochs. 30 Urdu characters make 106 different shapes due to the four different positions in the word. These 106 shapes are then classified into 53 general classes based on graphical similarity. The shape of each class comprises features for its description. Considering only 18 features of each shape, 53 general classes are then grouped into clusters using a Kohonen Self Organizing Map (K-SOM). The above mentioned work has been implemented in MATLAB.Index Term
--
Character’s shape, Features, Clustering, Kohonen-SOM, Topology.1. INTRODUCTION
Clustering is to group similar patterns. It can be thought of as an unsupervised learning problem. It is a process of gathering objects into groups whose members are somehow similar to each other. A collection of objects is called a cluster if it contains similar objects such that these objects are dissimilar to the objects belonging to other collections [7]. In Figure 1 above, four clusters are shown. Clusters contain more than one object. Objects within a cluster are similar if the distance between them is as small as possible. The distance defines a
similarity criterion among the objects of a particular cluster.
Fig. 1. Clusters
Objects can also be grouped into clusters depending upon their fitness to descriptive features. Such kind of clustering can be implemented using methods like Neural Networks. Neural Networks further have different types like Self-Organizing Map (SOM), Learning Vector Quantization
(LVQ1, LVQ2) etc. Our work is based on SOM Neural Network known as KOHONEN Self-Organizing Maps.
2. RELATED WORK
A lot of work is being done on object features in pattern recognition. Our work treats characters as objects. The work presented here is in fact related to our earlier work [1] in which a Self Organizing Map has been used for clustering in the scenario of text recognition. In this previous work Zaman along with Hussain and Ayub proposed a methodology for recognition system of segmented characters of the Urdu script for Nasakh. This work also
partially included clustering as a sub-phase. K.
Gopalakrishnan, S. Khaitan, A. Manik [2] have coped with how Kohonen Map (SOM) can be trained to identify and classify chemical analysis data. They applied a 5x5 Kohonen Map to classify one of 13 chemicals. Their methodology considers winning neuron in SOM on the basis of minimum-distance Euclidean criterion as here in our work. J. Vesanto and E. Alhoniemi [3] evaluated Self Organizing Map for clustering on parameterized distribution generated data. They applied SOM clustering on three data sets. M. Hangarge and B.V.Dhandra [10] also presented their work related to Optical Character Recognition of Offline Handwritten script. They consider distinct visual texture of the text in the image. The scripts they considered are English, Devnagari and Urdu. Their work extracts 13 spatial spread features of the text, using morphological filters. These spatial features are then used by KNN classifier for classification purpose. Prior to feature extraction they also apply some preprocessing in order to remove some connected components in the text which may cause noise. J. Ong and S. S. R. Abidi [4] described in their work how clusters are the groups of similar objects and Self-Organizing Kohonen Maps are one of the means used for data clustering applications. They used Neural Networks as data mining tool to gain statistical insights of large datasets. C. Amerijckx, M. Verleysen and P. Thissen, J. D. Legat [5] in their work, presented a distinguished property of SOM. They used Kohonen Neural Networks for compression scheme for the still images. They are also of the opinion that
the KOHONEN ALGORITHM has a number of significant
in a new dimension. He counts Self-organizing Neural Network for identifying consumer lifestyles which is an important characteristic and individual purchasing behavior
of the consumer in the market. He uses vector quantization
as underlying methodology in the algorithm. In his paper he has introduced a new algorithm which proves its ability to detect heterogeneous data patterns with a comparatively small number of parameters to be controlled by the user. M. H. S. Shahreza and M. S. Shahreza [9] have also worked on cursive script languages Arabic and Persian (Farsi). They presented a work with a new method to hide information in these cursive script languages. The Text Steganography method in their work, locates suitable letters in the original text for replacement. Then they change the code of located letters to hide the information. A. AMIN in [11] presented his work to cope with the problems related to printed and handwritten Arabic character recognition. His work also deals with the segmentation problem of cursive text of Arabic language.
3. OUR STRATEGY
We use a Kohonen Self-Organizing Map (SOM) for clustering. Clustering here is used as a separate module in
Optical Character Recognition (OCR). Segmented
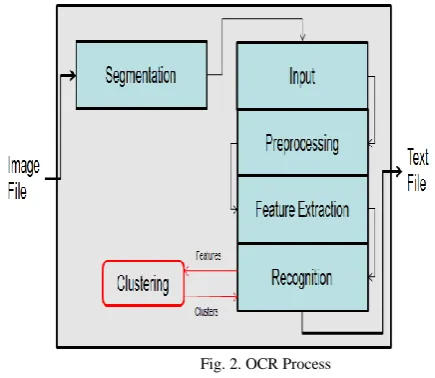
characters are clustered on the basis of their features. Figure 2 shows where clustering takes place in our OCR. It is also shown how Clustering uses features of the character‟s shape for recognition purpose. The input of the system is image whose visual features are used by clustering sub phase.
Fig. 2. OCR Process
3.1 CHARACTERS USED
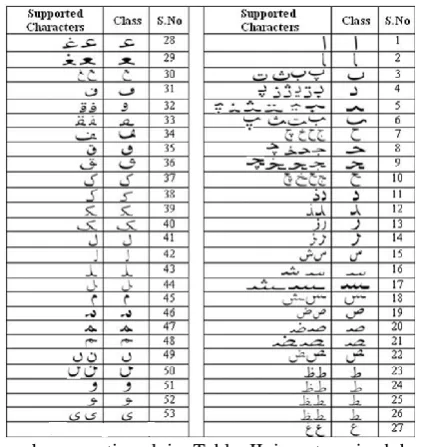
The most commonly used 30 Urdu characters are considered in our strategy. These 30 characters are not only the most common in Urdu but 28 of them are also part of the Arabic character set therefore using them also covers the issue of clustering in Arabic. The same character set was considered in our previous work presented in [1]. Figure 3 shows all of them:
Fig. 3. Used Character Set
Urdu script is a cursive script in its nature, therefore its words are formed by joining the characters with each other. A character can assume one of four different shapes depending upon whether it is totally isolated or joined at the beginning, middle, or at the end of a word. Because of their possible position in the word, these 30 characters make 106 different shapes as shown in Table I (seven characters do not occur at the start or in the middle of a word).
Table I
Of the 106 shapes some shapes are almost identical on the basis of their main region if their additional regions or dots are removed. Making the set simpler we combined similar shapes into 53 classes. This combination of similar shapes is due to their common features. Every class is represented and identified by the main region shared by all shapes in its group. As one class represents many shapes and those shapes differ from each other by very few features, this grouping simplifies the classification of a particular shape. These classes are given below in Table II.
Every class mentioned in Table II is categorized by 18 features. These 18 features are a feature set for that class. Each of the 18 features is binary in value. A feature‟s value is 1 if the class contains that feature, otherwise 0. Features are given below:
3.2 FEATURES USED
We used 18 visual features for each character. Figure 4
shows some of the features for character :
Fig. 4. Features in Character‟s Shape
Following are some features with their description:
Height: This feature is 1 if and only if the character has a
height greater than its width, e.g., , ,
Width: This feature is 1 if and only if the character has a
width greater than its height, e.g., ,
Loop_M: This feature is 1 if and only if the character
contains a loop in the middle, e.g., ,
Loop_S: This feature is 1 if and only if the character
contains a loop in the beginning, e.g., ,
Cross: This feature is 1 if and only if the character contains a crossover, the point from which four different
ways exit, e.g., ,
Curve_R: This feature is 1 if and only if the character has a
curve toward its right side, e.g , ,
Curve_U: This feature is 1 if and only if the character has a
curve toward its upside, e.g , ,
Start_H: This feature is 1 if and only if the character has a
horizontal start, e.g., ,
Start_V: This feature is 1 if and only if the character has a
vertical start, e.g., ,
End_H: This feature is 1 if and only if the character has a
horizontal end, e.g., ,
End_V: This features is 1 if and only if the character has a
vertical end, e.g., ,
Endp_1: This feature is 1 if and only if the character has
only one end point, e.g., ,
Endp_2: This feature is 1 if and only if the character has
two end points, e.g., ,
Endp_3: This feature is 1 if and only if the character has 3
end points, e.g., ,
Endp_4: This feature is 1 if and only if the character has 4
end points, e.g., ,
Joint_1: This feature is 1 if and only if the character has
only one joint, e.g., ,
Joint_2: This feature is 1 if and only if the character has
two joints, e.g., ,
Joint_3: This feature is 1 if and only if the character has
only three joints, e.g., ,
3.3 ARCHITECTURE USED
The 53 general classes discussed above are then grouped into clusters using a Self-Organizing Map (SOM) developed by Kohonen and shown in Figure 5. Input vector X: 53x18 containing n=18 features for each of m=53 classes, was used for training the SOM. The topology is a two dimensional vector which determines the number of clusters. The topology taken is rectangular but close to square vector.
Fig. 5. Neural Network
3.2 TOPOLOGIES USED
Four different topologies of orders 6x5, 8x7, 9x8, 10x10 were applied. During its learning process, the Kohonen algorithm started training parameters using Squared Euclidean Distance. It calculates the distance between input vector and weight vector and chooses the unit whose weight vector has the smallest Euclidean distance from the input vector. The following equation is used to compute the Euclidean Distance:
For t = 1 to size(Topology) do:
Where, „Dt‟ is the total distance of Xi incluster t. „Xi‟ is the
input vector. Wit is weight from input i to output t. Units
update their weights by forming a new weight vector which is a linear combination of the old weight vector and the current input vector. The weight update for output unit j is given as:
Wj(new) = Wj (old) + α [X – Wj (old)]
= α X + (1 - α) Wj (old)
where X is the input vector, Wj is the weight vector for unit
j (jth column of the weight matrix) and α is the learning rate decreased gradually during learning.
4. RESULTS
Each cluster contains one or more shapes. All shapes of a cluster share many common features.
With different topologies 6x5 (30 clusters), 8x7 (56 clusters), 9x8 (72 clusters) and 10x10 (100 clusters) we obtain different results. For each topology we use several different numbers of epochs, i.e. 75, 100, 150, and 200. The number of epochs and the maximum possible number of clusters (topology) are mentioned on the top of each result table. As we change topology and epochs these characteristics among the shapes also change.
4.1 RESULTS FOR TOPOLOGY 6X5
Table III shows result after 75 epochs. The topology used is 6x5, i.e. the total number of clusters cannot exceed 30. # in the table represents the cluster# in the topology grid. The final number of clusters formed is 23 and all other 7 clusters contain no character.
Here cluster 1 contains three shapes but cluster 2 has no shape and so on.
The maximum number of shapes in any cluster is 4.
Table III (75 Epochs, 6x5 Topology)
Now we change epochs from 30 to 100. Table IV shows the result after 100 epochs for the same topology 6x5. One can easily observe the difference from above results. 14 clusters are obtained after 100 epochs for topology 6x5. The number of clusters decreases as we increase epochs. The number of shapes per cluster is also increased. Cluster 1 has no shape. Cluster 2 gets 5 shapes. Cluster 26 contains all those shapes which start with a loop and have only one end point.
Table IV (100 Epochs, 6x5 Topology)
Table V below gives result after 150 epochs for topology 6x5. This gave 12 clusters. Cluster 2 contains the maximum number of shapes, i.e. 10.
Table V
(150 Epochs, 6x5 Topology)
The number of clusters formed is 13. Cluster 9 contains the maximum number of the shapes.
Table VI (200 Epochs, 6x5 Topology)
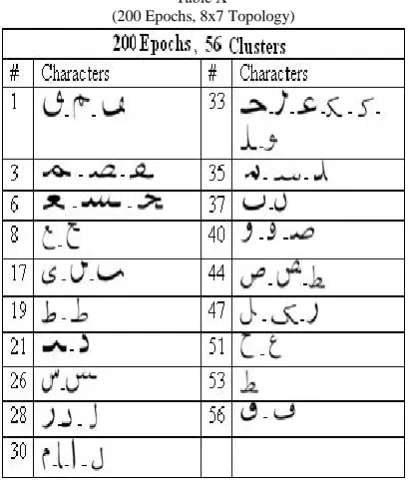
4.2 RESULTS FOR TOPOLOGY 8x7
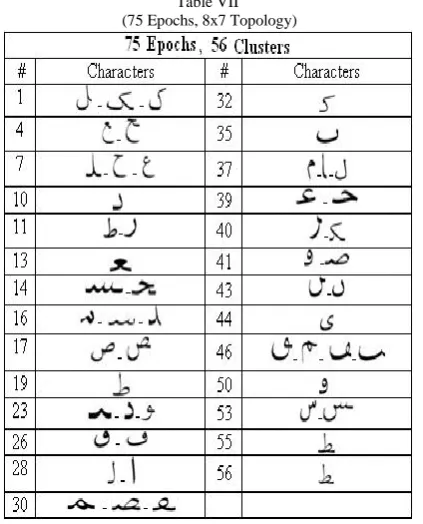
Next the topology is changed to 8x7, i.e. the number of clusters now cannot exceed 56. The clustering formed 27 clusters after 75 epochs. Table IX shows the clusters.
Table VII (75 Epochs, 8x7 Topology)
Table VIII below gives result after 100 epochs for topology 8x7. 27 clusters are formed consisting of at most 3 shapes.
Table VIII (100 Epochs, 8x7 Topology)
Table IX presents result after 150 epochs for topology 8x7. The total number of the clusters is 23. The maximum number of shapes in a cluster is 4 while the minimum number of shapes is 1.
Table IX (150 Epochs, 8x7 Topology)
Table X
(200 Epochs, 8x7 Topology)
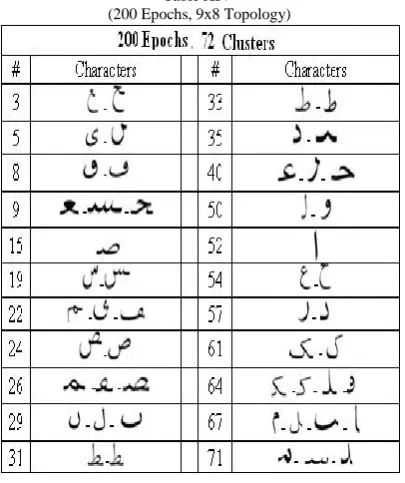
4.3 RESULTS FOR TOPOLOGY 9X8
Results of clustering for this topology after 75 epochs, is shown below in Table XI.
Table XI (75 Epochs, 9x8 Topology)
For epochs 100 and topology 9x8, the clustering is shown in Table XIII below. Total clusters formed are 28. Maximum number of shapes in a cluster is 3.
Table XII (100 Epochs, 9x8 Topology)
Table XIII shows the result of clustering after 150 epochs. The topology used is 9x8. The total number of clusters formed is 25.
Table XIII (150 Epochs, 9x8 Topology)
Table XIV (200 Epochs, 9x8 Topology)
4.4 RESULTS FOR TOPOLOGY 10X10
Table XV below shows the result after 75 epochs. The total number of clusters formed is 32. The maximum number of shapes in a cluster is 3.
Table XV (75 Epochs, 10x10 Topology)
Table XVI below shows clusters obtained after 100 epochs for topology 10x10.
Table XVI (100 Epochs, 10x10 Topology)
Table XVII presents clusters formed after 150 epochs. The topology used is 10x10. The total number of clusters formed is 27. The maximum number of shapes in a cluster is 5.
Table XVII (150 Epochs, 10x10 Topology)
Table XVIII (200 Epochs, 10x10 Topology)
5. SIGNIFICANCE
The presented results are of high importance. A clustering is more useful if it contains almost equal sized clusters with similar shapes because the final recognition becomes easier. During classification, an appropriate cluster is found and then the exact shape is recognized through at most three extra features. For example using the result (150 Epochs, 100 Clusters) in Table 17, we input to the system an arbitrary shape „S‟ for recognition, compute its features, apply them to the system and get cluster #4. As cluster #4 contains four shapes, we look for extra features, i.e., if shape „S‟ has no dot and has a value of feature Endp_2 equals to 1,
then shape „S‟ is . If „S‟ has one dot and the value of
fetaure Loop_M is equal to 1 then „S‟ is . Hence a shape
can be recognized with less comparisons. This work is also important because there is no significant OCR work for Urdu so far and the presented work is of high usefulness in that direction. Its also notable that any cursive script can adopt this kind of recognition system in order to facilitate its OCR system for classification and recognition.
6. OBSERVATIONS
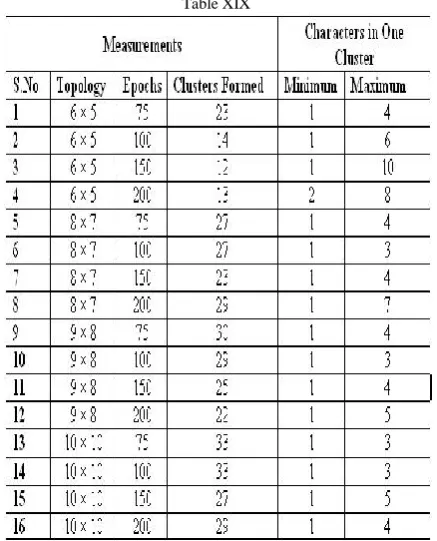
Following is some statistics obtained during the whole process of clustering. Against each topology and its corresponding Epoch, there are some findings like number of clusters, minimum number of characters per cluster and maximum number of characters per cluster. A topology with its epoch is given preference if it contains almost equal number of characters scattered in all the clusters.
Table XIX
Table XIX gives overall findings obtained after the process of clustering.
Fig. 6. Number of Clusters
Figure 6 gives numbers of clusters formed. It is also observed that during gradual increase in epochs, there is generally decrease in numbers of clusters. For example after least number (75) of epochs:
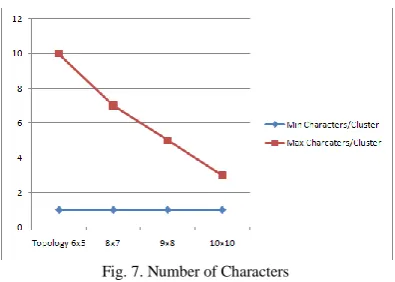
Fig. 7. Number of Characters
Figure 7 shows number of min/max characters found for different topologies. The number of characters per cluster also effects the results if there is much difference between maximum and minimum number of chareacters for a topology. The size of the character has also an impact because large size characters take longer for feature calculations.
7. CONCLUSIONS
In the this paper work, we introduced clustering that revolves arround the features of the character shapes of curvise script. Different features help the system place that character in a specific cluster. Many different clusters are experimented by changing Topology and Epoch for it. A cluster conatins all the shapes that share many features among them. A shape in a cluster can be very easily recognized with the support of its few additional features. After this whole process, we can conclude that small topologies yield a higher number of clusters as compared to large sized topologies.
As we increase the size of the topology, the number of
maximum characters in one cluster decreases as shown by the last column of Table 4.
Keeping the same number of epochs, an increase in the
size of the topology increases the number of clusters.
8. FUTUREWORK
Clustering plays a vital role in character recognition systems. This work can be extended for recognition of those cursive scripts (Arabic, Persian, etc.) whose character sets include shapes discussed in this work. One can also extend this work by adding more features of the characters to get better results. The size of the image character can also be taken into consideration which can increase processing speed for recognition. One more dimension for future work could be considering one universal character set which can cover all those cursive scripts that share many of the characters among them like Arabic,Udu,Persian, .etc. This work can also be used as a partial sub phase in the classification phase of any Offline Optical Character Recognition System. The proposed work can also be helpful to the OCR compilers which take Urdu script as input and digitize it for conversion into script like English, .etc.
ACKNOWLEDGEMENTS
The first author gratefully acknowledges the support from Higher Education Commission (HEC) of the government of Pakistan funding his PhD studies at Graz University of Technology in Austria.
REFERENCES
[1] S.A. Hussain, S. Zaman, M. Ayub, “A Self Organizing Map Based Urdu Nasakh Character Recognition”, IEEE 5th
International Conference on Emerging Technologies ICET 2009.
[2] K.Gopalakrishnan, S.Khaitan, A.Manik, “Enhanced Clustering Analysis and Visualization Using Kohonen‟s Self-Organizing Feature Map”, International Journal of Computational Intelligence 4;1 2008.
[3] J. Vesanto and E. Alhoniemi, ”Clustering of the Self-Organizing Map”, IEEE Transactions on Neural Networks Vol. 11, No. 3, May 2000.
[4] J. Ong and S. S. R. Abidi, ”Data Mining Using Self-Organizing Kohonen Map: A Technique for Effective Data Clustering & Visualization” , International Conference on Artificial Intelligence, (IC-AI‟99), June 28-July 1 1999, Las Vegas. [5] C.Amerijckx, M.Verleysen, P.Thissen, J.D.Legat,” Image
Compression by Self-Organized Kohonen Map”, IEEE Transactions on Neural Networks, Vol.9, No.3, MAY 1998. [6] T. Kohonen, “Self-Organizing Maps”, Springer, Berlin, 3rd
edition, 2001.
[7] http://www.elet.polimi.it/upload/ matteucc/Clustering/tutorial_html/
[8] R. Decker, “A Growing Self-Organizing Neural Network for Lifestyle Segmentation”, Journal of Data Science 4(2006), 147-168.
[9] M. H. S. Shahreza, M. S. Shahreza, ” Arabic/Persian Text Steganography Utilizing Similar Letters with different codes”, The Arabian Journal for Science and Engineering, Volume35, Number 1B, April 2010.
[10] M. Hangarge, B.V.Dhandra,” Offline Handwritten Script Identification in Document Images”, International Journal of Computer Applications (0975 – 8887), Volume 4 – No.6, July 2010.