PUBLIC
SAP HANA Platform SPS 12
Document Version: 1.0 – 2016-05-11
Configuration Guide for SAP HANA Smart Data
Integration and SAP HANA Smart Data Quality
Content
1 Getting Started. . . .5
1.1 Open a Support Connection. . . .6
2 Overview of Developer Tasks. . . .7
3 Remote and Virtual Objects. . . . 8
3.1 Search for an Object in a Remote Source. . . .8
3.2 Creating Virtual Tables. . . 9
Creating Virtual Tables from Remote Objects. . . 10
Creating Virtual Tables from a New Remote Source. . . .10
3.3 Create a Virtual Function. . . .11
3.4 Partitioning Virtual Table Data for Better Performance. . . 12
4 Enterprise Semantic Services. . . .14
4.1 Basic Search Query Syntax. . . .14
4.2 Search String Examples. . . .15
4.3 Search String Attribute Type and Content Type Names. . . .16
4.4 Define Term Mappings for Search. . . .18
4.5 Search for Remote Objects Using the SQL View. . . 19
4.6 Attribute Filter Expressions. . . 20
5 Transforming Data. . . . 24
5.1 Choosing the Run-time Behavior. . . .26
5.2 AFL Function. . . .28
5.3 Aggregation. . . 29
5.4 Case. . . 30
5.5 Cleanse. . . 33
Cleanse Configuration in Web-based Development Workbench. . . .41
About Cleansing. . . .47
Cleanse Input Columns. . . .53
Cleanse Output Columns. . . .55
5.6 Data Mask. . . .75
Change Default Data Mask Settings. . . .76
Mask Type. . . .79
Date Variance Type. . . .81
Numeric Variance Type. . . .83
Pattern Variance Type. . . 85
Data Sink Options. . . .96
Using Virtual Tables. . . .97
5.8 Data Source. . . 98
Data Source Options. . . .99
Reading from Virtual Tables. . . .100
5.9 Date Generation. . . .101
5.10 Filter. . . .102
Filter Options. . . .104
5.11 Geocode. . . .105
Geocode Configuration in Web-based Development Workbench. . . .109
About Geocoding. . . .113
Geocode Input Columns. . . .114
Geocode Output Columns. . . 116
5.12 Hierarchical. . . .119
Configure a Hierarchical node. . . 120
5.13 History Preserving. . . 121 5.14 Input Type. . . .123 5.15 Join. . . .125 Join Options. . . .126 5.16 Lookup. . . 127 5.17 Map Operation. . . .129 5.18 Match. . . .132 Match Options. . . 136
Match Input Columns. . . 139
Match Output Columns. . . .142
5.19 Output Type. . . 143 5.20 Pivot. . . .143 5.21 Procedure. . . .147 Procedure options. . . .148 5.22 R-Script. . . 149 5.23 Row Generation. . . .149 5.24 Sort. . . .151 Sort Options. . . .152 5.25 Table Comparison. . . 152 5.26 Template File. . . .155
Template File Options. . . .156
5.27 Union. . . 159
Union Options. . . .160
5.28 UnPivot. . . .160
5.29 Add a Variable to the Container Node. . . .165
5.31 Importing an ADP Flowgraph. . . .168
5.32 Activate and Execute a Flowgraph. . . .170
5.33 Reserved Words. . . .171
5.34 Nodes Available for Real-time Processing. . . .172
5.35 Use the Expression Editor. . . .172
6 Profiling Data. . . .174
6.1 Semantic Profiling. . . 174
6.2 Distribution Profiling. . . 180
6.3 Metadata Profiling. . . .186
7 Replicating Data. . . . 190
7.1 Create a Replication Task. . . .190
7.2 Add a Target Column. . . .192
7.3 Edit a Target Column. . . .193
7.4 Delete a Target Column. . . 194
7.5 Load Behavior Options for Targets in Replication Tasks . . . 194
7.6 Activate and Execute a Replication Task. . . .197
1
Getting Started
The Configuration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Quality describes concepts necessary for replicating, enhancing, cleansing, and transforming your data to make it more accurate and useful in less time using SAP HANA.
There are two main concepts regarding this product: smart data integration and smart data quality. This Configuration Guide provides conceptual, procedural, and reference information for a subset of the available features. The information in this guide is mainly for users in a developer role but may contain some helpful information for administrators as well. See the Administration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Quality for installation, security, and administration tasks. See the Adapter SDK Guide for SAP HANA Smart Data Integration for creating, configuring, and deploying custom adapters.
SAP HANA smart data integration is a set of functionality provided by several components that you can use to retrieve data from an external system, transform it, and persist it in SAP HANA database tables. SAP HANA smart data integration features and tools addressed in this guide:
● The Replication Editor in the SAP HANA Web-based Development Workbench is for creating real time or batch replication scenarios for moving data into SAP HANA studio.
● SAP HANA smart data integration transformation nodes available in the application function modeler of SAP HANA studio can be used for pivoting tables, capturing changed data, comparing tables, and so on.
SAP HANA smart data quality is a set of functionality provided by several components that you can use to cleanse and enrich data before it is persisted in the SAP HANA database. SAP HANA smart data quality features described in this guide include batch and real-time data cleansing using the Cleanse node and enriching geospatial data with the Geocode node.
In combination, smart data integration and smart data quality support the following use cases: ● Federation: Sending a query to the SAP HANA database for data that exists in an external system. ● Replication: Copying tables and their contents from an external system into the SAP HANA database with
minimal processing.
● Transformation, Cleanse, and Enrich: Extracting data from an external system, transforming, cleansing, enriching, and persisting the results in the SAP HANA database.
1.1
Open a Support Connection
In some support situations, it may be necessary to allow an SAP support engineer to log into your system to analyze the situation.
Procedure
1. To enable a support user to log on to your system, complete the following tasks: a. Install the SAProuter as described on SAP Support Portal.
b. Set up a support connection as described in SAP Note 1634848 (SAP HANA database service connections).
c. Configure a Telnet connection as described in SAP Note 37001 (Telnet link to customer systems) d. Configure an SAP HANA database connection as described in SAP Note 1592925 (SAP HANA studio
service connection).
e. Configure a TREX/BIA/HANA service connection as described in SAP Note 1058533 (TREX/BIA/HANA service connection to customer systems).
2. Create a database user and grant the MONITORING role.
The MONITORING role allows a database user to open the SAP HANA Administration Console perspective with read-only access to the system, system views, statistics views, trace files, and so on. However, this role does not provide any privileges for accessing application data. With the MONITORING role, it is also not possible to change the configuration of or start and stop a system. You can grant the MONITORING role to a support engineer if SAP support needs to connect to the system. Depending on the issue to be analyzed, further privileges may be needed to allow sufficient analysis (for example, to access application data or data models).
Related Information
SAP Note 1634848 SAP Note 37001 SAP Note 1592925 SAP Note 1058533 SAProuter2
Overview of Developer Tasks
Developer tasks described in this guide consist of designing processes that replicate data and processes that transform, cleanse, and enrich data.
The administrator should have already installed the Data Provisioning Agents, deployed and registered the adapters, and created the remote sources. See the Administration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Quality.
Here are the tasks typically performed by a developer. ● Design data replication processes.
● Design data transformation processes, which can include cleansing and enrichment.
See the Administration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Quality for details.
Related Information
Replicating Data [page 190]3
Remote and Virtual Objects
This section provides an overview of how to use Data Provisioning adapters with remote sources, virtual tables, virtual functions, and virtual procedures with SAP HANA.
Administrators add remote sources to the SAP HANA interface to make a connection to the data. Then
developers access the data by creating a virtual table from a table in the remote source. A virtual table is an object that is registered with an open SAP HANA database connection with data that exists on the external source. In SAP HANA, a virtual table looks like any other table.
You can also create virtual functions, which allow access to remote sources like web services, for example. Virtual procedures expand on virtual functions by letting you have large objects and tables as input arguments and can also return multiple tables.
3.1
Search for an Object in a Remote Source
You can search remote sources to find objects in the SAP HANA Web-based Development Workbench Catalog and create virtual tables.
Prerequisites
Searching a remote source requires the following privilege on the remote source: GRANT ALTER ON REMOTE SOURCE <remote_source_name> TO <user>. Granting this privilege allows the creation of a dictionary, which can then be searched.
Additionally, if you are using an SAP ECC adapter, be sure that you have a SELECT privilege on the following tables: ● DM41S ● DM26L ● DD02VV ● DM40T ● DD02L ● DD16S ● DD02T ● DD03T ● DD03L
Context
In the SAP HANA Web-based Development Workbench Catalog, expand Provisioning Remote Sources.
Procedure
1. Right-click the remote source to search in and select Find Table.
2. In the Find Remote Object window, click Create Dictionary to build a searchable dictionary of objects from the source.
3. To search, enter filter criteria for Display Name, Unique Name, or Object Description that Contains, Equals, Starts with, or Ends with characters you enter.
For example, to filter by name, enter the first few characters of the object name to display the objects that begin with those characters. The Case sensitive restriction is optional. To add additional criteria to further filter the list, click the plus sign and enter the additional parameter(s).
4. (Optional) The bottom of the window includes a time stamp for when the dictionary was last updated. You can refresh or clear the dictionary here.
5. Click Create Virtual Table. 6. Enter a Table Name. 7. Select a target Schema. 8. Click OK.
9. Close the Find Remote Object window.
3.2 Creating Virtual Tables
To read and write data from sources external to SAP HANA, create virtual tables within SAP HANA to represent that data.
You can create virtual tables that point to remote tables in different data sources. You can then write SQL queries in SAP HANA that can operate on virtual tables. The SAP HANA query processor optimizes these queries, and then executes the relevant part of the query in the target database, returns the results of the query to SAP HANA, and completes the operation.
Within SAP HANA studio, you can create virtual tables in SAP HANA by searching for the exact name of the table in the remote system or by browsing for the remote object.
Within the SAP HANA Web-based Development Workbench, you create virtual tables in SAP HANA by browsing for the remote object. (Right-click the remote source and select New virtual table.)
Related Information
SAP HANA Administration Guide (HTML) SAP HANA Administration Guide (PDF)
3.2.1 Creating Virtual Tables from Remote Objects
How to create virtual tables from remote objects
Context
You have already created a remote source. It appears in the Systems view, Provisioning Remote Sources .
Procedure
1. In the Systems view, expand the Remote Sources. Select the correct user and correct remote object on which you want to create your virtual table.
2. Right click the remote object and select Add as Virtual Table.... 3. Enter the Table Name and select the Schema from the drop-down list.
4. Click Create, Result: An information box appears stating that the virtual table has been added.
Results
The new virtual table will appear in the Systems view, Catalog <schema> Tables.
3.2.2 Creating Virtual Tables from a New Remote Source
How to create a virtual table from a new remote source
Context
Procedure
1. In the Systems view Catalog <Schema_Name> Tables, right click and select New Virtual Table...
2. Enter a Table Name, then click Browse.... A dialog box appears. Select the remote source, database, and table. 3. Click OK. Result: The source name and the remote object are filled in automatically by the names of the
components chosen in the previous step.
4. Click the Save the Editor icon in the upper right hand corner of the screen.
Results
This creates a virtual table. The new virtual table will appear in the tree view Catalog <schema> Tables.
3.3 Create a Virtual Function
You can browse remote functions on remote sources using Data Provisioning adapters, then import them as virtual functions in the same way you browse remote tables and import them as virtual tables.
Prerequisites
The remote function has been created and is available in the SAP HANA Web-based Development Workbench: Catalog.
Procedure
1. In the SAP HANA Web-based Development Workbench: Catalog, expand Provisioning Remote Sources . 2. Expand the remote source where you want to add the new virtual function.
3. Right-click the remote function and select New Virtual Function.
4. In the Create Virtual Function dialog box, enter a Function Name and select a Schema from the drop-down list. 5. Click OK.
Results
The new virtual table appears in the SAP HANA Web-based Development Workbench: Catalog ><Schema> > Functions.
Example
If you use the SQL Console to create a function, the following example illustrates how to create a function that returns the sum of two numbers.
First run the built-in procedure GET_REMOTE_SOURCE_FUNCTION_DEFINITION:
CALL "PUBLIC"."GET_REMOTE_SOURCE_FUNCTION_DEFINITION" ('testAdapter','sum',?,?,?);
Copy the output of the configuration and paste it in the CONFIGURATION section:
CREATE VIRTUAL FUNCTION SUM_TEST(A INT, B INT) RETURNS TABLE (SUM_VALUE INT) CONFIGURATION '{"__DP_UNIQUE_NAME__":"sum"}' AT "testAdapter";
For more information about using the SQL Console, see the SAP HANA Administration Guide.
For syntax details for CREATE VIRTUAL FUNCTION, refer to the SAP HANA SQL and System Views Reference.
Related Information
SAP HANA Administration Guide (HTML) SAP HANA Administration Guide (PDF)
SAP HANA SQL and System Views Reference (HTML) SAP HANA SQL and System Views Reference (PDF)
3.4 Partitioning Virtual Table Data for Better Performance
For better performance, you can partition virtual table input sources and have SAP HANA read those input sources in parallel.
You can specify within a replication task or flowgraph (within the Data Source node) that the system perform multiple reads in parallel from a virtual table input source in order to improve the reading throughput for some records of data provisioning type sources to be loaded in parallel.
Note
To verify that a certain data provisioning adapter supports partitioning, see the Administration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Quality for information on each adapter.
By default, partitioning of data is not enabled. You can enable this feature to improve performance by selecting one of the two partition types: range partitions and list partitions.
● Range partitions may specify only a single value.
● List partitions may specify either a single value or a comma delimited list of values.
For either type of partition, the value for each partition, representing which data goes into which parallel thread, should be entered in single quotation marks, as follows: 'example'
Partitioning of columns requires that the Not null attribute of the column is set to TRUE.
Related Information
Data Source Options [page 99]4 Enterprise Semantic Services
Enterprise Semantic Services provides an API to enable searching for artifacts and run-time objects based on their metadata and contents.
Related Information
Reference Information4.1 Basic Search Query Syntax
Basic search query syntax supported by Enterprise Semantic Services. query ::= [ scope-spec ] ( qualified-expression )+
scope-spec ::= (' category ' | ' appscope ' ) ' : ' IDENTIFIER ( scope-spec ) ? qualified-expression ::= [ ' + ' | ' - ' ] term-expression
term-expression ::= attribute-type-expression | attribute-filter-expression | term
attribute-type-expression ::= (attribute-type-name ' :: ' ( disjunctive-term-expression | conjunctive-term-expression | term )) | ' date ' ' :: ' (disjunctive-date-conjunctive-term-expression | conjunctive-date-conjunctive-term-expression | date) attribute-filter-expression ::= attribute-filter-name ' : ' ( disjunctive-term-expression | conjunctive-term-expression | term )
disjunctive-term-expression ::= ' ( ' term ( ' OR ' term )* ' ) ' conjunctive-term-expression ::= ' ( ' term ( ' AND ' term )* ' ) ' disjunctive-date-expression ::= ' ( ' date ( ' OR ' date )* ' ) ' conjunctive-date-expression ::= ' ( ' date ( ' AND ' date )* ' ) ' term ::= WORD | PHRASE
attribute-name ::= IDENTIFIER
attribute-type-name ::= 'AddressLine' | 'FullAddress' | 'BuildingName' | 'StreetName' | 'SecondaryAddress' | 'Country' | 'City' | 'Postcode' | 'Region' | 'Firm' | 'Person' | 'FirstName' | 'LastName' | 'HonoraryPostname' | 'MaturityPostname' | 'Prename' | 'PersonOrFirm' | 'Title' | 'Phone' | 'SSN' | 'NameInitial' | 'Email' /* attribute type names are case-insensitive */
attribute-filter-name ::= 'DesignObjectName' | 'DesignObjectType' | 'DesignObjectPath' | 'DesignObjectFullName' | 'EntitySetName' | 'EntitySetType' | 'EntitySetPath' | 'EntitySetFullName' | 'EntitySetLocation' /* attribute filter names are case-insensitive */
WORD ::= ( [A-Za-z0-9] | WILDCARD ) + /* A word containing wildcard characters is also called pattern */ PHRASE ::= ' " ' ( [/u0020-/u0021 /u0023-/uFFFF] | WILDCARD) + ' " ' /* A phrase containing wildcard characters is also called pattern */
WILDCARD = ' * '
date::= [0-9] [0-9] [0-9] [0-9] ' - ' [0-9] [0-9] ' - ' [0-9] [0-9] /* YYYY-MM-DD */ | [0-9] [0-9] [0-9] [0-9] [0-9] [0-9] [0-9] [0-9] /* YYYYMMDD */
| [0-9] [0-9] [0-9] [0-9] ' - ' [0-9] [0-9] /* YYYY-MM */ | [0-9] [0-9] [0-9] [0-9] /* YYYY */
IDENTIFIER ::= [A-Za-z]+ [A-Za-z0-9._$] +
4.2 Search String Examples
Examples of search string elements and their descriptions.
Element in Search String
Search String Examples Description of Search Results
Words Contracts by sales units Dataset names that include the words “contracts”, “by”, “sales”, or “units”
Words and phrase
number of contracts by “customer re gion” age year
Dataset names that include “number” or “contracts” or “cus tomer region” or “age” or “year”
Words and pat tern
Revenue by prod* region Dataset names that include “revenue” or a word that starts with “prod” or the word “region”.
Possible results include “revenue production” or “products re gion”.
Pattern within phrase
“insur* cont*” Dataset names that include a word starting with “insur” followed by a word starting with “cont”.
Possible results include “insurance contracts" or "insured con tacts"
Words and at tribute type ex pression
Number reversals date::(2010 OR 2011 OR 2012)
Dataset names that includes the word “number” or “reversals” or the contents of the dataset include a date column that con tains at least one of the values 2010, 2012, or 2012
Words and quali fied expression
Loss and Expense +"Outstanding Re serves"
Loss and Expense -insurance
Dataset names that optionally include the word “loss” or “ex pense”, but must contain "outstanding reserves"
Dataset names that optionally include “loss” or “expense”, but must not contain "insurance"
Element in Search String
Search String Examples Description of Search Results
Date values Date::2000
Date::(2000 AND 2001-01 AND 2001-02-01)
Date::(2000 OR 2001-01 OR 2001-02-01)
Dataset that contains a date column with the value 2000. Dataset that contains a date column with the value 2000 and 2001-01 and 2001-02-01.
Dataset that contains a date column with the value 2000 or 2001-01 or 2001-02-01.
Attribute type expressions with geography val ues
city::("New York" OR Paris) country::(USA AND Canada) region::"Ile de France"
Dataset that contains a city column with either the value “New York” or “Paris”
Dataset that contains a country column with both the value “USA” and “Canada”
Dataset that contains a region column with the value “Ile de France” Attribute type expressions with pattern City::Washington* LastName::Panla*
Dataset that contains a city column with a value that starts with “Washington”
Dataset that contains a last name column with a value that starts with “Panla”
Attribute filter
expressions EntitySetLocation:local foodmart EntitySetFullName:(foodmart OR adven tureworks)
EntitySetType:table
DesignObjectType:"hana * view"
Entitysets matching “foodmart” in local SAP HANA instance Entitysets with their name matching either “foodmart” or “ad ventureworks”
Entitysets of sql table or hana virtual table type Entitysets with design objects of hana calculation view,
hana attribute view or hana analytic view type See Attribute Filter Expressions [page 20].
Note
● Stopwords are either ignored or considered optional in a phrase. Stopwords are any pronoun, preposition, conjunction, particle, determiner, and auxiliary.
For example, “number of contracts” will include the search results “number contracts” and “number of contracts”.
● Special characters are ignored. Special characters include \/;,.:-_()[]<>!?*@+{}="&. For example, "contract_number" will be handled as "contract number".
4.3 Search String Attribute Type and Content Type Names
The search string can contain an attribute type name that corresponds to a content type name. The search results will return data set names that contain the content type and specified value.
Note
Attribute type names are not case sensitive in search strings.
Attribute Type in Search String Content Type Name
AddressLine Address Line
FullAddress Full Address
BuildingName Building Name
StreetName Street Name
SecondaryAddress Secondary Address
Country Country City City Postcode Postcode Region Region Firm Firm Person Person
FirstName First Name
LastName Last Name
HonoraryPostname Honorary Postname
MaturityPostname Maturity Postname
Prename Prename
PersonOrFirm Person Or Firm
Title Title
Date Date
Phone Phone
SSN SSN
4.4 Define Term Mappings for Search
Administrators define term mappings to provide multiple explicit interpretations of hypernyms, hyponyms, synonyms, acronyms, and abbreviations in a semantic search query.
Context
Term mappings provide explicit interpretations of a keyword in a semantic search query. A keyword can be interpreted as a hypernym, hyponym, or synonym in a given language, or as an acronym or abbreviation in a given business domain.
Keyword Interpretation Term Mapping Example Description of Search Results
Hypernym Find hyponyms (subcatego ries) of the search term.
(Car, VW Golf) Search for “car” will match “VW Golf" in the Entity Grid contents.
Hyponym Find hypernyms (superordi nates) of the search term.
(VW Golf, Car) Search for “VW Golf” will match “car” in the Entity Grid.
Synonym Find synonyms of the search term.
(client, customer) and (cus tomer, client)
A search for “client” will match “cus tomer” (and vice versa)) in the Entity Grid..
Acronym or Abbrevia tion
Find acronyms or abbrevia tions of the search term.
(Ltd, Limited) and (Limited, Ltd)
A search for “ltd” will match “limited” (and vice versa) in the Entity Grid. (contract, contr)
Plurals must be explicitly de fined: (contracts, contrs)
A search for “contract” will match “contr” in the Entity Grid.
To define term mappings, do the following:
Procedure
1. Log in to SAP HANA studio with a user or any user who has the Enterprise Semantic Search Administrator role.
2. For each term you want to map, insert a row into the term mapping table
SAP_HANA_IM_ESS"."sap.hana.im.ess.services.search::Mapping, which has the following columns:
Column Name Description
Column Name Description
LIST_ID A list_id value can be passed in the search.request parame
ter of the search API.
LANGUAGE_CODE Currently, only the following value is possible:
○ en
TERM_1 Term in the search query.
TERM_2 Matching term in the Entity Grid.
WEIGHT Always use 1.
The following sample SQL statement maps the abbreviation “Insur” to “insurance”.
insert into "SAP_HANA_IM_ESS"."sap.hana.im.ess.services.search::Mapping" values ('20','1','en','Insur','insurance',1);
4.5 Search for Remote Objects Using the SQL View
You can view the metadata of all remote objects published in the Enterprise Semantic Services (ESS) Entity Grid using a SQL view.
All remote objects published in ESS Entity Grid can be queried through the public SQL view "SAP_HANA_IM_ESS"."sap.hana.im.ess.services.views::REMOTE_OBJECTS".
Users only see the remote objects for which they have access privileges. Grant the privilege CREATE VIRTUAL TABLE on the remote sources for which the user should have access.
This view displays metadata information for each remote object. The description of each column of the view can be displayed in the view definition:
Column Description
REMOTE_SOURCE Name of the remote source containing the remote object
UNIQUE_NAME Unique identifier of the remote object within the remote
source
DISPLAY_NAME Display name of the remote object in the browsing hierarchy
of the remote source
UNIQUE_PARENT_NAME Unique identifier of the parent node of the remote object in the browsing hierarchy of the remote source
DISPLAY_CONTAINER_PATH Display name of the container path of the remote object in the browsing hierarchy of the remote source
DATABASE Database name for the remote source. Can be null.
Column Description
OBJECT_TYPE Type of the remote object (table or view)
4.6 Attribute Filter Expressions
Enterprise Semantic Services attribute filter expression descriptions and examples. Attribute filters belong to two categories:
● Object filters apply on an individual object (for example, a design object or an entity set)
● Class filters apply to a group of objects. A class filter must be used in conjunction with at least one object filter or a keyword; otherwise, the query does not return any objects because the filter is considered to be too broad (can return too many objects).
Attribute Filter Category Description Example Matching example
DesignObjectName object filter Applies on the name of a design-time object from which rundesign-time objects are created; for example, an SAP HANA view.
DesignObjectName: (inventory OR ECC)
This filter can match an SAP HANA view with name INVENTORY or ECC.
RemoteSourceName object filter Applies on the name of a remote source. RemoteSourceName: ("DB2_ECC" OR "ORACLE ECC") RemoteSourceName: ("*ECC*" OR "*ECC*") RemoteSourceName: ("DB2" AND "ECC")
This filter can match the remote sources: DB2_ECC_REMOTE_S OURCE
ORACLE_ECC_REMOT E_SOURCE
DesignObjectType class filter Applies on the type of a design-time object that was used to create a runtime object. Possible values of types of design-time objects are:
● SAP HANA calculation view ● SAP HANA analytic view ● SAP HANA attribute view
DesignObjectType: "hana * view"
This filter can match any SAP HANA view.
DesignObjectPath object filter Applies on the path of the fully qualified name of a design-time object that was used to create a runtime object. For an SAP HANA view, the path represents the path of packages containing
DesignObjectPath: "foodmart" DesignObjectPath: "hba.fscx604" DesignObjectPath:"sap * fscx604"
The first filter can match any design object whose container path contains the string "foodmart".
Attribute Filter Category Description Example Matching example
the view. There is no path for a remote source because it is the same as its full name.
The second filter can match any design object whose container path matches the phrases "hba.fscx604" or "sap * fscx604". DesignObjectFullName object filter Applies on the fully qualified
name of a design-time object. For an SAP HANA view, the fully qualified name includes the container path and the name.
DesignObjectFullName : (foodmart OR "DB2 ECC") DesignObjectFullName :"foodmart/calculat* views" DesignObjectFullName :"foodmart calculat*views" DesignObjectFullName :"foodmart calculationviews" DesignObjectFullName :"hba.fscx604.calculati onviews"
EntitySetName object filter Applies on the name of an entity set, which represents any object that can be returned in a search result. An entity set can represent:
● An SAP HANA catalog object ● A remote object EntitySetName: inventory EntitySetName: "business partner"
The first filter matches any entity set that contains "inventory" in its name.
The second filter matches any entity set that contains "business partner" in its name. EntitySetType class filter Applies on the type of an entity
set. Possible values are: ● SQL table
● SQL view
● SAP HANA column view ● SAP HANA virtual table Note that remote objects are either of type SQL table or SQL view.
EntitySetType: ("column view" OR "SQL table)"
This filter matches any entity set of type "column view" or "SQL table".
Attribute Filter Category Description Example Matching example
EntitySetPath object filter Applies on the path of the container of an object represented by an entity set. The path can be:
● A schema name for an SAP HANA catalog object ● A database.owner name for
a remote object in a database system ● A path of folders for a
remote object in an external application (for example ECC). EntitySetPath: "_SYS_BIC" EntitySetPath: "SAP_ANW" EntitySetPath:"SAP_C A - Cross Application Models ORG-EINH - Organizational units ORGE_A - Organizational Units Finance ORGE_12113 - Dunning Area" +EntitySetPath: "finance" +EntitySetPath: "SAP" is equivalent to: +EntitySetPath: ("finance" AND "SAP")
The first filter matches any entity set in schema _SYS_BIC. The second filter matches any entity set in the folder path matching the phrases.
EntitySetFullName object filter Applies on the fully qualified name of an entity set. The fully qualified name includes the container path and the name of the object represented by the entity set. EntitySetFullName: (inventory OR T407M) EntitySetFullName: "DB2_ECC_REMOTE_S OURCE" EntitySetFullName: "DB2_ECC_REMOTE_S OURCE * * T047M" EntitySetFullName: "DB2_ECC_REMOTE_S OURCE null null T047M"
EntitySetFullName: ("DB2_ECC_REMOTE_ SOURCE" AND "T047M")
The first example matches any entity set whose qualified name contains one of the two strings "inventory" or "T407M".
The second example matches any entity set whose qualified name contains the phrase DB2_ECC_REMOTE_S OURCE.
The last three filters match the entity set: DB2_ECC_REMOTE_S OURCE.<NULL>.<NUL L>.T047M
EntitySetLocation class filter Applies on the location of the object represented by an entity set. Possible values for location are:
● local means local SAP HANA instance, implicitly
EntitySetLocation: local
EntitySetLocation: remote
Matches any SAP HANA catalog object Matches any remote object
Attribute Filter Category Description Example Matching example
qualifying an SAP HANA catalog object
● remote means a remote object
5
Transforming Data
Use the application function modeler in SAP HANA Studio or the flowgraph editor in Web-based Development Workbench to create flowgraphs to transform your data.
Before using the application function modeler or the flowgraph editor, you must have the proper rights assigned. See the "Assign Roles and Privileges for tasks" topic in the SAP HANA Smart Data Integration and SAP HANA Smart Data Quality Administration Guide.
In application function modeler and Web-based Development Workbench, the data flows are stored as flowgraph objects with an extension of .hdbflowgraph. When activated, the data flows generate a stored procedure or a task plan. They can consume:
● database tables, views, and links to external resources ● relational operators such as filter, join, and union ● custom procedures written in SQL script
● functions from optional components such as the Application Function Library (AFL) or Business Function Library (BFL)
● smart data quality nodes such as Cleanse, Geocode, and Match (Web-based Development Workbench only) ● smart data integration nodes such as History Preserving, Lookup, Pivot, and Case
See the SAP HANA Developer Guide for SAP HANA Studio for more information about the application function modeler such as creating flowgraphs, connections, adding/editing nodes, and templates. See the SAP HANA Developer Guide for SAP HANA Web Workbench for more information about Web-based Development Workbench.
Configuring the flowgraph
This section describes the options available for processing the flowgraph. In SAP HANA Web-based Development Workbench:
1. Click the Properties icon.
2. Select the target schema. This is where you can find the available input and output tables. 3. Select the Runtime behavior type. For details, see "Choosing a Runtime Behavior."
Option Description
Procedure Processes data with a stored procedure. It cannot be run in realtime. A stored proce dure is created after running a flowgraph. Only a portion of the nodes are available to use in the flowgraph (no Data Provisioning nodes).
Batch Task Processes data as a batch or initial load. It cannot be run in realtime. A stored proce dure and a task is created after running a flowgraph. All nodes are available in the flow graph.
Realtime Task Processes data in realtime. A stored procedure and two tasks are created after run ning a flowgraph. The first task is a batch or initial load of the input data. The second task is run in realtime for any updates that occur to the input data.
Option Description
Transactional Task Processes data in realtime. A single task is created after running a flowgraph that is run in realtime for any updates that occur to the input data.
4. Select Data Type Conversion (For Loader only) if you want to automatically convert the data type when there is a conflict. If a loader (target) data type does not match the upstream data type, an activation failure occurs. When you select this option, a conversion function is inserted to change the upstream data type to match the loader data type.
For example, if you have selected this option and the loader data type for Column1 is NVARCHAR and is mapped to ColumnA that has a data type of CHAR, then a conversion function of to_nvarchar is inserted so that the flowgraph can be activated. However, if the input and output data types do not match, and this option is not enabled, then the flowgraph will not be activated.
Upstream data type Conversion function Loader data type Flowgraph activation
CHAR to_nvarchar NVARCHAR Activated
CHAR n/a NVARCHAR Not activated
5. Click the plus icon to add any variables or scalar parameters that you want to execute during run time. 6. Click OK.
Configuring nodes
This section of the guide describes the input, output and configurable properties of smart data integration and the smart data quality nodes.
In SAP HANA Web-based Development Workbench:
1. Select a node and drag it onto the canvas, and double-click to open.
2. To change the name of the node, enter a unique name in the Node Name option. 3. To perform just-in-time data preview, select the JIT Data Preview option.
Note
Just-in-time data preview is an option where you can process data from the beginning of the flowgraph up until the point of this node. After configuring this node, go back to the Flowgraph Editor, and click Save. Click the Data Preview icon to the right of this node to verify what your output will look like before running the entire flowgraph. The data is a temporary preview and is not written to any downstream output targets. Any changes to upstream nodes will result in changes to the data preview when the flowgraph is saved again.
4. To copy any columns from the input source to the output file, drag them from the Input pane to the Output pane.
5. Continue configuring the node in the Node Details pane. See the details of configuring each node later in this document.
6. Click Back to return to the Flowgraph Editor. In SAP HANA Studio Application Function Modeler:
2. To change the name of the node, click on the name. The name field becomes active for editing.
Note
The name of a node may only contain letters, underscores, and digits. It must be unique within the flowgraph.
3. In the General tab of the Properties view, configure the nodes.
Related Information
Choosing a Task Plan or a Stored Procedure [page 26] Nodes Available for Real-time Processing [page 172] Add a Variable to the Container Node [page 165]
5.1
Choosing the Run-time Behavior
When creating a flowgraph, you need to consider how you want it processed. consider these main differences when selecting the runtime behavior:
● Whether to create a stored procedure, task plan, or both ● Which nodes you might use in the flowgraph
● Whether you want to process in realtime or batch mode
When choosing between running a flowgraph as a task or a stored procedure is the availability of the nodes, and whether the flowgraph creates a stored procedure, a task plan or both.
Procedure
When selecting a stored procedure, you won't see the Data Provisioning palette, which contains a number of nodes used to transform data such as Cleanse, Match and Geocode. After activating the flowgraph, you will have created a stored procedure.
Unlike task plans, stored procedures cannot be run in realtime mode. Instead, a stored procedure always runs in batch mode, that is, on the complete procedure input.
Tasks
● Choose a task plan when you want to use any Data Provisioning nodes. These nodes are available in the Data Provisioning palette.
● The nodes in the General palette as well as those in the application function library and R script palettes can be used in the task plan. However, you cannot use the Data Sink (Template Table) node. You can use the standard Data Sink node. For this, the Data Sink table has to exist in the catalog.
● When you select a task plan, a Variable tab is enabled on the container node. There you can create variables to be used as part of function calls. Variables are created and initialized when the task is processed. You can explicitly specify the arguments to variables in the start command, or you will be prompted for initial values. For example, if you want to run the flowgraph for different regions in the US, then you can create variables such as "Southwest" or "Northeast" or "Midwest" in the container node. You'll set up a filter using the Filter node that can run only those records that match the filter. Then you can call the correct variable when calling Start Task, and only the data for those regions are processed.
● A connection can represent only one-to-one table mappings. The only exception is if the target anchor of the connection includes one of the following nodes:
○ AFL function node ○ Data Sink node ○ Procedure node ○ R script node
Tip
You can always represent the table mapping of a connection by adding a Filter node between the source and target of the connection, and then editing the table mapping in the Mapping Editor of the Filter node. You can learn more about these nodes in the SAP HANA Developer Guide.
● When creating a task plan, ensure that the column names for the input source and output target do not include any of the reserved words listed in the Reserved Words topic.
● For Realtime and Transactional tasks, when you are loading data from a virtual table, you must enable realtime processing on the source data in the flowgraph, depending on which data provisioning adapter you are using. Click the table and check the Real-time option in the properties.
Batch Task
In batch tasks, the initial load is updated only when the process is started or is scheduled to run. Unlike the procedure, you have access to all of the nodes. After running the flowgraph, a stored procedure and a task plan to run the batch is created. A batch task cannot be run in realtime.
Realtime Task
In realtime tasks, transactions are updated continuously. When the source is updated with a new or modified record, that record is immediately processed. After running a flowgraph, an initialization procedure and two tasks are generated. The first task is for the initial load, and the second task processes any new or updated data in the data source.
Transactional Task
In transactional tasks, transactions are updated continuously in realtime. When the source is updated with a new or modified record, that record is immediately processed. Unlike the realtime task, only a single task is generated to process any new or updated data in the data source. You cannot use a virtual table for transactional tasks. Use Table-Type as the input source.
Related Information
Reserved Words [page 171]Add a Variable to the Container Node [page 165] Activate and Execute a Flowgraph [page 170]
Administration Guide for SAP HANA smart data integration and SAP HANA Smart Data Quality (PDF)
5.2 AFL Function
Access functions of the Application Function Library.
Prerequisites
You have added an AFL Function node to the flowgraph.
Context
Use this node to model functions of the Application Function Library (AFL) that are registered with the system. AFL functions are grouped by function areas.
Note
You can retrieve the list of all AFL areas and functions registered in a HANA system by viewing the content of the views “SYS”.”AFL_AREAS” and “SYS”.”AFL_FUNCTIONS”.
Many AFL areas are optional components for HANA. For some of these optional components the SAP HANA Application Function Modeler (AFM) provides preconfigured node templates. In this case, the AFM automatically displays a separate compartment for this area in the Node Palette.
Note
Note
The AFL Function node is not available for real-time processing.
Procedure
1. Select the AFL Function node.
2. In the General tab in the Properties view, select the drop-down menus for Area and the Function.
The AFM changes the inputs and outputs of the node according to the existing meta-data for the function on the server.
Note
For some AFL areas there exists a preconfigured Node Palette compartment. You cannot change the Area
or the Function of a node added from one of these compartments. 3. If applicable, change the Category of the function.
4. Specify the inputs and the outputs of the function by editing the signature and the fixed content of its anchors.
Note
For some AFL areas there exists a preconfigured node template for this function. In this case, the fixed content of the inputs that define parameters is preconfigured.
Related Information
SAP HANA Business Function Library (BFL) SAP HANA Predictive Analysis Library (PAL)
5.3 Aggregation
An Aggregation node represents a relational group-by and aggregation operation.
Prerequisites
Note
The Aggregation node is available for realtime processing.
Procedure
1. Select the Aggregation node.
2. Map the input columns and output columns by dragging them to the output pane. You can add, delete, rename, and reorder the output columns, as needed. To multi-select and delete multiple columns use CTRL/ Shift keys, and then click Delete.
3. In the Aggregations tab, specify the columns that you want to have the aggregate or group-by actions taken upon. Drag the input fields and then select the action from the drop-down list.
4. (Optional) Select the Having tab to run a filter on an aggregation function. Enter the expression. You can drag and drop the input and output columns from the Elements pane, then drag an aggregation function from the
Functions pane. Click or type the appropriate operators. For example, if you want to find the transactions that are over $75,000 based on the average sales in the 1st quarter, your expression might look like this:
AVG("Aggregation1_Input"."SALES") > 75000.
Option Description
Avg Calculates the average of a given set of column values.
Count Returns the number of values in a table column.
Group-by Use for specifying a list of columns for which you want to combine output. For ex ample, you might want to group sales orders by date to find the total sales ordered on a particular date.
Max Returns the maximum value from a list.
Min Returns the minimum value from a list.
Sum Calculates the sum of a given set of values.
5. (Optional) Select the Filter Node tab to compare the column name against a constant value. Enter the expression by dragging the column names, the function, and entering the operators from the pane at the bottom of the node. For example, if you want to the number of sales that are greater than 10000, your expression might look like this: "Aggregation1_input"."SALES" > 10000. See the "SQL Functions" topic in the SAP HANA SQL and System Views Reference for more information about each function.
5.4 Case
Specifies multiple paths in a single node (the rows are separated and processed in different ways).
Route input records from a single source to one or more output paths. You can simplify branch logic in data flows by consolidating case or decision making logic in one node. Paths are defined in an expression table.
Note
The Case node is available for real-time processing.
General properties
Table 1: General options
Option Description
Name The name for the output target. This can be named the same as the input source.
Display name The name shown in the Palette pane.
Note
This option can only be changed when creating a template. It cannot be changed when us ing the node outside of a template.
Description (Optional.) Provides a comment about the operation. For example, "Splitting the information into North America and Europe."
Produce default output
Adds a default output target, such as a table. On the Default tab, specify the fields that should be included in the output. There can be one default output target only. If the record does not match any of the other output cases, it goes to the default output.
Row can be true for one case only
Specifies whether a row can be included in only one or in many output targets. For example, you might have a partial address that does not include a country name such as 455 Rue de la Marine. It is possible that this row could be output to the tables named Canada_Customer, France_Customer, and Other_Customer. Select this option to output the record into the first output table whose expression returns TRUE.
Leaving this option blank would put the record in all three tables.
Expression name Specify the name of the expression you are creating. Create multiple expressions to route the records the next node. For example, you might have an expression for "Marketing", "Finance", "Development" and the default expression might be for "Others". The default expression is used when all other Case expressions evaluate to false.
Expression The expression used for the Case node. Double click the cell in the table to open the Expres sion Editor. If you have multiple expressions, you can move them up or down in the list. The expressions are processed in order from top to bottom. See the "Using the Expression Editor" topic in the SAP HANA Developer Guide.
Mappings
The mappings tab shows how the input column names are mapped to output column names. If you have a large table, you can use Filter pattern to search for specific columns. See "Using the Mapping Editor" topic in the SAP HANA Developer Guide.
Input data
Select the input data General tab by clicking Input_<n>. Table 2: General
Option Description
Name The name of the input source. You can rename this source.
Kind Identifies the type of input source. For example, table, column, scalar. Table 3: Signature
Option Description
Name The column name in the input source. This can be named the same as the output from the previous node.
Type The type of data contained in the column, for example, Nvarchar, Decimal, Date, and so on.
Length The number of characters allowed in the column.
Scale The number of digits to the right of the decimal point. This is used when the data type is a deci mal.
Nullable Indicates whether the column can be null.
Use the Add, Remove, Up and Down buttons to edit the input fields accordingly. Table 4: Fixed Content
Option Description
Fixed Content Enable to have the input table of the node saved with the flowgraph file. Otherwise, it is placed in a separate table connected to the node. For more information, see the SAP HANA Developer Guide topic "Flowgraphs".
Output data
The Case node can output to one or more targets.
Select the output data General tab by clicking Output_<n>. Table 5: General
Option Description
Name The name of the output source. You can rename this source.
Kind Identifies the type of output source.
Table 6: Signature
Option Description
Name The column name in the input source. This can be named the same as the output from the previous node.
Option Description
Type The type of data contained in the column, for example, Nvarchar, Decimal, Date, and so on.
Length The number of characters allowed in the column.
Scale The number of digits to the right of the decimal point. This is used when the data type is a deci mal.
Nullable Indicates whether the column can be blank.
Use the Add, Remove, Up and Down buttons to edit the input fields accordingly.
Annotations
Create comments for users. For example, you might want to make a note of some particular settings in this flowgraph so that the administrator can schedule or understand certain customizations. The annotations are written to a table. See the "Application Function Modeler" section of the SAP HANA Developer Guide.
All
Shows all of the options in one screen. It includes, General, Mappings, and Annotations.
5.5 Cleanse
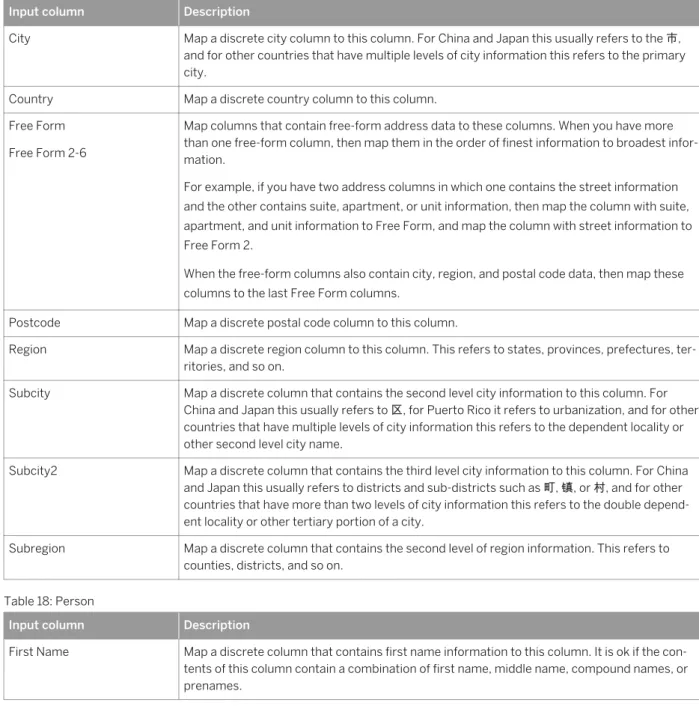
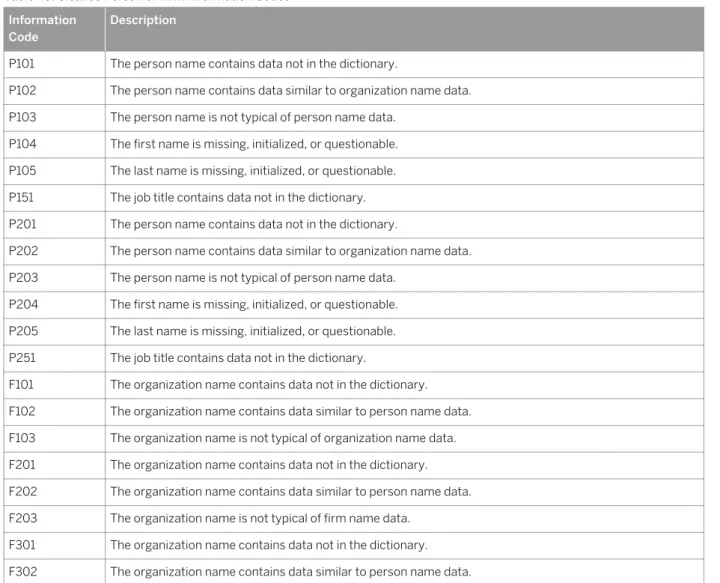
Identifies, parses, validates, and formats the following data: address, person name, organization name, occupational title, phone number, and email address.
Note
This topic applies to the Application Function Modeler tool in Hana Studio only.
Address reference data comes in the form of country-specific directories. For information about downloading and deploying directories, see “Smart Data Quality Directories” in the Administration Guide for SAP HANA Smart Data Integration and SAP HANA Smart Data Quality.
Only one input source is allowed.
Note
General Properties
Table 7: General options
Option Description
Name The name for the output target. This can be named the same as the input source.
Display name The name shown in the Palette pane.
Note
This option can only be changed when creating a template. It cannot be changed when us ing the node outside of a template.
Description (Optional.) Provides a comment about the operation. For example, "Cleanse customer data."
Input Fields tab
Use the Input fields tab to select and map your input data. Your input data might already be mapped to the output fields. You can check on the Input tab along the left side of the screen. If the fields are not mapped, or if you want to change the mapping, you can use the Input fields tab on the General properties panel to do so.
A list of the most common Cleanse input fields are listed in categories. Click Show Additional Fields to add more fields to the list. In the Address and Person categories, you can change the type of format based on how the data is contained in the fields based on whether the data is for addresses or people.
Format of input data Description
Composite Address: Use fields from this group when the input address data consists of fields with ad dress, city, region, and postal code data completely in free form. For example, the address data may reside in three fields that contain the various address elements fielded inconsis tently from one record to another. The order of mapping free-form fields is significant. See the description for mapping to the Free Form fields in the Cleanse Input Columns [page 53]
topic.
Person: Use the Person field from this group when the input data has a single field for person data. For example, the name John Louis Maxwell is in one Name field.
Discrete Address: Use fields from this group only when the input address data consists of fields from the SAP Business Suite data model. If your schema is similar to that of the SAP Business Suite, but not exactly, then you should use fields from the Hybrid group instead.
Person: Use fields from this group when the input data consists of two or more fields for per son data.
Hybrid Address: Use fields from this group when the input address data consists of one or more free-form fields for the street portion of the address, and discrete fields for city, region, and postal code. The order of mapping free-form fields is significant. See the description for mapping to the Free form fields in the Cleanse Input Columns [page 53] topic.
Person: Use fields from this group when the input data consists of one or more free-form fields and also has some additional information in one or more fields for the name data. For example, the column for First Name might contain only the first name for a person, such as John. The Last Name field might contain the last name with an honorary postname (such as Ph. D) or a maturity postname (such as Jr).
For all input fields, click in the Mapping column to select the input data that should be mapped to this field. If you have an input source connected to the Cleanse node, you will see the list of input fields in the Mapping list. See
Cleanse Input Fields [page 53].
Output Fields tab
The Output Fields tab in the General properties panel lists all of the available output fields for the Cleanse node. The Cleanse node can enrich your data when you select additional output fields. For example, it can include address assignment levels by changing the option in the Enabled column to True. See Cleanse Output Fields [page 55].
Settings tab
Use the Settings tab in the General properties panel to select your formatting preferences. Table 8: Email
Option Description
Casing Specifies the casing format.
Upper: Data is output in all capital letters. For example, JOHN.SMITH@MACARTHUR.COM. Lower: Data is output in all lowercase letters. For example, john.smith@macarthur.com Table 9: Phone
Option Description
N.A. Phone Format Specifies the format for North American phone numbers.
Parens: Separates the area code with parenthesis, and with one hyphen. For example, (800) 123-4567.
Periods: Separates all sections with periods. For example, 800.123.4567. Hyphens: Separates all sections with hyphens. For example, 800-123-4567. Table 10: Firm, Title, Person, and Person or Firm
Option Description
Diacritics Specifies whether to retain diacritical characters on output.
Include: Retains the diacritical characters. For example, Hernández or Telecomunicações São Paulo.
Remove: Replaces diacritical characters such as accent marks, umlauts, and so on with the ASCII equivalent. For example, Hernandez or Telecomunicacoes Sao Paulo.
Casing Specifies the casing format.
Mixed: Data is output in mixed case. For example, MacArthur Inc. Upper: Data is output in upper case. For example, MACARTHUR INC.
Option Description
Cleanse Domain When a country field is input to the Cleanse node, then the person, title, firm, and person-or-firm data is cleansed according to linguistic norms in the input country. Use this setting to se lect which language/region domain you want to use by default when cleansing data for re cords that have a blank country, or for all records when a country field is not available. If all input data is from one region, then select one domain. For example, for data in the United States and Canada, select EN_US | GLOBAL. If your data spans multiple linguistic regions, then select multiple domains, ordering them beginning with the domain that is most prevalent in your data. For example, for data in DACH (Germany, Austria, Switzerland), select DE | FR | IT | GLOBAL.
Select the domains you want to include.
● GLOBAL - Global (Required as the last domain listed.) ● AR - Arabic
● ZH - Chinese ● CS - Czech ● DA - Danish ● NL - Dutch
● EN_US - English (United States & Canada) ● EN_GB - English (United Kingdom & Ireland) ● EN_AU - English (Australia & New Zealand) ● EN_IN - English (India)
● FR - French ● DE - German ● HU - Hungarian ● ID - Indonesian ● IT - Italian ● JA - Japanese ● MS - Malay ● NO - Norwegian ● PL - Polish ● PT_BR - Portuguese (Brazil) ● PT_PT - Portuguese (Portugal) ● RO - Romanian ● RU - Russian ● SK - Slovak
● ES_MX -Spanish (Latin America) ● ES_ES - Spanish (Spain) ● SV - Swedish
● TR - Turkish ● ZH - Chinese
Option Description
Output Format When a country field is input to the Cleanse node, then the person, title, firm, and person-or-firm data is output according to cultural norms in the input country. Use this setting to select the cultural domain you want to use by default when cleansing data for records that have a blank country, or for all records when a country field is not available.
For example, when selecting one of the English domains, if you output person name data to discrete fields, the first name is output to First Name, the middle name to Middle Name, and the full last name to Last Name (nothing is output to Last Name 2), and if you output to the composite Person field, the name is ordered as first name - middle name - last name - matur ity postname - honorary postname with a space between each word. When selecting one of the Spanish domains, the output format is a little different. If you output to discrete fields, it outputs the paternal last name to Last Name and the maternal last name to Last Name 2. When selecting the Chinese domain, if you output to discrete fields, it outputs the given name to First Name and the family name to Last Name (nothing is output to Middle Name or Last Name 2). If you output to the composite Person field, the name is ordered as last name - first name without any spaces between the words.
The valid values are the same as Cleanse Domain, but you may only select one domain, and Global is not an option.
Table 11: Address
Option Description
Country
Identification Mode
Specifies what to do for addresses that are input without a country. This may be the result of the country field not being populated for all addresses, or because all addresses are from the same country and there is no country field because the country is assumed.
Assign: The Cleanse node attempts to determine the country by looking at the rest of the ad dress data. Select this option when there is a country field. This option also improves perform ance if the operation cache is used.
Constant: The Cleanse node does not attempt to determine the country. Instead, it uses the country provided in the Default Country setting. Because selecting this option results in per formance degradation, it is recommended that you attempt to assign country data so that the country name or country code for those addresses are input before the cleansing process.
Default Country When the Country Identification Mode is set to Assign, then the country selected in the Default Country is used for addresses that the Cleanse node can't determine the country. In this sce nario, it is considered a best practice to select NONE, unless you are certain all addresses with a blank country are from a single country. Selecting NONE also improves performance if the operation cache is used. When the Country Identification Mode is set to Constant, then the country selected in Default country is used for all addresses.
Diacritics Specifies whether to retain diacritical characters on output.
Include: Retains the diacritical characters. For example, Münchner Str 100.
Remove: Replaces diacritical characters with the ASCII equivalent. For example, Muenchner Str 100.
Casing Specifies the casing format.
Mixed: Data is output in mixed case. For example, Main Street South. Upper: Data is output in upper case. For example, MAIN STREET SOUTH.
Option Description
Street Formatting Specifies how to format the street data.
Abbr No Punctuation: Uses a shortened form of common address types (street types, direc tionals, and secondary designators) without punctuation. For example, 100 N Main St Ste 201. Abbr With Punctuation: Uses a shortened form of common address types with punctuation. For example, 100 N. Main St. Ste. 201.
Expand: Uses the full form of common address types. For example, 100 North Main Street Suite 201.
Expand Primary Secondary No Punctuation: Uses the full form of street type and directional, but abbreviates the secondary designator without punctuation. For example, 100 North Main Street Ste 201.
Expand Primary Secondary With Punctuation: Uses the full form of street type and directional, but abbreviates the secondary designator with punctuation. For example, 100 North Main Street Ste. 201.
Country Common: Uses the most common format of the country where the address is lo cated.
Region Formatting Specifies how to format the region name (for example, state or province). Abbreviate: Uses the abbreviated form of the region. For example, NY or ON.
Note
In some countries it is not acceptable to abbreviate region names. In those cases, the cleansed region is fully spelled out, even when you set the option to abbreviate. Expand: Uses the full form of the region. For example, New York or Ontario
Country Common: Uses the most common format of the country where the address is lo cated.
Postal Formatting Specifies how to format postal box addresses.
Note
In some countries it is not acceptable to fully spell out the form of the postal address. In other countries, it is not acceptable to include periods in the abbreviated form. In these cases, the cleansed addresses meet the country-specific requirements, even when you se lect a different option.
Abbr No Punctuation: Uses a shortened form of the postal address without punctuation. For example, PO Box 1209.
Abbr With Punctuation: Uses a shortened form of the postal address with punctuation. For ex ample, P.O. Box 1209.
Expand: Uses the full form of the postal address. For example, Post Office Box 1209. Country Common: Uses the most common format of the country where the address is lo cated.
Mappings
The mappings tab shows how the input column names are mapped to output column names. If you have a large table, you can use Filter pattern to search for specific columns. See "Using the Mapping Editor" topic in the SAP HANA Developer Guide.
Input data
Select the input data General tab by clicking Input_<n>. Table 12: General
Option Description
Name The name of the input source. You can rename this source.
Kind Identifies the type of input source, For example, table, column, scalar. Table 13: Signature
Option Description
Name The column name in the output source. This can be named the same as the output from the previous node.
Type The type of data contained in the column, for example, Nvarchar, Decimal, Date, and so on.
Length The number of characters allowed in the column.
Scale The number of digits to the right of the decimal point. This is used when the data type is a deci mal.
Nullable Indicates whether the column can be null.
Use the Add, Remove, Up and Down buttons to edit the input fields accordingly. Table 14: Fixed Content
Option Description
Fixed Content Enable to have the input table of the node saved with the flowgraph file. Otherwise, it is placed in a separate table connected to the node. For more information, see the SAP HANA Developer Guide topic "Flowgraphs".
Output data
One data target is allowed.
Table 15: General
Option Description
Name The name of the output target. You can rename this target.
Kind Identifies the type of output target. Table 16: Signature
Option Description
Name The column name in the input source. This can be named the same as the output from the previous node.
Type The type of data contained in the column, for example, Nvarchar, Decimal, Date, and so on.
Length The number of characters allowed in the column.
Scale The number of digits to the right of the decimal point. This is used when the data type is a deci mal.
Nullable Indicates whether the column can be null.
Use the Add, Remove, Up and Down buttons to edit the input fields accordingly.
Annotations
Create comments for users. For example, you might want to make a note of some particular settings in this flowgraph so that the administrator can schedule or understand certain customizations. The annotations are written to a table. See the "Application Function Modeler" section of the SAP HANA Developer Guide.
All
Shows all of the options in one screen. It includes, General, Mappings, and Annotations.