Quick and Secure Clustering Labelling for Digital forensic analysis
A.Sudarsana Rao
Department of CSE, ASCET, Gudur. A.P, India [email protected]C.Rajendra
Department of CSE ASCET, Gudur. A.P, India [email protected] ABSTRACT:In Digital forensic analysis Seized digital devices can provide precious information and evidences about facts and/or individuals on which the investigational activity is performed. In particular, algorithms for clustering documents can facilitate the discovery of new and useful knowledge from the documents under analysis. In that applies document clustering algorithms to digital forensic analysis of computers seized devices in police investigations. In the Digital forensic analysis investigate by carrying out extensive experimentation with clustering algorithms (K-means, K-medoids, Single Link, Complete Link, Average Link, and CSPA) applied in datasets. The proposed work involves investigating automatic approaches for cluster labelling. The assignment of labels to clusters may enable the expert examiner to identify the semantic content of each cluster more quickly— eventually even before examining their contents. Finally, the study of algorithms that induce overlapping partitions (e.g., Fuzzy C-Means and Expectation-Maximization for Gaussian Mixture Models) is worth of Investigation in Computer seized devices in digital forensic investigation.
Index Terms – Clustering, forensics analysis,
digital investigation.
INTRODUCTION:
In Digital evidence, as defined as the information and data of investigative value that are stored on, received, or transmitted by a digital device [1],[2], has become lately a crucial component in law enforcement agencies investigations. The relevance of this kind of evidence, collected when electronic data and devices are seized, is established by digital forensics analysts, which more and more often have to deal with massive amounts of data, still increasing with the capacity of mass storage devices.
In a more practical and realistic scenario, domain experts (e.g., forensic examiners) are scarce and have limited time available for performing examinations. Thus, it is reasonable to assume that, after finding a relevant document, the examiner could prioritize the analysis of other documents belonging to the cluster of interest, because it is likely that these are also relevant to the investigation [3]. Such an approach, based on document clustering, can indeed improve the
analysis of seized computers, as it will be discussed in more detail later.
Basically this is paper for the police investigations through forensic data analysis. Clustering algorithms are typically used for examining data analysis, where there is little or no prior knowledge about the data. This is exactly the case in several applications of Computer Forensics, including the one mention in this paper. [3] Clustering algorithms have been studied for decades, and the literature on the subject is huge. Therefore, we decided to choose set of (six) representative algorithms in order to show the potential of the proposed approach, namely: the partitional means [4] and K-medoids [5], the hierarchical single /Complete /Average Link [6], and the cluster ensemble algorithm known as CSPA [7]. These algorithms were run with different combinations of their parameters, resulting in sixteen different algorithmic instantiations, as shown in Table I. Thus, as a contribution of our work, we compare their relative performances on the studied application domain—using real-world investigation cases conducted by the Brazilian Federal Police Department. In order to make the comparative analysis of the algorithms more realistic, two relative validity indexes (Silhouette [5] and its simplified version [8]) have been used to estimate the number of clusters automatically from data.
Following table gives the various algorithms and their parameters. [3]
Acronym Algorithm Attributes Distance
Initializat
ion K-estimate
Kms K-means Cont.
(all) Cosine Random Simp.Sil. Kms
100 K-means 100>TV Cosine Random Simp.Sil. Kms
100* K-means 100>TV Cosine [18] Simp.Sil. KmsT
100* K-means 100>TV Cosine [18] Silhouette KmsS K-means Cont.
(all) Cosine Random Rec. Sil. Kms
100S K-means 100>TV Cosine Random Rec. Sil. Kmd
100
K-medoids 100>TV Cosine Random Silhouette Kmd
100*
K-medoids 100>TV Cosine [18] Silhouette Kmd
Lev
K-medoids Name Lev. Random Silhouette Kmd
LevS
K-medoids Name Lev. Random Rec. Sil. AL100 Average
Link 100>TV Cosine - Silhouette CL100 Complete
Link 100>TV Cosine - Silhouette
SL100 Single
Link 100>TV Cosine - Silhouette
NC CSPA Name,
Cont.(all) CSPA Random Simp.Sil. NC100 CSPA Name,
100>TV CSPA Random Simp.Sil. E100 CSPA Cont.100
random CSPA Random Simp.Sil.
Note: 100>TV: 100 attributes (words) that
the greatest variance over the documents Cont. 100 random: 100 randomly chosen attributes from document content
Cont. (all): all features from document distance Lev.: Levenshtein distance
Simp. Sil.: Simplified Silhouette
Rec. Sil.: “Recursive” Silhouette *: Initialization on distant objects Name: file name
As shown in table there are various algorithm with their parameters like distance which has cosine as well as levenshtein distance which is nothing but a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (i.e. insertions, deletions or substitutions) required to change one word into the other. The application for levenshtein distance is to in approximate string matching; the objective is to find matches for short strings in many longer texts, in situations where a small number of differences is to be expected. Table also gives the initialization of each algorithm. [1]
The remainder of this paper is organized as follows. Section II literature review Section III document clustering based techniques for forensic analysis Section IV. Implementation details V concludes the paper. Section VI gives references.
II LITERATURE REVIEW
The use of clustering has been reported by only few studies in the computer forensics field.[3] Basically, The use of classic algorithm for clustering data is described by most of the studies such as Expectation-Maximization (EM) for
unsupervised learning of Gaussian Mixture Models, K-means, Fuzzy C-means (FCM), and Self-Organizing Maps (SOM). These algorithms have well-known properties and are widely used in practice.[9]
Document Clustering for Forensic Analysis: An Approach for Improving Computer Inspection uses various algorithms and pre-processing technique for giving result as cluster data. Finally in their conclusion they have shown that, the approach presented by them applies document clustering methods to forensic analysis of computers seized in police investigations. Also, they are reported and discussed with several practical results that can be very useful for researchers and practitioners of forensic computing. More specifically, in their experiments the hierarchical algorithms known as Average Link and Complete Link presented the best results. Despite their usually high computational costs, they have shown that those algorithm are particularly suitable for the studied application domain because the dendrograms that they provide offer summarized views of the documents being inspected, thus being helpful tools for forensic examiners that analyze textual documents from seized computers.[3]
Role of Document Clustering in Forensic Analysis:
Computer forensic analysis involves the examining the huge set of files. Among
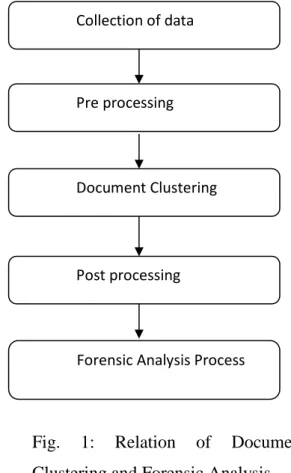
all of that files are not relevant to the forensic examiner interest. So analyzing such files and documents which are out of interest tends to more time consuming task. So the key approach is to apply document clustering [4] on such huge set of files and documents. As a result, these document clustering provides different set of clusters among which forensic examiner analyze only relevant documents related to investigation of reported case. It helps to improve speed of the forensic analysis process. It will also help for forensic examiner to analyze the files and documents by only analyzing representative of the clusters. The document clustering process involves the following phases as shown in Fig. 1:
1. Collection of Data:
Collection of data involves the processes like acquiring the files and documents from the computer seized devices. The collection of such files and documents involves special techniques.
2. Pre processing:
As discussed earlier pre processing involves the tokenization, removing of stop words, stemming process and weighted matrix construction phases.
3. Document Clustering:
After the pre processing document clustering is applied to form the set of clusters according to specified clustering criteria. 4. Post processing:
It is used for application such as forensic analysis in which clustering results are used for further analysis.
5. Forensic Analysis:
As discussed in post pre processing forensic analysis process uses the result of document clustering for further analysis. The result of document clustering enhances the forensic process within sake of time. Hence, this clearly specifies the role of document clustering in the process of forensic analysis.
Fig. 1: Relation of Document Clustering and Forensic Analysis
III Document Clustering Based
Techniques for Forensic Analysis:
S.Oliver [10] proposes Self Organizing Maps (SOM) to support decision making by forensic investigators. Self
Collection of data
Pre processing
Document Clustering
Post processing
Forensic Analysis Process
Organizing Maps (SOM) is basically used to search the pattern in data set. The files are clustered according to date and time of creation and type of files. So it’s an easy task for the forensic investigator for the analysis once he got specified pattern. R. Hadjidj [9] proposes email forensic analysis tool based on document clustering technique. It provides automated tool for multi-staged
analysis of e-mail for the forensic
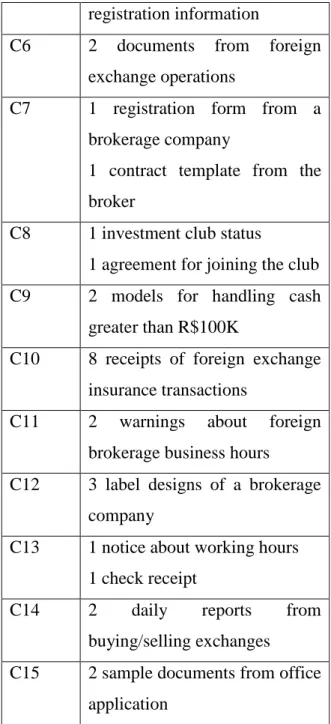
investigator which helps to gather the evidences related to crime in the court of law. This also notifies the document clustering role in the forensic investigation. Recently, Nassif and Hruschka [3] proposed an approach that applies document clustering algorithms for the forensic analysis of computer devices. They uses the relative validity index criteria for the estimating the number of clusters in an automated manner which overcomes the limitations previous techniques. Here the forensic examiner can analyze only relevant clusters documents in accordance with reported case. The results [3] are as shown in Fig. 3.
Cluster Information
C1 3 black documents
C2 4 financial transactions
C3 2 maternity payments
C4 2 grocery lists
C5 1 foreign exchange transaction
warning
1 list of documents for
registration information
C6 2 documents from foreign
exchange operations
C7 1 registration form from a
brokerage company
1 contract template from the broker
C8 1 investment club status
1 agreement for joining the club
C9 2 models for handling cash
greater than R$100K
C10 8 receipts of foreign exchange
insurance transactions
C11 2 warnings about foreign
brokerage business hours
C12 3 label designs of a brokerage
company
C13 1 notice about working hours
1 check receipt
C14 2 daily reports from
buying/selling exchanges
C15 2 sample documents from office
application
Fig. 3: Document Clustering for Forensic Analysis
Fuzzy Methods for Forensic Data Analysis is again describes a methodology and an automatic procedure for inferring accurate and easily understandable expert-system-like rules from forensic data. In most data analysis environments the methodology and the algorithms used were proven to be easily implementable. By discussing the
applicability of different fuzzy methods to improve the effectiveness and the quality of the data analysis phase for crime investigation the fuzzy set theory would get implemented.[11]
IV IMPLEMENTATION DETAILS:
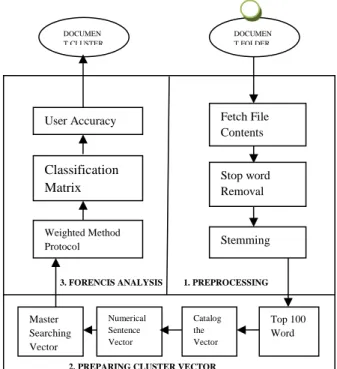
IV.I Architectural Diagram of Proposed System:
The proposed system shown in figure 2
Fig. 2: Architectural diagram of proposed
system in our propose system
Basically there are three important steps which are as follows
1) Pre-processing
2) Preparing cluster vector 3) Forensic analysis
1) Pre-processing- In pre-processing step
there are three steps such as a) fetch a file contents, b) stop word removal c) stemming. In all the above steps the basic purpose is to check the file contain and to remove the stop word like a, an ,the etc. and later on to do stemming on that file which will be removing ing and ed words from the given statement.
2) Preparing Cluster Vector- For preparing
the cluster vector one will need to find top 100 words from the file on which pre-processing step is already done. Now from that document or rather way we can say file or data numerical sentences such as the sentence which has numerical word in it that means the sentence which contains date or any kind on number in it.
3) Forensic Analysis- This will be the last
step of proposed method. From the diagram no 1 mention above one can say that for the forensic data analysis classification matrix need to be made with the help of weighted method protocol. At last one can find accuracy of his work.
V CONCLUSIONS AND FUTURE
WORK
By doing the survey on digital
forensic analysis it can be concluded that clustering on data is not an easy step. There is huge data to be cluster in compute forensic so to overcome this problem, this paper presented an approach that applies document clustering methods to digital forensic
DOCUMEN T CLUSTER
DOCUMEN T FOLDER
3. FORENCIS ANALYSIS 1. PREPROCESSING
2. PREPARING CLUSTER VECTOR
User Accuracy Classification Matrix Weighted Method Protocol Fetch File Contents Stop word Removal Stemming Top 100 Word Master Searching Vector Numerical Sentence Vector Catalog the Vector 821 www.ijaegt.com
analysis of computers seized in police investigations. Again by using labelling there will be document clustering for forensic data which will be useful for police investigations.
VI REFERENCES:
[1] U.S. Department of Justice, Electronic Crime Scene Investigation: A Guide for First Responders, I
Edition, NCJ 219941, 2008, http://www.ncjrs.gov/pdffiles1/nij/219941.pdf
[2]. J. Clerk Maxwell, A Treatise on Electricity and Magnetism(3rd ed., vol. 2. Oxford: Clarendon, 1892, pp.68–73).
[3]. Luis Filipe da Cruz Nassif and Eduarado Raul Hruschka “Document Clustering for Forensic Analysis: An Approach for Improving Computer
Inspection”- ieee transactions on information
forensics and security, vol., no. 1, january 2013. [4] A. K. Jain and R. C. Dubes, Algorithms for Clustering Data. Englewood Cliffs, NJ: Prentice-Hall, 1988.
[5] L. Kaufman and P. Rousseeuw, Finding Groups in Gata: An Introductionto Cluster Analysis. Hoboken, NJ: Wiley-Interscience, 1990.
[6] R. Xu and D. C.Wunsch, II, Clustering. Hoboken, NJ: Wiley/IEEE Press, 2009.
[7] A. Strehl and J. Ghosh, “Cluster ensembles: A knowledge reuse framework for combining multiple partitions,” J. Mach. Learning Res., vol.3, pp. 583– 617, 2002.
[8] E. R. Hruschka, R. J. G. B. Campello, and L. N. de Castro, “Evolving clusters in gene-expression data,” Inf. Sci., vol. 176, pp. 1898–1927, 2006.
[9]. R. Hadjidj, M. Debbabi, H. Lounis, F. Iqbal, A. Szporer, and D. Benredjem, “Towards an integrated e-mail forensic analysis framework,” Digital
Investigation, Elsevier, vol. 5, no. 3–4, pp. 124–137, 2009.
[10] B. K. L. Fei, J. H. P. Eloff, H. S. Venter, and M. S. Oliver, “Exploring forensic data with self-organizing maps,” in Proc. IFIP Int. Conf. Digital Forensics, 2005, pp. 113–123.
[11]. K. Stoffel, P. Cotofrei, and D. Han, “Fuzzy methods for forensic data analysis,” in Proc. IEEE Int. Conf. Soft Computing and Pattern Recognition, 2010, pp. 23–28.