International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
216
Comparative Study on Automatic Image Annotation
Dhatri Pandya
1, Prof. Bhumika Shah
21PG Student, Sarvajanik College of Engineering and Technology, Surat, India
2Prof.Bhumika Shah, Sarvajanik College of Engineering and Technology, Surat, India
Abstract— With the detonative development of internet technologies in the web huge amount of images are available on the web. Large amount of research has been carried out on image retrieval since last few years. There is need for efficient and viable procedure to find visual information on demand. Recent research shows that there is semantic gap between low level features of image and semantic concepts understood by the humans. Handling large volumes of digital information become vital as online resources and their usage continuously grows at high speed online image sharing applications are getting extremely popular. This shows the potential of these online image collections and the need to search them on the basis of words. So to enhance the image retrieval results annotation is required as label associated with image
represents the semantic information associated with it. The
traditional approach for assigning relevant keywords to image is manual annotation in which images are annotated manually by humans but the manual annotation is labor intensive and time consuming. To overcome this problem and to bridge the semantic gap between low level concepts of image and semantic concepts understandable by humans approach is presented that automatically annotated the image which is called automatic image annotation. In this paper we have focus on various approaches for automatic image annotation. The analysis and key aspects of automatic image annotation is also presented. This paper also aims to cover automatic tagging challenges and future directions related to it.
Keywords— Automatic Image Annotation (AIA), Content Based Image Retrieval (CBIR), Probabilistic Model, Support Vector Machine, Artificial Neural Network, Gaussian Mixture Model
I. INTRODUCTION
One of the significant ideas to bridge the semantic gap is to annotate the image which simplifies the image retrieval. In general, research efforts on image retrieval can be distributed into three types of approaches [1].The first approach is the traditional text based annotation. In this approach, images are annotated manually by humans and images are then retrieved in the same way as text documents. It is impractical to annotate large amounts of image manually as it is time consuming and expensive. Also human annotations are too subjective and vague. The second type of approach centers on content based image retrieval (CBIR), where images are automatically indexed
and retrieved with low level content characteristics like color, shape and texture.
However, recent research has shown that there is a significant gap between the low level content features and semantic concepts used by humans to interpret images. In addition, it is impractical for general users to use a content based image retrieval (CBIR) system because it furnishes users to provide query images. The third approach of image retrieval is the Automatic Image Annotation (AIA) so that images can be retrieved same as the text documents and extracts semantic features using machine learning techniques. In general, the image annotation refers to process of assigning relevant keywords to the image to bridge the semantic gap betweenlow level content features and semantic concepts understand by the humans. The basic purpose of automatic image annotation is to improve image retrieval accuracy which will reduce the irrelevant images in image retrieval system. The main objective of this work is to analyze and compare various approaches of automatic image annotation. This paper is organized as follows. Section II covers the basic concept of automatic image annotation. Section III reviews the basic approaches to automatic image annotation. Section IV discusses the comparison of various approaches of automatic image annotation. Section V covers the automatic tagging challenges. Section VI covers the evaluation of annotation effectiveness using various metrics.Section VII summarizes the various dataset available for automatic image annotation.
II. CONCEPT OF AUTOMATIC IMAGE ANNOTATION
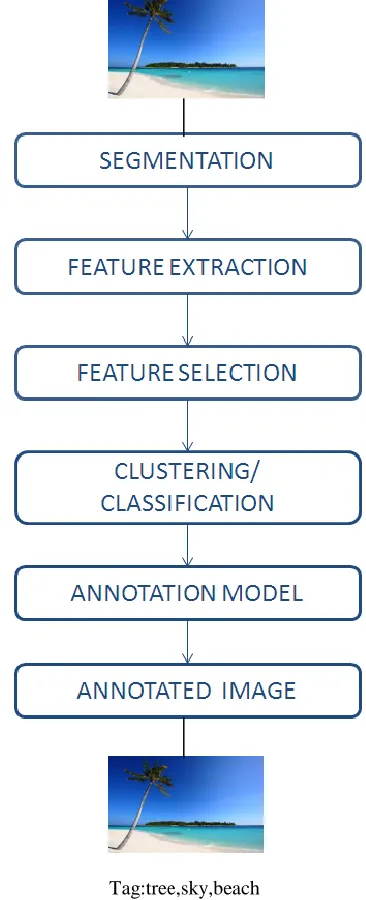
Automatic Image Annotation has been active research topic in the last few years due its high impact on the Web search. To simplify the image retrieval metadata is added to images by an automatic image annotation. The general framework of automatic image annotation is shown in Figure 1 which includes the following steps:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
217 There are various approaches for image segmentation such as region based and edge based approach.
(2) Feature Extraction: Low level visual information from segmented image is extracted using various feature descriptors like color, texture, shape. Color and texture are the most expressive to extract visual features of image [9].
(3) Feature Selection: It refers to the reducing high dimensional feature space to low dimensional feature space by using statistical techniques such as Principal Component Analysis and Particle Swarm Optimization Algorithm[15][16].
(4) Clustering/Classification: In this step the group of feature vectors is formed depending on efficient clustering techniques such as k means, fuzzy clustering [16] clustering partitions the group of feature vector based on some specified common features and various similarity measures for image retrieval. The classification techniques such as k nearest neighbor, SVM, Decision Tree can also be used for grouping of feature vectors based on some predefined class label [1].
(5) Annotation Model: In this step annotation of testing image is done on the annotation model chosen such that labels are transferred from training to test images based on the annotation model specified used for the annotation of the image. Annotate the image based on annotation model such as probabilistic model, classification model, nonparametric approach or graph based approach.
III. APPROACHES FOR AUTOMATIC IMAGE ANNOTATION
Automatic Image annotation can be classified into four approaches: Probabilistic Modeling, Classification, Graph Based, Parametric approach.
A. Probabilistic modelling approach
In this approach annotation of image is done by estimating the joint probability of an image with a set of words. Duygulu et al [7] make use of the statistical machine translation model and applied the EM (Expectation Maximization) algorithm to learn a maximum likelihood association of words to image regions using a bi-lingual corpus.. The pre-processed COREL data-set made available by Duygulu et al [7] has become a widely used and popular benchmark of annotation systems in the literature.The main essence of the algorithm is that it utilizes the probability table to estimated correspondences and using it to refine the estimate of the probability table. It annotates the image by partitioning the segments into blobs and finding the association of words and blobs by selecting the words with highest probability.
[image:2.612.357.540.153.603.2]Tag:tree,sky,beach
Figure 1.Concept of Automatic Image Annotation
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
218 grid segmentation and feature extraction is done using color and texture characteristics of image. Each training image has many annotations .This approach focuses on the presence or absence of words in the annotation rather than its importance. It does not rely on clustering and models continuous features.
Mori et al. [7] proposed a Co-occurrence Model which is based on the co-occurrence of words with image regions created using a regular grid. The annotation process began by partitioning images into rectangular tiles of the same size. Then, for each tile, a feature descriptor which was fusion of color and texture is calculated [9]. All the descriptors were then clustered into a number of groups which is represented by the centroid. Each tile inherited the whole set of labels from the original image. Then, the estimation of the probability of a label related to a cluster by the co-occurrence of the label and the image tiles within the cluster is done.
Wang et al [6] proposed progressive model to approximate the joint probability of words in for a given an image, the word with highest probability is first annotated.
Then, the successive words are annotated by incorporating the information of previously annotated words. In this model joint probability of words is calculated on basis of greedy algorithm.
B. Classification Based Approach
In this approach, low level features are extracted from image content, and the features are fed directly into a conventional binary classifier which gives a yes or no vote. The common machine learning tools include Support Vector Machine (SVM), Artificial Neural Network (ANN), and Decision Tree (DT).
Automatic image annotation using Support Vector Machine
The mechanism of SVM classifier works by finding a hyper plane from a training set of samples to separate them. Feature vector and class label is associated with each training sample. An SVM is basically a binary classifier. The output of the classifier is the semantic concept(s) which is used for image annotation [1] The aim is to define a Hyper plane which partitions the set of examples such that all the points with the same label are on the same side of the hyper plane [12][1].Chapelle et al [12] use the above mentioned basic framework to train 14 SVM classifiers for 14 image level concepts. Images are represented with HSV histogram..To train an SVM for a particular concept, training images belonging to that concept are regarded as positive instance while the others are regarded as negative instance. Therefore, each trained classifier can be regarded as one vs. all ’classifier. During testing, each classifier
generates a probabilistic decision. The class with maximum probability is selected as the concept of the test image.
Automatic image annotation using Artificial Neural Network
An Artificial neural network (ANN) is a learning network that can learn from examples and can make decision for a new sample. An ANN consists of multiple layers of interconnected nodes, which are also known as neurons or perceptions. The first layer is the input layer which has neurons equal to the dimension of input sample. The number of neurons in the output layer is equal to the number of classes.
The performance results of automatic image annotation is highly affected by the segmentation results so to avoid prior segmentation Zhao et al [10] proposed an approach called, latent semantic analysis (LSA) based neural network (NN) annotation scheme. The annotation scheme is comprises of three parts. First, LSA is introduced to reveal the latent contextual correlation among the keywords.
Second, with the labelled training images, Neural Network is obtained for characterizing the hidden association between the visual content of the image and the textual keyword. Third, given a test image, the learnt Neural Network is able to effectively provide the keywords to be annotated.
Automatic Image Annotation Based On Decision Tree
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
219 Simple Decision Tree (SDT) classification algorithm, to improve the decision tree algorithm, which calculate model by the heuristic search of model space for fast decision tree algorithm. To label a new sample, the tree is traversed from the root node to a leaf node using the attribute value of the new sample. The decision of the sample is the outcome of the leaf node where the sample reaches. Decision Tree algorithm is easy to interpret and understand and can learn with small number of samples. It is also robust for incomplete and noisy data. The advantage of this type of approach is that the retrieval is efficient as there is no need to do image indexing and expensive online matching as in other IR approaches. The disadvantage of this type of approach is that it does not consider the fact that many images belong to multiple categories [1].
C. Parametric Approach
In this approach, the feature space is assumed to follow a certain type of known continuous distribution.
The conditional probability p(x|c) is modelled using multivariate Gaussian distribution where x and c are mean and concept label associated with feature vector. Both Li and Wang [13] and Carneiro et al [14] learn the conditional probability models concept by concept and then use the models to annotate unknown images. Li and Wang [13] first break down training images in each concept into regions which are represented using LUV colours and wavelet texture features. They then cluster regions into clusters which they call prototypes. For each prototype, a Gaussian model is learned. Finally, a Gaussian Mixture Model (GMM) is built for each concept by averaging the Gaussian model so find individual prototypes within the concept .To annotate an unknown image, its region features are extracted and the posterior probability of the image belonging to a concept is computed based on the concept GMM model. The drawback of this method is that parameter estimation for the Gaussian models is complex.
Carneiro et al [14] do not segment images into regions. Instead, they assume that image features follow certain Gaussian distributions and directly learn a GMM for each training image within a model using expectation maximization (EM) algorithm. This is equivalent to a simultaneous segmentation and model learning process. They then build the concept GMM by averaging the individual GMMs contained by the concept. In the annotation stage, a GMM is learned for the unknown image and the GMM is then matched with each one concept model. The concepts with the finest match are selected as the annotations for the unknown image.
D. Graph Based Approach
Liu et al [8] projected an approach for AIA using image based graph learning and word based graph learning. For a given the annotated training set and the visual features of all the images, the image-based graph learning aims to propagate labels from the annotated images to the un-annotated images by their visual similarities. The labelling matrix is another necessary component during the graph learning. The image-based graph learning only focuses on the visual similarities among images, while the word correlations are not analyzed. Two words with high co-occurrence in the training set will lead to high probability to annotate certain image jointly, such as `cloud' and `sky', `water', and `fish'. Therefore, the word co-occurrence becomes an informative representation of the word correlation. To better capture the complex distribution of the image data, the Nearest Spanning Chain-based technique was proposed to construct the image-based graph.
The word-based graph learning was performed by exploring three kinds of word correlations. One is the word co occurrence in the training set, and the other two are derived from the web context.
IV. COMPARISON OF AUTOMATIC IMAGE ANNOTATION
[image:4.612.322.564.462.714.2]APPROACHES
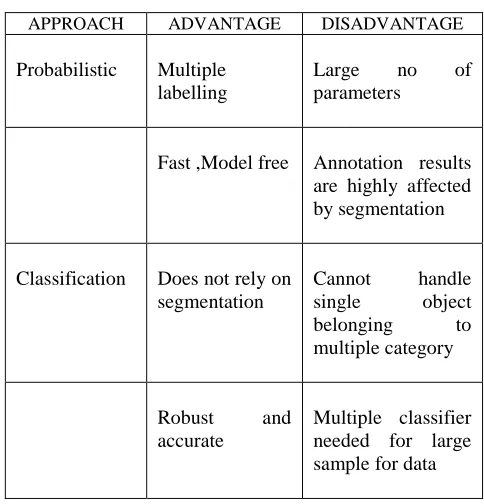
TABLE I
COMPARISON OF AIA APPROACH
APPROACH ADVANTAGE DISADVANTAGE
Probabilistic Multiple labelling
Large no of parameters
Fast ,Model free Annotation results are highly affected by segmentation
Classification Does not rely on segmentation
Cannot handle single object belonging to multiple category
Robust and accurate
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
220 Parametric Does not rely on
segmentation
Estimation of the parameters is complex
Multilabelling Training time is expensive
Graph Parameters are easy to tune
Does not consider the correlation between words
V. AUTOMATIC IMAGE TAGGING CHALLENGES
There are several major issues in AIA research. The first issue is high dimensional feature analysis. Currently, all existing features have limitations of describing images and none of existing features is influential enough to represent the huge variety of images in nature. The general practice is to combine numerous types of features to represent as many images as possible. However, the processing and analysing of high dimensional image features is a very complex issue. Due to the ‘curse of dimensionality’, the performance of classifiers degrades dramatically when feature dimension is too high. [1]Therefore, features need to be further mined to select the right number of features and right features for annotation. The recent advance in subspace research offers promising solution in this regard [1].
The second issue is how to build and effective annotation framework. Therefore, textual information or metadata should be employed to improve annotation accuracy. However, very often, metadata is either not accurate or not adequate.To integrate both low level visual information and high level textual information into a consistent annotation model is a challenging issue.
The third issue is that currently annotation and ranking are done simultaneously this is not efficient for image retrieval. The alternative is to do the annotation offline and separate the ranking from annotation, that is, images are first annotated with a concept/category and ranking is also done offline after annotation. Once the images are annotated and ranked offline, retrieval is instant.
The fourth issue is how to rank images within each of the categories resulted from the single labelling techniques, so as to get better retrieval accuracy.
The fifth issue is the lack of standard vocabulary and categorization for annotation.
The sixth issue is to filter irrelevant keywords assigned to image.
The seventh issue is to use efficient similarity measure based on image conceptual semantic representation between images.
Finally, there is no commonly acceptable image database for AIA training and evaluation. All AIA methods require a large number of pre-labelled image samples for training the model. Different AIA methods use different image datasets for training and evaluation, making it difficult to compare the performance.
The database issue is strongly related to the taxonomy issue. If a standard taxonomy of image semantics is available, a standard database can also be created accordingly. All these issues point to future research directions in AIA area [1].
VI. EVALUATION OF AUTOMATIC IMAGE ANNOTATION
EFFECTIVENESS
Once the test images are labelled by auto-annotation systems, annotation qualities need to be assessed for performance comparisons between different systems. A number of evaluation metrics have been used by researchers, some of which are introduced in the below section
.
A. Precision and Recall
The most popular metrics for comparing different information retrieval systems precision and recall are also widely adopted for evaluating the effectiveness of auto-annotation approaches. In the information retrieval community, precision of a query is defined as the ratio of the number of relevant documents that are returned by the system to the total number of documents returned, and recall is defined as the ratio of the number of relevant documents returned to the total number of relevant documents in the database [17]. There are two versions, per-image based and per-word based in automatic image annotation approaches to evaluate its effectiveness.
B. Per-image Precision and Recall
ground-International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
221 truth or manual annotations. Mathematically, they are calculated as follows [17].
Per Image Recall =r/n
where:
r : the number of correctly predicted words
n : the number of manual labels in the test
image
w : the number of wrongly predicted words
Per-image precision and recall values are averaged over the whole set of test images to generate the mean per-image precision and recall.
C. Per-word Precision and Recall
Duygulu et al [7] used mean per-word precision and recall to evaluate their annotation effectiveness. Per-word precision and recall are calculated on the basis of each keyword in the vocabulary. Specifically, precision is defined as the number of images correctly predicted with a given word, divided by the total number of images predicted with this word. Recall is defined as the number of images correctly predicted with a given word, divided by the total number of images having this word in its ground-truth or manual annotations. The values of precision and recall are averaged over the words in the vocabulary to generate the mean per-word precision and recall.
D. Keyword Number with Recall>0
Duygulu et al [7] also used the keyword number with recall>0 to show the diversity of correct words that can be predicted by the automatic image annotation.
VII. ANNOTATED DATASET
The wide varieties of dataset are available for doing research on automatic image annotation. Each dataset has various categories of images with total no of keywords specified for its dataset.The summary of various dataset with no of keywords contained in its visual dictionary and image category for each dataset is listed in table 2.
TABLE 2:
DATASET AVAILABLE FOR AIA
Dataset No of
keyword
Image Category
PASCAL VOC challenge 2005 databases[18]
101 Motorbike, people Cars, bicycle Li and Wang [19] 433 Natural Scene
Corel5K[3][7] 371 Natural Scene
IAPRTC12[[3]2] 291 Sports, Action
ESPGAME[3][2] 269 Sports
LABELME[22] Depends on the object category
Car,person,building,static street indoor and outdoor, village
VIII. CONCLUSION
Automatic Image Annotation is a promising methodology for indexing and image retrieval. In this paper review on various approaches of automatic image annotation and its comparison is discussed. The paper also focused on various metrics used for measuring the annotation effectiveness and Dataset available for automatic image annotation.Thus to enhance the image retrieval results various approaches of automatic image annotation can be applied depending on the image dataset and irrelevant images will be reduced in the image retrieval.The performance of the annotation model can be verified by annotation based image retrieval and applying ranking on the image and filitering noisy keywords assigned to the image and calculating the precision and recall measure for the image.
REFERENCES
[1] D. Zhang, Md. M. Islam, G. Lu, 2012. “A review on automatic image annotation techniques”, Pattern Recognition, vol. 45, no. 1, pp. 346–362.
[2] Manaf, S.A, Nordin, Md Jan, 2009. "Review on statistical approaches for automatic image annotation," Electrical Engineering and Informatics, ICEEI '09. International Conference on , vol.01, no., pp.56,61.
[3] A. Makadia, V. Pavlovic, and S. Kumar, 2008. “A new baseline for image annotation,” Proceedings of European Conference of Computer Vision, pp. 316-329.
[4] J. Jeon, V. Lavrenko, R. Manmatha,2003. "Automatic Image Annotation and Retrieval using Cross-Media Relevance Models", 26th Annual Int. ACM SIGIR Conference, Toronto, Canada. [5] S.L. Feng, R. Manmatha, V. Lavrenko,2004. Multiple Bernoulli
relevance models for image and video annotation, in: Proceedings of the CVPR04, pp. 1002–1009.
[6] Bin Wang; Zhiwei Li; Nenghai Yu; Mingjing Li,2007. "Image Annotation in a Progressive Way," IEEE International Conference on Multimedia and Expo, vol., no., pp.811-814.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
222
image vocabulary", In Seventh European Conference on Computer Vision (ECCV), Vol. 4, pp. 97-112.
[8] J. Liu, M. Li, Q. Liu, H. Lu, and S. Ma, 2009.“Image annotation via graph learning,” Pattern Recogn., 42(2), ,pp. 218-228
[9] Manjunath, B.S.,Ohm, J.-R., Vasudevan, V.V.; Yamada, A.,2001. "Color and texture descriptors," Circuits and Systems for Video Technology, IEEE Transactions on , vol.11, no.6, pp.703,715. [10] Yufeng Zhao,Yao Zhao, Zhenfeng Zhu; Jeng-Shyang Pan, 2008."A
Novel Image Annotation Scheme Based on Neural Network," Intelligent Systems Design and Applications, ISDA '08. Eighth International Conference on, vol.3, no., pp.644, 647.
[11] Shaohua Wan,2011."Image Annotation Using the Simple Decision Tree," Management of e-Commerce and e-Government (ICMeCG), 2011 Fifth International Conference on , vol., no., pp.141,146. [12] Chapelle, O, Heffner, P., Vapnik, V.N.,1999. "Support vector
machines for histogram-based image classification," IEEE Transactions on Neural Networks, vol.10, no.5, pp.1055, 1064. [13] J. Li, J.Z. Wang, Real-time computerized annotation of pictures,
IEEE PAMI 30 (6) (2008) 985–1002.
[14] G. Carneiro, A.B. Chan, P.J. Moreno, N. Vasconcelos, Supervised learning of semantic classes for image annotation and retrieval, IEEE PAMI 29 (3) (2007) 394–410.
[15] Fengxi Song; Zhongwei Guo; Dayong Mei, 2010. "Feature Selection Using Principal Component Analysis," System Science, Engineering Design and Manufacturing Informatization (ICSEM), 2010 International Conference on, vol.1, no., pp.27,30.
[16] Jafar, O.A.M., Sivakumar R., 2012."A study on fuzzy and particle swarm optimization algorithms and their applications to clustering problems," IEEE International Conference on Advanced Communication Control and Computing Technologies (ICACCCT), vol., no., pp.462,466.
[17] T. Jiayu,2008 “Automatic Image Annotation and Object Detection,” PhDthesis, University of Southampton, United Kingdom.
[18] M. Everingham, A. Zisserman, C. Williams, L. Van Gool, M. Allan, C. Bishop, O. Chapelle, N. Dalal, T. Deselaers, G.Dorko, S. Duffner, J. Eichhorn, J. Farquhar, M. Fritz, C.Garcia, T. Griffiths, F. Jurie, D. Keysers, M. Koskela, J. Laaksonen, D. Larlus, B. Leibe, H. Meng, H. Ney, B.Schiele, C. Schmid, E. Seemann, J. Shawe-Taylor, A.Storkey, S. Szedmak, B. Triggs, I. Ulusoy, V. Viitaniemi,J. Zhang,2006. The 2005 PASCAL visual object classes challenge,in: Selected Proceedings of the 1st PASCAL Challenges Workshop, Springer, Berlin.
[19] J. Li, J.Z. Wang,2003. Automatic linguistic indexing of pictures by a statistical modeling approach, IEEE Transaction on Pattern Analysis and Machine Intelligence 25 (9) (2003)1075–1088.
[20] http://eureka.vu.edu.au/_grubinger/IAPR/TC12 Benchmark.html [21] http://www.espgame.org