2017 2nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017)
ISBN: 978-1-60595-485-1
Deep Center Supervised Hash for Fast
Image Retrieval
MINGMU CHEN, JING FAN, JINSHUAI QU, LANLAN ZHANG and YUEPING LI
ABSTRACT
With the rapid growth of image data, the current mainstream image retrieval method uses the handcraft visual feature coding, which lack of learning ability, resulting in its image expression is not strong, and the large visual feature dimension which seriously restricting its image retrieval performance. The basic idea of this paper is to learn the hash center of each class, so that the distance of intra-class is closer in Hamming space, while maintaining the Hamming distance between the inter-class. Firstly, the deep implicit relationship of the training image is extracted by using the robust learning ability of the CNN, and enhance the distinguishing and expressive ability of the image hash feature. In particular, we have designed a CNN architecture in which a hash layer is added to encourage the input image to approximate discrete value (e.g. +1/-1). At the same time, we have carefully designed a hash center loss function, so that the distance between the intra-class to disperse, closer within the intra-class distance, and simultaneously imposing regularization on the real-valued outputs to approximate desired discrete values. We have conducted evolution on CIFAR-10 and NUS-WIDE images benchmarks, demonstrating that our approach can provide superior image search accuracy than other state-of-the-art hashing methods.
KEYWORDS
Image retrieval, Convolutional neural networks, Hashing learning, Hash center loss, Deep learning.
INTRODUCTION
With the arrival of big data era, the rapid growth of Internet image resources, how to large-scale image resources for rapid and effective retrieval to meet the demands of users need to be resolved. Image retrieval technology has developed from early text-based image retrieval for content-text-based image retrieval. Content-text-based image retrieval by extracting the image low level feature to representation image content. The visual
_________________________________________
low level feature include gradient-based image local feature descriptors, for example, SIFT [1] and HOG [2] etc. Compared with the hand-crafted features, the deep convolution neural network can obtain the inherent feature of the image, and it shows good performance in object detection [3], image classification [4-6], face classification [7] and image segmentation [8].
Utilized the deep convolution neural network to learn feature of the image, [5] first proposed an extraction image features of the framework, and in the ImageNet dataset to achieve a good performance.
For large-scale data retrieval, hashing approach is widely used in computer vision, machine learning, information retrieval and other related fields. In order to perform fast and efficient retrieval in large-scale image datasets, the hash technique embeds the high-dimensional features of the image to similarly the compact binary hash code. Due to the high efficiency of binary hash codes in Hamming distance calculation and the advantages of storage space, hash codes are very efficient in large-scale image retrieval. However, the retrieval performance of many existing hash methods is heavily dependent on the feature they use, which are basically extracted in an unsupervised manner, thus more suitable for dealing with the visual similarity search rather than semantic similarity search. On the other hand, the aforementioned of CNNs various task, the CNNs can be viewed as a feature extractor guided by the cost function which is designed for a particular task. CNNs gives us an indication of the success of each visual task, which it can capture the underlying semantic features of the image, although the appearance of the image is significantly different. So, there were several techniques based on deep models [9, 10] being proposed for addressing the problem of hashing.
Loss: *CenterLoss *SoftmaxLoss
Binarization Training
Images
Retrieval Image
Conv1 5X5X32/1
Conv1+ 5X5X32/1
MAX Pooling 2X2X32/2
Conv2 5X5X64/1
Conv2+ 5X5X64/1
AVE Pooling 2X2X64/2
Conv3 5X5X128/1
Conv3+ 5X5X128/1
AVE Pooling 3X3X128/2
Fully Connected
500
Binary‐like Outputs
k
Figure 1. Summarize the framework of our proposed method for hashing. The network is composed of three convolution-convolution-pooling layers followed by three fully connected layers, where the
second layer is the hash code layer. The convolution layers use 322, 642, and 1282 with 55 filters with stride 1 respectively, and pooling is performed over 33 windows
with stride 2. The first fully connected layer contains 500 nodes, and the second containsknodes, wherek is the length of the binary code.
The rest of this paper is organized as follows. In Section 2, related works to our method would be discusses. The implementation details of our method are presented in Section 3. Evaluates the proposed method on two large scale datasets in Section 4. Finally, Section 5 concludes the paper.
RELATED WORK
At present, there are some popular data-independent and data-dependent hash methods. Due to the advantages of speed and storage, many of the hashing methods [9-21] have been proposed to raise performance of approximate nearest neighbor search. Data-independent hash methods use unlabeled data for learning a set of hash functions. The most representative is Locality-Sensitive Hashing (LSH) [11], which uses random projections construction a hash function. It is intended to maximize the probability of matching similar data to similar binary encodings. However, LSH usually requires a longer hash code to achieve a satisfactory accuracy, which leads to a problem of large storage space requirements and recall rate is generally low.
After that, a large number of studies have shown that the use of supervisory information can improve the learning performance of hash coding, which is belong to data-dependent. These methods use the label information to generate a valid hash function from the training set. These mainstream hash algorithm can be further divided into the following three categories: unsupervised hash methods, supervised methods and semi-supervised methods. Unsupervised hash methods are not required for any label information. For example, Spectral Hashing (SH) [12] is a well-known representative algorithm for unsupervised learning. Not only requires the distance information in the Hamming space after the hash to be as consistent as possible with the original space, but also requires that the hash code is balanced and that each hash code is irrelevant; Iterative Quantization (ITQ) [14] minimized the quantization error by projecting data to the vertex of binary hypercube to learn a better binary hash code.
function. The above mentioned method can only deal with linearly separable data. It is difficult to act on linear inseparable data. Binary Reconstructive Embedding (BRE) [13] and Supervised Hashing with Kernels (KSH) [16] can address the linear inseparable, for their learning the hash function in the kernel space.
Due to the limitations of the hand-crafted feature, it is difficult to extract the semantic information of the image. In order to solve this limitation, CNNs-based hash methods [9, 10, 18-23] is proposed. [9, 10, 19, 22, 23] guides the network to learn the approximate binary code output that preserves the semantics similar and dissimilar relation of input image triplets. [18] first decomposes the semantic similarity matrix of the training image data into approximately hash codes, and then uses these approximate hash codes and image labels to train a deep convolution network. [20] train network models with approximate binary hidden layer as image features for image classification tasks. [21] uses the image pairs to train the neural network, and imposed a regularization term, so that the network output approximates the binary code. Compared to traditional hash, which is based on hand-crafted features, these CNNs-based methods have greatly improved the search performance. Nevertheless, these methods are based on triples and image pairs need to sample training samples, which waste a lot of time. And the training sample is drastically increased, resulting in increased training time. Our method learns class centers of each class directly in the training set, so that each type of sample is closer to their corresponding center to achieve better retrieval performance.
APPROACH
Hash learning goal is to learn similarity preserving hash functions that map image data onto compact binary codes. In other words, the similar image data should be imbedding to similar binary codes, the dissimilar image data should be as far away as
possible in Hamming space. Assuming that dataset has N images, which are
represented as X , and the hash function is embedding images to k- bit:
: { 1, 1}k
X
.We briefly review the recent work on learning preserve-similarity
hashing methods.
Contrastive loss [24] [21] utilizes the image pair{(b , b ,i j yij)}label information to
train the hash network. The cost function minimizes the distance between a pair of images with the same label information. The loss function is defined as follows:
/2
, ,
( , )
1 m [(1 ) || b , b || max( || b , b || ,0)]
i j i j H i j i j H
i j
L y y m
m
(1)Where m stands for the number of training images, b is the hash code from the
network,|| , || H indicates the distance between the two hash code vectors in Hamming
space, and the yi j, {0,1} denotes whether the image pairs are similar.
Triplet loss [25] [9] guides the network trained on tuple image{( ,x x,x)}where
denotes they are similarity, { ,x x}indicates them are dissimilar. The object function
aims to find a mapping where the Hamming distance between{ ,x x}is large than the
max(1 || b, b ||H || b, b || ,0)H
L (2)
where{(b,b ,b )} represents the{( , , )}
x x x after embedding.
Inspired by the contrastive loss and triplet loss, and we want to minimize intra-class hash codes while keep the difference between inter intra-class hash codes. So, we proposed the hash center loss function is defined as follows:
1 1 || || 2 i m y
C i c H
i
b b
L (3)
where m donates the number of training image data, bi indicates the binary
encoding of the training image data output, and yi
c
b is the yi-th hash class center of
deep hash code. This equation makes the same class closer to the center of the same class. However, this hash center loss can’t be used directly, since the network output is thresholding to the binary hash code, and will not allow the use of back-propagation to train the network. So we use the Euclidean distance to replace the Hamming distance, which leads to suboptimal results that we can’t ignore. Previous work uses sigmoid and tanh to approximate the thresholding process, but such non-linear functions can cause the network to be difficult to train. So we follow to [21] apply a regularization term to the network output to approximate the thresholding process. Then Eqn.(3) is rewritten as:
2
2 1
1
1
|| || || | | 1||
2
i
m
y
C i c i
i
b b b
L (4)
where || || 2 denotes the L2-norm, 1 is the unit vector, is representing the importance of regularization term, || || 1is the L1-norm vector, and | | is an absolute value operation.
However, Eqn.(4) can only ensure that the class features are close to each other, and the deep hash feature isn’t discriminative between the inter-class. So we use cascade training of softmax loss or cross-entropy loss and hash center loss to train the network. The whole equation can be written as the following two formulas:
2
2 1
1 1
1
log || || || | | 1||
2
T yii
i T j i b m m y
i c i
c b
i i
j
e
b b b
e
L (5a)
1 1
2
2 1
1
log 1 log 1
|| || || | | 1||
2
i
m c
j j
i i i i
i j
m
y
i c i
i
y h b y h b
b b b
L (5b)note that, if an image set only has single label information, we use softmax loss
the last fully connected layer andyi{1, 2,... }c denotes the image label. In addition, for
the multiple labels information, cross entropy loss will be used, as showed in Eqn.5(b),
whichh( ) is the predict probability, and {0,1}
c i
y is a binary label vector, where cthe
number of labels.
Due to memory limitations, we perform training based on mini-batch gradient
descent algorithm. So the gradients of LC w.r.t bi and update equation of yi
c
b need to
be computed. Since the absolute value operation in the objective function is non-differentiable at some certain points, we use subgradients instead, and define the
subgradients to be 1 at such points. The subgradients and update equation are
respectively written as:
i y C
i c
i
b b
b
L
(6)
1
1
( ) ( )
1 ( )
m
j
i c i
j i
c m
i i
y j b b b
y j
(7)
( )i i
Regularizer b
b
(8)
Where
1, 1 0 1
( ) 1
x or x x
otherwise
, (9)
( ) 1
[image:6.612.88.509.469.645.2] if the condition is satisfied, and vice versa.
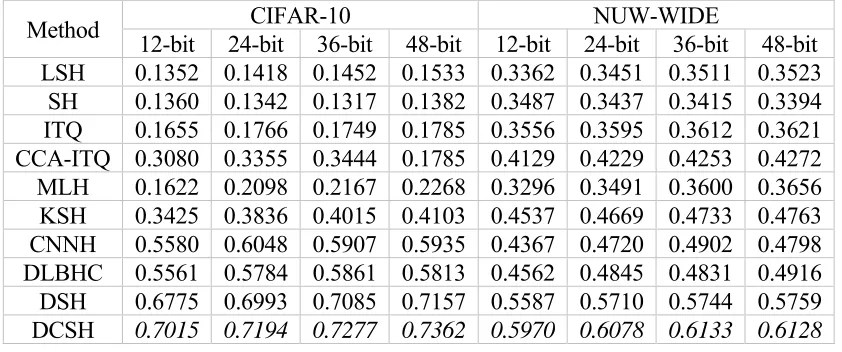
TABLE 1. COMPARISON OF RETRIEVAL MAP OF OUR DCSH HASHING METHOD AND THE OTHER HASHING METHODS ON CIFAR-10 AND NUW-WIDE.
Method 12-bit 24-bit CIFAR-10 36-bit 48-bit 12-bit 24-bit NUW-WIDE 36-bit 48-bit
LSH 0.1352 0.1418 0.1452 0.1533 0.3362 0.3451 0.3511 0.3523
SH 0.1360 0.1342 0.1317 0.1382 0.3487 0.3437 0.3415 0.3394
ITQ 0.1655 0.1766 0.1749 0.1785 0.3556 0.3595 0.3612 0.3621
CCA-ITQ 0.3080 0.3355 0.3444 0.1785 0.4129 0.4229 0.4253 0.4272
MLH 0.1622 0.2098 0.2167 0.2268 0.3296 0.3491 0.3600 0.3656
KSH 0.3425 0.3836 0.4015 0.4103 0.4537 0.4669 0.4733 0.4763
CNNH 0.5580 0.6048 0.5907 0.5935 0.4367 0.4720 0.4902 0.4798
DLBHC 0.5561 0.5784 0.5861 0.5813 0.4562 0.4845 0.4831 0.4916
DSH 0.6775 0.6993 0.7085 0.7157 0.5587 0.5710 0.5744 0.5759
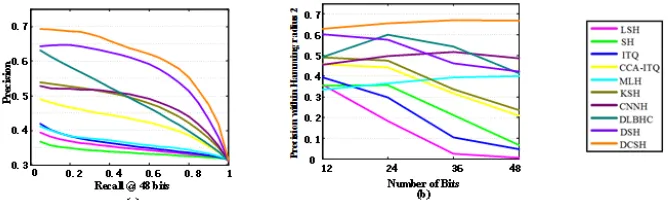
Figure 2. Comparisons with traditional methods on CIFAR-10 dataset. (a) Precision-Recall curves (48bit). (b) Precision within Hamming radius 2 using hash lookup.
Figure 3. Comparisons with traditional method on NUS-WIDE dataset. (a) Precision-Recall curves (48bits). (b) Precision within Hamming radius 2 using hash lookup.
EXPERIMENTS
We test the effectiveness of proposed hashing method on two benchmark datasets,
i.e., CIFAR-101, a tiny image collection and NUS-WIDE2, a large image set collected
from Flickr.
Two Dataset.
The CIFAR-10 dataset consists of 60,000 3232 colour images in 10 classes, with
6,000 image per class. We randomly sample 10,000 images (1,000 images per class) form the test search set. All the rest 50,000 images are used as training samples. The NUW-WIDE dataset contains nearly 270K images collected from the web. Each of these images is associated with one or multiple semantic tags (class labels) from 81 concept labels. We follow [16] to be used in the subset of images associated with 21 most frequent labels, where each of these concepts associates with at least 5,000 images, eventually form 195,834 images. For simplicity, we resize each image to
6464. We randomly select 10000 form the test search set. All the rest 185,834
images are used as training samples.
Implementation details.
On both datasets, we utilize the Figure 1 as our basic network architecture, which is composed of three convolution-convolution-pooling layers followed by three fully connected layers, where the second layer is the hash code layer. The convolution layers use 322, 642, and 1282 with 55 filters with stride 1 respectively, and
[image:7.612.122.458.225.325.2]contains 500 nodes, and the second contains k nodes, where k is the length of the
binary code.
We implement the network training based on the open source Caffe [26] framework. In our all experiments, our network is trained by stochastic gradient descent with 0.9 momentum. The initial learning rate is set to 0.01, and we decrease it to 10% after 10000 iterations. The weight decay parameter is 0.004.
Protocols and Baseline Methods.
We follow three evaluation metric i.e., Mean Average Precision (MAP), Precision-Recall and Precision curves within Hamming distance 2 hash lookup, which is widely used in [14][16][17]. We compare our DCSH method with nine hashing methods including six traditional method, i.e., Locality-Sensitive Hashing (LSH) [11], Spectral Hashing (SH) [12], Iterative Quantization (ITQ) [14], CCA Iterative Quantization (CCA-ITQ) [14], Minimal Loss Hashing (MLH) [15], and Supervised Hashing with Kernels (KSH) [16], and three deep hash method i.e., CNNH [18], DLBHC [20] and DSH [21].
For CNNH, DLBHC, DSH and DCSH, the original image is entered directly into the network. For conventional methods, we use the 512-D GIST descriptors for each image in CIFAR-10 and use the 225-D normalized block-wise color moments features for each images in NUS-WIDE. Note that, due to huge memory requirements for the MLH, KSH and CNNH, so in the implementation process, we randomly sample 20,000 image form a subset to train three model.
Evaluation Result on CIFAR-10 Dataset.
Table 1 show mAP performance of ten runs on CIFAR-10 dataset on the left. From the overall trend of the table, the mAP results of different number bits show that the performance of our DCSH is significantly better than other methods. In particular, compared to the best conventional competitor KSH and the most related competitor DSH, the mAP results of different number of the DCSH indicate a relative increase of
79.4%~104.8% and 2.71%~3.54%, respectively. Our method is superior to the other
all method, shows that the effectiveness of our proposed method, learning an intra-class center can improve performance.
In the evaluation of precision-recall curves in Figure 2(a). This result reflects the trends we saw in Table 1, and proving that our approach is superior to other methods. In other words, performance improvement is higher than other methods.
We further detail the precision within Hamming radius 2 using hash lookup as showed in Figure 2(b), the accuracy rate has a huge drop when the number of bits greater than 36 bits are used. The reason is that the number of images falling into the barrel is decreasing for the use of longer hash code.
Evaluation Result on NUS-WIDE Dataset.
lookup of our method DCSH can achieve 61.28% and 66.88% with 48 hash bits,
which make the improvement over the best competitor DSH by 6.04% and 58.59%.
The Precision-Recall also superior to other methods. Indicating that our proposed DCSH method is effective.
SUMMARY
In this paper, we have presents a method learning binary code by deep hash center learning, In our method, first we designed a CNN model which take image with label the overall trend of the table, the mAP results of different number bits show that the indicating them belong to which category as training inputs, and learning the binary code in the layer, The loss function is devise to learning a hash center for deep features of each class. During the training phase, we simultaneously hash code center and minimize the distance between the hash code and their corresponding class hash code center. The most important thing is that our method of retrieval performance than the previous conventional method.
ACKNOWLEDGMENTS.
This work is supported by the National Natural Science Foundation of China (grant No.61540063), the Application Basic Research Fund of Yunnan Province (grant No.2016FD058), Yunnan Provincial Department of Education Science Research Fund Project (grant No.2017ZDX045), Yunnan MinZu University project (No. DY2015YB06) and Program for Innovative Research Team (in Science and Technology) in University of Yunnan Province, Yunnan MinZu University youth fund research project(No.2017QN02)
REFERENCES
1. Lowe, D.G.: Distinctive image features from scale-invariant keypoints. International journal of computer vision, vol. 60, no. 2, p. 91-110.
2. Dalal, N.,Triggs, B.: Histograms of oriented gradients for human detection. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, p. 886-893. 3. Szegedy, C., Toshev, A.,Erhan, D.: Deep neural networks for object detection. In: Advances in
Neural Information Processing Systems, p. 2553-2561.
4. He, K., Zhang, X., Ren, S., et al.: Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: Proceedings of the IEEE international conference on computer vision, p. 1026-1034.
5. Krizhevsky, A., Sutskever, I.,Hinton, G. E.: Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, p. 1097-1105.
6. Szegedy, C., Liu, W., Jia, Y., et al.: Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 1-9.
7. Sun, Y., Chen, Y., Wang, X., et al.: Deep learning face representation by joint identification-verification. In: Advances in neural information processing systems, p. 1988-1996.
8. Chen, L.-C., Papandreou, G., Kokkinos, I., et al.: Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv preprint arXiv:1412.7062.
9. Yao, T., Long, F., Mei, T., et al.: Deep semantic-preserving and ranking-based hashing for image retrieval. In: International Joint Conference on Artificial Intelligence (IJCAI), p. 3931-3937. 10. Zhang, Z., Chen, Y.,Saligrama, V.: Efficient training of very deep neural networks for supervised
hashing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 1487-1495.
12. Weiss, Y., Torralba, A., Fergus, R.: Spectral hashing. In: Proceedings of the 21st International Conference on Neural Information Processing Systems, pp. 1753-1760: Curran Associates Inc. 13. Kulis, B., Darrell, T.: Learning to hash with binary reconstructive embeddings. In: Advances in
neural information processing systems, p. 1042-1050.
14. Gong, Y., Lazebnik, S.: Iterative quantization: A procrustean approach to learning binary codes. In: Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on, p. 817-824.
15. Norouzi, M., Blei, D.M.: Minimal loss hashing for compact binary codes. In: Proceedings of the 28th international conference on machine learning (ICML-11), p. 353-360.
16. Liu, W., Wang, J., Ji, R., et al.: Supervised hashing with kernels. In: Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, p. 2074-208.
17. Wang, J., Kumar, S., Chang, S.-F.: Semi-supervised hashing for large-scale search. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, no. 12, p. 2393-2406.
18. Xia, R., Pan, Y., Lai, H., et al.: Supervised Hashing for Image Retrieval via Image Representation Learning. In: AAAI, vol. 1, p. 2.
19. Lai, H., Pan, Y., Liu, Y., et al.: Simultaneous feature learning and hash coding with deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 3270-3278.
20. Lin, K., Yang, H.-F., Hsiao, J.-H., et al.: Deep learning of binary hash codes for fast image retrieval. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, p. 27-35.
21. Liu, H., Wang, R., Shan, S., et al.: Deep supervised hashing for fast image retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 2064-2072.
22. Zhang, R., Lin, L., Zhang, R., et al.: Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Transactions on Image Processing, vol. 24, no. 12, p. 4766-4779.
23. Zhao, F., Huang, Y., Wang, L., et al.: Deep semantic ranking based hashing for multi-label image retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 1556-1564.
24. Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learning an invariant mapping. In: Computer vision and pattern recognition, 2006 IEEE computer society conference on, vol. 2, p. 1735-1742.
25. Schroff, F., Kalenichenko, D.,Philbin, J.: Facenet: A unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, p. 815-823.