2017 2nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017)
ISBN: 978-1-60595-485-1
Data Query and Mining Frameworks for Storm
MIAO HE, LV SHI, LILI LU and XIAOLAN MEI
ABSTRACT
Storm is an open source fault-tolerant and real-time computation system. Storm makes it easy to process unbounded streams of data reliably. In this paper, we first discuss different application scenarios and main features of Storm in details. Then, we analyze the framework design of streaming data query and the framework design of data mining based on Storm. The algorithm optimization of data stream mining is introduced as well. Finally, we propose a new data stream query framework based on a vertical parallel algorithm which can improve the performance of data mining.
KEYWORDS
streaming data, data query, data mining, vertical parallel algorithm.
INTRODUCTION
Storm is an open-source distributed scalable fault-tolerant and real-time computation system developed by Twitter [1]. It defines a group of real-time computational primitives which can greatly simplify the parallel real-time data process and provide a simple API that allows developers to write complicated reliable real-time data processing applications with ease to handle continuous unbounded data stream, such as real-time analysis, online machine learning, continuous computing and distributional process RPC/ETL [2]. Storm is configured and managed by ZooKeeper [3] which makes the cluster expansion very convenient. The scalability of Storm can ensures that each message will be processed fast. Strom can process millions of messages per second with a small cluster. And the cluster can be dynamically expanded simply by adding machines and modifying Topology parallel settings. Storm uses Clojure and Java as development languages; other non-JVM languages can communicate with Storm through stdin/stdout in JSON format. One of the advantages
of Storm is that Storm Topology and message processing components can be defined in any programming language so that any developer can use it. The biggest feature of Storm is that the process of message can be guaranteed which guarantees the availability of the entire architecture. That is, Storm ensures the messages to be addressed means the entire streaming layer of the architecture will process messages.
_________________________________________
Nimbus
Nim bus
Master
Zoo kee per
cluster
Zoo kee per
Zoo kee per
Nimbus
Slaves
Sup ervi sor
Sup ervi sor
Sup ervi sor
Nimbus
Worker
Supervi sor
worker worker
worker worker
Worker
worker worker
worker worker
Worker
worker worker
[image:2.612.154.441.50.281.2]worker worker
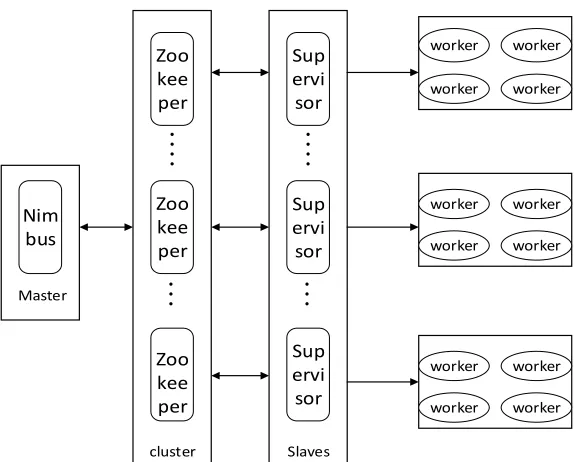
Figure 1. Stream data computing architecture ofStorm.
Storm uses master-slave system architecture as shown in Fig. 1. Nimbus daemon running on the master node is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for state and failures [4]. Slave node runs a work called Supervisor daemon. Supervisor listens for work assigned from Nimbus, and starts and stops Worker processes based on the work assigned to it. Each Worker executes specific tasks. Nimbus receives tasks from clients, assigns the tasks to Supervisor after verification, and writes the meta-information of the task to Zookeeper directory.
Zookeeper monitors the implementation of the tasks in real-time. If fault occurs, it will run fault detection, restart the failed Supervisor and Work processes, and submits the state of Worker and Supervisor to Nimbus. Nimbus and Supervisor are fail-fast and stateless. Their coordination is accomplished by Zookeeper.
Storm application scenarios
Storm scenarios mainly have the following three categories:
Stream processing. Storm can be used for the real-time processing of new data and
the updating of database. It is fault tolerance and scalability.
Continuouscomputation. Storm can do continuous queries and stream the results to client in real-time. For example, it can stream hot topics on Twitter to the browser.
Distributed RPC. Storm can be used to parallel process intensive queries. The
topology of Storm is a distribution function waiting for call information. When it receives a call message, it will calculate on the query and return the query results. One instance is that Distributed RPC can do parallel search and process large collections of data.
Main features of Storm
The main features of Storm are as follows:
A Simple programming model. Similar to MapReduce reducing the complexity of
Support a variety of programming languages. Storm support a variety of
programming languages. The default languages are Clojure, Java, Ruby and Python. But user just need to make a simple Storm communication protocol to increase support for other languages.
High fault tolerance. If some exceptions thrown out in the process of message
processing, Storm will re-arrange the units which have exceptions. Storm can guarantee every processing unit be full executed.
Support horizontal extension. There are three main entities in the real running
topology of Storm cluster: work process, threads and tasks. Each machine in the cluster can run multiple work processes; each work process can create multiple threads; each thread can perform multiple tasks; and each task is a real entity of data processing. Spout and bolt are performed as means of one or more tasks. Therefore, computing process runs among multiple threads, processes and servers, and supports flexible horizontal scaling.
High reliability. Storm ensures that each message from the spout can be "fully
processed", which is different from other real-time systems, such as S4 [6]. When task fails, Storm will re-get messages from the message source. Storm uses a clever way to determine whether a tuple is missing, that is, the sender and the responder both need to xor a random number to the third-party acker within the system. If the random number recorded on acker is 0 in a certain time, the message will be considered as being handled correctly. Otherwise acker will notify the spout to re-do.
Support local mode. Storm provides a local mode with a topology similar to the
cluster topology so that it contains all of the features in the process of simulating a Storm cluster.
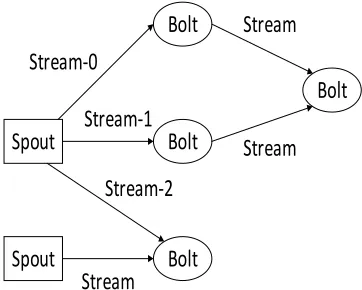
Efficient message processing. Storm is designed to guarantee that message can be
fast processed using ZeroMQ [7] as the underlying message queue which is shown in Fig. 2.
Storm does not provide data duplication and the persistence of operator. If they are required, they should be handled at the application level. This meets the original design intention of Storm. Messages repetition is the side-effect of fault tolerance and no-lose guarantee. Most real-time computations do not require to achieve the accuracy requirements of batch so that most applications are not sensitive to message repetition. If an application is so, it can remove duplicates at application layer, or define message process as idempotent operation, or let it be fixed by batch layer.
Spout
Spout
Bolt
Bolt
Bolt
Bolt Stream‐0
Stream‐1
Stream‐2
Stream
[image:3.612.206.387.537.682.2]Stream Stream
Storm provides persistence and high reliability of task state including the memory recovery state of task after the failover. Saving and restoring these state needs peripheral system to guarantee, such as a high reliable key-value storage system or a distributed file system. Not considering the persistence, the design and implementation of Storm has been greatly simplified. The system defects of Storm mainly include: allocate resources without considering task topology structure characteristic; not adapted to the dynamic changes of the data loading; use centralized operation level fault-tolerant mechanism which limits the scalability of the system in a certain extent.
FRAMEWORK DESIGN OF STREAMING DATA QUERY BASED ON STORM
The rapid development of information technology significantly enhances electronic information level in a wide range of industries. These data have the characteristics of streaming data. The industries usually only keep data for a period of time or keep only highly representative data. Streaming data query has two main features. One is real-time continuity. Compared with the conventional query which is a passive process depending on the user's query, continuous query is an active process which continues return query result as the data changes. Another one is unpredictability. The database structure in traditional query is known, so the query can be adjusted and optimized dynamically based on the size of the database. However, streaming data is constantly changing. In order to optimize the query, data have to be dynamically processed and the query result is an approximate result. As accurate processing of data is neither possible nor necessary, the management system of streaming data uses approximation as a means for data processing. Thus various approximations query algorithms become effective techniques for streaming data query processing, such as window queries, batch processing, sampling, abstract data structures, random projection technology and feature reduction technology. In addition, streaming data query need to support higher QOS, which requires that the query results summary of coarse-grained returns in a very short response time, while the precise fine-grained query results return in a longer response time. Streaming query algorithm can be used in the dynamic data process, query process fix and short-term access to data. In the field of real-time query, we tend to the buffer management of volatile data and developing a series of sampling and sketch technologies. The core idea of the optimization model of streaming query technology is to reduce the forwarding of streaming data and the throughput pressure of the overall message system. Query optimization is achieved by designing efficient memory buffer algorithm, and reusing existing streaming query task resources.
analyzes user's attribute in real time, and sends feedbacks to the search engines. In order to meet the requirements of time, we hope that Storm would be able to real-time analyze user behavior log in real real-time, gives feedback about the latest user attributes to search engines, and shows the closest current demand for the user. Ctrip [9] is another example which uses real-time analysis system to monitor its website performance. Using performance standard which HTML5 provides to access to available indicators and logs, Storm cluster can analyze log and warehousing in real time and use DRPC to aggregate them into statements and trigger alert events by judging some rules like comparison with historical data.
In this paper, we mainly study two framework designs of streaming query based on Storm: newly-built topology streaming query framework and passing parameters topology streaming query framework.
Newly-built topology: The framework design of streaming query based on Storm is
shown in Fig. 3. System.inSpout inputs SQL statements. Then bolt1 analyzes the
semantics and transfers to bolt2 which chooses the new function topology. After that, dataspout distributes the data read from Kafka message to each functional bolt to
realize query functions and finally outputs the result. This solution has higher stability and better extensibility, but is slower in response time.
Passing parameters topology: The framework design of streaming query based on
Storm is shown in Fig. 4. Respectively reading in the input stream and data stream through spout1 and spout2, preBlot affects bolt by changing the static variables. The
input stream is used to tag data streams. Blot judges the data flow through the tag and changes data processing method according to predefined rules. In this solution, bolt is a static topology and is faster in response time, but the extensibility is poorer.
Kafka dataSpout system.inSpout
selBolt otherBolts
resBolt Bolt1:Semantic
analysis Bolt2:bolt select
neo topology
Spout1 Spout2
preBlot static variable
selBlot
insertBlot
otherBlots
resultBlot
Data middl eware is used to store inter media te result s Data
flow
Sql sentence
Data flow input
[image:6.612.188.410.47.372.2]flow
Figure 4. Passing parameters topology framework of the streaming data query based on Storm.
FRAMEWORK DESIGN OF STREAMING DATA MINING BASED ON STORM
Storm
S4 framworkOther
platform algorithm
Stream pattern finder
Stream data classifier
Stream cluster analyzer
application
Network traffic flow
Stock exchange
flow
[image:7.612.180.420.52.274.2]Web click stream Others
Figure 5. Framework of streaming data mining.
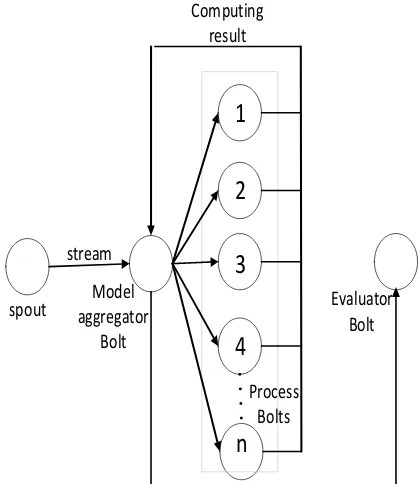
To minimize the occupied memory, we recommend a vertical parallel framework where process bolt is not stored in local model as shown in Fig. 6. Model-aggregator bolt assigns instances needed to be computed to each process bolt depending on the data attributes. Each bolt only stores statistical information assigned to it and computes the information value of the attributes and then sends computing results to model-aggregator bolt which gathers these information to generate global decision-making model. Users can set the number of process bolts according to the speed of instance process in order to achieve optimization of parallel algorithm. Model-aggregator bolt will sent the result to the evaluation bolt to assess the accuracy and processing capacity of the model.
1
2
3
4
n
Process Bolts Model
aggregator Bolt spout
stream
Computing result
Evaluator Bolt
[image:7.612.194.403.447.689.2]CONCLUSION
Storm is an open-source distributed scalable fault-tolerant and real-time computational system. It is configured and managed by ZooKeeper and uses master-slave system architecture. This paper discusses three Storm application scenarios, that is, stream processing, continuous computation and distributed RPC. Seven main features of Storm are also analyzed, including supporting a variety of programming languages and horizontal extension, high fault tolerance, high reliability and so on. The biggest feature of Storm is that the process of message can be guaranteed which guarantees the availability of the entire architecture. Then, the query frameworks and mining parallel algorithm framework of the streaming data based on Storm are proposed in this paper. A vertical parallel framework is recommended to minimize the occupied memory.
With the rapid increase of the amount of data, research work related to the theory and practice on streaming data calculation should be carried out, urgently comprehensive, systematic and in-depth. Combining with the detailed application requirements, large data flow computing systems and algorithms for specific applications should be developed, deployed, tested and optimized. Accordingly, the large data stream research and development should be further promoted.
ACKNOWLEDGEMENTS
This work was mainly supported by Zhongxing Corporation Foundation, and partly supported by National Natural Science Foundation of China (61170065, 61373017), Natural Science Foundation for Young Scientists of Jiangsu Province (BK20130876), Future Network Project of Jiangsu Province (BY2013095-4-03), National Postdoctoral Science Foundation (2013M541702) and Research Foundation of Nanjing College of Information Technology (YK20150401).
REFERENCES
1. A. Toshniwal, S. Taneja, A. Shukla, et al. Storm@twitter. ACM SIGMOD International Conference on Management of Data. (2014), p. 147-156.
2. J. Leibiusky, G. Eisbruch, D. Simonassi. Getting Started with Storm. O'Reilly Media, 2012. 3. P. Hunt, M. Konar, F.P. Junqueira, et al. ZooKeeper: Wait-free Coordination for Internet-scale
Systems. Proceedings of the 2010 USENIX conference on USENIX annual technical conference. Boston, MA, June 23-25, 2010, p. 11-11.
4. M. Wang, S. Yuan, Y. Zhu, et al. Real-time clustering for massive data using Storm. Journal of Computer Applications. Vol. 34 (2014) No. 11, p. 3078-3081.
5. J. Dean, S. Ghemawat. Simplified Data Processing on Large Clusters. Proceedings of Operating Systems Design and Implementation (OSDI). Vol. 51 (2004) No. 1, p. 107-113.
6. L. Neumeyer, B. Robbins, A. Nair, et al. S4: Distributed Stream Computing Platform. IEEE International Conference on Data Mining Workshops. IEEE Computer Society. (2010), p. 170-177. 7. P. Hintjens. ZeroMQ: Messaging for Many Applications. O’Reilly Media, 2013.