2019 International Conference on Information Technology, Electrical and Electronic Engineering (ITEEE 2019) ISBN: 978-1-60595-606-0
Fast Adaptive Reconstruction Algorithm for Line Spectrum Pair
Parameters Based on Compressed Sensing
Yi-man WANG* and Qiang LI
Chongqing Key Laboratory of Signal and Information Processing, School of Communication and Information Engineering, Chongqing University of Posts and Telecommunications,
Chongqing, China
*Corresponding author
Keywords: Line spectrum pair parameters, Compressed sensing, Adjustment parameters.
Abstract. Line Spectrum Pair Parameters (LSF) are important parameters in low rate speech coding. Implementing LSF transparent quantization with as few bits as possible is a research hotspot in the field of low-rate speech coding. Based on the theory of compressed sensing, this paper proposes a new adaptive reconstruction algorithm. At the encoding end, the algorithm performs frame type discrimination on the LSF of single frame or superframe after voice activation detection and then applies the compressed sensing method to observe and quantize the LSF parameters of the single frame or superframe. At the decoding end, parameters are adaptively selected according to every single frame or superframe type, so that the number of bits required to reconstruct the LSF is reduced. The experimental results show that the proposed algorithm can reduce the number of bits required for LSF reconstruction and improve the reconstruction quality under the appropriate codebook storage and search complexity.
Introduction
Voice coding[1] is an important part of digital voice communication. Line spectral pair parameters play an important role in the parameter encoding of speech. However, in a low SNR environment, the encoder performance and robustness are drastically reduced due to the small number of codes allocated to the speech signal per unit time. Therefore, how to develop low-rate, high-robustness and low-latency speech coder is the focus of current low-rate speech coding research.
The core idea of compressed sensing theory[2]-[4] is: as long as the signal is compressible or sparse in a certain domain, such a high-dimensional signal can be directly projected onto a low-dimensional space, and the original signal can be reconstructed with a small amount of observation. At present, there are two main reconstruction algorithms: convex optimization algorithm and greedy tracking algorithm. These algorithms have their own advantages and disadvantages, but the complexity is high. Therefore, how to design a low complexity and high robustness algorithm is the key to the application of compressed sensing theory to speech coding.
In order to obtain a lower coding rate without affecting the voice quality, this paper proposes an adaptive fast reconstruction algorithm based on compressed sensing for LSF parameters. The voice LSF parameters are combined in multiple frames, and different adjustment parameters are adaptively selected according to the different sparseness of different superframes to achieve optimal reconstruction quality. The experimental results show that the proposed algorithm can reduce the number of bits required for LSF reconstruction and improve the reconstruction quality under the appropriate codebook storage and search complexity, which is suitable for low-rate speech coding.
Compressed Sensing Theory
Let the length of the original signal X be N, expressed in a certain transform domain Ψ:
If the non-zero number K of θ (K<<N), then θ is a sparse representation of X over the transform domain Ψ.
If an observation matrix Φ(M×N, M<N) that is not related to the transform domain Ψ can be found, the observation signal Φ is used to observe and sample the original signal to obtain an observation sequence Y, where Y contains M observationsYi, if Y contains enough information to
reconstruct the signal X, then the optimization method can be used to reconstruct X from the observations with high probability:
A x
Y (2)
Where Ais the matrix ofMN, called perceptual matrix. Finally, the original signal x is reconstructed by the estimated coefficient θ.
Compressed Sensing Algorithm for LSF
Selection of Observation Matrix for LSF
The acquisition of measurement vectors[5] and the reconstruction of signals[6,7] are the core steps of compressed sensing. In the theory of compressed sensing, the measurement matrix Φ must be independent of the base space Ψ of the signal in order to satisfy the Restricted Isometry Property(RIP).
After the speech signal is transformed by a discrete cosine transform(DCT), most of the information of the signal is concentrated in the low frequency, and the high frequency part contains less energy. Observing the transformed speech signal using the row-step observation matrix mentioned in reference[8]. The row step observation matrix uses the correlation between signal samples, has low complexity and is simple to implement, and does not occupy storage space.
Table 1. Computational complexity and storage space allocation under different measurement matrices.
Φ Multiplication Addition Storage space
Gaussian MN M(N1) MN
Bernoulli 0 M(N1) MN
Row ladder 0 M(m1)NM 0
Compressed Sensing Implementation of LSF
Divide the speech signal into sub-frames of T milliseconds long, consecutive 1 superframe with consecutive n subframes, extracting the p-th order spectral frequency for each sub-frame to get
p
LSF1 [9,10], obtaining the superframe line spectrum frequency LSFnpcan be expressed as:
p n n n p p n p n x x x x x x x x x x x x LSF ... ... ... ... ... ... ... 2 1 2 2 2 1 2 1 2 1 1 1 2 1 (3) wherexi
xi1 xi2 ... xip
,i1,2,3,...,n, represents the p-dimensional LSF vector of the ith frame speech extraction.Fast Adaptive Reconstruction Algorithm for LSF Based on Compressed Sensing
Fast Reconstruction Algorithm for Compressed Sensing
is proposed. This fast reconstruction algorithm is different from the traditional matching tracking algorithm and does not require multiple iterative matching. The algorithm flow is as follows:
1.Input the signal Y1Mto be processed and the perceptual matrixACS, whereACSis calculated by the formula ACS MNNN, whereMNis the observation matrix and
N N
is the sparse transformation base.
2.Select the frontM column of the perceptual matrixACS, and obtain the adjusted perceptual matrix as the square matrix AMM.
3.Solve the linear equation1M Y1M
AMM
T
1.4.Solved the first M-dimensional coefficients of the sparse coefficient matrix,then add 0 to the
M
N dimension after, and get the sparse coefficient matrix
M |0...0
. 5.Sparse inverse transformation of matrixto reconstructs the original signal.This fast algorithm uses the DCT basis to gather most of the information of the signal in the low frequency part, converting the perceptual matrixACS into a square matrix, then the original iterative reconstruction algorithm is further simplified into a linear equation solution. After obtaining the front M-dimensional coefficient1M, the high-frequency part is added with 0, and then the sparse inverse transform is performed to obtain the original signal.
Adaptive Fast Reconstruction Algorithm for LSF
Adaptive Fast Reconstruction Algorithm. The pre-M dimension of the fixed selection perceptual matrix in reference[11]reduces the complexity of the algorithm, but in speech coding, the quality of speech may be degraded. Because the speech is divided into unvoiced and voiced, and the sparsity of different types of speech frames on the DCT basis is different[12], that is, the sparsity of voiced speech is generally better than the unvoiced sound, if the method in reference [11] is adopted for the entire speech, the unvoiced and voiced sounds will not achieve the optimal reconstruction effect at the same time.
Aiming at the above problems, this paper proposes a new adaptive fast reconstruction algorithm for LSF. The algorithm flow is as follows:
1.Input observation sequenceY1M, adjustment parameter and perceptual matrixACS, whichACSis calculated by the formulaACS MNNN whereMNis the observation matrix andNNis the sparse transformation base.
2.According to the adjustment parameter, the calculation valueFNis used to determine the dimension value Fof the adjusted perceptual matrixACS.
3.Select the frontFcolumn of the perceptual matrixACSto obtain the adjusted perceptual matrix F
M A .
4.Determine ifAMFis a square matrix, if M/N,FNM, thenAMFis a square matrix; if M/N, AMF is a non-square matrix.
5.If AMF is a square matrix, solve the linear equation
1 11
T F M M
F Y A
, if AMF is a non-square matrix, solve the equation using the least squares method
MT F M F M T F M
F A A A Y
1
1 1
.
6.Solving the front F-dimensional coefficients of the sparse coefficient matrix, and adding 0 to the N-F dimension after , to obtain the sparse coefficient matrix
F|0...0
.7.Sparse inverse transformation of matrixto reconstructs the original signal.
for reconstruction is less, and when the input frame is an unvoiced frame, its sparseness on the DCT basis is poor, and the dimension of the perceptual matrix required for reconstruction is more.
Adjustment Parameter Selection. In the fast adaptive algorithm proposed in this paper, an important parameter is introduced on the basis of the fast algorithm, namely adaptive adjustment parameter. The choice of plays a crucial role in the reconstruction effect and will directly affect the quality of the reconstruction parameters.
In the corpus, we select a number of male and female voice signals with different pronunciation contents as the coding object. Read the speech signal in turn to determine the type of each sub-frame in the speech signal, determining the superframe type according to consecutive n subframe types, and saving the superframes having the same type into the same voice file. Using the algorithm proposed in this paper, the voice files storing the same type of superframe are read out, and the superframe line spectrum frequency parameters are encoded and decoded. In the reconstruction process, the parameter is adjusted in units of
N 1
steps, and the values are
sequentially taken in the
1 , 1
N interval to reconstruct the frequency parameters of the speech line
spectrum. Then, calculate the error before and after each reconstruction of the superframe line spectrum frequency. Finally, thecorresponding to the minimum error is the optimal adjustment parameter value of the superframe type.
Result
The reconstruction performance of the parameter fast adaptive reconstruction algorithm is simulated by using the compressed sensing based line spectrum proposed in this paper. 20 voices are selected as the training speech set. The sampling frequency is 8000Hz, the frame length is 30ms, and the LSF are extracted as test data. We use spectral distortion to measure the quantitative reconstruction performance of parameters. It can be expressed as follow:
L n
n
n S d
S L
SD
1 1
0
2 ˆ lg 10 lg
10 1
1
(4)
Where L is the total number of frames for calculating spectral distortion,Sn
andSˆn
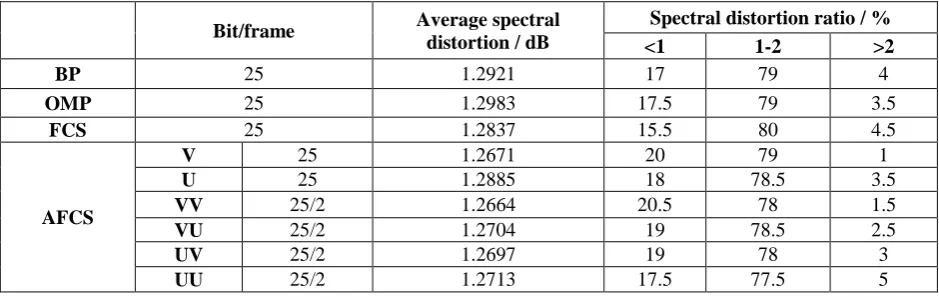
are the original power spectrum and the quantized power spectrum of the nth frame, respectively, and the smaller the spectral distortion, the better the performance. [image:4.595.63.533.593.741.2]The performance of the 200-frame LSF parameter is evaluated, and the results are as follows: Table 2. Reconstruction performance comparison.
Bit/frame Average spectral
distortion / dB
Spectral distortion ratio / %
<1 1-2 >2
BP 25 1.2921 17 79 4
OMP 25 1.2983 17.5 79 3.5
FCS 25 1.2837 15.5 80 4.5
AFCS
V 25 1.2671 20 79 1
U 25 1.2885 18 78.5 3.5
VV 25/2 1.2664 20.5 78 1.5
VU 25/2 1.2704 19 78.5 2.5
UV 25/2 1.2697 19 78 3
UU 25/2 1.2713 17.5 77.5 5
performance. As can be seen from Table 2, the LSF spectral distortion reconstructed by the proposed algorithm is significantly smaller than the traditional compressed sensing algorithm and the fast algorithm proposed in the reference[11]. And in the case of two frames combined, the number of reconstructed bits of the single frame LSF is halved, and the reconstructed LSF spectral distortion is also smaller than the conventional algorithm.
Conclusion
In this paper, a new adaptive fast reconstruction algorithm is proposed for the problem that the voiced signal of the compressed signal is sparse and the speech is not sparse. The algorithm selects appropriate adjustment parameters according to different frame types so that the LSF parameters achieve the best reconstruction. Experimental results show that the algorithm has better reconstruction effect than the traditional compressed sensing algorithm at lower computational complexity, and compared with the traditional speech coding algorithm and the traditional compressed sensing algorithm, the LSF parameters can be transparently quantized at a lower bit rate, and the quantization effect is slightly better than the traditional algorithm. Subsequent work will increase the number of frames n of multi-frame joints, train codebooks of different superframe types, and further reduce the bit rate required for LSF parameter encoding without affecting the reconstruction effect.
References
[1]Ye Li. Digital Speech Coding Technologies [M.BEIJING: Publishing House of Electronics Industry, 2013.
[2]Jingwen Yan, Lei Liu, Xiaobo Qu. Compressive Sensing and Its Applications[M]. National Defense Industry Press, 2015.
[3]Donoho D L. Compressed sensing [J]. IEEE Transactions on Information Theory, 2006:1289-1306.
[4]Candès E, and Wakin M. An introduction to compressive sampling [J]. IEEE Signal Processing Magazine, 2008: 21-30.
[5]Z Zhang, Y Xu, J Yang, X Li, D Zhang. A Survey of Sparse Representation: Algorithms and Application [J]. IEEE, 2017, 3: 490-530.
[6]Y Arjoune, N Kaabouch, HE Ghazi, A Tamtaoui. Compressive Sensing: Performance Comparison of Sparse Recovery Algorithms [J]. IEEE, Computing & Communication Workshop & Conference. 2017: 1-7.
[7]Sundman D, Chatterjee S, Skoglund M. Design and Analysis of a Greedy Pursuit for Distributed Compressed Sensing [J]. IEEE Trans. Signal Processing, 2016, 64(11): 2803-2818.
[8]L Ye, Z Yang, T J Wang, et al. Compressed sensing of speech signal based on row echelon measurement matrix and dual affine scaling interior point reconstruction method[J]. Acta Electronica Sinica, 2012, 40(3):429-434.
[9]Vinitha Ramdas, Sai Subrahmanyam R. K. Gorthi, Deepak Mishra. Simultaneous speech coding and de-noising in a dictionary based quantized CS framework [J]. Int J Speech Technol , 2016: 509-523.
[11] Andrianiaina, Rabah, Hassan. Compressed Sensing: A Simple Deterministic Measurement Matrix and a Fast Recovery Algorithm [J].IEEE Transactions on Instrumentation and Measurement. 2015:3405-3413.