2019 International Conference on Computation and Information Science (ICCIS 2019) ISBN: 978-1-60595-644-2
Research and Implementation of SVM and
Bootstrapping Fusion Algorithm in Emotion
Analysis of Stock Review Texts
Xiaofang Wang, Jin Wang, Haichuan Li, Shulin Liu
and Hongjiang Liu
ABSTRACT
In view of the unclear tendency of text sentiment in stock review texts, this paper constructs a stock evaluation text sentiment analysis algorithm that combines SVM and Bootstrapping. Firstly, to obtain the data series of the stock review text to be processed, a web crawler is used to collect the content of the financial blogger's stock review website in the first half of 2019. Then the SVM algorithm is used to classify the stock review text to obtain the emotional feature words. The set is then reconstructed using the Bootstrapping algorithm to obtain a high-performance classifier. Finally, the model of the analyzed emotional feature words is evaluated. The experimental results show that compared with the traditional algorithm, the recall rate is increased by 3.3%, the accuracy rate is improved by 3.9%, and the weighted harmonic average is improved by 3.9%. The improved algorithm classification is better than the traditional one. The accuracy and recall rate are better, and the weighted harmonic mean has been greatly improved.
Xiaofang Wang, China West Normal University, Nanchong, 637002; Chengdu College of University of Electronic Science and Technology of China, Chengdu, China, Email:[email protected]
JIN Wang, China West Normal University, Nanchong, 637002,China,
Email:[email protected]
Haichuan Li, Chengdu College of University of Electronic Science and Technology of China, Sichuan Chengdu 611731, China
Shulin Liu, Chengdu College of University of Electronic Science and Technology of China, Sichuan Chengdu 611731,China
1. INTRODUCTION
With the development of Internet technology, online commentary information has abruptly increased, and how to find valuable information in massive data is particularly important [1]. Especially for stock review data, there are rich contents and unclear emotional representations. How to judge stocks through stock evaluation information has become the focus and hotspot of stockholders' attention, attracting many experts and scholars to explore. Among them, the literature [2] proposes a Chinese stock evaluation sentiment analysis method based on opinion target sentence extraction. The algorithm uses semi-supervised learning classification methods and active words to identify emotions and conduct emotion discrimination. Although the algorithm uses the characteristics of stock review articles to improve the accuracy of sentiment analysis of stock review articles, it is not suitable for emotional analysis of stock review texts at the chapter level. Literature [3] proposed a method based on text sentiment analysis to analyze the influence of online stock reviews’ tendency. The algorithm calculates the sentiment index by establishing ARMA-GARCHX model and ARMAX-GARCH model, and then analyzing the relationship between emotional factors and stock market trend in online stock reviews. Despite the results of the algorithm analysis can analyze the investor's emotional tendency and predict the stock price fluctuation, it can only analyze the current and pre-emotional emotions, and the effect on the late emotional prediction is not good. Aim at the above problems, this paper will propose a stock evaluation text sentiment analysis algorithm based on SVM and Bootstrapping. The algorithm first uses SVM algorithm to realize the construction of small class S-B classifier, then uses the Bootstrapping algorithm to expand the classifier to enhance the classification effect. Finally, the model evaluation is applied to analysis of stock recall, accuracy and F value.
2. ALGORITHM PROCEDURE
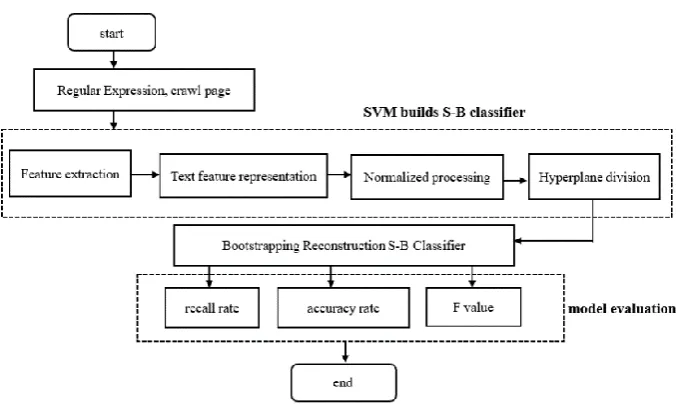
Figure 1. Algorithm flow.
2.1 Content Extraction
Through web crawling technology, this article extracts the relevant content of 22,500 articles from the financial forecasting articles written by many financial bloggers recommended by Sina blog in the first half of 2019, and integrates the dataset from the stock review texts. Then it will be used for testing and training [4].
A non-repetitive stock review article acquisition was achieved using a focused crawler module based on a specific page analysis [5]. The crawler technology adopts the modular idea and utilizes the multi-threaded task technology to satisfy the demand for the data collection of the stock review text in the greatest extent. The core module is to use the regular expression to achieve the acquisition of the stock review content [6], the formula is shown in formula (1).
𝑟𝑒 = ^[\𝑢4𝐸00 −\𝑢9𝐹𝐴5𝐴 − 𝑍𝑎 − 𝑧0 − 9_] + $ (1)
2.2 SVM Implements S-B Classifier Construction
2.2.1 FEATURE EXTRACTION
[image:4.595.99.481.314.398.2]Feature extraction is the process of segmenting text and then extracting attributes and emotional words. This paper uses the ICTCLAS word segmentation system which developed by the Chinese Academy of Sciences to implement text segmentation. After the word segmentation, since the stop words have no meaning for the stock evaluation analysis, in order to reduce the interference to the text and speed up the processing, the paper removes the stop words obtained from the data set and then extracts the features. For text feature extraction, the Java version based ICTCLAS4J is used, mainly using the My Lexicon class to describe the word segmentation module. The module members are shown in Table I.
Table I. Word segmentation module members and functions.
Participle module member functions
Sinput Input string
Ursdir User-defined dictionary path
Lctclas50 Created objects for Chinese word segmentation
AtiveBates Array of results after storing the word segmentation
Add Dictionary Add user dictionary
Text Process(str) Returns the result of the incoming str string participle
As shown in Table 1, this article uses the Add Dictionary (file Name) method to get the number of imported user words, and the Text Process (str) method for word segmentation. The obtained string is divided by spaces, and then the resource file storing the attribute dictionary and the sentiment dictionary is read. The words in the divided words and resource files will compare one by one, and the attribute words and emotional words are extracted to form the attribute word set (attrset) and emotional word set (sentset).
2.2.2 TEXT FEATURE REPRESENTATION
𝑡𝑓𝑖𝑗 = 𝑛𝑖,𝑗
∑𝑘𝑛𝑘,𝑗 (2)
Wherein, the word frequency 𝑡𝑓 indicates the frequency at which a certain word appears in the file, 𝑛𝑖,𝑗 indicates the number of occurrences of the word𝑡𝑖
in the file 𝑑𝑗, and ∑𝑘𝑛𝑘,𝑗 indicates the sum of the occurrences of all the words in
file𝑑𝑗. The sum of the occurrences of the words is calculated by using the word
frequency statistical formula, as shown in equation (3).
𝑖𝑑𝑓𝑖 = 𝑙𝑜𝑔|{𝑗:𝑡𝑖∈𝑑𝑗||𝐷| (3)
Among them, 𝑖𝑑𝑓 represents the frequency of the reverse file, which is a measure of the universal importance of a word. |𝐷| indicates the total number of files in the feature set, |{𝑗: 𝑡𝑖 ∈ 𝑑𝑗| indicates the number of files containing the word 𝑡𝑖.
Finally, the word frequency 𝑡𝑓𝑖,𝑗 and the reverse file frequency 𝑖𝑑𝑓𝑖 are
multiplied to acquire the weight of the word, as shown in equation (4):
𝑡𝑓𝑖𝑑𝑓𝑖,𝑗 = 𝑡𝑓𝑖,𝑗∗ 𝑖𝑑𝑓𝑖 (4) Substituting (3) into equation (4), the weight calculation result is obtained, as shown in equation (5):
𝑡𝑓𝑖𝑑𝑓𝑖,𝑗= 𝑙𝑜𝑔|{𝑗:𝑡𝑖∈𝑑𝑗| ∑ 𝑘𝑛𝑘,𝑗|𝐷|𝑛𝑖,𝑗 (5)
After the weight of the words is calculated by TF-IDF, a representative feature word set is selected from the stock evaluation feature set D, and then feature extraction is performed. The feature evaluation D set after feature extraction is used to achieve dimensionality reduction, and a representative feature dictionary is available.
2.2.3 NORMALIZED PROCESSING
For the stock review text, different sentiment words often have different analytical indicators. Such a situation will affect the results of the analysis. In order to eliminate the influence between the indicators, this paper standardizes (normalizes) the above results to resolve the problem of comparability between different indicators. This paper takes two strategies to achieve the procedure, one is standard normalization the other is maximum and minimum normalization. The normalization process limits the sentiment dictionary to a certain range required by this paper to eliminate the adverse effects caused by anomalous samples. After normalization, each indicator is in the same order and a small sample classifier is obtained.
2.2.4 HYPERPLANE DIVISION
the front and back sides (bullish and bearish). Then the S-dimensional vectors W and X are transposed to get the sample space feature set x and the plane space w, the transposition calculation is as shown in equations (6) and (7).
𝑥 = (𝑥1, 𝑥2, … . , 𝑥𝑑)𝑇 (6)
𝑤 = (𝑤1, 𝑤2, … . , 𝑤𝑑)𝑇 (7)
Wherein, any point x in the sample space, the distance to the hyperplane (w, b), is calculated by the distance calculation formula, as shown in equation (8).
𝑑 = 𝑤𝑡|𝑤|𝑥+𝑏 (8)
A hyperplane can divide the space in which it is located into two halves. The opposite side of the half that its normal vector points to is its front side, and the other side is its opposite side, judging the positive and negative of the hyperplane. This paper uses mathematical judgment to analyze, as shown in equation (9).
X is on A's {
𝑓𝑟𝑜𝑛𝑡,𝑊^𝑇 ∗ 𝑋 + 𝑏 > 0 𝑝𝑙𝑎𝑛𝑒,𝑊^𝑇 ∗ 𝑋 + 𝑏 = 0 𝑛𝑒𝑥𝑡,𝑊^𝑇 ∗ 𝑋 + 𝑏 < 0
} (9)
Where W represents the normal vector, so that σ = 𝑊^𝑇 ∗ 𝑋 + 𝑏, σ can be positive or negative. If the value of σ is positive larger, the representative point is positive in the plane and farther away from the plane, that is, the stronger the positive tendency of emotion. Conversely, if the value of σ is negative larger, the representative point is opposite in plane and farther away from the plane, that is, the stronger the negative tendency of emotion.
The sample feature word set S is divided into small-scale classifiers after hyperplane division. The sentiment orientation of the words is very clear and distinct, and it is divided into positive and negative categories, that is, the bullish and bearish in the field of stock evaluation.
2.3 Bootstrapping Reconstruction S-B Classifier
In the traditional SVM [6] text classification algorithm, a small-scale classifier is constructed, and the large-scale pending text U is processed by this, and the large-scale pending text U remaining in the training set D is processed by the method of calculating the semantic similarity. Due to the small size of the constructed classifier, its performance is difficult to be reliably guaranteed [7]. This paper introduces the Bootstrapping algorithm to realize the sample expansion based on the small-scale classifier. The sample feature word set S is used to construct a small-scale classifier, and the large-scale pending text U is cyclically extended to the classifier, so that the classifier is expanded to a certain scale. And enough to reliably complete the test work of the next test set.
The specific processing is as follows:
Input - training set 𝐷 = {𝑆, 𝑈}, where S is a trained text small sample data set, U is a large-scale text data set to be classified;
Let 𝑖 = 1;
Use 𝑆𝑖 to train the SVM classifier 𝐹𝑖, where i represents the number of cycles;
Partial document u is randomly extracted from𝑈𝑖, and u is classified by 𝐹𝑖 to get domain text m;
(4) Add m into the domain text set 𝑀𝑖: 𝑀𝑖+1= 𝑀𝑖+ 𝑚, and remove the
part of the document that has been trained from 𝑈𝑖: 𝑢𝑖+1 = 𝑈𝑖− 𝑢;
(5) Sort the articles in m according to the level of confidence, select the n articles with the highest confidence, and add them to the training text 𝑆𝑖+1:
𝑆𝑖+1= 𝑆𝑖 + 𝑛;
(6) u = φ, m = φ, n = φ;
(7) If i ≤ |U|/|u|, then 𝑖 + +, perform step (2), otherwise end, output F=𝐹𝑘. Since the new training set is added every time, the added training set may have errors. Therefore, the weight calculation formula is introduced into the feature word category probability formula, and the adjusted feature words belong to the category, and the formulas are as shown in equations (10) and (11). Show.
𝑤`
𝑘= 𝑤𝑘∗ 𝛿(𝑤𝑘, 𝑈𝑗 ) (10)
𝛿(𝑤𝑗, 𝑈𝑗 = {
𝛽, 𝑤𝑗 ≠ 𝑤1
1, 𝑤𝑗=𝑤1 } (11)
Where 𝑖 represents the current number of illusions and represents a weighting factor for training samples at different stages.
2.4 Model Evaluation
In this paper, the model evaluation[8] in the traditional SVM algorithm is used to evaluate the processing results, that is, the recall rate (Recall), accuracy (Precision) and F value are used to measure the effect of the improved algorithm. Among them, the recall rate is calculated as shown in equation (12).
𝑅𝑒𝑐𝑎𝑙𝑙 =𝑇𝑃+𝐹𝑁𝑇𝑃 (12)
Among them, TP indicates the number of samples in the positive propensity category that are correctly predicted to be positive, FN indicates the number of samples in the positive propensity category that are incorrectly predicted to be negative, and TP+FN indicates the number of samples in the actual positive propensity category.
Accuracy calculation, as shown in equation (13):
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃+𝐹𝑃𝑇𝑃 (13) Among them, FP represents the number of samples in the negative propensity category that are correctly predicted to be negative, and TP+FP represents the total number of samples predicted to be positive.
𝐹 =2×𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛×𝑅𝑒𝑐𝑎𝑙𝑙𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑅𝑒𝑐𝑎𝑙𝑙 (14)
As can be seen from equation (14), the accuracy rate indicates how many of the sentences actually judged to be positive in pervious speculation was positive; the F value indicates the weighted harmonic average of the recall rate and the correct rate, and the values of the two are balanced to reflect the predictive effect of the model on positive tendencies.
3 ANALYSIS OF RESULT
In this paper, the 22,500 financial bloggers in the first half of this year are the experimental data. The traditional SVM algorithm [9] and the improved algorithm proposed in this paper analyze the three evaluation parameters of the recall rate, accuracy rate and F value of the stock evaluation results in the same experimental environment. The evaluation parameters were analyzed and the results were as follows.
3.1 Recall Rates of Different Algorithm Analysis
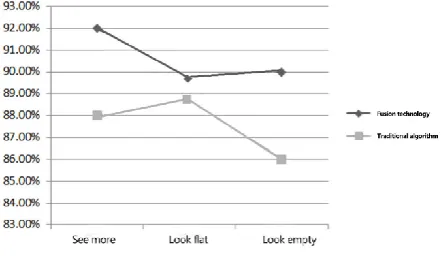
[image:8.595.182.403.465.595.2]This experiment mainly analyzes the recall rate of traditional SVM algorithm and improved algorithm in terms of seeing more, looking flat and look empty. The analysis results are shown in Figure 2.
Figure 2. Recall rate.
traditional algorithm is 86.4%, and the fusion algorithm is 3.9% higher than the traditional algorithm. The fusion algorithm has an average increase of 3.3% in recall rate of seeing more and bearish. The experimental results show that the fusion algorithm is obviously better than the traditional algorithm.
3.2 The Accuracy of Different Algorithm Analysis
[image:9.595.176.424.269.412.2]This experiment mainly analyzes the accuracy rate of traditional SVM algorithm and improved algorithm in terms of seeing more, look flat and look empty. The analysis results are shown in Figure 3.
Figure 3. Accuracy rate.
3.3 F Value of Different Algorithm Analysis
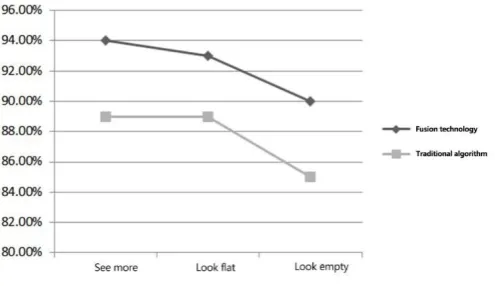
[image:10.595.181.425.167.308.2]This experiment mainly analyzes the F values of the traditional SVM algorithm and the improved algorithm in terms of seeing more, flat and look empty. The analysis results are shown in Figure 4.
Figure 4. F value.
It can be seen in Fig. 4, as the F value of the balance accuracy rate and the recall rate, after comparing the fusion algorithm with the traditional method, the F value of the fusion algorithm also exceeds the traditional method. In the seeing more case, the F-value of the fusion algorithm is 93.7%, the traditional algorithm is 88.9%, and the fusion algorithm is 4.8% higher than the traditional algorithm. In the looking flat case, the F-value of the fusion algorithm is 91.9%, the traditional algorithm is 88.7%, and the fusion algorithm is 3.2% more than the traditional algorithm. In the look empty case, the F value of the fusion algorithm is 90.3%, the traditional algorithm is 86.3%, and the fusion algorithm is 3.7% higher than the traditional algorithm. The F-value of the fusion algorithm is 3.9% higher than that of the traditional algorithm. The fusion algorithm has better processing effect and the performance of the training classifier is better. The algorithm is more reasonable than the traditional algorithm in dealing with key emotion words.
4. CONCLUSIONS
addition to being applied to stocks, the algorithm can also be applied to e-commerce, students’ public opinions, market supervision and other aspects.
ACKNOWLEDGEMENTS
Research supported by the Key Project of Education Department of Sichuan
under 13ZA0015(corresponding author: Jin Wang)
REFERENCES
1.Yujuan Yang, Huanhuan Yuan, Yongli Wang. 2019. “A sentiment analysis method for
comment texts,” Journal of Nanjing University of Science and Technology,
43(03):280-285+291.
2.Weijie Yang, Boyuan Ma, Wen Liu. 2014. “A sentiment analysis method for Chinese stocks
based on opinion target sentence extraction,” Computer Simulation, 31(03):431-436.
3.Hongwei Wang, Wei Zhang, Lijuan Zheng, Wei Lu. 2015. “The Impact of Internet Stock
Review on Stock Market Trend: A Method Based on Text Sentiment Analysis,” Journal of the
China Society for Scientific and Technical Information, 34(11):1190-1202.
4.Chengzhao Liu, Shuai Han, Mingchao Li, Yueqin Zhu. 2019. “Study on the scale prediction
analysis of gold deposits coupled with PCA-SVM algorithm,” Earth Science Frontiers,
1-8[2019-07-27].
5.Yufeng Duan, Wenjing Zhu, Qiao Chen, Hong Cui. 2014. “Research on semantic annotation of
Chinese species description text combined with naive Bayesian algorithm and Bootstrapping
method,” New Technology of Library and Information Service, 2014(05): 83-89.
6.Zhe Fu, Jun Li. 2018. “Overview of High Performance Regular Expression Matching
Algorithms,” Computer Engineering, 54(20):1-13.
7.Deyan Peng, Xinyu Hu. 2016. “Design and Implementation of SVM-based Product Comment
Sentiment Analysis System,” Internet of Things Technologies, 6(11):76-79.
8.Wei Zhang. 2018. “Analysis of Emotional Tendency of Comment Text Based on Evaluation
System,”Applied Linguistics, 2018(02):138-144.
9.Qian Mo, Yujie Zhang, Hangli Hu, Huaping Zhang. 2011. “A Mixed Analysis Method of
Stock Evaluation Perspectives,” Computer Engineering and Applications, 47(19):222-225.
10.Zhiying Hua, Meng Wu, Lijun Yang. 2019. “WSN Anomaly Detection Based on Quarter
Hypersphere SVM,” Journal of Nanjing University of Posts and Telecommunications:
1-8[2019-08-03].
11.Chuanming Yu, Feng Wang, Shasha Hu, Zhen An. 2019. “A cross-language text sentiment
analysis based on generating confrontation networks,” Information Studies: Theory &