A n A n n o t a t i o n S c h e m e for Free W o r d O r d e r L a n g u a g e s
Wojciech Skut, Brigitte Krenn, Thorsten Brants, Hans Uszkoreit
U n i v e r s i t / ~ t d e s S a a r l a n d e s66041 S a a r b r f i c k e n , G e r m a , n y
{
skut, krenn, brant s, uszkore±t }@col ±. un±- sb. de
A b s t r a c t
We describe an annotation scheme and a tool developed for creating linguistically annotated corpora for non-configurational languages. Since the requirements for such a formalism differ from those posited for configurational languages, several featu- res have been added, influencing the ar- chitecture of the scheme. T h e resulting
scheme
reflects a stratificational notion of language, and makes only minimal assump- tions about the interrelation of the particu- Jar representational strata.1 I n t r o d u c t i o n
T h e work reported in this paper aims at provi- ding syntactically annotated corpora ('treebanks') for stochastic g r a m m a r induction. In particular, we focus on several methodological issues concerning the annotation of non-configurational languages.
In section 2, we examine the appropriateness of existing a n n o t a t i o n schemes. On the basis of these considerations, we formulate several additional re- quirements. A formMism conrplying with these re- quirements is described in section 3. Section 4 deals with the t r e a t m e n t of selected phenomena. For a description of the annotation tool see section 5.
2 M o t i v a t i o n
2.1 L i n g u i s t i c a l l y I n t e r p r e t e d C o r p o r a Combining raw language d a t a with linguistic intor- mation offers a promising basis for the development of new efficient and robust NLP methods. Real- world texts annotated with difihrent strata of lin- guistic information can be used for grarninar indue- tion. The data-drivenness of this approach presents a clear advantage over tile traditional, idealised no- tion of competence grammar.
2.2 E x i s t i n g T r e e b a n k F o r m a t s
Corpora annotated with syntactic structures are commonly referred to as trt:tbauk.~. Existing tree-
bank annotation schemes exhibit a fairly uniform architecture, as they all have to meet the same basic requirements, namely:
D e s c r i p t i v i t y : GrammaticM phenomena are to be described rather than explained.
T h e o r y - i n d e p e n d e n c e : Annotations should not be influenced by theory-specific considerations. Nevertheless, different theory-specific represen- tations shMl be recoverable from the annota- tion, cf. (Marcus et al., 1994).
M u l t i - s t r a t a l r e p r e s e n t a t i o n : Clear separation of different description levels is desirable.
D a t a - d r i v e n n e s s : T h e scheme must provide repre- sentational means for all phenomena occurring in texts. Disambiguation is based on human processing skills (cf. (Marcus et at., 1994), (Sampson, 1995), (Black et al. , 1996)).
The typical treebank architecture is as follows:
S t r u c t u r e s : A context-free backboI~e is augmented with trace-filler representations of non-local de- pendencies. The underlying argum~.nt structure
is not represented directly, but can be recovered from the tree and trace-filler ammtations.
S y n t a c t i c c a t e g o r y is encoded in node IM:,els.
G r a l n m a t i c a l flinctioxls constitute a complex la- bel system (cf. (Bies et al., 1995), (Sampson, 1995)).
P a r t - o f - S p e e c h is annotated at word level.
Thus the context-li'ee constituent backbone plays a pivotal role in the annotation scherne. Due to the substantial differences between existing models of constituent structure, tile question arises of how the theory indcp~ndcnc~, requirement can be satis- fied. At this point the mlportance of the underlying
argument struc~ur¢: is emphasised (cf. (Lehmaim et al., 1996), (Marcus et al., 1994), (Sampson, 1995)).
2.3 L a n g u a g e - S p e c i f i c F e a t u r e s
solutions they offer are not always optirnal for other language types. As for free word order languages, the following features m a y cause problems:
• local a,nd ram-local dependencies tbrm a con- t i n u u m rather than clear-cut classes of pheno- mena;
• there exists a rich inventory of discontinuous constituency types (topicalisation, scrambling, clause union, pied piping, extraposition, split NPs and PPs);
• word order variation is sensitive to m a n y fac- tors, e.g. category, syntactic flmction, focus;
• the gramrn~ticMity of different word p e r m u t a - tions does not fit the tr~,ditional binary 'right- wrong' pattern; it, rather tbrms a gradual tran- sition between the two poles.
In light of these facts, serious difficulties can be ex- pected arising from the structurM component of the existing formalisms. Due to the frequency of discon- tinuous constituents in non-eonfigurational langua.- ges, the filler-trace m e c h a n i s m would be used very often, yielding syntactic trees fairly different from the underlying predicate-argument structures.
Consider the G e r m a n sentence
(1) d;tra.n wird ihn Anna. erkennen, da.t] er weint at-it will him Anita. recognise tha.t he cries 'Anna. will recognise Iron a.t his cry'
A sample constituent structure is given below:
S
~S#t
Adv~ V NP#2 NP I I V / \ daran e#1 wird ihn Anna e#e e#.~ erkennen, dass e r w e i n tT h e fairly short sentence contains three non-local dependencies, m a r k e d by co-references between tra- ces and the corresponding nodes. This hybrid repre- sentation makes the structure less transparent, and therefore more difficult to annotate.
A p a r t from this rather technical problem, two fur- ther arguments speak against phrase structure as the structural pivot of the annotation scheme:
• Phrase structure models stipulated tbr non- configura.tionM languages differ strongly from each other, presenting a challenge to the inten- ded theory-independence of the schelne.
• Constituent structure serves as an exl)la.natory device for word order variation, which is difficult to reconcile with the descriptivity requirement.
Finally, the structural handling of free word or- der means stating well-formedness constraints on structures involving m a n y trace-filler dependencies, which ha:s proved tedious. Since m o s t m e t h o d s of handling discontinuous constituents m a k e the for- naalism more powerfifl, the efficiency of processing deteriorates, too.
An Mternative solution is to make argurnent struc- ture the m a i n structural c o m p o n e n t of the forma- lism. This assumption underlies a growing num- ber of recent syntactic theories which give up the context-free constituent ba.ckbone, cf. (McCawley, 1987), (Dowty, 1989), (Reape, 1993), (Kathol and Pollard, 1995). These approaches provide an ade- quate explanation for several issues problematic ibr phrase-structure g r a m m a r s (clause union, extrapo- sition, diverse second-position phenomena).
2.4 A n n o t a t i n g A r g u m e n t S t r u c t u r e
A r g u m e n t structure can be represented in terms of unordered trees (with crossing branches). In order to reduce their a m b i g u i t y potential, rather simple, 'flat' trees should be employed, while more information can be expressed by a rich system of function labels. Furthermore, the required theory-independence means t h a t the form of syntactic trees should not reflect theory-specific assumptions, e.g. every syn- tactic structure has a unique hea.d. Thus, notions such as h e a d should be distinguished at the level of syntactic flmctions rather than structures. This re- quirement speaks against the traditional sort of d~:- p e n d e n c y trees, in which heads are represented as non-terminal nodes, cf. (Hudson, 1984).
A tree meeting these requirements is given below:
( , , ) - - -
I
Adv V NP N P V CPL NP V
daran wird ihn Anna erkennen, &tss er weint
Such a word order independent representation has the advantage of all structural ini'orrrlation being en- coded in a single d a t a structure. A unifbrm repre- sentation of local and non-local dependencies makes the structure more t r a n s p a r e n t 1 .
3 T h e A n n o t a t i o n S c h e m e
3.1 A r c h i t e c t u r e
YVe distinguish the tbllowmg levels of representation:
A r g u m e n t s t r u c t u r e , represented in terms of un- ordered trees.
G r a m m a t i c a l f u n c t i o n s , encoded in edge labels, e.g. SB (subject), MO (modifier), HD (head).
S y n t a c t i c c a t e g o r i e s , expresse(l by category la- bels assigned to non-terminal nodes and by part-of-speech tags assigned to terlninals.
3.2 A r g u l n e n t S t r u c t u r e
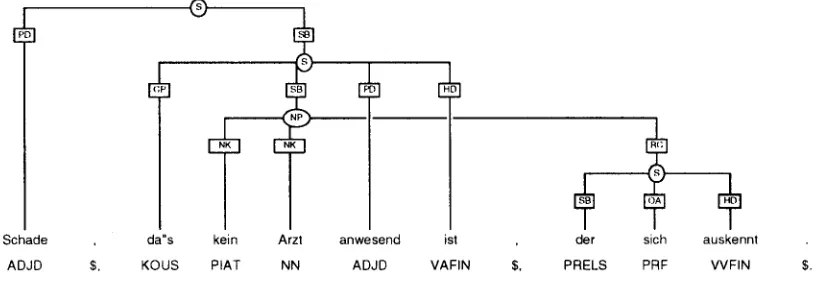
A structure for (2) is shown in fig. 2.
(2) schade, dM~ kein Arzt anwesend ist, tier pity that no doctor present is who sich auskennt
is competent
'Pity that no competent doctor is here'
Note t h a t the root node does not have a head de- scendant (HD) as the sentence is a predicative con- struction consisting of a subject (SB) and a predi- cate (PD) without a copula. T h e subject is itself a sentence in which the copula (is 0 does occur and is assigned the tag HD 2.
T h e tree resembles traditional constituent struc- tures. T h e difference is its word order independence: structural units ("phrases") need not be contiguous substrings. For instance, the extraposed relative clause (RC) is still treated as p a r t of the subject NP.
As the a n n o t a t i o n scheme does not distinguish dif- ferent bar levels or any similar intermediate catego- ries, only a small set of node labels is needed (cur- rently 16 tags, S, NP, AP . . . ) .
3.3 G r a m m a t i c a l F u n c t i o n s
Due to the r u d i m e n t a r y character of the a r g u m e n t structure representations, a great deal of reformation has to be expressed by g r a m n l a t i c a l functions. Their further classification m u s t reflect different kinds of linguistic information: m o r p h o l o g y (e.g., case, in- flection), category, dependency type (complementa- tion vs. modification), t h e m a t i c role, etc. 3
However, there is a trade-off between the granu- larity of information encoded in the labels and the speed and accuracy of annotation. In order to avoid inconsistencies, the corpus is a n n o t a t e d in two sta- ges: basic annotalion and r'efincment. While in the first phase each a n n o t a t o r has to a n n o t a t e structures as well as categories and functions, the refinement can be done separately for each representation level. During the first, phase, the focus is on almotating correct structures and a coarse-grained classification of g r a m m a t i c a l functions, which represent the follo- wing areas of information:
2CP stands for conwlementizer, OA for accusative object and RC for relative clause. NK denotes a 'kernel NP' component (v. section 4.1).
aFor an extensive use of gr;tnllnaticM functions Cf. (K~trlsson et al., 1995), (Voutilainen, 1994).
D e p e n d e n c y type: complemcnls are fllrther clas- sified according to features su(:h as category and case: clausal c o m p l e m e n t s (OC), accusa- tive objects (OA), datives (DA), etc. Modifiers are assigned the label MO (further classification with respect to t h e m a t i c roles is planned). Se- p a r a t e labels are defined for dependencies that do not fit the c o m p l e m e n t / m o d i f i e r dichotomy, e.g., pre- (GL) and p o s t n o m i n a l genitives (GR).
H e a d e d n e s s v e r s u s n o n - h e a d e d n e s s :
Headed and non-headed structures are distin- guished by the presence or absence of a branch labeled HD.
M o r p h o l o g i c a l i n f o r m a t i o n : Another set of la- bels represents morphological information. PM stands for moTThological partich, a label tbr G e r m a n infinitival zu aml superlative am. Se- parable verb prefixes are labeled SVP.
During the second a n n o t a t i o n stage, the annota- tion is enriched with information about, t h e m a t i c ro- les, quantifier scope and anaphoric ret)rence. As al- ready mentioned, this is done separately for each of the three information areas.
3.4 S t r u c t u r e S h a r i n g
A phrase or a lexical i t e m can p e r f o r m multiple func- tions in a sentence. Consider ~.qui verbs where the subject of the infinitival VP is not realised syntac- tically, but co-referent with the subject or object of the m a t r i x equi verb:
(3) er bat reich ZU kolnlnen he asked me to come
(mich is the imderstood subject of komm~.u.). In such cases, an additional edge is drawn from tim embed- (led VP node to the controller, thus changing the syntactic tree into a graph. We call such additional edges secondary links and represent t h e m as dotted lines, see fig. 4, showing the structure of (3).
4
T r e a t m e n t of S e l e c t e d P h e n o m e n a
As theory-independence is one of our objectives, the annotation scheme incorporates a n u m b e r of widely accepted linguistic analyses, especially ill the area of verbal, adverbial and adjectival syntax. However, some other s~andard analyse.s turn out to be proMe- marie, mainly due to the partial, idealised character of competence g r a m m a r s , which often margmalise or ignore such i m p o r t a n t phenolnena as 'deficient' (e.g. headless) constructions, apl)ositions, t e m p o r a l expressions, etc.
In the following paragraphs, we give annotations for a number of such phenomena.
4.1 N o u n P h r a s e s
idealised model needs severa.l additional assumpti- ons in order to account for such i m p o r t a n t pheno- m e n a as complex norninal NP components (cf. (4)) or nominalised a.djectives (of. (5)).
(4) my uncle Peter Smith (5) tier sehr (41iickliche
the very lta.ppy 'tire very ha.pl)y one'
In (4), different theories make different headedness predictions. In (5), either a lexical nominalisation rule for the adjective Gliicklichc is stipulated, or the existence of an empty nominal head. Moreover, the so-called DP analysis views the article der as the head of the phrase. Further differences concern the a.ttachment of the degree modifier ,ehr.
Because of the intended theory-independence of the scheme, we annotate only the cornmon rnini- mum. We distinguish an NP kernel consisting of determiners, a.djective phrases and nouns. All com- ponents of this kernel are assigned the label NK aml trea.ted as sibling nodes.
The diff>rence between the particular NK's lies in the positional and part-of-speech information, which is also sufficient to recover theory-specific structures frorn our 'underspecified' representations. For in- stance, the first determiner among the NK's can be treated as the specifier of the phrase. The head of the phrase can be determined in a similar way ac- cording to theory-specific assumptions.
In addition, a number of clear-cut NP components can be defined outside that juxtapositional kernel: pre- and postnorninal genitives (GL, GR), relative clauses (RC), clausal and sentential complements (OC). They are all treated as siblings of NK's re- gardless of their position (in situ or extraposed).
4.2 A t t a e h l n e n t A i n b i g u i t i e s
Adjunct a t t a c h m e n t often gives rise to structural ambiguities or structural uncertainty. However, fill or partial disambiguation takes place in context, and the annotators do not consider unrealistic readings. In addition, we have adopted a simple convention for those cases in which context information is insuf- ficient f~)r total disaml~iguat,ion: the highest possible a t t a c h m e n t site is chosen.
A similar convention has been adopted ibr con- structions in which scope ambiguities ha.ve syntac- tic effe, cts but a. one-to-one correspondence between scope a.nd attachment does not seem reasonable, cf. focus particles such a.s only or also. If the scope of such a word does not directly correspond to a tree node, the word is attached to the lowest node domi- nating all subconstituents a.pl)earing ill its scope.
4.3 C o o r d i n a t i o n
A problem for the rudimentary a.rgument structure representations is tile use of incomplete structures
in natural language, i.e. t)henornena such as coor- dination and ellipsis. Since a precise structural de- scription of non-constituent coordination would re- quire a rich inventor.), of incomplete phrase types, we have agreed on a sort of nnderspecified representa- tions: the coordinated units are assigned structures in which missing lexical material is not represented at the level of primary links. Fig. 3 shows the re- presentation of the sentence:
(6) sie wurde van preuliischen Truppen besetzt site was by Prussiaa, troops occupied und 1887 dem preutlischen Staat angegliedert and 1887 to-the Prussia.n state incorporated 'it was occupied by Prussian troops and incorpo- rated into Prussia i,t 1887'
The category of the coordination is labeled CVP here, where C stands for coordination, and VP tar the actual category. This extra, marking makes it easy to distinguish between ' n o r m a l ' and coordina- ted categories.
Multiple coordination as well a.s enumerations are annotated in the same way. An explicit coordinating conjunction need not be present.
Structure-sharing is expressed using secondary links.
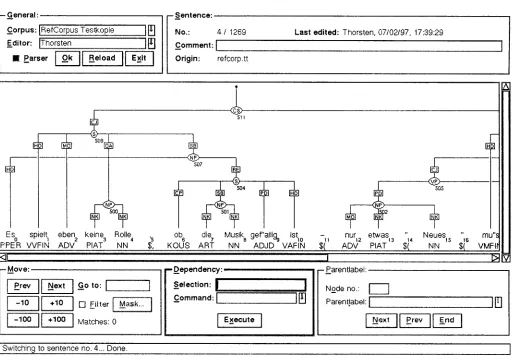
5 T h e A n n o t a t i o n T o o l
5.1 R e q u i r e n l e n t s
The development of linguistically interpreted cor- pora, presents a laborious and time-consuming task. In order to make the annotation process more effi- cient, extra effort has been put into the development of an annotation tool.
The tool supports immediate graphical feedback and automatic error checking. Since our scheme per- mits crossing edges, visualisa.tion as bracketing and indentation would be insufficient. Instead, the con> plete structure should be represented.
The tool should also permit a convenient hand- ling of node and edge hd)els. In particular, variable tagsets and label collections should be allowed.
5.2 I m p l e m e n t a t i o l l
As the need for certain flmctionalities becomes ob- vious with growing annota.tion experience, we have decided to iml)lement the tool in two stages. In the first phase, the ma.in flmctionality for buihling and displaying unordered trees is supplied. In the se- cond phase, secondary links and additional structu- ral flmctions are supported. The implementation of the first phase as described in the following para- graphs is completed.
help on c o m m a n d s and labels. In addition to pure annotation, we can attach conlments to structures.
Figure 1 shows a screen d u m p of the tool. The largest p a r t of the window contains the graphical re- presentation of tim structure being annot, ate(t. The tbllowing c o m m a n d s are available:
• group words a n d / o r phrases to a new phrase;
• ungroup a phrase;
• change the n a m e of a phrase or an edge;
• re-attach a node;
• generate the postscript o u t p u t of a sentence.
T h e three tagsets used by the annotation tool (for words, phrases, and edges) are variable and are stored together with the corpus. This allows easy modification if needed. T h e tool checks the appro- priateness of the input.
For the i m p l e m e n t a t i o n , we used T c l / T k Version 4.1. T h e corpus is stored in a SQL database.
5.3 A u t o m a t i o n
T h e degree of a u t o m a t i o n increases with the a m o u n t of d a t a available. Sentences a n n o t a t e d in previous steps are used as training m a t e r i a l for further pro- cessing. We distinguish five degrees of a u t o m a t i o n :
0) Completely m a n u a l annotation.
1) T h e user determines phrase boundaries and syntactic categories (S, NP, etc.). T h e p r o g r a m a u t o m a t i c a l l y assigns g r a m m a t i c a l fimetion la- bels. T h e a n n o t a t o r can alter the assigned tags. 2) T h e user only determines the conrponents of a new phrase, the p r o g r a m determines its syntac- tic category and the g r a m m a t i c a l functions of its elements. Again, the a n n o t a t o r has the op- tion of altering the assigned tags.
3) Additionally, the p r o g r a m performs simple bracketing, i.e., finds 'kernel' phrases.
4) Tile tagger suggests partial or cornplete parses.
So far, a b o u t 1100 sentences of our corpus have been annotated. This a m o u n t of d a t a suffices as training m a t e r i a l to reliably assign the g r a m m a t i c a l functions if the user determines the elements of a phrase and its type (step 1 of the list above).
5.4 A s s i g n i n g G r a m I n a t i c a l F u n c t i o n Labels
G r a m m a t i c a l functions are assigned using standard statistical part-of-speech tagging m e t h o d s (cf. e.g. ( C u t t i n g et al., 1992) and (Feldweg, 1995)).
For a phrase Q with children of type T . . . T~: and g r a m m a t i c a l fimctions G , , . . . , (7~:, we use the lexical probabilities
PO(GiITi)
and the contextual (trigram) probabilities
PQ(T; [Ti-,, Ti-~ )
T h e lexical and contextual probabilities are deter- mined separately for each type of phrase. During annotation, the highest rated g r a n m l a t i c a l fimction labels
Gi
a.re calculated using the Viterbi algorithnr and a.ssigned to the structure, i.e., we. <'Mculatek
argma.x H
PQ(T, IT,-1, ~_~,) . PQ(G, IT,).
G i = 1
To keep the h u m a n a n n o t a t o r f r o m missing errors m a d e by the tagger, we additionally calculate the strongest competitor for each label
Gi.
If its pro- bability is close to the winner (closeness is defined by a threshold on the quotient), the assignment is regarded as unreliable, and the a n n o t a t o r is asked to confirm the assignment.For evaluation, the already annota.ted sentences were divided into two disjoint sets, one tbr training (90% of the corpus), the other one tbr testing (10%). T h e procedure was repeated 10 times with different partitionings.
T h e tagger rates 90% of all assignments as reliable and carries t h e m out fully automatically. Accuracy for these cases is 97%. Most errors are due to wrong identification of the subject and different kinds of objects in sentences and VPs. Accuracy of the unre- liable 10% of assignments is 75%, i.e., the a n n o t a t o r has to alter the choice in 1 of 4 cases when asked ibr confirmation. Overall accuracy of the tagger is 95%. Owing to the partial a u t o m a t i o n , the average an- notation efficiency improves by 25% (from around 4 minutes to 3 minutes per sentence).
6 C o n c l u s i o n
As the annotation scheme described ill this p a p e r fo- cusses on a n n o t a t i n g argunlent structure rather t h a n constituent trees, it differs from existing treebanks in several aspects. These differences can be illustrated by a comparison with the Penn Treeba.nk annotation scheme. T h e following features of our fornlMisrn a.re then of particular i m p o r t a n c e :
* simpler (i.e. 'fiat') representation structures
• complete absence of ernl.)ty categories
• no special nlechanisnls tbr handling disconti- nuous constituency
T h e current tagset conlprises only 16 node labels and 34 function tags, yet a. finely grained cla.ssifica- tion will take place in the nea.r future.
We have argued t h a t the selected approach is bet- ter suited for producing higl, quality interpreted c o l p o r a m languages exhil)iting free constituent order. In general, the resulting interpreted d a t a also are closer to semantic annotation and more netltra.l with respect to particular synta, ctic theories.
- General:
_Corpus: [RefCorpus Teslkopie. IE] Editor: IThorsten JB
, _Parser [ - ~ 1 ~ei0ad
- Sentence:
No.: 4 / 1269
Comment: I Origin: refcorp.tt
Last edited: Thorsten, 07/02/97, 17:39:29
l
Es o spieltPPER VVFIN
509[~
S11
eben 2 keine 3 Rolle 's ob die 7 MusR 8 gef"allig 9 ist -,~ nuq2 etwasa
ADV PlAT NN $, KOUS ART 6 NN ADJD VAFIN 10 $( ADV PlAT
5O5
+
Neues mu",,
14 15 16
Move:
Matches: 0
F_Dependency:
/ Selection: I !
/ ~ o m m a n d : L ~ i .__1[ ~]
I[
i x.ou,, i
-- Paren tlabel: Node no.:
Parent!abel:IlNext II Prey
1 [ ' ~
JB
[ Switching to sentence no. 4... Done. J
Figure 1: Screen dump of the annotation tool
ring data, interpreted corpora, are a valuable re- source for theoreticzd and descriptive linguistic re- search. In a.ddition the a.t~proach provides empiri- cal material lot psycholinguistic investigation, since
preferences
for the choice of certain syntactic con- structions, linea.rizations, and atta.chments that havebeen
observed in online experiments of language pro- duction and comprehension can now be put in rela- tion with the frequency of these alterna,tives m la.rger amounts of texts.Syntactically a.nnotated corpora of German haze been missing until now. In the second phase of the project Verbnmbi] a. treebank for 30,000 German spoken sentences a.s well a.s for the S~tllle anlounl, of English ~md .]apanese sentences will be created. We will closely coordinate the further develolmlent of our corpus with the annotation work in Verbmobil and with other German efforts in corpus annotation. Since the combinatorics of syntactic constructions crea.tes a demand tbr very large corpora, efficiency of
annotation is an i m p o r t a n t criterion tbr the
success
of the developed methodology a.nd tools. Our anno- tation tool supplies efficient ma.nipulation and im- mediate visualization of argument structures. Par- tial a u t o m a t i o n included it, the current version si- gnificantly reduces the manual effort. Its extension is subject to fllrther investigations.7
A c k n o w l e d g e m e n t s
This work is part of the DFG Somlerforschungs- bereich 378 Re.~o'urc~-Adaptrm Coguitiv~, Proc~:s.~e~, Project (;3 Conc,:r'r~',.t Gramm.ar Proces.~ug.
We wish to thank Ta,nia, Avgustinova, Berthold Crysmann, La.rs Konieczny, Stephan Oepen, Karel Oliva, Christian Wei6 and two anonymous reviewers {'or their help:[ul comments on the content of this paper. We also wish to thank Robert Maclntyre and Ann Taylor for valualde discussions on the Penn Treebank annotation. Special thanks go to Oliver
[image:6.612.69.581.90.454.2]Plaehn, who implemented the annotation tool, and to our fearless annotators Roland Hendriks, Kerstin K15ckner, Thomas Schulz, and Bernd-Paul Simon.
R e f e r e n c e s
Ann Bies et al. 1995. BTuck~t, ing Guidelin~:.~ for Treebank H Slyh' Penn Treebank Project. Techni- cal report, University of Pennsylvania.
Ezra Black et al. 1996. Beyond Skeleton Par- sing: Producing a Comprehensive Large-Scale General-English Treehank With Full Grammati- cal Analysis. In Th.~: 16th Int.~:rnational Confe- rence on Computal, ional Linguistics, pages 107 - 113, Copenhagen, Denmark.
Doug Cutting, Julian Kupiec, Jan Pedersen, and Pe- nelope Sibun. 1992. A practical part-of-speech tagger. In Procteding~ o.f th( 3rd Confer~nc, ou Applied Natural Language Proc¢.ssing (ACL), pa- ges 133-140.
David Dowty. 1989. Towards a minimalist theory of syntactic structure. In Tilburg Conference on Discontinuous Constituency.
Helmut Feldweg. 1995. Implementation and evalua- tion of a German HMM for POS disambiguation. In Proceedings of EACL-SIGDAT-95 Workshop,
Dublin, Ireland.
Richard Hudson. 1984. Word Grammar. Basil Blackwell Ltd.
Fred Karlsson, Atro Voutilainen, J uha Heikkila, and Arto Anttila. 1995. (,'onstrai,.~ G'rammar. A Language-Independent System for Parsing Unre,- slricted Text. Mouton de Gruyter, Berlin, New York.
Kathol, Andreas and Carl Pollard. 1995. Extra.po- sition via Complex Domain Formation. In P~v-
ceedings of the 33 ''~ Annual M~.eting of the: ACL,
pages 174-180, C, ambridge, MA. Association for Computational Linguistics.
Sabine Lehmann et al. 1996. TSNLP - Test Sui- tes for Natural Language Processing. In Th~ 16th lnle't'national (:onf~renc~ on Computational Li~.- guistics, pages 711 - 717, Copenhagen, Denmark.
Mitchell Marcus et al. 1994. The Penn Treebank: Annotating Predicate Argument Structure. In
Proceedings of lhe Haman Language Technolog:t I Workshop, San Francisco. Morgan Kaufmann.
James McCawley. 1987. Some additional evidence for discontimfity. In Huck and Ojeda (eds.), Dis- continuous Const.iluency: Synl.a.v and Semanf.ies,
pp 185-200. New York, Academic Press.
Mike Reape. 1993. A Formal Theory o] Word Or- d~:r: A Ca.s~ ,gtudy iTt W~st. G~.r'm.,nw. P h D . the- sis, University of Edinburgh.
Geoffrey Sampson. 1995. E,gli.~h ]'or th~ Compu- ter. The SUSANNE Corp',..~ and Analytic 5'cheme.
Clarendon Press, Oxford.
Atro Voutilainen. 1994. Designing a Parsing Gram-
Sie PPER
E~
Schade ADJD
wurde VAFIN
E~
®
da"s
$. KOUS
Figure 2:
ff
E
E
kein Arzl anwesend ist der sich PlAT NN ADJD VAFIN $, PRELS PRF
Headed a,nd non-hea,ded structures, ext, ral.)osition
auskennl VVFIN
von preu'sischen APPR ADJA
®
Truppen besetzt und NN VVPP KON
1887 dem preu"sischen CARD ART ADJA
+
StaatsverbandNN
t
angeglieded WPP
Figure. 3: (',oordina,tion
EF PPER
bat VVFIN
I I I I
reich zu kommen PPER PTKZU VVINF
[image:8.612.101.559.171.652.2] [image:8.612.127.535.174.316.2]