RNA-Seq analysis and targeted mutagenesis for improved free fatty acid production in an engineered cyanobacterium
Full text
Figure
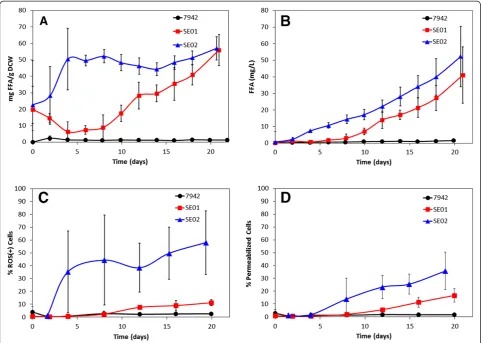

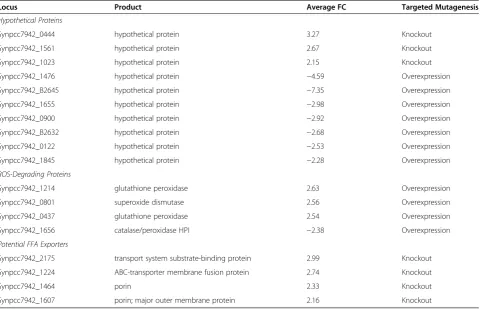
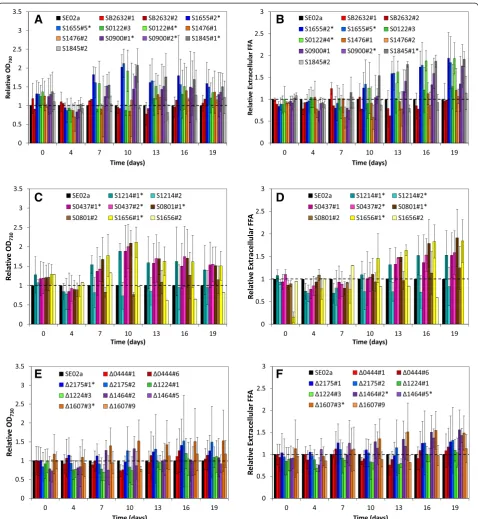
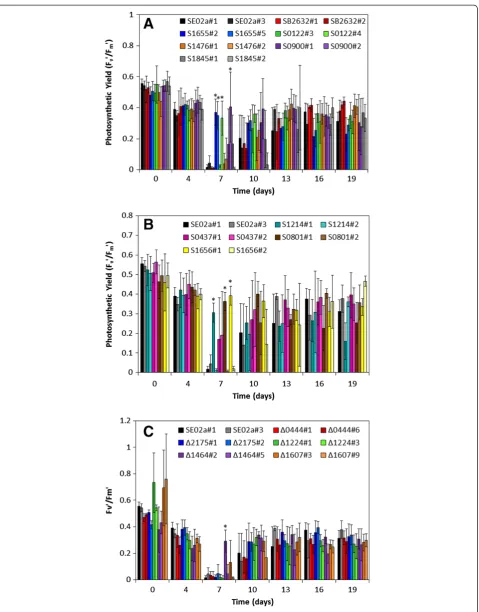

Related documents
Available Online At www.ijpret.com problems, these two dynamic methods are. also expected to be applied to
Results: ADC value of experimental group after neoadjuvant chemotherapy was higher than that before neoadjuvant chemotherapy, ADC value of experimental group before
characterized the distributions of reported pathogenic (ClinVar, Human Gene Mutation Database (HGMD)) and predicted deleterious variants in the pre-specified American College of
Previously, we screened breast cancer cell lines of various subtypes to find an accurate model for CA studies and found three Her2+ cell lines; HCC1954, JIMT- 1 and SKBR3 that
Apoptosis cannot occur in cell lines in vitro, because cell lines are immortalized by reprogramming the death program of the parental cells, because in culture there lack scavengers
We emphasize that a primary purpose of assessing children or classrooms is to improve the quality of early childhood care and education by identifying where more support,
Map-side join gave a worse time than the other two algorithms for the input with 5 million rows when then input dataset had skewed key distribution. This can be attributed to
