Auditory Sparse Representation for Robust Speaker Recognition Based on Tensor Structure
Full text
Figure
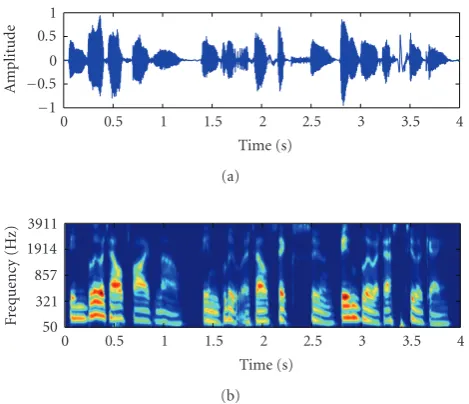


Related documents
Current incident detection approaches fall into the subsequent foremost groups: pattern recognition, time series analysis, Kalman filters, partial least squares regression [3,
The current Arts Music course in film music (MUSC 2662) deals primarily with the use of music in film dating from the 1970s and onward; at the moment there is no unit of study
Clever protocol allows Alice and Bob to increase their secrecy capacity by exchanging information over the feedback channel public authenticated.
Figure 5.16: Average connection probability given by Equation (5.6.20) for a pair of galaxies in the setup shown in Figure 5.13 with σ = 10 as a function of the line of sight
with cooperation of police and several na- tional and international academic institutes held the third international seminar on re- ducing burden of traffic accidents:
Thus, the first aim of this paper is to identify the most important and relevant DQ dimensions for the credit risk assessment task to assess the DQ level.. As we discussed in
4 plus goalkeepers on a match-derived relative pitch area evoked similar high physical loads as games with a larger number of players and a similar higher physical load than SSGs
