Personalized Image Search on Web Repository
using Partitioning Clustering Algorithm
S. Vighnesh M. Yogeshraj
Student Student
Department of Information Technology Department of Information Technology KCG College of Technology, Chennai -97 KCG College of Technology, Chennai -97
S. Sibi S. Subbulakshmi
Student Assistant Professor
Department of Information Technology Department of Information Technology KCG College of Technology, Chennai -97 KCG College of Technology, Chennai -97
Abstract
The popular search engines like Google, Yahoo, and Bing are used to search and find different type of like text documents, PDF, images and videos. Usually image based searching process are carried out using the textual information associated with it and the final result has both relevant as well as irrelevant images from the user’s point of view. The expected output from these types of system is to get relevant result. In day-to-day life searching of text and images based on keyword and queries. Search using the keyword is considered to be easy and optimal methods for retrieving text, images and other details. The outcome from such a system is not always cent percent relevant. The reasons for irrelevant search results may be due to inappropriate query and user’s wrong perception. Image re-ranking, is an efficient way to lookup the results of web-based image search. Partitioning Clustering algorithm is used to remove noisy data. The retrieved images are ranked based on text similarity. When the user will select an query image from the collection, the left over images is re-ranked based on their shape, color and texture with the query image. The given query image in the database is maintained to produce the precise search results.
Keywords: Clustering, Query-expansion, Database, Re-ranking, Image, Re-Ranking
________________________________________________________________________________________________________
I. INTRODUCTION
Nowadays the volume of digital image corpus grows drastically due to development in technology. All age group does search based on image for their understanding. The retrieving images from corpus are becoming gradually more important. Due to the rapid growth of Internet technology, World Wide Web is considered as one of the most significant sources of visual information. Proficient tools would be necessary to retrieve images from the Web. Web may be an unlimited, monstrous repossess for images, coating substantially more extensive resources, also will be expanding in an astounding velocity ceaselessly. During image retrieval the user needs to consider speed, storage, computational cost, and retrieval quality.
Data mining is an interdisciplinary subfield of computer science. It is the computational process of discovering patterns in large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics, and database systems. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. Data mining is the analysis step of the “Knowledge discovery in Databases” process or KDD.
Image re-ranking is a useful method for web-based image search. The search based on only keywords queried by the users is not efficient and results in imprecise output. The web-based image search used by Bing and Google uses image re-ranking. In image re-ranking, users' intention is captured by one-click on the query image. This helps in providing better search results to the users. The method in which a query keyword is initial used to retrieve a plethora of images based on the keyword.
Image re-ranking framework automatically learns different semantic spaces offline for different query keywords. To get semantic signatures for images and related details, their visual feature are projected into the specifically related semantic signature spaces. Images are re-ranked by comparing their semantic signatures and the query keyword during the online stage. The query-specific semantic signatures, in the reviewed paper, significantly improve both the accuracy and efficiency of the re-ranking process. Hence, it is proved to be a better method than the conventional web-based image search techniques [1].
a collection of images based on textual information of the given query keyword. The retrieved images are ranked based on text similarity. When the user selects a query image from the collection, the left over images is re-ranked based on their shape, color and texture with the query image. For a given query image in the database is maintained to produce the precise search results.
II. RELATED WORK
The system mainly focus on personalized image search on web repository using portioning algorithm with optimizes the performance of existing search engine. The purpose is to carry out the different tasks in the system. Different benefits include improved speed of the search, reliable data extraction using image search and clustering.
Some clustering and data mining strategies may use different algorithm to cluster the data to improve search. Fulfillment of the user will be improved if re-ranking is used as an important factor. Image re-ranking, is an efficient way to lookup the results of web-based image search. Clustering algorithm is used to remove noisy data. System retrieves a collection of images based on textual information of the given query keyword.
That image re-ranking, as an effective way to improve the results of web-based image search, has been adopted by current search engines such as Bing and Google[2]. Given a query keyword, pools of images are initial retrieved based on textual information. By asking the user to select a query image from the pool, the remaining images are re-ranked based on their visual similarities with the query image. A major challenge is that the similarities of visual features do not well correlate with images semantic meanings which interpret users search. Recently people proposed to match images in a semantic space which used attributes or reference classes closely related to the semantic meanings of images as basis. However, learning a universal visual semantic space to characterize highly diverse images from the web is difficult and inefficient. A novel image re-ranking framework, which automatically offline learns different semantic spaces for different query keywords can be used. The visual features of images are projected into their related semantic spaces to get semantic signatures.
Image re-ranking is a useful method for web-based image search. The search based on only keywords queried by the users is not efficient and results in imprecise output. The web-based image search used by Bing and Google uses image re-ranking. In image re-ranking, user’s intention is captured by one-click on the query image. This helps in providing better search results to the users. Reviewing the method in which a query keyword is initial used to retrieve a plethora of images based on the keyword.
Image re-ranking framework automatically learns different semantic spaces offline for different query keywords. To get semantic signatures for images their visual features are projected into their related semantic spaces[1].
The internet is one of the fastest embryonic areas of information gathering. Web users leave many records of their doings in the form of data while working on internet. The huge amount of these data is used as a row material for information and knowledge gathering. Proper mining processes are needed for this information. Web usage mining, also known as Web Log Mining, is the process of extracting interesting patterns in web access logs. Web servers record and collect data about user interactions whenever desires for resources are received. Analyzing the web access logs of different web sites can help understand the user behavior and the web structure, thereby improving the design of this huge collection of resources. Web server log files and customers navigation data that can be mined meaningfully and user access patterns is forecast to identify web user’s behavior [3].
III. ALGORITHM USED
Clustering Algorithm Employ in Web Usage Mining. Clustering can be considered the most important unsupervised learning technique; as every other problem of this kind, it deals with finding a structure in a collection of unlabeled data.
Clustering is whose members are similar in some way. A cluster is therefore a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters. There are four types of clustering methods namely: Distance-based ,Hierarchical, Partitioning, Probabilistic. From the above methods, the optimal method for personalized image search on web repository is partitioning clustering algorithm. Divide data into proper subset and relocate points between clusters.
Psuedo Code For Partitioning Clustering Algorithm
- Instances set (s), number of cluster (k) and threshold which is used to assign an instance to a cluster. - The Output is formation of “clusters.”
- Clusters are a group of relevant or related details. - A FOR loop is been used for clusters.
- FOR all clusters, if the keyword (Threshold) less or equal to a cluster then update cluster. - Increment the cluster group if incremented and end the IF and FOR loop.
- IF NOT, the keyword is sent to the next new cluster.
Input: S (instances set), K (number of clusters), Threshold (for assigning an instance to a cluster) Output: clusters
3) As_F - false
4) for all Cluster € Clusters do
5) if ||xi - centroid(Cluster)|| < threshold then 6) Update centroid(Cluster)
7) ins_counter(Cluster) + + 8) As_F - true
9) Exit loop 10) end if 11) ii endfor
12) If not(As_F) then 13) centroid(newCluster) - Xi 14) ins_counter(newCluster) - 1 15) Clusters ← Clusters υ newCluster 16) end if
17) end for
K- means algorithm
It accepts the number of clusters to group data into, and the dataset to cluster as input values. It then creates the initial K initial clusters from the dataset by choosing K rows of data randomly from the dataset.
Psuedo Code For K –Means Algorithm:
- Input is the set of entities to be clustered (E), number of clusters (k) and max iterations. - Output is the set of centeroids i.e keyword along with the clusters.
- FOR each set of cluster (ci) random selection is done.
- FOR all set of entities to be clusted argument Distance is to be calculated. - FOR each ci update cluster set.
- FOR each entity set find the minimum distance of the argument.
- IF minDist between the keyword and entity set is not equal to the length of argDistance then set minDist. - Increment the iteration if true every time the process is performed.
Input: E = {e1, e2 , ..., en} (set of entities to be clustered) k (number of clusters)
MaxIters (limit of iterations)
Output: C = {c1, C2, ... ,Ck } (set of cluster centroids) L = {l(e) | e = 1,2,...,n}(set of cluster labels of E) foreach ci € C do
| ci ← ej € E (e.g. random selection) end
foreach ej € E do
| (ei) ← argminDistance(ei,cj) j € {1...k} end
changed ← false; iter ← 0;
repeat
foreach ci € C do UpdateCluster(ci); end
foreach ei € E do
minDist ← argminDistance(ei,cj)j € {1...k}; if minDist ≠ l(ei),then
1(ei) ← minDist; changed ← true; end
end iter ++;
IV. PROPOSED WORK
Search engines like Google, Yahoo, and Bing are used to search and find different type of like text documents, PDF, images and videos. Image based search is carried out using the textual information associated with it and the final result contains both relevant as well as irrelevant images from the user’s point of view. The expected output from such a system is to get relevant result. In day-to-day life searching of text and images based on keyword. Searching by keyword is considered to be easy and capable methods to retrieve text and images. The outcome from such a system is not always cent percent relevant. The reasons for irrelevant search results may be due to inappropriate query and user’s wrong perception. Image re-ranking techniques are used to tackle the issues. Fulfillment of the user will be improved if re-ranking is used as an important factor. Image re-ranking, is an efficient way to lookup the results of web-based image search. Clustering algorithm is used to remove noisy data. System retrieves a collection of images based on textual information of the given query keyword. The retrieved images are ranked based on text similarity. When the user opts for a query image from the collection, the left over images is re-ranked based on their shape, color and texture with the query image. For a given query image in the database is maintained to produce the precise search results.
Architecture Diagram
Fig. 1: Architecture diagram of personalized image search using partitioning clustering algorithm
V. IMPLEMENTATION AND RESULT
Search query is entered by user. Pre-processing for the given query will be done. After pre-processing is done system will check the query in database.
Fig. 2: Layout of search engine
Fig. 3: Layout of output page
In Fig 3 images are re-ranked based on query image. The system will retrieve a pool of images if the keyword is not found in database. The user needs to select an image which will act as query image for the given text. User selects the image which the user feels is appropriate for the given text. The query images are compared with the database images based on semantic signature. After comparison the images are arranged according to their ranking score. Distances between semantic signature is computed. Performance is evaluated for precision, recall and f- measures using clustering algorithm.
VI. MEASURING SEARCH EFFECTIVENESS
Search engine effectiveness can be measured using techniques such as: Precision, Recall, F-measure and false negative rate.
Fig. 4: Recall calculation
RECALL is the ratio of the number of relevant records retrieved to the total number of relevant records in the database. It is usually expressed as a percentage.
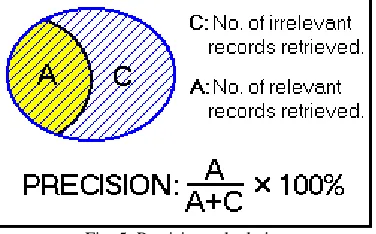
Fig. 5: Precision calculation
PRECISION is the ratio of the number of relevant records retrieved to the total number of irrelevant and relevant records retrieved. It is usually expressed as a percentage.
The false negative rate (FNR):
It is the proportion of positives cases that were incorrectly classified as negative, as calculated using the equation: FNR = B / A+B
Assume the following: There are 5 Given keywords. Each keyword contains 30 images associated with it. A total of 150 images are stored in the database.Calculate the precision, recall and F-measure scores for the search.
Using the designations in the system, it produces a Recall value of 76% and precision value of 33.3% . The system produces an F-measure value of 99.7%
VII. FUTURE WORK
In the near future personalized image search on a web repository using partitioning clustering algorithm can be implemented in commercial search engines such as google, yahoo and Bing.
VIII. CONCLUSION
Uploading images, keyword, description and hyper-links in a Database by the admin. When the user is typing a keyword in the search engine, it immediately shows a set of images. Then according to the user’s intension image and the details related to the images will be shown. Also hyperlinks related to that image will be shown. Text based image retrieval is not enough to satisfy user expected result. The implementation consist of initially images are retrieved based on given keyword. Then the system captures user’s intention and retrieves images by comparing semantic signature of images which are stored. It also maintains the database statistics of keyword and query image which makes it computationally superior and improves retrieved results. Finally, Precision and Recall performance metrics are used to evaluate search results.
REFERENCES
[1] Harshil Jain , Riya Lodha and Khushali Deulkar ,IMPRESSCO describing Web-based Image Search using Image Re-Ranking Technique on Vol .4, No.5
(Oct 2014).
[2] Xiaogang Wang, Member, IEEE , Shi Qiu, Ke Liu, and Xiaoou Tang, Fellow, IEEE describing “Web Image Re-Ranking Using Query-Specific Semantic
Signature on VOL. 36, NO. 4, APRIL 2014.