Available at http://www.ijcsonline.com/
Text Summarization using Neural Network Theory
Simran Kaur Jolly1, Wg Cdr Anil Chopra2
1
Department of CSE, Lingayas University, Faridabad Haryana, India
2Assistant Professor, MRIU, Faridabad, Haryana, India
Abstract
The idea of neural is based on the belief that working of human brain by making the right connections can be copied using silicon and wires as living neurons and dendrites. The human brain is composed of billion nerve cells called neurons. They are connected to each other cells by Axons. Stimuli from external environment or inputs from sensory organs are accepted by dendrites. These inputs create electric impulses, which quickly travel through the neural network. A neuron can then send the message to other neuron to handle the issue or does not send it forward. It is a new technique for summarizing corpus of articles using a neural network. A neural network is trained to learn the relevant characteristics of sentences that should be included in the summary of the article. The neural network is then modified to generalize and combine the relevant characteristics apparent in summary sentences. Finally, the modified neural network is used as a filter to summarize news articles. Since digitally stored information is more and more available, users need suitable tools able to select, filter, and extract only relevant information. Text summarization can be categorized into two approaches: extraction and abstraction. This paper focuses on extraction approach. The goal of text summarization based on extraction approach is sentence selection. One of the methods to obtain the suitable sentences is to assign some numerical measure of a sentence for the summary called sentence weighting and then select the best ones among them. A summary text is a derivative of a source text condensed by selection and/or generalization on important content. Query-focused summaries enable users to find more relevant documents more accurately, with less need to consult the full text of the document. Extractive summarization methods try to find out the most important topics of an input document and select sentences that are related to these chosen concepts to create the summary. This paper is a study of neural used for extractive summarization, namely, Neural Network.
Keywords: Adaptive clustering, feature fusion, neural networks, pruning, text summarization.
I. INTRODUCTION
Earlier, a large amount of research papers and books have been digitally stored. However, the storage media to store such a large database was very expensive. Therefore the concept of automatic summarization was introduced to store the information about papers and books in limited storage space. But due to large amount of information available on the web, there is a need to represent each document by its summary to save time and effort for searching the correct information. In summary, the following are the important reasons in context of automatic text summarization: 1) A summary or abstract saves time 2) A summary or an abstract facilitate document selection and literature searches. 3) It improves document indexing efficiency 4) Machine generated summary is free from bias 5) Customized summaries can be useful in question answering systems where they provide personalized information. 6) The use of automatic or semi-automatic summarization by commercial abstract services may allow them to scale the number of published texts they can evaluate. Automatic document summarization is extremely helpful in tackling the information overload problems. It is the technique to identify the most important pieces of information from the document, omitting irrelevant information and minimizing details to generate a compact coherent summary document. There are different types of summarization approaches depending on what the summarization method focuses on to make the summary of
the text [2]. 1) Abstract vs. Extract summary - Abstraction is the process of paraphrasing sections of the source document whereas extraction is the process of picking subset Ease of Use of sentences from the source document and presents them to user in form of summary that provides an overall sense of the documents content. 2) Generic vs. Query-based summary - Generic summary do not target to any particular group. It addresses broad community of readers while Query or topic focused queries are tailored to the specific needs of an individual or a particular group and represent particular topic. 3) Single vs. Multi-document summary - Single document summary provide the most relevant information contained in single document to the user that helps the user in deciding whether the document is related to topic of interest.
not sufficient to convey their important points. Therefore, a summarization tool for news articles would be extremely useful, since for given news topic or event, there are a large number of available articles from the various news agencies and newspapers. Because news articles have a highly structured document form, important ideas can be obtained from the text simply by selecting sentences based on their attributes and locations in the article. We propose a machine learning approach that uses artificial neural networks to produce summaries of arbitrary length news articles. A neural network is trained on a corpus of articles. The neural network is then modified, through feature fusion, to produce a summary of highly ranked sentences of the article. Through feature fusion, the network discovers the importance (and unimportance) of various features used to determine the summary-worthiness of each sentence.
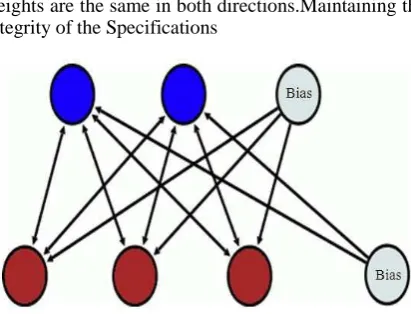
A. Restricted Boltzmann Machine: is a stochastic neural network (that is a network of neurons where each neuron has some random behavior when activated). It consist of one layer of visible units (neurons) and one layer of hidden units. Units in each layer have no connections between them and are connected to all other units in other layer (Fig. 1). Connections between neurons are bidirectional and symmetric. This means that information flows in both directions during the training and during the usage of the network and those weights are the same in both directions.Maintaining the Integrity of the Specifications
II. TEXT SUMMARIZATION WITH NEURAL NETWORKS In this technique, firstly, each document is first converted into sentences. Each sentence is represented as a vector [f1, f2... f7], composed of 7 features. Considering a machine learning approach, that uses artificial neural networks to produce summaries of news articles. News articles have a highly structured document form; important ideas can be obtained from the text simply by selecting sentences based on their attributes and locations in the article. A neural network is trained on a corpus of articles. The neural network is then modified, through feature fusion, to produce a summary of highly ranked sentences of the article ie most frequently occurring sentences. Through feature fusion, the network discovers the relevance of various features used to determine the summary-worthiness of each sentence [4]. Seven Features of a Document 1) f1
Paragraph follows title 2) f2 Paragraph location in document 3) f3 Sentence location in paragraph 4) f4 First sentence in paragraph 5) f5 Sentence length 6) f6 Number of thematic words in the sentence 7) f7 Number of title words in the sentence Feature f5, sentence length, is useful for filtering out short sentences such as datelines and author names commonly found news articles. It is also anticipated that short sentences are not to be included in summaries. Feature f6, the number thematic words, indicates the number of thematic words in the sentence, relative to the maximum possible. It is obtained as follows: from each document, remove all prepositions, and reduce the remaining words to their morphological roots. Abbreviations and Acronyms
The resultant content words in the document are counted for occurrence. The top 10 most frequent content words are considered as thematic words. This feature determines the ratio of thematic words to content words in a sentence. This feature is expected to be important because terms that occur frequently in a document are probably related to its topic. Therefore, a high occurrence of thematic words in salient sentences is expected. Finally, feature f7 indicates the number of title words in the sentence, relative to the maximum possible. It is obtained by counting the number of matches between the content words in a sentence, and the words in the title. This value is then normalized by the maximum number of matches. This feature is expected to be important because the importance of a sentence may be affected by the number of words in the sentence also appearing in the title. These features may be changed or new features may be added. The selection of features plays an important role in determining the type of sentences that will be selected as part of the summary and, therefore, would influence the performance of the neural network. There are mainly two different phases in this system.
discover the trends and relationships among the features that are inherent in the majority of sentences.
This is accomplished by the feature fusion phase, which consists of two steps: 1) eliminating uncommon features; and 2) collapsing the effects of common features. The connections having very small weights after training can be pruned without affecting the performance of the network. As a result, any input or hidden layer neuron having no emanating connections can be safely removed from the network. In addition, any hidden layer neuron having no abutting connections can be removed. This corresponds to eliminating uncommon features from the network
2) Sentence Selection: Once the network has been trained, pruned, and generalized, it can be used as a tool to filter sentences in any paragraph and determine whether each sentence should be included in the summary or not.
Figure 2. block diagram
This phase is accomplished by providing control parameters for the radius and frequency of hidden layer activation clusters to select highly ranked sentences. The sentence ranking is directly proportional to cluster frequency and inversely proportional to cluster radius. Only sentences that satisfy the required cluster boundary and frequency are selected as high-ranking summary sentences.
Features of Each document are converted into a list of sentences. Each sentence is represented as a vector [f1, f2... f7], composed of 7 features. Seven Features of a Document f1 f2 f3 f4 f5 f6 f7 Paragraph follows title Paragraph location in document Sentence location in paragraph First sentence in paragraph Sentence length Number of thematic words in the sentence Number of title words in the sentence Features f1 to f4 represent the location of the sentence within the document, or within its paragraph. Feature f5, sentence length, is useful for filtering out short sentences such as datelines and author names commonly found in news articles. We also anticipate that short sentences are unlikely to be included in summaries [3]. Feature f6, the number of thematic words, indicates the number of thematic words in the sentence, relative to the maximum possible.
III. TEXT SUMMARIZATION PROCESS
A. Proposed Deep Learning Approach
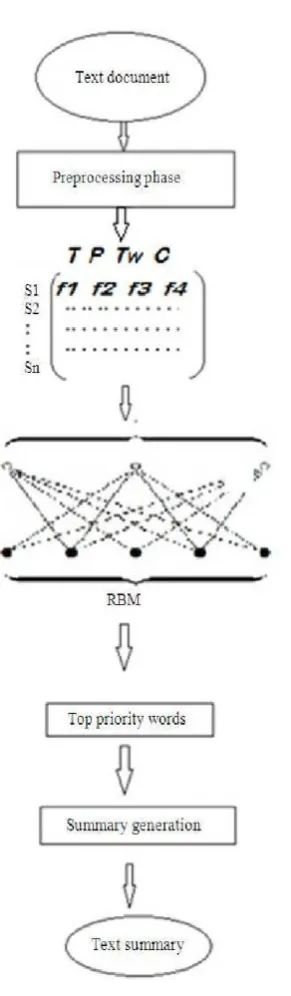
Text summarization technique is divided into two approaches extractive and abstractive. But due to the limitation of natural language generation techniques in generating the abstractive summary generally extractive approach is used for summarization. For summarizing the text there is a need of structuring the text into certain model which can be given to RBM as input. First of all in text summarization the text document is preprocessed using various prevalent preprocessing techniques and then it is converted into sentence matrix defined over a vocabulary of words. This structured matrix each row will work as a input to our RBM (Fig. 2). After getting the set of top priority word from the RBM the input query, sentence vector and high priority word output is compared to generate the extractive summary of the text document.
B. Preprocessing
To make the document light (not containing unwanted words) preprocessing of the text document for structuring is done by applying various techniques developed by the linguist. There are myriads of technique by which we can reduce the density of text document. In this study we are using the following techniques.
C. Part of Speech Tagging
tagging like hidden Markova models, using dynamic programming.
D. Stop Word Filtering
Stop words are the words which are filtered out prior to or after the preprocessing task generally there is no specific rule on aparticular word to be stop word, it is completely subjective depends upon the situation. In our condition we considering words like a, an, in by as stop word and filters this word from the original document. Stop word filtering is the standard filtering in text mining applications.
E. Stemming
Another important technique we need to apply is stemming. Stemming is process of bringing the word to its base or root form for example using words singular form instead of using the plural (using boys as boy), removing the ‘ing’ from verb (changing doing to do). There are number of algorithms, generally referred as stemmers’, are there that can be used to perform the stemming.
F. Feature Vector Extraction
After reducing the density of document is structured into a matrix. A sentence matrix S of order n*v is containing the features for every sentence of a matrix. For very informative summarization we are extracting four features of a sentence of text document viz similarity with title, relative position of sentence, term weight of words forming sentences, concept-extraction of sentence. Sentence matrix row vector represents the sentence which is making the document and column vector contains the entry for these extracted features.
G. Feature Computation
A sentence is considered important if it’s similar to the title of text document. Here similarity is considered on the basis of occurrence of common words in title and sentence. A sentence has good feature score if it has maximum number of words common to the title. The ratio of the number of words in the sentence that occur in title to the total number of words in the title helps to calculate the score of a sentence for this feature. It is calculated by:
f1 st t
Where:
S = Set of words of sentence
T = Set of words of title
st = Common words in sentence and title of document
H. Positional Feature
Positional value of a sentence is also extracted. A sentence is relevant or not can also be judged by its position in the text. To calculate the positional score of sentence we are considering the following conditions:
f2 = 1, if sentence is the starting sentence of the text f2 = 0, if sentence comes in the middle paragraphs of
Text
f2 = 1, if sentence comes in the last of the text
I. Term Weight
This is another very important feature to be consider for summarization of text. Here by term weight we simply mean the term frequency and its importance. This is the most standard feature considered in various natural language processing tasks. The frequency here is the term frequency which reflects the importance of a word in a document, it simply tells number of times a word appears in the text. The term frequency of a word will be given by tf(f,d) where f is the frequency of the word and d is text the document. The total term weight is calculated by computing tf(f,d) and idf for a document. Here idf refers to inverse document frequency which simply tells about whether the term is common or rare across all documents. It is obtained by dividing the total number of documents by the number of documents containing the term and then taking the log of that quotient. The idf is given by:
idf
t, D
log D d D : t dwhere, D is the total number of documents, D: td, it is the number of documents where term t appears. The total term weight is given by tf*idf which can be calculated by:
tf * idf (t,d,D) = tf (t,d )* Idf (t,D) f 3 =tf * idf .
J. Concept Feature
The concept feature from the text document is extracted using the mutual information and windowing process. In windowing process a virtual window of size ‘k’ is moved over document from left to right. Here we want to find out the co-occurrence of words in same window and it can be calculated by following formula:
MI(w i , w j ) log 2
P(w i , w j )
P(w i ) * P(w j )
where, P(wi, wj)- Joint probability that both keyword appeared together in a text window.
P(wi)- probability that a keyword wi appears in a text window and can be computed by:
f1 st t
Where:
U = Set of words of sentence
V = Set of words of title
st = Common words in sentence and title of document
P(wi ) swt
sw
Where:
|sw| = Total number of windows constructed from a text document
The sentence matrix generate by above steps is:
S1T P Tw C
S2f1 f 2 f 3 f 4
. .. ... ..
. .. ... ..
..
Sn ... .. ..
K. Sentence Matrix
Here sentence matrix S = (s1, s2,……..s n) where si = (f1, f2,……..f4), i<= n is the feature vector.
L. Deep Learning Algorithm
The sentence matrix S = (s1, s2,……..s n) which is the feature vector set having element as si which is set contains the all the four features extracted for the sentence si. Here this set of feature vectors S will be given as input to deep architecture of RBM as visible layer. Some random values is selected as bias Hi where i = 1,2 since a RBM can have at least two hidden layer. The whole process can be given by following equation:
S s1 ,s2 ...sn
where, si = (f1,f2,……..f 4), i<= n where n is the number of sentences in the document. Restricted Boltzmann machine contains two hidden layers and for them two set of bias value is selected namely H0H1:
H 0
h 0 , h 1 , h
2 ...hn
H1
h 0 , h 1 ,h
2 ...hn
These set of bias values are values which are randomly selected. The whole operation of Sentence matrix is performed with these two set of randomly selected value. The whole operation with RBM starts with giving the sentence matrix as input. Here s1,s2,……..s n are given as input to RBM. The RBM generally have two hidden layers as we mentioned above.
Two layers are sufficient for our kind of problem. To get the more refined set of sentence features. RBM works in two step. The input to first step is our set of sentence matrix, S = (s1,s2,……..s n), which is having the four features of sentence as element of each sentence set. During the first cycle of RBM a new refined sentence matrix set:
s '
s ' ,s ' ,...s '
1 2 n
The above expressed s’is generated by performing:
P(wi ) swt
/sw
Where:
swi = The number of windows containing the keyword wi
|sw| = Total number of windows constructed from a text document
s '
s ' ,s ' ,...s '
1 2 n
The above expressed s’ is generated by performing:
n ∑si hi
1
During step 2 the same procedure will be applied to this obtained refined set to get the more refined sentence matrix set with H1 and which is given by:
s" s"1 ,s"2 ,...s"n
After obtaining the refined sentence matrix from the RBM it is further tested on a particular randomly generated threshold value for each feature we have calculated. For example we select threshold thrc as a threshold value for the extracted concept-feature. If for any sentence f4<thr then it will be filtered and will become member of new set of feature vector.
Step 1. s1 ,s2 ⋯,sn
[f1,f 2,f 3,f 4] [f1,f 2,f 3,f 4] [f1,f 2,f 3,f 4]
ց ւ
n
∑s i h i (H 0 ) 1
s ' (s1' ,s2'⋯,sn' )
Step 2. s1' ,s2'⋯,sn'
[f1,f 2,f 3,f 4] [f1,f 2,f 3,f 4] [f1,f 2,f 3,f 4]
ց ւ
n
∑s i h i (H1 ) 1
s ''
'' '' ''
) (s1 ,s2 ⋯,sn
M. Optimal Feature Vector Set Generation
vector set optimally we use back propagation algorithm. Back propagation algorithm is well known method to adjust the deep architecture to find good optimum feature vector set for the precise contextual summary of text. The deep learning algorithm in this phase uses cross-entropy error to fine tune the obtained feature vector set. The cross-entropy error for adjustment is calculated for every feature of the sentence
.For example term weight feature of the sentence will be reconstruct by using following formula:
[ ∑ v fv log fv ∑ v (1 fv )log(1 fv )]
Where:
fv = The tf value of vth word fv^ = The tf value of reconstruction
In this way all three features will be optimized.
N. Summary Generation
In summary generation phase, the obtained optimal feature vector set is used to generate the extractive summary of the document. For summary generation first task is obtaining the sentence score for each sentence of document. Sentence score is obtained by finding the intersection of user query with the sentence. After this step ranking of the sentence is performed and the final set of sentences for text summary generation defining the summary is obtained.
O. Ranking of Sentence
This is the final step to obtain the summary of text. Here ranking of the sentence is performed on the basis of the sentence score obtained in previous step. The sentences are arranged in descending order on the basis of the obtained sentence score. Out of these sentences top-N sentences are selected on the basis of compression rate given by the user. To find out number of top sentences to select from the matrix we use following formula based on the compression rate.
It is given by:
N CNS 100
Where:
Ns = Number of sentences in document
C = Compression rate
[f1,f 2,f 3,f 4] [f1,f 2,f 3,f 4] [f1,f 2,f 3,f 4]
ց ւ
n
∑
s i h i (H1 )1
s ''
'' '' ''
)
(s1,s2⋯ ,sn
IV. RESULTS AND ANALYSIS
We used 50 news articles from the Internet with various topics such as technology, sports, and world news to train the network. Each article consists of 16 to 89 sentences with an average of 29 sentences. The entire set consists of 1,435 sentences. Every sentence is labeled as either a summary sentence or an with an average of 6 sentences per article. After the feature fusion phase, f
1 (Paragraph
follows title) and f
4 (First sentence in the paragraph) were
removed as well as two hidden layer neurons. The removal of f
1 feature is understandable, since most of the
articles did not have sub-titles or section headings. Therefore, the only paragraph following a title would be the first paragraph, and this information is already contained in feature f
2 (paragraph location in document).
The removal of f
4 feature indicates that the first sentence
in the paragraph is not always selected to be included in the summary. We then used the same 50 news articles as a test set for the modified network. The accuracy of the modified network ranged from 94% to 100% with an average accuracy of 96.4% when compared to the summaries of the human reader. That is, the network was able to select all sentences that were labeled as summary sentence in most of the articles. However, the network missed one to two sentences in six of the articles and selected one sentence that was not labeled as summary in each of five articles. The performance of the text summarization process depends heavily on the style of the human reader and to what the human reader deems to be important to be included in the summary.
A human reader and the modified network summarized 10 different news articles, independently. The performance of the modified network was 96% accurate when compared with the human reader’s summaries. For each article, 4 to 9 sentences were selected by the network as summary sentences with an average of 5 sentences. Both the human reader and the modified network summarized 7 of the articles exactly the same. For two of the articles, the modified network missed one sentence in each article; and for one of the articles, the modified network included a sentence that was not selected by the human reader.
V. CONCLUSIONS
REFERENCES
[1] Ms. Sonali. B. Maind, “Research Paper on Basic of Artificial Neural Network”, International Journal on Recent and Innovation Trends in Computing and Communication, Volume: 2 Issue: 1, pp: 96 – 100.
[2] P.B. Baxendale, “Machine-Made Index for Technical Literature: An Experiment ”, IBM Journal of Research and Development, vol. 2(4), pp. 354-361, 1958.
[3] J. Kupiec, J. Pederson and F. Chen, “A Trainable Document Summarizer”, Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, Washington, pp. 68-73, 1995.
[4] M. Porter, “An algorithm for suffix stripping”, Program, vol. 14(3), pp. 130-137, 1980.
[5] H.P. Luhn, “The Automatic Creation of Literature Abstracts”, IBM Journal for Research and Development, vol. 2(2), pp. 159-165, 1958.
[6] M.R. Hestenes and E. Stiefel, “Methods of conjugate gradients for solving linear systems”, Journal of Research of the National Bureau of Standards, vol. 49, pp. 409-436, 1952.
[7] I. Mani, Automatic Summarization, John Benjamins Publishing Company, pp. 129-165, 2001.
[8] W.T. Chuang and J. Yang, “Extracting sentence segments for text summarization: a machine learning approach”, Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, pp. 152-159, 2000.
[9] C-Y. Liu and E. Hovy, “Identifying Topics by Position”, Proceedings of the 5th Conference on Applied Natural Language Processing (ANLP- 97), Seattle, Washington, pp. 283-290, 1997 [10] K. Sparck Jones, “A Statistical Interpretation of Team Specificity