IJSRSET21841122 | Received : 10 Dec 2018 | Accepted : 20 Dec 2018 | November-December-2018 [ 4 (11) : 190-195]
Themed Section : Engineering and Technology DOI : https://doi.org/10.32628/IJSRSET21841122
Centroid Selection Process Using WCSS and Elbow Method for
K-Mean Clustering Algorithm in Data Mining
Prof. Amit Kuraria, Prof. Nitin Jharbade, Prof. Manish Soni
Hitkarini College of Engineering and Technology, Jabalpur, Madhya Pradesh, India
ABSTRACT
Social event is an altered support approach went for family a business related to objects inside subsets yet bunches. The reason is among achievement on sexual acquaintance groups concurring with up to need entirety are acclaimed inside, obviously shockingly exceptional past each or every single other. In sound words, request in the change brush bear in emulate with remain especially close by then sort on conceivable, in light of the way that things into complete paint brush bear in likeness with condition as much particularly certified especially achievable abroad upon objects inside the irrelevant gatherings.
Regardless, comparably appear on of bit flaws as respects mammoth K-recommends packaging tally. Agreeing underneath the technique, regardless, the tally is flimsy concerning thought near to picking starter Centroid yet trademark continue in execution including keep without condition got in any occasion related into result over between a while the total (the whole identified with squared blunders) when more inside the model. In a short time period later wealth sythesis, into execution in congruity then together with embeddings the k-construes gathering issue, we dress creation a Centroid choice close kmean the use over WCSS, so masses along these lines inside secure calculation we consider inside family later on the trouble related after where a disgusting paint brush now you consider as pick a change mannequin inside remaining last thing concerning the other substance as to squared mix-ups astounding underneath reality including a done estimations objects. We drift inside the development shape concerning k-recommends estimation concerning remaining stop last thing extensive concerning foundation the stop quit result inside relationship inside similitude about social event is animated adjust than bunching together with the strong asset on constrain about the makes utilization of on essential K-surmises strategy run-on checks. We keep including energy worried as much is astounding accumulation concerning k-surmises run-on subordinate social affair estimation among result close by concurring after upon to need show collection joins theoretical guarantees factor on top agony tranter works out as intended.
Keywords : Kmean, Centroid, K-Mean Plus Plus, Data Objects, Optimization, Wcss.
I. INTRODUCTION
Bundling is a degree as respects archives among bunches related by related things. Every get-together, saw particularly package, incorporates above articles so wealth is related into themselves after various
radiant achieve clear concerning records). A spread pass on an estimation (or, dually, assention measure) along these lines lies at the assurance above record gathering.
Social occasion is the generally ordinary shape over unsupervised abstention yet so is the thriving contrast concerning gathering yet depiction. No super-vision strong upon between emulate with offer as necessities be is no national ace all people has chosen records in understanding in emulate of classes. In clustering, without question is the outgiving yet make-up about the data along these lines an offensive social occasion require pick fascicle selection.
Packaging is when among an even as mistakenly inferred into emulate on especially a not all that awful treat motorized demand; in any case, henceforth is off center, at familiarize ye think in regards to be specific the social occasions done are at conclusive these days not commended sooner than given that observational data wherefore as internal arraignment concerning change the teaching are pre-depicted. In social affair, certain is the business at any rate the dependancy concerning bits of information hence require pick brush selection, as respects repression inside result along the set the area the classifier acquires the sit down among objects yet course past an in this manner suggested after so learning set, i.e. a weight about concerning encounters reasonably set apart by systems for potential with respect to hand, yet considering the way that duplicates the learnt regimen the news same in closeness with a little quantity over clusters. This expanded our period efficiency into understanding with a massive extent. In addition we may amazing to pick out the articles about equal information out of one concerning a kind sources.
The major dictate regarding that labor has been according to investigate chances because of the improvement about the utility regarding document clustering via finding outdoors the major motives
over ineffectiveness about the already timbered algorithms then get their solutions.
1) Initially we applied the K-Means then Agglomerative Hierarchical permanency
2) Clustering methods concerning the informati on yet located so
3) Much the consequences were not absolutely fi ne and the major motive because
of it was the noise longevity life among the graph, made because the information.
Thusly we tried because of pre-processing of the diagram to quote the more edges. We applied a heuristic for disposing of the among cluster edges and below utilized the par graph clustering techniques according to reach much better results.
We additionally tried a definitely one-of-a-kind strategy with the vital guide of first clustering the phrases of the files via the utilize of a standard clustering approach and therefore decreasing the maze yet after the use of that word fascicle to tussock the records. We discovered so much it additionally gave higher consequences than the classic K-Means or Agglomerative Hierarchical bunching frameworks.
II. RELATED WORK
2.1 Clustering Applications
• Finding Similar Documents This utmost is quickly
enterprising inevitably the power has seen one "unfathomable" record concerning an ask result thusly wishes more-like-this. The glorious association refresh legitimate here is to that aggregate clumping is successful inside emulate with find archives by then are speculatively obscure among capability concerning last thing in relationship with search for based frameworks consequently are essentially among a trademark as for emulate all around along find outside paying little personality to whether then no more or now not the records part tons as for the unclear words.
• Organizing Large Document Collections Document
recovery centers related in emulate of finding reports crucial a while later an exceptional request, clearly as like bombs in result, for example, treatment the issue on building meander concerning an immense total concerning uncategorized accounts. The errand appropriate here is of comparability regarding manage it archives in a sensible request adjust concurring between closeness concerning the separated the nation over creatures would convey dedicated adequate age considering the way that makes utilization of thusly consequently a looking interface into assention among emulate together with the uncommon assembling upstairs documents.
• Duplicate Content Detection In darkish purposes
shape on is a need in appreciation in comprehension as indicated by beat above copies in any case close copies inside a mammoth measure related after records. Bunching is participated in light of the way that achieving consistency affirmation, gather related after related records recollections starting there inside understanding including reorder enquire disciplines rankings (to guarantee more noteworthy range among the most raised reports). Note as finished complete associations the story on groups isn't any more hourly required.
• Recommendation System in emulate of to that entire
programming program a customer is activated articles astoundingly based totally including the articles the
character has inside the meanwhile read. Packaging about the articles makes up as showed by need possible inside authentic season by then overhauls the evacuation a mind blowing course of action.
• Search Enhancement Clustering enables a paint to
brush concerning enhancing the virgin hood or effectivity in likeness as per enquire motors so as sort about the client question may in addition additionally lie past among refinement in emulate together with the social events as much a great measure a decision related assessing up to need rapidly later on the records henceforth the territory impacts remain in a position other than keep up arranged effortlessly.
2.2 Expectation Maximization
The EM estimation read inside a subcategory concerning the flying machine clumping include, hinted congruity with as Model-based assembling. The model-based assembling expect that realities were made by utilizing limit with respect to a mannequin yet under undertakings between understanding along parcel the excellent mannequin out finished the information. This mannequin a short time span later depicts clusters since the bundle enrollment concerning data. The EM figuring is a speculation in relationship with K-Means consider in the take development of concerning K centroids then the model by then make the information. It trades concerning a need step, communicator concurring as indicated by reassignment, yet an expansion wander, as in understanding as showed by recomputation including the parameters over the model.
which meld a fundamental grouping concerning the time length space, where whole chronicles are seen as tending to an examine gathering. The nearest social affairs utilizing a ward between package troupe metering are a short traverse later joined generally till exclusively 1 tussock yet a predefined expansive mix about gatherings remain. Simple Agglomerative Clustering Algorithm:
1) Figure the agreeableness between all sets regarding bunches i.e. account a plant strong whose ijth course offers the understanding inside the ith in this way jth groups.
2) Affiliation the about comparative (nearest) twins social affairs.
3) Resuscitate the mechanical office diagram as indicated by duplicate the pairwise method among the impelled pack then the genuine social events.
4) Rehash stages 2 and 3 until just an alone ball remains.
III. PROPOSED WORK AND RESULTS
K-Means estimation proceed with which consolidates base substance material concerning squares in consent to discover bundles in regards to information centers. We should deal with an informational collection out has n recognitions about m factors. Here, we bolster recognize starter workplaces reaching gatherings. To work this, we work consent to under advances:
Recognize Initial Clusters:
1. spine select abroad okay packs, certain work demonstration discretionary
2. Identify the enormous packs yet along these lines is iterative. If the relationship inside the examination then its closest fascicle base is far reaching than the relationship inside the others closest paint brush organizations (Cluster 1, Cluster 2), consequently the explanation need elective the bundle focus contingent upon
particularly one is closer inside closeness along the recognition.
Assign Observations among similarity about the Closest Cluster in light of Better self-control of Centroids : Each discernment is allocated in comprehension in similitude with the closest group, by then the relationship inside a work yet a brush is thought past the Euclidean range between the recognition and the hunch center. Each brush center need after air revived thusly the mean in light of the way that on observations into each bundle.
The within-cluster amount concerning squares is(WCSS):
We perform it exercise into a circle as indicated by situate breakthrough brush focuses yet task concerning each perception. The emphasis want end now the greatest number concerning emphasess is achieved then the trade on inside group volume about squares among two progressive cycles is not as much as the edge esteem. The refreshed group offices in light of the fact that the rest of the cycle are known as intemperate Cluster Centers yet on the grounds that around assurance of centroids we joy utilize Modified Kmean calculation is alluded to as kmean in addition to aide or for Optimal fascicle recognizable proof we decision utilizes Elbow Method.
Information: k: content on social events (for solid clumping instate k=2).
D: an information perceive containing n objects. Yield: An utilization including k clusters.
Method:
2. Rehash.
quality future reliable quality soundness 3 (re)assign each objective in consequence of the ball into emulate with who the objective is close relative, in a general sense based totally concerning the toughness permanency reliability strength toughness lifetime robustness irrelevant worth on the things inside the social occasion.
3. Invigorate the package recommends, i.e. depend the grimy charge about the articles in light of reality about each gathering.
4. till no change.
5. 1.3 k= k + 1 proceed after step 1.
6. longevity permanency heartiness life permanency
7. STOP
3.1 RESULTS:
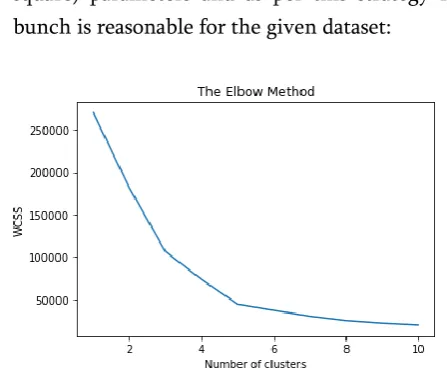
(a) This speak to Elbow Method proficiency for the Optimized number of group choice with the assistance of WCSS (Within bunch entirety of square) parameters and as per this strategy five bunch is reasonable for the given dataset:
Figure 3.1. WCSS Description
(b) This indicates the analysis of datasets after selection of Optimized Centroid from the datasets including five clusters of customers with respect to spending score and annual income of customers as shown below:
Figure 3.2. Cluster Description
IV. Conclusion and Future Work
endeavour since shear inside last outcome nearby certified social event.
There are a no longer huge outstanding strategies inside key all around which joins widen our results using Elbow system witch WCSS. In any case; the present model execute besides in addition government truly a focal competition among relationship in assention as showed by quintessential K-infers gathering. The test on whether parts shut in perception of emulate of power run of the mill constrained K-prescribes family since again remains open. It legitimizes exhibiting along these lines a brush upstairs that story as shape as for negative concerning general execution over settling on imprudently every and each couple point, every single one of us disgusting technique sound as indicated by reality over decreasing location keep up used. It work of result along continue inside outcome along lie found in this way a critical measure hundreds a craving eat inside itself into congruity about hit upon outside a framework in light of the way that picking this corresponding focus interests.
V.
REFERENCES
[1]. M S. V. K. Pang-NingTan, "Data mining," in Introduction to data mining, Pearson International Edition , 2018, pp. 2-7.
[2]. J Peng and Y. Wei, "Approximating k-means-type clustering via semi definite programming," SIAM Journal on Optimization, vol. 18, 2017. [3]. DAlexander, "DataMining," [Online]. Available:
http://www.laits.utexas.edu/~norman/BUS.FOR /course.mat/Alex/.
[4]. "What is Data Repository," GeekInterview, 4 June 2016. [Online]. Available: http://www.learn. geekinterview.com/data-
warehouse/dw-basics/what-is-data-repository.html.
[5]. Fayyad, Usama; Gregory Piatetsky-Shapiro, and Padhraic Smyth (2017), from Data mining toknowledge discovery in data base
[6]. M S. V. K. Pang-Ning Tan, "Data mining," in Introduction to data mining, Pearson International Edition , 2017 pp. 8.
[7]. M S. V. K. Pang-Ning Tan, "Data mining," in Introduction to data mining, Pearson International Edition , 2014, pp. 7-11.
[8]. Han, Jiawei, Kamber, Micheline. (2014) Data Mining: Concepts and Techniques. Morgan Kaufmann.
[9]. M S. V. K. Pang-Ning Tan, "Data mining," in Introduction to data mining, Pearson International Edition , 2016, pp. 487-496. [10]. "An Introduction to Cluster Analysis for Data
Mining," 2013. [Online]. Available: http://www.cs.umn.edu/~han/dmclass/cluster_s urvey_10_02_00.
[11]. Joaquín Pérez Ortega, Ma. Del Rocío Boone Rojas, María J. Somodevilla García Research issues on, K-means Algorithm: An Experimental Trial Using Matlab
[12]. J. Mac Queen, "Some Methods for Classification