Contents lists available at ScienceDirect
Neurocomputing
journal homepage: www.elsevier.com/locate/neucom
On
expressiveness
and
uncertainty
awareness
in
rule-based
classification
for
data
streams
Thien Le
a, Frederic Stahl
a ,∗, Mohamed Medhat Gaber
b, João Bártolo Gomes
c,
Giuseppe Di Fatta
aaDepartment of Computer Science, University of Reading, Whiteknights, Reading, Berkshire, RG6 6AY, United Kingdom
bSchool of Computing and Digital Technology, Birmingham City University, Curzon St, Birmingham B4 7XG, England, United Kingdom cDataRobot, 1 International Place, 5th Floor, Boston, MA 02110, United States
a
r
t
i
c
l
e
i
n
f
o
Article history:
Received25February2016 Revised24May2017 Accepted26May2017 Availableonline3June2017 Keywords:
DataStreamMining BigDataAnalytics Classification Expressiveness Abstaining
Modularclassificationruleinduction
a
b
s
t
r
a
c
t
MiningdatastreamsisacoreelementofBigDataAnalytics.Itrepresentsthevelocityoflargedatasets, whichisoneofthefouraspectsofBigData,theotherthreebeingvolume,varietyandveracity.Asdata streamsin,modelsareconstructedusingdataminingtechniquestailoredtowardscontinuous andfast modelupdate.TheHoeffdingInequalityhasbeenamongthemostsuccessfulapproachesinlearning the-oryfordatastreams.Inthiscontext,itistypicallyusedtoprovideastatisticalboundforthenumberof examplesneededineachstepofanincrementallearningprocess.Ithasbeenappliedtoboth classifica-tionandclusteringproblems.DespitethesuccessoftheHoeffdingTreeclassifierandotherdatastream miningmethods,suchmodelsfallshortofexplaininghowtheirresults(i.e.,classifications)arereached (blackboxing).Theexpressivenessofdecisionmodelsindatastreamsisanareaofresearchthathas at-tractedlessattention,despiteitsparamountofpracticalimportance.Inthispaper,weaddressthisissue, adoptingHoeffdingInequalityasanupperboundtobuilddecisionruleswhichcanhelpdecisionmakers withinformedpredictions(whiteboxing).WetermedournovelmethodHoeffdingRuleswithrespectto theuseoftheHoeffdingInequalityinthemethod,forestimatingwhetheraninducedrulefromasmaller samplewouldbeofthesamequalityasaruleinducedfromalargersample.The newmethodbrings inanumberofnovelcontributionsincludinghandlinguncertaintythroughabstaining,dealingwith con-tinuousdatathroughGaussian statistical modelling,and anexperimentally proven fastalgorithm. We conductedathoroughexperimentalstudyusingbenchmarkdatasets,showingtheefficiencyand expres-sivenessoftheproposedtechniquewhencomparedwiththestate-of-the-art.
© 2017TheAuthors.PublishedbyElsevierB.V. ThisisanopenaccessarticleundertheCCBYlicense.(http://creativecommons.org/licenses/by/4.0/)
1. Introduction
One problem the research area of ‘Big Data Analytics’ is con-cerned with is the analysisof high velocity data, also known as streaming data [1,2] ,that challenge our computational resources. Theanalysisofthesefaststreamingdatainreal-timeisalsoknown as the emerging area of Data Stream Mining (DSM) [2,3] . One important data mining technique, and in turn DSM category of techniquesisclassification.Traditionaldataminingbuildsits clas-sificationmodelsonstaticbatchtrainingsetsallowingseveral iter-ationsoverthe data.ThisisdifferentinDSMastheclassification modelneedstobeinducedinalinearorsublineartime
complex-∗ Correspondingauthor.
E-mail addresses: [email protected] (T. Le), [email protected],
[email protected] (F. Stahl), [email protected] (M.M. Gaber),
[email protected](J.B. Gomes),[email protected](G.D. Fatta).
ity [4] .Furthermore, DSMclassification techniques need toallow dynamicadaptation to concept drifts as the data streams in [4] . Applications of DSM classification techniques are manifold and compriseforexamplemonitoringthestockmarketfromhandheld devices [5] ,real-timemonitoringofafleetofvehicles [6] ,real-time sensingofdatainthechemicalprocessindustryusingsoft-sensors [7] ,sentimentanalysisusingreal-timemicro-boggingdatasuchas twitterdata [8] ,tomentionafew.
The challenge ofdata streamclassification lies inthe need of theclassifierto adaptinreal-timetoconcept drifts,whichis sig-nificantlymore challengingifthedata streamis ofhighvelocity. Manydatastream classification techniquesare basedonthe ‘Top DownInductionofDecisionTrees’,alsoknownasthe ‘divide-and-conquer’approach [9] ,suchas [10,11] .However, thedecisiontree formatisalsoamajorweaknessandoftenrequiresirrelevant infor-mationtobe availabletoperformaclassification task [12] . More-over,adaptationofthetrees ishardercompared withrules when http://dx.doi.org/10.1016/j.neucom.2017.05.081
achangeoccurs,thiscould bea disadvantageforreal-time appli-cations.
The here presented work proposes the Hoeffding Rules data streamclassifier that isbased on modular classification rules in-stead of trees. Hoeffding Rules can easily be assimilated by hu-mans,andat the sametime doesnot require unnecessary infor-mation tobe available forthe classification tasks. Rule induction from data streams can be traced back to the Very Fast Decision Rules (VFDR) [13] and eRules data stream classifiers [9] for nu-mericaldata.eRulesinducesmodularclassificationrulesfromdata streams, but requires extensive parameter tuning by the user in ordertoachieveadequateclassificationaccuracyincludingthe set-tingofthewindowsize.Notingthisdrawbackthataffectsthe ac-curacy,iftheparametersarenotsetcorrectly,astatisticalmeasure that automatically tunes the parameters is desirable. Addressing thisissue, Hoeffding Rulesadjusts these parameters dynamically withverylittleinputrequiredbytheuser.Theherepresented Ho-effdingRulesalgorithmis basedon thePrism [12] rule induction approachusingaslidingwindow[14,15] .However,thiswindowfor bufferingtrainingdata isadjusted dynamically by making use of theHoeffdingInequality [16] .OneimportantpropertyofHoeffding RulescomparedwiththepopularHoeffdingTreedatastream clas-sificationapproach [10] is,thatHoeffdingRulescanbeconfigured toabstainfromclassifyingan unseendatainstancewhenitis un-certainaboutitsclasslabel.Inaddition,ourapproachis computa-tionallyefficientandhenceissuitable forreal-time requirements. Animportant strengthof theproposed technique isthe high ex-pressivenessoftherules.Thus,havingtherulesasthe representa-tionoftheoutputcan helpusers inmakingtimely andinformed decisions.Outputexpressivenessincreasestrustindatastream an-alyticswhichisoneofthechallengesfacingadaptivelearning sys-tems [17] .Toaddresstheexpressivenessissueforofflineblackbox machine learning models, the new algorithm Local Interpretable Model-AgnosticExplanations(LIME) hasbeenproposedin [18] .The methodgenerates a shortexplanation for each new classified or regressedinstanceoutofapredictivemodel,inaformthatis in-terpretablebyhumans (canbeexpressed asrules, inaway).The workhasattractedagreatdealofmediaattention,andhas empha-sisedtheneedforexpressivemodels.Modeltrusthasbeenfurther emphasised.Thisworkandmanyotherfollow-upresearchpapers havebeenthe resultofexperimental workthatshowedsome se-riousflawsin deeplearning models(a highlyaccurate blackbox approach) [19] .Thework showedthatmiss-classification by deep learningmodelsofsomeimages– duetoaddednoisetothese im-ages– canoccurtosurprisinglyveryobviousexamplestohumans. Again, modelinterpretability and trust havebeen emphasised as animportantareaofresearch.
The utilityofexpressivenessisintroducedinthispapertorefer tothecostofexpressivenesswhencomparingtheaccuracyoftwo methods.Asaccuracyhasbeenthedominatingmeasureofinterest incomparingclassifiersinbothstaticandstreamingenvironments, it is evident that real-time decision making based on streaming modelsstill suffersfromtheissueoftrust [17] .Toaddressthis is-sue,theuserisabletodetermineanaccuracylossband (
ζ
),such thatthemodelcanbeexpressiveenoughtogranttrust,andatthe sametimetheaccuracycanbetoleratedat(−ζ
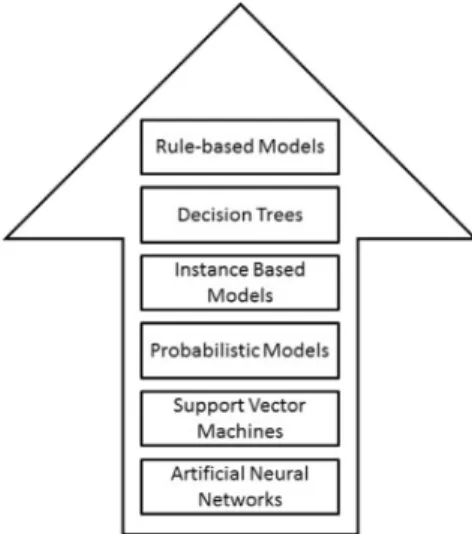
%)ofanyotherbest performingclassifierwhichislessexpressive(canbeatotalblack box).We argue that such a newmeasure will open the doorfor moretrustfulwhiteboxmodels.Inmanyapplications(e.g., surveil-lance,medicaldiagnosis,terrorismdetection),decisionsneedtobe basedon clear arguments.In such applications, havinga trustful modelwithacompetent accuracycanbemuch moreappreciated thanhavingahighlyaccuratemodelthatdoesnotconveyany rea-soningaboutits decision. Otherexamples ofapplicationsthat re-quireconvincingargumentscanbefoundin [18] .Fig.1. Hierarchyofoutputexpressiveness.
Thispaper isorganisedas follows: Section 2 highlights works related to the Hoeffding Rules approach. Section 3 highlights our dynamic rule induction and adaptation approach for data streams. An experimental evaluation and discussion is presented in Section 4 .Concludingremarksareprovidedin Section 5 .
2. Relatedwork
Thevelocity aspectoftheBigDatatrendisthemaindriverof workdone forover adecadeintheareaofdatastreammining– long before the Big Data term wascoined. Among the proposed techniquesintheareacomealonglistofclassificationtechniques. Approaches to data stream classification varied from approxima-tionto ensemblelearning. Twomotivesstimulated such develop-ments:(1)fastmodelconstruction addressingthehighspeed na-tureofdatastreams;and(2)changeintheunderlyingdistribution ofthedata,inwhathasbeencommonlyknownasconceptdrift.
HoeffdingInequality [16] hasfounditswayfromthestatistical literatureinthe60softhelastcenturytomakeanimpactindata stream mining, having a number oftechniques, mostlyin classi-fication, withnotable success.The Hoeffdingbound is astatistical upper bound on the probability that the sum of a random vari-able deviatesfrom its expected value. The basicHoeffding bound
hasbeenextendedandadoptedinsuccessfullydevelopinga num-berofstreaming techniquesthatwere termedcollectivelyasVery FastMachineLearning(VFML) [20] .
Earlier work on data stream mining addressedthe aforemen-tionedissues.However, theenduserperspectivehasbeengreatly missing,andhencetheuser’strustinsuchsystemswasfrequently questioned. Thisissuehas beendiscussed in a positionpaper by Zliobaiteetal [17] .
Inthispaperwe address thisissue,attemptingto providethe end userwith the mostexpressive knowledge representationfor datastreamclassification,i.e., rules.Wearguethat rulescan pro-videtheuserswithinformativedecisionsthatenhancethetrustin streamingsystems. Fig. 1 showsahierarchyofoutput expressive-ness,withrule-based modelsbeing atthetop ofall ofthe other classificationtechniques.
2.1. Ruleinductionfromdatastreams
FLORA is a family of algorithms for data stream rule induc-tion that adjusts its window size dynamically using a heuristic based on the predictive accuracy and concept descriptions. The mostrecentFLORAalgorithm,FLORA4,addressestheissueof con-cept drift. It can use previous concept descriptions in situations
of recurring changes and is robust to noise in the data stream [21] . From theAQ-PM familyof algorithms, theAQ11-PM system is the mostrepresentative. AQ11-PM uses learnedrules to select data instances from the training data that lie on the boundaries ofinducedconceptdescriptionsandisstoringtheseso-called ‘ex-treme ones’ in partial memory [22] . However, those approaches are stillnotadapted tohighspeeddatastreamenvironments, es-pecially those featuring continuous attributes. The FACIL [23] al-gorithm workssimilarlytoAQ11-PM.However, FACILdoesnot re-quireallstoreddatainstancestobeextremeandtherulesarenot revisedimmediatelywhentheybecomeinconsistent.Adaptationto driftisachievedbysimplydeletingolderrules.Nevertheless,none of theseapproacheswasevaluated onmassive datasets with nu-mericalvalues(FACILrequiresthatthenumericdataisnormalised between0and1).The mostrecentapproachisVFDR [13,24] that sharesideaswithVFMLandwasimplementedandtestedinMOA [14] ,aworkbenchforevaluating datastreamlearningalgorithms. VFDRisabletolearnanorderedorunorderedruleset.
VFDRisthemostsimilaralgorithmtoourapproach(Hoeffding Rules).ThemaindifferencebetweenVFDRandtheHoeffdingRules approachproposedinthispaperisthat HoeffdingRulesinduction isbased onPrism [12] whileVFDRinductionis similartothe in-ductionofHoeffdingTree.Moreover,theHoeffdingRulesapproach canabstainfromclassifying,whichcontributestothehigh expres-sivenessoftheinducedruleset.
For a more in-depthreview ofthe related work we refer the readertoasurveyonincrementalrule-basedlearners [25] .
3. HoeffdingRules:expressivereal-timeclassificationrule inducer
This section highlights the developmentof the proposed Ho-effdingRulesclassifierconceptually.Itinvolvestheinductionofan initial classifier in the form of a set of expressive ‘IF… THEN…’
rules. The section first highlights expressive rule sets in general in Section 3.1 , and then discusses the Prism algorithm as a ba-sicapproachforinducingsuchrules onbatchdatain Section 3.2 . Prism hasbeen adopted by HoeffdingRules asthe basic process forinducingexpressiverules.However,ithasbeenenhancedwith a moreexpressive ruleterminductionmethodforcontinuous at-tributes as describedin Section 3.3 based on probability density distribution. Section 3.4 thendescribestheHoeffdingboundused by HoeffdingRulesasa metricto estimate a gooddynamic win-dowsizeofthedatastreamtoinduceexpressiverulesfrom.Lastly, Section 3.5 illustratestheoverallHoeffdingRulesreal-time induc-tionprocess.
3.1. Expressiverulerepresentationandinduction
Expressiveclassificationrulesarelearntfroma givensetof la-belled datainstances, which consistsof attribute valuesandrule learningalgorithmstoconstructoneormorerulesoftheform: IFt1ANDt2ANDt3...ANDtkTHENclass
ω
iTheleftsideofaruleistheconditionalpartoftherule,which consistsofaconjunctionofruleterms.Aruletermisalogicaltest that determines whether adata example tobe classified hasthe classification
ω
i ornot.Aclassificationrule canhaveoneup tokruleterms,wherekisthenumberofattributesinthedata. A ruleterm can havedifferentforms forboth categorical and continuous attributes. A rule termforcategorical attributes typi-callyhastheform
α
=v
inwhichvisoneofthepossiblevaluesof attributeα
. Forcontinuousattributes, binary splittingtechniques are widely used such asin [26–28] . With binarysplitting a rule term isof theform (α
< v) or(α
≥ v), inthis case, vis a con-stantfromtherangeofobserved valuesforattributeα
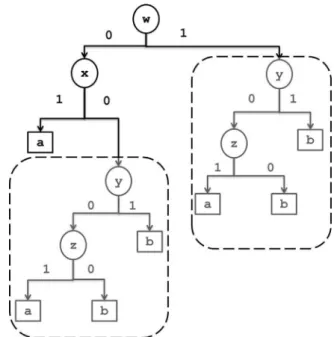
.Hence, ifFig.2. Anexampleofthereplicatedsubtreeproblemfortherules:IF w =0AND x =1THEN class =a,IF y =0AND z =1THENclass =a . Otherwise, class =b.
thedatainstancessatisfy thebodyorconditionalpartoftherule, thentherulepredicts
ω
iastheclasslabel.3.2.Predictiverulelearningprocess
Thissectiondiscussestheinductionofexpressiverulessuchas the ones described in Section 3.1 based on the Prism algorithm [12] .HoeffdingRules’basicruleinductionstrategyisalsobasedon Prism.Prismusesa‘separate-and-conquer’approachtoinduce ex-pressiverules.Incontrast,the‘divide-and-conquer’ruleinduction approach (which generates decision trees), Prism generates deci-sionrulesdirectlyfromtrainingdataandnotintheintermediate formofatree,suchasforexampletheC4.5algorithm [29] : IFw=0ANDx=1THENclass=a
IFy=0ANDz=1THENclass=a Otherwise, class=b
Thethree rules above cannot be representedinthe formof a decisiontree,astheydonothaveanyattributesincommon. Rep-resentingtheserulesina decisiontreewouldrequireadding un-necessaryandmeaningless ruleterms. Thisis alsoknown asthe
‘replicatedsubtreeproblem’ [30,31] illustrated in Fig. 2 forthetwo rulesabove.
Thetreestructureexamplein Fig. 2 isgeneratedunderthe as-sumptionthatthereexistonlythefourattributes(w,x,z,y);that each attributeis eitherassociated withthevalue 0or 1; and in-stancescoveredbythetworulesaboveareclassifiedasbelonging toclassawhereastheremainingrulespredictclassb.
Thisexamplerevealsthat the‘divide-and-conquer’rule induc-tion approach can lead to unnecessarily large and complex trees [30] ,whereasthePrismalgorithmisabletoinducemodularrules such as the two rules above, that have no attribute in common. Also,theauthorsof [32] discussthatdecisiontreemodelsareless expressive, as they tend to be complex and difficult to interpret byhumans oncethetreemodelgrowstoa certainsize.Also, the authorsofthewell-known C4.5decisiontreeinductionalgorithm [29] acknowledged that pruning a decision tree model doesnot guarantee simplicityand can still be too cumbersome to be un-derstoodbyhumans.
Ithasbeenshownin [28] thatPrism’sinductionmethodof ex-pressiverules achievesa similar classification accuracycompared withdecision tree based classifiers and sometimes even outper-forms decision trees (especially ifthe data is noisyor there are clashesin the data) [28] . Thus, Prism has been chosen as a ba-sicruleinductionstrategyforHoeffdingRules.Anotherreasonfor choosing Prismis that it naturallyabstains from classification, if norulematches,whereas adecisiontreebasedapproachforcesa classification [9] .Abstaining maybe necessaryin critical applica-tionswheremiss-classificationsareverycostly,suchasinmedical orfinancialapplications.
Prism follows the ‘separate-and-conquer’ approach which re-peatedlyexecutes the followingtwosteps:(1)induce a newrule andaddit to therule setand(2)remove all datainstances cov-eredby the newrule. The stopping criterion for executing these two steps is usually when all data instances are covered by the ruleset.Hence,thisapproachisalsooftenreferred toasthe ‘cov-eringapproach’.Cendrowska’soriginalPrismalgorithmfor categor-icalattributesimplementsthis‘separate-and-conquer’approachas shownin Algorithm 1 ,wheretα isa possibleattributevalue pair
Algorithm 1: Learningclassification rules fromlabelled data instancesusingPrism.
1
for
i
=
1
→
C
do
2
D
←
Dataset;
3
while
D
does
not
contain
only
instances
of
class
ω
ido
4
forall
the
attributes
α
∈
D
do
5
Calculate
the
conditional
probability,
P
(
ω
i|
t
α)
for
all
possible
rule
terms
t
α;
end
7
Select
the
t
αwith
the
maximum
conditional
probability,
P
(
ω
i|
t
α)
as
rule
term;
8
D
←
S,
create
a
subset
S
from
D
containing
all
the
instances
covered
by
t
α;
end
10
The
induced
rule
R
is
a
conjunction
of
all
t
αat
line
7;
11
Remove
all
instances
covered
by
rule
R
from
original
Dataset;
12
repeat
13
lines
3
to
9;
until
all
instances
of
class
ω
ihave
been
removed
;
end
(ruleterm) andD isthe trainingdata.The algorithm isexecuted foreachclass
ω
iinturnontheoriginaltrainingdataD.There have been variations of Prism, such as N-Prism which also deals with continuous attributes [28] ; PrismTCS which im-posesan order ofthe rules in therule set [33] ; PMCRI which is a scalableparallel version ofPrismTCS [31] and Prismbased en-sembleapproachessuchasRandomPrism [34] .
HoeffdingRulesusesthisbasicPrismapproachtoinducerules froma recentsubset ofthedatastream.However, different com-paredwithPrism, HoeffdingRulesuses a moreexpressive repre-sentation of rule terms for continuous data, which will be dis-cussednext in Section 3.3 ; andalso usestheHoeffdingboundto adaptthe inducedrulesettoconceptdrifts inthedatastreamin real-time,aswillbediscussedin Section 3.4 .
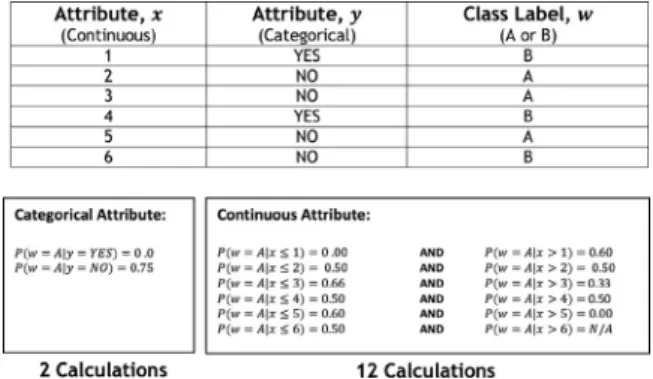
Fig.3. Cut-pointcalculationstoinducearuletermforcontinuousandcategorical attributes.
3.3. Probabilitydensitydistributionforexpressivecontinuousrule terms
The original Prism algorithm [12] only works on categorical attributes and produces rule terms of the form
(
α
=ν
)
. eRules [9] and VeryFastDecision Rules (VFDR) [13] areamong the few algorithms specifically developed forlearning rules directly from a data streamin real-time. Forcontinuous attributes, eRulesand VFDRproduceruletermsoftheform(α
<ν
),or(α
≥ν
)and(α
≤ν
),or(α
>ν
),respectively.Asummary oftheprocess ofhow eRulesandVFDRdealwith continuousattributescanbedescribedasfollows:
1. Foreachpossiblevalue
α
jofacontinuousattributeα
,calculatetheconditionalprobabilityforagiventargetclassforbothrule terms(
α
<ν
)and(α
≥ν
)or(α
≤ν
)and(α
>ν
).2. Return the rule term, which has the overall best conditional probabilityforthetargetclass.
It is evident that this process of dealing with continuous at-tributes requires many cut-point calculations for the conditional probabilitiesforeachpossiblevalue
α
jofacontinuousattribute.The example illustrated in Fig. 3 comprises just six data in-stances, one continuous attribute, one categorical attribute, and two possible class labels. It shows how many cut-point calcula-tions are needed by eRulesor VFDR inorder to induce one rule term. The numberofcut-pointcalculationsneededforeach con-tinuousattributeisthenumberuniquevaluesoftheattribute mul-tipliedby2.Clearlybothalgorithms,eRulesandVFDR,stillrequire a lotof calculationseven thoughthe dataintheexample isvery small.Thisisadrawbackascomputationallyefficientmethodsare needed for mining data streams. Furthermore, eRules and VFDR usea ‘separate-and-conquer’ strategy, whichrequires many itera-tionsuntilaruleiscompleted.
G-eRulesusestheGaussiandistributionoftheattribute associ-atedwithaclass labelasintroduced in [35] ,tocreateruleterms oftheform(x<
α
≤y),andthusavoidsfrequentcut-point calcu-lations.Evidenceoftheimprovementsinperformancewhile main-tainingtheaccuracyoftheinducedrulesisdiscussedin [35] .This methodisalsousedintheHoeffdingRulesalgorithmtoavoid fre-quentcut-pointcalculations.Itisalsomoreexpressivethan induc-ingruletermsfrombinarysplits,asruletermsoftheform(x<α
≤y)can describeanintervalofdata.Onewouldneedtousetwo ruletermsinducedbybinarysplittingtodescribe thesame inter-valofdatavaluesofaparticularattribute.Foreachcontinuous at-tribute ofthe the instances, a Gaussian distribution representing all possible valuesof that continuousattribute fora given target classisusedtogeneratethesemoreexpressiveruleterms.Ifthedatainstanceshaveclasslabelsof
ω
1,ω
2,...,ω
ithenwecancomputethemostrelevantvalueofacontinuousattributethat is themost relevantone toa particular class label basedon the
Fig.4. Theshadedarearepresentsarangeofvaluesofcontinuousattributeαfor classωi.
Gaussian distributionofthevaluesassociated withthisparticular classlabel.
The Gaussian distribution is calculated for a continuous at-tribute
α
witha meanμ
andavarianceσ
2 fromall possible nu-meric values associatedwith the class labelω
i. The classcondi-tionaldensityprobabilityiscalculatedasinthe Eq. (1) :
P
(
tα|
ω
i)
=P(
tα|
μ
,σ
2)
= 1 √ 2rσ
2exp(
−(
tα−μ)
2 2σ
2)
(1) Hence, a heuristic based on P(
ω
i|
tα)
, or equivalentlylog
(
P(
ω
i|
tα))
is calculated and used to determine theproba-bilityofaclasslabelforavalidvalueofacontinuousattributeas inthe Eq. (2) :
log
(
P(ω
i|
tα))
=log(
P(
tα|
ω
i))
+log(
P(ω
i))
−log(
P(
tα))
(2)The probability betweentwo values,
i,can be calculated for
therangebetweenthesetwovaluessuchthatifx∈
i,thenx
be-longs to class
ω
i.Thismethod maynot guaranteeto capturethefull details ofthe intricate continuousattributes, butthe compu-tational and memory efficiency can be improved significantly as shownin [35] comparedwithbinarysplittingtechnique. The effi-ciency asa resultofusingGaussian distributiononlyneeds tobe calculatedonceandcanbeincrementally updatedovertime with justtwovariables,
μ
andσ
2.Asillustratedin Fig. 4 ,theshadedareabetweenxandyshould representthemostcommonvaluesofacontinuousattribute
α
for classwi.Agoodrule termofacontinuousattributeisderived bychoosinganareaunderthecurveofthecorrespondingdistribution forwhichthedensityclassprobabilityP
(
x<α
≤y)
isthegreatest. This techniqueis used to identifya possiblerule term inthe formof(x<α
≤y),whichishighlyrelevanttoarangeofvalues of thecontinuous attributeα
fora target classω
i froma subset of data instances. The process can be describedin the following steps:1. Mean
μ
andvarianceσ
2 of each class label is calculated for eachavailablecontinuousattribute.2. Eqs. (1) and(2 )areusedtoworkouttheclassconditional den-sityandposteriorclassprobabilityforeachvalueofa continu-ousattributeforatargetclass.
3. Avaluewiththegreatestposteriorclassprobabilityisselected. 4. Choose a smaller value compared with the value selected in
step 3 that also has the greatest posterior class probability among all small er values. Choose also a greater value com-paredwiththevalueselectedinstep3thatalsohasthe great-estposteriorclassprobabilityamongallgreatervalues.
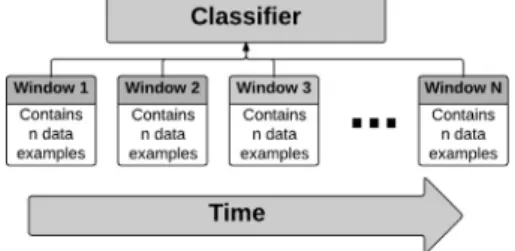
Fig.5. Slidingwindowsprocess.
5.Calculate density probability with the two values in step 4
by usingthecorresponding Gaussiandistribution calculatedin
step1forthetargetclass.
6.Selecttherangeoftheattribute(x<
α
≤y)asaruleterm,for whichthedensityclassprobabilityisthemaximum.Thenormality assumptionshould notcausemajor problemsif largeenoughsamplesizesareused(>30or40) [36] .Asstatedby Altman andBland [37] , thedistribution ofdatacan beignored if thesamples consist ofhundreds ofobservations. Thisis thecase for data stream classifiers such as Hoeffding Rules, as they are designedfor infinite data streams. Also, there are a few notable pointsfrom the central limit theorem [37,38] regardingthe nor-malityassumption:
• Ifthe sampledatais approximatelynormallydistributed,then thesamplingdistributionwillalsobenormaldistributed.
• Ifthesamplesizeislargeenough(>30or40) then,the sam-pling distribution tends to be normally distributed, regardless oftheactualunderlyingdistributionofthedata.
Fromthepointsjustmentionedabove,truenormalityis consid-eredtobeamythbutagoodestimationofnormalitycanbe con-firmedby usingnormalplots orsignificance tests [37] .The main ideabehindthesetestsistoshowwhetherdatasignificantly devi-atesfromnormality [36–38] .
Thenextsectiondescribestheadaptationoftheruleinduction processtodatastreams.
3.4.UsingtheHoeffdingboundtoensurequalityoflearntrulesfrom adatastream
Itisreasonabletoassumethattherecentdatainadatastream ismorelikelytoreflectthecurrentconceptmoreaccurately com-paredwitholderdata [39] .Someworks [9,13,40–42] indata min-ing discuss and use a sliding windows process as illustrated in Fig. 5 .
Thefundamentalidea ofthe slidingwindows processisthata window is maintained which stores mostrecently seen data in-stances,andfromwhicholderdatainstancesaredropped accord-ingtosome setofrules. Datainstancesinawindowcanbe used forthefollowingthreetasks [14,43] :
1.Todetectchange.Usingastatisticaltesttocomparethe under-lyingprobabilitydistributionbetweendifferentsub-windows. 2.Toobtainupdatedstatisticsfromrecentdatainstances. 3.Torebuildorrevisethelearntmodelafterdatahaschanged.
Byusingslidingwindowstechnique,algorithmswillnotbe af-fectedbystaledataandtheycanalsobeusedasatoolto approx-imatetheamountofmemoryrequired [1] .
TheproposedHoeffdingRulesalgorithmusesHoeffding Inequal-ity [16] toestimatetheconfidenceof,whetheraddingaruleterm toa rule, orstopping therule’s induction process isappropriate. Thismakes it morelikely thatthe rulewill coverinstances from thestreamthatmatchtherule’stargetclass.TheuseofHoeffding
Inequalityin HoeffdingRuleswasinspired by [10,44,45] .In addi-tion,theword‘Hoeffding’ inouralgorithm nameisderived from the nameof the formula called HoeffdingInequality [16] , which provides a statistical measurement in confidence of the sample meanofnindependentdata instancesx1,x1,...,xn.IfEtrue is the
truemeanandEest istheestimationofthetruemeanfroman
in-dependentsamplethenthedifferenceinprobabilitybetweenEtrue
andEestisboundedby Eq. (3) ,whereRisthepossiblerangeofthe
differencebetweenEtrueandEest: P[
|
Etrue−Eest|
>]<2e−2n
2/R2
(3) FromtheboundsoftheHoeffdingInequality,itisassumedthat withtheconfidenceof1−
δ
,theestimationofthemeaniswithinofthetruemean.Inotherwords,wehave:
P[
|
Etrue−Eest|
>]<
δ
(4)From Eqs. (3) and(4 ) andsolvingfor
,aboundonhowclose theestimatedmeanistothetruemeanafternobservations,with aconfidenceofatleast1−
δ
,isdefinedasfollows:=
R2ln
(
1/δ)
2n (5)
By using Hoeffdingbound asan independent metric to verify thetruelikenessofaruleterm,we saythat therulesthatsatisfy theHoeffding bound are likelyto be asgood asthe rules learnt fromaninfinitedatastream.
is calculated after the rule term with the best conditional probabilityforclass
ω
iisselected.However,theruletermwillbeaddedtothecurrentruleunlessthe differenceoftheconditional probabilitiesbetweentheselected(best)andthesecond bestrule termisgreater than
.Otherwise, therule’s induction process is completedandthe rule isadded tothe ruleset. Anewiteration foranewruleisstartedagainwithdatainstancescoveredby the previousruleremoved.
If G(tα) is the heuristic measurement that isused to test the ruletermtα,thenRin Eq. (5) representstherangeofG(tα).G(tα) in our approach is the conditional probability P
(
class=i|
tα)
at whicha rule termtα coversa target classω
i.Hence, theproba-bilityrangeofaruletermRis1.nisthenumberofdatainstances thattherulehascoveredsofar.
Concerning the goodness ofthe best ruleterm, lettαj be the rule termwith the highest conditional probability fromthe cur-rentiteration,andtαj−1 be theruletermwiththesecond highest conditionalprobabilityfromthecurrentiteration,then:
G=G
(
tαj)
−G(
tαj−1)
(6)If
G>
, then the Hoeffding bound guarantees that with a probability of 1−
δ
, the trueG≥
(
G−)
. If this is the case, we include the rule term into the current rule as part of Algorithm 1 atstep7andcontinuetosearchforanewruletermif therulestillcovers datainstancesofdifferentclassificationsthan thetargetclass.Onceallpossiblerulesareinducedforallclass la-bels fromthe currentwindow, then all instances covered by the rules are removedandthe instances not covered are addedto a temporarybuffer.Thisbufferisthencombinedwiththedatafrom thenextslidingwindowforinducingnewclassificationrules.Essentially, we usethe Hoeffdingbound to determinea prob-abilitywiththe confidenceof1−
δ
that theobservedconditional probability,withwhich theruletermcovers thetarget classin nexamples,isthesameaswewouldobserveforaninfinitenumber ofdatainstances.
The next section brings the previously outlined methods for ruleinduction,dealingwithcontinuousattributesandadaptation toconceptdrifttogether.
3.5. OveralllearningprocessofHoeffdingRules
Thefollowingsectionsdescribehowweadaptedandcombined slidingwindows,HoeffdingInequality,andthePrismalgorithmto induceandmaintainan adaptivemodularsetofdecisionrulesfor streaming data. These techniqueshave been discussed in greater detailinthe Sections 3.1 –3.4 .
3.5.1. Inducingtheinitialclassifier
ThefirststepofHoeffdingRules’executionisthegenerationof the initial classifier, which is done in a batch mode usingPrism onthefirstninstancesinthewindow.Asdescribedin Section 3.2 , thePrismalgorithmisabletoinduceexpressiveclassificationrules directlyfromtrainingdatabyusing‘separate-and-conquer’search strategy. Themethod ofinducingnumericalrule termsusingthis algorithm hasbeen replacedwith thecomputationally more effi-cientwayofinducingnumericalruleterms,basedontheGaussian Probability Density Distributions described in Section 3.3 in this paper.
Forthefirst window, thewindow sizen ispredefined. Subse-quentlythenumberofdatainstancesforeachwindowconsistsof unseendatainstances plusthe datainstancesnot coveredby the rulesfromthepreviouswindow.ThelearningprocessofHoeffding Rulesisdescribedin Algorithm 2 .
Algorithm 2:HoeffdingRules– inducing rules froman infi-nitedatastream.
R←Learntruleset;
r←Aclassificationrule;
S←Streamofdatainstances;
Wunseen←Bufferofunseendatainstance;
WHB←Bufferofdatainstancesnotcoveredbyrulesfrom
previousWunseen;
n:pre-definedwindowsize; 7 whileShasmoredatainstancedo 8 i→newinstancefromS; 9 if r∈Rcoversithen
10 Validatetherulerandremoveifnecessary;
else 12 AdditoWunseen; 13 13 ifWunseen=nthen 14 W :=Wunseen+WHB; 15 empty(Wunseen,WHB);
16 Learnruleset,R,inbatchmodeasinAlgorithm3 fromW;
17 AddR toR;
18 WHB:=datainstancesnotcoveredbyr∈R inW;
end end end
3.5.2. Evaluatingexistingrulesandremovingobsoleterules
The evaluation and removal of rules is done online.Once la-belled instances are available, then the rules ofthe current clas-sifier are applied on these instances. Each rule remembers how many instances it has correctly and incorrectly classified in the past. From this, the rule can update its accuracy aftereach clas-sificationattempt.Ifarule’sclassification accuracydropsbelowa pre-definedthreshold(bydefault0.8)andtherulehasalsotaken partin a minimumnumber ofclassification attempts (bydefault 5), then the rule isremoved. The reasonforconsidering a mini-mumnumberofclassificationattemptsistoavoidthattheruleis removedtooearly.
Algorithm3:HoeffdingRules– inducingrulesinbatchmode. 1
for
i
=
1
→
C
do
2
D
←
input
Dataset;
3
while
D
contains
classes
other
than
ω
ido
4
forall
the
α
in
D
do
5
if
α
is
categorical
then
6
Calculate
the
conditional
probability,
P
(
ω
i|
t
α)
for
all
rule
terms
t
α;
else
if
α
is
continuous
then
7
calculate
mean
μ
and
variance
σ
2of
continuous
attribute
α
for
class
ω
i;
8
foreach
value
α
jof
attribute
α
do
9
Calculate
P
(
α
j|
ω
i)
based
on
created
Gaussian
distribution
created
in
line
8;
end
11
Select
α
jof
attribute
α
,
which
has
highest
value
of
P
(
α
j|
ω
i)
;
12
Create
t
αin
form
of
x
<
α
≤
y
as
discussed
in
Section
3.3;
13
Calculate
P
(
t
α|
ω
i)
,
where
t
αis
in
the
form
of
x
<
α
≤
y
;
end
end
16
Calculate
Hoeffding
bound,
=
R2 ln(1/δ) 2∗(no.instancesinD);
17
if
P
(
t
α|
ω
i)
best−
P
(
t
α|
ω
i)
second−best>
then
18Select
t
αfor
which
P
(
t
α|
ω
i)
is
a
maximum;
else
20
Stop
inducing
current
rule;
end
22
Create
subset
S
of
D
containing
all
the
instances
covered
by
t
α;
23
D
←
S;
end
25
R
is
a
conjunction
of
all
the
rule
terms
built
at
line
17;
26
Remove
all
instances
covered
by
rule
R
from
input
Dataset;
27
repeat
28
lines
2
to
22;
until
all
instances
of
ω
ihave
been
removed
;
30Reset
input
Dataset
to
its
initial
state;
end
return
induced
rules
;
Forexample,iftherule’sminimumnumberofclassification at-temptsbeforeremovalisonly1,thenitwouldberemovedalready if the first classification attempt fails. However, withthe default settings,therulewouldatleast‘survive’5attempts.Assumingthat only the firstof the5 attempts fails, then therule wouldbe re-tained,asithasanaccuracyof4÷5=0.8,whichistheminimum classificationaccuracyrequired.
Thedefaultsettingsmaybeadjusted accordingtotheuser re-quirements.Alowerminimumaccuracywillresultintheclassifier adapting slower,however,ahighaccuracymayresultinrules ex-piring quickly, and thus more computationis required to induce newrules.Alsoalownumberofminimumclassificationattempts will result inrules expiring quickly anda high numberof mini-mum classificationattempts willresultina sloweradaptation.In
Fig.6. CombiningdatainstancesthatsatisfytheHoeffdingboundfromthe previ-ouswindowwiththeunseendatainstancesfromthecurrentwindow.
ourexperiments,wehavefoundthatthedefaultvaluesworkwell inmostcases.Thedefaultvalueshavebeenusedinall experimen-talresultspresentedinthispaper.
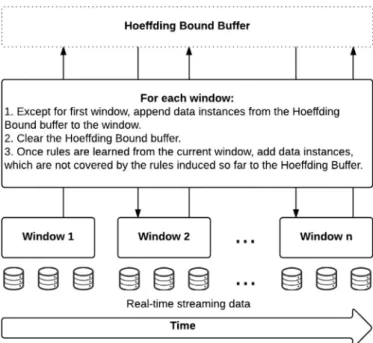
3.5.3. StoringdatainstancesthatdonotsatisfytheHoeffdingbound
OneofthenotablefeaturesofHoeffdingRulesistheuseof Ho-effding Inequality to determine the credibility of a rule term as describedin Section 3.4 .Foranalgorithmbasedon ‘separate-and-conquer’strategy inbatch data,a newruletermis searchedand addedtoacurrentruleuntiltheruleonlycoversdatainstancesof thetargetclass.Slidingwindowtechniqueisusedasdescribedin Section 3.4 to actively learn rulesin real-time. Thewindow con-tainsthe most recenttraining datainstances, and thesedata in-stancesareusedtoinduceclassificationrulesovertime.However, HoeffdingRulesalgorithmdoesnotalwaysinducerulesthatcover onlyexamplesofthetargetclass,becauseHoeffdingRuleswillstop inducingfurtherruletermsiftheruledoesnotsatisfythe Hoeffd-ingboundmetricfromthecurrentsubsetofdatainstances.
Asillustratedin Fig. 6 ,onceallpossiblerulesareinducedfrom theslidingwindowthenalldatainstancesthatarenotcoveredby thenewlycreatedrulesarestoredinabuffer.Thisbufferis com-bined with the next window of unseen data instances from the stream.Hence,afterthefirstwindow,eachslidingwindowisfilled with unseen data instances from the window and the instances fromtheHoeffdingbound bufferfromtheprevious windows.The Hoeffdingboundbuffercontainsinstancesthatarenotcoveredby thecurrentruleset.
3.5.4. Additionofnewrules
Theaddition ofnewrules alsotakesplace online.Asoutlined in Section 3.5.2 ,Hoeffding Rulesapplies its currentrules to new data instances that are already labelled,in order to evaluate the ruleset’s accuracy. However, ifnoneofthe rules applies toa la-belleddatainstance,thenthisdatainstanceisaddedto the win-dow. Once the window of unseen instances reaches the defined threshold,datainstances arelearntasoutlined in Algorithm 2 to inducenew rules,which are thenadded tothe currentclassifier. Nextthewindowisresetbyremovingallinstancesfromit.
Thisisbasedontheassumptionthattheinstancesinthe win-dow will primarily cover concepts that are not reflected by the
currentclassifier.Thus, rules induced fromthiswindow will pri-marilyreflectthesemissingconcepts.Byaddingtheserulestothe classifier,itisexpectedthattheclassifier willadaptautomatically tonewemergingconceptsinthedatastream.
4. Experimentalevaluationanddiscussion
An empirical evaluation has been conducted to evaluate Ho-effdingRulesintermsofaccuracy,adaptivitytoconcept driftand the trade off between accuracy for a white box model such as HoeffdingRules compared with a lessexpressive model such as HoeffdingTree. In addition, Hoeffding Rules has also been eval-uated interms of its expressivenesscompared with its more di-rectcompetitors HoeffdingTreeandVFDR.Thishas been accom-plishedempirically bymeasuring thenumberofaverage decision stepsneededforclassifyingan unseendatainstance,and qualita-tivelybyexaminingsomeofthedecisionrulesinducedby Hoeffd-ingRules ontwo examples. The implementationofthe proposed learningsystem was developed in Java, using the MOA [14] en-vironmentasatest-bed.MOA standsforMassiveOnlineAnalysis andisanopen-source frameworkfordatastreammining.Related totheWEKAproject [46] ,itincludesacollectionofmachine learn-ingalgorithmsandevaluationtoolsspecialtodatastreamlearning problems.TheMOAevaluationfeatures(i.e.,prequential-error im-plementedasEvaluatePrequential)were usedinour experiments. FortheMOAevaluation,thesamplingfrequencywassetto10,000. Thistechniqueandsettingarecommonlyusedinthedatastream miningliterature assuch in [14,47] .Inthe remainderofthis sec-tion,unless statedotherwise,the defaultparameters of theMOA platformwereused.
4.1.Experimentalsetup
Twodifferentclassifierswereusedforcomparingandanalysing theHoeffdingRulesalgorithm.
• VFDR (Very Fast Decision Rules) [13] , is to the best of our knowledgethestate-of-artindatastreamrulelearning.
• Hoefffding Tree [10] , is state-of-art in decision tree learning fromdatastreams.
The rationalebehindthischoiceistwofold:(1)HoeffdingTree hasestablished itselfforthelastdecadeasthestate-of-the-artin datastreamclassification, withalong historyofsuccess; and(2) bothtechniquesusetheHoeffdingboundforresultapproximation, whichwe havealso adoptedinour technique. Itis worth noting that opaque blackbox methods recentlytrialed in a datastream setting like deep learning [48] lack the expressiveness element, andthushavenotbeenchosenforourexperimentalstudy.
Table 1 shows the default parameters for the classifiers that wereusedinallofourexperimentsunlessstatedotherwise.
4.2.Datasets
Different synthetic and real world datasets were used in our experiments.Asforsyntheticdatasets,streamgeneratorsavailable inMOA were used. The real world datasets ‘Airlines’ and‘Forest Covertype’are knownandused forbatch learning,in whichcase all datainstances from datasets are read andlearnt in one pass. However, we simulate these datasets into data streams by read-ingdatainstancesfromthesedatasetinorderedsequenceoverthe time.
Each dataset used in our experiments can be summarised as follows:
• SEA artificial generator was introduced in [49] to test their stream ensemble algorithm. The dataset has two class labels
and three continuous attributes in which one attribute is ir-relevanttotheclasslabelsandunderlyingconceptofthedata stream.Moreinformationhowthisdatastreamisgeneratedis describedin [49] . Bifet etal. [9,13,15] also usethis datasetin theirempiricalevaluationsamongotherdatasets.
• RandomTree Generatorwasintroduced in [10] andgenerates astreambasedonarandomlygeneratedtree.Thegeneratoris basedonwhatisproposedin [10] .Itproducesconceptsthatin theoryshouldfavourdecisiontreelearners.Itconstructsa de-cision treeby choosing attributes atrandom for splittingand assignsarandomclasslabeltoeachleaf.Oncethetreeisbuilt, newexamplesaregeneratedbyassigninguniformlydistributed randomvaluestoattributes,whichthendeterminetheclass la-belusingtherandomlygeneratedtree.
• STAGGER was introduced by Schlimmer and Granger [50] to test the STAGGERconcept drift tracking algorithm. The STAG-GERconcepts areavailable asa datastreamgeneratorinMOA andhasbeenusedasabenchmarkto testforconceptdriftin [50] . The dataset represents a simple block world defined by threenominalattributessize,colourandshape,each compris-ing3differentvalues.Thetargetconceptsare:
size≡small∧color≡red color≡green∨shape≡circular size≡(medium∨large)
While performing preliminary experiments with the data stream generators in MOA, it became apparent that the con-cepts defined did not match the ones proposed in the orig-inal paper. This was observed from the rules generated by ourapproach fromthe STAGGER datastream. Meanwhile, the ‘bug’ was reported to the MOA development team and the current, corrected implementation of the generator has been usedforthe experimentspresentedinthis section.This high-lights the expressiveness of the rules induced by Hoeffding Rules.
• ForestCoverType contains the forest cover type for 30 × 30 meter cells obtained from US Forest Service (USFS) Region 2 ResourceInformationSystem(RIS)data.Itcontains581,012 in-stancesand54 attributes,andit hasbeenused inseveral pa-persondatastreamclassification,i.e.,in [51] .
• Airlinesdatasetwasgeneratedbasedontheregressiondataset by ElenaIkonomovska, whichconsistsof about500,000 flight records.Themain taskofthis datasetisto predict whethera givenflightwillbedelayedbasedontheinformationof sched-uleddeparture.Thisdatasethasthreecontinuousandfour cat-egoricalattributes.ElenaIkonomovskaalsousesthisdatasetin oneofherstudiesondatastreams [52] .Thisdatasetwas down-loadedfromtheMOAwebsiteandusedinourempirical exper-imentswithoutanymodifications.
Allsyntheticdatastreamgeneratorsarecontrollableby param-etersand Table 2 showsthesettingsusedforallsyntheticstreams inourevaluation.
4.3. Utilityofexpressiveness
The empiricalevaluation isfocused on thecost of expressive-nesswhencomparingtheaccuracyandperformancebetween clas-sifiersfordatastreams.
4.3.1. Accuracylossband
Asmentionedin [17] ,alearntmodelfromthelabelleddata in-stancesmayproducehighpredictive accuracyforunlabelleddata, butthelearntmodelcan behard andcomplextounderstandfor human users or even domain experts. All classifiers were evalu-atedonthe samebasedatasetsinordertoexaminethetrade-off betweenrule-based classifierssuch asVFDR andHoeffdingRules
Table1
Parametersettingsforclassifiersusedintheexperiments.
HoeffdingRules VFDR(VeryFastDecisionRules) HoeffdingTree
VF.P:0.1 HT.NUE:Gaussianobserver
VF.SC:0.0 HT.NOE:Nominalobserver
HR.SW:200 VF.TT:0.05 HT.GP:200
HR.MRT:3 VF.AAP:0.99 HT.SC:Informationgain
HR.RVT:0.7 VF.PT:0.1 HT.SCON:0.0
HR.HBT:0.01 VF.AT:15 HT.TTH:0.05
HR.APT:0.5 VF.GP:200 HT.BS:false
VF.PF:Firsthit HT.RPA:false
VF.OR:false HT.NPP:false
VF.AD:false HT.LP:NBAdaptive
VF.P:%oftotalsamplesseeninthenode HT.NUE:Numericattributeestimator VF.SC:Splitconfidence HT.NOE:Categoricalattributeestimator
HR.SW:Slidingwindowsize VF.TT:Tiethreshold HT.GP:Graceperiod
HR.MRT:Minimumruletries VF.AAP:Anomalyprobabilitythreshold HT.SC:Splitcriterion HR.RVT:Rulevalidationthreshold VF.PT:Probabilitythreshold HT.SCON:Splitconfidence HR.HBT:Hoeffdingboundthreshold VF.AT:Anomalythreshold HT.TTH:Tiethreshold
HR.APT:Adaptationthreshold VF.GP:Graceperiod HT.BS:Binarysplit
VF.PF:Predictionfunction HT.RPA:Removepoorattribute
VF.OR:Orderedrules HT.NPP:Nopre-prune
VF.AD:Anomalydetection HT.LP:Leafpredictive
Table2
Parametersettingsforsyntheticstreamgeneratorsusedintheexperiments.
RandomTree RandomTreewithdrift SEA SEAwithdrift STAGGERS STAGGERwithdrift
Beforedrift Afterdrift Beforedrift Afterdrift Beforedrift Afterdrift
RT.TRSV:1 SEA.F:1 ST.IRS:1
RT.ISV:1 RT.TRSV:1 RT.TRSV:5 SEA.IRS:1 ST.F:1
RT.NCL:4 RT.ISV:1 RT.ISV:5 SEA.BC:true ST.BC:true
RT.NCA:5 RT.NCL:4 RT.NCL:4 SEA.NP:10% SEA.F:1 SEA.F:2
RT.NNA:5 RT.NCA:5 RT.NCA:5 SEA.IRS:1 SEA.IRS:1 ST.IRS:1 ST.IRS:1
RT.NVPCA:5 RT.NNA:5 RT.NNA:5 SEA.BC:true SEA.BC:true ST.F:1 ST.F:2
RT.MTD:5 RT.NVPCA:5 RT.NVPCA:5 SEA.NP:10% SEA.NP:10% ST.BC:true ST.BC:true
RT.FLL:3 RT.MTD:5 RT.MTD:5
RT.LF:15% RT.FLL:3 RT.FLL:3
RT.LF:15% RT.LF:15%
Driftat:150,000 Driftat:150,000 Driftat:150,000
Driftwidth:10,000 Driftwidth:10,000 Driftwidth:10,000
RT.TRSV:Treerandomseedvalue RT.ISV:Instanceseedvalue RT.NCL:Numberofclasslabels
RT.NCA:Numberofcategorialattribute(s) SEA.F:Classificationfunctionasdefinedinpaper
RT.NNA:Numberofnumericalattribute(s) SEA.IRS:Seedforrandomgenerationofinstances ST.IRS:Instancerandomseed
RT.NVPCA:Numberofvaluespercategoricalattribute SEA.BC:Balancedclass ST.F:Classificationfunction
RT.MTD:Maxtreedepth SEA.NP:Noisepercentage ST.BC:Balancedclass
RT.FLL:Firstleaflevel RT.LF:Leaffraction
∗400,000datainstancesaregeneratedforeachexperiment.
∗Ineachexperiment,allclassifiersaregivenidenticaldatainstancesandsamesequencedorder.
comparedwithtreebasedclassifierssuch asHoeffdingTree. Con-ceptdriftwasalsosimulatedinallsyntheticdatasetsfrom150,000 data instancesonwards forapproximately1000 furtherinstances, wherebothconceptswerepresentbeforeswitchingcompletelyto thenewconcept.Theaccuracy lossband
ζ
can beeitherpositive or negative, where positive values indicate that Hoeffding Rules achievesabetteraccuracyandnegativevaluesindicatethe short-fallinaccuracycomparedwithitscompetitor.Figs. 7 a–f, 8 aandbshowthataccuracylossband
ζ
of Hoeffd-ingRulesisverycompetitivecomparedwithHoeffdingTreewhile clearlyoutperformingVFDRinmostcases.Thereadershouldnote that the existing implementations of Hoeffding Tree, VFDR and syntheticdatageneratorsinMOAwereused,theseclassifiersmay havebeenoptimisedtoworkwellonthesesyntheticdatasets.Two real datasetsAirlines andCoverType are chosen andincluded for anunbiasedevaluation.VFDRistheclosestalgorithmtoHoeffding Rulesbecauseitisanativerule-basedclassifierwiththeabilityto producerulesdirectlyfromtheseenlabelleddatainstances. How-ever,VFDRdoesnotofferabstainingandforcesaclassification.Ev-idently, HoeffdingRules has a positive loss band compared with VFDRonbothrealandsyntheticdatasetsandoutperforms Hoeffd-ingTreeon theAirlinesdataset,while sufferingaminornegative lossbandonafewoccasionsontheCovertypedataset.
4.3.2. Costofexpressiveness
Wealsoestimatedthecost ofexpressivenessintermsofsteps required for a model to predict a class label. This evaluation is focussedon the most expressive rule and treebased algorithms. Moredecisionmakingstepsinruleandtreebasedalgorithms im-pliesmoreandpotentiallyunnecessary andcostly testsforauser to obtain a classification, which is not desirable [12,53] . Support VectorMachines andArtificial NeuralNetworks basedalgorithms arenotinvestigatedhereastheyarenearlynon-expressiveand dif-ficulttocomprehendby humananalysts.Alsoinstancebasedand probabilisticmodelsarenotveryinterestingtothehumananalyst interms ofexpressiveness asthey only indirectlyexplain a clas-sificationthrougheithertheenumeration ofdatainstances inthe
Fig.7. Differenceinaccuracycomparedwithotherclassifiersforsyntheticdatastreams.
Fig.8. Differenceinaccuracycomparedwithotherclassifiersforrealdatastreams.
caseof instance based learners,or through basic probabilities in thecaseofprobabilisticlearners.
Classification steps for HoeffdingRulesand VFDR refer tothe numberof rule terms (conditions) in a rule that are needed for classifyingadatainstance.Similarlyclassificationstepsfor Hoeffd-ingTreerefertothenumberofnodesthatneedtobevisited (con-ditions)fromtherootofthetreetotheleafthatprovidesa partic-ularclassification.Asshownin Fig. 9 a–h,HoeffdingRulesismore competitive in terms of numberof classification steps over time compared with the Hoeffding Tree classifier. We observed in all experiments that HoeffdingTree does not start building its tree
modeluntilseveralthousanddatainstanceshavebeenbufferedto satisfy the HoeffdingInequality. HoeffdingTreedoesnot limit the depth ofthetree nordoesit havea built-in pruningmechanism torestrictits size,thusitgrowslargerovertime.Thisisreflected in the increasing numberof steps required over time to classify data instances as can be seen in Fig. 9 a–h. In addition, we ex-pectallthreeclassifierstoadapttoconceptdrifts.Therule-based classifierswillchangetheirrulesets,whereas HoeffdingTreewill replaceobsoletesubtreeswithnewersubtrees. Eitherway,a con-cept drift mayalter thenumberof stepsneededto reach a clas-sification significantly.This explains the more abrupt changes of
Fig.9. TheaveragenumberofclassificationstepsneededbyHoeffdingRulescomparedwithHoeffdingTreeandVFDR.
Table3
AccuracyevaluationbetweenHoeffingTree,VFDRandHoeffdingRules.
Algorithm Measure(%) Dataset
SEA RandomTree STAGGER ForestCovertype Airlines
Nodrift Withconceptdrift Nodrift Withconceptdrift Nodrift Withconceptdrift
HoeffdingRules Tentativeaccuracy 82.6 84.30 81.86 75.62 100 98.50 74.24 66.74
Abstainingrate 8.07 6.43 49.51 56.02 22.27 28.52 10.04 16.47
VFDR Overallaccuracy 81.3 82.26 52.28 47.07 100 86.20 61.32 62.50
HoeffdingTree Overallaccuracy 88.08 89.23 88.98 61.08 100 99.75 82.04 66.04
Fig.11.LearningtimeHoeffdingRules,HoeffdingTreeandVFDR.
classificationstepsofsomealgorithmsfortheSTAGGERand Cover-typedata streams depictedin Fig 9 fandh. Regarding the Cover-typedatastream,itconsistsofrealdataandthusitisnotknown ifthereisaconceptdrift.However,themoreabruptchangesofthe numberofclassificationstepsindicatesthatthereisadriftstarting somewherebetweeninstances150,000to200,000.Thuswe have useda separate concept drift detectionmethod, a version ofthe Micro-Clusterbased concept drift detection method presented in [54,55] ,which has confirmeda drift starting atposition 150,000 instances.
Fig. 9 a–h also compare the average number of classification stepsof HoeffdingRuleswithVFDR. Thefigures show thatVFDR hasaverysimilaraveragenumberofclassificationstepscompared withHoeffdingRules.Forallobservedcases,exceptforthe Cover-type datastream, HoeffdingRules needs an average of about1.5 classification steps only. However, as shown in Table 3 , Hoeffd-ingRulesachievesamuchhigherclassificationaccuracythanVFDR andinmostcasesalsorequireslesstimetolearnasillustrated in Fig. 11 .In mostcaseswherethereis conceptdrift itcan beseen that the numberof average classification steps increasesfor Ho-effdingTree,whereasHoeffdingRules’andVFDR’saveragenumber ofclassificationstepsstaysalmostconstant.
The number ofsteps requiredfora classification task demon-stratesthe effortrequiredtotranslate a classificationfroma tree basedmodelintotheformofan expressive‘IF... THEN...’rule.The currentimplementation ofHoeffdingTreein MOA,aswell asthe HoeffdingTree algorithm presentedin its original paper [10] , do notprovide anymechanismfortranslating aleaf intoan expres-siverule.Onecanarguethat asetofdecisionrulescan beeasily extractedfrom an existing tree model asQuinlan [56] has men-tionedasearly asin1986. An extracteddecisionrule froma hi-erarchicalmodelrepresentslogictestsfromarootnodetoa leaf. However,asHoeffdingTreeisdesignedtoadapttochangesindata streams,thisextraction processwould needto repeatevery time thetree expandsor changes its structure. Therefore, maintaining an accurate andup-to-date rule set froma Hoeffding Treecould beachallengeandacomputationallydemandingtask.
Forsyntheticdatasetswithconceptdriftat150,000in Fig. 9 b,d andf,wedetectednotablechangesinthenumberofstepsrequired forclassificationusingHoeffdingTreebutnotforusingHoeffding
Rule andVFDR.This isan expectedbehaviour becauseHoeffding Treemayneedtoreplaceanentiresubtreeorintheworstcasethe entiretreefromtherootnodeifthereisadriftinthedatastream. However, rule-basedclassifierssuch asHoeffdingRulesandVFDR do not need to replace larger numbers of rules, as rules can be examined, alteredandreplaced individually.Examining,replacing andalteringindividual ‘rules’ (decision paths fromtheroot node toaleafnode)isnotpossibleintreeswithoutalsoalteringfurther ‘rules’thatareconnectedtotheruletobechangedthrough inter-mediatetreenodes.Forrealdatasets,wedonothaveanabsolute ground truth whether concept drifts are encoded in the data or not,butwe expect tosee conceptdrifts inreal-life datastreams. In particular, we saw a correlated behaviour between abstaining andclassificationstepsin Figs. 9 hand 10 fortheCovertypedataset between150,000and200,000instances.Asmentioned beforewe haveused a version ofthe Micro-Clusterbased concept drift de-tectionmethodpresentedin [54,55] ,whichconfirmedadrift start-ingatposition150,000instances.InthisparticularcaseHoeffding Rulesdropped slowlyin theaverage numberofsteps neededfor classification, and Hoeffding Tree suddenly stopped growing and stalledforabout50,000datainstancesbeforestartingtogrow fur-ther.Hence,webelievethatHoeffdingTreealsoadaptedtoadrift here.
4.3.3. Expressiverules’rankingandinterpretation
Atanygiventimeausercaninspectthedecisionrulesdirectly from the rule set produced by HoeffdingRules and can be con-fidentthat therulesreflecttheunderlyingpatternencodedinthe datastreamatanygiventime.Forexample,weextractedthetop3 rules(based ontherules’individual classificationaccuracy)learnt fromthetworealdatasets,CovertypeandAirlinesat50,000data instances:
• Covertypedataset:
• IFSoil-Type40=0ANDSoil-Type30=0ANDSoil-Type38=0
THENClass=0
• IFSoil-Type38=1THENClass=7
• IF Soil-Type10 =1AND 0.57 < Aspect <=0.64 THEN Class
=6
• Airlinesdataset:
• IFAirportTo=CHAANDDayOfWeek=3ANDAirportFrom= ATLANDAirline=EV THENClass=1
• IFAirportFrom=CLTTHENClass=0
• IFAirportTo=AZOTHENClass=1
Asitcanbeseen,rulesinducedbyHoeffdingRulescanbe mod-ular (independent from each other) meaning that the rules not necessarilyhaveanyattributesin common, whichisnot possible whenrulesarepresentedinatreestructure.Rulesextractedfrom a treewillhave atleastthe attributechosen to split onthe root node incommon, even ifthisattributemaynot be necessaryfor someclassificationtasks.Thusatreestructuremayresultin poten-tiallyunnecessary andcostlytestsfortheuser.Thisisalsoknown asthereplicatedsubtreeproblem [30] .Wereferto Section 3.2 for anexplanationofthereplicatedsubtreeproblem.
Inadditionasmentionedin Section 4.2 ,whileperforming pre-liminaryexperiments withthedatastream generatorsin MOA,it becameapparentthat theconceptsdefinedfortheSTAGGER gen-eratordidnotmatchtheonesproposedintheoriginalpaper [50] . This furtherhighlights theexpressivenessofthe ruleset induced by HoeffdingRules. This‘bug’wasreportedto theMOA develop-ment team and a corrected version of the stream generator was usedfortheexperimentsdescribedinthispaper.
4.4. Abstainingfromclassification
The results presented in Section 4.3 showed the tolerance of rule-basedclassifierscomparedwithdecisiontreebasedclassifiers fortheutilityofexpressiveness. Anotherimportantfeatureof Ho-effding Rulesisthe abilitytoabstain. In Fig. 10 ,we observethat theabstainingrateofHoeffdingRulesdecreasesasHoeffdingRules processes more instances, except for the Random Tree dataset. For synthetic datasets withconcept drift, we also notice that at thepointofsimulatedconceptdrift(150,000),theabstainingrate spikedupbutquicklyrecoveredtoadapttothenewconcept.This indicates one of the major benefits of abstaining instances from classification, when HoeffdingRulesis uncertain abouta classifi-cationit doesnot riskclassifyingunseendatainstances.This fea-tureisdesirableorevencrucialindomainsandapplicationswhere miss-classificationiscostlyorirreversible.Asmentionedbeforewe haveuseda versionofa Micro-Clusterbasedconceptdrift detec-tionmethodpresentedin [54,55] ,whichconfirmedadriftstarting atposition150,000instances.
Table 3 showstheaccuracyevaluationbetweenHoeffdingTree, VFDRandHoeffdingRules. OneuniquefeatureofHoeffdingRules is itsabilityto refusea classificationiftheclassifier isnot confi-denttooutputadecisivepredictionfromitsruleset.Werecorded the tentative accuracyand abstainingrate forHoeffdingRules as wellasoverallaccuracyforHoeffdingTreeandVFDR.Tentative ac-curacyforHoeffdingRulesistheaccuracyforinstanceswherethe classifierisconfidenttoproduceareliableprediction.Thetentative accuracywasalsousedforestimatingtheutilityofexpressiveness shownin Section 4.3 .
WecanseethatHoeffdingRulesoutperformsVFDRinallcases and is very competitive compared with Hoeffding Tree, both on syntheticandrealdatastreams.HoeffdingRulesisalsocompetitive withHoeffdingTree,theaccuracyofboth classifiersisvery close, with Hoeffding Rules outperforming Hoeffding Tree in 3 cases. However,comparedwithHoeffdingTree,HoeffdingRulesproduces amoreexpressiverulesetandfundamentallydoesnotsufferfrom the replicated subtree problem. Also, theclassification rules gen-eratedbyHoeffdingRulescanbeeasilyinterpretedandexamined byhumanusersordomainexperts.Decisiontreeswouldfirstneed toundergoafurtherprocessingstepbeforeahumanusercan in-terpret therules.This wouldtranslatethe treeintorules starting in singlepassesfromthe rootnode downto each leaf.This may well beatoocumbersomeandatootimeconsumingtaskforthe decisiontaker.
Automatingtreetraversaltoincreaseexpansivenessisan addi-tionallinearprocesswithrespecttothenumberoftreenodes,or initsbestcaseforbalancedtrees,itcanbe O(log(tn))wheretn is
thenumberofnodesinthetree [57] .
4.5. Computationalefficiency
In ordertoexamine HoeffdingRules’ computationalefficiency, we havecompared HoeffdingRules, VFDR andHoeffdingTreeon thesamedatastreams asin Table 3 .As shownin Fig. 11 ,the ex-ecution time ofHoeffdingRulesoutperforms that ofVFDRby far andisalsoveryclosetothatofHoeffdingTrees.
It canbe seen that HoeffdingRules isparticularly superior to VFDR fordata streams withmostly numerical attributes such as theSEA andRandom Tree(RT) datastreams. Thisis expectedas VFDR needs many cut-point calculations for inducing new rule terms from numerical attributes, whereas Hoeffding Rules just needs to update the Gaussian Probability Density Distributions. Thiscomputationaldifferencehasbeendiscussedin Section 3.3
Insummary, loosely speaking,Hoeffding Rulesshowsa much betterperformanceintermsofutilityofexpressivenesscompared with its direct competitor VFDR and is also competitive com-paredwithitslessexpressivecompetitorHoeffdingTree.Thesame countsfortheevaluationwithrespecttocomputationalefficiency, HoeffdingRules’ runtimesaremuch shortercomparedwithVFDR andonlyslightlylongercomparedwithHoeffdingTree.
5. Conclusions
The research presented inthis paperis motivatedby thefact thatrule-baseddatastreamclassificationmodelsaremore expres-sive than other models, such as decision tree models, instance based models and probabilistic models. Inducing a classifier on data streams has some unique challenges compared with data miningfrombatchdata,asthepatternencodedinthestreammay change over time which is known as concept drift. While most datastreammining classification techniquesfocusonachievinga highaccuracyandquickadaptationtoconceptdrift,theyareoften ratherunfriendly,cumbersomeortoocomplexto providetrustful decisionstotheusers,whichisundesirableinmanydomainssuch assurveillanceormedicalapplications.
This paper proposed the new Hoeffding Rules data stream classifier that focusses on producing an expressive rule set that adapts to concept drift in real-time. Compared withless expres-sivedata streamclassifiers,HoeffdingRulesexplains howa deci-sionisreached.Thealgorithmisbasedona‘separate-and-conquer’ approach andthe Hoeffdingbound to adapt the ruleset to con-cept drifts inthe data.Different comparedwithexisting well es-tablished data stream classifiers, Hoeffding Rules may decide to abstainfromclassifyingadatainstanceifitisuncertainaboutthe trueclasslabel.Thisagainisdesirableinapplicationswhereafalse classification label may be very costly such asin medical appli-cationsornetworkintrusion detection.Additionally,theabstained datainstancescanalsobeconsideredforactivelearning,whichis adirectiontogoforwardforourproposedHoeffdingRules classi-fiertoimproveandmaximisetheeffectivenessofthelearntmodel. Inthis way,the abstainingfeature is not justreducing the miss-classificationbutcanalsopotentially improvethe accuracyofthe overallmodel.
An empirical evaluation examined the utility of inducing ex-pressive rules with Hoeffding Rules compared with its competi-tors VFDRandHoeffdingTree.VFDR is anotherhighlyexpressive rule-based classifier, and Hoeffding Tree is a less expressive but state-of-the-art tree based data stream classifier. The evaluation measuredthelossband