Copyright © 2015 Inderscience Enterprises Ltd.
Clone attack detection and data loss prevention in
mobile ad hoc networks
Ganapathy Mani
Department of Computer Science, George Washington University, Washington, DC, USA
Email: gans87@gwu.edu
Abstract: Wireless ad hoc networks, mobile ad hoc networks (MANETs) in particular, are not protected by tamper-resistant or equipped with high-storage-capacity hardware because of their low-cost and small size. So they are highly vulnerable to intrusion, node compromise, physical capture attacks and data loss. Due to harsh environments where these devices operate, they face data loss and reduced data availability, and if captured by an attacker, the devices can easily be compromised and cloned. The cloned devices will have the same identity as legitimate devices and interact with other devices to compromise them. In this paper, we propose two mechanisms: 1) novel clone attack detection scheme – log in log out detection (LLD) and system-wide announcement detection (SWAD) using low-energy dynamic (LED) clustering; 2) combinatorial replication and partition (CORP) of data – pairwise balanced design property of combinatorial arrangement – to prevent data loss. These mechanisms can be extrapolated to geospatial networks as well.
Keywords: mobile ad hoc networks; MANETs; data loss; clone attacks; replica attacks; combinatorial design; data replication; data availability; fault-tolerance.
Reference to this paper should be made as follows: Mani, G. (2015) ‘Clone attack detection and data loss prevention in mobile ad hoc networks’, Int. J. Space-Based and Situated Computing, Vol. 5, No. 1, pp.9–22.
Biographical notes: Ganapathy Mani received his Master in Computer Science at the George Washington University in Washington DC, USA. He is a Lecturer in the Department of Computer Science at George Washington University. His research interests include network protocols, distributed systems, information management, and human-computer interaction. He has authored several international conference publications and invited for several presentations. He received his Bachelor’s degree in Electronics and Communication Engineering from Anna University, India.
This paper is a revised and expanded version of a paper entitled ‘CORP: an efficient protocol to prevent data loss in mobile ad-hoc networks’ presented at the 27th IEEE International Conference on Advanced Information Networking and Applications Workshop (WAINA), Barcelona, Spain, 25–28 March 2013.
1 Introduction
Two of the major concerns in mobile ad hoc networks (MANETs) are detecting or preventing cloning (replica) attacks as well as preventing data loss to increase the fault-tolerance of the entire network.
1.1 Data loss in MANETs
Due to unpredictable node movements, harsh working environments, and quick battery exhaustion, the devices in the network often loose their communication links creating multiple partitions in the network. Studies (Vallur et al., 2008; Derhab and Badache, 2009) have shown the significant negative impacts due to the loss of data during communication. MANETs are of paramount importance in disaster management, search and rescue missions, military
and law enforcement activities, and combat zones during war. Data loss and lack of data availability during communication can have devastating consequences in those operations.
1.1.1 Inadequacies of current solutions in preventing data loss
There are several schemes of data replication protocols such as Hara and Madria (2006), and Derhab and Badache (2006) to prevent data loss in MANETs. Any mechanism that uses data replication must address the challenges faced by MANETs such as limited energy storage of devices, fast drainage of battery, limited storage capacity, and unpredictable node mobility in the network. Two basic approaches – based on flooding the network – have been proposed to tackle data loss in MANETs:
1 a distributed approach of flooding the entire network with the information about the data or metadata (information about the real data)
2 selective flooding through algorithms based on gossip or epidemic where the messages are sent to the near by nodes that are chosen randomly.
The first method is not feasible due to the limited storage space of MANETs’ devices and the second method cannot be used in sparse networks because the devices that are far away will not receive the messages due to the limited communication range. Even if they are willing to communicate to the long distances, it would result in increased communication overhead thus draining the battery.
Reference point group mobility (RPGM) proposed by Wang and Li (2002). Here, the authors assume constant speed for the devices in MANETs. But in the real world, the devices in MANETs can have different velocity levels for each individual device determined by the service providers. Sawai et al. (2006), and Haas and Liang (1999) proposed Quorum (subset)-based replication mechanism where subsets of replicated servers will be selected randomly and they will perform the operations among that subset of devices. This saves energy for each device because its communication range is reduced. But these subset of devices face the danger of draining their batteries fast. Since the entire network is based on these subsets of devices, if the battery is drained, it could jeopardise the entire network’s functionality. They are also constrained by very limited memory space.
Chen et al. (2002) proposed a distributed mechanism where each node is aware of its partition and broadcasts an announcement called ad to the entire network. The message ad contains the information about the free space available in the node, sequence number, and processor utilisation. Local nodes will update their lookup tables based on this message. But the lookup table’s information increases exponentially because of the node movements thus increasing the storage overhead. Dynamic connectivity-based grouping (DCBG), static access frequency (SAF), dynamic access frequency, and neighbourhood (DAFN) methods were proposed by Hara (2001) to increase the data availability through reallocation methods. But these methods’ reallocation period is a constant thus they cannot adapt to the unpredictable movement and various routing mechanisms of MANETs.
1.1.2 Our contributions to solve the problem
We propose combinatorial replication and partition (CORP) scheme to make a perfect distribution of replicated data among host nodes in the network. Our scheme significantly reduces the data loss and increases the data availability.
• Using combinatorial organisation (balanced block designs) of the network communication links, CORP allows the data item to be replicated only few times and yet significantly increases the data availability.
• CORP increases the intrinsic reliability of the entire network with its fault-tolerance capability. It also allows the nodes that have replicated data items to interact concurrently thus allowing faster data transmission.
• Because the mobile nodes will be aware of their remaining energy and speed, they can request another node to continue the work if it is moving fast or if there is no or little energy remaining. This increases data availability as well as fault-tolerance of the network.
• The devices with high remaining energy and average speed will only be selected to be the host of data transmission. The device with the low energy will not participate in the network partition thus extending its life.
1.2 Clone attacks in MANETs
Security in MANETs is a widely studied topic and there are significant challenges in preventing as well as detecting the attacks (Martin and Guyennet, 2011; Meng et al., 2013; Atassi et al., 2014; Indra and Taneja, 2014). Due to their low cost and small size, MANETs are very useful in several areas. But it comes at the cost of security. A recent study (Gligor, 2007) shows that MANETs are highly susceptible to physical capture and/or node compromise attacks because of the low-cost hardware, small size, and very limited resources in the devices. As a consequence, the attackers can launch node clone attacks in which an attacker can deploy several cloned nodes in the network. These clones can collude and become the base of several other attacks. MANETs communication protocols basically rely on forwarding/relay. The clones can easily manipulate these protocols and mislead the entire network and cause significant damage by blocking traffic in the network, compromise communication channels, and launch gray-hole and wormhole attacks (Hu et al., 2002; Song et al., 2005).
Since these clones have all the credentials such as keys, proper IDs etc. as that of legitimate devices in the network, they can participate in the network’s communication processes. This can lead to various insider attacks (Liu et al., 2007; Capkun and Hubaux, 2005) and take over of the entire network. In a recent study these clones are referred to as ‘attack multipliers’ (Xing and Cheng, 2010). So it is crucial to devise solutions for this problem while using less resources (storage, computation, power, etc.) from the devices in the network.
1.2.1 Inadequacies of current solutions to detect clone attacks
The detection of clone attacks in MANETs is a hard challenge due to the need for designing schemes with respect to underlying mobility, the large number of wide spread cloned nodes, and cloned nodes collusion. A method proposed in Shaw and Kinsner (1997) stores a unique signature for the device based on its signal transmission characteristics at the base station. Any device that violates
the signature characteristics would considered to be a cloned node. Procedures like this are used by cell phone network administrators to prevent the cloning of devices. But in mobile multi-hop environments, it is very hard for the base station to track individual devices and their multi-hop way transmission characteristics. Some of the current methods to detect clones, fail due to node mobility, local view of the network by the detection devices, and they fail to address node collusions. Other localised schemes (Liu et al., 2007) fail to detect clone attacks when they are widely distributed in the network.
A centralised hierarchical method was proposed in Choi et al. (2007) where the network will be divided into several sub-regions and each one will have a header node to keep track of the devices in the sub-regions. From the hierarchical tree, child nodes report to the header nodes and header nodes report to base station. When combining the member lists reported by child nodes, a header node checks the intersection of two node reports and any empty intersection indicates the presence of cloned nodes in the network. Brooks et al. (2007) also proposed a centralised scheme where the base station collects the key usage statistics (number of times a key is used for communication processes) and detects clones in frequency domain, i.e., frequent use of the key causes the base station to report a clone attack based on the assumption that the number of node pairs that select the same random key is independent and identically distributed. Eschenauer and Gligor (2002) proposed a scheme where the random keys are preloaded to each node and two other neighbours establish a shared key if the preloaded keys have at least one in common.
There have been three recent studies for clone attacks detection in mobile environment. A localised scheme XED was proposed in Yu et al. (2008) in which each node remembers the random number it issued when it met with other nodes. When these two nodes meet again, they check this random number they exchanged last time. If the numbers do not match then they report clone attacks. Even though this scheme does not have any limitation on the number of clones/compromised nodes in the network, the scheme will fail if the nodes collude with each other. They can mislead the protocol by synchronising their random number to respond to legitimate nodes. Another centralised solution called SPRT was proposed in Ho et al. (2009). If the speed of the node is more than the initial speed limit set by the service provider, they predict that there must be clone attacks in the network. But collusive nodes can synchronise their movements and hide from the detection protocols. Same as XED, SPRT does not resist the colluding clones.
Detection protocols TDD and SDD were proposed in Xing and Cheng (2010). They detect clones both in time and space (location) domain based on a key exchange mechanism. MANET nodes use an ordered one-way encryption function called a challenge chain to periodically report their location and time to their two-hop neighbours. Violation of challenge chain order and unique location at a given time epoch is considered to be a clone attack on the node. These methods works fine with collusive nodes and
mobility. But when it comes to sparse networks (Garetto et al., 2008), a node cannot follow the two-hop neighbourhood rule, and thus the compromised nodes can collude. Normal node behaviours such as switching off or suddenly loosing signal could wrongly be interpreted as clone attacks. Since each node must save the logs of all the nodes it meets, the storage cost increases linearly and the energy consumption increases drastically. But MANET devices are not designed to save large amounts of data or posses huge batteries.
1.2.2 Our contributions to solve the problem
In this paper, we propose two schemes to detect clones with LED clustering. These methods allow the clones to generate contradictory information. Comparing with the existing studies mentioned in the introduction, we have the following significant unique contributions.
• Our schemes have the capability of making the clones generate contradictory information when they engage in exchange with other nodes or move to a new cluster.
• Since our methods do not have any limitations on the number of clones and their distribution in the network, we provide excellent resilience against collusive clones. Since we do not make any assumptions about the mobility models, our scheme can be applied to wide range of MANETs. These are significant improvements compared to the schemes (Ho et al., 2009; Yu et al., 2008).
• Unlike Xing and Cheng (2010), we initiate the detection process whenever it is necessary instead of constantly reporting to nearby nodes.
• We take advantage of system-wide announcements (SWAs) to make sure that the cluster head knows the current status of the node, which avoids misinterpretation of normal silence (like switched off) of a node.
• The network is divided into clusters, which makes our scheme a localised one. But at the same time, we make sure it has globalised view of the entire network through cluster heads.
• Finally, our schemes make use of a simple one-way hash function for clone detection, which produces very low computation overhead.
2 Assumptions, notations and models
2.1 Network model
We consider the networks consisting of mobile devices or wireless sensors with mobility [vehicular ad hoc networks (VANETs) and internet-based mobile ad hoc networks (iMANETs)]. In most cases, these devices are not equipped with tamper-resistant hardware. The communication range of the network is from NRmin to NRmax and Rmin to Rmax is for
a node. Table 1 represents the notations that we used in this paper.
Table 1 Table of notations
Notations Means
MH Mobile host for data transfer
d Data item
UT Update trigger for data messages
NR Communication range of the entire network
N N nodes in network
CR One side length of a cluster
2
R
C Area of a cluster
ct Number of nodes in a cluster
R The communication range of a node
C The cluster
CH Cluster head
T R Trigger for security
H Hash function
hp Hash pair
f Function
Sig Signature
lc Location coordinates
D Distance between the node and cluster head
P Remaining power in the device
2.1.1 Network clusters
We divide the communication range into equal parts to form a network cluster grid (NCG) formation. We assume that each side of the network clusters will be equal in size, which can help to manage clusters effectively without any confusion over boundaries. Each cluster can have their own shape as long as they satisfy the following equation,
max max R NR C λ = (1)
where CRmax is the communication range of the clusters, λ is the desired number of clusters in the network, λ ≥ 1, NRmax%λ ≈ 0, and CRmax ≤Rmax. An advantage of this arrangement is that the service provider will be able to set the value for λ based on the overhead that they will be able to sustain. This gives the flexibility to the service provider to set the right number of clusters based on their requirements and other factors such as cost and energy. Also, we use this arrangement to reduce long distance communication overhead. These boundaries for clusters can be monitored and maintained through GPS (Hofmann-Wellenhof et al., 1993) systems. Each cluster (Cid) will have a cluster head (CHCid) for monitoring ct
number of nodes. These cluster heads will have sufficient battery power (P), and storage capacity to carry out the tasks. Each cluster will have two backup nodes to take over the CH’s responsibilities in case the cluster head stops
communication [Wu et al. (2008), and Younis and Fahmy (2004) show having cluster head backups is possible]. One CH backup will be close to the current CH and another backup will be far from the CH. We will discuss the rationale behind this arrangement in Section 5. During the deployment of the nodes, the cluster heads are initially selected by the network service provider (or base station). Cluster heads store the information about all the nodes in their cluster. We assume that every node in a cluster is able to obtain information about its location coordinates and verify other nodes location in the cluster through GPS (Hofmann-Wellenhof et al., 1993) or other positioning methods (Thaeler et al., 2005; Yi et al., 2007b). We further assume that the clocks of all nodes are loosely synchronised. We use t1, t2, t3, …, ti, …, tj, … to represent the time moments in the cluster where tj < tj given i < j, i, j∈Z+. We assume that the data is partitioned into data items (di) based on our combinatorial arrangement. This data partition can be done on packet level or data level. Each mobile host (MHi) will have a data item (diMHi) and some mobile hosts will have a replicated ( i)
i
MH R
d version of this data item.
2.1.2 Mobility model
After deploying the nodes, they can exercise different mobility models. A node’s speed can vary as per its needs from 0 to Vmax where Vmax = maximum velocity of the node set by the service provider. Each node in the network has the capability of releasing SWAs when an event is triggered. These SWAs are responsible for initiating the communication process between a node and cluster head. We assume that an attacker should initiate any of these triggers to clone or compromise a node. We define the triggers that could release a SWA as switched-off, switched-on, transmitting, receiving, and sudden increase in speed because we assume that an attacker will attempt at least one of those operations to clone a device. We denote these triggers as (TRm) where m = login, logout, on, off, tx, rx, and Vmax (here, login and logout are nothing but the triggers set off when a node leaves a cluster to join another and on, off are switched on and off. Recent study (Perrone and Nelson, 2004) discusses these kinds of attacks based on on-off). These triggers would initiate the communication process between the cluster head and a node. We assume that once the adversary compromises a node, he/she will try to capture other nodes and clone them as soon as possible by connecting to other devices to:
1 transfer his malicious code
2 copy vital information from the node to his device. The attacker also has to move fast to get away from the captured location to avoid being detected, which will increase the velocity of the device. So we assume that the attacker must initiate any one of these triggers when the attacker tries to capture or compromise more nodes to clone.
2.2 Security model
Before deployment, node u is pre-assigned with a pair private and public keys (Xing and Cheng, 2010) and a unique id. u is also preloaded with a one-way hash function H and a unique random private seed. u can create a one-way hash set with H and the unique random private seed. This hash set is denoted by hp0, hp1, hp2, …, hpi, hpi+1, hpi+2, where hpi = H(hpi+1) (hp is nothing but a hash pair).We also assume that the node stores a location generation function flc and a time generation function ftime where flc(u, t) computes the location coordinates of the node u given its id and time t. ftime(u, hp, ti) computes time given an id u, a hash pair hp, and the time moment when the communication was initiated. Given the node u the time is calculated by t = ftime(u, hp, ti). Let each node u align with an integer j1, we use hash pair hp as a seed for mapping j1 to another integer j2, we then set t t= ij.
As existing studies suggest, we assume that once a node is compromised or captured, all the information (e.g., codes, keys, ID, etc.) of the node can be extracted from it. An attacker that has captured a node u can deploy clones of u anywhere in the network. So these clones can act as legitimate nodes, participate in the network activity, and launch various internal attacks. For example, they can inject false data and mislead other nodes and base station, which can cause severe traffic and network outage. With this, we also assume the clones can collaborate with other clones deployed by the attacker; they are advanced, efficient, and can attempt to be silent avoid detection. Based on these assumptions, all existing approaches lack in detecting certain types of node replication attacks in MANETs.
3 Combinatorial replication and partitioning protocol
COPR is the combination of two parts: SWAs and Replication using balanced incomplete block design (BIBD).
3.1 Data replication and partition with BIBD
CORP, presented in Mani (2013), is based on the combinatorial property of BIBD: A BIBD design on a set of v elements is a collection of b k-subsets such that each element appears exactly in r subsets and each pair of elements appear exactly in λ subsets. The BIBD is represented by its parameters in standard notation: (b, v, r, k,
λ)-configuration (Mani et al., 2013). For example, consider a small network with seven nodes and a dataset D. The data in the dataset will be partitioned into seven subsets (data items) according to the BIBD. So D = {d1, d2, d3, d4, d5, d6, d7} which constitutes a BIBD partition of (7, 7, 3, 3, 1)-configuration. This data can be split into packet level or data level. In this configuration there are seven data blocks (DB) are available and each with three data items (subsets): DB1 = {d1, d5, d7}, DB2 = {d1, d2, d6}, DB3 = {d2, d3, d7},
DB4 = {d1, d3, d4}, DB5 = {d2, d4, d5}, DB6 = {d3, d5, d6}, DB7 = {d4, d6, d7}.
There are other similar configurations such as (7, 7, 3, 3, 1)-configuration: (12, 9, 4, 3, 1), (13, 13, 4, 4, 1), (21, 21, 5, 5, 1), (26, 13, 6, 3, 1), etc. For any practical use of this design, we do not require a perfectly uniform design of network with BIBD. The deviation from the balance does not affect the functioning of the network. The pairwise balanced property characterises the following combinatorial design: for any pair of data items di and dj, there is a DB DBx, to which both data items belong simultaneously (Mani, 2013). The evaluation of these parameters is given in Section 4.
3.2 BIBD partition of data in MANETs
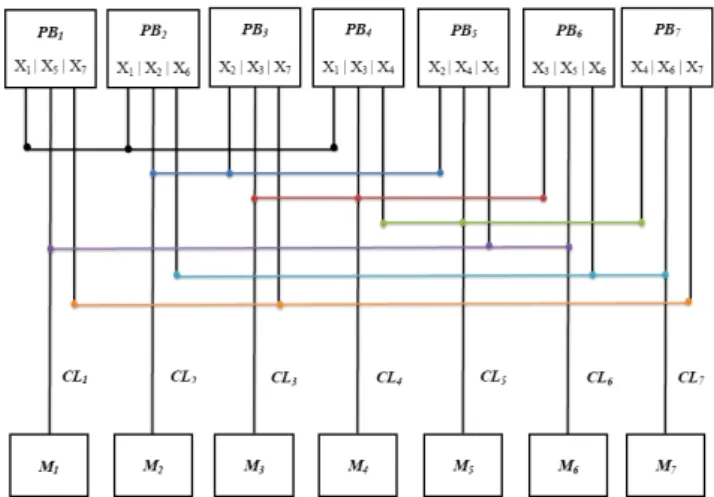
The devices in the network will be partitioned based on BIBD. In this case, each mobile host node will have their own data item with the other two replicated data items available in and acquired from other two host nodes. Figure 1 gives the architecture of the BIBD with (7, 7, 3, 3, 1)-configuration. PB represents the processing block for mobile host, Xi is the data item (d), CL is communication link between the nodes and Mi is the memory of mobile host. This network connection structure allows changes to the data items to be updated simultaneously and independently in all the nodes with their replicated data items through the communication configuration (links). One of the important features of this arrangement is that the data items will not interfere with one another during transmission or reception. This feature creates an efficient distributed structure for the network that supports the object-oriented system design.
As per the definition of the pairwise balanced design (PDB) property, taking any pair of data items from PB, X2 and X4, we can always find a PB with those two data items. X2 and X4 are available in PB5. So if any data item is corrupted in any of the processing host node, its always possible to find the a replacement of the corrupted item. This not only increases the data availability, it also increases the fault-tolerance of the network and thus of the data items. Figure 1 An example architecture of BIBD: (7, 7, 3, 3,
3.3 SWA – CORP
Each device in the MANET communicates with their replica device by the SWA whenever there is an update or a change has been made to the data item. For this CORP-SWA, we consider four update triggers (UT) that will initiate a SWA: 1 node is going out of the communication range (UTRmax) 2 low remaining battery power (UTPmin)
3 an update or q change has occurred for the data item (UTupdate)
4 device switches off (UToff).
The SWA will include the average speed, remaining battery power, and location coordinates of the moving device.
(
)
: || || || i || i || i || i j MH MH MH MH MH i j i i Msg → UT MH MH P V lc tHere, ti is the time when SWA was initiated, V is the velocity of the host node, and P is the power remaining in the host node. i j i MH j i lc lc V t t − = − (2) where j > i and i, j∈Z+.
Through the SWA-CORP each node can calculate its replica nodes’ average velocity, remaining battery power, and the communication range. In case, if any one of these parameters of a node is odd then the replica node will look for another eligible near by node to replicate the data of the bad (compromised) node. This ensures the constant data availability and reduces data loss. The host node maintains a lookup table (tableMHi) to store the logs of changing information about the replica host nodes as well as its replicated data items.
4 Clone attack detection protocols
We overcome the problem of detecting node cloning attacks using two schemes. We will detail our log in log out detection (LLD) scheme and system wide announcement detection (SWAD) schemes. First, we need to introduce our SWA protocol, which is the basis for both LLD and SWAD.
4.1 SWA – clone attacks
When u is leaving its current cluster i id
C and joins a new cluster j
id
C it releases the following messages,
(
)
(
log)
: || || i Cid i i id id u CH u u u u u out C C i Msg TR u CH Sig CH hp Sig t lc P →(
)
(
log 1)
: || || j Cid j i id id u CH u u u u u in C C i Msg TR u CH Sig CH hp Sig t lc P → +where TR is the trigger that initiated the communication, Sigu is the signature of u signed by ( j )
id C u CH with ( j ) id C
u s CH s′ ′ public key for the communication message,
i id
C
CH is the cluster head of the last cluster from which the node is leaving, ( i )
id
C
Sig CH is the last cluster head’s signature, which is the proof that the node u was indeed in the cluster, lc and t represents the location coordinates and time at which the communication was triggered, hpi represents the hash pair whose index is smaller than all the unissued hash pairs. Here, D is the distance between u and
.
j id
C
CH After the communication is finished, u removes the hash pair u.
i
hp So u’s next hash pair will be hpi+1.
Table 2 The table of MHi storing SWA received from a replica
Node ID Details MHj UToff ||MHi||PMHi||VMHi||lciMHi||ti MHk min || || || || || j j j MH MH MH P j j j UT MH P V lc t … …
The cluster head maintains Table 2 (tablecid) for the information it obtains from SWAs from each node. It also maintains a separate table for the information about each node’s distance (D) from j
id
C
CH and speed (Velocity), where
j Cid CH u u D = lc −lc (3) u u j i u u u j i lc lc V t t − = − (4)
The nodes u and v have communicated with the cluster head during the time period δ. The usage of δ will be explained in Section 5. The node u cannot alter or tamper with its hash pairs because the hash pairs and the order of their delivery are closely monitored by the cluster head. So given a node u:
• It cannot issue hash pairs that are duplicated because each hash pair in u’s hash set is unique.
• The new hash pairs must comply with the one-way property, which means they can be used to compute the previous one but not the other way around.
• It cannot skip a hash pair and issue a new hash pair to CH since the cluster head will have updated
information about u’s hash pair and its order.
• It cannot be in two modes (triggers) at a given time. For example, the node u cannot be switched-off and switched-on at the same time. u cannot consecutively send a message to cluster head with switched-on or off. If node u issued a switched-off trigger then the next message should carry switched-on trigger.
5 Underlying rationale of our approach
We derive the following specs from the SWA of CORP. A trigger is set off at the following event and SWA initiation follows:
1 high velocity or going outside of the communication range
2 low remaining battery power.
This SWA is initiated to select a new host for the data item. It also notifies the details about its current situation to the nodes that are requesting its data item along with another close by replica id. In this way, the requesting node can obtain the data item from that eligible device. In order to force the mobile host nodes for the proper process of initiating data transfer, selecting a new mobile host to have the data item replicated, we identify the following rules: 1 When host node receives a request for the data item, it
must posses sufficient energy to do the data transfer. If not, it forwards the request to the closest node with more energy and its replicated data item.
min MHi
P P (5)
2 The host node must be under the maximum velocity limit allowed by the service provider.
max
i
MH
V V (6)
3 The distance between the transmitting node and receiving node must be small
j i
MH MH
j i
L≤ loc −loc (7)
We derive the following specs from the SWA of clone attacks:
1 At any given time, the location coordinates and hash pair of a node in the network must be unique which means a node cannot appear in two clusters or at two locations at the same time.
2 The location coordinates, hash pair of a node must be in consecutive order along the perceived path and time coordinates.
Based on 1, 2 the information of the message must satisfy the following rule. Any violation of these will be interpreted as clone attack on node u.
3 The ordinal order of ui n
hp and uj n
hp in u’s hash pair must be the same as that of ti and tj. In other words,
, iff and if ui uj
i j i j n n
n <n t <t hp ≠hp (8)
Based on the rules and specs specified above, we construct the algorithms for the protocols for data loss prevention and clone attack detection.
CORP Data Transfer Protocol
Input: i, i,
i j i
MH MH
MH MH MH
Msg → V P table
Output: 0=Success, 1=Different node was chosen for transfer
function CORP(VMHi,PMHi)
Request received by Hbi for data block di
if (PminPHbi andVHbi Vmax) then
Begin Transfer
Return 0
else
if (tableMHi ≠0) then
According to Section 5 rules
Identify the suitable replica for transfer Notify about replica node to requesting node Begin Transfer Return 1 else if (MsgMHi→MHjUTi was initiated) then According to Section 5
Select a new host to replicate data item Notify other replica host nodes Return 0
end if end if end if end function
The time complexity of the Algorithm 1 is O(1) when the speed and power are maintained without any distractions. But when a SWA is triggered then the node goes through the replica nodes’ (nodes with the replicated data items) eligibility in tableMHi to either request or notify the regular
nodes as well as the host nodes. The time complexity for this process is O(b), where b is the number of mobile nodes participating in the CORP partition.
5.1 LLD: log in log out detection
In this part, we present our LLD scheme, an authentication and centralised mechanism to detect clone attacks in MANETs. In this procedure, two cluster heads from different clusters participate with a single node.
LLD checking onuat time intervaltn Input: , Cidi, Cidj, , , , i j id id CH CH n n m n C C u hp hp TR t table table
Output: 0=Normal, 1=Clone Detected
function LLD( , , , , i, j) id id
m n C C
u hp TR t table table
if (u is leaving the cluster i id
C at tn) then
u initiates SWA with TRlogoff to i id C
CH
∀u in the cluster, where i, id C u CH≠ u calculates 1 1 ( , CHCidi , ) time n n t← f u hp− t− time t of u.
Location←flc(u, t) location to send Msg
(
|| Cidi)
i Cid
CH
u CH
Location⇐ Msg → Sig Msg sent from u to i id C CH along with i id C CH signature. According to the Section 5 rules if (u’s message is consistent) then
Return 0
CH backups & i id
c
table are updated by i id C CH else Return 1 i id C CH
alerts the cluster about u. end if
end if
if (u is joining the cluster j id
C at tn) then
u initiates SWA with TRlogin to j id
C
CH
Perform steps 3–7 for j id C CH j id C CH forwards u’s Msg to i id C CH to verify if (u’s found in i id c
table without TRlogoff) then Return 1 else Return 0 i id C CH sends Msg(OK) to j id C CH i id C
CH deletes u’s details from i.
id c table j, id c
table CH Backups are updated with u’s info
end if
end if end function
The algorithm’s basic concept is as follows: When the node leaves the cluster and moves to another cluster it generates a SWA with TRlogin and sends the updated announcement with new hash pair to j
id C CH at time tn. j id C CH sends a message to i id C
CH with u’s recently received message and launches a security check. i id C CH checks i id c
table for any other nodes
with the same identity with different TR during the time interval δ. i
id
C
CH will be able to verify u easily, because of the one-way property of the hash pair by using preloaded
0u
hp or any of the previously issued hash pairs. Message from u must have consistent location and hash pair claims according to Section 5. Any violation of the rules in Section 5 would prompt the cluster head to issue an alert to the whole cluster and nearby cluster heads about node u. Then node u will be saved in all nodes in the network as a threat.
After receiving u n
hp the CH calculates the time t using the function ftime. An important point to note here is the computation of the time t and the exchange process is lightly differed to the time tn–1. With this we can clearly see that:
1 After deleting the information about node u, if i id
C CH receives any updated information from a node with u’s id, it is clearly a clone. So u cannot engage in cluster activity without its previous cluster head’s clearance. 2 Since there is a difference in time to calculate t and
report to the j ,
id
C
CH an attacker cannot determine the t without its hash pair. By one-way property of the hash pair, the attacker cannot determine the time t or location to send the message.
Let us consider an example. If u has successfully left the cluster and if i
id
C
CH receives a message from a duplicate of u inside its cluster then it clearly indicates a clone attack in the network. It is not only that the clone node did not go through LLD but the message will not be complying with the rules specified in Section 5.
5.2 SWAD: system wide announcement detection
When an exchange (transfer or receiving) takes place between two devices, a SWA message will be initiated
(
)
(
)
: || || || || || i Cid i i id id u CH u u u u u tx C C i Msg TR u v CH Sig CH hp Sig t lc P →(
)
(
)
: || || || || || i Cid i i id id v CH v v v v v rx C C i Msg TR v u CH Sig CH hp Sig t lc P →where u is the node, which is transferring the data and v is the node that is receiving the data. v will also send the message to the cluster head with the rx tag for the trigger. To make every node follow the exchange process faithfully, we impose the following strategies:
• As soon as the node u is connected with another node v for an exchange process (transmit or receive), u sends an updated information with the trigger.
• v will also follow the same procedure and updates the information by sending its current exchange process
with the trigger. For example, if u is transmitting and updates cluster head with tx trigger then v must update the information with rx trigger.
• If a node is going to be switched off by the user, it should update its information with an off trigger. And it should follow the order of this process. For example, if node u updates its information with an off trigger, the next time it should update its Msg with an on trigger. Based on our strategies, we derive the following rules: Rule 1 For a node u in the network, it should not travel
faster than Vmax and it will not be able to perform exchange processes with more than a few devices. Rule 2 Some triggers follow an order thus cannot be in the
same trigger at the same time. For example, TRoff must be followed by TRon and vise-versa. Also, u cannot be in two different triggers at the same time. SWAD Check on uandv
Input: , ,u v tableCid,Msgu→CHCidi,Msgv→CHCidi
Output: 0=Normal, 1=Clone Detected, 2=CH absent 3=N/A 1: function SWAD( , , id, , )
u v
C
u v table Msg Msg
2: u, v initiates SWA with TRrx and TRtx to i id C
CH
3: if (tableCid ≠0) then
4: According to rules in Section 5 5: if (Msgu, Msgv are consistent) then
6: Return 0
7: Send acknowledgement to node u and v
8: if (Acknowledgment was not received) then
9: Return 2
10: u and v report with Error 2.
11: Backup CH takes over responsibilities
12: end if
13: else
14: Return 1 Clone attack on u and v
15: i
id C
CH alerts the cluster about u and/or v
16: end if
17: else
18: Return N/A No Action
19: end if
20: end function
u and v can be checked with their message by their CH and it can determine which one is making false claims about its location and hash pair. SWAD check applies to the trigger off and on and goes through the same process of detection. Unlike TDD (Xing and Cheng, 2010), SWAD does not consider a switched off node to be a clone. Another important factor is that these triggers can be extended as per the network providers security need. For example, they can add going into a low signal zone or going into sleep or awake as triggers, so that each node will go through SWAD.
5.3 Cluster dynamics
5.3.1 LED cluster formation
In our detection scheme, cluster heads play an important role in monitoring the devices in the system. Figure 2 shows the clusters in a network. A cluster head compromise would be catastrophic to the network and we take some measures to avoid it. In order to manage the tasks, we apply the following strategies:
1 The power (battery) remaining must be greater than all the other nodes in cluster.
2 If the cluster head is going through an exchange process (transferring or receiving) for their important security, system-configuration, and operating system files then the cluster head notifies the backup clusters.
3 If node u wants to become a cluster head, its velocity should be less than all other nodes in the cluster. Note: We consider these kinds of exchange processes as a threat.
Remarks: After a certain system-configured low power level, the CH looses its credentials and the near by backup node takes over.
Figure 2 Random six-clusters NCG with LED clustering (see online version for colours)
Note: Red nodes represent cluster heads, green nodes represent long distance cluster head backups, and blue nodes represent short distance cluster head backups.
5.3.2 Cluster head change and selection
When each node engages into a cluster, the cluster head calculates their velocity, distance and saves both values in a table (tablech) with the current power level it received from the node. These nodes will be sorted based on the power remaining in each node. The first two devices would be the next contenders for the cluster heads. Both of the cluster head backups will be aware of their responsibility and notify the current cluster head when their energy is reduced below threshold or Velocitymax has been reached. We denote the
near by cluster head backup as cid C
CH and longer distance cluster head backup lid.
C
CH In some of the attacks, attackers tend to cooperate and capture many close by devices. Our proposed cluster head arrangement will prevent these kinds of coordinated attacks since the new cluster head would be very far away from the current one. The cluster head selection algorithm explains in which scenario the long distance cluster head back up would be considered.
Cluster Head Selection Input:tablech
Output: 0=Success, 1=No Action 1: function CHS(tablech)
2: if (tablech≠ 0) then
3: Sort tablech by Power and Velocity
4: According to the rules in Section 5 5: if (PCHCidi is low or id i C CH is leaving i) id C then 6: Notify id c C CH 7: id i C CH deletes tableCid 8: Return 0 9: end if 10: if (u, v report Error 2 or iid C CH is in TRoff) then 11: id l C
CH takes over as cluster head
12: end if
13: According to the rules in Section 5
14: if ( max)
i Cid CH
Velocity Velocity then
15: Notify id l C CH to take over. 16: end if 17: else 18: Return 1 19: end if 20: end function
If the trigger represents a threat, we select a CH backup from long distance. To be safe, we assume switching o and removing battery, which causes sudden absent of cluster head, are security threats. The CH selection process makes sure that the cluster head will not be compromised easily. Each cluster head in the cluster will also go through the same detection protocols as they engage in the exchange processes. We consider transmitting or receiving important system configurations or operating system files to be a credible threat for compromising nodes. So when these kinds of exchanges happen, the cluster head will notify the backup cluster head to take over and the new cluster head will determine the new backup cluster heads, and the
id
C
table will be updated (sent) to them.
6 Efficiency analysis
6.1 Evaluation of parameters for CORP
In the notation (b, v, r, k, λ), b is the number of devices in the networks participating in CORP, v is the number of communication or network links among the participating devices, r-number of devices connected by the communication link to transmit or receive the data, k is the number of replicated data items (d) in the device, and λ is the number of times a pair of data items appear together in a host node. The detailed performance analysis has been provided in our previous work (Mani, 2013). Since,
b k v r∗ = ∗ (9)
(k− ∗ = ∗ −1) r λ (v 1) (10)
v b≤ (11)
the actual implementation of the PBD property does not require a perfectly uniform BIBD. The parameter λ
determines the network’s fault-tolerance capability. Let us consider a small system, for example, λ = 1 and k = 3. To build a system with PBD property,
6 v r≈ (12) 2 6 v b≈ (13)
So a system of 20 data items would require more than 60 mobile host nodes as well as ten communication links.
6.2 Security analysis of clone detection
Our schemes are based on detecting the contradictory information of a node u and its clone uc generate in the cluster. We analyse three different scenarios of detection and show that node u and uc always generate hash pair contradiction in the cluster.
6.2.1 Hash pair contradiction
Following the precedence set by Xing and Cheng (2010), we analyse three different possibilities of hash pair contradiction and derive the probability of detection accuracy.
Consider u issues the hash pair u1 n
hp at ti and its clone uc generates hpun2 at tj, where tj > ti and lets assume δ≥ |tj – ti| where δ is a random time moment. Let Shp be the set of hash pairs generated by nodes u and uc within [ti, ti + δ] and [tj – δ, tj]. Shpu ={hpun1,hpnu1+1, ...,hpn xu1+ } and 2 2 1 2 { c , ..., c , c}. uc u u u hp n y n n S = hp − hp + hp
Given the node u and uc and the hash pair sets they have issued to the cluster head at [ti, ti + δ], there are three different scenarios where uc will generate a hash pair contradiction [Note: The following cases actually match with protocols proposed in Xing and Cheng (2010), but
these scenarios are accompanied by the status of LED clustering].
1 n2 < n1: The index of the hash pair 2
c u n hp is smaller than 1, u n
hp which shows n2 must have been issued earlier than n1 and hpun2c is an expired hash pair. This clearly indicates that there is a hash pair contradiction and the cluster head would be able to take immediate action. 2 n1≤n2≤n1 + x: Here, the hash pairs are generated
within the time δ, which means that they generate a contradictory hash pair that violates rules specified in Section 5 and uniqueness of each hash pair. In another words, the hash pairs issued by uc and u cannot be the same within the time duration δ.
3 n2 > n1 + x: 3 node u cannot have made this many exchanges or log in and out of so many clusters. So u cannot issue x + 1 hash pairs within δ. Thus, ( u)
hp S hp issued by u should be in consecutive order in u’s hash pair. So the maximum hash pair index that u can issue at δ is hpun1+x. So the cluster head issues a warning to all the nodes in the cluster and nearby cluster heads.
6.2.2 Number of cloned nodes based detection accuracy
The probability of a trigger, sending a message to the cluster head, is higher due to the extensive trigger mechanisms for implying a possible attack. So given the number of clones available in the network, our SWAD’s detection accuracy Prob(SWAD) approaches a 100%.
6.3 Storage, communication, computation analysis
In this section, we first compare the performance of the detection schemes in Table 3 with the recent related studies in terms of a node’s storage, communication and computation costs.
Table 3 The table of i id C
CH which stores the information that it has received from u at the time interval δ
Node ID Details u ,
(
idi)
, 1, 1, ,1 1, 1 u u u u u m C i i i i i TR Sig CH hp Sig t lc P v ,(
idi)
, 1, 1, ,1 1, 1 u u u u u m C j j j j j TR Sig CH hp Sig t lc P … …When verifying the legitimacy of u, LLD and SWAD request u to send f CHlc( Cid, ).t So the computation overhead for both schemes to be launched on any node is O(1). Since f CHlc( Cid, ).t is a random location coordinate in the cluster, the communication cost of both the schemes is O(1). Since both of our schemes are localised procedures, the communication and computation cost would be O(1). An individual node does not have to keep the record of any
exchanges and each node does not store anything except the previously issued hash pair, and thus the storage overhead would be O(1). But for the CH and backups, they have to save and update the transactions from the cluster nodes. So the storage overhead would be O(ct) and the CH selection process would take O(ct). Since our scheme is localised through clusters, CH would not have to deal with large number of nodes. Compared to other existing schemes, in LLD and SWAD, nodes maintain constant communication, computation, and storage costs. Also, these schemes are highly fault-tolerant since they have two backup cluster heads.
6.4 Performance metrics
CORP addresses the following issues:
1 Replication cost: Number of replicated nodes that are deployed in the network. To increase the data availability, the nodes have to have the same replicated data item. This may increase the replication cost as well as the storage cost of the entire network.
2 Live mobile nodes: Number of mobile nodes with enough battery power to stay alive. The nodes can drain their batteries by communicating frequently and unnecessarily.
3 Data availability: The probability to access the data item when that particular data item was requested. Whenever the data item is requested by a node, it is important for the data item to be available immediately. Otherwise the movement of the MANET node can disrupt the communication and may lead to data loss. 4 Maintenance cost: The communication as well as the
computation cost of maintaining cluster-based network.
6.4.1 Simulation results for CORP
Using NS2, we implemented a simulation of CORP built 1,000 × 1,000 network with 65 mobile hosts. The communication range was set to 70 metres (taking Bluetooth devices into account) and random walk model was employed since the model emulates the unpredictable movements of the MANET devices. We set the size of each data item to be 1 MB. All of the mobile nodes will have the same characteristics as well as access frequencies (number of times a data item is accessed). We employed the energy model proposed in Feeney and Nilsson (2001), and Yi et al. (2007a), and started the system with 60,000 Joules for each mobile.
For Table 5, we use Derhab and Badache’s (2009) metrics methods. Energy-aware and partition-aware protocols with server’s demise prediction have high data availability. But the networks without the capability of predicting the server’s demise will have medium data availability. CORP is designed to be aware of energy, speed, partition, and the demise of the host node. Equipped with these attributes, CORP significantly controls the data loss.
Figure 3 Comparison of data availability (see online version for colours)
Figure 4 Comparison of number of mobile hosts alive (see online version for colours)
Figure 3 and Figure 4 show the comparison between CORP as well as weighted easy access-battery (WEA-B) method, expected access (EA) method, weighted easy access (WEA) method, and weighted easy access-hop (WEA-H) method that are developed in Yi et al. (2007a). EA method replicates the data item that is frequently accessed. WEA increases the weighted access – a multiplication of data items accessed in neighbouring nodes as well as its own – of the data items thus making the data availability to be higher. WEA-battery is nothing but a method where each mobile host will dynamically change the weight of the data item based on its remaining battery power. In WEA-H method, the mobile host nodes will consider the length of the path in which the data will be routed to the requester node.
Table 4 Storage, communication, and computation cost of detecting clones
Schemes Storage Communication Computation
XED (Yu et al., 2008) O(1) O(N) O(1) SPRT (Ho et al., 2009) O N( ) O(1) O(1) TDD (Xing and Cheng, 2010) O N( ) O(N) O(θ(t)) SDD (Xing and Cheng, 2010) O(d) O(N) O(d) LLD, SWAD O(1) O(1) O(1) LLD, SWAD (for CH) O(ct) O(1) O(1)
Note: In TDD θ(t) is the number of meetings node u
makes with other nodes, in SDD (LC, LWC) d is the number of randomly selected nodes for comparison.
Table 5 Performance comparison of existing schemes with CORP using performance metric model
Scheme Data availability Replication cost
DPA (Chen et al.,
2002) High O(n)
CPA DAG-based (Derhab and Badache, 2006)
Medium high l/stable subgraph
WEAB (Yi et al., 2007a)
Medium high O(n)
KCRP (Zheng et al., 2005)
Medium high O(n)
CORP Very high O(k)
Source: Derhab and Badache (2009)
We ran 15 simulations each for the duration of 10,000 seconds. We randomly silence the nodes to see the effects of CORP. CORP managed to maintain a steady data availability from 80% to 90%, which is 20% to 50% higher than the schemes suggested in Yi et al. (2007a). Since CORP is an energy-aware protocol, the mobile hosts rarely exhaust their batteries. As a result, the nodes in the network partition will be alive for a long time.
6.4.2 Clustering
Our clustering arrangement requires that the nodes only have to communicate with cluster head. So it reduces energy drainage from MANET nodes. We investigated our schemes’ performance in NS2 with random waypoint model (Santi, 2012) with Yi et al.’s (2007a) energy settings. We used 1,000 × 1,000 m network with CRmax = 200 m and 100 nodes. Exchange processes in both schemes were set to random.
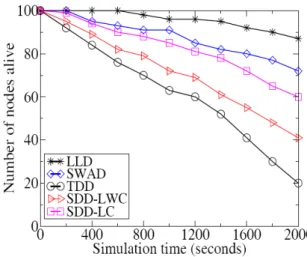
In Figure 5, we compare the energy consumption of LLD and SWAD with the current best solution for detecting clone attacks in the network (Xing and Cheng, 2010). Our simulations show that TDD and SDD take more energy
from MANET devices due to the requirement to constantly communicate with their two-hop neighbours and update their status. So they die early because of communication and storage overhead. On the contrary, LLD and SWAD initiate the communication process between a node and a cluster head only when there is a necessity. Hence, the energy consumption for these algorithms is much less compared to others.
Figure 5 Number of nodes alive in the network with LLD and SWAD (see online version for colours)
6.4.3 Overhead analysis
Table 4 shows the overhead of individual algorithms from different schemes. When the area of a cluster ( 2)
R
C is very small and the node mobility inside the cluster is high, the communication overhead may increase, but the storage and computation cost stay the same. To solve this issue, our scheme gives the freedom of setting the size (area) of the cluster to the service provider, so that they can adjust the area based on their own requirements and reduce the communication overhead. For example, if the service provider has a highly mobile network, then increasing the size of the cluster would reduce the number of executions of the LLD and cluster head selection algorithms, which would result in low communication overhead.
7 Conclusions
In this paper, we presented the techniques for preventing data loss and detecting clone attacks in MANETs. Many existing approaches for clone attack detection depend on a static network models or localised schemes without a global view of the network and number of clones in the network. Few other methods provide solutions to these problems but with high storage or communication or computation cost. Our LLD and SWAD methods with LED clustering address these fundamental dependencies and limitations with low overhead. Since we are using a one-way hash function, the computation cost is much less compared to other schemes and our scheme can be applied to any mobility model. Our methods do not depend on distribution or number of clones
in the network. Our analysis indicates that these schemes can tackle node collusions and detect clones with high accuracy. We also proposed CORP – a combinatorial distributed network design to improve data availability and prevent data loss while reducing the energy consumption of the mobile devices. The security and data loss prevention protocols are incorporated into a simple yet efficient local-exchange protocols. This research offers several new directions for routing, network formation, and mobile communication strategies. In the future, we intend to investigate the cluster management cost and energy efficient hardware designs for MANETs in the framework of internet of things (Bari et al., 2013).
Acknowledgements
We would like to thank Prof. Simon Berkovich for his suggestions and comments on combinatorial balanced block designs. We also would like to thank Prof. Xiuzhen Cheng for her advise and comments on clone attack detection protocols. Finally, we would like to thank Prof. Abdou Youssef, chairman of the Computer Science Department at George Washington University, for generously allocating an office space and equipment to conduct this research.
References
Atassi, A., Sayegh, N., Elhajj, I., Chehab, A. and Kayssi, A. (2014) ‘Decentralised malicious node detention in WSN’,
International Journal of Space-Based and Situated Computing, Vol. 4, No. 1, pp.15–25.
Bari, N., Mani, G. and Berkovich, S. (2013) ‘Internet of things as methodological concept’, 2013 Fourth International Conference on Computing for Geospatial Research and Application (COM.Geo), IEEE, pp.48–55.
Brooks, R., Govindaraju, P.Y., Pirretti, M., Vijaykrishnan, N. and Kandemir, M.T. (2007) ‘On the detection of clones in sensor networks using random key predistribution’, IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, Vol. 37, No. 6, pp.1246–1258. Capkun, S. and Hubaux, J.P. (2005) ‘Secure positioning of
wireless devices with application to sensor networks’,
Proceedings of IEEE Computer and Communications Societies, March, Vol. 3, pp.1917–1928.
Chen, K., Shah, S.H. and Nahrstedt, K. (2002) ‘Cross-layer design for data accessibility in mobile ad hoc networks’, Wireless Personal Communications, Vol. 21, No. 1, pp.49–76.
Choi, H., Zhu, S. and La Porta, T.F. (2007) ‘SET: Detecting node clones in sensor networks’, Third International Conference on Security and Privacy in Communications Networks and the Workshops, SecureComm 2007, September, pp.341–350. Derhab, A. and Badache, N. (2006) ‘Localized hybrid data
delivery scheme using k-hop clustering algorithm in ad hoc networks’, IEEE International Conference on Mobile Adhoc and Sensor Systems (MASS), October, pp.668–673.
Derhab, A. and Badache, N. (2009) ‘Data replication protocols for mobile ad-hoc networks: a survey and taxonomy’,
Communications Surveys & Tutorials, Vol. 11, No. 2, pp.33–51, IEEE.