G. Nimako, E.J Otoo and Michael Sears
School of Computer Science The University of the Witwatersrand
Johannesburg, South Africa
Introduction
The conceptual model of a dataset as amultidimensional array
has been around since the early days ofrelational database model.
Records of multi-attribute files, perceived as points in
multi-dimensional space, form the bases of many of the efficient data structures and algorithms.
Examples: KD-Tree, Quad-Tree, Grid-File, multi-dimensional OLAP and data warehousing.
Scientific data-sets are maintained predominantly as multi-dimensional arrays - HDF5, NetCDF, New SciDB, etc.
The conceptual model of a dataset as amultidimensional array
has been around since the early days ofrelational database model.
Records of multi-attribute files, perceived as points in
multi-dimensional space, form the bases of many of the efficient data structures and algorithms.
Examples: KD-Tree, Quad-Tree, Grid-File, multi-dimensional OLAP and data warehousing.
Scientific data-sets are maintained predominantly as multi-dimensional arrays - HDF5, NetCDF, New SciDB, etc.
Motivation
Processing massively large scientific data(Big Data), in the realm of Peta-scale and Exa-scale computing usingPartitioned Global Address Space (PGAS)computational model. This also
subsumes thehadoop-likecomputing model. The PGAS computational model are exemplified by:
Global Array Toolkit, Unified Parallel C (UPC), OpenShmem Application to hyper-spectral image data storage and analysis The database consistent with this model of computation isSciDB
It is anArray Data Modelon shared parallel architectures with unbounded non-uniform dimensions with holes, arbitrary nesting, sophisticated storage representations, including overlapping chunks, etc.
Distributed dense arrays that can be accessed through a shared memory-like style
Motivation: The Global Array Toolkit
Distributed dense arrays that can be accessed through a shared memory-like style
Multidimensional Array Files
Mapping ofconventional array elements onto linear storage, using row-major orcolumn-major order allows for extendability of the array in only one dimension.
The problem has been addressed in some earlier papers. Notably by :
G. Nimako, E. Otoo and D. Kwofie, PARCO Journal [2013] G. Nimako, E. Otoo and D. Kwofie, IASDS of IEEE Cluster [2013] G. Nimako, E. Otoo and D. Kwofie, P2S2 [2012]
Tsuji, M. Kuroda and K. Higuchi [2008] A. Rosenberg and L. Stockmeyer [1977]
Multidimensional Array Files
Mapping ofconventional array elements onto linear storage, using row-major orcolumn-major order allows for extendability of the array in only one dimension.
The question then arises: ”How can we store arrays elements so that the index range of any dimension can be extended?”
The problem has been addressed in some earlier papers. Notably by :
G. Nimako, E. Otoo and D. Kwofie, PARCO Journal [2013] G. Nimako, E. Otoo and D. Kwofie, IASDS of IEEE Cluster [2013] G. Nimako, E. Otoo and D. Kwofie, P2S2 [2012]
Tsuji, M. Kuroda and K. Higuchi [2008] A. Rosenberg and L. Stockmeyer [1977]
Mapping ofconventional array elements onto linear storage, using row-major orcolumn-major order allows for extendability of the array in only one dimension.
The question then arises: ”How can we store arrays elements so that the index range of any dimension can be extended?”
The problem has been addressed in some earlier papers. Notably by :
G. Nimako, E. Otoo and D. Kwofie, PARCO Journal [2013] G. Nimako, E. Otoo and D. Kwofie, IASDS of IEEE Cluster [2013] G. Nimako, E. Otoo and D. Kwofie, P2S2 [2012]
Tsuji, M. Kuroda and K. Higuchi [2008] A. Rosenberg and L. Stockmeyer [1977]
Main Contributions
We present a computable access functionF∗(hi
0, i1, . . . , ik−1i)
that maps the k-dimensional indexhi0, i1, . . . , ik−1ito a value that
gives the linear address location`j in timeO(k+ logN)using
O(k2N1/k)addition space. This allows us to store elements of extendible array directly as array-files.
We introduce Parallel Chunked Extendible Dense Array I/O (PEXTA) for the GA
PEXTA can be used as a drop-in replacement for the Disk Resident Array of the GA-Toolkit
PEXTA provides an efficient I/O for Parallel Implementation of Endmember Extraction Algorithms From Hyperspectral Data.
Main Contributions
We present a computable access functionF∗(hi
0, i1, . . . , ik−1i)
that maps the k-dimensional indexhi0, i1, . . . , ik−1ito a value that
gives the linear address location`j in timeO(k+ logN)using
O(k2N1/k)addition space. This allows us to store elements of extendible array directly as array-files.
We introduce Parallel Chunked Extendible Dense Array I/O (PEXTA) for the GA
PEXTA provides an efficient I/O for Parallel Implementation of Endmember Extraction Algorithms From Hyperspectral Data.
Main Contributions
We present a computable access functionF∗(hi
0, i1, . . . , ik−1i)
that maps the k-dimensional indexhi0, i1, . . . , ik−1ito a value that
gives the linear address location`j in timeO(k+ logN)using
O(k2N1/k)addition space. This allows us to store elements of extendible array directly as array-files.
We introduce Parallel Chunked Extendible Dense Array I/O (PEXTA) for the GA
PEXTA can be used as a drop-in replacement for the Disk Resident Array of the GA-Toolkit
PEXTA provides an efficient I/O for Parallel Implementation of Endmember Extraction Algorithms From Hyperspectral Data.
We present a computable access functionF∗(hi
0, i1, . . . , ik−1i)
that maps the k-dimensional indexhi0, i1, . . . , ik−1ito a value that
gives the linear address location`j in timeO(k+ logN)using
O(k2N1/k)addition space. This allows us to store elements of extendible array directly as array-files.
We introduce Parallel Chunked Extendible Dense Array I/O (PEXTA) for the GA
PEXTA can be used as a drop-in replacement for the Disk Resident Array of the GA-Toolkit
PEXTA provides an efficient I/O for Parallel Implementation of Endmember Extraction Algorithms From Hyperspectral Data.
Rest of the Talk
Extendible Arrays of Data Chunked Extendible Arrays PEXTA I/O Model
PEXTA Implementation for GA
Using PEXTA for Parallel Implementation of Endmember Extraction Algorithms From Hyperspectral Data
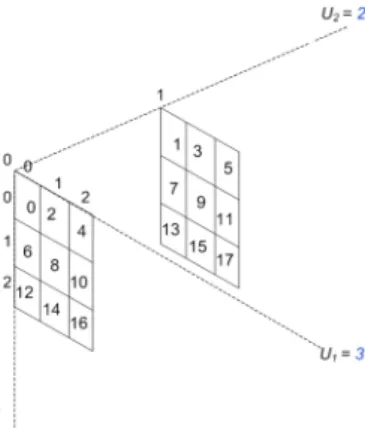
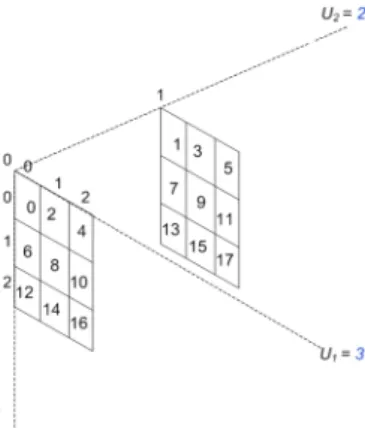
Consider an 3-D arrayA[U0][U1][U2]whose elements are
allocated in row-major order.
The location of an elementAhi0, i1, i2i, is given by
loc(Ah0,0,0i+qwhereq is computed as: q =i0∗C0+i1∗C1+i2∗C2
and
C0=U1∗U2
C1=U2
C2= 1
The valuesC0, C1, C2 are held in thedope-vector.
Conventional Array Using Row-Major Ordering
Consider an 3-D arrayA[3][3][2]whose elements are allocated in row-major order as below
Consider an 3-D arrayA[3][3][2]whose elements are allocated in row-major order as below
Conventional Array Using Row-Major Ordering
Consider an 3-D arrayA[3][3][2]whose elements are allocated in row-major order as below
Consider an 3-D arrayA[3][3][2]whose elements are allocated in row-major order as below
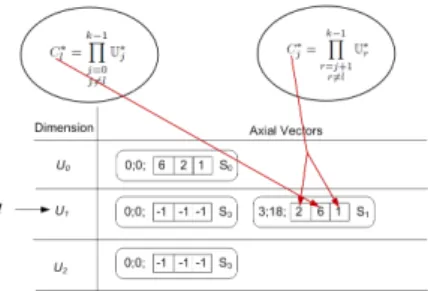
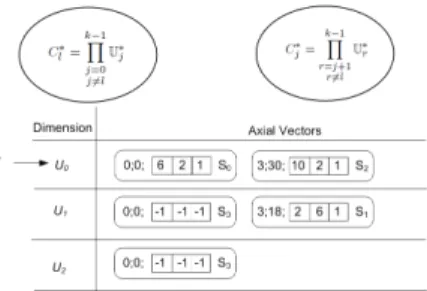
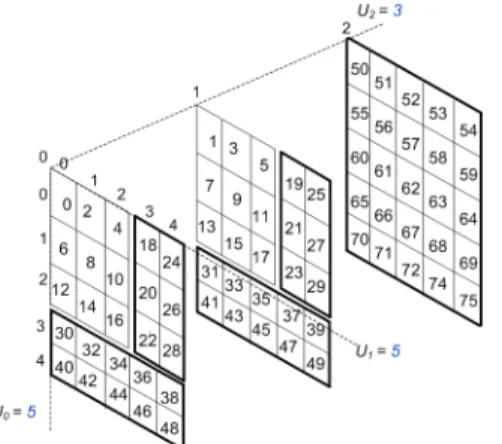
Linear Mapping for a Dense Extendible Array
The mapping function for extendible array uses axial-vectors to store information that includes thedope-vector at the time of extending the dimension
A list of axial-vectors is maintained for each dimension.
LetA[U∗0][U∗1][U∗2]be an arbitrary3-dimensional array, whereU∗j implies that the bound can be extended.
Similarly we employ the notation:
F()when referring to conventional array mapping function.
The mapping function for extendible array uses axial-vectors to store information that includes thedope-vector at the time of extending the dimension
A list of axial-vectors is maintained for each dimension.
LetA[U∗0][U∗1][U∗2]be an arbitrary3-dimensional array, whereU∗j implies that the bound can be extended.
Similarly we employ the notation:
F()when referring to conventional array mapping function.
Linear Mapping for a Dense Extendible Array
The mapping function for extendible array uses axial-vectors to store information that includes thedope-vector at the time of extending the dimension
A list of axial-vectors is maintained for each dimension.
LetA[U∗0][U∗1][U∗2]be an arbitrary3-dimensional array, whereU∗j
implies that the bound can be extended. Similarly we employ the notation:
F()when referring to conventional array mapping function.
Illustration of the Linear Mapping for a Dense Extendible
Array
Illustration of the Linear Mapping for a Dense Extendible
Array
Illustration of the Linear Mapping for a Dense Extendible
Array
Illustration of the Linear Mapping for a Dense Extendible
Array
Illustration of the Linear Mapping for a Dense Extendible
Array
Illustration of the Linear Mapping for a Dense Extendible
Array
Linear Mapping for a Dense Extendible Array
Suppose that in ak-dimensional extendible arrayA[U∗0][U∗1][U∗2]...[U∗k−1],
dimensionlis extended byλl, then the index range increases fromU∗l to U∗l +λl.
Let the locationAh0,0, ...,U∗l, ...,0i(i.e. the starting location of an
allocatedhyperslab) be denoted as`Z0
U∗l whereZ0U∗ l = Qk−1 r=0U ∗ r.
The Mapping Function
q∗=F∗(hi0, i1, i2, ..., ik−1i)) =Z0U∗ l + (il−U ∗ l)C ∗ l + k−1 X j=0 j6=l ijCj∗ Cl∗= k−1 Y j=0 j6=l U∗j Cj∗= k−1 Y r=j+1 r6=l U∗r
The limitation imposed byF()is that extensions of the array can only be done on one dimension (i.e. that is dimensionU0since it was not used in the evaluation ofF().
Suppose that in ak-dimensional extendible arrayA[U∗0][U∗1][U∗2]...[U∗k−1],
dimensionlis extended byλl, then the index range increases fromU∗l to U∗l +λl.
Let the locationAh0,0, ...,U∗l, ...,0i(i.e. the starting location of an
allocatedhyperslab) be denoted as`Z0
U∗l whereZ0U∗ l = Qk−1 r=0U ∗ r.
The Mapping Function
q∗=F∗(hi0, i1, i2, ..., ik−1i)) =Z0U∗ l + (il−U ∗ l)C ∗ l + k−1 X j=0 j6=l ijCj∗ Cl∗= k−1 Y j=0 j6=l U∗j Cj∗= k−1 Y r=j+1 r6=l U∗r
The limitation imposed byF()is that extensions of the array can only be done on one dimension (i.e. that is dimensionU0since it was not used
in the evaluation ofF().
Chunking Extendible Dense Arrays
The use of the list for axial-vectors can be expensive and depends in particular on the interruptible expansions. (worst case is when we have cubical extensions).
Such interruptible expansions cause the addition of a new entry in the list of axial vectors.
Chunking the array gives some additional advantages:
It gives contiguous storage allocations for the elements of the chunks.
When arrays are allocated onto secondary storage, I/O can be made in multiples of the chunk size.
The allocation is done inchunksas opposed to the single
The use of the list for axial-vectors can be expensive and depends in particular on the interruptible expansions. (worst case is when we have cubical extensions).
Such interruptible expansions cause the addition of a new entry in the list of axial vectors.
Chunking the array gives some additional advantages: It gives contiguous storage allocations for the elements of the chunks.
When arrays are allocated onto secondary storage, I/O can be made in multiples of the chunk size.
The allocation is done inchunksas opposed to the single elements.
We model the PEXTA after MPI-I/O Definitions
Thefiletypedescribes the data layout in file
Thebuftypedescribes how data is laid out in a process’s buffer The elementary datatype,etype, ensures consistency between the type signature of both filetype and buftype.
The principal-array data and the axial-vectors, that correspond to
the leaf-nodes of theO2-Tree, are stored on disk as the
principal-array file,Fp and metadata file,Fm, respectively.
AlthoughFpwill be stored on disk, it is accessed through the
PEXTA Overview and Implementation
We model the PEXTA after MPI-I/O Definitions
Thefiletypedescribes the data layout in file
Thebuftypedescribes how data is laid out in a process’s buffer The elementary datatype,etype, ensures consistency between the type signature of both filetype and buftype.
The principal-array data and the axial-vectors, that correspond to the leaf-nodes of theO2-Tree, are stored on disk as the
principal-array file,Fp and metadata file,Fm, respectively.
AlthoughFpwill be stored on disk, it is accessed through the
PEXTA Model supports both regular and irregular distributions of global array of the GA-Toolkit. We have completed implementation for regular distribution.
Processes can perform independent or collective reads and writes of their respective sub-arrays.
An external/independent process can request for an exclusive
write lock token on the metadata file,Fm and append chunks of
PEXTA Overview and Implementation
PEXTA Model supports both regular and irregular distributions of global array of the GA-Toolkit. We have completed implementation for regular distribution.
Processes can perform independent or collective reads and writes of their respective sub-arrays.
An external/independent process can request for an exclusive write lock token on the metadata file,Fm and append chunks of
When a new session starts, the processes within a communicator group reads the newly updated metadata file into their individual
O2-Trees.
PEXTA Overview and Implementation
When a new session starts, the processes within a communicator group reads the newly updated metadata file into their individual O2-Trees.
The PEXTA API provides routines quite similar to DRA for creating disk resident array
We however provide additional functions for extendibility. Functions
int PEXTA Init(int maxArrays, double maxArraySize, double totalDiskSpace, double maxMemory);
int PEXTA Create(int type, int ndim, size t
dims[],char *name, char* filename, int mode, int mode, size t reqdims[], int g a, int *p a);
int PEXTA IRead(int g a, int p a, int *request); int PEXTA Extend(int p a, size t edims[],size t odims[], int *request);
Recently, high-performance computing systems have become more widespread in remote sensing applications.
Parallel techniques for endmember extraction may allow rapid inspection of massive data archives
It will also enable generation of comprehensive spectral libraries and other useful information
An opportunity to explore methodologies in areas such as
multisource data registration and mining that previously looked too computationally intensive for practical applications due to the immense files involved
Hyperspectral Data Analysis
Mixed pixels (due to insufficient spatial resolution and mixing effects in surfaces)
Sub-pixel targets (very important and crucial in many hyperspectral applications)
The goal is to find extreme pixel vectors (endmembers) that can be used to unmix other mixed pixels in the data using a linear mixture model.
Each mixed pixel can be obtained as a combination of
endmember fractional abundances. A crucial issue is how to find spectral endmembers.
Endmember Extraction Algorithms:
Boardman’s Pixel Purity Index (PPI) Algorithm
Harsanyi and Chang’s Orthogonal Subspace Projection (OSP) Winter’s N-FINDR Algorithm
Parallel Endmember Extraction Using PEXTA and GA
The master processor scatters the data among the distributed workers
We provide collective operations in PEXTA for data partitioning. Alternatively, the GA collective operation for data partitioning can be used.
Spectral-Domain Partitioning
A single pixel vector (spectral signature) may be stored in different processing units
It requires communications for individual pixel-based calculations such as spectral angle computations.
Parallel Endmember Extraction Using PEXTA and GA
Spatial-Domain Partitioning
Every pixel vector (spectral signature) is stored in the same processing unit.
This is beneficial for a proposed sliding-window algorithm in terms of low-level image processing computations.
Poor parallel I/O performance has been a bottleneck in many data-intensive applications
The organisation of extendible arrays using a mapping function is highly appropriate for most scientific datasets where the model of the data is perceived as a large multi-dimensional array.
Main application areas is for hyper-spectral image processing and a host other scientific applications that are based on multidimensional data models.
Remote sensing missions require efficient I/O able to cope with the extremely high dimensionality of the collected data without
compromising mission payload.
Future work on the use of in memory resident caches of both the chunks and the array are anticipated.