H
igh
P
erformance
C
ontent
C
entric
N
etworking on
V
irtual
I
nfrastructure
by
Tang Tang
A thesis submitted in conformity with the requirements
for the degree of Master of Applied Science
Graduate Department of Electrical and Computer Engineering
University of Toronto
Abstract
High Performance Content Centric Networking on Virtual Infrastructure Tang Tang
Master of Applied Science
Graduate Department of Electrical and Computer Engineering University of Toronto
2013
Content Centric Networking (CCN) is a novel networking architecture in which communication is resolved based on names, or descriptions of the data transferred instead of addresses of the end-hosts. While CCN demonstrates many promising potentials, its current implementation suffers from severe performance limitations. In this thesis we study the performance and analyze the bottleneck of the existing CCN prototype. Based on the analysis, a variety of design alternatives are proposed for realizing high performance content centric networking over virtual infrastructure. Preliminary implementations for two of the approaches are developed and evaluated on Smart Applications on Virtual Infrastructure (SAVI) testbed. The evaluation results demonstrate that our design is capable of providing scalable content centric routing solution beyond 1Gbps throughput under realistic traffic load.
Contents
1 Introduction 1 1.1 Motivation . . . 2 1.2 Problem Statement . . . 3 1.3 Contributions . . . 3 1.4 Organisation . . . 4 2 Background 5 2.1 Information Centric Networking . . . 52.1.1 Advantages of ICN . . . 5
2.1.2 Open Issues and Challenges in ICN . . . 6
2.1.3 Major ICN Projects . . . 7
2.1.4 Main Components of an ICN . . . 8
2.2 Content Centric Networking . . . 9
2.2.1 Advantages of the CCN Approach . . . 9
2.2.2 CCN Architecture Overview . . . 10
2.3 Smart Application on Virtual Infrastructure . . . 17
3 Related Work 19 3.1 ICN Testbeds . . . 19
3.2 Performance of CCN . . . 21
3.3 CCN Router Designs . . . 22
4 Bottleneck Analysis and Service Decomposition of CCN 23 4.1 Motivation . . . 23
4.2 CCNx Performance Benchmark and Bottleneck Analysis . . . 24
4.2.1 Experiment Setup . . . 24
4.2.2 Performance Benchmarking Results . . . 25
4.2.3 Data Chunk Digest: Calculation and Impact on Performance . . . 30
4.2.4 Bottleneck Analysis . . . 31
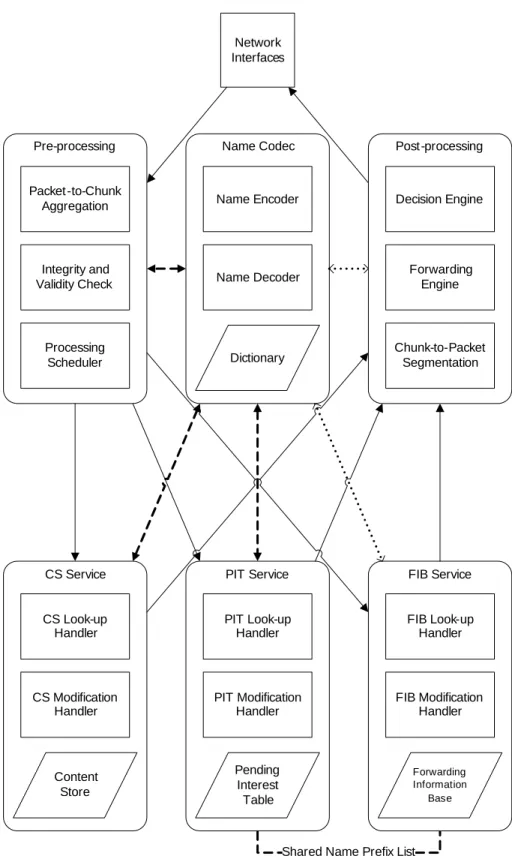
4.3 CCNx Node Service Decomposition . . . 32
4.3.1 Augmented Functional Flow for Interest and Content Chunks . . . 32
4.3.2 Extracted Service Model of a CCN Router . . . 35
4.4 Concluding Remark . . . 38
5 SAVI CCN Design Alternatives 40 5.1 Design Requirements and Criteria . . . 40
5.2 SAVI Testbed User Topology and Resources . . . 41
5.3 Alternative 1: Header Decoder Optimization . . . 42
5.3.1 SAVI Resource Mapping . . . 43
5.3.2 Advantages . . . 43
5.3.3 Limitations . . . 44
5.4 Alternative 2: Parallel Table Access within Single Node . . . 44
5.4.1 SAVI Resource Mapping . . . 45
5.4.2 Advantages . . . 47
5.4.3 Limitations . . . 47
5.5 Alternative 3: Distributed Chunk Processing with Synchronized Table Services . . . 47
5.5.1 Out-of-sync Tables and “Good enough” Table Look-ups . . . 50
5.5.2 SAVI Resource Mapping . . . 50
5.5.3 Advantages . . . 51
5.5.4 Limitations . . . 51
5.6 Alternative 4: Distributed Chunk Processing with Central Table Service . . . 51
5.6.1 Chunk Processing Pipelining . . . 53
5.6.2 Optionally Centralized Name Codec Services . . . 53
5.6.3 SAVI Resource Mapping . . . 54
5.6.4 Advantages . . . 54
5.6.5 Limitations . . . 54
5.7 Alternative 5: Distributed Chunk Processing with Partitioned Tables . . . 55
5.7.1 Redefine a CCN Node Using Partitioned Table Approach . . . 56
5.7.2 Table (Name Space) Partitioning and Dynamic Re-partitioning . . . 58
5.7.3 Duplication of Popular Name Entries . . . 59
5.7.4 Handling Different CCN Message Types . . . 59
5.7.5 Internal Topology and Routing . . . 60
5.7.6 Reliability, Robustness, and Ability to Scale . . . 61
5.7.7 SAVI Resource Mapping . . . 61
5.7.8 Advantages . . . 62
5.7.9 Limitations . . . 62
5.8 Concluding Remark . . . 63
6 SAVI CCN Implementation and Evaluation 65 6.1 Optimized Header Decoder . . . 65
6.1.1 Methodology . . . 66
6.1.2 Experiment Results . . . 73
6.1.3 Remarks and Limitations . . . 77
6.2 Distributed Chunk Processing with Partitioned Tables . . . 78
6.2.1 Using CCNx as Processing Units . . . 79
6.2.2 Two Approaches Towards Realizing Pre-routing . . . 79
6.2.3 Estimated Upper and Lower Bounds of Performance Scaling . . . 83
6.2.4 Preliminary Evaluation . . . 86 6.3 Concluding Remarks . . . 93 7 Conclusions 94 7.1 Summary . . . 94 7.2 Future Work . . . 95 Bibliography 96 v
List of Tables
4.1 CPU usage and throughput of vanilla CCNx . . . 26
4.2 Statistics on header processing time for Content Store size=50000 . . . 27
4.3 Statistics on header processing time for Content Store size=0 . . . 28
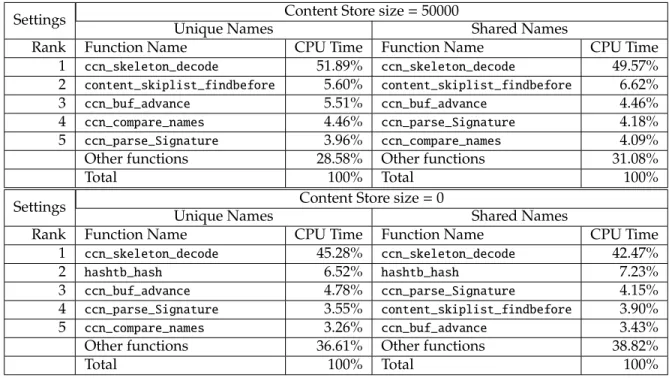
4.4 Top 5 time-consuming functions in CCNx under various settings . . . 31
5.1 Summary of the proposed design alternatives . . . 64
6.1 Observedccn_skeleton_decoder−>statevalues as input toccn_skeleton_decode . . . 70
6.2 OpenFlow entries to implement the unified virtual interface . . . 81
List of Figures
2.1 CCN chunk structure . . . 11
2.2 CCN node model [1] . . . 14
2.3 CCN node forwarding logic flow . . . 16
4.1 Experiment topology for performance benchmarking . . . 25
4.2 Histograms showing header processing time for each individual Interest and Data chunk for Unique Name (top) and Shared Name (bottom) settings, with Content Store size set to 50000 . . . 28
4.3 Histograms showing header processing time for each individual Interest and Data chunk for Unique Name (top) and Shared Name (bottom) settings, with Content Store size set to 0 29 4.4 Augmented functional flow of CCN forwarding logic . . . 33
4.5 CCN node model highlighting the 6 core services . . . 36
5.1 SAVI testbed user topology [2] . . . 41
5.2 Functional flow for parallel table access within single node . . . 46
5.3 Service model for distributed chunk processing with synchronized table services . . . 49
5.4 Service model for distributed chunk processing with central table service . . . 52
5.5 Service model for distributed chunk processing with partitioned tables . . . 56
5.6 Recursively redefining CCN nodes as networks of collaborating member nodes . . . 57
6.1 Functional flow for testing and verification routine . . . 72
6.2 Physical topology of experiments evaluating optimizedccn_skeleton_decode. . . 73
6.3 Logical topology of experiments evaluating optimizedccn_skeleton_decodeusing unique content names . . . 74
6.4 Unique content names: CPU usage and data rate vs. number of client-server pairs . . . . 75
6.5 Logical topology of experiments evaluating optimizedccn_skeleton_decodeusing shared
content names . . . 76
6.6 Shared content names: CPU usage and data rate vs. number of clients . . . 76
6.7 Logic flow of a processing unit with per-node re-routing function . . . 80
6.8 Data rate analysis for one processing unit . . . 84
6.9 Topology emulating the implementation of partitioned tables with centralized pre-routing unit . . . 88
6.10 Topology emulating the implementation of partitioned tables with per-node pre-routing module . . . 88
6.11 Preliminary evaluation for partitioned tables: unique content name case, system through-put vs. number of routing nodes. . . 89
6.12 Preliminary evaluation for partitioned tables: same content name case, system through-put vs. number of routing nodes. Higher throughthrough-put was achieved by avoiding instan-tiating all routing nodes on the same computing agent. . . 92
List of Acronyms and Definitions
API Application Programming Interface
ASCII American Standard Code for Information Interchange BEE Berkeley Emulation Engine
BM Baremetal
CATT Cache Aware Target idenTification CCN Content Centric Network(ing) CDN Content Delivery Network
COMET COntent Mediator architecture for content-aware nETworks CONET COntent NETworking project
CPU Central Processing Unit CS Content Store
CUDA Compute Unified Device Architecture DHT Distributed Hash Tables
DONA Data-Oriented Network Architecture DoS Denial of Service
DPI Deep Packet Inspection FIB Forwarding Information Base GB Gigabyte
Gbps Gigabit per second
GENI Global Environment for Network Innovations GPGPU General Purpose Graphic Processing Units HPC High Performance Computing
IaaS Infrastructure-as-a-Service ICN Information Centric Networking IP Internet Protocol
LFU Least Frequently Used LRU Least Recently Used MB Megabyte
Mbps Megabit per second MPI Message Passing Interface MTU Maximum Transmission Unit NDN Named Data Network(ing) NetInf Network of Information OSPF Open Shortest Path First OSPFN OSPF for NDN
OVS Open vSwitch P2P Peer-to-Peer
PBR Potential Based Routing PIT Pending Interest Table
PSIRP Publish-Subscribe Internet Routing Paradigm pub/sub publish-subscribe
PURSUIT Publish-Subscribe Internet Technology
QoS Quality of Service ROFL Routing on Flat Labels Rx/Tx Receive/Transmit
SAIL Scalable and Adaptive Internet Solutions SAVI Smart Application on Virtual Infrastructure SDI Software Defined Infrastructure
SDN Software Defined Network(ing) SIMD Single Instruction Multiple Data Std.Dev. Standard Deviation
TCP Transmission Control Protocol
TRIAD Translating Relaying Internet Architecture integrating Active Directories UDP User Datagram Protocol
VANET Vehicular Ad-hoc Networks VM Virtual Machine
VoCCN Voice-over-CCN VoIP Voice-over-IP
XML Extensible Markup Language
Chapter 1
Introduction
Over the past few decades, the Internet has become an essential infrastructure of the modern society. Although its simple design has been stunningly successful, the Internet has been pushed by its users to face many new challenges [3]. For example, a recent study has estimated that up to 98% of Internet traffic today consists of data related to content distribution [4], despite the fact that the original design of the Internet was based on a point-to-point communication model.
Such mismatches between the functional objectives and the canonical architecture of the Internet has stimulated much research and engineering efforts. One of the many approaches of realizing large-scale content distribution over the existing Internet is through the Peer-to-Peer (P2P) overlay networks [5–7]. In a P2P network, the content consumers (peers) allow access to each others’ resources such as computational power, storage, and network bandwidth without requiring centralized control by the content providers. Such collaboration among peers allows content to be distributed not only from providers to consumers, but also between consumers. The P2P architecture dissolves the barrier between servers and clients in the traditional server-client networking model, and possesses many advantages such as high scalability and availability [5]. Recent research has also demonstrated that through collaboration of peers, the virtual community can utilize diverse resources provided by each peer to accomplish greater tasks beyond the potential of each individual participant [8].
Another approach is the Content Delivery Network (CDN) [9–12]. CDNs are designed to provide reliable and high-performance content delivery services to content consumers. There are two general approaches to achieve such goal: overlay approachandnetwork approach. In overlay CDNs, contents are duplicated and distributed across the Internet at multiple distinctsurrogate servers. Users requesting the data are directed to the closest surrogate server and contents are served by traversing only a
Chapter1. Introduction 2
local portion of the Internet. Such design decouples the content delivery from the core network infrastructure, allowing direct deployment over existing Internet infrastructure. The overlay model has achieved commercial success by companies such as Akamai [13], Amazon CloudFront [14], and CDNetworks [15]. In network-oriented CDNs, on the other hand, devices such as routers and switches are augmented to make application-specific forwarding decisions. An example of early network-based content delivery solution is Internet Protocol (IP) Multicast [11].
In a recent trend multiple methods are combined to explore novel alternatives: [16] and [17] inves-tigated the usage of P2P methodology in CDNs for improved scalability and reliability; [18] looked at bringing Distributed Hash Tables (DHT) and other P2P techniques to publish-subscribe (pub/sub) networks for high-performance content distribution; [19] focused on content caching and accessing in pub/sub system as an alternative way of implementing high-performance CDNs.
All approaches described above focus on realizing high-performance content distribution over existing Internet architecture. While several have been quite successful in both academia and industry, none of them resolves the fundamental conflicts between efficient content dissemination and the point-to-point communication model of Internet today. Motivated by the limitations of existing Internet architecture, researchers around the world have been re-evaluating and re-designing Internet from lower levels. Many have come to the agreement that the center of future Internet needs to be shifted fromhoststocontent, which forms the foundation of Information Centric Networking.
Information Centric Networking (ICN) describes the paradigm shift of content dissemination strat-egy from host addressing to content naming. In an ICN, data are described bynames, and communication is resolved based on the names of content instead of the location of hosts. Such approach brings many benefits as outlined in Section 2.1.
1.1
Motivation
ICN is proposed as an approach towards efficient content dissemination over the Internet. Because the ultimate goal of ICN is to deliver data to the interested entities on the network quickly and reliably, the performance, specifically throughput is one of the most important metrics among many critical specifications of an ICN system.
Currently there is a clear gap between the two streams of research concerning ICN and its perfor-mance (Chapter 3): on the one hand, researchers focusing on improving the perforperfor-mance of existing ICN projects propose novel mechanisms for specific components of an ICN system, and show their results through numerical analysis or simulations. On the other hand, researchers implementing the
Chapter1. Introduction 3
ICN prototypes build testbeds with functional verification and refinement as their primary objectives. This thesis is motivated by such gap between the proposednovel mechanisms in improving ICN performance and thepracticalimplementation and evaluation of these mechanisms in realistic settings. Specifically we plan to design, implement, and evaluate practical ways of improving the performance of an ICN system, and demonstrate the throughput gain through experiments using realistic traffic.
1.2
Problem Statement
The goal of this thesis is to design, implement, and evaluate a high performance network application based on an existing ICN prototype. Specifically we aim to improve the throughput of Content Centric Networking (CCN) [1] using the CCNx open source project [20] on the Smart Application on Virtual Infrastructure (SAVI) testbed.
We propose the following objectives for this thesis:
1. Firstly, we will study and analyze the existing CCN scheme and CCNx code, understand the underlying architecture, and find the bottleneck(s) of the current implementation;
2. Next, we will propose and compare design alternatives towards improving the performance of the existing implementation, with mapping between CCN functional modules and SAVI resources; 3. Finally, based on the results of above studies, we will implement a preliminary prototype of
improved CCN application and evaluate its performance on SAVI testbed. Some of the expected challenges of this thesis project include:
• Finding effective ways of benchmarking the existing CCNx project and locating the system bot-tleneck under realistic operating conditions;
• Designing a practical high performance CCNx-based system, preferably compatible with the existing CCNx architecture, which fully utilizes resources of a virtual infrastructure;
• Implementing a functional prototype within the project time limit; • Testing and evaluating the prototype on SAVI at scale.
1.3
Contributions
This thesis presents a practical ICN design approach towards realizing high performance Content Cen-tric Networking on virtual infrastructure. A preliminary implementation based on CCNx is deployed,
Chapter1. Introduction 4
tested, and evaluated on SAVI testbed. Several contributions are made during the course of this thesis. They include:
• A study on the performance of existing CCNx prototype is presented, based on which bottleneck of the current system is identified;
• The logic flow of a CCN node is augmented with highlights of the bottleneck functions. A high level service model is extracted from the logic flow, which identifies the critical services of a CCN node;
• Five design alternatives are proposed for realizing high performance content centric networking on virtual infrastructure. SAVI resource mapping as well as pros and cons for each design approach are discussed;
• Preliminary implementation of two of the design approaches are deployed and tested on SAVI testbed. Evaluation using realistic traffic load shows that our design is scalable and it is capable of sustaining throughput beyond 1Gbps.
1.4
Organisation
The rest of this thesis report is organized as follows: in Chapter 2 we provide the background information on ICN, CCN, and SAVI testbed in general. In Chapter 3 we review some of the existing literature on the topics of ICN testbeds around the globe, performance of CCN, as well as CCN router designs. Then in Chapter 4, we explain our methodology of benchmarking CCNx on SAVI. Based on the benchmarking results, we locate the bottleneck function and present a service decomposition of the CCN node. Chapter 5 takes the analysis further by proposing design alternatives for a high performance content centric networking solution. For each proposal, mapping from services to SAVI resources is also discussed. In Chapter 6, we examine two distinct methods of improving CCN throughput, and present preliminary implementations using CCNx. Evaluation results on SAVI testbed are then presented and discussed for both approaches. In the last chapter, we conclude this thesis with a summary and plans for future works.
Chapter 2
Background
2.1
Information Centric Networking
Information Centric Networking (ICN), also known as Named Data Networking (NDN) or Content Centric Networking (CCN), describes collectively the approaches towards future Internet architecture in which the communication model is built aroundnames(description of content) of the information instead of hosts or locations of the information. ICN designs treat identity, security, and access of information as the primitive of their communication models, and as a result, decouples the retrieval of information from its location.
2.1.1
Advantages of ICN
ICN has many advantages over the current Internet due to the shift of emphasis from hosts to names of information. Some of the most noted ones include:
Efficient Content Distribution
A primary feature of ICN is caching of contents at arbitrary network locations. This is enabled by characterizing contents by ‘names’ which describe contents themselves instead of URLs which de-scribe the locations. In comparison to the existing packet caching feature offered by some network devices, the caching in ICN is built into the communication model, and offers greater flexibility in management of cached contents. Caching of content allows efficient content dissemination over an ICN enabled network by serving clients with the nearest local copy. Research has shown that the ICN scheme can substantially improve bandwidth utility and network delay [21–23].
Security
Chapter2. Background 6
The paradigm shift from host locations to content has also promoted new security strategies in the communication scheme. Because the content can be obtained from any network entity, security was designed to focus on the content itself instead of where (host identity) and how (communication channel) it was obtained. Security and related features such as digitally signing every data packet are not only recommended but usually required by ICN. As a result, though still an active field of research, ICN is believed to be more secure and robust against various threats seen in today’s Internet, including identity fraud and denial of services (DoS) attacks [24].
Resilience and Mobility
Because ICN data packets can be temporarily stored at any network location, ICN can be used to provide resiliency in networks in which connections or physical channels are not always available. In ICN, if a request for content is not satisfied due to temporary network outage, the issuer (content consumer) can resend the request once the connection is back. Depending on the timeout settings and caching policy, the requested content could be retrieved by a much closer network entity than the original content source. This allows a much faster and more efficient ‘reconnect’ after an outage occurs. The same feature can be used to support networks requiring mobility of nodes: when the access point changes for a network node, it is able to quickly continue its communication because previously requested information can be easily retrieved. One example of ICN’s application in networks with high resilience and mobility requirements is the Vehicular Ad-hoc Networks (VANET) [25, 26].
Support for Applications and Services
As a direct consequence of all the above characteristics, ICN is believed to support certain ap-plications and services better than today’s Internet. Efficient content distribution ensures ICN performs well for content distribution and information multicast, which is what ICN was initially conceived for; the unique security related features allow ICN to be used for services requiring high data integrity; its resilience and support for mobility enables ICN as a viable option for Vehicular Ad-hoc Networks (VANET) [25, 26] and many more.
2.1.2
Open Issues and Challenges in ICN
Though much potential is seen in ICN, it is also agreed that the current ICN scheme has many open issues. Some of the challenges brought by the content-centric approach towards Internetworking include:
Chapter2. Background 7
Support for Point-to-point Applications
Although the majority of traffic on Internet today are for content distribution, there are many applications which are inherently point-to-point. For example in financial transactions, unicast messaging, and Voice over IP (VoIP) services, the packet exchanges are strictly of interest to only the participating hosts, and often should not be cached due to security reasons. Researchers have been looking into these communication models. Prototypes like Voice-over-CCN (VoCCN) [27] were built to demonstrate ICN’s capability in supporting traditional point-to-point applications, though much work still remains with respect to efficiency and security [24].
Performance
Because ICN traffic is characterized by ‘names’ which are usually more flexible than fixed length addresses of hosts, more complex mechanisms are involved in name resolution, data routing, and content caching. Such complexity has profound implication on the overall performance of the system because any performance bottleneck in the pipeline can slow down the entire system. In addition, performance of ICN can go much beyond the basic throughput to include a variety of metrics such as power consumption, bandwidth efficiency, latency, etc.
Quality of Service
Quality of Service (QoS) is another metric closely related to performance. QoS describes how ICN can meet the different requirements from various applications and services it needs to support beyond best-effort. QoS is also related to other topics such as resource management, reliability, and priority determination. While the significance of QoS in ICN has been recognized, there has not been much published work describing implementation-level details about QoS in ICNs.
2.1.3
Major ICN Projects
Because of all the advantages outlined above, ICN is seen as a promising approach towards designing future Internet by researchers around the globe. Pioneered by Translating Relaying Internet Architecture integrating Active Directories (TRIAD) [28] and Routing on Flat Labels (ROFL) [29], many projects have flourished based on the fundamental concepts of ICN. Some of the most influential ones include:
• Data-Oriented Network Architecture (DONA) [30];
• Content Centric Networking (CCN) [1, 20] in the Named Data Network (NDN) project [31]; • Subscribe Internet Routing Paradigm (PSIRP) [32] and its continuation: the
Chapter2. Background 8
• Network of Information (NetInf) [34–36] from the Architecture and Design for the Future Internet (4WARD) [37], which is also part of the Scalable and Adaptive Internet Solutions (SAIL) project [38];
• COntent Mediator architecture for content-aware nETworks (COMET) [39, 40] funded by the EU Framework 7 Programme (FP7);
• The CONVERGENCE project [41] including the COntent NETworking (CONET) project [42], also funded by FP7.
Descriptions and in-depth comparisons of these projects can be found in survey papers [24, 43, 44].
2.1.4
Main Components of an ICN
Despite the large number of incarnations of the ICN concept, the main architectural components of any ICN project remain within the following 4 categories:
Naming
Naming describes the format of content names and how they are associated with the content pieces they describe. Some key metrics of a naming scheme include: structural hierarchy, readability by human, available character sets, flexibility, and extensibility. Based on the naming conven-tion, different algorithms or methodologies are implemented to generate, associate, distribute, certify, and search for the names. Naming forms the foundation of an ICN implementation and profoundly influences the design and performance of other components in the system.
Name Resolution and Data Routing
Name resolution describes how names are ‘understood’ by network entities within an ICN. It determines how any given piece of information is located, whether at the original content source or any cached location. It must also be able to handle changes (deletion and addition) of the content names in an ICN. While name resolution usually gives direction on where to find the requested content, data routing describes how the data is delivered. One of the main issues is how to scale any routing methodology to the size of today’s Internet. Many proposals use techniques from IP routing into ICNs for certainty in functionality, while others adopt new schemes to avoid existing problems in IP routing [44].
In-network Caching
Chapter2. Background 9
content distribution in an ICN. It involves caching and duplication mechanisms, caching policies, cache space management, as well as deployment and dynamic update of caching information for joint optimization.
Security
Today’s Internet was designed based on a trusted environment, and utilizes add-on services like firewalls to achieve security goals. In contrast, security is raised as a primary and required function in ICNs, and covers topic such as data integrity, entity (content and host) authentication and verification, cryptographic key management, access control, etc.
Because ICN is an on-going project in which little clear consensus has been reached for any of the components, the four topics listed above are also active fields for research efforts. Pros and cons of various ways of implementing the components in some of the projects have been discussed in [24].
2.2
Content Centric Networking
Content-Centric Networking (CCN) [1, 20] from the Named Data Network (NDN) project [31] is one of the many Information Centric Networking prototypes drawing much research attention recently.
2.2.1
Advantages of the CCN Approach
In this thesis project we choose to follow CCN’s architecture for designing and implementing our system, because it provides the following additional benefits in comparison to other ICN approaches: CCNx open source project
The most important reason why we choose CCN as the basis of our design is the CCNx open source project [20]. CCNx is a fully functional Linux-based application conforming to the CCN protocol. Its source code is available to the public through CCNx website [20] and is based on popular languages: the low-level control and management routines are written in C for high performance, and the high-level APIs are provided in Java for extensibility.
CCNx is helpful to us in 2 ways: firstly it implements all essential components of a practical ICN system in a very accessible way. Any new components or modifications we make can utilize the existing functions, reducing the development time of our project. Secondly CCNx provides a window through which we can gain confident insights into the behavior and performance of a practical ICN system, a fundamental requirement to our project which other ICN approaches cannot provide.
Chapter2. Background 10
CCNx-based application prototypes
In addition to the implementation of the CCN protocol itself, CCNx and its APIs also lead to a range of applications developed by other researchers. Some example applications include point to point message passing (ccnchat), file sharing (the repositoryccnr), video streaming (VLC plugin), voice (VoCCN [27]), and automated traffic generation (ccntraffic and ccndelphi[45]). These available applications enables us to quickly test our own implementation, and to evaluate it under various realistic use case scenarios.
Optional human-readable content names
Besides the CCNx code, CCN also possesses some helpful features defined in its protocol, one of which being the naming scheme. CCN uses hierarchical strings of arbitrary length as the content names, which is explicitly visible in the packet headers. While it may have its own pros and cons, the optionally human-readable content names can be helpful to both implementation and debugging of our project. By capturing the packets, we are able to directly see and analyze the packet transactions.
Support from existing devices
Another characteristic of the CCN protocol is its transport layer implementation: CCN uses IP as its transport layer support, and is proposed as an IP overlay. The choice of IP overlay instead of a more “clean slate” approach enables direct deployment over existing Internet devices, and allows coexistence of CCN and other IP traffic [1]. We see this design decision a positive feature because it allows fast prototyping on existing networking devices. At the same time the open nature of CCNx does not lock our project on IP-based devices as long as the interface is compatible. In addition, the SAVI testbed is based heavily on OpenFlow [46, 47] for its networking capability, which supports IP extensively. As a result the IP transport of CCNx minimizes any possible compatibility issues between our project and the SAVI hardware.
2.2.2
CCN Architecture Overview
This section provides a brief overview of the CCN Architecture. We focus on the components most relevant to our project, and therefore will not cover all the details about CCN protocol. A complete cov-erage of the CCN architecture is provided in [1], and details of the CCNx protocol and implementation can be found on the CCNx website at [20].
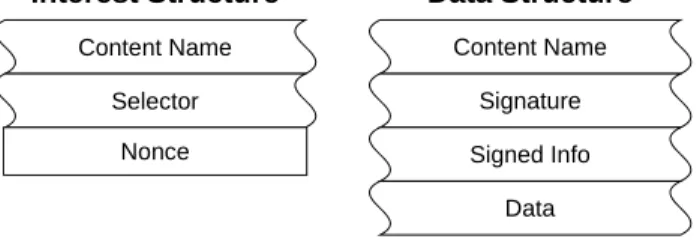
Chapter2. Background 11 Content Name Interest Structure Selector Nonce Content Name Data Structure Signature Signed Info Data
Figure 2.1: CCN chunk structure
CCN Chunk Types
The CCN protocol categorizes any traffic in a CCN network into one of the two types: Interest and
Data(Fig. 2.1). The basic units of information exchange in CCN are referred to aschunks. Similar to an IP network, chunks transferred in a CCN network have two parts: header and payload. Unlike in IP packets, the headers of CCN chunks have variable length and therefore are logically defined.
Interests are sent out by content consumers as requests for content. An Interest contains only a header without any payload and consists of three components: a Content Name used to described what content the consumer is interested in, a Selector describing additional filtering if multiple Data match the current Interest, and a Nonce to distinguish Interests with the same Content Name for avoiding Interest looping. The lengths of Content Name and Selector can be variable based on amount of information they contain, while Nonce is usually a randomly generated binary value of fixed length.
Data are sent out by content providers in response to any received Interests. A CCN Data consists of both header and payload, and is typically much larger in size than Interests due to the addition of payload. The Data header comprises three components: a Content Name describing the content of the payload, a Signature containing information such as digest algorithm and witness, and a Signed Info field containing publisher ID, key locator, stale time, etc. The Signature and Signed Info field work together to provide security-related features such as authentication and authorization in a CCN network.
According to the CCN protocol, a Data chunk is said to ‘satisfy’ an Interest if 1) the Content Name in the Interest is a prefix of the Content Name in the Data, and 2) the Data passes any additional filtering defined by the Selector in Interest. It is worth to mention that this definition and the structures described in Fig. 2.1 are all based on the canonical CCN protocol defined in [1]. CCNx adds much more implementation-level details and one additional packet type (controlmessages) which we will not explain here due to space limitation. More information is available on the documentation page of CCNx
Chapter2. Background 12
website [20] as well as documentations in the code base.
Information Exchange on CCN
Information exchange on a CCN network is initiated by any content consumer sending out Interests to its immediate neighbor nodes as a request for Data. Any node that receives an Interest but does not hold a copy of the requested Data will keep a copy of the Interest and forward the Interest to whom it believes may know where to find the Data. Once the Interest reaches a node with the request Data, whether it is a routing node or the content provider, the Interest is consumed, and the requested Data is sent back to the content consumer through the same route as the Interest but in reverse order. This is possible because each node traversed by the Interest holds a copy of the Interest (calledpending Interest) with the interface from which it arrives. All pending Interest are consumed as well when the Data traverses the network back to the content consumer. More details on how each CCN node handles Interest and Data chunks are discussed in Section 2.2.2.
Packet Aggregation in CCNx
In this thesis we deliberately use the wordchunkto refer to the basic unit of CCN transaction because one CCN chunk usually does not map to one IP packet directly. This is because the large size of a CCN chunk header relative to the 1500 byte maximum transmission unit (MTU) of a non-jumbo Ethernet frame. As a typical CCN header can have anywhere between 50 to 1000 octets, little space would be left for content payload if every IP packet were to contain the full header. To avoid excessive overhead, a CCN node ‘aggregates’ chunks sent to the same destination by interface, and encapsulates CCN chunks into IP packets with necessary segmentation. Such transport level segmentation (CCN chunk to IP packets) happens in addition to the application level segmentation (content to CCN chunks).
In the CCNx implementation, aggregation of CCN chunks to IP packets is handled automatically by
socketGNU C libraries and the Linux network stack: applications construct CCN chunks (which can
be either Interest or Data) and push them through sockets, which perform necessary segmentation and encapsulation transparent to the application.
Naming
As mentioned in the previous section, CCN incorporates a hierarchical naming scheme with optionally human-readable components. Typically a CCN name defines a tree structure much like the URLs used in today’s Internet. The root of the tree structure is aglobally routable name, which is a content name
Chapter2. Background 13
understood by all relevant CCN nodes. The leaves are referred to asorganizational names, which are only resolved by CCN nodes within the organization. The name trees with different roots collaboratively describe thename spacecontaining all the possible content names.
In addition to the American Standard Code for Information Interchange (ASCII) string describing the content, a CCN name is suffixed by components for versioning and segmentation of the data. This typically binary (non-ASCII) part of the name is usually automatically generated and handled by applications, and it contains crucial information for versioning and transport sequencing in CCN. More information on the topic can be found in [1].
XML Formatting and Binary Encoding in CCNx
In CCNx, the content name is only one part of a chunk. Unlike in IP networks where each packet is divided into fixed length headers and variable length payload, chunks in CCNx networks do not have any fixed length fields. Instead, data chunks in CCNx implementation are formatted using Extensible Markup Language (XML) schema with explicit field boundaries.
The XML-formatted chunks in CCNx support extension of application-specific components in ad-dition to the canonical components defined in the CCN protocol such as content name and chunk type. Users or developers of CCNx can define their own chunk components and remain backward compatible to the vanilla CCNx node implementation because any unrecognized header components are ignored by default. However such improved extensibility flexibility come at the cost of low performance in CCNx header resolution. We will discuss this further in Chapter 4.
The XML-formatted chunks are not transmitted directly on CCNx networks in human readable form. Instead, the wire format of CCNx chunks is a binary encoding of the XML structure. The utility used for binary encoding and decoding in CCNx is calledccnb.ccnbdefines a fixed order of components within a CCNx chunk, so that the binary encoding of the same chunk has the same bit sequence for transmission regardless of what order is used in its human-readable representation. More information about theccnbspecifications can be found on [20].
CCN Node Model: the 3 Components
A CCN node can be abstracted as a core forwarding engine with multiplefaces. A face is a generalized notion of interface: it can represent not only the hardware network interface through which communi-cation with other CCN network entities is realized, but also the logical interface used for exchanging information with attached applications. CCN chunks arrive at the faces, longest prefix matching is
Chapter2. Background 14
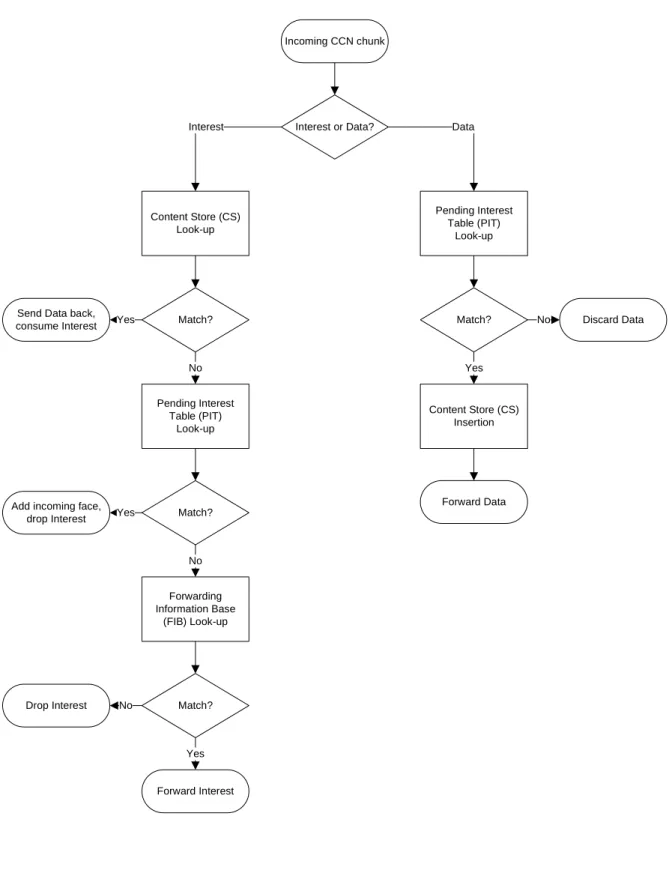
Figure 2.2: CCN node model [1]
performed on its content name, and based on the matching results actions are taken on the chunks. The core forwarding engine of a CCN node contains three main components: Content Store (CS) , Pending Interest Table (PIT) , and Forwarding Information Base (FIB) (Fig. 2.2).
The Content Store is the key component for realizing in-network caching. Similar to the memory buffer in IP routers, a Content Store temporarily stores any Data chunks passing through the CCN node. The difference is that CS in a CCN node uses additional filtering and caching policies to define which CCN chunks to cache and how replacement is done.
The Pending Interest Table stores any unsatisfied Interest chunks forwarded towards the content sources. It keeps a copy of any incoming pending Interests with the face from which they come from, which is ‘consumed’ when matched Data chunks are sent back to the content consumers. PITs are necessary because routing in CCN is done only on Interests: Data simply trace back the Interests requesting them.
The Forwarding Information Base acts much like FIBs in IP routers and is used to route Interest chunks towards potential content sources. The difference between a CCN FIB and a FIB in IP routers is that the CCN FIB allows multiple outgoing faces, which implies that routing in CCN is not restricted to a spanning tree: multiple potential sources of content can be queried in parallel.
To illustrate how the three components of a CCN node function, let us consider a CCN chunk arriving at one of the faces of a CCN node. First of all, the node identifies the type of the incoming chunk as either Interest or Data. In the case of an incoming Interest, it is first checked against the Content Store.
Chapter2. Background 15
If any matching entry is found, meaning a cached Data satisfies the incoming Interest, the matched Data is sent directly to the face Interest comes from, and no further action is needed. If the CS look-up misses, the Interest is then looked up in the Pending Interest Table. Any matched entry means there are already pending Interests recorded at this node possibly from other faces, and the incoming face of the current Interest is added to the list of faces interested in such Data without the current Interest being forwarded. If the PIT look-up misses too, the incoming Interest is first recorded in the PIT, then looked up for the final time in the Forwarding Information Base. If a matching entry is found, the Interest is forwarded according to the matched entry; otherwise, it implies that the incoming Interest cannot be resolved by the current node, and the CCN protocol requires the incoming Interest to be dropped to avoid flooding of Interest on network.
In the case of an incoming Data chunk, its name is first looked up in Pending Interest Table. If no matching pending interest is found, the incoming Data is said to be unsolicited and should then be discarded as it may be the result of a system malfunction or even malicious attack. If any number of entries in the PIT can be satisfied by the incoming Data, the Data is forwarded to all the requesting faces of every matched pending Interest, and all matched pending Interest are erased from PIT because they have been satisfied. Before it is finally forwarded, the Data chunk is added to Content Store for future Interests.
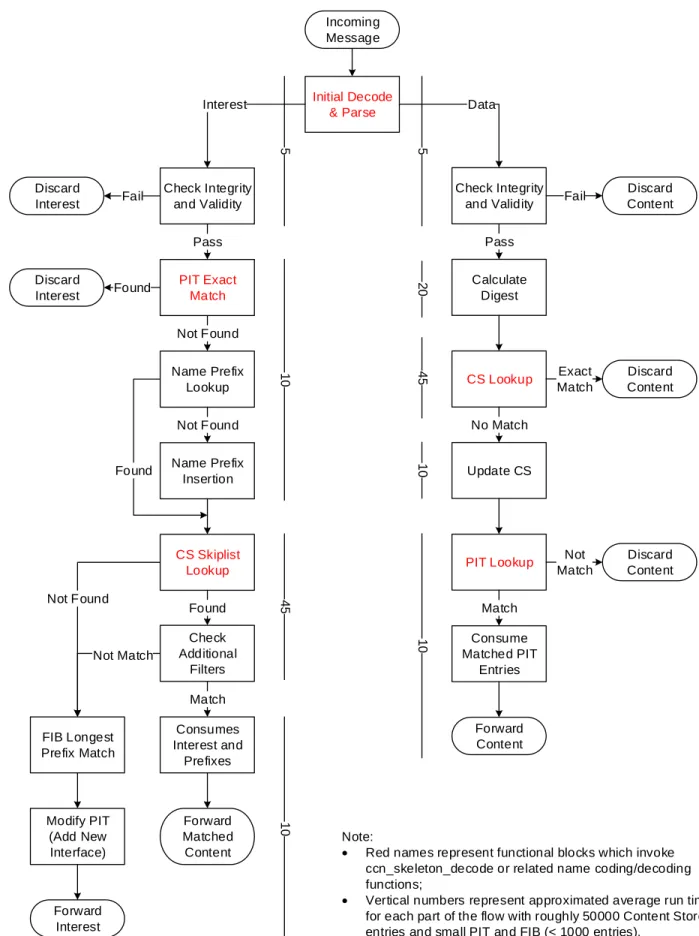
The logic flow described above on how a CCN node resolves incoming chunks is also illustrated in Fig. 2.3.
Transport: Reliability and Flow Control
CCN is designed as an IP overlay, implying that it relies on an IP stack for underlying network substrate. Comparing to other more “clean-slate” ICN approaches, CCN presents a much simpler solution for features of networking and lower layers by assuming IP connectivity, and it enables CCN to be incrementally deployed on existing Internet infrastructure. However the use of IP protocol stack also imposes certain limitations on current CCN design. The fundamentally point-to-point nature of IP goes against the content-based network model. We believe much work remains in bringing CCN forward without assuming IP dependency, but this will be the topic of a future project.
According to the CCN protocol, CCN does notrequire a reliable network substrate. This implies that Interests and/or Data can be corrupted during transport. In addition, communications over CCN are consumer-driven, and the content providers are stateless. As a result, any unsatisfied Interest needs to be resent by consumers upon certain conditions such as a time-out. This effectively constructs a
Chapter2. Background 16 Incoming CCN chunk Interest or Data? Pending Interest Table (PIT) Look-up Content Store (CS) Look-up Interest Data Match? Send Data back,
consume Interest Yes
Pending Interest Table (PIT)
Look-up No
Match? Add incoming face,
drop Interest Yes
No Forwarding Information Base (FIB) Look-up Match? Yes Forward Interest No Drop Interest
Match? No Discard Data
Yes
Content Store (CS) Insertion
Forward Data
Chapter2. Background 17
host-to-host reliability model in which hop-by-hop reliable transmission is not guaranteed by CCN nodes.
Similarly, flow control is also handled by content consumers by how they send out Interests. CCN protocol requires that Interest and Data chunks are one-to-one, i.e. exactly one Data chunk is delivered in response to one Interest by any CCN node. This maintains aflow balancewithin the network at each hop, and allows CCN Interest chunks to be used as tools of achieving flow control by applications much like the ACK packets in Transmission Control Protocol (TCP).
2.3
Smart Application on Virtual Infrastructure
The NSERC Strategic Network for Smart Applications on Virtual Infrastructure (SAVI) [48] is an initiative building a large scale testbed for research in future Internet applications. SAVI envisions an application platform in the form of an extended cloud infrastructure with extremely large scale computing, storage, and network resources. Some of the characteristics of SAVI testbed include: agile resource management, scalability, reliability, accountability, security, interconnect and federation, and rapid deployment of applications [49].
SAVI has five research themes: smart applications, extended cloud computing, smart converged edge, integrated wireless optical access, and SAVI application platform testbed. A detailed description of each theme is provided in [50]. In this thesis project, we focus on the last theme, i.e. the SAVI application platform testbed, as explained in the upcoming subsection.
SAVI Testbed for Networking Experiments
The application platform testbed of SAVI is designed and implemented to help researchers to overcome the difficulty in deploying and testing new networking applications at scale. The testbed takes the form of federated smart-edge clusters from which researchers can reserve a variety of resources isolated from other users or projects.
In terms of implementation, SAVI testbed demonstrates the following key technology highlights: • Infrastructure-as-a-Service (IaaS) cloud capability, including computing, storage, networking,
dashboard, identity management, and image services, enabled by OpenStack [51]; • Software defined networking (SDN) capability enabled by OpenFlow [46, 47];
Chapter2. Background 18
• Software defined infrastructure (SDI) capability enabled by SAVI SDI Manager, which is currently under development.
These technologies connect and enable a wide variety of hardware as available resources to SAVI users. Some of the key hardware available to users include:
• High performance multi-CPU server blades called Computing Agents, which are available in the form of virtual machines (VM);
• Dedicated machines called Baremetal (BM) with dedicated gigabit Ethernet connectivity. Baremetal comes with a variety of flavors including high performance, low power, and legacy support; • Highly parallel co-processors such as general purpose graphic processing units (GPGPU) attached
to high performance Baremetal;
• Programmable hardware available both as attached devices (NetFPGA [53, 54]) to high perfor-mance Baremetals and as standalone network devices (BEE2 and miniBEE development plat-forms [55]);
• OpenFlow enabled switches available as slices through FlowVisor.
These resources, together with the underlying technologies supporting them, make the SAVI testbed a preferred platform over other cloud services or computing facilities for designing, implementing, and evaluating our project due to the following reasons:
• Variety of available resources enables a larger design space and more design alternatives;
• Flexible edge-core architecture of SAVI allows prototyping and experimentation in different envi-ronments;
• Federation of SAVI edges and highly scalable SAVI core enables testing and experiments at scale; • Software defined infrastructure allows more transparency and control over resources from users’ perspective through knowledge of physical topology, ability to suggest physical host of virtual instances, etc.
In addition, because the SAVI testbed is a relatively young project itself, we are able to enjoy the additional benefits of 1) a more controlled environment due to the low number of active users and running projects, and 2) more interactions with the testbed development group for requesting features and enhancements at the cost of occasional system instability.
Chapter 3
Related Work
In this chapter we go over some of the existing works related to this thesis. Specifically we will cover three areas: the ICN testbed initiatives around the globe, literature on improving the performance of CCN or other ICN approaches, and high performance content-centric router designs.
3.1
ICN Testbeds
In Section 2.1.3, we gave a list of major ICN-themed initiatives. Though most of them are still research projects under development, some of the projects have reached the stage of testing and evaluation on testbeds. We surveyed a few of the ICN testbeds because we believe they are closely related to our goal of designing, implementing, and evaluating an ICN prototype on SAVI testbed.
NDN testbed
As part of the Named Data Networking (NDN) project, the NDN testbed is an open initiative running CCN on a large scale [56]. Essentially, the NDN testbed deploys the CCNx software on a slice of the Global Environment for Network Innovations (GENI) testbed [57], and uses OSPFN [58] as the routing solution. As of the time this thesis is written, NDN is actively running and collaboratively maintained by many universities and research facilities in the U.S. A video streaming application was demonstrated during CCNxCon2012 using the NDN testbed [59]. The main goal of NDN testbed is to study the different components of current CCN design, and push the specifications forward towards standardization. Although performance is one of the metrics under investigation, it is not the main concern for NDN project and its testbed deployment.
Chapter3. RelatedWork 20
CONET on OFELIA
Initially described in [60], CONET is a ICN framework within the CONVERGENCE project [41]. The implementation of CONET is described in [61] as coCONET, and is designed based on a software defined network enabled by OpenFlow. The discussion is extended in [62] to describe a plan of deploying CONET on OpenFlow-enabled testbeds, or specifically the OFELIA (OpenFlow in Europe - Linking Infrastructure and Applications) project [63]. In a more detailed technical report [64], CONET researchers propose to use dedicated Boundary Nodes to interface between traditional IP networks and CONET ICN, both based onIP network stackenabled by OpenFlow. In practice, the implementation of CONET is based on CCNx, with focus on CONET-specific lookup-and-cache forwarding mechanisms and transport [42]. Little information is publicly available on the OpenFlow-specific features of CONET implementation beyond [64].
PURSUIT testbed
PURSUIT [33] is an EU FP7 project proposed as a more “clean slate” approach towards ICN. Unlike CCNx and its derivatives, it does not require IP stack, and is designed based on Ethernet. The resulting prototype implementation is namedBlackadderand is publicly available as an open source project. Blackadder is developed based on the Click Router [65] platform, and its testbed deployment relies on OpenVPN [66] to create a virtual Ethernet substrate over Internet with IP-based equipment.
Similar to the NDN testbed, the PURSUIT testbed is used mainly for functional verification and testing of the PURSUIT prototype. Performance is not one of the primary objectives.
NetInf testbed
The Network of Information (NetInf [36]) on EU FP7 project SAIL is an ICN initiative focusing on caching content in the Internet and re-expressing them asinformation objects. In NetInf, centralized servers are used to find and cache content from Internet in real-time, and clients queries data from the servers using content descriptions (names). Its implementation, OpenNetInf [35] consists of both server and client applications. The servers are publicly available as preconfigured virtual machines, and clients as plugins for Mozilla Firefox®browser and Mozilla Thunderbird®email client. Source code for both server and client applications are also available.
NetInf testbed is a complete set of virtual NetInf nodes run by the NetInf development group, and is used for testing purposes only as substitute for local NetInf nodes. Performance is mostly considered in NetInf protocol specifications and OpenNetInf design, without being emphasized
Chapter3. RelatedWork 21
on testbed deployment.
3.2
Performance of CCN
Though performance is currently not one of the major concerns on existing ICN testbeds, much research effort has been put on improving performance of ICN systems from a variety of angles.
As one of the fundamental component of any ICN, in-network caching is a topic drawing much attention. [67] shows through mathematical analysis and simulations that simple caching policies such as Least Frequently Used (LFU) can give significant performance improvement by reducing average hop count when compared to ICNs without in-network caching. Building on the most basic caching policies, a large variety of caching mechanisms are proposed and evaluated, and performance improve-ments beyond simple LFU or LRU caching are demonstrated usually through numerical analysis or simulations. Some examples of existing work on alternative caching policies include: [68], [69], [70] and [71] on various forms of collaborative caching among ICN peers, [72] on diffusive caching, [73] on probabilistic caching, and [74] on selective neighbor caching.
Another area of research related to improving ICN performance is on the layer of networking and transport. [75] discusses congestion avoidance in data-centric opportunistic networks and recommends high data refresh rate for optimal delivery efficiency. [75] discusses the economic incentives behind routing policies in NDN and proposes the use of Cache Sharing between peers and Routing Rebates between customers and provides. [76] introduces Potential Based Routing (PBR) for ICN and Cache Aware Target idenTification (CATT) caching policy, and demonstrates their potential of achieving near optimal routing performance using simulations. [77] proposes to simplify the existing CCN forwarding structure and argues that their design can achieve 1Gbps forwarding performance with software and 10Gbps with hardware acceleration through numerical analysis. [78] proposes Popularity-Aware Load Balancing for content networks and shows that differentiating popular and unpopular content favors multi-path routing patterns in simulations. [79] investigates segmentation and chunk sizing in ICN and recommends segmentation of data chunks into smaller units for reliability and congestion control.
In addition to the above, research has also focused on performance in ICN. For example, [80] evaluates CCN performance with different storage management algorithms on a testbed; [81] looks at alternative data structure implementation and algorithms for Content Store in CCNx to improve CS hit probability; [82] analyzes the performance implication of content integrity check in a more generic system with in-network caching; [83] proposes a wrapper to enable CCNx on Ethernet substrate without IP and shows it lowers the latency; and [84] introduces parallelization to FIB lookup and shows that
Chapter3. RelatedWork 22
system performance is improved using either bloom filter or hash table as the lookup algorithm.
3.3
CCN Router Designs
Another research topic highly related to this thesis is the design of high performance content centric routers. In [85], researchers evaluated the bandwidth, latency, and cost of current state-of-the-art hardware in the context of the three key components of a CCN router (CS, PIT, and FIB). Conclusion drawn is that with today’s technology, hardware implementation of CCN can support traffic up to the scale of a campus or service provider network but not the Internet. The same group of researchers extend the discussion to [86], in which Caesar, a hardware implementation of CCNx-compatible router is proposed. Two key design decisions are made in [86]: 1) one forwarding engine is attached to each physical interface, and is responsible for a subset of the entire CS, PIT, and FIB; 2) hardware bloom filter is used to filter incoming packets, and packets that cannot be handled by current interface are routed to the correct interface through a switching fabric internal to all physical interfaces.
Besides Caesar, other work on CCN router designs include: [87] provides an alternative content centric router design on programmable hardware with emphasis on the Content Store and supporting operations (however like Caesar, the design is evaluated by simulation only); [88] discusses 3 different memory structures for realizing a generalized name lookup table for CCN nodes; and [89] focuses specifically how Pending Interest Table can be implemented in CCN routers.
Chapter 4
Bottleneck Analysis and Service
Decomposition of CCN
4.1
Motivation
The goal of this thesis project is to design and implement a high performance CCN routing solution on SAVI tesbed. Though [1] gives a thorough explanation of the CCN protocol (see Section 2.2.2 for some of the highlights), we have little knowledge about the practical implementation of CCN (i.e. the CCNx project) beyond the limited documentation in [20], which are also quite out of date. Before setting out for the actual design, however, it is crucial for us to understand the performance metrics and current bottlenecks of the existing CCN implementation.
Specifically, we dedicate this chapter of the thesis to answering the following questions:
• What is the performance of the current CCN implementation, or specifically, how fast can CCNx process CCN chunks (Interests and Data)?
• What is the bottleneck in the current CCNx project limiting its performance?
• If we were to build our system using CCNx, what specific functional module(s) should we work on in order to avoid or relieve the bottlenecks?
Chapter4. BottleneckAnalysis andServiceDecomposition ofCCN 24
4.2
CCNx Performance Benchmark and Bottleneck Analysis
To understand the real performance and bottlenecks of a practical CCN implementation, we believe it is necessary to go beyond numerical analysis and simulations. As a result, we decide to deploy CCNx software on SAVI and to systematically evaluate its performance under realistic traffic load.
4.2.1
Experiment Setup
We set up our performance evaluation experiments on SAVI using vanilla CCNx 0.7.1 on a combination of virtual machines (VM) and baremetal (BM). We ran theccndrouting daemon on a baremetal with Intel® Core™i7 CPU at 3.6GHz and 16GB RAM. This baremetal acted as the single routing node without consuming or generating CCN chunks, and all performance measurements were conducted on it. Connected to the routing node were 4 virtual machines instantiated on SAVI computing agents. Each VM had access to one virtual CPU at 2.2GHz with 2GB RAM. Among the 4 VMs, 2 of them ran
ccndwithccntraffic, and the other 2 ranccndwithccndelphi.
ccntrafficandccndelphifrom [45] are a pair of traffic generating applications running on CCNx.
When deployed,ccntrafficgenerates CCN Interest chunks according to a predefined list, andccndelphi←
-generates CCN Data chunks with a specified root name. We utilize these two applications throughout our thesis work for testing and evaluation purposes because they provide a simple way of generating realistic CCN traffic with arbitrary predefined patterns. In addition, becauseccntrafficgenerates
In-terests andccndelphigenerates Data, we commonly refer to CCN nodes runningccntrafficascontent consumersorclientsand those runningccndelphiascontent providersorservers.
We chose to use baremetal on SAVI testbed for our performance analysis because of 2 reasons: firstly, it has the most powerful CPU (Intel®Core™i7 3.5GHz) for executing single-threaded application, which should give a good estimation on the best possible performance metric of CCNx running on current commercial state-of-the-art hardware; secondly, instances running on baremetals have exclusive access to the hardware, which minimizes influences external to the running CCNx program.
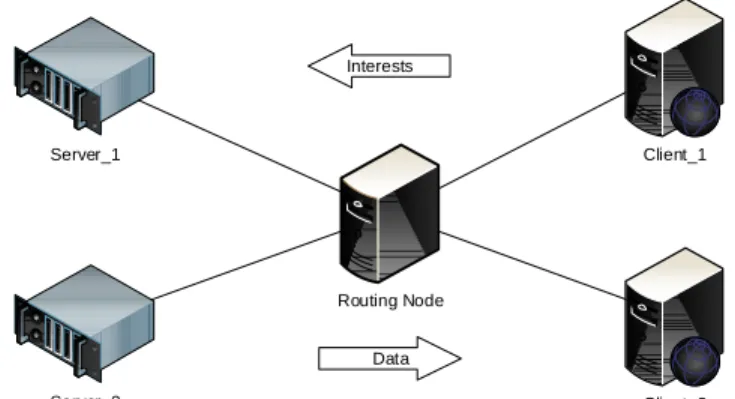
For our benchmarking experiments, we logically connected the 2 server nodes and 2 client nodes directly to the routing nodes usingccndccommands. The resulting topology and direction of packet flow are shown in Fig. 4.1
For all experiments, CCNx was configured to run in TCP mode; servers were configured to generate Data chunks with payload of 1024 bytes; software on all 5 nodes were compiled using GNU C compiler version 4.6.3 and ran on 64-bit Ubuntu 12.04 LTS. We also turned compiler optimization offbecause we used GDB to step through the code as a way to study the code. More discussion on this topic will be
Chapter4. BottleneckAnalysis andServiceDecomposition ofCCN 25 00000000000000 00000000000000 00000000000000 Routing Node Server_2 00000000000000 00000000000000 00000000000000 Client_2 00000000000000 00000000000000 00000000000000 Client_1 Server_1 Interests Data
Figure 4.1: Experiment topology for performance benchmarking
presented in the later sections of this chapter.
We constructed 2 scenarios for evaluating CCN and studying its bottlenecks: unique content name case and shared content name case. Under unique content name settings, Server 1 and Client 1 exchanged information based on content name pattern ccnx:/gen/1/chunk index, while Server 2 and Client 2 were configured to use content names ccnx:/gen/2/chunk index, where chunk index is simply an integer starting as 0 and increases. In contrast, for shared content name case, both clients sent Interest of format ccnx:/gen/chunk index to the routing node, and both servers could generate Data satisfying the Interests. These cases cover the two extremes of possible traffic scenarios: unique content name, on the one hand, represents the ‘worst’ use case for CCN in which no content transferred from any server to a client can be re-used by another client, and Content Store in each node is not providing any benefit because CS look-ups from Interests always miss. Shared content name, on the other hand, represents the ‘best’ traffic scenario for CCN because Data used to serve the early Interests are cached in the Content Stores on the routing node, and are used to satisfy all subsequent Interests from other clients before the Data expire. This reduces the delay and bandwidth resulting from the communication between the routing node and servers and thus improves the overall system performance.
4.2.2
Performance Benchmarking Results
Preliminary evaluation of CPU usage and throughput
As a first step, we benchmarked vanilla CCNx on SAVI testbed using the experiment settings described above. We measured two metrics on the routing node: CPU usage of theccndprocess and total inbound
and outbound throughput. All theccndinstances were configured with the same default settings (e.g.
Content Store size set to 50000). The experiments were first run for approximately 3 minutes after clients started sending Interests for the system to reach steady state. Then during the next 100 seconds CPU
Chapter4. BottleneckAnalysis andServiceDecomposition ofCCN 26
Experiment setting ccndCPU usage Inbound data rate (MB/s) Outbound data rate (MB/s)
Unique content names 71.02% 5.70 5.69
Shared content names 69.41% 5.11 9.31
Table 4.1: CPU usage and throughput of vanilla CCNx
usage measurements were taken using thetoputility at a rate of 1 instantaneous reading per second. The readings were average after 100 such measurements were taken. The throughput measurement in megabytes-per-second (MB/s) was taken using theifconfigcommand by dividing the total amount of inbound and outbound traffic by 100. Every experiment setting was run 3 times, and results were shown in Table 4.1 by averaging the measurements for the 3 runs. All data rates shown are in megabytes-per-second (MB/s). Number of IP packets transmitted through the physical interface is not shown in the table because they do not directly translate to number of CCN chunks per second processed due to packet aggregation in CCNx (Section 2.2.2). Instead, CCN chunks processed can be estimated1by assuming size of Interests and Data chunks being 500 bytes and 1500 bytes respectively.
It can be seen from Table 4.1 that though the CPU is not at full load, the data rate for both unique content name and shared content name cases are far below the 1 gigabit-per-second (Gbps) link capacity of the routing node: assuming 70% CPU usages corresponds to at most 50% of the full capacity of the routing nodes, we expect a maximum throughput of 23MB/s or 184 megabit-per-second (Mbps) for unique content name case, and a maximum throughput of 30MB/s or 240Mbps for shared content name case. There is plenty of room for improvement if we were to set 1Gbps as our design goal. Similar observation is also described in [77].
It is interesting to note that the effect of in-network caching can be clearly seen from Table 4.1: for shared content name case, outbound data rate (data to clients) is 1.83 times the inbound data rate (data from servers). As a comparison, the ratio of outbound to inbound data rate is 1.00 for unique content name case.
Header processing time
While the above experiments evaluated the performance of CCNx prototype on a system level, they did not provide much insight in performance of header processing on a chunk-level. In order to quantify how much time it takes to process each CCN chunk and to understand how CCNx implements the chunk forwarding mechanism, we identified the part of the code which performs Interest and Data header processing, and re-ran the experiments to measure how much time it took each function call of
1CCNx provides API which measures the chunk-per-second rate on each face. However from our experiments we found that
such probing is expensive and invoking the API frequently degrades the performance of the system. As a result, we generally avoided using the API when conducting performance-sensitive readings.
Chapter4. BottleneckAnalysis andServiceDecomposition ofCCN 27 XX XX XX XX XX Metrics
Settings Unique Names Shared Names Interest Data Interest Data Total Number of Chunks 210,129 209,928 347,682 213,926
Mean (µs) 71.65 93.11 72.55 95.44
Median (µs) 70 91 72 94
Std. Dev. (µs) 22.12 35.62 24.44 35.50 Table 4.2: Statistics on header processing time for Content Store size=50000
processing Interest or Data header to return.
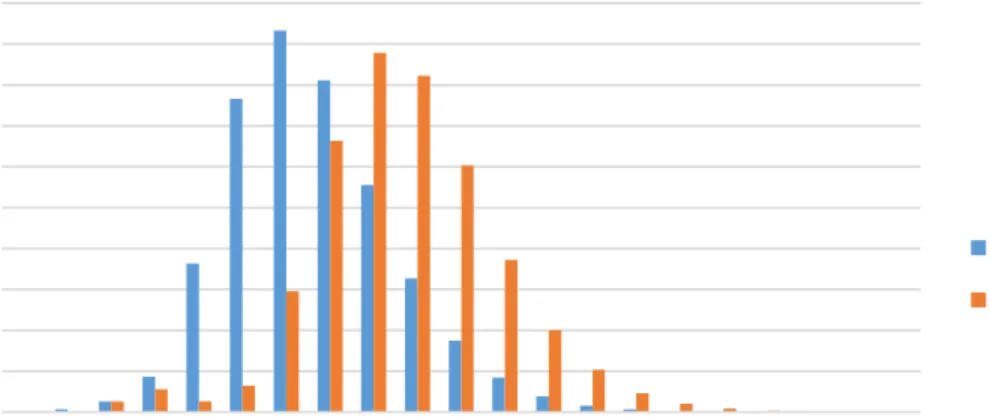
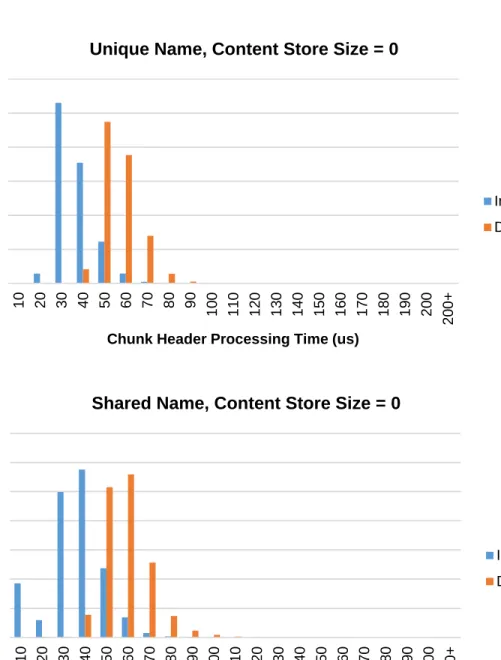
The experiments were first run with Content Store size set to the default value of 50000. We take measurements as soon as clients started sending Interests, and recorded processing time of both Interest and Data chunks for approximately 200 seconds. Readings from the first 100 seconds were discarded as system reached steady state (Content Stores fully populated) at the end of the first 100 seconds. The measured processing times for the later 100 seconds are plotted in histogram as Fig. 4.2 for both unique content name setting and shared content name setting. Some of the key values for the two runs are summarized in Table 4.2.
A few observations can be drawn from Fig. 4.2 and Table 4.2: first of all, the total count of Interest and Data chunks sampled is well below the typical value for a CCNx node operating under normal conditions. This is because that probing the processing time for each and every CCN chunk placed a significant I/O overhead which only exists within the settings of this experiment. Secondly, processing each Data chunk takes approximately 20 microseconds more than processing one Interest, and such difference is consistent across both unique and shared name cases. The extra 20 microseconds processing time for Data chunks came from the calculation of Data Digest. Further discussion on this topic is provided in Section 4.2.3. Thirdly, processing time for Interests or Data does not differ much for unique and shared name settings, though Fig. 2.3 suggests a shorter flow for shared name case because CS-matched Interests skip PIT and FIB look-ups. This implies that looking up PIT and FIB takes negligible amount of processing time in the actual CCNx implementation under our experiment settings.
After revisiting the chunk logic flow defined in CCN protocol (Fig. 2.3), we realized that for our experiments, the sizes of both PIT and FIB are small compared to CS: Content Store can cache up to 50000 CCN data chunks, while FIB contains only a few routes and PIT holds around a few hundred pending interests. To verify that searching and modifying the Content Store are the most time-consuming part of processing a header, we repeat the above experiments with Content Store size set to 02. Results of this run are shown in Fig. 4.3 and Table 4.3.
2The current CCNx implementation does not support turning offthe Content Store. By setting CCND CAP environmental
variable to 0 forccnd, every Data chunk cached will time out in a short period of time, effectively allowing minimal Data chunk
Chapter4. BottleneckAnalysis andServiceDecomposition ofCCN 28 0 5 10 15 20 25 30 35 40 45 50 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 1 1 0 1 2 0 1 3 0 1 4 0 1 5 0 1 6 0 1 7 0 1 8 0 1 9 0 2 0 0 2 0 0 + N o . o f C C N C h u n k s ( * 1 0 0 0 )
Chunk Header Processing Time (us)
Unique Names, Content Store Size = 50000
Interest Data 0 10 20 30 40 50 60 70 80 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 1 1 0 1 2 0 1 3 0 1 4 0 1 5 0 1 6 0 1 7 0 1 8 0 1 9 0 2 0 0 2 0 0 + N o . o f C C N C h u n k s ( * 1 0 0 0 )
Chunk Header Processing Time (us)
Shared Names, Content Store Size = 50000
Interest Data
Figure 4.2: Histograms showing header processing time for each individual Interest and Data chunk for Unique Name (top) and Shared Name (bottom) settings, with Content Store size set to 50000
XX XX XX XXX X Metrics
Settings Unique Names Shared Names Interest Data Interest Data Total Number of Chunks 213,750 213,525 328,919 304,324
Mean (µs) 31.84 52.35 31.11 54.58
Median (µs) 30 51 32 53
Std. Dev. (µs) 11.77 17.43 15.01 16.23 Table 4.3: Statistics on header processing time for Content Store size=0
![Figure 2.2: CCN node model [1]](https://thumb-us.123doks.com/thumbv2/123dok_us/1919759.2782188/25.918.199.747.106.451/figure-ccn-node-model.webp)
![Figure 5.1: SAVI testbed user topology [2]](https://thumb-us.123doks.com/thumbv2/123dok_us/1919759.2782188/52.918.184.765.113.367/figure-savi-testbed-user-topology.webp)