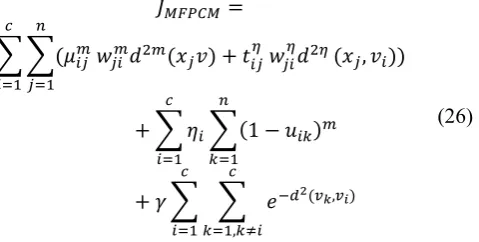S. Sathappan,
Computer Science,
Erode Arts and Science College, Erode-638 009. Tamil Nadu. India.
Dr. S. Pannirselvam,
Abstract—Image compression plays a significant role in multimedia data communication, particularly when the allotted band is limited. The restrictions in bandwidth for communication require a better technique for sending the image. This can be achieved by compressing the image accordingly. Additionally, because of the restriction in number of wireless channels, advancement image transmission has achieved extensive recognition. Wavelet-based image compression is the widely used compression technique as it affords recognized transmission in low bandwidth allotted channels in which significant low frequency data in the image is transmitted initially, and then less significant high frequency data are transmitted. However, the usage of wavelets may reduce the quality of image. To overcome those difficulties, this paper focuses on developing a better image compression technique for progressive. A low bit rate image compression technique by compressing the indices of Vector Quantization (VQ) and creating residual codebook is presented in this paper. The indices of VQ are compressed by gathering the similarity between image blocks, which decreases the bit per index. A residual codebook comparable to VQ codebook is obtained that indicates the noise resulted in VQ. With the help of this residual codebook the noise in the reconstructed image is diminished, by this means improving the quality of image. In VQ, clustering is performed to split the image into blocks for identifying the similarity. The clustering algorithm used in this paper is the modified version of Fuzzy Possibilistic C-Means (MFPCM) which includes repulsion term for better clustering. The experimental result suggests that the proposed image compression technique results in better compression with higher PSNR valve when compared to the conventional image compression techniques.
Keywords—Image compression, Vector Quantization, Residual Codebook, Modified Fuzzy Possibilistic C-Means, Repulsion
I. INTRODUCTION
HE reduction in size of the image is achieved by means of applying the data compression technique on digital images. The intention of image compression is to decrease the repeated content of the image pixel. This will help in effective storing or transmmision data in an efficient form. Image compression can be lossy or lossless. Lossless compression is usually favored for artificial images like technical drawings, icons or comics. The main reason for this is the usage of lossy compression techniques, particularly when utilized at low bit rates which results in evolving of compression artifacts. Lossless compression techniques may also be utilized for high value content like medical imagery or image scans created for compression purposes. Lossy techniques are particularly
appropriate for natural images like photos in applications where minor loss of reliability is acceptable to accomplish a considerable decrease in bit rate. The lossy compression that results in imperceptible variations can be called visually lossless. Some of the techniques available for lossless image compression are run-length encoding and entropy encoding. Some of the techniques applicable in image compression with loss in image quality are transform coding based scheme such as Fourier-related transform like DCT or the wavelet transform, followed by quantization and entropy coding. This paper focuses on using Vector Quantization technique for compressing an image.
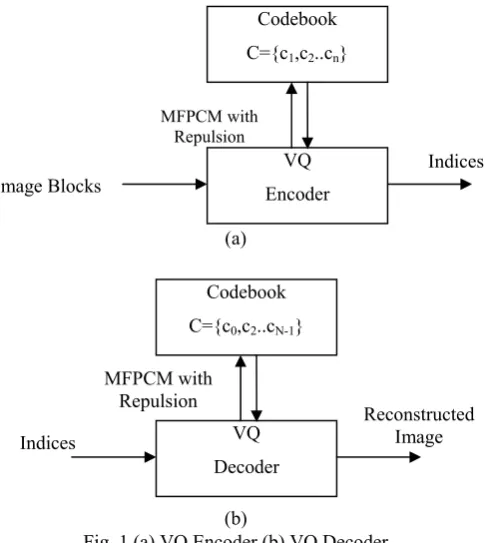
Vector Quantization [6] [7] is an effective method for image compression. VQ compression system has two parts namely VQ encoder and decoder as shown in Fig.1.
(a)
(b)
Fig. 1 (a) VQ Encoder (b) VQ Decoder
In VQ method, the given image is partitioned into a set of non-overlapping image blocks , , … , of size 4 x 4 pixels each and a clustering algorithm, for example Modified Fuzzy Probabilistic C-Means with repulsion in the
Vector Quantization for Image Compression using
Repulsion based FPCM
T
Codebook C={c1,c2..cn}
VQ Encoder
MFPCM with Repulsion
Indices Image Blocks
Codebook C={c0,c2..cN-1}
VQ Decoder MFPCM with
Repulsion
proposed technique, is used to generate a codebook
, , … , for the given set of image blocks. The codebook C comprises of a set of representative image blocks called codeword’s. The VQ encoder calculates a nearest match codeword in the codebook for all image block and the index of the codeword is passed to VQ decoder. VQ decoder changes the index values in the decoding stage with the codeword from the codebook and generates the reconstructed image. To achieve low bit rate, many VQ schemes like side-match VQ (SMVQ) [9], classified SMVQ (CSMVQ) [10] and Gradient dependent SMVQ (GSMVQ) [6], have been developed. SMVQ [9] utilizes the high correlation between neighboring blocks to achieve low bit rate. It makes use of the master codebook C to encode image blocks in the first column and first row in advance.
The further image blocks are encoded using the correlation with the adjacent encoded image blocks. For the compression method, consider x is the input image block, u and l be the upper and left adjacent codeword’s, the size of the known image block size be k = m× n. The side-match distortion of a codeword Y is given as:
, , ,
,
SMVQ, CSMVQ, GSMVQ and JSPVQ provide the low bit rate system but needs high encoding time than VQ method. In this paper, an efficient low bit rate image compression scheme is proposed based on VQ that makes use of compression of indices of VQ and residual codebook with modified fuzzy probabilistic c-means with repulsion instead of LGB. This method provides the low bit rate and enhanced image quality than SMVQ, CSMVQ, GSMVQ and JPVQ. To generate codebook, Modified Fuzzy Possibilistic C-Means technique is used and to improve the accuracy of clustering repulsion term is used.
The rest of the paper is organized as follows: in section II, the literature survey is presented. In section III the FPCM scheme is described. Proposed technique is described in section IV, performance of the proposed system is evaluated in section V and section VI concludes the paper with some discussion.
II. LITERATURE SURVEY
Yanfeng Zhang et al., [1] proposed an Agglomerative Fuzzy K-means clustering method with automatic selection of cluster number (NSS-AKmeans) approach for learning optimal number of clusters and for providing significant clustering results. High density areas can be detected by the NSS-AKmeans and from these centers the initial cluster centers with a neighbor sharing selection approach can also be determined. Agglomeration Energy (AE) factor is proposed in order to choose an initial cluster for representing global density relationship of objects. Moreover, in order to calculate local neighbor sharing relationship of objects, Neighbors Sharing Factor (NSF) is used. Agglomerative Fuzzy k-means
clustering algorithm is then utilized to combine these initial centers to get the desired number of clusters and create improved clustering results. Experimental observations on several data sets have proved that the proposed clustering approach was very significant in automatically identifying the true cluster number and also providing correct clustering results.
Xiao-Hong et al., [2] presented a novel approach on Possibilistic Fuzzy C-Means Clustering Model Using Kernel Methods. The author insisted that fuzzy clustering method is based on kernel methods. This technique is said to be kernel possibilistic fuzzy c-means model (KPFCM). KPFCM is an improvement in Possibilistic Fuzzy C-Means (PFCM) model which is superior to fuzzy c-means (FCM) model. The KPFCM model is different from PFCM and FCM which are dependent on Euclidean distance. The KPFCM model is dependent on non-Euclidean distance by implementing kernel methods. In addition, with kernel methods the input data can be mapped into a high-dimensional attribute space where the nonlinear pattern now looks linear. KPFCM can deal with noises or outliers superior than PFCM. The KPFCM model is interesting and provides better solution. The experimental observation shows that KPFCM provides significant performance.
Zhang Zhe et al., [3] proposed an improved K-Means clustering algorithm. K-means algorithm is extensively utilized in spatial clustering. The mean value of all the cluster centroid in this technique is taken as the Heuristic information; hence it has some demerits such as sensitive to the initial centroid and instability. The improved clustering algorithm referred to the best clustering centroid which is searched during the optimization of clustering centroid. This increases the searching probability around the best centroid and enhanced the strength of the approach. The experiment is performed on two groups of representative dataset and from the experimental observation, it is clearly noted that the improved K-means algorithm performs better in global searching and is less sensitive to the initial centroid.
Sreenivasarao et al., [5] presented a Comparative Analysis of Fuzzy C- Mean and Modified Fuzzy Possibilistic C -Mean Algorithms in Data Mining. There are various algorithms used to solve the problem of data mining. FCM (Fuzzy C mean) clustering algorithm and MFPCM (Modified Fuzzy Possibililstic C mean) clustering algorithm are comparatively studied. The performance of Fuzzy C mean (FCM) clustering algorithm is analyzed and compared it with Modified Fuzzy possibilistic C mean approach. Difficulty of FCM and MFPCM are measured for different data sets. FCM clustering technique is separated from Modified Fuzzy Possibililstic C mean and that uses Possibililstic partitioning. The FCM uses fuzzy portioning such that a point can fit in to all groups with different membership grades between 0 and 1. The author concludes that the Fuzzy clustering, which comprise the traditional component of soft computing. This approach of clustering is appropriate for managing the difficulties related to understandability of patterns, incomplete/noisy data, mixed media information and human interaction and can offer estimated solutions quicker. The proposed approach for the unlabeled data clustering is presented in the following section.
III. METHODOLOGY
The compression scheme comprises of two components, compression of indices and generation of residual codebook. These two components are described in the following section.
3.1.Compression of Indices
While vector quantizing the image blocks, there expected to exist high correlation between the neighboring blocks and also between the equivalent codeword indices. As a result, coding of indices is done by comparing the previous indices; thereby reduction can be attained in the bit rate. In Search Order Coding (SOC) [14], a general searching method is followed to locate a match for the present index from the preceding indices. The search order SO is termed as the order in which the current index is compared with the preceding indices.
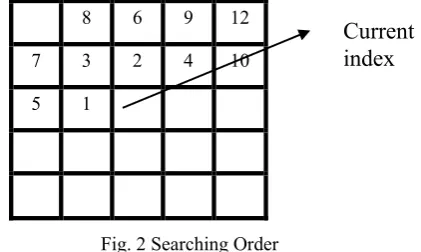
Fig. 2 Searching Order
The SO utilized in [14] is depicted in Fig.2. The label “1” represents the highest searching priority, “2” represents the second highest priority and so on. To reduce the comparisons of the current index with the preceding indices, the searching
range (SR) is fixed. The SR is the number of preceding indices to be compared with current index.
The index of the codeword of a block is encoded utilizing the degree of the resemblance of the block with formerly encoded upper or left blocks. When the degree of the resemblance of the existing block with one of the two formerly encoded blocks is huge, the index of the codeword of the block is encoded by utilizing the index of the adjacent codeword that is the codeword index of the existing block and that of the adjacent blocks are similar. If the degree of resemblance of the block with the adjacent blocks is not huge, it is supposed that the closest match codeword of the existing block may be closer to the codeword’s of the adjacent blocks. For instance, if one of the two adjacent blocks codeword’s index is ‘N’, the nearest match codeword of the block to be encoded exist between (N-J) th codeword and (N+J) th codeword in the codebook, where J is any random number. Hence the index is coded in log 2 ∗ bits. This scheme is dependent on the property present in the codebook design utilizing LBG algorithm with splitting approach. In the splitting method, huge size codebook is produced by dividing each codeword of the lesser codebook into two. At all the time, the size of the codebook is in powers of two (2M→ 2(M+1)). Therefore, two similar image blocks may have equal closest match codeword in Jth position at codebook of size 2M and at codebook of size 2(M+1). By utilizing the real index value, other non-similar blocks are encoded. In this approach, predicting the similarity of a block with its left and higher blocks is not necessary to encode the index of the block. To facilitate this scheme, the coding index is compared with preceding indices based on the given SO in Fig.2 and SR is fixed as 2. Let 1, 2, . . ,12 be the SO and
_ 1 , _ 2 , . . _ 12 be the indices values of the SO = 1, 2,…, 12. The following steps are used to encode VQ index.
1 Get the first index generated by the VQ encoder and transmit as such.
2. Get the next index generated by VQ Encoder. Compare this index with the previous indices according SO
3. if SO = 1, code it as “00” and go to the step 2 else
if SO = 2, code it as “01” and go to the step 2 else go to the next step.
4 if index value ≤ (ind_val (SO = 1) + J) and index value ≥ ─ (ind_val (SO = 1)+J) { if ind_val (SO =1) = ind_val (SO=2) code it as “10” followed by log (2 * ) 2 J bits else
code it as “100” followed by log (2 * ) 2 J bits. }
go to step 2. else
if index value ≤ (ind_val (SO = 2) + J) and index value ≥ ─ (ind_val (SO = 2)+J) code it as “101” followed by log (2 * ) 2 J bits and go to step 2.
8 6 9 12
7 3 2 4 10
5 1
else
code it as “11” followed by its original index and goto step 2.
Decoding of the compressed indices is completed by reversing the above given coding steps.
3.2.Construction of Residual Codebook (RC)
Residual codebook , , … , is built using
absolute error values produced by VQ technique. For the creation of residual codebook, the least similar image blocks that are found in the codebook are considered. In the reconstructed image, the distortion is raised by the least similarity blocks compared to the high similarity blocks. Residual codeword ( for a least resemblance image block is generated by comparing it with its nearest match codeword. The group of residual codeword’s , ,… is called
residual codebook. Resemblance of an image block x with its nearest match codeword Yi is decided depended on minimum distortion rule (α) which exists between them. In an image block, if the mean square error (α) is higher than a predefined threshold value (σ), then the block is considered to be less resemblance block.
Let , , … , be a k-pixels image block and
, , … , be a k-pixels nearest match codeword, then the α is defined as:
1
(1)
The steps used for building residual codebook are given below.
Step1: An image which is to be compressed is decomposed into a set of non-overlapped image blocks of 4x4 pixels.
Step 2: A codebook is generated for the image blocks using LBG algorithm.
Step 3: Pick up the next codeword from the codebook C and find its all closest match less similarity image blocks(X) found out using (1) from the given set of image blocks and construct residual codeword using the following equation.
1
|
|, |
|, … , |
|
(2)
where k denotes the number of elements in the codeword and the image block respectively and m represents the number of least resemblance image blocks that are nearer to the codeword .
Repeat the step 3 until all the codeword’s are processed in the codebook. The residual values of the unhandled bits are determined from adjacent residual values using the following steps.
1.
3
2.
2
3.
3
4.
4
5.
4
6.
3
7.
2
8.
3
where pv (*) is the pre determined value of the equivalent bit in the residual sign bit plane and rrv (*) is the particular reconstructed residual value of the bit in the residual sign bit plane.
B
D
E
F
J
L
M
O
Fig. 3 Bits encircled are used for prediction
Once the residual codeword created, all the value nearer to the match codeword is added in the block. As the residual sign bit plane for all image block consists only 8 bits, alternative residual values in the residual codeword are dropped and it also minimizes the cost of storing residual codebook. The dropped residual values are determined from the adjacent residual values as specified above.
The main drawback of the LBG algorithm is that it consumes more time to generate the codebook and the next drawback is that each image has to allocate one individual codebook for encoding, which requires large storage space. To overcome these drawbacks, Modified Fuzzy Possibilistic Clustering C-Means Algorithm using Repulsion is used in this paper.
3.3.Proposed Modified Fuzzy Possibilistic Clustering C-Means Algorithm using Repulsion to Replace LBG
Fuzzy Possibilistic Clustering Algorithm
The fuzzified version of the k-means algorithm is Fuzzy C-Means (FCM). It is a clustering approach which permits one piece of data to correspond to two or more clusters and extensively used in pattern recognition. This approach is an iterative clustering approach that brings out an optimal c partition by reducing the weighted inside group sum of squared error objective function JFCM:
A
C
F
H
I
K
, ,
,
,1
∞
(3)
In the equation X = {x1, x2,...,xn} ⊆ Rp is the data set in the p-dimensional vector space, the number of data items is symbolized as p, c denotes the number of clusters with 2 ≤ c ≤ n-1. V = {v1, v2, . . . ,vc} is the c centers of the clusters, vi denotes the p-dimension center of the cluster i, and d2(x
j, vi) denotes the space between object xj and cluster centre vi. U = {μij} symbolizes a fuzzy partition matrix with uij = ui (xj) is the degree of membership of xj in the ith cluster; xj is the jth of p-dimensional calculated data. The fuzzy partition matrix satisfies:
0 ≺
≺ , ∀ ∈ 1, … ,
(4)
1, ∀ ∈ 1, … ,
(5)
m is a weighting exponent parameter on each fuzzy membership and establishes the amount of fuzziness of the resulting classification; it is a fixed number higher than one. Under the constraint of U the objective function JFCM can be reduced. Consider the value of JFCM with respect to uij and vi and zeroing them respectively, is compulsory but not adequate circumstances for JFCM to be at its local extrema will be as the following:
⁄
, 1
, 1
.
(6)
∑
∑
, 1
.
(7)
In noisy atmosphere, the memberships of FCM do not always correspond well to the extent of belonging of the data, and may be incorrect. This is mainly because the real data unavoidably engages with some noises. To recover this disadvantage of FCM, the constrained circumstance (5) of the fuzzy c-partition is not considered to obtain a possibilistic kind of membership function and PCM for unsupervised clustering is proposed. The component created by the PCM belongs to a intense region in the data set; each cluster is free from the other clusters in the PCM strategy. The following formulation is the objective function of the PCM.
, ,
,
1
(8)
where
∑
||
||
∑
(9)
is the scale parameter at the ith cluster,
1
1
,
(10)
denotes the possibilistic typicality value of exercised model xj belong to the cluster i. m ∈ [1,∞] is a weighting aspect said to be the possibilistic parameter. PCM is also depending on initialization distinctive of other cluster approaches. The clusters always will not have more mobility in PCM approaches, as all data point is categorized as only one cluster at a time rather than all the clusters concurrently. Consequently, a suitable initialization is necessary for the algorithms to converge to almost global minimum.
The characteristics of both fuzzy and possibilistic c-means approaches is incorporated. Memberships and typicalities are very significant factors for the correct attribute of data substructure in clustering difficulty. As a result, an objective function in the FPCM based on the memberships and typicalities is characterized as below:
, ,
,
(11)
with the following constraints :
1, ∀ ∈ 1, … ,
(12)
1, ∀ ∈ 1, … ,
(13)
The result of the objective function can be attained by an iterative approach where the degrees of membership, typicality and the cluster centers are revised with the equations as follows.
,
,
⁄
, 1
, 1
.
(14)
,
,
⁄
, 1
, 1
.
(15)
∑
∑
, 1
.
(16)
FPCM. The noise sensitivity flaw of FCM is eliminated by PFCM, which avoids the concurrent clusters difficulty of PCM. But the estimation of centroids is influenced by the noise data.
Modified Fuzzy Possibilistic C-Means Technique (MFPCM)
Objective function is very much necessary to enhance the quality of the clustering results. Wen-Liang Hung presented a new methodology called Modified Suppressed Fuzzy c-means (MS-FCM), which significantly develops the performance of FCM due to a prototype-driven learning of parameter α [19]. Exponential division potency between clusters is the base for the learning practice of α and is revised at each of the iteration. The parameter α can be calculated as
min
||
||
(17)
In the above equation β is a normalized term so that β is chosen as a sample variance. That is, β is defined:
∑
|
̅ |
̅
∑
But the remark which must be pointed out here is the common value used for this parameter by all the data at each of the iteration, which may induce in error. A new parameter is added with this which avoids this frequent value of α and changes it by a new parameter like a weight to every vector. Or every point of the data set possesses a weight in relation to every cluster. Consequently this weight permits to have a better classification especially in the case of noise data. The following equation is used to compute the weight.
∑
̅
∗ ⁄
(18)
In the previous equation wji represents weight of the point j in relation to the class i. In order to alter the fuzzy and typical partition, this weight is used. The objective function is comprised of two terms. The first one is the fuzzy function and utilizes a fuzziness weighting exponent, the second one is possibililstic function and utilizes a classic weighting exponent. It enables a quicker decrement in the function and enhances in the membership and the typicality if they tend toward 1 and diminish the degree when it tend toward 0. This grouping is to add weighting exponent as exhibitor of space in the two objective functions. The objective function of the MFPCM can be given as follows:
,
,
(19)
U = {μij} represents a fuzzy partition matrix, is defined as:
,
,
⁄
(20)
T = {tij} represents a typical partition matrix, is defined as:
,
,
⁄
(21)
V = {vi} represents c centers of the clusters, is defined as:
∑
∗
∑
(22)
The main disadvantage of the MFPCM is the fact that the objective function is truly reduced only if all the centroids are identical. The typicality of a cluster is based only on the space between the points to that cluster. To overcome this disadvantage and to improve the estimation of centroids, typicality and to lessen the undesirable effect of outliers, this algorithm is combined with repulsion.
Modified Fuzzy Possibilistic C-Means with Repulsion
In this approach Modified Fuzzy Possibilistic C-Means with Repulsion was proposed to reduce the drawbacks associated with the MFPCM and to improvise the clustering efficiency.
This approach focuses to reduce the intracluster distances while increases the intercluster distances, without implicitly using the constraint, but by adding a cluster repulsion term to the objective function.
∑
∑
,
∑
∑
1
∑
∑
,
,
(23)
Where γ is a weighting factor, and satisfies:
0,1 ,
∀
(24)
The repulsion term is significant if the clusters are nearer. With increasing space it becomes lesser until it is compensated by the attraction of the clusters. If the clusters are adequately spacious, and the inter-cluster space reduces the attraction of the cluster can be compensated only by the repulsion term.
Minimization of objective function with respect to cluster prototypes leads to:
∑
∑
1
,
,
∑
∑
1
,
,
(25)
,
1
,
,
(26)
The weighting factor γ is generated to stabilize the attraction and repulsion force that is reducing the intradistances within the clusters and increasing the interdistances among the clusters.
The difficulty in unidentified bounds of the weighting feature is related to cluster validity techniques. Cluster validity gives the better partition created by a clustering approach. The general way of calculating the validity is the amount of intracluster distances, over the least amount of the intercluster distances. This is known as the Xie-Beni index vXB, and is given as:
, ;
∑
∑
‖
‖
min
(27)
A good U, V pair should produce a small value of (27) because u is expected to be high when ||xk vi|| and well-separated v’s will produce a high value.
3.4.
The Proposed AlgorithmThe proposed scheme combines compression of VQ indices and Modified Fuzzy Possibilistic C-Means with Repulsion. The steps used in this compressor are as follows
1. An image which is to be compressed is decomposed into a set of non-overlapped image blocks of size 4x4 pixels.
2. A codebook is generated for the image blocks using Modified Fuzzy Possibilistic C-Means with Repulsion.
3. Construct a Residual Codebook (as described in section 3.4) for those image blocks (less similarity blocks) whose α is greater than σ .
4. Pick the next image block (current block) and find its closest match codeword in the codebook. Calculate mean square error α for the image block using equation (1) and index of the codeword is encoded using VQ indices compression scheme presented in section 3.1.
5. if (α ≤σ ), the current block is encoded as “0”. else
the current block is encoded as “1” followed by interpolated residual sign bit plane which is computed as described in section 3.2.
6. Repeat the step 4 until no more blocks exist in the image.
The compressed images decoded by reversing the all previously explained steps and residual block is reconstructed
and added for all less resemblance block as illustrated in section 3.2.
IV. EXPERIMENTAL RESULTS
To estimate the proposed technique experiments are done on standard gray scale images using a Pentium-IV computer running at 1.60 GHz under Linux Fedora core-2. Three images of 512 x 512 pixels in size are used. Codebook is generated using Modified Fuzzy Possibilistic C-Means with Repulsion for all the methods. Codebook is also created with LBG [8] for better comparison result. For this scheme, a codebook of size 64 is used. Performance evaluation of the proposed approach is done using the parameters like bit rate (bits per index) and peak signal-to-noise ratio (PSNR) given by:
10 log
255
where MSE (mean squared error) is defined as:
1
where xi and yi represents the original and the encoded pixel values and n is the total number of pixels in an image. The bits required to store codebook for different threshold values ranging between 50 and 2000 for Lena, Camera man and Pepper.
The performance of proposed method is estimated with the existing approaches for different gray- scale images of size and is given in the table I. J is set to 4 for the proposed method. From table I, it can be observed note that proposed method with the Modified Fuzzy Possibilistic C-Means with Repulsion instead of LBG has an enhancement in coding the VQ indices.
TABLE I
PERFORMANCE OF PROPOSED METHOD VQ WITH CODEBOOK SIZE 64 USING LBG,MODIFIED FUZZY POSSIBILISTIC C-MEANS,MODIFIED FUZZY POSSIBILISTIC C-MEANS WITH REPULSION IN CODING STANDARD GRAY SCALE
IMAGES OF SIZE 512 X 512 EACH
Images
VQ (bits / index)
LBG (bits / index)
MFPCM (bits / index)
MFPCM with Repulsion
(bits / index)
Lena 6 3.92 3.45 2.98 Camera
Man 6 4.08 3.68 3.01
Peppers 6 3.72 3.24 2.89
TABLE II
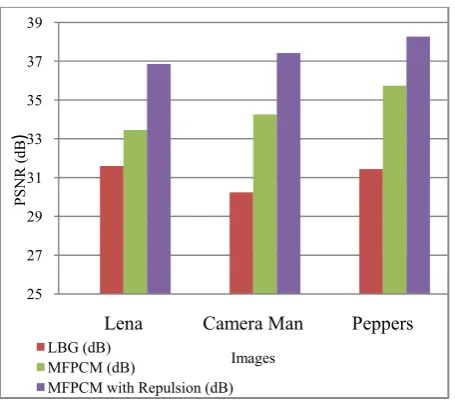
COMPARISON OF PSNR VALUES FOR THREE STANDARD IMAGES
Images LBG (dB)
MFPCM (dB)
MFPCM with Repulsion
(dB) Lena 31.60 33.45 36.86 Camera
Man 30.24 34.26 37.42
Peppers 31.44 35.74 38.27
From Fig. 4 it is estimated that this approach gives PSNR values of 36.86db, 37.42db and 38.27db for Lena, Camera man and Peppers respectively. From this it can be observed that the proposed approach produces better result than all the existing methods.
Fig. 4 Comparison of PSNR values for three standard images
V. CONCLUSION
The rapid growth and development of electronic imaging in recent years necessitates the efficient design of an image compression system for providing the better image quality in different applications. Various image compression techniques are available in the literature but most of them possess certain limitations. A novel image compression technique is proposed in this paper which provides better image quality and low bit rate. This proposed approach is based on VQ technique and uses residual codebook to enhance the image quality and compression of VQ indices to reduce the bit rate. To generate the code book, Modified Fuzzy Possibilistic C-Means with Repulsion is used which improves the compression ratio. Experimental results on standard images show that the proposed scheme gives better PSNR values and low bit rate than the existing approaches as codebook generation is done using the Modified Fuzzy Possibilistic C-Means with
Repulsion. As this proposed approach uses smaller codebook, it provides faster compression than the other methods.
VI. REFERENCES
[1] Yanfeng Zhang, Xiaofei Xu and Yunming Ye, “An Agglomerative Fuzzy K-means clustering method with automatic selection of cluster number,” 2nd International Conference on Advanced Computer Control (ICACC), Vol. 2, pp. 32-38, 2010.
[2] Xiao-Hong Wu and Jian-Jiang Zhou, "Possibilistic Fuzzy c-Means Clustering Model Using Kernel Methods," International Conference on Intelligent Agents, Web Technologies and Internet Commerce, Vol. 2, Publication Year: 2005, Pp. 465 – 470.
[3] Zhang, Zhe Zhang, Junxi Xue and Huifeng, “Improved K-Means Clustering Algorithm,” Conference on Image and Signal Processing, Vol. 5, pp. 169-172, 2008.
[4] Yang Yan and Lihui Chen, "Hyperspherical possibilistic fuzzy c-means for high-dimensional data clustering", ICICS 2009. 7th International Conference on Information, Communications and Signal Processing, 2009, Publication Year: 2009 , Pp. 1-5
[5] Vuda. Sreenivasarao and Dr. S. Vidyavathi, "Comparative Analysis of Fuzzy C-Mean and Modified Fuzzy Possibilistic C-Mean Algorithms in Data Mining", IJCST Vol. 1, Issue 1, September 2010, Pp. 104-106 [6] R.M.Gray, “Vector quantization,” IEEE Acoustics, speech and Signal
Processing Magazine, pp. 4-29, 1984.
[7] M.Goldberg, P.R.Boucher and S.Shlien, “Image Compression using adaptive vector quantization,” IEEE Transactions on Communication, Vol. 34, No. 2, pp. 180-187, 1986.
[8] Y. Linde, A. Buzo and R. M. Gray, “An algorithm for vector quantizer design,” IEEE Transactions on Communication, Vol. 28, No. 1, 1980, pp. 84 – 95.
[9] T.Kim, “Side match and overlap match vector quantizers for images,” IEEE Trans. Image. Process., vol.28 (1), pp.84-95, 1980.
[10] Z.M.Lu, J.S Pan and S.H Sun, “Image Coding Based on classified sidematch vector quantization,” IEICE Trans.Inf.&Sys., vol.E83-D(12), pp.2189-2192, Dec. 2000.
[11] Z.M.Lu, B.Yang and S.H Sun, “Image Compression Algorithms based on side-match vector quantizer with Gradient-Based classifiers,” IEICE Trans.Inf.&Sys., vol.E85-D(9), pp.1414- 1420, September. 2002. [12] Chia-Hung Yeh, “Jigsaw-puzzle vector quantization for image
compression” , Opt.Eng Vol.43, No.2, pp. 363-370, Feb-2004. [13] C.H.Hsieh, and J.C Tsai, “Lossless compression of VQ index with
search order Coding,” IEEE Trans. Image Processing, Vol.5, No. 11, pp. 1579- 1582, Nov. 1996.
[14] Chun-Yang Ho, Chaur-Heh Hsieh and Chung-Woei Chao, “Modified Search Order Coding for Vector Quantization Indexes,” Tamkang Journal of Science and Engineering, Vol.2, No.3, pp. 143- 148, 1999. [15] K. Lung, “A cluster validity index for fuzzy clustering”, Pattern
Recognition Letters 25(2005) 1275-1291.
[16] U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, “Advances in Knowledge Discovery and Data Mining”, AAAI Press and MIT Press, Menlo Park and Cambridge, MA, USA 1996.
[17] M.S. Yang, On a class of fuzzy classi4cation maximum likelihood procedures, Fuzzy Sets and Systems 57 (1993) 365–375.
[18] M.S. Yang, C.F. Su, On parameter estimation for normal mixtures based on fuzzy clustering algorithms, Fuzzy Sets and Systems 68 (1994) 13– 28.
[19] W.L. Hung, M Yang, D. Chen,” Parameter selection for suppressed fuzzy c-means with an application to MRI segmentation”, Pattern Recognition Letters 2005.
[20] R.C. Gonzalez, R.E. Woods, Digital Image Processing, Pearson Education Pvt. Ltd., New Delhi, 2nd Edition.
[21] M. Antonini, M. Barlaud, P. Mathieu, I. Daubechies, Image Coding using Wavelet Transform, IEEE Transactions on Image Processing, Vol. 1, No. 2, pp. 205-220, April, 1992.
25 27 29 31 33 35 37 39
Lena Camera Man Peppers
PSNR
(
dB
)
Images LBG (dB)
MFPCM (dB)