MAXIMILIEN, EUGENE MICHAEL Toward Autonomic Web Services Trust and Selection.
(Under the direction of Professor Munindar P. Singh).
Emerging Web services standards enable the development of large-scale
applica-tions in open environments. In particular, they enable services to be dynamically selected
and bound. However, current techniques fail to address the critical problem of selecting
the right service instances. The right service instances should be determined based on user
preferences and business policies in a manner that considers their trustworthiness.
We propose a multiagent approach that naturally provides a solution to the
selec-tion problem. This approach is based on an architecture and programming model in which
agents represent applications and services. The agents support considerations of semantics
and quality of service (QoS). They interact and share information, in essence creating an
ecosystem of collaborative service providers and consumers. Consequently, our approach
enables applications to be dynamically configured at runtime in a manner that continually
adapts to the preferences of the participants. Our agents are designed using decision theory
and make use of Semantic Web knowledge representation techniques for shared
conceptu-alizations (ontologies).
Our primary contribution is a model of trust, based on QoS, and constructed
from the perspective of individual agents. We evaluate the system and the trust model
empirically, via simulation experiments. The results show that our solution:
1. Captures simple quality preferences of service consumers and allows their agents to
the trust model, service consumers’ agents are able to continually select the correct
service implementations as the QoS exposed by the service implementations varies.
3. Captures complex preferences of service consumers. The improved model accounts for
multiple QoS preferences, multiple quality tradeoffs, as well as semantic and statistical
by
E. Michael Maximilien
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial satisfaction of the requirements for the Degree of
Doctor of Philosophy
Department of Computer Science
Raleigh 2004
Approved By:
Dr. Peter R. Wurman Dr. Laurie A. Williams
Dr. Munindar P. Singh Dr. Mladen A. Vouk
Biography
I was born on March 4th, 1973 in Port-au-Prince, Ha¨ıti. I attended the
presti-gious Saint-Louis de Gonzague high school, where I developed a passion for mathematics
and the sciences, computer programming (in Pascal), and was president of SODECO—a
small, student-owned, on-campus business. Being the son of an American citizen, I was
fortunate to attend college in the USA. In my first semester of college at Florida
Interna-tional University (FIU), Miami, I won a NACME scholarship with IBM which resulted in
summertime internships at the IBM Boca Raton software lab. I completed my B.Sc. (with
honors) in computer engineering at FIU in August 1995 and immediately started working
for IBM in Raleigh as a software engineer. Since I have always had a keen interest in the
emerging field of Object-Oriented Programming and Design (OOP/D), upon employment,
I realized that an advanced degree would be a great way to keep up with the evolution
of OOP/D and software engineering. With IBM’s full support, I enrolled in the graduate
computer science program at North Carolina State University (NCSU).
During my part-time studies to get my master’s degree in computer science at
NCSU, I increasingly became interested in the challenges of programming large, scalable,
and distributed systems (particularly Web systems). This led me to conduct doctoral
research with Dr. Munindar P. Singh, in what is considered the next wave in large-scale
distributed system for the Web: Web services and service-oriented architecture (SOA).
To facilitate the autonomy, programming, and scalability of this new environment, we are
looking (as are many others) into applying multiagent system (MAS) research results in
and making use of semantic data; thereby, approaching the goals of the next generation
Web or Semantic Web.
At IBM, I currently serve as advisory software architect. I have spent my entire
career at the IBM Retail Store Solutions (RSS) division doing all kinds of software-related
work from low-level driver development work, to high-level software architecture for large
enterprise store systems. I have also served as committee member for two Java software
standard activities. About seven of my nine years with IBM have involved programming in
Java and applying object-oriented design techniques, e.g., UML and design patterns.
During my career at IBM RSS I have received one Outstanding Technical
Achieve-ment award, one Leadership award, and one Excellence award. I was an invited guest to
the IBM Academy in 2001. I hold three issued and eight pending patents. I am a member
of the Tau Beta Pi, Eta Kappa Nu, Upsilon Pi Epsilon, and Golden Key academic honor
societies. I am also a member of the IEEE and the ACM professional societies. I am an
avid reader and a passionate soccer player.
Acknowledgements
Completing one’s dissertation is a difficult, lonely, and major endeavor. Mine was
no different. Along the way, some kind of support structure becomes increasingly important
for keeping one’s sanity along with actually completing the work. My own support structure
consisted of three main pillars.
First, my colleagues at IBM, starting with the RSS management team; particularly,
Ken Edwards and Heinz McArthur. Ken’s willingness to allow me the much needed one
year absence from “actual work” ultimately allowed me to complete this major task; for
that, I am forever grateful. I am indebted to Heinz’ constant support and management.
To my many IBM mentors, a resounding and heartfelt thank you! In particular, to John
Turek of IBM Research, thanks for your guidance and advises. To Curt Jews, of IBM TSS
Americas, the many conversations would be difficult to list. To Mike Pierce, of IBM PCD
and PSG, without your support these words would not be possible. To Peter Hortensius, of
IBM PCD and PSG, I am forever grateful for your blind trust in me without which I would
not have had the opportunity to complete this degree. To Mark Dean, of IBM Research,
your career and achievements, are an inspiration. To Sharon Nunes, of IBM CHQ, your
trust in me and your unconditional mentorship are admirable, and ultimately something I
will try to model after, throughout in my career. Last but not least, to Nick Donofrio, of
IBM CHQ, thank you for your support and for continuing and persisting in establishing a
diversified and innovative culture inside IBM while maintaining “respect for the individual”.
This results in a company rooted in strong corporate ethics and values, with a tradition
remaining a great corporate citizen. Your passion and leadership are commendable and
exemplary.
Second, to my NCSU advisors, colleagues, research partners, and friends. Your
guidance, empathy, and feedback have been invaluable. Particularly the Web services
re-search group: Adel, Amit, Ashok, Ergun, Feng, Leena, Nirmit, Soydan, and Yonghong;
thanks for all the discussions, feedback, and friendly support. Special thanks to Ashok
Mallya for extensive feedback on some chapters. To my advising committee: Drs. Singh,
Vouk, Williams, and Wurman. Thank you for pushing me to my limits and getting the best
out of me. Thanks to Dr. Vouk for asking the tough questions. Thanks to Dr. Wurman
for pointing out how the notion ofhonesty could improve my trust model. In particular, to Laurie Williams, thank you for showing me that working closely with others in computer
science can be more joyful, pleasant, and not to mention more efficient while yielding higher
quality work than otherwise; I thoroughly enjoyed our paper collaborations.
To my advisor Dr. Munindar Singh, where do I start? I owe you so much. Thanks
for teaching me how to do research, to write, and to critically think as a researcher. Your
patience, understanding, challenges, and brilliant mind have had a profound impact on me
and ultimately help me grow into who I am today. I hope one day to be able to repay you
a third of what you willingly and freely gave me. Thank you.
Third, to my family members, beginning with my parents: Claudette and
Pierre-Richard. Your constant reminders of how important an education is, are etched in my
memory; and ultimately, it is the well that I reach for to replenish my drive. To my sisters,
I looked forward to. To my brother Laurent, I have found memories of times spent at
Delmas 83 and fishing in Montrouis. To my godfather Fred, thanks for the frequent phone
conversations and emails reminders that we get to be 31 but once. To my uncle Rony, you
introduced me to computing (with a Mac) when I was 12 and from that day on, I knew what
I wanted to do for the rest of my life. To my uncle Pitchoun, thanks for the calculus lessons
during my first year at Saint-Louis de Gonzague; your unconditional help and patience are
praiseworthy. To my aunts, Sheyla and Evelyn, and to my many cousins, thanks for the
moral support.
Finally, to my grandmother Toye who passed away on December 29th, 2002. I wish
you were here to witness me finishing this degree. Your unwillingness to accept anything
but close to perfection during my high school years at Saint-Louis de Gonzague, in
Port-au-Prince, Ha¨ıti, while also being the most loving and generous person that I have ever known,
Contents
List of Figures xi
List of Tables xiii
List of Listings xiv
1 Introduction 1
1.1 Motivations . . . 3
1.1.1 Problem Scenarios: Use Cases . . . 4
1.1.2 Quality of Service Motivated . . . 5
1.1.3 Why is Service Selection Difficult? . . . 6
1.1.4 Trust and Trustworthiness in Open Environments . . . 7
1.1.5 Autonomic Systems . . . 8
1.1.6 Additional Technical Challenges . . . 9
1.2 Contributions and Evaluation . . . 12
1.2.1 Summary of Contribution . . . 12
1.2.2 Problem Space and Current Approaches . . . 14
1.2.3 Software Engineering . . . 16
1.2.4 Trust and Trustworthiness . . . 18
1.2.5 Autonomic Computing . . . 19
2 Trust and Selection 22 2.1 Service Trust . . . 23
2.1.1 Dimensions of Trust . . . 23
2.1.2 Rational-Empirical Trust Model Assumptions . . . 26
2.2 Service Selection and Binding . . . 29
2.2.1 Mapping the Problem Space . . . 31
2.3 Problem Description . . . 35
2.4 Service Trust Model: Simple Preferences . . . 38
2.4.1 Provider Advertisements and Consumer Preferences . . . 38
2.4.2 Quality Reputation, Provider Honesty, and Trustworthiness . . . 40
2.5 Service Trust Model: Complex Preferences . . . 47
2.5.1 Consumer Utility . . . 49
2.5.2 Quality Relationships . . . 53
2.5.3 New Service Trust Function . . . 55
2.6 Discussion . . . 60
2.6.1 Multiple Quality Utility and Relationships . . . 61
2.6.2 Generic Agent and Service Binding . . . 62
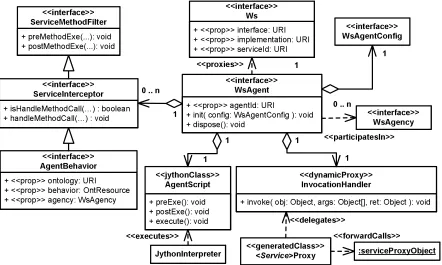
3 Framework 64 3.1 Architecture, Design, and Use of System . . . 65
3.2 Agents and Agencies Design . . . 70
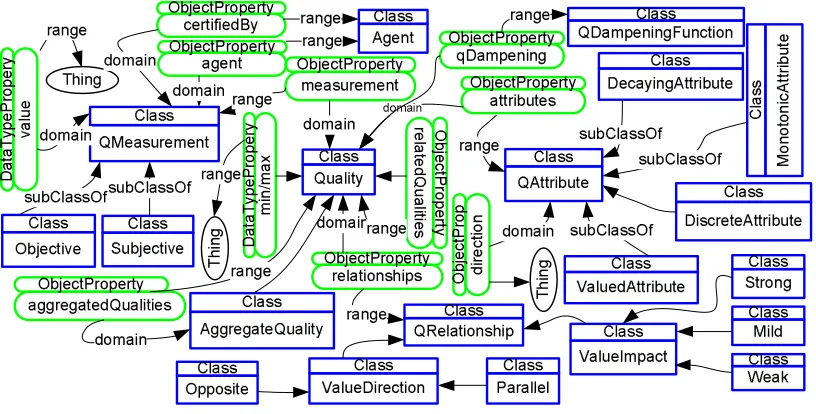
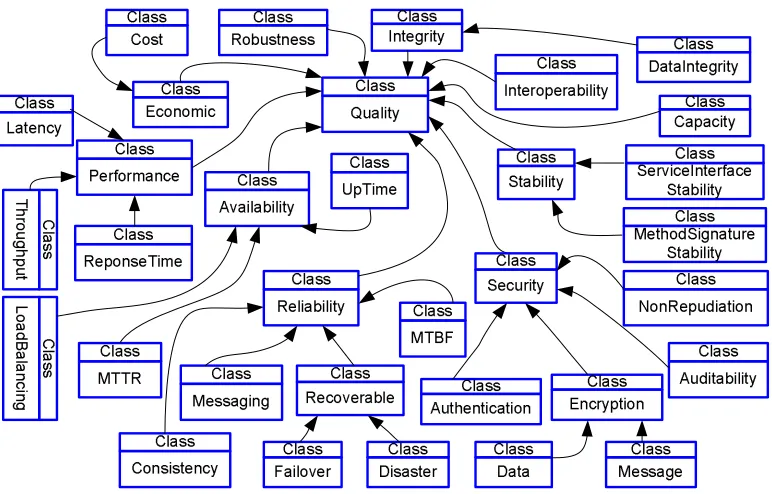
3.3 Knowledge Representation . . . 76
3.3.1 Service Ontology . . . 76
3.3.2 QoS Ontology . . . 77
3.4 Policies . . . 83
3.4.1 Provider Policies . . . 83
3.4.2 Consumer Policies . . . 85
3.5 Matching Algorithms . . . 88
3.5.1 Matching Complex Preferences . . . 94
4 Evaluation 99 4.1 Conceptual Evaluation . . . 99
4.1.1 Trust and Trustworthiness . . . 100
4.1.2 Reputation . . . 102
4.1.3 Autonomy of System . . . 105
4.2 Empirical Evaluation and Expected Results . . . 107
4.2.1 Service Selection: Architecture Comparison . . . 108
4.2.2 Service Selection: Trust and Autonomy . . . 111
4.2.3 Service Selection: Complex Preferences . . . 113
4.2.4 Additional Comparisons . . . 114
4.3 Empirical Results . . . 116
4.3.1 How to Evaluate? . . . 116
4.3.2 Experiment 1: Trust and Autonomy . . . 118
4.3.3 Experiment 2: Self-Adjusting Trust . . . 129
4.3.4 Experiment 3: Complex Preferences . . . 139
4.3.5 Experiment 4: Additional Comparisons . . . 150
5 Discussion 155 5.1 Summary . . . 155
5.2 Interaction Styles . . . 157
5.2.1 Catalogue . . . 158
5.2.2 Examples . . . 165
5.3 Literature . . . 168
5.3.1 Quality of Service in Software Engineering and in Web Services . . . 169
5.3.3 SOA, Web Services, and Semantic Web Services . . . 179
5.3.4 Autonomic Computing, Decision Theory, and Multiagent Systems . 180 5.4 Remaining Challenges . . . 181
5.4.1 Standardization . . . 182
5.4.2 Technical . . . 183
5.5 Directions . . . 186
5.5.1 Malfeasant Agents . . . 186
5.5.2 Service Provider Agents . . . 187
5.5.3 Local Trust Model . . . 187
5.5.4 Keystone Consumers and Providers . . . 188
A System 189 A.1 UML Extensions . . . 189
A.2 System Hardware and Software Platform . . . 189
B Experiments 194 B.1 Experiment 1: Trust and Autonomy . . . 194
B.2 Experiment 2: Self-Adjusting Trust . . . 195
B.3 Experiment 3: Complex Preferences . . . 195
List of Figures
2.1 Service instance usage lifecycle . . . 30
2.2 Dynamic service selection and binding spectrum . . . 33
2.3 Linear consumer quality utility . . . 50
2.4 Sigmoid (s-curve) consumer quality utility . . . 51
3.1 Agents and agencies in a service-oriented architecture . . . 66
3.2 Architecture overview . . . 67
3.3 Typical agent usage control flow . . . 69
3.4 Agent design . . . 71
3.5 Agent UML static class diagram . . . 73
3.6 Agency design . . . 75
3.7 Service ontology . . . 77
3.8 QoS upper ontology . . . 78
3.9 QoS middle ontology . . . 80
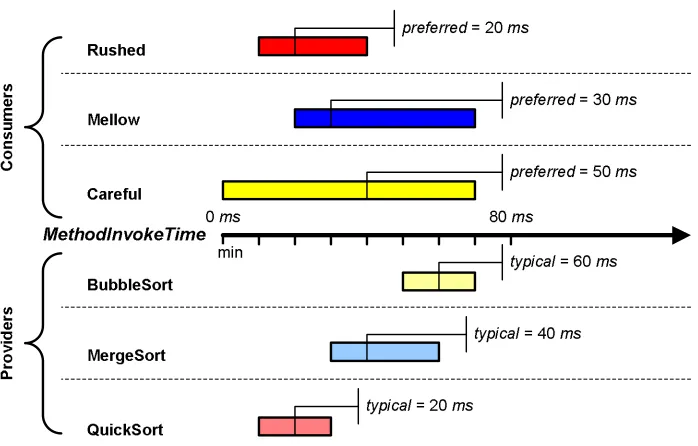
4.1 Integer SortService interface and implementations’ static class diagram . . . 120
4.2 MethodInvokeTime, MethodFaultRate, and PercentAvailability with respect to middle ontology qualities . . . 122
4.3 MethodInvokeTime consumers’ QoS preferences and providers’ advertisements123 4.4 MethodFaultRate consumers’ QoS preferences and providers’ advertisements 123 4.5 PercentAvailability consumers’ QoS preferences and providers’ advertisements 124 4.6 Selection without doping and without agency data (Simulation 1.0) . . . 125
4.7 Selection with full doping and without agency data (Simulation 1.1) . . . . 126
4.8 Selection with full doping (Simulation 1.2) . . . 127
4.9 Selection with delayed full doping (Simulation 1.3) . . . 128
4.10 Selection with delayed half-service doping (Simulation 1.4) . . . 129
4.11 Full service doping and no explorer agents (Simulation 2.0) . . . 134
4.12 Full doping, stop doping after six selections, and no explorer agents (Simu-lation 2.1) . . . 134
4.13 Full doping and three explorer agents (Simulation 2.2) . . . 135
4.15 Full service doping stopped after six and three explorer agents with 5000 ms execution frequency (Simulation 2.4) . . . 136 4.16 Full service doping stopped after six and three explorer agents with 4500 ms
execution frequency (Simulation 2.5) . . . 137 4.17 Three explorer agents with full service doping stopped after six selections
and restarted after 15 (Simulation 2.6) . . . 138 4.18 LoanService interface and implementations’ static class diagram . . . 140 4.19 QoS lower ontology for the LoanFinancing domain . . . 141 4.20 Baseline LoanServiceselection with simple consumer preferences (Simulation
3.0) . . . 144 4.21 Selection for varying quality relationships (Simulations 3.1, 3.2, and 3.3) . . 145 4.22 Selection for implementations of varying quality relationships and consumer
quality preference weights: {1,12,13}(Simulation 3.4) . . . 146 4.23 Selection for implementations with dopings: {WP, WP, MP, MP, SP}and
without explorer agents (Simulation 3.6) . . . 147 4.24 Selection for implementations with dopings: {WP, WP, MP, MP, SP}and
with explorer agents (Simulation 3.7) . . . 149 4.25 Selection for implementations with dopings: {WP, WP, MP, MP, SP}and
quality reputation calculation using simple average (Simulation 4.0) . . . . 151 4.26 Selection for implementations with dopings: {WP, WP, MP, MP, SP}and
quality reputation calculation using dampening function: d(t) = t(qq) forLF
and IR (Simulation 4.1) . . . 152 4.27 Selection for implementations with dopings: {WP, WP, MP, MP, SP}and
quality reputation calculation using dampening function: d(t) =q ×2−t(q) forLF and IR (Simulation 4.2) . . . 154 5.1 IS1: Direct consumer-to-provider interaction style . . . 158 5.2 IS2: Consumer-to-provider intermediary service agent interaction style . . . 160 5.3 IS3: Provider intermediary service agents . . . 161 5.4 IS4: Consumer-to-provider intermediary service agent interaction style with
referrals . . . 162 5.5 IS5: Consumer and provider intermediary service agents interaction style . 163 5.6 IS6: Consumer and provider intermediary service agents interaction style
with referrals . . . 164 5.7 IS1–6: Summary of Web services interaction styles, showing how they build
on each other. . . 164
A.1 WSAF software components logical view . . . 191
List of Tables
2.1 Details of a consumer’s quality utility function . . . 51
2.2 Examples of ontological and statistical quality relationships . . . 55
4.1 Experiment 1: simulations basic common parameters . . . 118
4.2 Experiment 1: simulations secondary parameters . . . 119
4.3 Providers number assignment (doped and clean) . . . 120
4.4 Experiment 2: simulations’ explorer agents parameters . . . 132
4.5 Experiment 2: simulations’ doping policy parameters . . . 133
4.6 QoS relationships for the LoanFinancing domain . . . 142
4.7 Experiment 3: simulations’ secondary parameters . . . 143
4.8 Experiment 4: simulations’ secondary parameters . . . 150
5.1 Summary of Web services consumer-to-provider interaction styles . . . 159
A.1 UML stereotype extensions . . . 190
A.2 Simulation hardware platform details . . . 192
A.3 Simulation service providers’ software platform details . . . 192
A.4 Simulation service consumers’ software platform details . . . 192
A.5 WSAF agents’ software platform . . . 193
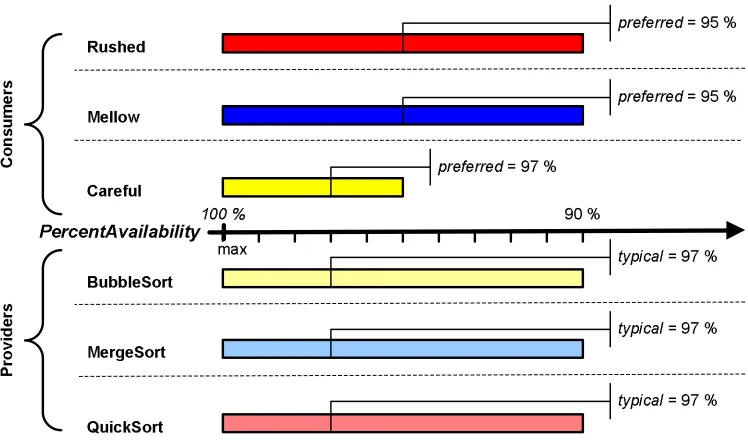
B.1 Careful consumers’ policy . . . 195
B.2 Mellow consumers’ policy . . . 195
B.3 Rushed consumers’ policy . . . 197
B.4 BubbleSort services’ policy . . . 197
B.5 MergeSort services’ policy . . . 197
B.6 QuickSort services’ policy . . . 197
B.7 Full-doping . . . 197
B.8 Delayed half-service doping . . . 198
B.9 LoanService dopings (part 1) . . . 198
B.10 LoanService dopings (part 2) . . . 198
B.11 LoanService consumers’ QoS preferences . . . 198
B.12 LoanService provider’s advertisement . . . 199
List of Listings
3.1 Provider advertisement policy example . . . 84
3.2 Consumer preferences policy example . . . 87
3.3 Matching algorithm . . . 88
3.6 Extended consumer preferences policy example . . . 96
3.7 Extended semantic matching algorithm . . . 97
B.1 SortServiceAgentExplorer round-robin selection algorithm . . . 199
B.2 SortService explorer agent’s script . . . 200
Chapter 1
Introduction
The Web services architecture, set of standards, and technologies support
describ-ing, finddescrib-ing, and binding to services. This initial standards work is necessary to provide
for the development of software systems that can function in open settings. We share the
overarching vision of many in this research area that in open settings, services would be
dynamically created and administered, and would be incorporated into working software
systems without the need for frequent human intervention. Indeed, this vision is one of the
charms of the service-oriented architecture (SOA). Although current Web services standards
and technologies are necessary to realize this vision, they are far from sufficient.
In simple terms, between the finding and the binding steps lies another crucial step,
which is not fully considered by current approaches. This is the step ofselection wherein a desired service instance is chosen by a prospective consumer. Conceptually, service selection
is difficult due to the main challenge of an open environment: the consumer cannot easily
arises partly because the consumer may not be able to trust the service or its provider,
and partly because the consumer lacks the knowledge of the environment within which the
service is executing. For instance, an otherwise trustworthy service may be overwhelmed
with local load and thus suffer from a degradation of quality (see Section 2.1.2 for our trust
definitions).
We distinguish three separate distinct phases of consumer-to-service interactions.
Service discovery. When a consumer finds a desired service interface. This search is typ-ically based on common service repositories such as Universal Description Discovery
and Integration (UDDI).
Service selection. When a consumer selects a service instance (implementing a discovered interface). Selection is based on nonfunctional attributes such as QoS and trust. A
service instance may be replaced by another at runtime if it no longer meets the
consumer’s needs, if it becomes untrustworthy, or if a better instance is found.
Service binding. When a consumer begins using a selected instance. Binding typically
occurs at the time of first need.
The binding phase can also lead to more dynamic interactions such asrebinding. Rebinding occurs at runtime if the consumer decides to unbind with the current service
instance and start the selection process anew. The decision to unbind and reselect could be
due to the consumer’s QoS needs not being met by the current service instance or due to a
lack of trust in the service provider, e.g., if the current service invocation fault-rate reaches
other available service instances that potentially better match its needs or for which it has
a higher level of trust.
1.1
Motivations
To provide a solution for the service selection and the subsequent dynamic binding
challenges, we propose an open multiagent system that facilitates these tasks on behalf of
the service consumers. Conceptually, these agents create an open community of service
helpers acting on behalf of the consumers. They interact and share information to achieve
the best service selection for their consumers. They do so based on each consumer’s
qual-ity preferences policy. Additionally, the agents provide dynamic selection and binding of
services by allowing the consumers to specify additional policies for reselection and
rebind-ing and by monitorrebind-ing the consumer’s service interactions and initiatrebind-ing a reselection and
rebind as the policies are violated.
We further motivate the selection and binding problems and propose a solution by
first illustrating two use cases. We then discuss the use of QoS as an important nonfunctional
service characteristic that leads to better service selection and higher levels of trust between
service consumers and providers. Next, we give a brief discussion of our hypothesis that:
A desirable emergent property isself-adjusting trust between the interacting par-ties.
Finally, we terminate our motivations with an outline of some additional key
1.1.1 Problem Scenarios: Use Cases
Consider the following two use cases to motivate our solution:
1. Business-to-consumer (B2C) search service: A user is searching the Web for goods
or services. The user application employs Web search engines’ services to execute
the user’s query and chooses one of the services based on the preferences of the user
along with the search words. The search application uses a service agent for each
search service interface and at runtime based on the query input and the consumer’s
preferences, the agent picks the “best” search service implementation to execute the
query.
2. Business-to-business (B2B) loan service: A car dealership provides financing to its
potential buyers. Because the dealership wants to offer various financial options,
it does not have any fixed relationships with any banks. Instead, it selects loan
services based on the quality reputations of the available loan services, aggregated
from previous user episodes. Briefly, the dealership financing software uses a service
agent, which it instantiates for each loan service interface and for user episode. Using
the business policies and user preferences, the agent selects the most appropriate
service implementations and presents the top alternatives to the user.
Maximilien and Singh [2004a] discuss another comprehensive scenario involving
1.1.2 Quality of Service Motivated
Representationally, the key idea behind our work is to adorn service descriptions
with QoS annotations. These augmented descriptions, however, would not be produced
by the service providers but would, in essence, be developed by the service consumers.
Instead of the service consumers working individually, which would limit their effectiveness
in judging only those service instances with which they have directly interacted, it is helpful
for them to share their knowledge about the service instances. However, QoS knowledge
cannot be easily shared because it is based on the judgments of the various participants,
which can be subjective. A simple, practical way to reduce the effect of the potential
arbitrariness of individual consumers is to aggregate the consumers’ judgments into general
opinions. The twin design goals of sharing and aggregation can be satisfied through the
mechanism of anagency [Singh and Huhns, 2005].
Agency. A rendezvous node in the system where agents are able to share information
about services.
To facilitate the representation of QoS knowledge, we formulate an ontology for
QoS, that includes a categorization of the various attributes that may apply to a given
service. Some QoS attributes are general enough as to apply across multiple domains.
Examples of these QoS are the average request-response time of a service, its failure or
fault-rate, and its availability. Other QoS attributes can be highly domain-specific. An
example for Web search services is the average number of search elements returned per
The set of QoS attributes not only depends on the domain but also changes
dy-namically as consumers come up with new needs. Consequently, a practical approach to
QoS-based service selection cannot hard code the attributes that it would consider. To
max-imize dynamism, our approach enables capturing the consumer’s needs and QoS attributes
for a service instance after each consumer episode.
1.1.3 Why is Service Selection Difficult?
Current techniques for publishing and finding services rely upon descriptions of
the interfaces of the services. There is a challenge of ensuring that the service instances
(or implementations) comply with the interface but this challenge is mitigated by two
main considerations. Service development tools can generate the service interfaces based
on the implementations, and service consumers can generate the necessary programming
APIs from the service interfaces. And, when services are selected by humans, they can
ensure—via out-of-band communication if necessary—that the selected services will behave
as expected. The noted techniques are sufficient because service interfaces are discrete and
because humans are involved at critical steps. Current matchmaking techniques, which
are based on Semantic Web technologies, help fine-tune the service interfaces and support
matching them based on richer knowledge structures [Sycara et al., 2003].
However, when we consider service selection broadly in terms of QoS, the problem
is more difficult. QoS cannot readily be described via an interface because often the key
aspects of QoS depend on how, by whom, and where a given service is instantiated. In many
cases, the QoS requirements for a particular consumer might be known only to the consumer
have a specificQoS profile orQoS policy.
The solution we propose involves an agent-based architecture that overlays current
Web services architecture. The agents represent both service consumers and providers. The
agents capture the consumers’ requirements for quality and share information about service
providers and implementations to help the consumers converge upon the providers and
implementations that best match their QoS profiles. Chapter 3 discusses our architecture
in details.
1.1.4 Trust and Trustworthiness in Open Environments
As discussed above, the selection phase involves making a rational selection
de-cision between many providers and their service implementations. If a service provider
has already been determined to be trustworthy, then the selection phase becomes one of selecting the provider’s service implementation with the highest level of trust. Naturally, determining the level of trust to assign to a provider and to its service implementations is
nontrivial, especially in open environments. We are specifically talking about environments
where service consumers and providers are autonomous, that is, free to behave as they
wish; and where there are no central trusted authorities that can act as brokers of trust.
In our view, trust is derived from the provider’s reputation for qualities and is subject to
the consumer’s quality needs. Section 2.1.2 defines our use of trust and trustworthiness and
Sections 2.4 and 2.5 describe our trust model.
Our proposed framework provides a solution to this trust problem by having agents
collect and share information about their interactions with the service implementations that
establishing trust. Specifically, it allows agents to determine a service implementations’
reputations for qualities.
Service quality reputation. The aggregation of collected quality data for a given quality exposed by a service implementation.
Since the quality of service will change over time, it is also necessary that the
quality reputation calculation take these changes into account. Following Zacharia and Maes
[2000], we dampen the quality reputation so that recent data matters more in determining
reputation. We resolve the dampening factors for a quality from the shared QoS ontology.
Combining the calculated quality reputation with the consumer’s QoS preferences
and a provider’s QoS advertisement for a service implementation, our service agent is able
to intelligently assign a trust level to the set of available services implementations.
1.1.5 Autonomic Systems
An important characteristic of automatic selection by using trust in open
environ-ments, such as the Web, is that trust should be self-adjusting. That is, service implemen-tations that behave incorrectly should (in essence) be purged from the system by virtue
of not being selected. Poor service implementations should accumulate a low reputation.
Conversely, when a once awry service implementation starts to behave correctly, we would
like the agents to increasingly consider it for selection. This dynamic and self-adjusting
consideration of trust for selection matches the goals of autonomic computing [Kephart and
Chess, 2003].
levels of trust between the interacting parties are dynamically established and adjusted
to reflect recent interactions.
Handling service selection and binding in open environments presupposes
self-adjusting trust.
1.1.6 Additional Technical Challenges
With the addition of agents to SOA, our proposed solution raises various additional
technical challenges ranging from agent programming and design, to knowledge engineering
and dissemination. We consider some of the more pressing challenges in the following:
• First, programmers employing our framework must be able to incorporate service
agents into their applications and assert policies to customize their agent. Current
SOA tools (e.g., IBM’s Websphere Application Developer) allow developers to point
to a service interface [WSDL, 2001] and automatically generate proxy objects for
the described service. With our framework, since the agents are exposed as Web
services, the same steps can be applied for programming the consumers. However,
the consumers use the augmented service agent interface to communicate their policies
and provide feedback to the agent.
• Second, the agents should be extensible; that is, it should be relatively straightforward
to extend the capabilities of a service agent with new behaviors.
• Third, consumer applications need to communicate their selection policies to their
providing a shared conceptualization of the domain is addressed via ontologies
[Gru-ber, 1993; OWL-S, 2004]. Consumer policies are captured using a policy language
with a QoS ontology as the basis for the policy assertions. The service agents make
their decisions using these assertions along with the inferences from the ontology.
• Fourth, assuring secure interactions between consumers and their agents and between
the agents in a manner that retains the openness of the environment remains an
important problem. Solving some of these security issues amounts to using common
security facilities currently available for the Internet, such as public and private key
in-frastructures (PKIs) and the use of message digests to prevent information tampering.
However, these approaches are no panacea since there are approaches to circumvent
and present new threats to the interactions, e.g., the use of PKIs imply the need
for identity sharing which means that fake identities become a problem along with
needing identity management that can scale. Wong and Sycara [2000] discuss security
issues for open multiagent systems (MAS) and give a sketch of an initial design of a
security infrastructure for MAS that could be used to extend our framework.
• Finally, to achieve service selection for the open environment of service consumers and
providers, we will assume that the selection and trust architectures have the following
desirable traits:
1. Maintain autonomy of consumers and providers. The architecture should never
impose constraints on the consumers or providers that limit their autonomy.
For instance, we consider always requiring contractual agreements between
and therefore an architecture that requires such agreements does not fully meet
our autonomy trait.
2. No centralized management. Similar to the autonomy of consumers and providers,
open environments by definition do not have centralized control.
3. Fast runtime selection. To allow runtime selection of services that can be used
in applications for human-facing applications, the system’s selection algorithm
should be computationally tractable. Consumers will have some limits to the
time that they are willing to wait for service selections to occur. The architecture
must take these limits into account and the selection must be possible within their
bounds.
4. Ability to adjust selection at runtime. Since the environment is open, new service
providers and implementations better matching a consumer’s preferences could
become available. It is therefore important that consumers be able to adjust
their service selections (reselection and rebind).
5. Improvement of selection decisions over time. Since the agents are able to share
their experiences, over time, they should be able to improve their selection
deci-sions.
6. Scale on the Web. The Web is vast and expanding daily. To be useful on the
1.2
Contributions and Evaluation
Our primary contribution is a comprehensive agent-based trust framework for
service selection in open environments. We introduce a policy language to capture service
consumer’s and provider’s quality policies, algorithms to select services based on those
policies, and representations to dynamically capture data about service performance with
respect to various (customizable) QoS dimensions. As a result, service-based applications
are dynamically configured at runtime to choose the “best” service implementations with
respect to each participant’s preferences. We demonstrate the effectiveness of this approach
in selecting good services via simulation experiments.
1.2.1 Summary of Contribution
The main focus of this dissertation is to apply decision theory for Web services
selection automation. That leads to works on preference or utility theory, on social and
economic trust models, and on decision theory. Some of these theories and models are used
to help derive decision models for business environments [Bell et al., 1988, pp. 443—463].
Briefly, humans are often not rational when it comes to making complex decisions;
especially decisions involving multiple attributes, uncertainty, and tradeoffs. The above
theories (utility and decision theories) help rationalize the decision-making process. This
dissertation creates a trust model for services and an agent framework that uses the model
to automate some of the decision tasks (e.g., dynamic selection of service implementations)
on behalf of the SOA architect or designer. The agents are reflex agents [Russell and Norvig,
multi-attribute utility and decision theory [Keeney and Raiffa, 1976]. That is, our agents use the
trust model to make simple, one shot, decisions on which service implementation to select
on behalf of the consumer.
We model the service selection problem as a decision problem and provide a
solu-tion using a service trust model. We determine trust using QoS, service quality reputasolu-tions,
and provider trustworthiness and honesty. We assume that the environment is open, that
is, service consumers and providers are free to enter and leave the system at any time.
Our primary contribution is the trust model, which we evaluate empirically,
pri-marily via simulation experiments. The results show that our solution:
1. Captures simple quality preferences of service consumers and allows their agents to
make automated service implementation selections. The agents use a shared
con-ceptualization of services and QoS; they derive a service provider’s and service
im-plementation’s trustworthiness using the trust model and the collected quality data
evidence.
2. Exhibits self-adjusting trust (in the autonomic computing sense). That is, using the
trust model, service consumers’ agents are able to select the correct service
implemen-tations as the QoS exposed by the service implemenimplemen-tations vary. Good services are
selected and misbehaved ones are purged.
3. Captures complex preferences of service consumers. That is, we adjust the trust model
to account for multiple QoS preferences, multiple quality tradeoffs, and semantic as
well as statistical relationships between qualities.
short summaries of the current work in that area. We then further classify our primary
contributions into three main broad categories: Software Engineering, Trust and
Trust-worthiness, and Autonomic Computing. For each, we outline research questions that we
attempt to answer and our proposed methodology for answering them.
1.2.2 Problem Space and Current Approaches
To give an initial map of the problem space and an overview of current approaches,
we first give a partitioning of the problem space and discuss relevant literature in service
discovery, selection, and binding. Next we discuss relevant literature on trust and
trustwor-thiness and on decision theory that closely relate to our own approach. Section 5.3 gives a
thorough literature survey with comparisons to our work.
The service selection and binding space can be divided into two primary categories:
design-time and runtime. In design-time selection and binding, the application designer or
architect use service registries coupled with service descriptions to select and test binding
to a service. Nonfunctional characteristics are considered during trial and error tests of the
selected services. Newer techniques using richer semantic descriptions of services can help
in the discovery of service interfaces. OWL-S [Sycara et al., 2003] is an example of a rich
service ontology used for semantic service discovery.
The other category, which is of most concern to our work, is runtime service
se-lection and binding. In this case, the service interface is already discovered; however, at
runtime, the service implementations are discovered, selected, and bound to, based on
non-functional service attributes such as QoS. Work in this area encompasses QoS requirements,
2003] gives an overview of the requirements. The QoS UML profiles described in [Aagedal
et al., 2004] and [Cortellessa and Pompei, 2004] are examples of QoS models. Various
bro-kering and middleware architectures [Sheth et al., 2002; Ran, 2003a,b; Tian et al., 2003;
Wohlstadter et al., 2004] have been proposed for using QoS in Web services. Also, in
the realm of Grid Services, QoS is an important characteristic used for differentiating the
available services on the Grid [Al-Ali et al., 2002].
Using QoS for service selection is also proposed by [Ran, 2003a; Tian et al., 2003;
Kalepu et al., 2003; Zeng et al., 2004]; however, while most of these works address some
form of service selection, they do not fully address it adequately for open environments,
such as using trust and reputations and a decentralized multiagent architecture as we are
proposing. Wohlstadter et al. [2004] propose a policy language for advertising the QoS
needs of clients and to allow the middleware to matchmake servers and clients. However,
their work lacks a complete conceptualization of nonfunctional attributes for Web services.
Further, their matchmaking techniques is not geared to enable dynamic evolution of the
QoS exposed by the services, that is, does not address autonomic characteristics.
The Web services literature on trust and trustworthiness neither addresses QoS
directly nor the applicability of trust for dynamic and autonomic service selection. Huynh
et al. [2004] give a framework for trust determination in open systems, as ours, but do
not use QoS conceptualizations to determine the needs of the trustor. Zacharia and Maes
[2000] give a general model for reputations that we extend into the world of Web services
and dynamic service selection.
algorithm; the trust model that they use to make their selection decisions extend the work
by Keeney and Raiffa in decision making with multiple objectives [Keeney and Raiffa, 1976].
1.2.3 Software Engineering
Our framework extends current SOA standards with the addition of agents that
can automate some tasks (e.g., service selection and binding) on behalf of service consumers.
Specific contributions are:
1. Architecture. We provide the architecture and the initial implementation of a
frame-work that extends SOA with agents. As such we contribute to the state of the art in
SOA.
2. QoS ontology. Our agents make use of a shared conceptualization of quality. This
ontology is partially evaluated by using a service selection agent. In itself, this ontology
is also a contribution to the current state of knowledge representation for services as
it could be used for means other than service selection, e.g., service composition.
3. Service selection. Our selection agents make use of a selection algorithm which we
evaluate empirically. The policy language used to express the QoS needs of consumers
and the advertisements of providers is also part of this contribution.
4. Consumer utility. To express consumer’s quality preferences and provider’s quality
advertisements, we have introduced a policy language that makes use of the QoS
on-tology. However, this policy language is not sufficient to account for the full combined
based on [Keeney and Raiffa, 1976, pp. 219—280] that directly considers these
qual-ity relationships which are specified in the QoS ontology and can also be measured
from the collected data. This is a novel approach for determining the quality utility
for service consumers; and our evaluation shows under which circumstances it yields
better results than when such relationships are not accounted for.
Research Questions
Our primary research question in the software engineering category has to do
with extracting structural properties of qualities and accounting for them in consumer
preferences. Specifically,what are quality relationships which, if not considered explicitly in the consumer utility, lead to incorrect service selection?
As a secondary question, we attempt to determine holistically, using our heuristic
evaluation of the framework, the interaction styles between consumers and providers which
lead to the emergence of the system properties of trust and autonomy. In other words,
we attempt to answer the following question: what are some interaction styles between consumers and providers that lead to the emergence of trust and autonomy?
Methodology
To answer the first question we evaluate our agent framework with services whose
qualities are artificially strongly correlated—e.g., by doping multiple qualities of the
ser-vice implementations during the same invocation sequence, thus forcing specific quality
relationships for some of the available service implementations. We then determine what
selection algorithm compared with an improved algorithm which explicitly takes quality
re-lationships into account. Section 4.2.3 gives a detailed account of the planned experiment,
Section 3.5 gives an overview of the algorithm, and Section 4.3.4 exposes our obtained
re-sults. Section 5.2 gives a catalogue of service consumer-to-provider interaction styles that
our framework enables.
1.2.4 Trust and Trustworthiness
The second category of contributions lies in providing a system of trust for services
in an open environment. Specifically, the following are contributions to the state of current
research:
1. Trust model. Our trust model for service selection mimics open autonomous party
interactions. Our experiments show results that are very promising in providing a
solution to the service selection problem.
2. Reputation algorithm. Our assignment of trust and trustworthiness is partly based on
the accumulated reputation of quality data for services. We contribute to reputation
research by first extending current reputation approaches using a shared knowledge
representation (QoS ontology) and by the evaluation of reputation systems in the
world of Web services.
Research Questions
extensions compare, when instead, the basic reputation algorithm is used?
Methodology
We answer this question by comparing our approach with the closest research in
the field. Specifically, we compare conceptually and empirically our improved reputation
algorithm with [Zacharia and Maes, 2000] and [Zeng et al., 2004] algorithms and show the
circumstances under which our improvements results in more appropriate levels of trust
assignments. We know the actual levels of trust since we set our experiments up in a
manner that allows us to have oracle knowledge of the service implementations that should
be trusted and therefore selected. We then empirically compare our reputation model with
the reputation models of [Zeng et al., 2004; Huynh et al., 2004] and show the circumstances
in which our experiments result in better service selection, that is, faster convergence to the
services that we know should be selected since we set them up to have better QoS than the
other services.
Section 4.2.4 gives an overview of the experiment used to answer the comparison
question and Section 4.3.5 summarizes the obtained results.
1.2.5 Autonomic Computing
As motivated in Section 1.1.5, the characteristic of self-adjusting trust is important
for providing a solution to the dynamic service selection and binding problems in open
environments. Our evaluation shows that, indeed, our approach results in a level of dynamic
self-adjusted trust between consumers and providers. We believe this emergent autonomic
art in autonomic computing, which has the overarching goal of achieving systems with
self-management characteristics.
Research Questions
Our initial results for service selection show that the system exhibits autonomic
characteristics in that as services behave incorrectly, they are purged from the selection
consideration of agents. However, what happens when a service starts behaving correctly? When should such services be reconsidered for selection?
Methodology
We propose to add to our agent community some explorer agents whose sole
pur-pose is to explore and evaluate services that have been purged and fallen out of favor of
the current consumers. We expect such additions to yield better autonomic characteristics.
Adding explorer agents to the system also leads to an important secondary set of questions,
which we will empirically provide initial answers to. That is:
1. What is the necessary density of such explorer agents in the entire agent population?
2. What are the levels of activities of explorer agents necessary to allow services that have started behaving correctly to reenter consideration of consumers?
The remaining of this dissertation is organized as follows. Chapter 2 describes our
environment, our trust definitions, the selection problem, and our solutions to the selection
problem. Chapter 3 gives a complete overview of our framework including the design of
Section 3.3.2 gives our quality ontology. Chapter 4 discusses our evaluation which is
com-prised of a conceptual evaluation in Section 4.1 and an empirical evaluation in Section 4.2.
Chapter 5 concludes with a summary in Section 5.1, a thorough literature survey of related
work in Section 5.3, a discussion of remaining challenges in Section 5.4, and an outline of
directions for future research in Section 5.5. Finally, Appendix A gives an overview of our
system’s hardware and software and Appendix B shows the details of the experiments used
Chapter 2
Trust and Selection
The Web services standards, while they are essential to allow some form of
auto-mated access to services on the Web, are mostly geared towards design-time automation and
usage. This may be sufficient for a human doing design-time service selection and
bind-ing but is not appropriate for software agents dobind-ing automatic runtime service selection
and binding. Service descriptions via WSDL are necessary but not sufficient to automate
service selection and binding—they principally lack a means to represent nonfunctional
service attributes. To achieve true runtime integration we need a means to collect
nonfunc-tional information about services and use that information to assign dynamic trust levels
to the service providers and implementations. Such a trust model presupposes additional
2.1
Service Trust
As humans do in real-life situations, the agents in our system need to be able to
make decisions using partial information, limited computational resources, and bounded
time. As such, an agent’s decision process is to derive a trust value for each service instance—taking into account the service provider and the service implementation. Using
this trust assignment, our agent can derive thetrustworthiness of each provider, vis-`a-vis a consumer’s preferences, which then results in a straightforward selection decision. To better
understand the motivations for this approach and the details of the trust and
trustworthi-ness calculations, we briefly discuss the dimensions of trust in our environment, give some
basic assumptions and definitions, and describe our trust model.
2.1.1 Dimensions of Trust
The trustworthiness of a service provider is, in essence, a predictor of quality values
for some future usage of the provider’s service. It is an aggregate value that corresponds
to historical levels of quality of the provider’s services and to how truthful the provider
was in advertising its services’ qualities. Consumers use this value to determine the trust
level to assign to the provider’s services and make selection decisions. In determining
the trustworthiness of a provider’s service, a consumer takes into account its own quality
preferences, its past experiences with the provider’s service, the reputation of the service
for the qualities the consumer considers important, and any endorsements the provider may
Agent’s Trust Attitude
The model described above works well for our environment; however, it is worth
noting that there can be many more dimensions of trust. Let us first consider the
“men-tal attitudes” of the consumer agent in question. We distinguish two orthogonal possible
attitudes for the consumer agent with respect to its notion of trust:
1. Trust neutral. The agent assigns no trust values to a provider or its services. This results in random selection of providers and service instances. However, an advantage
of using a trust neutral agent is that the agent does not spend any resources in its
selection decisions. This attitude is rational when all providers have some a priori
guaranteed QoS levels higher than the agent’s need. For instance, when there is
a Service Level Agreement (SLA) [IBM Corporation, 2003a] in effect for the service
implementations which guarantees the quality levels required by the service consumer.
2. Trust seeking. The agent’s attitude is to seek and build trust with its interacting partners. The agent determines the trust assignment to potential services based on
the following parameters:
• Its own prior experience with the service. This assumes that the agent has
previously selected the service for usage and also kept some quality information
on its experiences. This local information allows the agent to recall how satisfied
it was with the service episode.
have selected and used the service.
• Implicit trust assignments. These areendorsements of providers by trusted third parties. By keeping a set of trusted third parties, the agent can automatically
infer a level of trust for services. This is especially useful for new providers or
when a provider’s service implementations have not accumulated much quality
reputation.
• Provider honesty. How honest is a provider in terms of its services’ quality
advertisements? The more honest a provider, the more a consumer can trust its
advertisements, and the more the provider is trustworthy.
In general, it is also worth noting that our agent’s trust attitudes to achieve service
selection are a form of satisficing [Simon, 1979, p. 3]. That is, our agents try to select the service best matching its current preferences using a trust determination based on its
experiences and the shared collected experiences of other agents. There is no attempt to
find the optimal trusted service (which would result in an optimal match) whether one exist
or not.
Agent’s Trust Environment
The agent’s trust attitude is coupled with the environment in which it lives. That
is, depending on the characteristics of the environment, the agent may decide different
strategies for trust and trustworthiness assignments. We broadly categorize the agent’s
environment using four main dimensions:
system.
2. Shared knowledge. In the form of agreed upon service and QoS ontologies; that is, shared conceptualizations for services and for qualities.
3. Published data. Each agent accumulates quality data for each service usage episode.
This data may or may not be published in common agencies. When the data is
published, it is available to all agents without any distinction. When the data is not
published, it is only available to one agent or a group of agents. Published data is
especially important to determine a service’s quality reputation.
4. Reliability of data. This dimension considers how truthful an agent’s data is and by extension, the shared data among agents. For instance, a malfeasant agent could
participate in an agency and contribute false quality information about services. This
falsified information would then impact the shared data of all agents participating in
that agency.
2.1.2 Rational-Empirical Trust Model Assumptions
The notion of trust is multifaceted and multidimensional. It is therefore important
to make certain assumptions to limit the scope and purpose of our trust model. Since we
are mainly concerned with agents that automate service selection and binding decisions on
behalf of their consumers in the open Web, we make certain simplifying assumptions about
the environment and the agents participating in it, while keeping the resulting environment
compatible with the open Web. These assumptions result in an idealized model but allow
since one of our motivations is that the trust model be self-adjusting in the presence of
dynamically-changing service quality profiles, we tailor our assumptions so as to not prevent
such an environment—retaining the environment’s appeal and applicability to the Web.
Assumption 2.1 (Service Agent Environment). The service agent environment is
open and dynamic, with no central authority.
Our agents have a common purpose: to select the services that best meet their
consumer’ quality preferences. In addition, they also benefit from the shared
conceptualiza-tion of qualities in the QoS ontology. Using this ontology they are able to objectively and
subjectively opine on their experiences with a selected service. These opinions are shared,
which leads us to the next assumption.
Assumption 2.2 (Shared Quality Opinion). The service agents are free to share
opin-ions on service interactopin-ions and this information is accessible to all other agents in the
community.
Agents contribute their subjective and objective quality opinions to common
agen-cies. This also assumes that the necessary infrastructure for the quality agencies is in place
to support the agent’s data contributions and queries. Since the environment is open and
is large-scale, we likewise assume that the agency and its data are scalable.
The shared opinions of the agents allow them to infer trust information on a
service which would have been limited otherwise, since the agent probably has not had
direct experiences with all the members of the set of available services. Further, since
the qualities of a service vary with time, even if an agent had prior experiences with the
opinions, the agents are able to collectively better infer a service’s future quality prospects.
However, a limitation of this approach is that it assumes that the opinions are truthful.
Otherwise, a service provider could deploy agents whose opinions are falsely positive about
its own services, thereby biasing the shared opinions.
Assumption 2.3 (Truthful Service Agents). All participating service agents in the
system are truthful in reporting their quality opinions. That is, they report true assessments
of nonfunctional attributes that they gathered on services that they interact with.
Trust Definitions
With the basic assumptions of our agent community environment in place, we
now give brief definitions for our main trust concepts. Sections 2.4 and 2.5 build on these
definitions to create our trust model.
We begin with a distinction between trust and trustworthiness. Trust represents
values computed from trustworthiness and the agent’s preferences; and trust is used in the
agent’s decision process. Trustworthiness is computed by the agent, but from collected
data, and is used as a means of predicting trust. We further assume that both trust and
trustworthiness values are scaled appropriately to allow them to be added to determine a
composed value.
Provider and Service Trust. A value for predicting the qualities of service—that
mat-ters to a service consumer—for a potential interacting service provider and its service
implementations. Service trust is composed of implicit provider trust, provider and
Provider and Service Trustworthiness. An aggregate trust value for a provider or ser-vice implementation based on past interactions with previous serser-vice consumers. Used
as a predictor of service trust.
Since providers make advertisements for their services’ qualities, it is natural to
consider providers that truthfully advertise their services’ capabilities as more trustworthy
than otherwise. We define provider honesty to account for this factor.
Provider Honesty. Represents how close a provider’s service implementations’ qualities
reputations match its advertised values.
Quality Reputation. An aggregate value for a quality of a service implementation over
time and over many service consumer interaction episodes.
With the above definitions we now take an in-depth look at the service selection
and binding problem and a map of the problem space. Starting in Section 2.4 we revisit
how trust is used to provide a solution.
2.2
Service Selection and Binding
As explained in Chapter 1, we distinguish three phases of interactions between
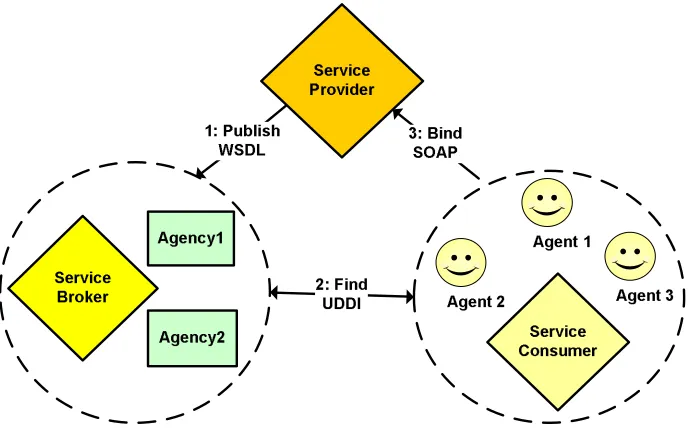
consumers and services: service discovery, service selection, and service binding. Figure 2.1
shows a service instance usage lifecycle, from discovery to binding, and the typical steps in
between resulting from the different types of interactions between service consumers and
Service Interface discovered (unselected and
unbound implementation)
Service discovery Service
implementation selected (unbound) Service selection
Using service ontology and service registries
Using QoS ontology and agencies
Service rebind
Service implementation
bound
Due to failure and using consumer binding preferences for binding decisions
Service binding Service reselection Due to service QoS
falling below some threshold
Typically on first need
Figure 2.1: Service instance usage lifecycle. After service discovery, a service agent selects
the appropriate service implementation based on the trust level associated with the
imple-mentation and the preferences of the consumer. Once a service impleimple-mentation is selected,
it is bound to (typically at the time of first use). Using the preferences of the consumer, the
service agent can dynamically perform service reselection and service rebind—potentially
2.2.1 Mapping the Problem Space
To create realistic agents that can automate design-time concerns, such as service
selection and binding, we need an ontology for services that accommodates quality. The
agents make use of the quality descriptions to capture and share information about services
on behalf of its principal, i.e., the service consumer. In general, we would like to achieve
the following degrees of selection and binding:
• Dynamic selection and binding. Select services and bind at runtime. That is, select and bind to the appropriate service implementation matching the quality needs of
the service consumer at the time of service invocation. By delaying the selection and
binding to the service implementation as late as possible we are in effect allowing all
available service implementations to be considered for usage and integration. In some
cases, the selection and binding occurs at the time of first need (lazy selection and binding).
• Automated selection and binding. Since the selection decision is not hard-coded, as new service implementations with higher quality are introduced (with the right
mech-anisms and QoS data), the agents would discover and potentially select and bind to
such services—assuming they match the quality criteria of the service consumers.
• Reselection and rebinding. Since a service’s implementation quality varies with time and usage, we should expect that there may be a time when the quality levels of an
implementation will fall below the accepted limits of a consumer’s policy. At such
Suchrunfiguration (configuration at runtime) contributes to the overall resilience and autonomy of the system.
Whereas the above kinds of selections and bindings assume that the interface for
the service is constant, and that the selection process selects a matching service
implementa-tion, we should also mention the case where the interface varies. In this case, the consumer
has some prior notion of the service interface or even an exemplar of such an interface. Via
interface matchmaking, the agent finds services supporting the semantics of the required
service and then select and bind to an implementation as described. We term this case
adaptive selection and adaptive binding. This is an extreme case of dynamic selection and binding and we do not consider it in this work. The OWL-S specification was created to
eventually enable such adaptive selection and binding; however, the term used in OWL-S is
semantic matchmaking of services [Trastour et al., 2001; McIlraith et al., 2001]. Also, the OWL-S specification currently focuses only on design-time selection—though, it could be
extended to support some level of runtime selection.
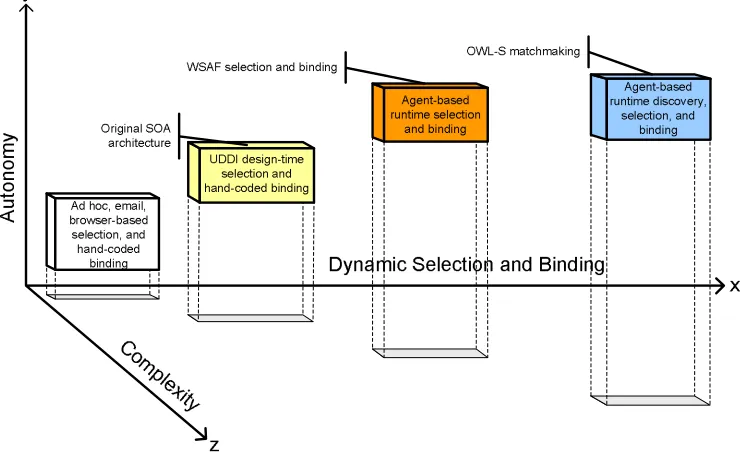
Figure 2.2 maps the space of different types of dynamic service selections and
bindings possible in service-oriented applications. The x-axis shows the levels of dynamism
of the selection and binding, ranging from design-time to runtime. The y-axis denotes
the levels of autonomy, ranging from manual human-selection and binding to automated
agent-selection and binding. The z-axis depicts the perceived complexity for the application
designer. We partition the service selection and binding space into:
Au
ton
om
y
Dynamic Selection and Binding
Agent-based runtime discovery,
selection, and binding Agent-based
runtime selection and binding UDDI design-time
selection and hand-coded binding Ad hoc, email,
browser-based selection, and hand-coded
binding
WSAF selection and binding OWL-S matchmaking
Original SOA architecture
Com
plexity
x
z
y
Figure 2.2: Dynamic service selection and binding spectrum—a map of the dynamic service
selection and binding problem space. The x-axis shows the level of dynamism for service
selection and binding, the y-axis denotes the levels of autonomy, and the z-axis depicts the
perceived complexity by the SOA designer. Our approach is “Agent-based runtime selection