Machine Aided Error-Correction Environment
for Korean Morphological Analysis and Part-of-Speech Tagging
Junsik Park, Jung-Goo Kang, Wook Hur and Key-Sun Choi
C e n t e r for Artificial I n t e l l i g e n c e R e s e a r c hK o r e a A d v a n c e d I n s t i t u t e of Science a n d T e c h n o l o g y T a e j o n 305-701, K o r e a
{ j s p a r k , j g k a n g , h o o k , k s c h o i } @ w o r l d . k a i s t . a c . k r
Abstract
Statistical m e t h o d s require very large corpus with high quality. But building large and fault- less a n n o t a t e d corpus is a very difficult job. This paper proposes an efficient m e t h o d to con- struct part-of-speech tagged corpus. A rule- based error correction m e t h o d is proposed to find and correct errors semi-automatically by user-defined rules. We also make use of user's correction log to reflect feedback. E x p e r i m e n t s were carried out to show the efficiency of error correction process of this workbench. The re- sult shows t h a t about 63.2 % of tagging errors can be corrected.
1
Introduction
N a t u r a l language processing system using cor- pus needs the large a m o u n t of corpus (Choi et al., 1994), but it also requires the high quality.
T h e process of making the general a n n o t a t e d corpus can be viewed as Figure 1. T h e r e are some difficulties in processing tile a n n o t a t e d corpus. First, the n u m b e r of items in a dictio- n a r y is not so large. T h e second problem is in the difficulty of modifying the errors p r o d u c e d by a u t o m a t i c tagging. Manual error correction would require large a m o u n t of costs, a n d there m a y still r e m a i n errors after correcting process. T h e r e were also researches a b o u t a u t o m a t i c cor- rection, b u t t h e y had problems a b o u t t h e side- effects after a u t o m a t i c error correction (Lee and Lee, 1996; Lim et al., 1996).
In this paper, we will integrate the morpho- logical analysis and tagging, and provide inter- active user interface. User gives the feedback to resolve the ambiguities of analysis. To re- duce the cost and improve the correctness, we have developed an environment which is enable to find errors a n d modify them.
In the following section, related works are de- scribed. In section 3, we propose our model. Then, i m p l e m e n t a t i o n and experiment results are explained. Finally, discussion is followed.
2
Related Works
An a u t o m a t i c tagging is prone to errors t h a t cannot be avoidable due to the lack of over- all linguistic information. To model the au- t o m a t i c error-detection process, the statistical approach of detecting tagging error has been developed (Foster, 1991). In this section, we will describe some approaches about rule- based error correction m e t h o d for Korean part- of-speech(hereafter, " P O S " ) tagging system.
2.1
Transformation-Based
Part-of-Speech Tagging System
(Lira et al., 1996) proposed tagging system t h a t uses word-tag t r a n s f o r m a t i o n rules dealing with agglutinative characteristics of Korean, and also extends the tagger by using specific transforma- tion rule considering the lexical information of mistagged word.General training algorithm of the transforma- tion rule (Brill, 1993) is as follows:
1. Train initial tagger on initial training cor- pus Co.
2. Make Confusion m a t r i x with the result of comparing t h e c u r r e n t training corpus
Ci
(initially, i = 0) and C~, the o u t p u t of a m a n u a l a n n o t a t i o n on Co.
3. E x t r a c t rules correcting the errors of Con- fusion m a t r i x best.
4. Apply the e x t r a c t e d tagging rules to the training corpus
Ci
and generate improved versionCi+l.
dOCUmCIII
knowlcdgc
p r o g r a m
A u l o m a l i c e r r o r ¢ o r l e c l i o n j
i
I
1 .~,,,n,~,,¢.or~ ... ,i .... User. /
Figure 1: Process of making part-of-speech tag annotated corpus
6. Repeat steps 2 to 5 until frequency of error correction, which is done by rules found in the previous step, is less than threshold.
2.2 R u l e - b a s e d E r r o r C o r r e c t i o n
This method (Lee and Lee, 1996) is based on Eric Brill's tagging model (Brill, 1993). This tagging system is a hybrid system using both statistical training and rule-based training. Rule-based training is performed only on the statistical tagging errors. The rules are learned by comparing the correctly tagged corpus with the output of tagger. The training is leveraged to learn the error-correction rules.
3 P r o p o s e d M o d e l
3.1 T h e C a u s e s o f P a r t - o f - S p e e c h
T a g g i n g E r r o r
We will mention important causes to make POS tagging errors. The first cause comes from the low accuracy at tagging unknown words, since assigning the most likely tag for unknown words cannot be expected to give a good result. Sec- ond, the linguistic information reflects only the morpheme concatenation, as mentioned in the previous section. Especially, errors occur be- cause of the complex morphological characteris- tics of Korean. Third, the ambiguities of mean- ings cannot be resolved, since tagger would not distinguish them in the morphological level.
3.2 P r o c e s s i n g U n k n o w n W o r d s
Some of the tagging errors come from the un- known word - absence of the word entry in the dictionary. If at least o n e sequence of morpho- logical analysis can produce sequence of mor- phemes registered in the dictionary, the un- known word identification routine does not work even if other sequence contains unknown word. If no sequence is successful, then the system sug- gests the possible POS-tagged unknown words. In our system, if tile morphological analyzer cannot find that all morphemes are in the dic- tionary, unknown words are supposed to be in- eluded in the word. Then, the user adds the unknown words into the dictionary with dictio- nary manager, if any. After adding the words, morphological analyzer is called once again. Be- cause the user adds the identified unknown words into the dictionary, morphological over- analysis can be avoided.
3.3 C o r r e c t i o n o f E r r o r s
[image:2.612.70.433.45.247.2]and manual correction log are necessary for au- t o m a t i c error detection a n d candidate sugges- tion. Rule-based m e t h o d is a way of finding the wrong tags with exact m a t c h using the pre- described rule and suggestion pair. T h e correc- tion rules are in t h e form of:
(< current morpheme>
<current tag> )*/position of wrong mor- I ph.eme or.tag/corrected morpheme or tag I
where • means the repetition. Four kinds of operators can be used in current m o r p h e m e or tag.
• D o n ' t C a r e ( * ) indicates t h a t matching with all m o r p h e m e or tag is p e r m i t t e d . If we replace all t h e tag c~ after n o u n word with tag/3, the rule ' , < noun > * < c~ >
/ 4 / < fi > ' is used.
• Or(I ) allows to m a t c h any one of the ex- pressions. If we replace all the tag c~ after c o m m o n or proper n o u n word with tag/3, the rule ' , < noun > I < propernoun >
, < c ~ > / 4 / < f i > ' i s u s e d .
• C l o s u r e ( W ) m a t c h e s only the content be- fore " + " . If we replace all the tag c~ af- ter c o m m o n n o u n ( t a g g e d as 'non', 'ncpa', 'ncps'), with tag ~, the rule, ' , n c + , <
c~ > / 4 / < / 3 > ' is sufficient.
• N o t (!) matches except expressions follow- ing "!" If we replace all the tag except c~ after n o u n word with tag c~, the rule
~* < noun > *! < c~ > / 4 / < c~ > ' is
used.
For example, the following rule can replace all the tag 'jcs' before the word "~1 ~-(doeda)" with 'jcc'.
'* jcs ~ ( d o e ) pvg / 2 / jcc'
A n o t h e r is the m e t h o d of using m a n u a l cor- rection log. Errors which are not d e t e c t e d by correction rules should be corrected by h u m a n tagger. T h e result of correction is compiled for the next time. Manual log is composed of part of error a n d p a r t of suggestion. For example, w h e n we change " r ~ - ~ ( d a ' u n ) / n c p a " to " ~ ( d a b ) / x s m + ~ - ( n ) / e t m " , the e n t r y will be ' d a ' u n / n c p a , d a b / x s m + n / e t m ' . We can a d a p t the e n t r y to the a u g m e n t e d case, such as ' x ] - ~ ( s a r a m ) / n c n + d a ' u n / n c p a ' , ' ~
:~(hag' gyo ) / n c n + d a ' u n / n c p a ' .
Correction rule can apply to the m a n y kinds of word phrase; while m a n u a l log is concerned a b o u t only one instance of word phrase. W i t h the m a n u a l correction logs, m a n y repetitive er- rors in a d o c u m e n t can be remedied.
4 I m p l e m e n t a t i o n
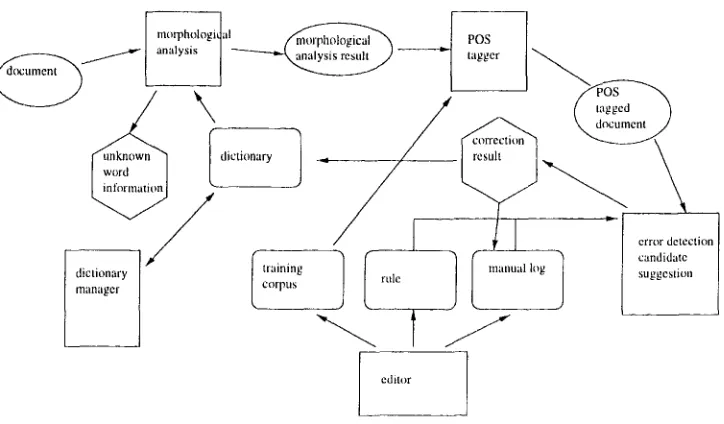
We have i m p l e m e n t e d error-correction environ- ment to provide the h u m a n tagger with t h e interactive and efficient tagging environment. T h e overall s t r u c t u r e of our e n v i r o n m e n t is shown in Figure 2.
T h e process of making P O S - t a g g e d docu- ments in this environment is as follows:
1. Identify u n k n o w n words t h r o u g h morpho- logical analysis.
2. A d d u n k n o w n word to the dictionary.
3. R e p e a t morphological analysis using up- d a t e d dictionary until no m o r e u n k n o w n word is found.
4. R u n a u t o m a t i c P O S tagging.
5. Detect u n k n o w n word error and suggest a correct candidate word.
6. Act according to reaction of h u m a n tagger
- approving modificaton or not, receiving direct input from the h u m a n tagger.
7. R e p e a t steps 5 and 6 with a u t o m a t i c error correction using rules and correction logs so t h a t incremental improvement of tagging accurarcy can be achieved.
8. Correct manually, if there is any error, which is not detected.
9. Save what the h u m a n tagger corrected at step 8, and start detecting errors a n d give suggestion on the P O S - t a g g e d d o c u m e n t , with m a n u a l log.
10. If u n k n o w n word exists in the result from step 9, save the result in t h e dictionary; otherwise, a d d it to the m a n u a l log.
11. R e p e a t steps 8 and 10 until the h u m a n tag- ger finds no error in the P O S - t a g g e d docu- ment.
editor
Figure 2: The Structure of Proposed Environment
;~ F;~I IOl~Jn~ 0 ~ H ~ Po~up
w r l ~ / l l -
.I,f
Figure 3: Tagging Workbench
correction 70 65 60 55 50 45 40 35 30
I I I I I i I
i I I i I i i
document
5 E x p e r i m e n t s and R e s u l t s
We have experimented on the documents, us- ing morphological analyzer and tagger (Shin et al., 1995). The correction log of one document affects the tagging knowledge base. Then, the next tagging process is automatically improved. In the experimental result, error elimination rates are evaluated.
The result of experiment is in Figure 4. In Figure 4, automatic correction means the right correction made by error detection using rule and manual correction log. Manual correction means the correction made directly by user. We can see that the rate of automatic correction increased, while that of manual correction de-
Figure 4: Comparison between automatic and manual correction
creased.
We can correct about 7% of total errors by resolving unknown words. With the increasing number of entries, the probability of unknown word occurrence will decrease.
6 C o n c l u s i o n
[image:4.612.72.434.40.252.2] [image:4.612.303.555.312.454.2] [image:4.612.69.287.312.443.2]analysis, automatic tagging and manual correc- tion. But, manual error correction step requires a large amount of costs.
This paper proposed an environment to re- duce the cost of correcting errors. In the mor- phological analysis process, we have eliminated the errors of unknown words, and find errors with error correction rules and manual correc- tion log, suggesting the candidate words. Users can describe error correction rule easily by sim- plifying the format of error rule. As a result of experiment, about 63.2% of tagging errors were corrected.
Our environment needs further enhance- ments. One is the need of observation on the pattern of errors to make rules so that accuracy may be improved, and the other is the efficient use of manual logs; currently we use pattern matching. More general rules could be found by expressing the manual logs in other ways.
R e f e r e n c e s
E. Brill. 1993. "A Corpus-Based Approach to Language Learning". Ph. D. Thesis, Dept. of Computer and Information Science, Univer- sity of Pennsylvania.
K. Choi, Y. Han, Y. Han, and O. Kwon. 1994. "KAIST Tree Bank Project for Korean: Present and Future Development". SNLP, Proceedings of International Workshop on
Sharablc Natural Language Resources, pages
7-14.
G.F. Foster. 1991. "Statistical Lexical Disam- biguation". M.S. Thesis, McGill University, School of Computer Science.
G. Lee and J. Lee. 1996. "Rule-based error cor- rection for statistical part-of-speech tagging".
Korea-China Joint Symposium on Oriental
Language Computing, pages 125-131.
H. Lim, J. Kim, and H. Rim. 1996. "A Korean Transformation-based Part-of-Speech Tagger with Lexical information of mistagged Eo- jeol". Korea-China Joint Symposium on Ori-
ental Language Computing, pages 119-124.