C r o s s - D o c u m e n t Event Coreference: A n n o t a t i o n s , E x p e r i m e n t s ,
and Observations
A m i t
Bagga
G e n e r a l E l e c t r i c C o m p a n y C R D P O B o x 8
S c h e n e c t a d y , N Y 1 2 3 0 9 b a g g a @ c r d . g e . c o m
5 1 8 - 3 8 7 - 7 0 7 7
B r e c k
Baldwin
I R C S , U n i v e r s i t y o f P e n n s y l v a n i a 3401 W a l n u t S t r e e t , # 4 0 0 C
P h i l a d e l p h i a , P A 1 9 1 0 4 b r e c k @ u n a g i . c i s . u p e n n . e d u
2 1 5 - 8 9 8 - 0 3 2 9
1 A b s t r a c t
We have developed cross document event tracking technology t h a t extends our earlier efforts in cross document person coreference. The software takes class of events, like "resignations" and clusters doc- uments t h a t mention resignations into equivalence classes. Documents belong to the same equivalence class if they mention the same "resignation" event, i.e. resignations involving the same person, time, and organization. Other events evaluated include "elections" and "espionage" events. Results range from 45-90% F-measure scores and we present a brief interannotator study for the "elections" d a t a set.
2
Introduction
Events form the backbone of the reasons why peo- ple communicate to one another. News is interesting and i m p o r t a n t because it describes actions, changes of state and new relationships between individuals. While the communicative importance of described events is evident, the phenomenon has proved diffi- cult to recognize and manipulate in automated ways (example: MUC information extraction efforts).
We began this research program by developing algorithms to determine whether two mentions of a name, example "John Smith", in different docu- ments actually referred to the same individual in the world. T h e system t h a t we built was quite success- ful at resolving cross-document entoty coreference (Bagga, 98b). We, therefore, decided to extend the system so t h a t it could handle events as well. Our goal was to determine whether events in separate documents, example "resignations", referred to the same event in the world (is it the same person re- signing from the same company at the same time). This new c l a s s o f coreference has proved to be more challenging.
Below we will present our approach and results as follows: First we discuss how this research is dif- ferent from Information Extraction and Topic De- tection and Tracking. Then we present the core al- gorithm for cross document person coreference and our m e t h o d of scoring the the system's output. The m e t h o d for determining event reference follows with
presentation and discussion of results. We finish with an interannotator agreement experiment and future work.
3 D i f f e r e n c e s b e t w e e n C r o s s
D o c u m e n t E v e n t R e f e r e n c e a n d I E
and
T D TBefore proceeding further, it should be emphasized that cross-document event reference is a distinct goal from Information Extraction (IE) and Topic Detec- tion and Tracking ( T D T ) .
Our approach differs from both IE and T D T in t h a t it takes a very abstract definition of an event as a starting place, for instance the initial set of doc- uments for resignation events consists of documents t h a t have "resign" as a sub-string. This is even less information than information retrieval evaluations like T R E C . IE takes as an event description large hand built event recognizers t h a t are typically finite state machines. T D T starts with r a t h e r verbose de- scriptions of events. In addition to differences in what these technologies take as input to describe the event, the goal of the technologies differ as well. Information Extraction focuses on mapping from free text into structured d a t a formats like database entries. Two separate instances of an event in two documents would be mapped into the database structures without consideration whether they were the same event or not. In fact, cross-document event tracking could well help information extraction sys- tems by identifying sets of documents t h a t describe the s a m e event, and giving the patterns multiple chances to find a match.
John Perry, of Weston Golf Club, an- nounced his resignation yesterday. He was
the President of the Massachusetts Golf Association. During his two years in of- rice, Perry guided the M G A into a closer relationship with the Women's Golf Asso- ciation of Massachusetts.
Oliver "Biff" Kelly of Weymouth suc- ceeds John Perry as president of the Mas- sachusetts Golf Association. "We will have continued growth in the future," said Kelly, who will serve for two years. "There's been a lot of changes and there will be continued changes as we head into the year 2000."
Figure 2: E x t r a c t from doc.36
I
G
IFigure 3: Coreference Chains for doc.36
tlemen's Association lawsuit against Oprah Winfrey. Given "lawsuits" as an event, we would seek to put documents mentioning t h a t lawsuit into the same equivalent class, but would also form equivalence classes of for other lawsuits. In addition, our even- tual goal is to provide generic cross-document coref- erence for all entities/events in a document i.e. we want to resolve cross-docuemtn coreferences for all entities and events mentioned in a document. This goal is significantly different from T D T ' s goal of clas- sifying a stream of documents into "bins".
4 C r o s s - D o c u m e n t C o r e f e r e n c e f o r
I n d i v i d u a l s
T h e primary technology t h a t drives this research is cross-document coreference. Until recently, cross- document coreference had been thought to be a hard problem to solve (Grishman, 94). However, pre- liminary results in (Bagga, 98a) and (Bagga, 98b) show t h a t high quality cross-document coreference is achievable.
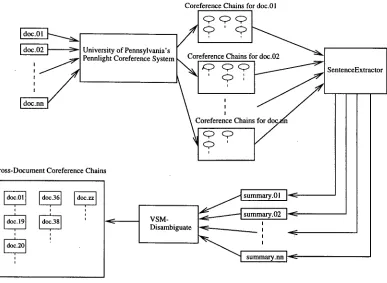
Figure 1 shows the architecture of the cross- document system built. Details about each of the main steps of the cross-document coreference algo- r i t h m are given below.
• First, for each article, the within document coreference module of the University of Penn- sylvania's CAMP system is run on t h a t article. It produces coreference chains for all the enti- ties mentioned in the article. For example, con- sider the two extracts in Figures 2 and 4. T h e coreference chains o u t p u t by CAMP for the two extracts are shown in Figures 3 and 5.
• Next, for the coreference chain of interest within each article (for example, the coreference chain
Figure 4: E x t r a c t from doc.38
J I r
I I I
,
I I
Figure 5: Coreference Chains for doc.38
t h a t contains "John P e r r y " ) , the Sentence Ex- t r a c t o r module extracts all the sentences t h a t contain the noun phrases which form the coref- erence chain. In other words, the SentenceEx- t r a c t o r module produces a "summary" of the ar- ticle with respect to the entity of interest. These summaries are a special case of the query sensi- tive techniques being developed at Penn using CAMP. Therefore, for doc.36 (Figure 2), since at least one of the three noun phrases ( " J o h n Perry," "he," and "Perry") in the coreference chain of interest appears in each of the three sentences in the extract, the s u m m a r y produced by SentenceExtractor is the extract itself. On the other hand, the s u m m a r y produced by Sen- t e n c e E x t r a c t o r for the coreference chain of in- terest in doc.38 is only the first sentence of the extract because the only element of the corefer- ence chain appears in this sentence.
Finally, for each article, the VSM-Disambiguate module uses the summary extracted by the Sen- tenceExtractor and computes its similarity with the summaries extracted from each of the other articles. T h e VSM-Disambiguate module uses a standard vector space model (used widely in in- formation retrieval) (Salton, 89) to c o m p u t e the similarities between the summaries. Summaries having similarity above a certain threshold are considered to be regarding the same entity.
4.1 Scoring
[image:2.612.87.288.166.261.2] [image:2.612.337.523.182.240.2]Coreference Chains for doc.O 1
~
U:~ v ;/; ihtY~[r
P ef:n syl: asnyi~'~
s m Core~nc~hai~for doc.02
~ [
Cross-Document
Coreference Chains
I I
I i
I i
J
t VSM-
I Disambiguate
~
summary.Ol ]
I summary.nn I
Figure 1: Architecture of the Cross-Document Coreference System
uments in the d a t a sets was a b o u t a single entity, or a b o u t a single event, the cross-document coreference chains produced by the system could now be evalu- ated by scoring the corresponding within-document coreference chains in the m e t a document.
W e used two different scoring algorithms for scor- ing the o u t p u t . T h e first was the s t a n d a r d algo- r i t h m for within-document coreference chains which was used for the evaluation of the systems partic- ipating in the MUC-6 and the MUC-7 coreference tasks. This algorithm computes precision and recall statistics by looking at the n u m b e r of links identified by a system c o m p a r e d to the links in an answer key. T h e shortcomings of the M U C scoring algorithm when used for the cross-document coreference task forced us to develop a second algorithm - the B- C U B E D algorithm - which is described in detail be- low. Full details a b o u t b o t h these algorithms (in- cluding the shortcoming of the MUC scoring algo- rithm) can be found in (Bagga, 98).
4.1.1 T h e B - C U B E D A l g o r i t h m
For an entity, i, we define the precision and recall with respect to t h a t entity in Figure 6.
T h e final precision and recall numbers are com- p u t e d by the following two formulae:
N
Final Precision = ~ wi * Precisioni
i=l
N
= ~ wi * Recalli
Final Recall
i----1
where N is the n u m b e r of entities in the document, and wi is the weight assigned to entity i in the docu- ment. For the results discussed in this paper, equal weights were assigned to each entity in the m e t a doc- ument. In other words, wi = -~ for all i.
5
C r o s s - D o c u m e n t
C o r e f e r e n c e for
E v e n t s
In order to extend our systems, as described ear- lier, so t h a t it was able to handle events, we needed t o figure out a m e t h o d to c a p t u r e all the informa- tion a b o u t an event in a document. Previously, with n a m e d entities, it was possible to use the within- document coreference chain regarding the entity to extract a " s u m m a r y " with respect to t h a t entity. However, since C A M P d o e s not a n n o t a t e within- document coreference chains for events, it was not possible to use the same approach.
[image:3.612.121.508.64.347.2]taining one of three pre-specified synonyms to the verb.
T h e new version of the system was tested on sev- eral d a t a sets.
5.1 A n a l y s i s o f D a t a
Figure 7 gives some insight into the d a t a sets used for the e x p e r i m e n t s described later in the paper. In the figure, Column 1 shows the n u m b e r of articles in the d a t a set. T h e second column shows the av- erage n u m b e r of sentences in the s u m m a r y for the e n t i t y / e v e n t of interest constructed for each article. Column 3 shows, for each s u m m a r y , the average n u m b e r of words t h a t were found in at least one other s u m m a r y (in the same d a t a set). T h e condi- tions when measuring the overlap should be noted here:
• the s u m m a r i e s are filtered for stop words • all within-document coreference chains passing
t h r o u g h the s u m m a r i e s are expanded and the resulting additional noun phrases are attached to the s u m m a r i e s
T h e fourth column shows for each such overlapping word, the average n u m b e r of summaries (in the same d a t a set) t h a t it is found in. Column 5 which is the p r o d u c t of the n u m b e r s in Columns 3 and 4 shows, for each s u m m a r y , the average n u m b e r of summaries, in the d a t a set, it shares a word with (the a m o u n t of overlap). We hypothesize here t h a t the higher the a m o u n t of overlap, the higher is the ambiguity in the domain. We will return to this hypothesis later in the paper.
Figure 7 shows t h a t the "resign" and the "espi- onage" d a t a sets are r e m a r k a b l y similar. T h e y have very similar n u m b e r s for the n u m b e r of sentences per s u m m a r y , the average n u m b e r of overlapping words per s u m m a r y , and the average n u m b e r of summaries t h a t each of the overlapping words occur in. A closer look at several of the summaries from each d a t a set yielded the following properties t h a t the two d a t a sets shared:
• T h e s u m m a r i e s usually consisted of a single sen- tence from the article.
• T h e "players" involved in the events (people, places, companies, positions, etc.) were usually referenced in the sentences which were in the summaries.
However, the "election" d a t a set is very different from the other two sets. This d a t a set has almost twice as m a n y sentences per s u m m a r y (2.38). In addition, the n u m b e r of overlapping words in each s u m m a r y is also c o m p a r a t i v e l y high although the average n u m b e r of summaries t h a t an overlapping words occurs in is similar to t h a t of the other two d a t a sets. But, "elections" has a very high overlap
8,
¢: o
O. 100
90 [
80
70
60
50
40
30
20
10
0
Precision/Recall vs Threshold
~.-o"]~', MUC AIg: Precision --o-- j ,,El.,, ' MUC AIg: Recall -~--
-
"+ "'o
MUC AIg: F-Measure -o--\ O..
"o.
" , " 0 ""ET. O . . E ] .
~ k "E] --E}-- O - . 0 . G..E]...0. 0 "
"-I,, " 0
I I I I I I I I I
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Threshold
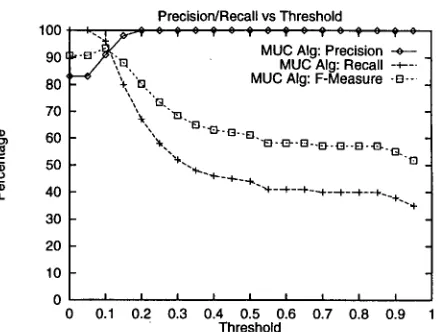
Figure 8: Results for the " J o h n Smith" d a t a set us- ing the MUC scorer
100
90
80
70
g 6o
g_ 4o
30
20
10
0
Precision/Recall vs Threshold
= '"*, Our AIg.~ Precision ',,~, Our AIg: Recall -+---
~ r Ig." F-~easum - o - -
- f :il.
i
\" "'~"~"G--O-
~ - O - - E ] - - ( ~ - El--E}- O. D
I I I I ! I ! I I
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Threshold
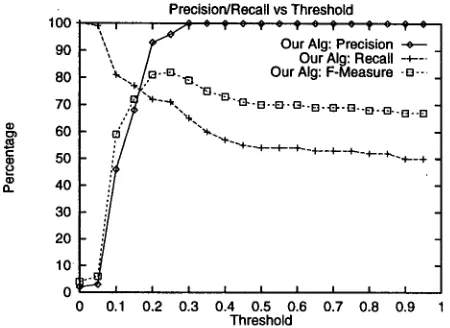
Figure 9: Results for the "John Smith" d a t a set us- ing the B - C U B E D scorer
n u m b e r (22.41) which is a b o u t 30% more t h a n the other d a t a sets. From our hypothesis it follows t h a t this d a t a set is c o m p a r a t i v e l y much more ambiguous; a fact which is verified later in the paper.
Assuming our hypothesis is true, the overlap num- ber also gives an indication of the o p t i m a l threshold which, when chosen, will result in the best precision and recall numbers for the d a t a set. It seems a rea- sonable conjecture t h a t the o p t i m a l threshold varies inversely with the overlap n u m b e r i.e. the higher the overlap number, the higher the ambiguity, and lower the o p t i m a l threshold.
5.2 E x p e r i m e n t s a n d R e s u l t s
We tested our cross-document coreference s y s t e m on several d a t a sets. T h e goal was to identify cross- document coreference chains a b o u t the same event.
[image:4.612.319.538.65.231.2] [image:4.612.317.538.277.438.2]E (D
,o
,?_.
Precision/Recall vs Threshold
100 I I ~ . , , x ^ • ^ , , ,
" . M'~'b ,~lg~Pr~cisio~"~
%N~N /
9O I- m'~('~'~B"r~. MUG AIg: Recall -+---
80 L .,",v/~ ""w,'°"B._ MUC AIg: F-Measure -o--.
L.. 7
",,. -%
7 0 ~ / ~'-, 19.
/ ~ ", " s - . B .
60 I-7 ~',, '~-~.
~ . 'E~'13.. ~.
"4" ---1% "B.
"4~ .+. "O..O
"k" "1" - .,+. ,,{..
50
40
30
20
10
0 I I I I I I I I I
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
T h r e s h o l d
Figure 10: Results for the "resign" d a t a set using the M U C scorer
100
90
80
70
60
50
40
30
20
10
0
(D fl.
Precision/Recall vs Threshold
"'*, ~ Our AIg: Precision
",~,'B--B.~ Our Ale: Recall -+---
m:7 "'~, = ' ~ ' B . . ~ . Our AIg: F-~Aeasure -B--
.,,'? "'i"'"~..,.W. ~ [] ID-O--i~-..O._G..E].,.E}.(3..E )
I I I I ! I I I I
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
T h r e s h o l d
Figure 11: Results for the "resign" d a t a set using the B - C U B E D scorer
• Figure 7 shows, for each d a t a set, the number of articles chosen for the experiment.
• All of the articles in the d a t a sets were chosen r a n d o m l y from the 1996 and 1997 editions of the New York Times. T h e sole criterion used when choosing an article was the presence/ absence of the event of interest in the d a t a set. For ex- ample, an article containing the word "election" would be p u t in the elections d a t a set.
• T h e answer keys for each d a t a set were con- structed manually, although scoring was auto- mated.
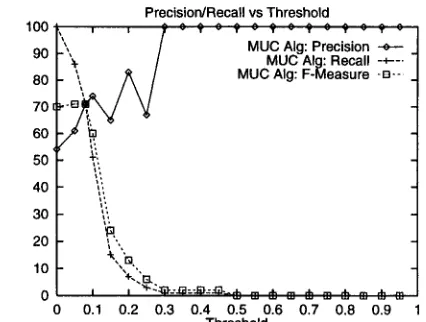
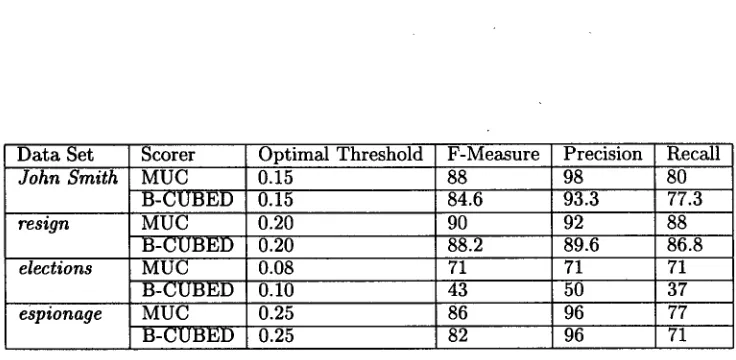
Figure 16 shows for each d a t a set, the optimal threshold, and the best precision, recall, and F- Measure obtained at t h a t threshold.
5 . 3 A n a l y s i s o f R e s u l t s
We had mentioned earlier t h a t we expected the opti- m a l threshold value to vary inversely with the over-
c a) o
$
100
90
80
70
60
50
40
30
20
10
0
P r e c i s i o n / R e c a l l v s T h r e s h o l d
• , , ~ : ; v ;. : ; : ; : ; :
[", f MUC AIg: Precision ~ o
l '~- / MUC AIg: Recall -~-.
I - " A / MUC AIg: F-Measure "B'-
L , i ,
",÷..a
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
T h r e s h o l d
Figure 12: Results for the "elections" d a t a set using the MUC scorer
f:: (1)
p
100
90
80
70
60
50
40
30
20
10
0
Precision/Recall vs T h r e s h o l d
, , ~ : ; : ; . ; : ; : ; o ? o
".', /~ Our AIg: Precision
', ~ / O u r AIg: Recall -+--
- i / ' ~ Our AIg: F-Measure -B---
, , " + - - ~ - ~ : ~ - ' - ' ~ - ' - - ~ . . . ,~ m ,~
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
T h r e s h o l d
Figure 13: Results for the "elections" d a t a set using the B - C U B E D scorer
lap number. Figure 16 verifies this - the o p t i m a l thresholds decline for the "espionage", "resign", and the "election" d a t a sets (which have increasing over- lap numbers). In addition, the results for the "elec- tion" d a t a set also verify our hypothesis t h a t d a t a sets with large overlap numbers are more ambiguous. There are several different factors which can affect the performance of the system. We describe some of the more i m p o r t a n t ones below.
e x p a n s i o n o f c o r e f e r e n c e c h a i n s : E x p a n d i n g the coreference chains t h a t pass t h r o u g h the sentences contained in a s u m m a r y and appending the coreferent noun phrases to the s u m m a r y results in a p p r o x i m a t e l y a 5 point increase in F-Measure for each d a t a set. u s e o f s y n o n y m s : For the "election" d a t a set, the
[image:5.612.329.542.66.227.2] [image:5.612.80.298.66.229.2] [image:5.612.318.539.271.437.2](D
¢1)
o #.
100
90
80
70
60
5 0
40
30
20
10
0 0
Precision/Recall vs Threshold
2 : MUC AIg: Precision -e.--
/~-.s..~ MUC AIg: Recall -+--- "--GI(." ~ - "u'-e~ MUC AIg: F-Measure -s--
J .,¢._..i.i. " .. .. .
"'4, E] [] ID O--O..{D..O..13...O..O.. 0
I I I I I I I I I
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Threshold
Figure 14: Results for the "espionage" d a t a set using the MUC scorer
Precision/Recall vs Threshold
10o
90 ~- " ~: Our AIg: Precision I '~ ] Our AIg." Recall -~-- 80 ~- ~ , . ~ l g : F-Measure -[]--
30 20 10 0
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Threshold
Figure 15: Results for the "espionage" d a t a set using the B - C U B E D scorer
of the system by 3 F-measure points. The re- sulting increase in performance implies that the sentences containing the term "election" did not contain sufficient information for disambiguat- ing all the elections. Some of the disambigua- tion information (example: the "players" in- volved in the event) was mentioned in the ad- ditional sentences. This also strengthens our observation t h a t this d a t a set is more compar- atively more ambiguous.
p r e s e n c e o f a s i n g l e , large c o r e f e r e n c e c h a i n : T h e presence of a single, large cross-document coreference chain in the test set affects the performance of a system with respect to the scoring algorithm used. For example, the "election" d a t a set consisted of a very large coreference chain - the coreference chain consisting of articles regarding the 1996 US General (Congressional and Presidential) elections. This chain consisted of 36 of the 73
links in the d a t a set. T h e B - C U B E D algorithm penalizes systems severely for precision and recall errors in such a scenario. T h e difference in the results reported by the two scoring algorithms for this d a t a set is glaring. T h e MUC scorer reports a 71 point F-Measure while the B-CUBED scorer reports only a 43 point F-Measure.
5.4 T h e "election" D a t a S e t
Since the results for the "election" d a t a set were significantly lower t h a n other results, we decided to analyze this d a t a set in more detail. T h e following factors makes this d a t a set harder to deal with: p r e s e n c e o f s u b - e v e n t s : The presence of sub-
events t h a t correspond to a single event makes the task harder. T h e "election" d a t a set of- ten mentioned election events which consisted of more t h a n one actual election. For example, the d a t a set contained articles which mentioned the 1996 US General Elections which comprised of the US Congressional elections and the US Presidential elections. In addition, there were articles which only mentioned the sub-elections without mentioning the 'more general event. " p l a y e r s " a r e t h e same: Elections is one event
where the players involved are often the same. For example, elections are a b o u t the same po- sitions, in the same places, and very o f t e n in- volving the same people making the task very ambiguous. Very often the only disambiguating factor is the year (temporal information) of the election and this too has to be inferred. For ex- ample, articles will mention an election in the following ways: "the upcoming November elec- tions," "next years elections," "last fall's elec- tions," etc.
d e s c r i p t i o n s a r e v e r y s i m i l a r : Another very im-
p o r t a n t factor t h a t makes the "elections" task harder is the fact t h a t most election issues (across elections in different countries) are very similar. For example: crime rates, inflation, un- employment, etc.
6 I n t e r a n n o t a t o r A g r e e m e n t
When comparing machine performance against a hu- man annotation, it is i m p o r t a n t to u n d e r s t a n d how consistently two humans can perform the same task. If people cannot replicate one other, then there m a y be serious problems with the task definition t h a t question the wisdom of developing a u t o m a t e d meth- ods for the task.
[image:6.612.74.296.65.229.2] [image:6.612.71.296.272.436.2]whatever mutual understanding we had on what the goal of our annotation was from phone calls over the course of a few months. We did not develop an an- notation standard because we have not considered a sufficiently broad range of events to write down nec- essary and sufficient conditions for event coreference. For now our understanding is:
Any two events are in the same equivalence class if they are of the same generic class, ie "elections" or "resignations", and the principle actors, entities, and times are the same.
This definition does not cover the specificity of event descriptions, i.e. the difference between the general November 96 elections and a particular elec- tion in a district (at the same time). We left this decision up to human judgment rather than trying to codify the decision at this early stage.
I n t e r a n n o t a t o r agreement was evaluated in two phases, a completely independent phase and a con- sensus phase where we compared annotations and corrected obvious errors and attentional lapses but allowed differences of opinion when there was room for judgment. T h e results for the completely in- dependent annotation were 87% precision and 87% recall as determined by treating one annotation as t r u t h and the other as a systems o u t p u t with the MUC scorer. Perfect agreement between the annota- tors would result in 100% precision and recall. These results are quite high given the lack of a clear anno- tation standard in combination with the ambiguity of the task.
After adjudication, the agreement increased sig- nificantly to 95% precision and recall which indi- cates t h a t there was genuine disagreement for 5% of the links found across two annotators. Using the B- CUBED scorer the results were 80% for the indepen- dent case and 93% for the consensus phase. These figures establish an upper bound on possible ma- chine performance and suggest t h a t cross document event coreference is a fairly natural phenomenon for people to recognize.
7
F u t u r e R e s e a r c h
The goal of this research has been to gain experience in cross document reference across a range of enti- ties/events. We have focused on simple techniques (the vector space model) over rich data structures (within document coreference annotated text) as a means to b e t t e r understanding of where to further explore the phenomenon.
It is worth exploring alternatives to the vector space model since there are areas where it could be improved. One possibility would be to explic- itly identify the individuating factors of events, i.e. the "players" of an event, and then individuate by comparing these factors. This would be particularly helpful when there is only one individuating factor
like a date that differentiates two events.
The benefit of cross document entity reference centers around nove.1 interfaces to large d a t a collec- tions, so we are focusing on potential applications t h a t include link visualization (Bagga, 98c), question answering, and multi-document summarization. 8 C o n c l u s i o n s
We have shown t h a t it is possible to extend our earlier work with cross document person reference to include cross document event reference. This is achieved by using the vector space model to form equivalence classes of "summaries" a b o u t the events in question. These summaries are generated by in- cluding sentences that have coreference into the core event sentence as well as sentences t h a t fit within a synonymy class for the event in question. Our results are encouraging with performance ranging from 45% f-score to 90% f-score. We also have established that human annotators agree on cross document event reference around 95% of the time.
R e f e r e n c e s
Bagga, Amit, and Breck Baldwin. Algorithms for Scoring Coreference Chains. Proceedings of the Linguistic Coreference Workshop at The First International Conference on Language Resources and Evaluation, May 1998.
Bagga, Amit, and Breck Baldwin. How Much Pro- cessing is Required for Cross-Document Coref- erence? Proceedings of the Linguistic Corefer- ence Workshop at The First International Confer- ence on Language Resources and Evaluation, May 1998.
Bagga, Amit, and Breck Baldwin. Entity-Based Cross-Document Coreferencing Using the Vector Space Model. In Proceedings of the 36th An- nual Meeting of the Association for Computa- tional Linguistics and the 17th International Con- ferende on Computational Linguistics (COLING- ACL'98), pp. 79-85, August 1998.
Bagga, Amit, and Breck Baldwin. Coreference as the Foundations for Link Analysis Over Free Text Databases. In Proceedings of the COLING- A CL'98 Content Visualization and Intermedia Representations Workshop (CVIR'98), pp. 19-24, August 1998.
Grishman, Ralph. Whither Written Language Eval- uation?, Proceedings of the Human Language Technology Workshop, pp. 120-125, March 1994, San Francisco: Morgan Kaufmann.
number of correct elements in the output chain containing entity~
Precisioni =
Recalli =
number of elements in the output chain containing entityi
number of correct elements in the output chain containing entityi number of elements in the truth chain containing entity~
Figure 6: Definitions for Precision and Recall for an Entity i
d a t a set
John Smith
# of articles 197
avg # of sentences per summary 1.16
avg # of overlapping words in summary 2.46
avg # of summaries t h a t overlapping words occur in 5.74
a m o u n t of overlap per s u m m a r y 14.13
resign 219 1.35 4.35 3.99 17.36
elections 135 2.38 5.66 3.96 22.41
1.28
espionage 184 4.57 3.62 16.54
Figure 7: Analysis of the Data Sets
D a t a Set
John Smith
resign
elections
espionage
Scorer MUC B-CUBED MUC B-CUBED MUC B-CUBED MUC B-CUBED
Optimal Threshold 0.15
0.15 0.20 0.20 0.08 0.10 0.25 0.25
F-Measure 88
84.6 90 88.2 71 43 86 82
Precision Recall
98 80
93.3 77.3
92 88
89.6 86.8
71 71
50 37
96 77
96 71
[image:8.612.95.524.113.668.2] [image:8.612.123.491.465.645.2]