P S E U D O P A R S I N G S W I F T - A N S W E R A L G O R I T H M b y
(c) S Pal Asija 19 8 9
Patent A t t o r n e y & Professional Engineer 7 W o o n s o c k e t Ave , Shelton, Conn. 0 6 4 8 4
PH: ( 2 0 3 ) - 7 3 6 - 9 9 3 4 or 7 3 6 - 0 7 7 4
I N T R O D U C T I O N
P s e u d o parsing S W I F T - A N S W E R algorithm is a subset of patented ( 4 , 270 , 182) S W I FT - A N W E R algorithm w h i c h is based on the firstpure software algorithm patent ever issued a n y w h e r e in the world. It is also a federal T r a d e m a r k registered in the principal register of the Unites States Patent a n d T r a d e m a r k Office. It isan a c r o n y m w h i c h stands for Special W o r d Index Full Tex t A 1 ph a N u m e r i c Storage W i t h Easy Retrieval. It is called P s e u d o parsing b e cause it deviates substantially f r o m conventional parsing algorithms, e v e n tho u g h itaccomplishes confusingly similar
objectives. It isnot a software p a c k a g e nor a key w o r d search system.
N O T A K E Y W O R D S Y S T E M
S o m e AI(Artificial Intelligence) experts a n d computational linguists h a v e erroneously perceived this s y s t e m as a k e y w o r d s y s t e m and
therefore h a v e evaluated a n d crticized itas such. But in reality it is not a k e y w o r d system. In fact the s y s t e m n e v e r asks the user for the r -ywords. K e y w o r d s if a n y are automatically created a n d m a n a g e d by this system. It is strictly internal to the s y s t e m a n d therefore completely transparent to the user.
Just as in h u ma n t o h u m a n c o m m u n i c a t i o n s in this h u ma n / ma c h i n e c o m m u n i c a t i o n s y s t e m also, neither the m a c h i n e nor the h u m a n being is conscious of a n y k e y w o r d s . W h e n yo u ask a h u m a n being a question he or she does not ask y o u for k e y words, e v e n t ho ugh the r e s p o n d a n t m a y subconsciously select a n d use s o m e k e y w o r d s to properly r e s p o n d to you. Just as the user does not care w h a t the subconscious of the r e s p o n d a n t does , the user also does not care w h a t the internal software of the s y s t e m does to properly r e s p o n d to the users c o m m u n i c a t i o n s .
B R I E F D E S C R I P T I O N OF T H E D R A W I N G
a) Figure 1 s h o w s the p r o g r a m flow chart of the S W I F T - A N S W E R algorithm.
b) Figure 2 s h o w s the S W I F T - A N S W E R Data Flo D i a g r a m .
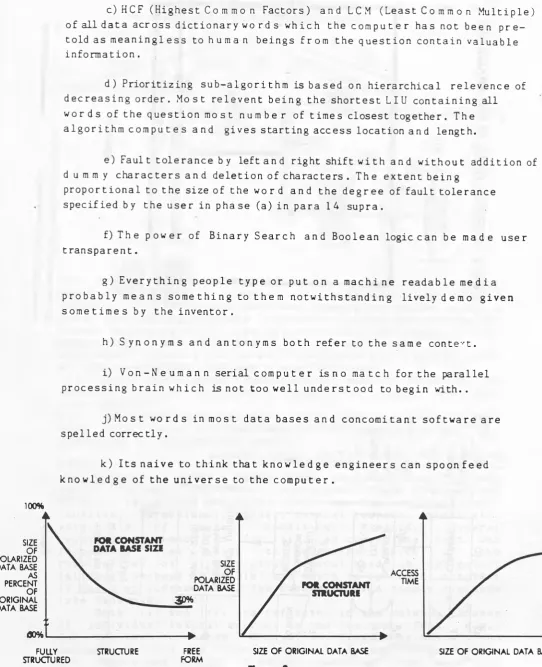
c) Figure 3 s h o w s three p e r f o r m a n c e curves as follows.
(i)Figre 3 (A) m a p s size of the polarizeddata base as a
percentage of the original data base alng the Y axis as the structure of the data base is varied f r o m fully structured to free f o r m along the X axis for a constant data base size.
(ii) Figure 3 (B) m a p s size of the polarized data base along the Y axis as a function of the size of the original data base along the x axis for a
data base of contstant structure.
(ill) Figure 3 (C) s h o w s access time a b o v e a certain threshold is i n d e p e n d e n t of the size of the original data base.
P S E U D O - P A R S I N G A L G O R I T H M
T h e P s e u d o - p a r s i n g S W I F T - A N S W E R algorithm of this invention c o m p r i s e s the -following steps.
a) Separation of a natural language text into senteneces , phrases and words.
b) Separation of W o r d s into non-context an d context words.
c) Separation of non-context w o r d s into noise w o r d s such as p r o n o u n s a n d prepositions a n d c o m m o n w o r d s such as C o m m o n w o r d s a p p e a r i n g too frequently in a file or data base.
d) Alphabetizing all context words.
e) M a p p i n g f r e q u e n c y a n d location of all non-contex t w o r d s with respect to source data original files.
NOTE: T h e a b o v e m e n t i o n e d five steps of the P s e u d o parsing
al gorithm are applied to the natural l a n g u a g e unstructred files in the batch m o d e a n d then again to the s p o n t a n e o u s convoluted questions in the real time m o d e .
f) p e r f o r m i n g m a t h e m a t i c a l operations such as taking highest
c o m m o n factor a n d lowest c o m m o n mu ltiple of the statistical information that c o r r e p o n d s to context w o r d s in the question.
Note: This step in turn generates a lsitof prioritized a n s w e r w h i c h specified that the best a n s w e r based u p o n the totality of this question begins on disc so a n d so , sec to r so a n d so a n d is so m a n y bytes long and the second best a n s w e r begins on disc so a n d so, sector so and so a nd is so m a n y bytes l o n g a n d soon.
g) applying the user transparent boolean logic to different p e r m u t a t i o n s a n d combinations of the c o n t e x t w o r d s in the question.
NOTE: T h e p s e u d o parsing i s c o m p l e t e d at this step. T h e r e m a i n i n g steps described in the patent deal with fetching a n d presenting the right a n s w e r in the right f ormat to the user.
U N I Q U E A L G 0 R I_T H M
T h e algorithm i s u n i q u e c o m p a r e d to the prior art b e c a u s e itisthe only software that r e s p o n d s to a users e r r o n e o u s s p o n t a n e o u s questions primarily b e cause it p e r f o r m s the following user transparent functions automatically.
a) A u t o m a t i c LIUs (Logical Information Units) b) A u t o m a t i c & Unlimited Dictionary.
c) A u t o m a t i c K e y W o r d s d) A u t o m a t i c Boolean Logic
e) A u t o m a t i c Prioritizing of A n s w e r s f) A u t o m a t i c Fault Tolerance
g) A u t o m a t i c Context Deter m i n a t i o n .
h) A u t o m a t i c D B M ( D a t a B a s e M a n a g e m e n t )
Th e following functions a n d features are not automated.
a) Questions & R e f r a m i n g of questions b) Interpretation of A n s w e r s
c) Specification of the U S E R e n v i r o n m e n t
d) Creation of the Un s t r u c t u r e d Source Data Base e) Selection of Special Features
f) Inputting of additional context de pe nda n t c o m m o n w o r d s a nd ' s y n o n y m s & a n t o n y m s ' i e s e a r c h o n y m s .
This u n i q u e algorithm creates the illusion of artificial intelligence without e v e n using a conventional "Spell-Check” dictionary let alone s p o o n feeding rules of parsing, g r a m m a r , p r o g r a m m i n g and k n o w l e d g e of the world. T h e artificial intelligence if a n y in this s y s t e m is inherent in the structure of the algorithm w h i c h m a k e s it ind e pe nd en t of the k n o w l e d g e d o m a n i n of the data base.
F I V E P A H S E A L G O R IT H M
a) Installation phase during w h i c h the c o m p u t e r asks you a series of q ues t ions to get t o k n o w your c o m p u t e r e n v i r o n m e n t an d your
applicational n e e d s including your data bases , so that itcan load appropriate operating s y s t e m , interface mod ul es a n d drivers.
b) Batch P h a s e during w h i c h the algorithm pre-processes each file specified in phase (a) a n d extracts certain things f r o m them.
c) Real T i m e P h a s e during w h i c h the s a m e algorithm is applied to the question as w a s applied to the files in p h a s e (b).
d) Priority phase during w h i c h the prioritizing algorithm ranks all possible a n s w e r s without going to the data base files.
e) Presentation P h a s e during w h i c h the algorithm presents a n s w e r s in the order established in the priority p h a s e (a) s u pra by fetching t h e m f r o m the original files.
P O W E R F U L A L G O R I T H M
T h e p o w e r of the algorithm can be traced to the following precepts a n d principles.
a) All natural languages saturate. As a language saturates a n d the data base g r o w s larger the probability of a n e w w o r d a p p e a r i n g goes d o w n a n d the proabability of a repeat w o r d goes up. T h e length of the index does
not increase although v o l u m e of cross-indexing does.
b) S o m e w o r d s such as m o s t p r o n o u n s a n d propositions do not m e a n m u c h e v e n to people let alone c o m p u t e r s
SW
IFT
-ANS
WER
D
A
TA
FL
O
W
D
IA
G
R
A
M
Cl 2 3
9
i I
£ it
2 a
2
c) H C F (Highest C o m m o n Factors) a n d L C M (Least C o m m o n Multiple) of all data across dictionary w o r d s w h i c h the c o m p u t e r has not been p r e told as m e a n i n g l e s s to h u m a n beings f r o m the question contain valuable information.
d) Prioritizing sub-algorithm is based on hierarchical relevence of decreasing order. M o s t relevent being the shortest L I U containing all w o r d s of the question m o s t n u m b e r of times closest together. T h e algorithm c o m p u t e s a n d gives starting access location an d length.
e) Faul t tolerance b y left a n d right shift with an d without addition of d u m m y characters a n d deletion of characters . T h e extent being
proportional to the size of the wo r d a n d the degree of fault tolerance specified by the user in phase (a) in para 14 supra.
f ) T h e p o w e r of Binary Search a n d Boolean logic can be m a d e user transparent.
g) Everything people type or put on a m a c h i n e readable m e d i a p r o b a b l y m e a n s s o m e t h i n g to t h e m notwithstanding l i v e l y d e m o given s o m e t i m e s by the inventor.
h) S y n o n y m s a n d a n t o n y m s both refer to the s a m e contevt.
i) V o n - N e u m a n n serial c o m p u t e r is no m a t c h for the parallel processing brain w h i c h is not too well u n d e r s t o o d to begin with. .
j ) M o s t w o r d s i n m o s t data bases a n d con c o m i t a n t software are spelled correctly.
k) Its naive to think that k n o w l e d g e engineers can s p o o n f e e d k n o w l e d g e of the universe to the computer.
100%
FULLY STRUCTURE FREE SIZE O F O RIGIN AL DATA BASE SIZE O F O RIG IN AL DATA BASE STRUCTURED FORM
Figure 3