Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 65–79 65
Semantic expressive capacity with bounded memory
Antoine Venant and Alexander Koller Department of Language Science and Technology
Saarland University
{venant|koller}@coli.uni-saarland.de
Abstract
We investigate the capacity of mechanisms for compositional semantic parsing to describe re-lations between sentences and semantic repre-sentations. We prove that in order to represent certain relations, mechanisms which are syn-tactically projective must be able to remem-ber an unbounded numremem-ber of locations in the semantic representations, where nonprojective mechanisms need not. This is the first result of this kind, and has consequences both for grammar-based and for neural systems. 1 Introduction
Semantic parsers which translate a sentence into a semantic representation compositionally must recursively compute a partial semantic represen-tation for each node of a syntax tree. These partial semantic representations usually contain placeholders at which arguments and modifiers are attached in later composition steps. Ap-proaches to semantic parsing differ in whether they assume that the number of placeholders is bounded or not. Lambda calculus (Montague,
1974;Blackburn and Bos,2005) assumes that the number of placeholders (lambda-bound variables) can grow unboundedly with the length and com-plexity of the sentence. By contrast, many meth-ods which are based on unification (Copestake et al.,2001) or graph merging (Courcelle and En-gelfriet,2012;Chiang et al.,2013) assume a fixed set of placeholders, i.e. the number of placeholders is bounded.
Methods based on bounded placeholders are popular both in the design of hand-written gram-mars (Bender et al.,2002) and in semantic parsing for graphs (Peng et al., 2015; Groschwitz et al.,
2018). However, it is not clear that all relations be-tween language and semantic representations can be expressed with a bounded number of place-holders. The situation is particularly challenging
when one insists that the compositional analysis is projective in the sense that each composition step must combine adjacent substrings of the in-put sentence. In this case, it may be impossible to combine a semantic predicate with a distant argu-ment immediately, forcing the composition mech-anism to use up a placeholder to remember the ar-gument position. If many predicates have distant arguments, this may exceed the bounded “memory capacity” of the compositional mechanism.
In this paper, we show that there are relations between sentences and semantic representations which can be described by compositional mech-anisms which are bounded and non-projective, but not by ones which are bounded and projective. To our knowledge, this is the first result on expressive capacity with respect to semantics – in contrast to the extensive literature on the expressive capacity of mechanisms which describe just the string lan-guages.
More precisely, we prove that tree-adjoining grammars can describe string-graph relations us-ing the HR graph algebra (Courcelle and En-gelfriet, 2012) with two sources (bounded, non-projective) which cannot be described using linear monadic context-free tree grammars and the HR algebra withksources, for any fixed k(bounded, projective). This result is especially surprising be-cause TAG and linear monadic CFTGs describe the same string languages; thus the difference lies only in the projectivity of the syntactic analysis.
We further prove that given certain assump-tions on the alignment between tokens in the sen-tence and edges in the graph, no generative de-vice for projective syntax trees can simulate TAG with two sources. This has practical consequences for the design of transition-based semantic parsers (whether grammar-based or neural).
Plan of the paper.We will first explain the
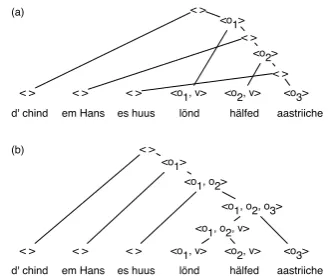
originally had. However, this derivation combines verbs with nouns which are not adjacent in the string, which is not allowed in many grammar for-malisms. If we limit ourselves to combining only adjacent substrings (projectively, see Fig.1b), we must remember the placeholders for all the verbs at the same time if we want to obtain the correct predicate-argument structure. Thus, the number of placeholders grows with the length of the sen-tence; this is only possible with a lambda-style compositional mechanism.
There is scattered evidence in the literature for this tension between bounded memory and projectivity. Chiang et al. (2013) report (of a compositional mechanism based on the HR al-gebra, unification-style) that a bounded num-ber of placeholders suffices to derive the graphs in the AMR version of the Geoquery corpus, but Groschwitz et al. (2018) find that this re-quires non-projective derivations in 37% of the AMRBank training data (Banarescu et al.,2013). Approaches to semantic construction with tree-adjoining grammar either perform semantic com-position along the TAG derivation tree using unifi-cation (non-projective, unifiunifi-cation-style) (Gardent and Kallmeyer, 2003) or along the TAG derived tree using linear logic (projective, lambda-style) (Frank and van Genabith, 2001). Bender (2008) discusses the challenges involved in modeling the predicate-argument structure of a language with very free word order (Wambaya) with projective syntax. While the Wambaya noun phrase does not seem to require the projective grammar to collect unbounded numbers of unfilled arguments as in Fig.1b, Bender notes that her projective analysis still requires a more flexible handling of seman-tic arguments than the HPSG Semanseman-tic Algebra (unification-style) supports.
In this paper, we define a notion of semantic expressive capacity and prove the first formal re-sults about the relationship between projectivity and bounded memory.
3 Formal background
LetN0 = {0,1, . . .}be the nonnegative integers.
Asignature is a finite setΣ of function symbols
f, each of which has been assigned a nonnega-tive integer called itsrank. We write Σn for the
symbols of rank n. Given a signatureΣ, we say that all constantsa∈Σ0aretreesoverΣ; further,
if f ∈ Σn andt1, . . . , tn are trees over Σ, then
f(t1, . . . , tn) is also a tree. We writeTΣ for the
set of all trees overΣ. We define theheightht(t)
of a treet = f(t1, . . . , tn) to be1 + maxht(ti),
andht(c) = 1forc∈Σ0.
LetX /∈ Σ, and letΣX = Σ∪ {X} (withX
as a constant of rank 0). Then we call a treeC ∈ TΣX acontextif it contains exactly one occurrence ofX, and writeCΣ for the set of all contexts. A context can be seen as a tree with exactly one hole. Ift ∈ TΣ, we writeC[t]for the tree inTΣ that is
obtained by replacingXwitht.
Given a string w ∈ W∗, we write|w|a for the number of times thata∈W occurs inw.
3.1 Grammars for strings and trees
We take a very general view on how semantic rep-resentations for strings are constructed composi-tionally. To this end, we define a notion of “gram-mar” which encompasses more devices for de-scribing languages than just traditional grammars, such as transition-based parsers.
We say that a tree grammar G over the sig-nature Σ is any finite device that defines a lan-guage L(G) ⊆ TΣ. For instance, regular tree
grammars (Comon et al.,2007) are tree grammars, and context-free grammars can also be seen as tree grammars defining the language of parse trees.
We say that astring grammarG= (G,yd)over the signatureΣand the alphabetW is a pair con-sisting of a tree grammar G over Σ and a yield function yd : TΣ → W∗ which maps trees to strings over W (Weir, 1988). A string grammar defines a languageL(G) ={yd(t)|t∈L(G)} ⊆
W∗. We call the treest∈L(G)derivations. A particularly common yield function is the function ydpr, defined as ydpr(f(t1, . . . , tn)) =
ydpr(t1)·. . .·ydpr(tn)ifn >0andydpr(c) =c
if c has rank 0. This yield function simply con-catenates the words at the leaves of t. Applied to the phrase-structure tree t in Fig. 2c, ydpr(t)
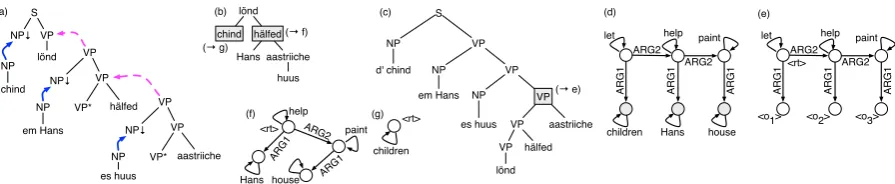
is the Swiss German sentence in (1). Context-free grammars can be characterized as string grammars that combine a regular tree grammar with ydpr. By contrast, we can model tree-adjoining gram-mars (TAG,Joshi and Schabes,1997) by choosing a tree grammarGthat describes derivation trees as in Fig.2b. Theyd function could then substitute and adjoin the elementary trees as specified by the derivation tree (see Fig.2a) and then read off the words from the resulting derived tree in Fig.2c.
stant s-graphs and the rename and forget opera-tions. The class of graphs which can be expressed as values of terms over the algebra increases with
k. We writeHk for the HR algebra withksource names (and some set of edge labels).
LetGbe an s-graph, and let G0 be a subgraph of G, i.e. a subset of its edges. We call a node aboundary nodeofG0 if it is incident both to an edge in G0 and to an edge that is not inG0. For instance, the s-graph in Fig. 2e is a subgraph of the one in Fig.2d; the boundary nodes are drawn shaded in (d). The following lemma holds:
Lemma 2. LetG=JC[t]Kbe an s-graph, and let
G0 be a subgraph ofG such that the s-graphJtK
contains the same edges asG0. Then every bound-ary node inG0 is a source inJtK.
3.4 Grammars with semantic interpretations
Finally, we extend string grammars to composi-tionally relate strings with semantic representa-tions. LetG = (G,yd)be a string grammar. The tree grammarGgenerates a languageL(G)⊆ TΣ
of trees. We will map each tree t ∈ L(G) into a term h(t) over some algebra A over a signa-ture ∆using a linear tree homomorphism (LTH)
h:TΣ→ T∆(Comon et al.,2007), i.e. by compo-sitional bottom-up evaluation. This defines a rela-tion between strings and values ofA:
REL(G, h,A) ={(yd(t),Jh(t)KA)|t∈L(G)}
For instance,Acould be some HR algebraHk;
thenREL(G, h,Hk)will be a binary relation be-tween strings and s-graphs. In this case, we abbre-viateJh(t)Kasgraph(t).
If we look at an entire class Gof string
gram-mars and a fixed algebra, this defines a class of such relations:
L(G,A) ={REL(G, h,A)| G ∈G, hLTH}.
In the example in Fig.2, we can define a linear homomorphismh to map the derivation tree t in (b) to a term h(t) which evaluates to the s-graph shown in (d). At the top of this term, the s-graphs at the “chind” and “h¨alfed” (f,g) nodes are com-bined into (d) byh(l¨ond):
h(l¨ond) =hrti let
||fo(hrti
ARG1
−−→ hoi ||renrt→o(G(f)))
||fo(hrti
ARG2
−−→ hoi ||renrt→o(G(g)))
This non-projective derivation produces the s-graph in (d) using only two sources,rtando. By
a b b
c d d
a a
c
b
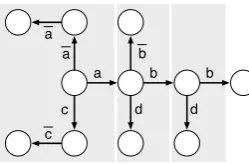
Figure 3: TheCSDgraph for ((2), (1, 0), (1), (0, 0)); blocks indicated by gray boxes.
contrast, a homomorphic interpretation of the pro-jective tree (c) has to use at least four sources, as the intermediate result in (e) illustrates.
4 Projective cross-serial dependencies
We will now investigate the ability of projec-tive grammar formalisms (G,Hk) to express
L(TAG,H2). We will define a relation CSD ∈
L(TAG,H2) and prove that CSD cannot be gen-erated by projective grammar formalisms with boundedk. We show this first for arbitrary projec-tiveG, under certain assumptions on the alignment
of words and graph edges. In Section5, we drop these assumptions, but focus onG=LM-CFTG.
4.1 The relationCSD
To construct CSD, consider the string language CSDs={AnBmCnDm |m, n≥1}, where
A={ahkakik|k≥0},
and analogously for B, C, D. An example string inCSDs is ahhaaii bhbi b chci d d. Note thatk
can be chosen independently for each segment. Every string w ∈ CSDs can be uniquely
described by m, n, and a sequence K(w) = (K(a), K(b), K(c), K(d)) of numbers specifying the k’s used in each segment, where K(a), K(c)
each containnnumbers andK(b), K(d)containm
numbers. In the example, we haven= 1,m= 2, andK(w) = ((2),(1,0),(1),(0,0)).
We associate a graphGw with each stringw∈
CSDsby the construction illustrated in Fig.3. For
each1 ≤ i ≤n, we define thei-tha-blockto be the graph consisting of nodesu−→c vwith a further outgoinga-edge from u. In addition,u connects to a linear chain ofKi(a)edges with labela, andv
to a linear chain ofKi(c)c-edges. Gw consists of
a linear chain of the n a-blocks, followed by the
*1
a
b *1
b! *0 *0
*0
c d
d
→ (a)
b <rt>
d G0
<rt>
d b
d b a <rt>
c d
b
d b
→ (b)
→ (c)
→ (c)
→ (d) (a)
(b)
(c) (d)
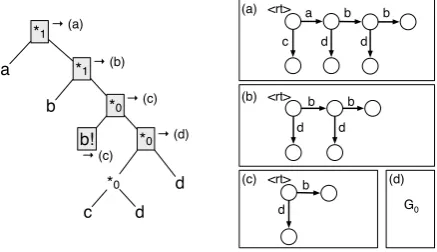
Figure 4: An derivation of ((0), (0,0), (0), (0,0)).
Note thatCSDis a more intricate version of the cross-serial dependency language. CSD can be generated by a TAG grammar along the lines of the one from Section3.4, using a HR algebra with two sources; thusCSD∈ L(TAG,H2).
4.2 CSDwith bounded blocks
The characteristic feature of CSD is that edges which are close together in the graph (e.g. the a
andcedge in an a-block) correspond to symbols that can be distant in the string (e.g. a andc to-kens). Projective grammars cannot combine pred-icates (a) and arguments (c) directly because of their distance in the string; intuitively, they must keep track of either the c’s or thea’s for a long time, which cannot be done with a boundedk.
Before we go into exploiting this intuition, we first note that its correctness depends on the details of the construction ofCSD, in particular the abil-ity to select arbitrary and independentK(x)for the differentx ∈ {a, b, c, d}. Consider the derivation
t on the left of Fig. 4 with its projective yield
abbcdd; this is the case((0),(0,0),(0),(0,0))of
CSD, corresponding to the CSDgraphG1 shown
in Fig. 4 (a). We can map t to this graph by applying the following linear tree homomorphism
hintoH2:
h(∗1) =fs(x1||renrt→s(x2)) h(∗0) =x1
h(b) =d←−bhrti −→ hsi h(b!) =d←−bhrti h(a) =c←−ahrti −→ hsi
A derivation of the form∗0(t1, t2)evaluates to the
same graph ast1; the graph value oft2is ignored.
Thus if we assume that the subtree of t for cdd
evaluates to some arbitrary graphG0, the complete
derivationt evaluates to G1. Some intermediate
results are shown on the right of Fig.4.
If we letCSD0 be the subset ofCSDwhere all K(x)are zero, we can generalize this construction into an LM-CFTG which generatesCSD0. Thus,
CSD0 can be generated by a projective grammar
that is interpreted into H2. But note that the
derivation in Fig.4is unnatural in that the symbols in the string are not generated by the same deriva-tion steps that generate the graph nodes that intu-itively correspond to them; for instance, the graphs generated for the d tokens are completely irrele-vant. Below, we prevent unnatural constructions like this in two ways. We will first assume that string symbols and graph nodes must bealigned
(Thm.1). Then we will assume that theK(x) can be arbitary, which allows us to drop the alignment assumption (Thm.2).
4.3 k-distant trees
Let R ⊇ CSD0 be some relation containing at
least the string-graph pairs ofCSD0, e.g.CSD
it-self. Assume that R is generated by a projec-tive grammar (G, h) with G = (G,ydpr) and a fixed number k of sources, i.e. we have R = REL(G, h,Hk). We will prove a contradiction.
Given a pair (w, Gw) ∈ R, we say that two
edgese, f inGwareequivalent,e≡f, if they
be-long to the same block. We call a derivation tree
t∈T=L(G)k-distantifthas a subtreet0such that we can find k edges e1, . . . , ek ∈ graph(t0)
with ei 6≡ ej for alli 6= j and k further edges e01, . . . , e0k ∈ Gw\graph(t0)such thatei ≡ e0i for
alli. For such trees, we have the following lemma.
Lemma 3. Ak-distant tree has a subtreet0 such
thatgraph(t0)has at leastksources.
Proof. Let BKi be thei-th block in Gw; we let 1 ≤ i ≤ m+nand do not distinguish between
a- andb-blocks. Lett0 be the subtree oftclaimed by the definition of distant trees. For each i, let
Ei0 = BKi ∩ graph(t0) be the edges in the i-th
block generated byt0, and letEi =BKi\Ei0.
By definition,EiandEi0are both non-empty for
at leastkblocks. Each of these blocks is weakly connected, and thus contains at least one nodeui
which is incident both to an edge inEi and inEi0.
This node is a boundary node of graph(t0). Be-cause u1, . . . , uk are all distinct, it follows from
Lemma2thatgraph(t0)has at leastksources.
We also note the following lemma about deriva-tions of projective string grammars, which fol-lows from the inability of projective grammars to combine distant tokens. We write Sep =
{a/c, c/a, b/d, d/b}.
Lemma 4. LetG= (G,yd)be a projective string
that anyt ∈ L(G) with yd(t) ∈ a∗bscsd∗ has a subtreet0 such thatyd(t0)containsr occurrences ofxand no occurrences ofy, for somex/y∈Sep.
4.4 Projectivity and alignments
A consequence of Lemma 3 is that if certain string-graph pairs inCSD0 can only be expressed
with k+1-distant trees, then R (which contains these pairs as well) is not in L(G,Hk), because
Hkonly admitsksources.
However, as we saw in Section 4.2, pairs in CSD0 can have unexpected projective derivations
which make do with a low number of sources. So let’s assume for now that the string grammar
G and the tree homomorphism h produce tokens and edge labels that fit together. Let us callG, h
aligned if for all constantsc ∈ Σ0, graph(c)is a
graph containing a single edge with label yd(c). The derivation in Fig. 4 cannot be generated by an aligned grammar because the graph for the to-ken bcontains a d-edge. We writeL↔(G,A) = {REL(G, h,A)| G ∈GandG, haligned}for the
class of string-semantics relations which can be generated with aligned grammars.
Under this assumption, it is easy to see that any relation including CSD0 (hence,CSD) cannot be
expressed with a projective grammar.
Theorem 1. Let G be any class of projective
string grammars and R ⊇ CSD0. For any k, R6∈ L↔(G,Hk).
Proof. Assume that there is aG = (G,ydpr) ∈
Gand an LTHhsuch thatR = REL(G, h,Hk).
Givenk, chooses ∈ N0 such that every treet ∈
T = L(G) withyd(t) = asbscsds has a subtree
t0 such thatyd(t0)containsk+ 1occurrences of
xand no occurrences of y, for some x/y ∈ Sep. Such an sexists according to Lemma4. We can choosetsuch that(yd(t),graph(t))∈CSD0.
BecauseG, hare aligned,graph(t0)contains no
y-edge and at leastk+ 1x-edges. Each of these
x-edges is non-equivalent to all the others, and equivalent to ay-edge ingraph(t)\graph(t0), so
t is k+1-distant. It follows from Lemma 3 that graph(t0)hask+ 1sources, in contradiction to the assumption thatG, huses onlyksources.
5 Expressive capacity of LM-CFTG
Thm.1is a powerful result which shows thatCSD cannot be generated by any device for generating projective derivations using bounded placeholder
memory – if we can assume that tokens and edges are aligned. We will now drop this assumption and prove thatCSDcannot be generated using a fixed set of placeholders using LM-CFTG, regardless of alignment. The basic proof idea is to enforce a weak form of alignment through the interaction of the pumping lemma with very longx-chains. The result is remarkable in that LM-CFTG and TAG are weakly equivalent; they only differ in whether they must derive the strings projectively or not.
Theorem 2. CSD 6∈ L(LM-CFTG,Hk), for any
k.
5.1 Asynchronous derivations
Assume that CSD = REL(G, h,Hk), for some
k, withG = (G,yd) an LM-CFTG. Proving that this is a contradiction hinges on a somewhat tech-nical concept ofasynchronousderivations, which have to do with how the nodes generating edge la-bels such asaare distributed over a derivation tree. We prove that all asynchronous derivations of cer-tain elements ofCSDare distant (Lemma5), and that all LM-CFTG derivations of CSD are asyn-chronous (Lemma6), which proves Thm.2.
In what follows, Let T = L(G). let us write for any tree or context t and symbol x, ntx as a shorthand for |yd(t)|x, etx for the number of x
-edges ingraph(t)andmtxfor the maximum length of a string inx∗which is also substring ofyd(t).
Definition 1(x, y, l-asynchronous derivation). Let
x/y ∈ Sep, l > 0, t ∈ T, We callt an x, y, l
-asynchronous derivationiff there is a decomposi-tiont=C[t0]such that
ety0 ≥nty−ntxl−mty
etx0 ≤ntxl+mtx(l+ 1).
We call the pair (C, t0) an x, y, l-asynchronous splitoft.
Lemma 5. For any k, l > 0, there is a pair
ok,l = (wk,l, Gk,l) ∈ CSDsuch that everyx, y, l -asynchronoustwithok,l = (yd(t),graph(t))isk -distant.
Proof. Forx∈ {a, b, c, d}andm∈N0, letx(m)
denote the wordhmxmim. Letr=s= 3l+k+ 1
andok,l = (wk,l, Gk,l) be the unique element of
CSDsuch that
wk,l = (aa(s))r(bb (s)
)r(cc(s))r(dd(s))r.
Let t be an a, c, l-asynchronous derivation of
By definition, we can split t = C[t0] such that graph(t0)has at mostqa=lr+(l+1)s= (2l+1)s a-edges and at leastqc=rs−rl−s= (2l+k+1)s c-edges. Notice first that graph(t0) contains at most2l+ 1 different complete a-blocks of Gk,l,
because eacha-block containss a-edges. Having
2l+ 2 of them would require(2l+ 2)s a-edges, which is more than theqaa-edges thatgraph(t0)
can contain.
Next, consider2l+kdistincta-blocks ofGk,l.
These blocks contain a total of(2l+k)s <(2l+
k + 1)s = qc c-edges. Hence, the c-edges of
graph(t0)cannot be contained within only2l+k
distinct blocks.
So we can find at least 2l + k + 1 c-edges in graph(t0) which are pairwise non-equivalent. There are at leastkedges among these which are equivalent to an edge inGk,l\graph(t0), because
graph(t0)contains at mostlcompletea-blocks of
Gk,l. Thus,tisk-distant.
5.2 LM-CFTG derivations are asynchronous
So far, we have not used the assumption that T
is an LM-CFTL. We will now exploit the pump-ing lemma to show that all derivation trees of an LM-CFTG forCSDmust be asynchronous.
Lemma 6. IfTis an LM-CFTL, then there exists
l0 ∈ N0 such that for every t ∈ T, there exists x/y∈Sepsuch thattisx, y, l0-asynchronous.
We prove this lemma by appealing to a class of derivation trees in which predicate and argument tokens are generated in separate parts.
Definition 2 (x, y, l-separated derivation). Let
x/y∈Sep. A treet∈ T∆isx, y, l-separatedif we can writet=Cx[C0[ty]]such that|yd(ty)|x = 0 and |yd(Cx)|y = 0 and |yd(C0)|x ≤ l. The triple (Cx, C0, ty) is called an l-separation of t. We call anl-separationminimalif there is no other
l-separation oftwith a smallerC0.
Intuitively, we can use the pumping lemma to systematically remove some contexts from at ∈
T. From the shape of CSD, we can conclude certain alignments between the strings and graphs generated by these contexts and establish bounds on the number ofx- andy-edges generated by the lower part of a separated derivation. The full proof is in the appendix; we sketch the main ideas here.
Letpdenote the pumping height ofT. There is a maximal number of string tokens and edges that a context of height at most p can generate under
a given yield and homomorphism. We call this numberl0in the rest of the proof.
Lemma 7. Fort ∈ T, letryt be the length of the
maximal substring of yd(t) consisting in only y -tokens and containing the rightmost occurrence of
y inyd(t). If t isx, y, l0-separated, there exists
a minimalx, y, l0-separationDx[D0[ty]]oftsuch that, lettingt0 =D0[ty],ety0 ≥nty−ntxl0−rty.
Moreover, for any x, y, l0-separation t = Ex[E0[t1y]], lettingt1=E0[t1y],etx1 ≤n
t1
x +ntxl0.
Proof (sketch). Both statements must be achieved in separated inductions on the height of t, although they mostly follow similar steps. We therefore focus here only on the crucial parts of the (slightly trickier) bound on et0
y . Let Dx[D0[ty]] be a minimal x, y, l0-separation of t
andt0=D0[ty].
Base CaseIfht(t) ≤p, we haventy ≤ l0. We
also haventx>0, sonty−ntxl0−rty ≤0≤e t0 ¯ y.
Induction step If h(t) > p, we apply
Lemma 1 to t to yield a decomposition t =
C1[C2[C3[C4[t5]]]], where t0 = C1[C3[t5]] ∈ T,
ht(t0) < ht(t)andht(C2[[C3]C4]) ≤p. We first
observe thatt0 isx, y, l0-separated. By induction,
there exists a minimal separationt0 =Cx[C0[t0y]]
witht00 =C0[t0y]validating the bound one t00 y .
Be-cause of pumping considerations, we need to dis-tinguish only three configurations ofC2 andC4.
We present only the most difficult case here. In this caseC2 andC4 generate only one kind
of bar symbol,y, and brackets. One needs to ex-amine all possible waysC2,C4 andt0 may
over-lap. We detail the reasoning in the case wheret0
does not overlap withC2 orC4. Then, since all y-tokens are generated by t0, projectivity of the
yield and the definition of CSD impose that the generatedy-tokens contribute to the rightmosty -chaini.e. ryt =ryt0 +nC2[C4]
y . Hencee t0
y ≥e
t0 0
y ≥
nty−nC2[C4]
y +ntxl0−ryt0 +nCy2[C4].
Lemma 8. For anyt∈T, iftisx, y, l0-separated
thentisx, y, l0-asynchronous.
Proof. By Lemma7there is a minimalx, y, l0
-separation t = Dx[D0[ty]] such that, for t0 = D0[ty], the bound onety0 and the bound one
t0
x both
obtain. Observe thatrt
y ≤ mty by definition, and
sincet0 generates at mostl0 x-tokens, by
projec-tivity it generates at most(l0+1)mtxx-tokens (one
sequence ofmt
xbetween each occurrence ofxand
Lemma 9. For anyt ∈ T,tisx, y, l0-separated
for somex/y∈Sep.
Proof(sketch). The proof proceeds by induction on the height oft.
If ht(t) ≤ p, then |yd(t)|z ≤ l0 for any z ∈
{a, b, c, d}, hence t is trivially x, y, l0-separated
for somex/y∈Sep.
If h(t) > p, Lemma 1 yields a decomposition
t =C1[C2[C3[C4[t5]]]], wheret0 =C1[C3[t5]]∈ T, ht(t0) < ht(t) andht(C2[C3[C4]]) ≤ p. By
induction t0 is x, y, l0-separated for some x/y ∈
Sep. Let us assumex/y = a/c, other cases are analoguous. The challenge is to conclude to the
x, y, l separation of t, after reinsertion of C2 and
C4int0.
IfC2andC4generate noa- orc-token, the
dis-tribution of a- andc-tokens in the tree is not af-fected, hence t is a, c, l0-separated. Otherwise,
due to pumping considerations, we need to distin-guish three possible configurations regarding the shape of the yields ofC2andC4. We present one
here, see the appendix for the others; they are in the same spirit.
We consider the case where left(C2) contains
some a-token and no b, c, d-tokens, and yd(C4)
contains somec-token. Assumeleft(C4)contains
somec. It follows that allb-tokens are generated by C3. Sot has less thanl0 b-tokens, by
defini-tion ofCSDit has then also less thanl0 d-tokens,
so(C1, C2[C3[C4]], t5)is ad, b, l0-separation.
As-sume now thatright(C4) contains somec. It
fol-lows that t5 generate no d-token and C1
gener-ate no b-token. Hence (C1, C2[C3[C4]], t5) is a
b, d, l0-separation.
This concludes the proof of Lemma6and Thm.2.
6 Conclusion
We have established a notion of expressive capac-ity in compositional semantic parsing. We have proved that non-projective grammars can express sentence-meaning relations with bounded memory that projective ones cannot. This answers an old question in the design of compositional systems: assuming projective syntax, lambda-style com-positional mechanisms can be more expressive than unification-style ones, which have bounded “memory” for unfilled arguments.
From a theoretical perspective, the stronger re-sult of this paper is perhaps Thm.2, which shows without further assumptions that weakly equiva-lent grammar formalisms can differ in their
se-mantic expressive capacity. However, Thm.1may have a clearer practical impact on the development of compositional semantic parsers. Consider, for instance, the case of CCG, a lexicalized grammar formalism that has been widely used in seman-tic parsing (Bos, 2008; Artzi et al., 2015; Lewis et al., 2016). While a potentially infinite set of syntactic categories can be used in the parses of a single CCG grammar, CCG derivations are still projective in our sense. Thus, if one assumes that derivations should be aligned (which is natural for a lexicalized grammar), Thm.1implies that CCG with lambda-style semantic composition is more semantically expressive than with unification-style composition. Indeed, lambda-style compositional mechanisms are the dominant approach in CCG (Steedman, 2001; Baldridge and Kruijff, 2002;
Artzi et al.,2015).
Furthermore, under the alignment assumptions of Section 4, no unification-style compositional mechanism can describe string-meaning relations like CSD. This includes neural models. For in-stance, most transition-based parsers (Nivre,2008;
Andor et al.,2016;Dyer et al.,2016) are projec-tive, in that the parsing operations can only con-catenate two substrings on the top of the stack if they are adjacent in the string. Such transition sys-tems can therefore not be extended to transition-based semantic parsers (Damonte et al., 2017) without (a) losing expressive capacity, (b) giving up compositionality, (c) adding mechanisms for non-projectivity (G´omez-Rodr´ıguez et al., 2018), or (d) using a lambda-style semantic algebra. Thus our result clarifies how to build an effective and accurate semantic parser.
We have focused on whether a grammar formal-ism is projective or not, while holding the seman-tic algebra fixed. In the future, it would be inter-esting to explore how a unification-style composi-tional mechanism can be converted to a lambda-style mechanism with unbounded placeholders. This would allow us to specify and train semantic parsers using such abstractions, while benefiting from the efficiency of projective parsers.
Acknowledgments
References
Daniel Andor, Chris Alberti, David Weiss, Aliaksei Severyn, Alessandro Presta, Kuzman Ganchev, Slav Petrov, and Michael Collins. 2016. Globally nor-malized transition-based neural networks. In Pro-ceedings of ACL.
Yoav Artzi, Kenton Lee, and Luke Zettlemoyer. 2015. Broad-coverage CCG Semantic Parsing with AMR. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.
Jason Baldridge and Geert-Jan M. Kruijff. 2002. Cou-pling CCG and Hybrid Logic Dependency Seman-tics. InProceedings of the 40th ACL.
Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2013. Abstract Meaning Representation for Sembanking. InProceedings of the 7th Linguis-tic Annotation Workshop and Interoperability with Discourse.
Emily M. Bender. 2008. Radical non-configurationality without shuffle operators: An analysis of Wambaya. In Proceedings of the 15th International Conference on HPSG.
Emily M. Bender, Dan Flickinger, and Stephan Oepen. 2002. The Grammar Matrix: An open-source starter-kit for the rapid development of cross-linguistically consistent broad-coverage precision grammars. In Proceedings of the COLING Work-shop on Grammar Engineering and Evaluation.
Patrick Blackburn and Johan Bos. 2005. Represen-tation and Inference for Natural Language. CSLI Publications.
Johan Bos. 2008. Wide-coverage semantic analy-sis with Boxer. In Semantics in Text Processing. STEP 2008 Conference Proceedings. College Pub-lications.
David Chiang, Jacob Andreas, Daniel Bauer, Karl Moritz Hermann, Bevan Jones, and Kevin Knight. 2013. Parsing graphs with hyperedge replacement grammars. InProceedings of the 51st ACL.
Hubert Comon, Max Dauchet, R´emi Gilleron, Flo-rent Jacquemard, Denis Lugiez, Sophie Tison, Marc Tommasi, and Christof L¨oding. 2007. Tree Au-tomata techniques and applications. Published on-line athttp://tata.gforge.inria.fr/.
Ann Copestake, Alex Lascarides, and Dan Flickinger. 2001. An algebra for semantic construction in constraint-based grammars. InProceedings of the 39th ACL.
Bruno Courcelle and Joost Engelfriet. 2012. Graph Structure and Monadic Second-Order Logic, a Lan-guage Theoretic Approach. Cambridge University Press.
Mary Dalrymple, John Lamping, Fernando C. N. Pereira, and Vijay Saraswat. 1995. Linear logic for meaning assembly. InProceedings of the Workshop on Computational Logic for Natural Language Pro-cessing.
Marco Damonte, Shay B. Cohen, and Giorgio Satta. 2017. An incremental parser for Abstract Meaning Representation. InProceedings of the 15th EACL.
Frank Drewes, Hans-J¨org Kreowski, and Annegret Ha-bel. 1997. Hyperedge replacement graph gram-mars. In G. Rozenberg, editor,Handbook of Graph Grammars and Computing by Graph Transforma-tion, pages 95–162. World Scientific.
Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. 2016. Recurrent neural network grammars. InProceedings of NAACL.
Anette Frank and Josef van Genabith. 2001. GlueTag: Linear logic based semantics for LTAG. In Proceed-ings of the LFG Conference.
Claire Gardent and Laura Kallmeyer. 2003. Semantic construction in feature-based TAG. InProceedings of EACL.
Jonas Groschwitz, Matthias Lindemann, Meaghan Fowlie, Mark Johnson, and Alexander Koller. 2018. AMR dependency parsing with a typed semantic al-gebra. InProceedings of ACL.
Carlos G´omez-Rodr´ıguez, Tianze Shi, and Lillian Lee. 2018. Global transition-based non-projective depen-dency parsing. InProceedings of ACL.
Aravind K. Joshi and Yves Schabes. 1997. Tree-Adjoining Grammars. In G. Rozenberg and A. Salo-maa, editors,Handbook of Formal Languages, vol-ume 3. Springer-Verlag.
Stephan Kepser and James Rogers. 2011. The equiva-lence of tree adjoining grammars and monadic linear context-free tree grammars. Journal of Logic, Lan-guage and Information, 20(3):361–384.
Alexander Koller. 2015. Semantic construction with graph grammars. InProceedings of the 11th Inter-national Conference on Computational Semantics, pages 228–238.
Mike Lewis, Kenton Lee, and Luke Zettlemoyer. 2016. LSTM CCG Parsing. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
T. Maibaum. 1978. Pumping lemmas for term lan-guages. Journal of Computer and System Sciences, pages 319–330.
Joakim Nivre. 2008. Algorithms for deterministic in-cremental dependency parsing. Computational Lin-guistics, 34(4):513–553.
Xiaochang Peng, Linfeng Song, and Daniel Gildea. 2015. A synchronous hyperedge replacement gram-mar based approach for AMR parsing. In Proceed-ings of the 19th Conference on Computational Lan-guage Learning.
William Rounds. 1969. Context-free grammars on trees. InProceedings of the First Annual ACM Sym-posium on Theory of Computing (STOC).
Stuart M. Shieber. 1985.Evidence against the context-freeness of natural language. Linguistics and Phi-losophy, 8(3):333–343.
Mark Steedman. 2001. The Syntactic Process. MIT Press, Cambridge, MA.
David Weir. 1988. Characterizing mildly context-sensitive grammar formalisms. Ph.D. thesis, Uni-versity of Pennsylvania.
A Details of the proof of Theorem 1
Lemma 4. LetG= (G,yd)be a projective string
grammar. For anyr ∈N0there existss∈N0such that anyt ∈ L(G) with yd(t) ∈ a∗bscsd∗ has a subtreet0 such thatyd(t0)containsr occurrences ofxand no occurrences ofy, for somex/y∈Sep.
Proof. Depending onyd, one can always choose
s > r such that anyt with |yd(t)| > 2s has at
least one strict subtreet0with|yd(t0)| ≥2r. The lemma follows by induction over the height oft. It is trivially true for height 1. For the induc-tion step, consider thatw0 = yd(t0)must have at leastroccurrences of some letter because of pro-jectivity and the shape of yd(t); assume it is a, the other cases are analogous. Ifw0 has no occur-rences of c, we are done. Otherwise, by projec-tivity,w0 contains all theb’s, i.e.w0 ∈ a∗bsc+d∗. In this case, eitherw0 containss > roccurrences of b and no occurrences of d, in which case we are again done. Or it contains an occurrence ofd; thenw0 ∈a∗bscsd∗is in the shape required by the lemma, and we can apply the induction hypothesis to identify a subtreet00oft0 withroccurrences of somexand none of the correspondingy; andt00is also a subtree oft.
B Details of the proof of Theorem 2
In all of the following, we assume that for some
k ∈ N0 we haveCSD = REL(G, h,Hk), where
G = (G,yd) is an LM-CFTG (hence projective,
i.e. yd = ydpr). We letT = L(G) andp be the pumping height ofT.
B.1 Terminology
Let us extend the domain ofydto contexts: for a contextC, we letyd(C) =left(C)·right(C).
We say that a stringsisbalancedif, for anyz∈
{a, b, c, d}and any positioniinssuch thatsi =z
there are two encompassing positionsk ≤ i ≤ l
such thats[k,l]∈ {hnzin|n∈
N0}. We say that a
tree or a context is balanced if its yield is balanced. By construction, all trees ofTare balanced.
For t ∈ T, a pumping decomposition of t
is a 5-tuple (C1, C2, C3, C4, t5), consisting in
4 contexts C1-C4 and one tree t5 such that t = C1[C2[C3[C4[t5]]]], ht(C2[C3[C4]]) ≤ p,
ht(C2) + ht(C4) > 0 and for any i ∈ N0, C1[vi[t5]] ∈ T, where we let v0 = C3 and vi+1=C2[vi[C4[X]]].
B.2 Pumping considerations
Lemma 10. Let t ∈ T with ht(t) > p,
and consider a pumping decomposition t =
C1[C2[C3[C4[t5]]]]. Lets = left(C2)·left(C4)·
right(C4)·right(C2) =yd(C2[C4]). The two
fol-lowing propositions obtain:
• For any(x, y)∈ {(a, c),(b, d)},|s|x =|s|y.
• Lett0 = C1[C3[t5]]. For u ∈ T∆ andz ∈
{a, b, c, d, a, b, c, d}leteuz denote the number
ofz-edges ingraph(u). It holds for anyz ∈ {a, b, c, d, a, b, c, d}thatetz=ezt0+|s|z. Proof. Let (x, y) ∈ {(a, c),(b, d)}. t ∈ T so yd(t)∈CSDswhich entails
|yd(t)|x=|yd(t)|y. (1)
since t0 ∈ T by construction, we have
hyd(t0),graph(t0)i ∈CSD. From there
|yd(t0)|x=|yd(t0)|y. (2)
But|yd(t)|x,y =|yd(t0)|x,y+|s|x,y. Plugging this into (1) yields
|yd(t0)|x+|s|x=|yd(t0)|y+|s|y.
Simplifying using (2) we find |s|x = |s|y which
establishes the first point. For the second point, we have fromhyd(t),graph(t)i ∈CSDand by defini-tion ofCSDetz =|yd(t)|z =|yd(t0)|z+|s|z.
Sim-ilarily since hyd(t0),graph(t0)i ∈ CSD we have
etz0 =|yd(t0)|z. Henceetz =et 0 z +|s|z.
We will now present a pair of lemmas stat-ing, in formal terms, that decompositions t =
C1[C2[C3[C4[t5]]]] provided by the pumping
• First, in the case where the ’pumpable’ con-texts C2 and C4 generate only ‘bar’ tokens
and brackets in {a, b, c, d,h,i}∗, we show that yd(C2) ∈ {h,i}∗, so that only C4 is
actually pumping ‘bar’ tokens of some kind. Moreover,t5 generates only ’bar’ tokens and
brackets as well.
• Second, we explore the alternative, where the ’pumpable’ contexts generate some of the ‘core’ tokens in {a, b, c, d}, say – for the sake of this informal presentation – somea -tokens. By lemma10, they must generate as manyc-tokens, for which we can again dis-tinguish three possible configurations: 1.a’s andc’s are respectively generated on differ-ent sides of a single context (C2 and/orC4),
but then neitherC2 norC4 generate anybor d-tokens. 2.C2 generate bothaandd-tokens
(on the left and right sides respectively) and nobandc-tokens, whileC4 ensures
genera-tion of correspondingbandc-tokens (on the left and right sides respectively). 3. Or else, one ofC2, C4 generates thea-tokens and no c,bordwhile the other generates the corre-spondingc-tokens and noa,bord.
Below follows the formal presentation of these lemmas:
Lemma 11. Let t ∈ T with ht(t) > p,
and consider a pumping decomposition t =
C1[C2[C3[C4[t5]]]] such that for all z ∈
{a, b, c, d}, |yd(C2[C4])|z = 0. There is x ∈
{a, b, c, d}such that all of the following holds:
1. yd(C2)∈ {h,i}∗andyd(C4)∈ {h, x,i}∗.
2. Either left(C4) ∈ {x}∗ and |left(C3)|z = 0for any z ∈ {a, b, c, d}, or symmetrically,
right(C4) ∈ {x}∗ and|right(C3)|z = 0for
anyz∈ {a, b, c, d}.
3. |yd(t5)|z = 0for anyz∈ {a, b, c, d}
Proof. First point: Lets = left(C1) andn0 =
|s|h. Let y ∈ {a, b, c, d} and assume y ∈
left(C2). Pumping C2-C4 n0 + 1-times yields
a tree tn0+1 ∈ T such that s ·left(C2)
n0+1 is
a prefix of yd(tn0+1). We thus see that tn0+1
is not balanced, which is in contradiction with
tn0+1 ∈ T. A symmetric argument establishes
thaty /∈right(C2).
Assume now that there are two distinctx, y ∈
{a, b, c, d}such thatx∈yd(C4)andy∈yd(C4).
Notice that, sinceC4does not contain non-bar
to-kens, if x and y occur on the same side of C4
(for instanceleft(C4) = hxihyi) thent /∈ T
be-cause no string inCSDSadmitsleft(C4)as a
sub-string, whereasyd(t) does. So xandy must oc-cur on distinct sides. It follows that C4 does not
generate tokens in {h,i} either: if for instance left(C4) =u· h ·x·vfor some stringsuandvin
{xh,i}∗,u·h·x·v·u·h·x·vwould be a substring of
C1[C2[C2[C3[C4[C4[t5]]]]]] ∈Twhich again is a
contradiction. Let nown1 = |yd(t5)|i. Pumping C2-C4n1+ 1times yields a treetn1+1 ∈ Twith
a substring of the formxn1+1yd(t
5)yn1+1 (up to x/ysymmetry) which cannot be balanced, yield-ing a final contradiction.
Second point: yd(C4) ∈ {h/ ,i}∗, because
oth-erwise pumping C2 andC4 more times than the
maximum number of occurrences of a bar to-ken inyd(t) would yield an unbalanced tree. So there is a x such that x ∈ left(C4) or x ∈
right(C4). Assume for contradiction that any
dif-ferent token occurs on the same side ofC4 then C1[C2[C2[C3[C4[C4[t5]]]]]] ∈ T contains a
sub-string that cannot be found in any sub-string of CSD yielding a contradiction. So left(C4) ∈ {x}∗ or
right(C4) ∈ {x}∗. Assume left(C4) ∈ {x}∗, the
other case is symmetric. Assume for contradiction that|left(C3)|z >0for somez∈ {a, b, c, d}. Let n2 = |yd(C3)|h. PumpingC2-C4 n2 + 1 times
yields a treetn2+1 ∈Tsuch that (by projectivity)
yd(tn2+1)has a substring of the formz·u·xn2+1
where |u|h ≤ n2. Hence tn2+1 ∈ Tis not
bal-anced, yielding a contradiction.
Third point: Assume for contradiction that
|yd(t5)|z >0. Assume thatleft(C4) ∈ {x}∗, the
caseright(C4) ∈ {x}∗ is symmetric, and point 2
ensures that these two cases are exhaustive. Let
n3 = |t5|i and consider the treetn3+1 ∈ T ob-tained by pumpingC2-C4 n3 + 1times. By
pro-jectivity, yd(tn3+1) has a substring of the form
xk·u·z·vwithk≥n3+ 1and|u|i≤n3. Hence tn3+1 is not balanced andtn3+1 ∈/ T, yielding a
contradiction.
Lemma 12. let t ∈ T with ht(t) > p,
and consider a pumping
decomposi-tion t = C1[C2[C3[C4[t5]]]]. Let
(x, y, X, Y) ∈ {(a, c, A, C),(b, d, B, D)}
such that |yd(C2[C4])|x 6= 0. One of the following obtains:
1. For some(i, j) ∈ {(2,4),(4,2)},left(Ci) ∈ X+, right(C
i) ∈ Y+, left(Cj) ∈ X∗ and
right(Cj)∈Y∗.
B+andright(Cj)∈C+.
3. Either left(C2) ∈ X+, right(C2) = and
left(C4)·right(C4) ∈Y+, or symmetrically
left(C2) =,right(C2) ∈Y+andleft(C4)·
right(C4)∈X+.
Proof. All these observations follow easily from the first point of Lemma 10 (governing the rela-tive number of occurrences of a, c-tokens on one hand andb, d-tokens on the other hand), projectiv-ity, and the following observation: only one side ofC2orC4cannot generate two different kinds of
tokens in{a, b, c, d}or be unbalanced. Otherwise pumping would (from projectivity) ensure that the resulting tree has a substring of a shape impossible forCSD(for example, if bothaandb-tokens occur on the same side ofC2, pumping once produces a
substringa·u·b·v·a·u·b·v).
B.3 Separation
Lemma 13. Lett=C1[C2[C3[C4[t5]]]] ∈Tand
t0 =C1[C3[t5]]∈ T. Iftisx, y, l-separated then
so ist0.
Proof. Consider an x, y, l-separation oft: t =
Dx[D0[ty]]. Let Cx, C0 and t0y be respectively
obtained by removing all nodes from C2 or C4
from Dx, D0 and ty. One easily checks that t0 =Cx[C0[t0y]].
Moreover, |yd(Cx)|y ≤ |yd(Dx)|y = 0,
|yd(C0)|x ≤ |yd(D0)|x ≤ l and |yd(t0y)|x ≤
|yd(ty)|x= 0. Hencet0isx, y, l-separated.
B.4 Minimality argument
Lemma 14. Let t = C1[C2[C3[C4[t5]]]] ∈ T
and t0 = C1[C3[t5]] ∈ T such that t is x, y, l
-separated. By Lemma 13, t0 is separated. Let
Dx[D0[ty]] be a minimal separation of t and Cx[C0[t0y]]be a minimal separation oft0. D0[ty] contains all nodes ofC0[t0y].
Proof. Assume for contradiction that a node π
of C0 is not in D0. It must then be in Dx or ty. Assume that it is in Dx, the case where it
is in ty is analoguous. Since π is not in D0,
there is a non-trivial subcontextDx0 ofDx rooted
at π, i.e. Dx = Dx00[Dx0] with ht(D0x) > 0.
Let Cx00, Cx0 be obtained by removing all nodes from C2 or C4 from D00x and D0x respectively.
By definition ofDx, |yd(Dx00[D0x])|y = 0, hence
|yd(Cx00[Cx0])|y = 0. Further observe that we have Cx[C0] = Cx00[Cx0[C00]] for some subcontext C00
ofC0. Since π is not in C2 or C4, ht(Cx0) > 0
thusht(C00) <ht(C0). But lettingEx =Cx00[Cx0], Ex[C00[t0y]]is then anx, y, l-separation oftwhich
contredicts the assumed minimality ofCx[C0[t0y]].
B.5 Inductive bounds
For any tree or contexttand symbolx, let us write
ntxas a shorthand for|yd(t)|x,etx for the number
ofx-edges generated bytandrtxthe length of the rightmost maximal substring ofyd(t)consisting in onlyx-tokens (more formally,rxt =|s|x, wheres
is the unique substring such thatyd(t) =u·s·v
wheres ∈ x∗, ifu is non empty its last token is notx, and|v|x= 0).
There is a maximal number of string tokens and edges that a context of height at mostpcan gen-erate under the considered yield and homomor-phism. We calll0this number and focus from now
onl0-separated andl0-asynchronous derivations.
Below are the proofs of the two statements of Lemma 7 of the main paper (respectively, 7-1 and 7-2).
Lemma 7-1. If t ∈ T is x, y, l0-separated and
t=Dx[D0[ty]]is anx, y, l0-separation oft, then
fort0 =D0[ty]we have
et0
x ≤n
t0
x +n
t
xl0. (xbound)
Proof. We prove the result by induction over the pair(ht(t0),ht(t))(with lexicographic ordering).
Base CaseAssumeht(t0)≤p. Thenet0 ≤l0.
Sinceyd(t)∈CSDs,ntx>0, thusntx0+ntxl0 ≥l0
which ensures the bound.
Induction step If h(t0) > p then h(t) ≥
h(t0) > p. We apply Lemma 1 to t to yield
a decomposition t = C1[C2[C3[C4[t5]]]], where
t0 = C1[C3[t5]] ∈ T, ht(t0) < ht(t) and
ht(C2[C3[C4]]]) ≤p. Notice thatt0 cannot
over-lap withC2[C3[C4]without overlapping with C1
ort5as well, for otherwiseh(t0)≤p.
As in the proof of Lemma13, lettingCx, C0, t0y
be obtained by removing all nodes from C2 and C4fromDx,D0andtyrespectively, we obtain an
x, y, l-separation t0 = Cx[C0[t0y]]. We let t00 =
C0[t0y]and distinguish between possible
configu-rations forC2 andC4:
Case 0 If neither C2 or C4 generate any x
-token, we find by induction
et 0 0
x ≤n
t00
x +n
t0 xl0.
Moreover, we haveet 0 0
x =e
t0
x,n
t0 0
x =n
t0
x andnt
0
x ≤
nort5 generate anyy-token, projectivity imposes ryt = ryt0 + nC2[C4]
y and we can conclude as
in the previous case. The only remaining sub-case is when |yd(C3)|x = 0, in which case t
is 0-separated, and considering the (minimal) 0 -separation (C1, X, C2[C3[C4]]) we can use the
same argument as in the case where t0
encom-passes all nodes ofC2andC4.
Case 2Consider now the remaining case where
Lemma12 applies. If neitherC2 orC4 generate
some x or y-token, they don’t generate x or y -tokens either, and the same reasoning as Case 1 subcase i) applies. OtherwiseC2[C4]generate at
least somex-token. We then haventx ≥ ntx0 + 1. Sincet0contains all nodes fromt00we further have
et0
y ≥e
t0 0
y. Finallynty ≤nt 0
y +l0. We conclude
us-ing inequation3.
B.6 Conclusion
Lemma 8. For anyt∈T, iftisx, y, l0-separated
thentisx, y, l0-asynchronous.
Proof. By Lemma 7-2, there is a minimal
x, y, l0-separation t = Dx[D0[ty]] such that the
y bound obtains fort0 = D0[ty]. By lemma 7-1
the x bound obtains for t0 as well. Observe
fi-nally, thatrty ≤mtyand sincet0generates at most l0x-tokens, by projectivity and definition ofCSD,
it generates at most(l0+ 1)mtx x-tokens (one
se-quence of mtx between each occurrence ofx and the next, plus possibly one in front of the first and one after the last). Hence,
et0
y ≥n
t
y−ntxl0−mty et0
x ≤ntxl+mtx(l0+ 1).
andtisx, y, l0-asynchronous.
Lemma 9. For anyt ∈ T,tisx, y, l0-separated
for somex/y∈Sep.
Proof. The proof proceeds by induction on the height oft.
If ht(t) ≤ p. Then|yd(t)|z ≤ l0 for anyz ∈
{a, b, c, d}, hence t is trivially x, y, l0-separated
for somex/y∈Sep.
If h(t) > p, Lemma 1 yields a decomposition
t =C1[C2[C3[C4[t5]]]], wheret0 =C1[C3[t5]]∈ T,ht(t0) <ht(t)andht(C2[C4])≤p. By
induc-tion t0 is x, y, l0-separated for some x/y ∈ Sep.
For sake of succintness, let us present the induc-tive step forx/y = a/c, the reasoning for other cases is analoguous. Let us examine the different possible configurations ofC2andC4.
Case 1If Lemma11appliesi.e.C2andC4
gen-erate only one kind of bar token,z, and brackets, one checks easily that inserting C2 and C4 does
not change the distribution of a and c-tokens in the tree, hencetisa, c, l0-separated.
Case 2If Lemma12applies, note first that ifC2
andC4 generate noaorc-token, we can conclude
as in Case 1 as the distribution ofaandc-tokens in the tree is not changed either. Otherwise, we as-sume thatC2orC4generate someaorc-token and
distinguish between subcases 1-3 of Lemma12:
Subcase 1 in this case for some i ∈ {2,4}
left(Ci) contains an a-token and no b, c or d
-token whileright(Ci) contains some c-token and
noa, bord-token. Assumei= 2, the case where
i = 4 is similar. By projectivity and definition ofCSDsfollows that allb-tokens are generated in C3[C4[t5]] and allc-tokens inC1. tis therefore
b, d,0-separated, henceb, d, l0-separated.
Subcase 2in this case,left(C2)contains some
a-token and no b, c, d-token, right(C3) contains
somed-token and no a, c, d-token, left(C4)
con-tains someb-token and noa, c, d-token,right(C4)
contains somec-token and noa, b, d-token. It fol-lows thatt5generate no occurrence ofaandC1no
occurrence of c. Since|yd(C2[C3[C4]])|a ≤ l0,
(C1, C2[C3[C4]], t5)is ana, c, l0-separation.
Subcase 3 Assume left(C2) contains some a
-token and no b, c, d-token and that left(C4)
con-tains some c-token. It follows that all b-tokens are generated by C3. So yd(t) contains less than l0 b-tokens, by definition ofCSD it also contains
less thanl0 d-tokens, so(C1, C2[C3[C4]], t5)is a
d, b, l0-separation.
Assume now left(C2) contains some a-token
and no b, c, d-token and that right(C4) contains
some c-token. It follows that t5 generate no d-token and C1 generate no b-token. Hence
(C1, C2[C3[C4]], t5)isb, d, l0-separation.
The remaining cases are symmetric exchanging