University of Windsor University of Windsor
Scholarship at UWindsor
Scholarship at UWindsor
Electronic Theses and Dissertations Theses, Dissertations, and Major Papers
9-24-2019
Using Prior Knowledge for Verification and Elimination of
Using Prior Knowledge for Verification and Elimination of
Stationary and Variable Objects in Real-time Images
Stationary and Variable Objects in Real-time Images
Foram Pravinkumar Patel
University of Windsor
Follow this and additional works at: https://scholar.uwindsor.ca/etd
Recommended Citation Recommended Citation
Patel, Foram Pravinkumar, "Using Prior Knowledge for Verification and Elimination of Stationary and Variable Objects in Real-time Images" (2019). Electronic Theses and Dissertations. 7831.
https://scholar.uwindsor.ca/etd/7831
This online database contains the full-text of PhD dissertations and Masters’ theses of University of Windsor students from 1954 forward. These documents are made available for personal study and research purposes only, in accordance with the Canadian Copyright Act and the Creative Commons license—CC BY-NC-ND (Attribution, Non-Commercial, No Derivative Works). Under this license, works must always be attributed to the copyright holder (original author), cannot be used for any commercial purposes, and may not be altered. Any other use would require the permission of the copyright holder. Students may inquire about withdrawing their dissertation and/or thesis from this database. For additional inquiries, please contact the repository administrator via email
Using Prior Knowledge for Verification and Elimination of Stationary
and Variable Objects in Real-time Images
by
FORAM PRAVINKUMAR PATEL
A THESIS
Submitted to the Faculty of Graduate Studies
Through Computer Science
In Partial Fulfilment of the Requirements for
The Degree of Master of Science at the
University of Windsor
Windsor, Ontario, Canada
2019
Using Prior Knowledge for Verification and Elimination of Stationary
and Variable Objects in Real-time Images
by
FORAM PRAVINKUMAR PATEL
APPROVED BY:
______________________________________________
M. Hlynka
Department of Mathematics and Statistics
______________________________________________
A. Mukhopadhyay
School of Computer Science
______________________________________________
X. Yuan, Advisor
School of Computer Science
iii
Declaration of Originality
I hereby certify that I am the sole author of this thesis and that no part of this
thesis has been published or submitted for publication.
I certify that, to the best of my knowledge, my thesis does not infringe upon
anyone’s copyright nor violate any proprietary rights. Any ideas, techniques,
quotations, or any other material from the work of other people included in my
thesis, published or otherwise, are fully acknowledged in accordance with the
standard referencing practices. Furthermore, to the extent that I have included
copyrighted material that surpasses the bounds of fair dealing within the meaning of
the Canada Copyright Act, I certify that I have obtained a written permission from
the copyright owner(s) to include such material(s) in my thesis and have included
copies of such copyright clearances to my appendix.
I declare that this is a true copy of my thesis, including any final revisions,
as approved by my thesis committee and the Graduate Studies office and that this
thesis has not been submitted for a higher degree to any other University or
iv
Abstract
With the evolving technologies in the autonomous vehicle industry, now it has
become possible for automobile passengers to sit relaxed instead of driving the car.
Technologies like object detection, object identification, and image segmentation
have enabled an autonomous car to identify and detect an object on the road in order
to drive safely. While an autonomous car drives by itself on the road, the types of
objects surrounding the car can be dynamic (e.g., cars and pedestrians), stationary
(e.g., buildings and benches), and variable (e.g., trees) depending on if the location
or shape of an object changes or not. Different from the existing image-based
approaches to detect and recognize objects in the scene, in this research 3D virtual
world is employed to verify and eliminate stationary and variable objects to allow
the autonomous car to focus on dynamic objects that may cause danger to its driving.
This methodology takes advantage of prior knowledge of stationary and variable
objects presented in a virtual city and verifies their existence in a real-time scene by
matching keypoints between the virtual and real objects. In case of a stationary or
variable object that does not exist in the virtual world due to incomplete pre-existing
information, this method uses machine learning for object detection. Verified
objects are then removed from the real-time image with a combined algorithm using
contour detection and class activation map (CAM), which helps to enhance the
v
Dedication
vi
Acknowledgements
Throughout this thesis, I have received excellent support and guidance. Firstly, I
would like to express my sincere gratitude to my advisor, Dr. Xiaobu Yuan, for his
continuous support, motivation and immense knowledge. As a mentor, his direction
supported me all the time to learn something new and to complete this research. I
would like to thank my thesis committee members, Dr. Asish Mukhopadhyay and
Dr. Myron Hlynka for their meaningful remarks and recommendations.
I am grateful to my family, whose love, motivation and positive thoughts
strengthened me to reach closer to my ambition. They are the role models and the
source of my inspiration. Last but not the least, I would like to thank all the faculties
and staff of the School of Computer Science and my friends who encouraged me at
vii
Table of Contents
Declaration of Originality ... ii
Abstract ... iv
Dedication ... v
Acknowledgements ... vi
List of Figures ... x
List of Abbreviations/Symbols ... xiii
List of Tables ... xiv
Chapter 1: Introduction ... 1
1.1 Overview ... 1
1.2 Google’s Self Driving Car ... 2
1.3 Need to aware of surroundings ... 3
1.4 Object Detection ... 4
1.5 Feature Detection and Selection ... 5
1.6 Object Elimination ... 5
Chapter 2: Literature Review ... 7
2.1 Object Detection ... 7
2.1.1 Machine Learning Approach ... 8
2.1.2 Deep Learning Approach ... 11
2.2 Feature Detection and Selection ... 15
2.3 Object Verification ... 18
2.4 Transfer Learning ... 20
2.5 Class Activation Map (CAM) Generation and Usage ... 22
2.6 Object Elimination ... 24
2.6.1 Instance Segmentation ... 24
2.6.2 Diminished Reality ... 27
2.7 Related Work ... 28
2.8 Thesis Statement ... 30
2.8.1 Problem Statement ... 30
viii
Chapter 3: Proposed Approach ... 32
3.1 Motivation ... 32
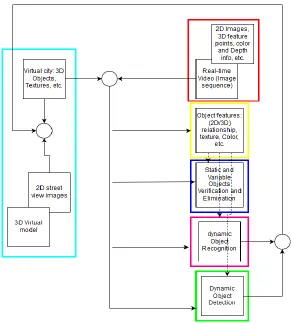
3.2 Working of the Overall System ... 32
3.2.1 Working of Individual Modules ... 33
3.3 Proposed Methodology for Static and Variable Object Verification and Object Elimination ... 36
3.3.1 Static and Variable Object Verification ... 36
3.3.1.1 Object detection module ... 37
3.3.1.2 Feature Detection module ... 37
3.3.1.3 Feature Selection module ... 38
3.3.1.4 Object Verification module ... 39
3.3.1.5 Object Verification algorithm ... 39
3.3.2 Static and Variable Object Elimination ... 41
3.3.2.1 Contour Detection Module ... 42
3.3.2.2 Generation of Class Activation Map (CAM) ... 42
3.3.2.3 Object Masking ... 43
3.3.2.4 Object Elimination algorithm ... 43
3.4 Time Complexity of the Proposed Approach ... 44
Chapter 4: Implementation and Experiments ... 45
4.1 Software Information ... 45
4.2 Construction of 3D Virtual World ... 45
4.3 Creation of Repository of Virtual World ... 46
4.4 Experiments and Results of Object Detection ... 47
4.4.1 Experiments and Results of Object Detection for Buildings ... 48
4.4.2 Experiments and Results of Object Detection for Tree ... 48
4.4.3 Experiments and Results of Object Detection for Street light ... 49
4.4.4 Experiments and Results of Object Detection for Bench ... 50
4.5 Experiments and Results of Object Verification ... 51
4.5.1 Centroid Detection of Real-time Static Object ... 51
4.5.2 Feature Detection Using FAST corner Detector of Real-time Object . 52 4.5.3 Calculation of the Distance of Real-time Object ... 52
4.5.4 Feature Selection in Real-time Image ... 52
ix
4.5.6 Object Verification of Static Object Using Prior Knowledge ... 53
4.5.7 Increasing the Confidence Score Using Neighbour Object ... 54
4.6 Experiments and Results of Object Elimination ... 55
4.6.1 Results of Generation of Class Activation Map (CAM) ... 55
4.6.2 Results of Contour Detection ... 57
4.6.3 Results of Object Elimination Using Combined Approach ... 60
4.7 Results Comparison and Discussion ... 62
4.7.1 Advantages of the Proposed Approach ... 62
4.8 Limitations of the Proposed Approach ... 64
Chapter 5: Conclusion and Future Work ... 66
5.1 Conclusion ... 66
5.2 Future Work ... 67
References/Bibliography ... 68
x
List of Figures
Figure 1: Google’s Self-Driving Car prototype ... 2
Figure 2: Google’s Autonomous Car driving on the road ... 4
Figure 3: Dynamic Object Detection ... 4
Figure 4: Detected features on a chessboard ... 5
Figure 5: Object Masking using Mask-R-CNN ... 6
Figure 6: Object Detection to identify different objects ... 7
Figure 7: Machine Learning algorithm workflow ... 8
Figure 8: Example of a CSVM network (Image source: Yakoub et al., [19]) ... 9
Figure 9: AdaBoost HOG detector applied on a test image (Image Source: Arunmozhi et al., [24])... 10
Figure 10: Deep Learning Approach Workflow ... 11
Figure 11: The architecture of R-CNN (Image source: Girshick et al., [49]) ... 12
Figure 12: The Architecture of Fast R-CNN (Image source: Girshick et al., [48]) 12 Figure 13: The architecture of Faster R-CNN (Image source: Ren et al., [47]) ... 13
Figure 14: Illustration of YOLO (Image source: Redmon et al., [40]) ... 14
Figure 15: object detection results (Image source: Tian et al., [42]) ... 15
Figure 16: Different types of detected features... 16
Figure 17: Feature Selection workflow... 16
Figure 18: Harris-Stephens Corner Detection (Image source: Haggui et al., [63]) 18 Figure 19: Image matching based on different corner detection methods. a Harris method, b the method in [75] ... 18
Figure 20: Overall system overview of DCNN approach (Image source: Chen et al., [78]) ... 19
Figure 21: Training the entire model Vs Transfer Learning ... 20
Figure 22: Three strategies for fine-tuning ... 21
Figure 23: Generated CAM for different breeds of dog using CNN ... 22
Figure 24: CCAM applied to localize common objects (Image source: Li et al., [108])... 23
xi
Figure 26: Segmented results: a. initial contours and local region; b. Final evolved
contours; c. segmented result (Image source: Lu et al. [109]) ... 25
Figure 27: Mask R-CNN framework for instance segmentation (Image source: He et al., [115]) ... 26
Figure 28: Concept of Diminished Reality ... 27
Figure 29: Diminished reality techniques: a. diminish, b. Seeing through, c. replacing, d. inpainting (Image source: Mori et al., [12]) ... 28
Figure 30: Overall system architecture ... 33
Figure 31: Architecture of the proposed approach ... 36
Figure 32: Flowchart of object verification component ... 37
Figure 33: Pixel P selected as a corner point ... 38
Figure 34: Flowchart of object elimination component ... 41
Figure 35: Constructed 3D virtual World ... 46
Figure 36: Constructed 3D Objects... 46
Figure 37: Rendered 3D object ... 47
Figure 38: Extracted 3D features on rendered images ... 47
Figure 39: Detected Skyscraper, Street light, Tree in the real-time image ... 48
Figure 40: Detected Skyscraper, Tree in the real-time image ... 48
Figure 41: Detection of Tree in the image ... 49
Figure 42: Detected Trees, Skyscraper in the real-time image ... 49
Figure 43: Street light, Trees detected in the test image ... 50
Figure 44: Street light, Trees detected in the test image ... 50
Figure 45: Bench detected in the test image ... 51
Figure 46: Centroid Calculation... 51
Figure 47: Detected centroid in the real-time image with coordinates ... 51
Figure 48: Detection of corner points using the FAST algorithm ... 52
Figure 49: Detected corner points on real-time image... 52
Figure 50: Calculating the distance between keypoints and centroid ... 52
Figure 51: Selected top 8 keypoints for top-right (1st quadrant) ... 53
Figure 52: Plotted selected keypoints on the real-time image ... 53
xii
Figure 54: Object verification result of real-time object ... 54
Figure 55: Selected keypoints of the virtual nearest static object (e.g. building) ... 54
Figure 56: Selected keypoints of the real-time nearest static object (e.g. building) ... 55
Figure 57: Verification result of neighbour stationary object (e.g. building) ... 55
Figure 58: Increased confidence score of a verified static object ... 55
Figure 59: Result of CAM Generation of Tree (left: input image, centre: generated heatmap, right: heatmap superimposed on input image) ... 56
Figure 60: Result of CAM Generation of Street light (left: input image, centre: generated heatmap, right: heatmap superimposed on input image) ... 57
Figure 61: Result of CAM Generation of Street light (left: input image, centre: generated heatmap, right: heatmap superimposed on input image) ... 57
Figure 62: Result of Contour Detection of Trees ... 58
Figure 63: Result of Contour Detection of Street light ... 59
Figure 64: Result of Contour Detection of Bench ... 59
Figure 65: Result of Contour Detection of Buildings ... 60
Figure 66: Result of Object Elimination of Trees ... 60
Figure 67: Result of Object Elimination of Street light ... 61
Figure 68: Result of Object Elimination of Bench ... 61
Figure 69: Result of Object Elimination of Buildings ... 61
Figure 70: Result of the proposed algorithm ... 62
Figure 71: Person Detected in the poster using RetinaNet model ... 63
Figure 72: Reflection of car and person on the building detected as a dynamic object ... 63
Figure 73: Detection of dynamic objects after object elimination ... 64
xiii
List of Abbreviations/Symbols
LiDAR Light Detection and Ranging
RADAR Radio Detection and Ranging
GPS Global Positioning System
3D 3-dimensional
2D 2-dimensional
CNN Convolutional Neural Network
ANN Artificial Neural Network
R-CNN Region Based Convolutional Neural
Network
YOLO You Only Load Once
ROI Region of Interest
FCN Fully Convolutional Network
SIFT Scale Invariant Feature Transformation
ORB Oriented FAST and Rotated BRIEF
BRIEF Binary Robust Independent Elementary
Features
SOA Service Oriented Architecture
SURF Speeded Up Robust Features
FAST Features from Accelerated Segment
Test
CAM Class Activation Map
xiv
List of Tables
Table 1: Related Work ... 30
Table 2: Time complexity of the proposed algorithm ... 44
1
Chapter 1: Introduction
1.1 Overview
With the aid of significant technologies and researches, now the vision of
self-driving car on the road has become a possibility to run on the road. It is not a
jaw-dropping concept as research in this direction has been carried out for years.
Seemingly within just a few years, autonomous cars have gone from science fiction
fantasy to road-bound reality [1]. Apart from many automobile giants like Tesla,
GMC, Uber, and Mercedes-Benz, there are many other technology corporations like
Google, Apple, IBM, and Intel that have infused billions of dollars in this research
and development to turn this arduous vision of a fully autonomous car into an
actuality. Nowadays, self-driving cars are being tested on the road, but they are far
away from being feasible [2]. The design of such an advanced machine involves
immense expertise to ensure smooth and safe driving.
While an autonomous car operates on the road, the knowledge of surroundings that
consist of various objects mainly differentiated according to the orientations and
movement should be taken into consideration. When a 3D virtual world is
constructed with representations of static and variable objects in the real world, it
helps the autonomous car to be familiar with the surroundings while driving. Darms
et al. [3] and Hu et al. [4] have described static objects as those that do not move
during the operation of the car. The list includes buildings and other roadside objects
like benches, trees, and light pole. Fu, Kun, et al. have used multiple class activation
map to extract discriminative parts of aircraft of different categories [5]. Verified
objects are masked out in the real-time images.
The new method of this thesis makes use of a constructed virtual environment that
works as prior knowledge to outperform various tasks such as object verification
and elimination. The existence of the real objects is verified by matching feature
2
using the combined approach of contour detection and class activation map (CAM).
This research aims to use pre-existing information to verify and eliminate stationary
and variable objects from real-time scenes to allow an autonomous car to pay
attention to moving objects like pedestrians and cars in order to drive safely.
1.2 Google’s Self Driving Car
Many auto-giants companies like Tesla, Mercedes, Uber, Google, BMW, and Volvo
have already developed their semi-autonomous cars on the market. Zhao et al.
explained the key technology of a self-driving car [6]. Despite using exclusive
hardware, autonomous vehicles are still far from being fully automatic. Google has
started constructing a self-driving car – waymo almost ten years ago. In 2015,
Google provided "the world's first fully driverless ride on public roads" to a legally
blind friend of principal engineer Nathaniel Fairfield [7]. Figure 1 displays the
Google’s autonomous car. Much tech-savvy hardware is being used to improve
visibility, to measure the distance to other objects, and to fetch geolocation
information. Although some of the hardware are expensive, they are necessary as
these sensors assist in detecting objects for safe driving. The rotating roof-top
LiDAR is considered as the heart for object detection. The LiDAR is used to
measure the distance to other objects to build the 3D map in order to see obstacles.
The bumper-mounted radar is responsible for measuring the distance to vehicles in
front and behind the car. Rear-mounted aerial receives geolocation information from
GPS satellites, and ultrasonic sensors attached to one of the rear wheels monitors
the car’s movement. These devices are necessary for the safe operation of
autonomous cars.
3
1.3 Need to Aware of Surroundings
Situational awareness is the most essential key to safe driving. Drivers should be
conscious of their location and the surroundings to navigate the car at the desired
location [128]. The same objective has been applied for an autonomous vehicle to
function on the road by recognizing objects and obstacles. When an autonomous car
is running on the road, it must be responsive to the surroundings for safe moving.
Sensor technologies including GPS provide information about the surrounding
environment. These sensors gather data to narrate the change in the position and
orientation of the car. They constantly pass on the information about surroundings
like the position of pedestrians, and other objects near the car to the system in order
to navigate smoothly.
There are mainly three categories of objects a car may come in the contact while
driving:
▪ Stationary objects: Those objects that are static at the same location with the
same pose. (e.g. Buildings, Bench, Street light)
▪ Variable objects: Those objects that stay stable at the same place, but a pose
may vary (e.g. trees)
▪ Dynamic objects: Those object that may change the location and pose (e.g.
human, animal, car)
Among all objects, dynamic objects create more danger to a self-driving car. These
objects need to be detected. Darms et al. [3] and Hu et al. [4] have described dynamic
objects as those potentially move during the observation periods. Figure 2 shows
how an autonomous car observes the surroundings while driving with the aid of
4
Figure 2: Google’s Autonomous Car driving on the road
1.4 Object Detection
Sensors attached to the car are responsible to estimate distance and steer clear of
collision with obstacles. The nearby objects are identified using various machine
learning algorithms of object detection. Druzhkov et al. [8] published a survey of
deep learning techniques for object detection and image classification. A domain
shift framework based on image-style level and instance-level algorithm based on
Faster- RCNN has been used for object detection [9]. Object classification has been
performed using a fusion of CNN and light detection and ranging (LIDAR) for an
autonomous vehicle [10]. Figure 3 depicts the object detection task where dynamic
objects are located and displayed using bounding boxes with the respective class
label and probability score. The proposed approach detects roadside stationary (e.g.
buildings, street light) and variable (e.g. trees) objects using Faster-RCNN
technique. The model has been trained to detect an instance of an object in the
real-time scene.
5
1.5 Feature Detection and Selection
Feature plays a significant role in various image-based applications. It can be
expounded as a vector to define an object or its accompaniment. Features are specific
structure in the image such as edges, corners, blobs, and points. Different feature
detection algorithms are Harris Corner detection, Shi-Tomasi Corner detector and
Good Feature Track, SIFT, SURF, FAST algorithm for corner detection, BRIEF,
and ORB. The survey of feature detection algorithm is presented by Li et al. [11].
The paper also presents mathematical models of algorithms. Performance
comparison of various algorithms is presented based on accuracy, speed, scale
invariance, and rotation invariance. Figure 4 shows the detected corner points using
Harris corner detection algorithm. The proposed approach detects corner keypoints
using feature detector and the most relevant feature points are selected using the
mathematical approach.
Figure 4: Detected features on a chessboard
1.6 Object Elimination
A part of a scene can be hidden as they were behind an invisible object using
masking technologies. Object elimination can be implemented for various tasks like
background removal, foreground subtraction, object detection, instance
segmentation. Multiple approaches to perform elimination include contour
detection, Mask-RCNN, diminished reality. A survey of different diminished reality
techniques has been published by Mori et al. [12]. Yang et al. [13] introduced a
contour detection framework using fully convolutional Encoder-Decoder Network
6
Mask-RCNN algorithm. The proposed method uses a combined approach of contour
detection and class activation map for object elimination.
Figure 5: Object Masking using Mask-R-CNN
This research work is the primary approach for stationary (e.g. buildings, street light,
benches) and variable (e.g. Trees) object verification and object elimination in
real-time images giving the insights for an autonomous car to navigate smoothly on the
road. The proposed approach performs verification task by matching interest points
extracted from a real-world object with a virtual world object. Once the object is
verified successfully, the removal of static and variable objects in the real-time scene
is executed via the fusion method of contour detection and Class Activation Map
(CAM) to achieve more accuracy.
In this thesis, Chapter 2 entails a review of the previous work done on object
detection and object elimination for autonomous vehicles. It also caters to the
criterion techniques for the proposed approach. Chapter 3 describes the proposed
system of use of prior data for object verification and elimination in the real-time
scene in depth. Chapter 4 demonstrates a detailed explanation of the proposed
approach using experimental results and presents comparison with other related
work. Chapter 5 contains the conclusion of the thesis together with possible future
7
Chapter 2: Literature Review
This chapter provides a survey of the relevant background of recent works in object
detection and object elimination using 2D and 3D images. It also covers use of prior
knowledge to help improving the performance of object verification and object
elimination.
2.1 Object Detection
Object detection is related to computer vision and image processing that locates
instances of objects of a certain class in still images and videos. Object detection has
many applications in computer vision area such as face detection, image retrieval,
and pedestrian recognition. Figure 6 below displays an illustration of object
detection algorithm to identify roadside objects (e.g. car, traffic light, truck) [14].
Zou et al. [15] discussed a survey of object detection in the last 20 years. This survey
covers milestone detectors in history, detection datasets, metrics, fundamental
building blocks of the recognition system, speed up techniques, and the recent state
of the art detection methods. It also reviews some important identification
applications, such as pedestrian detection, face detection, and text detection, etc.,
and makes an in-deep analysis of their challenges as well as technical improvements
in recent years.
Figure 6: Object Detection to identify different objects
Methods of object detection mainly fall into either Machine Learning-based
8
2.1.1 Machine Learning Approach
In machine learning approaches, it is necessary to first define features using any one
method listed below. Then classification is performed on the detected features using
a technique such as Support Vector Machine (SVM), and Random Forest (RF) [69].
• Viola-Jones Object detection framework based on Haar features • Scale-Invariant Feature Transform (SIFT)
• Histogram of Oriented Gradients (HOG) features
Erickson et al. [16] published a paper that uses machine learning for medical
imaging. They have also reviewed different classification such as Naïve Bayes,
Support Vector Machine, Neural Networks, k-Nearest Neighbours, Deep Learning,
and Decision Tree to select suitable features. Figure 7 below portrays the workflow
of general machine learning algorithms.
Figure 7: Machine Learning algorithm workflow
Lei et al. [17] analyzed the feature selection techniques for object-based
classification of unmanned aerial vehicle imagery. Their work specifically emphases
on assessing the effect of feature dimensionality and training the set size using SVM
and RF classifiers to achieve different feature selection methods, including the filter
method, wrappers, and embedded methods. Bakhshipour et al. [18] illustrated an
algorithm for weed detection based on their pattern by applying support vector
machine and artificial neural network. Their work also involves the use of shape
features such as Fourier descriptors and moment invariant features. The
9 An approach of Convolutional SVM Network was applied for object detection in
UAV Imagery [19]. The CSVM network is based on several alternating
convolutional and reduction layers ended by a linear SVM classification layer. The
convolutional layers in CSVM rely on a set of linear SVMs as filter banks for feature
map generation. During the learning phase, the weights of the SVM filters are
estimated through a forward supervised learning strategy unlike the backpropagation
algorithm widely used in standard convolutional neural networks (CNNs) [19].
Figure 8 below illustrates the architecture of the Convolutional SVM algorithm.
Figure 8: Example of a CSVM network (Image source: Yakoub et al., [19])
Wei et al. [20] designed an approach for multi-vehicle detection by combining Haar
and HOG features. This algorithm makes full use of HOG characteristics and uses
its good descriptive ability to describe target vehicles whereas Harr features are
utilized to extract the prospect region of interest (ROI). Moreover, the obtained HOG
features from the ROI target area can be selected by applying the cascade structured
AdaBoost classifier features and target area classification. The precise target can be
further detected by a Support Vector Machine (SVM) [20]. Chee et al. [21] proposed
an algorithm for Pedestrian detection through the fusion of image gradient and
magnitude properties extracted using Histogram of Oriented Gradient (HOG) and
Histogram of Magnitude (HOM) features.
An automatic method for the recognition of individual oil palm trees using images
from unmanned aerial vehicles (UAVs) was developed by Wang et al. [22]. First,
using a support vector machine (SVM) classifier, UAVs images are categorized
between vegetation and non-vegetation. Then, a feature descriptor based on the
10
features for machine learning. Finally, SVM classifier has been trained and
optimized using the HOG features from positive (i.e., oil palm trees) and negative
samples (i.e., objects other than oil palm trees) [22]. An approach for object
detection and classification was published by Rashid et al. [23] that uses a merged
strategy of deep convolutional neural network and SIFT point features. Firstly, an
improved saliency method is implemented, and the point features are obtained.
Then, DCNN features are extracted from two deep CNN models like VGG and
AlexNet. Thereafter, Reyni entropy-controlled method is executed on DCNN
pooling and the SIFT point matrix for robust feature selection. Finally, the selected
robust features are fused in a matrix by a serial approach, that is later fed to ensemble
classifier for recognition [23]. An analysis of three commonly used strategies,
Histogram of Oriented Gradients (HOG), Haar-like features and Local Binary
Pattern (LBP) for object detection is investigated using a public dataset in [26].
Figure 9 below demonstrations the result of AdaBoost HOG detector on a test image.
A novel algorithm on a mobile system that can notify drivers about the possibility
of collision with pedestrians was developed [24]. The partial Haar transform and
HOG are fused for pedestrian detection.
Figure 9: AdaBoost HOG detector applied on a test image (Image Source:
Arunmozhi et al., [24])
Prasanna et al. [25] built an approach for human tracking system using joint
Haar-like and HOG features where Haar characteristics are used for the object’s structure
and the HOG features for the edge. A set of mixed features is developed with these
11
of robust features. Finally, with the help of SVM classifier, classification is
executed.
2.1.2 Deep Learning Approach
In the Deep Learning Approaches, the algorithms are capable of performing
end-to-end object localization task without defining any features and are based on
Convolutional Neural Network (CNN) [69]. Deep Learning approaches are as
follows:
• Region Proposals (R-CNN, Fast R-CNN, Faster R-CNN) • Single Shot MultiBox Detector (SSD)
• You Only Look Once (YOLO)
Brunetti et al. [27] published a survey on computer vision and object detection
methodologies for pedestrian detection and tracking. Panchpor et al. [29] and
Pouyanfar et al. [31] published a study on various object detection algorithms using
deep learning. Arnold et al. [28] reviewed a survey on 3D object detection methods
that utilize sensors and datasets for autonomous driving. 3D object identification
technique introduces a third dimension that reveals the object’s size and location
information useful for path planning, collision avoidance, and so on [28]. Liu et al.
[30] submitted a survey on advanced techniques for generic object detection.
Sindagiet al. [32] published a survey of the latest approaches of CNN for single
image-based crowd counting.
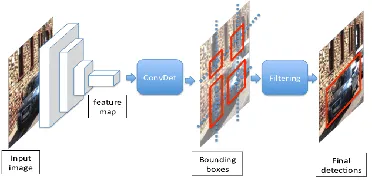
Figure 10: Deep Learning Approach Workflow
Girshick et al. [49] introduced an approach named R-CNN: Regions with CNN
12
illustrates the workflow of deep learning approach. The input to this approach is test
image that locates the object using bounding boxes. Figure 11 shows the architecture
of R-CNN.
Figure 11: The architecture of R-CNN (Image source: Girshick et al., [49])
The algorithm uses a selective search to extract 2000 regions from the input image
that are wrapped into a square and fed into CNN to produce 4096-dimensional
feature vector. The CNN works as a feature extractor and the output dense layer
consists of the extracted features that are forwarded to SVM classifier to identify the
presence of an object within the bounding box. The problem with R-CNN is that it
takes 47 seconds to generate an output. Also, it requires much time for training as
2000 regions for each image need to be classified.
Girshick et al. [48] developed an enhanced approach of R-CNN, i.e., Fast R-CNN
algorithm. Fast R-CNN requires less time to generate an output than simple R-CNN.
The architecture of Fast R-CNN is shown in Figure 12.
Figure 12: The Architecture of Fast R-CNN (Image source: Girshick et al., [48])
According to Fast R-CNN algorithm, the input image is directly fed into CNN to
13
obtained. Then using ROI pooling layer, all the proposed regions are reshaped into
a fixed size to be fed into a fully connected layer. The corresponding class label of
the proposed region and offset value of the bounding box are predicted using
soft-max layer. The Fast R-CNN is faster than R-CNN and the convolution operation is
performed only once per image and feature map is generated from it.
Ren et al. [47] built an improved approach of Fast R-CNN called Faster R-CNN.
Figure 13 depicts the architecture of Faster R-CNN.
In Faster R-CNN, the input image is supplied to CNN to create a convolutional
feature map. Instead of using a selective search algorithm, a separate network is used
to predict the region proposals. The expected region proposals are reshaped into a
fixed size using ROI layer to classify the image within the proposed region and
estimate the offset values for the bounding boxes using soft-max layer.
Figure 13: The architecture of Faster R-CNN (Image source: Ren et al., [47])
Neumann et al. [44] published a fully annotated dataset including tracking
information for pedestrian detection and tracking at night. The scene is recorded
taking advantage of industry-standard camera including different sensors and
weather conditions. Sheng et al. [46] proposed an approach for vehicle area detection
and vehicle brand classification using RCNN, Faster R-CNN, AlexNet, ResNet,
VGGNet, and GoogLeNet.
Redmon et al. [40] designed YOLO (You Only Look Once) algorithm for object
14 Figure 14: Illustration of YOLO (Image source: Redmon et al., [40])
In YOLO, a single neural network predicts the corresponding class probability and
bounding box. First, the image is split into SxS grid where each grid cell predicts
only single object, containing m bounding box and for each bounding box, the class
probability and offset value are evaluated against a pre-set threshold value to locate
the object.
Verma et al. [33] illustrated an algorithm with a fusion of monocular camera and a
2D Lidar for vehicle detection using YOLO. Possatti et al. [34] proposed to integrate
the power of deep learning-based detection using YOLO with the prior maps utilized
by car platform IARA (Acronym for Intelligent Autonomous Robotic Automobile)
to recognize the relevant traffic lights of predefined routes. Mittal et al. [35]
explained the object detection and classification tasks using YOLO algorithm. Putra
et al. [36] developed an improved approach of YOLO for human and car recognition.
Wang et al. [37], Zhang et al. [38], and Zhang et al. [39] used SSD approach for
object detection. Chowdhury et al. [45] designed Faster R-CNN and SSD approach
for pedestrian intention detection.
Židek et al. [41] built a method for object detection using deep learning technique
trained by 3D virtual models. The CNN model is trained using 2D samples generated
automatically from the 3D virtual models. Loing et al. [43] designed a methodology
for localization without using the single real-time image by utilizing only 3D models
15
named ParallelEye. Faster R-CNN and DPM networks are trained via fusing
ParallelEye virtual dataset with a time image dataset for object detection in
real-time view. Figure 15 shows the results of object detection using two different
models. Top row images are detected using a model purely trained on the real-time
images whereas bottom row objects are detected using a network, trained using
combined virtual and real-time scenes.
Figure 15: object detection results (Image source: Tian et al., [42])
2.2 Feature Detection and Selection
In computer vision and image processing, feature plays a vital role that can be
described as a prominent characteristic of an image. They are benefited to execute
certain tasks such as feature selection, feature matching, object recognition and so
on. Features represent the specific structure in the image such as edges, centroid,
blobs, and points. Berger et al. [72] explained the feature and the actual feature usage
in the industry.
Features are identified using detectors from the image. Feature detection is the
process of finding image features or keypoints of a given type at each pixel that are
somehow special in the image. Several detectors for features detection are as
follows:
• Harris corner detection
• Shi- Tomasi corner detection algorithm
16 Figure 16: Different types of detected features
Feature extraction is the method of computing a descriptor from the pixel around
each interest point using feature descriptors such as SURF, HOG, and FREAK.
Feature starts from an initial set of measured data and builds derived values
(features) intended to be informative and non-redundant, facilitating the subsequent
learning and generalization steps, and in some cases leading to better human
interpretations. Feature extraction is related to dimensionality reduction [76].
In computer vision, feature selection is expounded as a process for creating the new
subset of essential features to enhance generalization by reducing overfitting, and
for dimensionality reduction. Common names for feature selection are variable
selection, attribute selection, or variable subset selection. Feature selection differs
to feature extraction by returning the subset of selected features, whereas feature
extraction defines new features from the function of the original features. Figure 17
portrays the workflow of the feature selection technique.
Figure 17: Feature Selection workflow
Feng et al. [73] designed a method for feature detection and matching using Harris
corner detection algorithm. Making use of Harris corner detection algorithm,
features are obtained. Rotation invariant Feature Descriptor (RFID) is used to
17
detection algorithms proposed in the last four decades. Corner detection algorithms
can be divided into intensity-based, contour-based, and model-based methods.
Intensity-based frameworks are based on measuring local intensity variation of the
image. Contour-based methods identify corners by analyzing the shape of edge
contour. Model-based algorithms extract corners by fitting the local image into a
predefined model [50]. Karim et al. [51] presented a study on the comparison of
feature extraction techniques by combining SURF with FAST and BRISK, followed
by feature matching. Al-Rawabdeh et al. [53] submitted a review on the performance
of FAST-9 and FAST-12 as well as the Harris detector in terms of the repeatability
rate, completeness, and correctness under different threshold values for UAV object
localization. Hore et al. [55]analyzed the performance of SIFT and SURF feature
descriptors in different circumstances such as rotational effect, scaling effect,
illumination effect, and blurring effect to achieve object recognition. Kabir et al.
[64] presented a comparison of four feature detection methods for the modern and
old buildings, including Canny edge detection, Hough line transform, Find
Contours, and Harris Corner. A comparison of four feature detection approaches;
Harris, SURF, FAST, and FREAK, is published by Ghosh et al. [67] for image
mosaicing.
DeTone et al. [52] built a self-supervised approach for training feature detectors and
descriptors to make them suitable for a large number of multi-view geometry
problems. Gao et al. [56] developed a novel method utilizing shadows that
automatically extracts building samples and verifies buildings accurately to enhance
automation and accuracy. Liu et al. [59] presented an automatic methodology for
building area extraction from optical high-resolution imagery using the newly
developed morphological building index (MBI). The new FPGA (Field
Programmable Gate Array) architecture for reuse of sub-image data was introduced
in [54]. In the proposed architecture, a remainder-based approach is firstly designed
for reading the sub-image and a fusion of FAST and BRIEF (Binary Robust
Independent Elementary Features) descriptors is used for corner detection and
18
algorithm against various image distortions such as rotation, scaling, fisheye, and
motion distortion.
Zhao et al. [61] built a method to estimate the height of the building using both
corner points and roofline. Haggui et al. [63] developed an approach using Harris
corner detector for NUMA manycore recognition. Figure 18 shows the Harris corner
identification on NUMA manycore.
Figure 18: Harris-Stephens Corner Detection (Image source: Haggui et al., [63])
Wu et al. [57] proposed and implemented Deep Validation, a novel framework for
real-world error-inducing corner detection using DNN-based system. A novel
framework for corner detection and tracking for the real-time scene was presented
in [58]. Ghandour et al. [60] designed Building Detection with Shadow Verification
(BDSV) for building localization using the shadow, shape, and color features of
buildings. Hu et al. [62] illustrated a non-interactive approach based on binary
feature classification for building area recognition and building contours extraction
from aerial images.
Infrared image matching using SUSAN corner detection was introduced in [75].
Figure 19 displays the comparative result of the proposed approach in [75] with
Harris Corner Detection.
Figure 19: Image matching based on different corner detection methods. a Harris
19
2.3 Object Verification
Verification has been implemented primarily for fingerprint, iris, and face matching.
Chen et al. [78] proposed an approach for unconstrained face verification practicing
Deep CNN features, trained using the CASIAWebFace dataset and the performance
was evaluated on both IJB-A and LFW datasets. Figure 20 illustrates the overall
system architecture of the proposed DNN framework for face verification in [78].
Figure 20: Overall system overview of DCNN approach (Image source: Chen et
al., [78])
An approach for video-based unconstrained face verification and recognition was
discussed in [79]. Crosswhite et al. [80] proposed a template adaptation method for
face verification and identification. Their work also proved that it can be applied to
existing state-of-art methods for enriched performance. Zhang et al. [82] evaluated
a method for animal object detection and segmentation from wildlife monitoring
videos captured by motion-triggered cameras, called camera-traps. First, using
multilevel graph cut, animal object region proposals are generated in the
spatiotemporal domain. Then using developed a cross-frame temporal patch
verification method, these region proposals are determined if they are true animals
or background patches.
Hsu et al. [83] developed an architecture for vehicle verification between two
nonoverlapped views using sparse representation. Karami et al. [66] published a
survey of image matching technologies- SIFT, SURF, BRIEF, and ORB. Taira et al.
[84] built a system for indoor object localization that estimates the 6DoF camera
20 proposed an approach for retina verification based on Structural Similarity (SSIM)
to verify using similarity score. Kavitha et al. [86] designed an approach for a
secured voting system using face, iris, and fingerprint verification. Qin et al. [87]
suggested a deep learning-based segmentation methodology for finger-vein
verification by training CNN to extract the vein patterns from any image regions and
to estimate the probability of pixels to check if they belong to the vein or the
background. They also made use of FCN to recover missing finger vein shapes for
amended performance.
2.4 Transfer Learning
In machine learning, transfer learning is a method that makes use of knowledge
gained while solving one problem to apply it for a different but related problem. For
instance, knowledge obtained to recognize a cat can be applied for dog recognition.
Some widely used pre-trained models are:
• VGG • InceptionV3 • ResNet5
Figure 21 below illustrates the difference between training the entire model and
using transfer learning.
Figure 21: Training the entire model Vs Transfer Learning
The pre-trained models are primarily trained on the large dataset and, for a new
similar dataset, the pre-trained model weights can be used for extracting the features.
21
classifier of the model has been removed and new classifier has been added to
perform a defined task and later fine-tuned using any one of the following strategies:
1. Train the entire model: Use the architecture of the pre-trained model and
train it according to the dataset from scratch.
2. Train some layers and leave the others frozen: For the small dataset, freeze
more layers to prevent overfitting whereas for a large dataset, train more
layers.
3. Freeze the convolutional base: The convolutional layer is set in its original
form and its output is used for the classification task.
Figure 22 presents these 3 strategies of fine-tuning in a graphical way.
.
Figure 22: Three strategies for fine-tuning
Weiss et al. [97] reviewed the transfer learning methodology and its applications.
Huh et al. [96] proposed an approach where they used pre-trained CNN features on
various subsets of the ImageNet dataset and evaluated transfer performance on a
variety of standard vision tasks. Yuan et al. [91] presented a learning-based
framework for shadow removal using an online learning strategy and fine-tuned with
the automatically identified examples in the new videos. Wang et al. [94] developed
an architecture for ship detection via fusion of single shot multiBox detector (SSD)
and transfer learning. A system for end-to-end airplane detection in remote sensing
images using transfer learning approach is presented in [92]. Kapur et al. [90] used
transfer learning for object detection in real-time video. A deep learning-based
22 Mohamed et al. [88] presented a work on applications of transfer learning for object
detection. Yabuki et al. [89] and Singh et al. [93] designed a method for object
detection using transfer learning based on CNN with feature extractor technique.
2.5 Class Activation Map (CAM) Generation and Usage
A Class Activation Map (CAM) is a technique for producing discriminative image
regions used by CNN to identify defined class in the input image. CAM allows us
to observe at which image regions CNN is looking and appropriate to a specific
class. Zhou et al [98] proposed a framework of re-using the trained classifier for
getting good localization of distinct class, without having bounding box coordinates
information. Figure 23 presents the generated class activation map for different
breeds of dog using CNN.
Figure 23: Generated CAM for different breeds of dog using CNN
CAM delivers certain assurance that the model has correctly learned the distinctive
features between multiple categories in the form of visualization. Moreover, it
conveys us to see what features are guiding the model’s decision to classify various
objects in the input image that are used by the model to make a prediction.
These means are pursued to generate class activation map:
1. The pre-trained network is used and most of its weights are freezed
2. The model is modified and fine-tuned to generate CAM output
3. Classifier is trained
4. The last convolutional layer is used to create CAM output
23
To generate CAM, the network architecture is limited to have a global average
pooling layer after the last convolutional layer, followed by the dense layer. To get
this model structure, the network is modified and fine-tuned to get CAM.
In detail, the first building block for this layer is a convolutional layer that produces
an output shape of in terms of batch size, number of filters, width, height. The output
from the GAP layer is treated by the dense layer and softmax layer to assign a weight
to each of the categories that set the importance of each the convolutional layer
output. To generate CAM, output images from the convolutional layer are multiplied
by their assigned weights and added. By superimposing the class activation map on
input image allows us to identify the most essential image regions to the specific
category.
Kwaśniewska et al. [99] demonstrate a method of face detection from low-resolution
thermal images and the most relevant area is highlighted. Tang et al. [101] proposed
a deep discriminative map network for visual tracking. The system utilizes two
neural networks for positioning and size change estimation. Guo et al. [103]
developed a methodology to recognize human attributes without the detection of a
body part and the prior correspondence between body parts and attributes with the
help of CAM network. Li et al. [105] showed a framework for remote sensing image
scene classification using CAM. The attention map is generated using a pre-trained
network as priors for the classification task that are used as an explicit input to
end-to-end training for the first time, aiming to force the network to focus more on the
most appropriate parts. Li et al. [108] used CAM to localize common objects in an
input image. Figure 24 displays the result of produced CAM to locate common
objects.
Figure 24: CCAM applied to localize common objects (Image source: Li et al.,
24 Charuchinda et al. [106] introduced a technique to build an image classification
network using class activation map (CAM) to identify whether each sub-image
contains the class of interest. The output of the CAM is the filter response where
pixels with high probability are likely to belong to the class of interest. Vasu et al.
[107] made use of class activation map to obtain a view of deep network’s perception
of aerial imagery and identify salient local regions. Moreover, the concept of
transfer-learning is involved to train the model on a similar dataset. Fu et al. [13]
applied a methodology of multi-class activation map for recognition of aircraft in
the remote sensing images.
Pericherla et al. [100] designed an approach to reduce the L2 distance i.e., Euclidean
distance between produced adversarial images and the original images using class
activation map. Selvaraju et al. [102] introduced Grad-CAM model for class
discriminative localization from any CNN-based network without modification and
re-training and applied for image classification and captioning. Kumar et al. [104]
developed a method for visualization and to understand the decisions made by deep
neural networks (DNNs) for a given specific input.
2.6 Object Elimination
Object elimination is the process of masking or deleting an identified or verified
object from a scene. Masking is a technique of hiding a part or a part of an object as
if it were behind an invisible object. Object elimination can be implemented for
various tasks such as foreground extraction, background removal, object detection,
and instance segmentation. Approaches to implement object masking are as follows:
1. Contour detection-based masking
2. Mask-RCNN
3. Diminished Reality
The detail of each masking methodology is described in the following subsections.
2.6.1 Instance Segmentation
Instance segmentation can be defined as the identification of boundaries of the
25
problem of detecting and delineating each distinct object of interest appearing in the
image. Instance segmentation can be achieved by various technologies like
contour-based and Mask R-CNN. Figure 25 depicts the result of instance segmentation in
the input image.
Figure 25: Example of Instance segmentation
Lu et al. [109] designed a method for lip segmentation. Lip segmentation is the initial
step for the lip-reading system. They proposed an active contour model-based lip
segmentation method that adopts local information. Figure 26 illustrates the result
of lip segmentation using contour detection.
Figure 26: Segmented results: a. initial contours and local region; b. Final
evolved contours; c. segmented result (Image source: Lu et al. [109])
Tesema et al. [110] introduced a methodology for human segmentation in still
images using Deep Contour-Aware Network (DCAN) which is a unified multi-task
deep learning framework combining the complementary object and contour
information simultaneously for better segmentation performance. Griffiths et al.
[111] presented an approach to improve public GIS building footprint labels using
26 [112] discussed a method for vehicle detection and segmentation in the context of
autonomous driving using fully convolutional network for semantic labeling and
estimating the boundary of each vehicle. CNN provides the area around the contours
that aids to separate the vehicle instance. Hayder et al. [113] introduced a distance
transform-based mask representation that allows prediction of instance
segmentations beyond the limits of initial bounding boxes. Chen et al. [81]
developed a framework for more accurate detection and segmentation of histology
images using deep contour-aware network. Yang et al. [13] suggested a deep
learning approach for contour detection using fully convolutional encoder-decoder
network. Li et al. [114] presented a novel method to borrow contour knowledge for
salient object detection.
Mask R-CNN is widely used for instance segmentation. Mask R-CNN locates each
pixel of the object in the image instead of the bounding boxes. He et al. [115]
introduced a novel framework for instance segmentation: Mask R-CNN. Figure 27
shows the framework of Mask R-CNN.
Figure 27: Mask R-CNN framework for instance segmentation (Image source: He
et al., [115])
When an input image is passed to the network, it gives the object bounding box,
classes, and masks on the detected object.
Mask R-CNN contains two stages:Firstly, it generates region proposals where there
might be an object based on the input image. Secondly, it predicts the class of the
object, refines the bounding box and applies a mask in the pixel level of the object
27 Novotny et al. [116] developed an approach for segmenting unknown 3D objects in
real-time depth images using Mask R-CNN, trained on synthetic data. Liu et al.
[117] suggested an improved version of Mask R-CNN for instance segmentation by
applying the features from low levels. Yu et al. [118] built a model for fruit detection
where Mask R-CNN adopts Resnet50 backbone network that is merged with the
Feature Pyramid Network (FPN) architecture for feature extraction. For each feature
map, RPN was trained to create region proposals. After generating mask images of
ripe fruits using Mask R-CNN, a visual localization method for strawberry picking
points was performed. Johnson at al. [119] demonstrated that Mask R-CNN allows
highly effective and efficient segmentation of a wide range of microscopy images
under various conditions and different cells.
2.6.2 Diminished Reality
Diminished Reality (DR) is a technique to virtually remove, hide, and see-through
real objects from the real world. Diminished reality is the conceptual reverse of
Augmented Reality. AR allows us to augment, add virtual world as desired whereas
DR allows erasing physical content from the real-world scene. The real-time
application of diminished reality includes furniture shopping, film studio, city
planning, and interior designing. Figure 28 demonstrates the perception of DR by
removing the glasses in an input image.
Figure 28: Concept of Diminished Reality
Mori et al. [12] published a survey on diminished reality techniques that is beneficial
for virtually erase, hide an object from the real-time scene. They provided a concept
28
executing diminish, seeing through, replace, and inpainting technologies. Figure 29
illustrates the concept of diminished reality methods.
Kawai et al. [120] performed diminished reality using inpainting method for
background geometry removal with fewer constraints than the conventional ones.
Mori et al. [121] designed an approach for capturing and reproducing the real world
as desired using diminished reality.
Figure 29: Diminished reality techniques: a. diminish, b. Seeing through, c.
replacing, d. inpainting (Image source: Mori et al., [12])
Siltanen et al. [122] developed a novel framework for interior designing without
using prior information of textures, via inpainting method. Nakajima et al. [123]
introduced an approach for deleting an object using diminished reality.
2.7 Related Work
The below table 1 highlights correlated work done so far by researchers in the area
closely related to this thesis, including their contributions and scope of
improvements.
Research Paper Contributions Scope of
Improvement
Training and Testing
Object Detectors with
Virtual Images. Tian, Y.,
Presents an artificial way to
construct perceived image
datasets automatically with
precise annotation and
Generated virtual
images can be used
as prior data for
29
Li, X., Wang, K., & Wang,
F. Y. (2018)
trained DPM and Faster
R-CNN with real-time images
and virtual images for object
detection
without training any
object detectors
A new FPGA architecture
of FAST and BRIEF
algorithm for on-board
corner detection and
matching. Huang, J., Zhou,
G., Zhou, X., & Zhang, R.
(2018)
FAST and BRISK
descriptors are combined for
corner detection and
matching.
Corner matching
between real-time
image and virtual
image using the
proposed algorithm
is not described.
Unconstrained face
verification using deep cnn
features. Chen, J. C., Patel,
V. M., & Chellappa, R.
(2016, March)
Face verification is
performed using deep
convolutional features that is
trained using IARPA
dataset.
Training of the
model is required for
face verification that
increases the time.
Localizing Common
Objects Using Common
Component Activation
Map. Li, W., Jafari, O. H.,
& Rother, C. (2019)
Designed CCAM model to
localize common objects in
an image by treating CAM
as components to discover
common elements.
This approach
doesn’t perform
elimination by using
the most relevant
part generated by
CAM.
Lip segmentation using
localized active contour
model with automatic
initial contour. Lu, Y., &
Zhou, T. (2018)
Lip segmentation is
performed using an active
contour-based model.
Requires deep
learning model to
train to get contours
that is
time-consuming.
Semantic object selection
and detection for
Introduced a model for
diminished reality that
Training of the
30
diminished reality based
on SLAM with viewpoint
class. Nakajima, Y., Mori,
S., & Saito, H. (2017,
October).
automatically recognizes the
region to be removed,
without generating the 3D
model of the target object ad
by utilizing SLAM,
segmentation, and
recognition framework.
object detection is
mandatory. This
consumes more
computational
power.
Table 1: Related Work
2.8 Thesis Statement
2.8.1 Problem Statement
Literature survey clearly shows the need to detect dynamic objects accurately while
an autonomous car is driving in order to avoid collisions. According to a literature
survey, recent technologies use machine learning approaches for dynamic object
detection and tracking in real-time that results in training the model and requires
more computational sources. In some cases, the model detects an object that is not
going to move (e.g. a person in the poster) as a dynamic object and gives bounding
box as the trained models are image-based. This ends in consuming more power to
process that exceptional object as a dynamic one. A similar concept applies to a car
when a reflection of a car falls on the glass building, and object detection algorithm
treats that reflection as a dynamic object. The methodologies for object elimination
such as diminished reality, mask R-CNN uses machine learning and requires
training of the model to detect the object that needs to be removed.
The proposed approach of object verification and object elimination uses
constructed 3D virtual world as pre-existing knowledge. The proposed algorithm of
object verification and removal makes use of virtual world to verify physical
stationary (e.g. Buildings) and variable (e.g. Trees) in the real-time environment by
matching keypoints of virtual objects with physical objects without any training. The
proposed method of elimination uses a fusion of contour detection and class
31
removal of stationary and variable objects will improve the accuracy and efficiency
of the dynamic object algorithm.
2.8.2 Thesis Contribution
The major contribution of this thesis can be summarized as follows:
• Constructed 3D virtual model works as prior information for static (e.g.
Building) and variable (e.g. Trees) object verification and elimination in the
real-time scene in order to make dynamic objection algorithm efficient and
accurate.
• The proposed approach of object verification doesn’t require any machine
learning algorithm for training.
• The verified object can be used to geo-locate the self-driving car in a
real-time environment.
• For the objects having pre-existing data, the proposed fusion approach of
contour detection and class activation map (CAM) for object elimination
algorithm can be applied directly without any training.
• In case of objects without having prior knowledge, the model is trained using
transfer learning concept to generate CAM to perform object elimination.
• After applying the object removal algorithm to the real-time image, the
resulting image will be left with dynamic objects making an autonomous car
focus only on those objects that cause more danger. This makes the detection


![Figure 11: The architecture of R-CNN (Image source: Girshick et al., [49])](https://thumb-us.123doks.com/thumbv2/123dok_us/1342451.1167138/27.612.168.450.511.617/figure-architecture-r-cnn-image-source-girshick-et.webp)
![Figure 20: Overall system overview of DCNN approach (Image source: Chen et al., [78])](https://thumb-us.123doks.com/thumbv2/123dok_us/1342451.1167138/34.612.192.426.204.320/figure-overall-overview-dcnn-approach-image-source-chen.webp)