19
Designing An Efficient Real Time Summon Acuity System
For Physically Drained Human
1
SUBA.S,
2DR.MURUGESAN.M
1PG Scholar, Department of Computer Science, SRG Engineering College, Namakkal 2Proffessor & HOD, Department of Computer Science, SRG Engineering College, Namakkal
1[email protected], 2[email protected]
Abstract - Hand-gesture recognition is a method of non-verbal communication for physically drained people for its freer expression much more other than body parts.It is the best method to interact with the computer without using other peripheral devices such as keyboard, mouse. The main objective of this project is to present a vision-based user interface designed to achieve computer accessibility for the people who lack hand fine motor skills. A detection and tracking framework was constructed with unique descriptive features for face and hand representation. A method based on Hidden Markov Model (HMM) is presented for gesture trajectory modeling and recognition. HMM is a powerful statistical tool for modeling a wide range of time series data. Markov Chain Monte Carlo (MCMC) plays a positive role in Bayesian statistical calculation. Image classification is one of classical problem of concern in image processing.Artificial Neural Network classifier is used to classify the gestures. Once gesture is identified, the appropriate command for it will be executed.
Keywords - Artificial Neural Network (ANN), Hand Gesture recognition, Hidden Markov Model (HMM), Markov Chain Monte Carlo (MCMC).
INTRODUCTION
Gesture recognition is a topic in computer science and language technology with the goal of interpreting human gestures via mathematical algorithms. Gestures can originate from any bodily motion or state but commonly originate from the face or hand. Current focuses in the field include emotion recognition from the face and hand gesture recognition. Many approaches have been made using cameras and computer vision algorithms to interpret sign language. However, the identification and recognition of posture, gait, proxemics, and human behaviors is also the subject of gesture recognition techniques. Gesture recognition can be seen as a way for computers to begin to understand human body language, thus building a richer bridge between machines and humans than primitive text user interfaces or even GUIs (graphical user interfaces), which still limit the majority of input to keyboard and mouse. Direct use of hands as an input device is an innovative method for providing natural Human Computer Interaction. Conceiving a future era of human-computer interaction with the implementations of 3D application where the user may be able to move and rotate objects simply by moving and rotating his hand - all without help of any input device.
A hand gesture recognition system has a wide area of application in human-computer
interaction and sign language. Hand gestures can be classified in two categories: static and dynamic. A static gesture is a particular hand configuration and pose represented by a single image. A dynamic gesture is a moving gesture represented by sequence of images. The key problem in hand gesture interaction is how to make hand gestures understood by computers. For hand gesture recognition system, different technologies are used for acquiring input data. They are:
Vision based approaches
Data glove based approaches
Color glove based approaches
a.Vision b. Data Glove c. Color glove based Fig 1: Approaches in Hand Gestures Technology
20
The proposed system presents a more effective and user friendly methods of human computer interaction intelligently with the usage of hand gestures. It can recognize gestures effectively in cluttered backgrounds and also in a non-laboratory environment. It has been designed to be cost effective and uses low cost input tools like webcam for capturing hand as input. The main objective of the proposed system is to develop more effective and robust algorithms to solve false merging and false labeling problems in hand tracking through interaction and occlusion. This system proves the effectiveness of hand gestures as an alternative modality for individuals with mobility impairments by both subjective explanation and quantified results.SYSTEM OVERVIEW
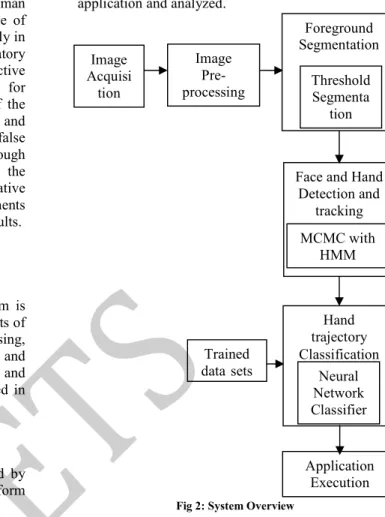
The architecture of the proposed system is illustrated in Fig 2. The Project essentially consists of five parts: Image Acquisition and Pre-processing, Foreground Segmentation, Hand Detection and Tracking, Hand Trajectory Classification and Application Execution. These parts are described in the following sections:
A. Image Acquisition and Pre-processing
The movement of the hand is recorded by web camera and the images are converted into a form that can be processed easily.
B. Foreground Segmentation
Image segmentation partitions an input image into its constituent parts or objects. So in this section, Background is ruled out from the captured frames and the whole body is kept as the foreground.
C. Hand Detection and Tracking
Hand detection is used to initialize the position of hands for the tracking phase. After initialization, hands were tracked through video sequences by Monte Carlo methods.
D. Hand Trajectory Classification
In this section, the identified trajectories are compared with motion models and decoded as commands for the application.
E. Application Execution
The decoded command will be executed in application and analyzed.
Fig 2: System Overview
GESTURE RECOGNITION
A. Image Acquisition and Pre-processing
The first stage of any vision system is the image acquisition stage. After the image has been obtained, various methods of processing can be applied to the image to perform the many different vision tasks required today. Initially the system acquires images captured from a webcam. The output of webcam is basically a video sent to the system which is a homogeneous series of frames. The image acquired from the webcam is 2D color image. So it is converted into 3D by using Stereo 3D Coding algorithm from which depth map image can be obtained. Depth map is created for each frame or a series of homogeneous frames to indicate the depths of objects in the scene.
B. Foreground Segmentation Image
Acquisi tion
Image Pre-processing
Application Execution Trained
datasets
Hand trajectory Classification
Neural Network Classifier Threshold Segmenta
tion Foreground
Segmentation
Face and Hand Detection and
tracking
21
Initially, the user’s body was treated as a foreground object in order to detect the user’s movement. The goal of image segmentation is to partition an image into a certain number of pieces which have coherent features (color, texture, etc.) and in the meanwhile to group the meaningful pieces together for the convenience of perceiving. Threshold is one of the widely methods used for image segmentation. It is useful in discriminating foreground from the background. By selecting an adequate threshold value T, the gray level image can be converted to binary image. The binary image should contain all of the essential information about the position and shape of the objects of interest (foreground). The advantage of obtaining first a binary image is that it reduces the complexity of the data and simplifies the process of recognition and classification.In this paper, segmentation consists of two steps. In the first step, the input image was thresholded using depth information. The depth value of each pixel is defined as D(i.j). Initially, the iteration is started by setting threshold value (T) as average of gray values. A mask image was generated by keeping the pixels with a depth value greater than threshold value while discarding others. For each iteration, means of two regions segmented by T is calculated and by setting this as new threshold value the process is repeated until the difference between successive iteration threshold values is small. In the second step, the region with the largest area was extracted from the mask image. All the remaining regions with an area smaller than TSH were discarded.
TABLE I
FOREGROUND SEGMENTATION ALGORITHM
Algorithm 1: Foreground Segmentation
Input: Threshold T, pixel value of Depth image D(i,j)
Output: Pixel value of mask image D1(i,j); pixel
value of foreground mask image D2(i,j)
D1(i, j)
TSH = max (Area (Bi)) //Bi is the ith blob in the mask
image D;
D2 (i, j)
C. Hand Detection and Tracking
In this section, the centroids of the face and hand regions were extracted to initialize the tracking stage. Skin and nonskin color histograms were created using HSV color space to obtain the mask image as shown in Fig.3(a). To obtain hand regions without the face, a face detector is used to remove the face region from target image. The remaining two largest regions in the target image were selected as hand regions [Fig.3(b)]. The centroids of the hands were obtained by computing the first moment of the two regions. This hand detection is used o initialize tracking procedure. Afterwards the hands positions were continuous tracked by MCMC with HMM techniques.
(a) (b)
Fig 3: Face and hand detection (a) Skin Color Detection (b) Hand Extraction
Tracking can be done by detecting objects at each frame and matching them across time motion heuristics to constrain correspondence problem. At each time instant, the tracking algorithm proceeds in two main stages: first, recursively estimate the states of the currently visible hands relying on the model and solved using a MCMC sampling scheme. The Metropolis–Hastings algorithm is a MCMC method for obtaining a sequence of random samples from a probability distribution for which direct sampling is difficult. This sequence can be used to approximate the distribution or to compute an integral. The main task of this algorithm is given as follows: Sample from p(X) with discrete values X
ϵ{x
j, j≥1}.
Create aMarkov chain Xn. To make its stationary distribution
π(X) equal to p(X) at state Xn = xi, Select a proposal
function q(xi, xj). Generate a sample y with P{Y= xj}
= q(xi, xj) with probability α(xi, xj), set Xn+1 = y and 1
- α(xi, xj) and set Xn+1 = Xn. The transition matrix is
given by equation (1)
Pij = q(xi, xj) α(xi, xj) if j≠ i;
Pii = q(xi, xj) + ∑ k≠ i q(xi, xk) 1 - α(xi, xk) otherwise;
(1) The chain will be time reversible and have stationary probability π(X) if π(xi)Pij = π(xj)Pji for i
≠j. Selecting
α(xi, xj) = min(π(xj)q(xj ,xi)/ π(xi) q(xi, xj), 1)
(2) satisfies
22
Second stage in tracking algorithm is to make a decision on adding a new hand or on deleting currently tracked hands. This operation was carried out by Hidden Markov Model (HMM).TABLE II MCMC ALGORITHM
Algorithm 2: MCMC algorithm To draw N samples from p(X):
Select a proposal distribution q(x2| x1)
Initialize x1
for i = 1 to MaxIteration do Draw y ~ q(y|xi)
α(xi, y) ← min (p(y)q(y,xi)/p(xi)q(xi,y),1)
Draw u ~ Unif(0,1)
if u < α(xi, y) then xi+1 ← y,
else xi+1 ← xi
end if end for
return Last N samples
HMM is rich in mathematical structures and has been found to efficiently model spatial-temporal information in a natural way. Therefore, HMM has been successfully applied for spatial-temporal objects such as gesture recognition and speech recognition. A Hidden Markov Model consists of two stochastic processes. The first stochastic process is a Markov chain that is characterized by states and transition probabilities. The states of the chain are externally not visible, therefore “hidden”. The second stochastic process produces emissions observable at each moment, depending on a state-dependent probability distribution. It is important to notice that the denomination “hidden” while defining a Hidden Markov Model is referred to the states of the Markov chain, not to the parameters of the model. HMM includes three parameters ¸ = (∏; A; B) where ∏ represents initial vector, A is the transition matrix and
B refers to emission matrix. Evaluation, Decoding
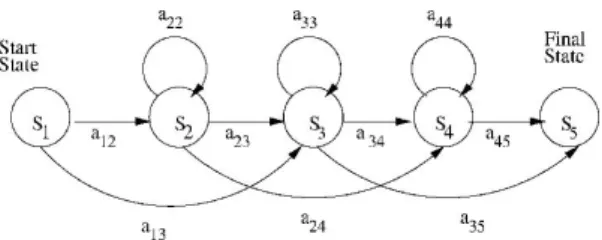
and Training are the main problems of HMM and they can be solved by using Forward-Backward, Viterbiand BW algorithms respectively. Also, HMM has three topologies; Fully Connected (i.e. Ergodic model) where any state can be reached from other states, LR model such that each state can go back to itself or to the following states and LRB model in which each state can go back to itself or the next state only. The isolated and continuous gestures paths are recognized by its discrete vector and HMM Forward algorithm corresponding to maximal gesture models over the Viterbi best path.
Given HMM with state space S, initial probabilities ∏i of being in state i and transition
probabilities aij of transitioning from state i to state j.
Say we observe outputs y1 .. yT. The most likely state
Fig 4: Five-state left-to-right HMM for gesture recognition.
sequence y1 .. yT that produces the observations is
given by the recurrence relations:
(3) Here Vt,k is the probability of the most probable state
sequence responsible for the first t observations that has k as its final state. The Viterbi path can be retrieved by saving back pointers that remember which state xwas used in the second equation. Let Ptr(k,t) be the function that returns the value of x used to compute Vt,k if t > 1, or k if t = 1. Then:
(4)
D. Hand Trajectory Classification
Artificial Neural Network algorithm was employed to classify hand gesture trajectories in the lexicon. Feed Forward Artificial Neural Network (FF-ANN) have non-recurrent architecture and supervised training / learning paradigm. They are also popular because of its universal approximation results, intuitive appeal, simple coding, implementation using back-propagation algorithm and fault tolerance behaviour. The architecture of a FFANN with n inputs in the input layer, one hidden layer with m nodes and a single node in the output layer is given as shown in the Fig. 5.
23
standard deviation of the induced local field of the neurons that lies between linear and standard parts of the sigmoidal activation function.
Fig 5: Architecture of FF-ANN
• Presentation of the training examples: Inputs are given to the network as an epoch of training examples. In the supervised learning, adjustments to the synaptic weights of the network are performed after presentation of all the examples in the training sample that constitute one epoch of training.
• Forward Computation: The induced local fields and function signals of the network are computed by proceeding forward through the network layer-by-layer. Also the error of the desired response vector is computed.
• Backward Computation: The local gradients of the network are computed and adjustments of the synaptic weights of the network using learning rate parameter η and momentum constant α is done. • Iteration: Iterate the forward and the backward computations by presenting new epochs of training examples to the network until the chosen criterion is reached.
E. Application Execution
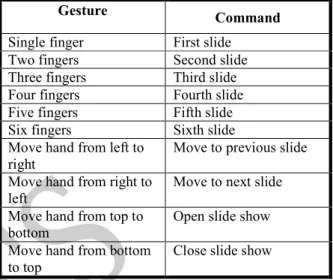
The commands decoded by gesture recognition results were used by various applications. Here PowerPoint slide movement is controlled by the commands decoded from gesture recognition. Initially all the fingers are kept closed and then a gesture for controlling the slides was performed. After a gesture was made all the fingers were closed and after a time delay of 2 seconds the next gesture was made. The Table III shows the gestures and their corresponding command in slide show.
EXPERIMENTAL RESULTS
The tracking performance of these algorithms was evaluated by employing three metrics: false merging, false labeling and tracking accuracy. The false merging is defined as the situation where the tracker of one hand occupies 80%
TABLE III
LIST OF DECODED COMMANDS
Gesture Command
Single finger First slide
Two fingers Second slide
Three fingers Third slide Four fingers Fourth slide Five fingers Fifth slide
Six fingers Sixth slide
Move hand from left to right
Move to previous slide
Move hand from right to left
Move to next slide
Move hand from top to bottom
Open slide show
Move hand from bottom to top
Close slide show
of the area of the other hand. The false labeling is defined as the situation where the trackers of both hands change positions during/after interaction or occlusion. The tracking accuracy is defined by
Tracking Accuracy = Total number of(true positives + true negative)
Total number of tracked frames
(5) A true positive is defined as the situation where as a target object is present and the tracker was able to find it. True negatives are instances where the target object is not present and the tracker also agreed that the object was absent.
24
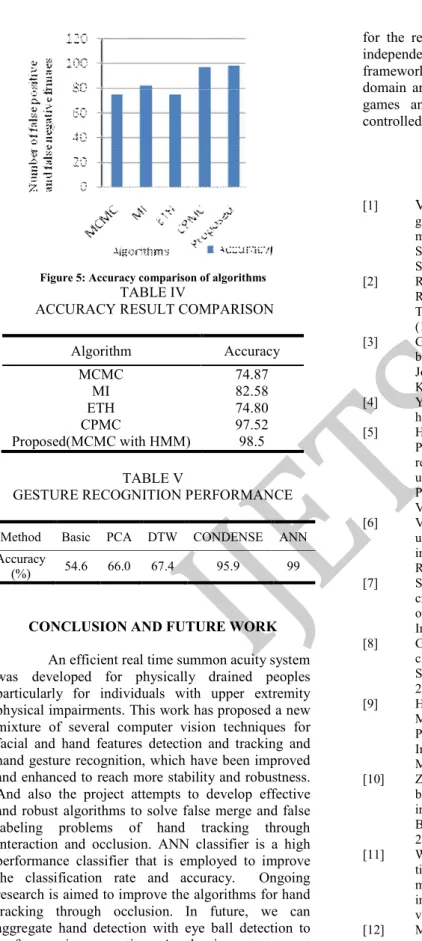
Figure 5: Accuracy comparison of algorithms
TABLE IV
ACCURACY RESULT COMPARISON
Algorithm Accuracy
MCMC 74.87
MI 82.58
ETH 74.80
CPMC 97.52
Proposed(MCMC with HMM) 98.5
TABLE V
GESTURE RECOGNITION PERFORMANCE
Method Basic PCA DTW CONDENSE ANN
Accuracy
(%) 54.6 66.0 67.4 95.9 99
CONCLUSION AND FUTURE WORK
An efficient real time summon acuity system was developed for physically drained peoples particularly for individuals with upper extremity physical impairments. This work has proposed a new mixture of several computer vision techniques for facial and hand features detection and tracking and hand gesture recognition, which have been improved and enhanced to reach more stability and robustness. And also the project attempts to develop effective and robust algorithms to solve false merge and false labeling problems of hand tracking through interaction and occlusion. ANN classifier is a high performance classifier that is employed to improve the classification rate and accuracy. Ongoing research is aimed to improve the algorithms for hand tracking through occlusion. In future, we can aggregate hand detection with eye ball detection to perform various operations. Another important aspect
for the related development could be design of an independent gesture vocabulary framework. This framework could be independent of the application domain and useful for controlling different types of games and other applications dependent on the controlled through user defined gestures.
REFERENCES
[1] Vanco, M; Minarik. I; Rozinaj G, “Dynamic
gesture recognition for next generation home
multimedia,”ELMAR, 201355th International
Symposium, Vol., no., pp 219, 222, 25-27 Sept.2013.
[2] R.Liang, M.Ouhyoung, A Real time Gesture
Recognition system for sign language, Proc. Third IntConf. Autom. Face Gesture Recognition. (1998).
[3] G.R.S Murthy& R.S.Jadon, A Review of
vision-based hand gestures recognition, International
Journal of Information Technology and
Knowledge Management.
[4] Y..Fang, K.Wang, J.Cheng&H.Lu, A Real time
hand gesture recognition method, IEEE 2007.
[5] Hairong Jiang, Bradley SDuerstock, Juan
P.Wachs Member, IEEE,“Facilitated gesture recognition based interfaces for people with upper extremity physical impairments” in Proc. Pattern Recognition, Image Analysis Comp. Vision Applicat,2012, pp 228-235.
[6] Viola and M. Jones, “Rapid object detection
using a boosted cascadeof simple features,” inProc. Int. Conf. Comput. Vision Pattern Recogn. Vol. 1. 2001, pp. 511–518.
[7] Stefan Duffner and Jean-Marc Odobez,”Track
creation and Deletion framework for Long-term online multiface tracking” IEEE transactions on Image Processing, Vol.22, No.1
[8] Guoqiang Peter Zhang, “Neural Networks for
classification-A Survey” IEEE Transactions on Systems, Man, Cybernetics, Vol30. No.4, Nov 2000
[9] H.Jiang, Bradley S. Duerstock, Juan P.Wachs, “A
Machine Vision-Based Gestural Interface for
People with Upper Extremity Physical
Impairments” IEEE Transactions on Systems, Man, Cybernetics, Vol 44, No 5.
[10] Z. Khan, T. Balch, F. Dellaert, “An
MCMC-based particle filter for tracking multiple interacting targets,” in Computer Vision-ECCV. Berlin, Heidelberg, Germany: Springer, 2004, pp. 279–290.
[11] W. Qu, D. Schonfeld, and M. Mohamed,
“Real-time distributed multi-object tracking using multiple interactive trackers and a magnetic-inertiapotential model,”IEEE Trans. Multimedia, vol. 9, no. 3, pp. 511–519,Apr. 2007.
[12] M. Eichner, M. Marin-Jimenez, A. Zisserman,
25
estimation and search in (almost) unconstrained still,”ETH Zurich Tech. Rep. 272, Sep. 2010.
[13] A.. Savitzky and M. J. E. Golay, “Smoothing and
differentiation of databy simplified least squares procedures,”Anal. Chem.,vol. 36, no. 8pp.1627– 1639, 1964.
[14] Oikonomidis I, Kyriazis N, and Argyros A.A, “Tracking the articulated motion of two strongly interacting hands,” in Proc.
IEEE Conf.Comput. Vision Pattern Recogn.,
pp. 1862–1869, Jun. 2012.
[15] Veenu, MPS Bhatia, and Pravin Chandra, “Feasibility of Training and Investigation into Training of Sigmoidal FFANN with Gaussian Learning Rate and Zero Weight Initializations”, Int. J. on Recent Trends in
Engineering and Technology, Vol. 11, No.