Available online at
http://www.iaeme.com/IJARET/issues.asp?JType=IJARET&VType=11&IType=10 ISSN Print: 0976-6480 and ISSN Online: 0976-6499
DOI: 10.34218/IJARET.11.10.2020.139
© IAEME Publication Scopus Indexed
DESIGNING PARAMETER AGNOSTIC
FRAMEWORK FOR PREDICTING DISEASE
ONSET USING DEEP LEARNING METHODS
Anand Javali
Ph.D. Research Scholar, Department of Computer Science and Engineering, Jain Deemed University, Bengaluru, India
Dr. Suchithra. R
Director MCA Department, Department of Computer Science and Engineering, Jain Deemed University, Bengaluru, India
ABSTRACT
Health Care and Life Sciences have been one of the most researched domains. The advent of newer computing paradigms has opened many new and unexplored avenues. These were first initiated by the newer instruments which further gave rise to newer paradigms that leverage the data generated using these instruments. With the High-Performance Computing paradigms, becoming more accessible, we can now leverage various machine learning / deep learning approaches to utilize the data by digitizing it in various forms like Electronic Health Record (EHR) and Electronic Medical Record (EMR), etc. Mostly the medical notes comprise a lot of unstructured data and leveraging only structured information will lead to the loss of a significant amount of information. Although EHR contains a ton of data that can give valuable insights, it is still challenging to extract the information due to its inherent quality of being unstructured and missing data, variable length, and more importantly the lack of domain knowledge, which helps in the analysis. The Long Short-Term Memory (LSTMs) based implementation of Recurrent Neural Networks (RNNs) can be employed to solve the problem of variable-length records but the other issues like linking domain knowledge and extracting information from unstructured data remains a challenge. Also, many researchers have been employing several Deep Learning models to predict the onset of certain diseases by leveraging the data set pertaining to only the particular disease in question leaving the disease agnostic avenue for the trail. We endeavour to develop a generic framework that can be used to predict the onset of any disease by extracting valuable information out of unstructured medical data. In this work, we propose a generic framework that is not specific for any disease/disorder for prediction of the possibility of occurrence of a particular disease/disorder. We have employed RNNs with LSTMs to solve the variable-length issue and then leveraged the NLP based techniques to build a corpus to help map the domain-related information and also to extract the
relevant information form the unstructured data. Our results show that the current model has a very small loss of 0.005 and average accuracy of 98.72 % with an AUC of 75.89%
Key words: Medical Records, Unstructured Data, Deep Learning, Disease Prediction, Electronic Health Records, Clinical Trials.
Cite this Article: Anand Javali and Dr. Suchithra. R, Designing Parameter Agnostic Framework for Predicting Disease Onset Using Deep Learning Methods, International Journal of Advanced Research in Engineering and Technology, 11(10), 2020, pp. 1453-1465.
http://www.iaeme.com/IJARET/issues.asp?JType=IJARET&VType=11&IType=10
1. INTRODUCTION
The introduction of the EHR and EMR has changed the way researchers perceive medical records and also it has introduced new paradigms in the clinical research domain. These paradigms contain a lot of structured and unstructured data which when are extracted appropriately extracted and mined for can give us newer and better insights. These insights can help the physicians to have a better understanding of the pattern of certain diseases/disorders, which the conventional methods may not be able to provide and improve the quality of health care.
Many researchers have tried to leverage the potential of a High-Performance Computing framework to employ various machine learning/ deep learning algorithms to gain insights into medical data. Some researchers have tried to employ algorithms like Time Series Analysis (TSA) to the medical data that is temporal to either classifying the diagnosis, predicting the possibility of occurrence of a disease/condition to mortality rate. Most of the observations in such studies involve parameters like vital signs, lab results, assessments, etc. which often suffer from missing values leading to inaccurate results.
Many researchers in their attempt to predict the occurrence of clinical events have employed several deep learning and machine, learning models. Most of the researchers [1-4] have shown more inclination towards using structured data to achieve the results. This effort involved transforming the clinical data into a multi-dimensional vector. This, however, hampered the capability to extract a lot of information from the unstructured data.
It then became trivial to solve the problem of extracting valuable information out of the unstructured data so that better results can be achieved by employing the deep learning/machine learning models. Some of the other factors affecting the results were the variable length, missing data, and irregular sampling. Hence, some researchers to overcome these hindrances proposed employing Recurrent Neural Networks (RNN) in combination with Long Short-Term Memory (LSTM), which proved to be effective especially in the case of variable-length data thereby capturing long-range dependencies.
In our work, we focus on developing a generic framework that makes it imperative to be able to efficiently extract the information from the unstructured data. In addition, it is trivial that medical notes contain numerical data which is very significant, and also certain abbreviations and notations which provide a context to the data that is being recorded. Hence, we had to focus on the following:
1. Capability to extract information from the unstructured text
2. Extract and understand the numerical values and the related context. 3. A generic framework that can be leveraged for any disease.
It is important to note here that the model/framework should have the inherent capability to understand the context that means that we should be able to feed in the domain knowledge by creating relevant embedding. Besides, as mentioned in the previous section the framework should be capable enough to handle the data related to different diseases/conditions that have different lengths and types. We started with CNN, RNN, and LSTMs and experimented with various combinations of deep learning/machine learning models and architecture.
It is trivial to state that the models that use only structured data and the models that are based on extracting the information from the unstructured data outperform temporal data.
2. MATERIALS AND METHODS
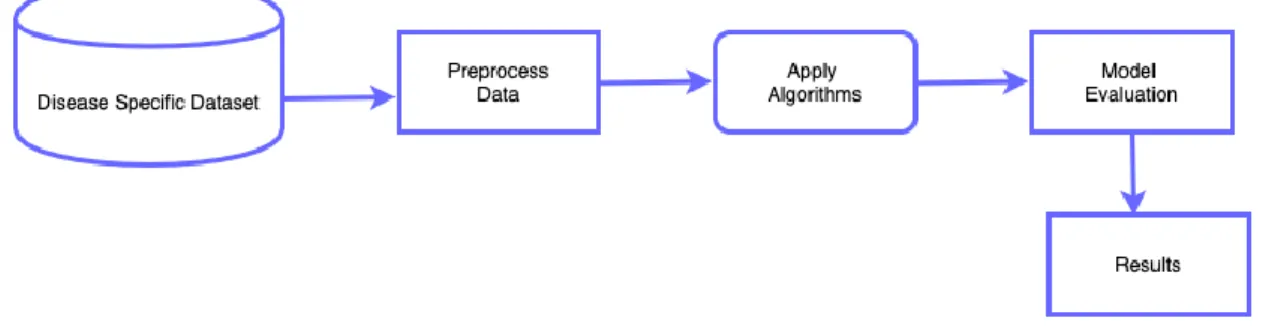
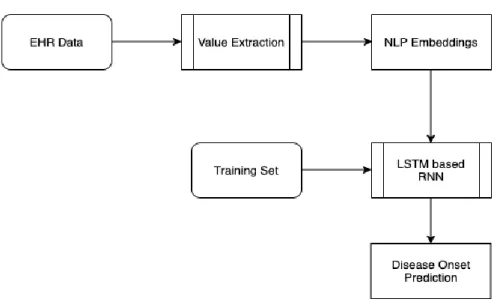
Generally, the Machine / Deep Learning based architecture for disease prediction is very tightly coupled with the disease-specific data set. Though this approach helps the researchers focus on a particular disease it comes with a caveat of being non-scalable and not extensible to other diseases. The general architecture of such conventional studies is as shown in Figure 1
Figure 1 Generic Architecture for Disease-Specific Study
This approach requires a lot of effort in data pre-processing, handling missing data, and evaluation of models. Also, we can see that a considerable time is used in hyper-parameter tuning to achieve better results. This exercise of hyper-parameter tuning can grow to be very complex as the parameters under consideration increase.
Furthermore, these conventional studies are performed on a curated data set that is structured and generally very well labeled, unlike the problem that we are working on in this study. If one were to extract the data from unstructured medical data for a specific disease then we have to run the model against the embedding generated for a particular disease that will result in a large set of embedding which generally has lots of overlapping rules and syntax.
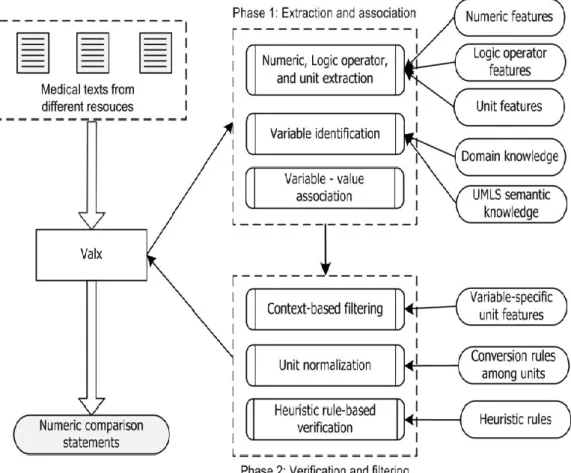
The methodology employed in this work is as shown in Figure 2 the solution is implemented in 2 phases i.e. Value Extraction and then the Deep Learning Model for prediction.
Figure 2 Methodology
Since the input data (medical data) is highly unstructured, we first try to solve the problem of extracting the information from the data. The value extraction itself is implemented in 2 phases i.e. Extraction and Association followed by verification and filtering. In the former phase, we perform a value extraction where we extract all the numerical data, comparison data and map the domain information that is explained in the further sections followed by the verification and filtering phase where the information is verified for its semantic correctness and filtered. We have created a simulated corpus of 25k embedding’s which are generally found in any EHR data in our work, which is then split into training and test set and also positive and negative sets. Since we have a simulated data set of about 25k embedding, we wanted to employ such methods that help to avoid overfitting. In our work, we employ the dropout policy exclusively on the non-recurrent connections.
As a part of our experiments, we have tried and employed different strategies to arrive at a baseline using different combinations of dropout (DO), batch size, encoding length, etc. 2.1. Information Extraction
The clinical data, on which the clinical study relies upon, generally exist as unstructured text free from any guidelines. [5-10]. this form of free text mainly consists of numerical information which more often is in comparative modes, e.g. “Eligibility for inclusion: 40 years or older.” Or “RBS less than or equal to 120 mg/dl”. These statements are not mere numerical comparisons. In such cases, the quantifiable entities are often glued with the context, which is always domain-driven. For example, “mg/dl” provides a context of blood glucose level. The numbers sans these notations mean absolutely nothing. It may be noted that doctors interpret the 120 mg/dl as RBS 120, but for researchers who are not from the domain sans the domain knowledge, it becomes very difficult to interpret like a Doctor.
With the advent of Natural Language Processing, we are now able to tokenize the statements and extract the textual information. However, for the extraction of numerical data, there are a lot of limitations. A rule-based method for extracting numerical information/expression was developed by Tu et al. [11] but it had its limitations. The major deterrent for leveraging this was a lack of support to identify the unit associated with the numerical values. They further extended their work and developed ERGO [12] to extract the information from an unstructured text that was computed readily. Nonetheless, this also suffered from performance issues and was not in a state to be leveraged for the development of a generic framework.
Anand Javali & et. al.[25], done experiments on comparative analysis machine learning algorithms and results concluded as 84.17% of Naïve Bayes is the best-suited algorithm for predicting chronic diabetes disease followed by Support Vector Mechanism with 81.17% and this approach is would be the most efficient model for the Chronic Disease Prediction.
Some researchers used the concept of ontology to create context and relationship between various aspects of the unstructured medical data [13] but the process of formalizing was too expensive in terms of labour as it required a lot of manual effort. Other researchers have leveraged the text mining algorithms in some of the works like [14] to extract the details and map them to NLP entities like location, person, etc. This model however suffered from a lack of scalability.
This necessitated a framework that could suit the real-world unstructured text so that we could extract the textual, numeric, and domain-specific information from the unstructured data. Hao et al. [15] in their work on value extraction methods for lab test data developed novel methods to extract the numeric and comparison statements information from the lab results which was pretty much real-world data that could easily be extended to suit the unstructured medical notes data.
Take an example of a statement that has numerical comparison e.g. “Subjects should be aged between 18-30 years old.” If we closely examine the above statement, we can find that there are four aspects in any such statement as shown in Figure 3
Figure 3 Comparison Statement Example
1. The variable i.e. the entity being tested / quantified/ clinical event. 2. The comparison criteria / logical operator
3. The threshold values for comparison 4. The unit of measuring the variable.
In this example, the variable is the age of the subjects, which is being quantified and would be a feature. The comparison is between which can be mathematically translated to 18 age 30. 18 and 30 here are the threshold values of the variable that is being extracted/considered. “years” is the unit of measuring the variable i.e. age.
Figure 4 General Architecture for extracting and normalizing numerical comparison statement form medical data
2.1.1. Phase 1: Extraction and association
The Value Extraction Methodology is as shown in Figure 4. The following section will explain each step involved.
Step 1 - Unstructured Text Processing: The most trivial step in processing such unstructured and inconsistent textual data is to normalize the character encoding and also normalizing the representation of any special characters/symbols that may have been used. The next step would be to identify the numerical data in text form i.e. in words and convert it to numbers. E.g. “one week” is to be converted to “1 week”.
The text is further tokenized into individual sentences and searched for the existence of any numeric patterns and its attributes and comparison statements around them. Generally, any such clinical data contains the criteria that are used to determine the inclusion of the subjects for the clinical trials and failing to adhere to the criteria the subjects are excluded from the clinical trial. Step 2 - Extracting numeric data and comparison statements: The regular expressions are used to detect the numeric patterns and extract them which are as described in [15]. After extracting the numeric patterns, the next step is to detect any unit of measurement if exists.
Step 3 - Identifying the clinical entity to be tested (clinical variable): Once the variables are identified, it becomes very important to identify the corresponding units, comparison statements which also means that we need to identify and extract the comparison operator and the threshold values of the variables. Many doctors use different notations to represent a particular variable or clinical event. Some Doctors may use “RBS” or just “Random” to represent “Random Blood Sugar”. This is a challenge in extracting the context, which requires the framework to have the inherent domain knowledge to identify such data and extract them. The concept of the Unified
Medical Language System (UMLS) is used for recognizing these entities. Furthermore, n-gram strings are used to identify comparison statements. These n-grams are then mapped to the UMLS and the Domain Knowledge (DK) after filtering out the stop words.
Step 4 - Clinical Event and numerical data association: At times the variables and their units are agglutinated in cases where there are multiple threshold values. For example, “Aged between 18 and 30 years” here we need to glue the unit “years” to both the lower and upper threshold values.
2.1.2. Phase 2: Verification and Filtering of data that does not align with any rules/patterns.
Step 5 - Context Filtering: Once the variables and their Domain Knowledge are extracted, we check if and with what entities/expressions are they associated with and then are compared based on their units. For example, “mm/hg” cannot be a unit of measurement for weight.
Step 6 - Normalization of Units: Different medical professionals use different representations of the same unit of measurement, which needs to be standardized if we have to develop a generic framework. For example, we can map “kg” to “pounds” and then convert them and represent them.
Step7 - Rule-based verification: now all will convert the unstructured data into tokens with the units normalized. Now rules are defined to filter out the statements that are syntactically correct but semantically incorrect. For example, let us assume that the prototype for a comparison statement would be “<var> <operator> <threshold>/<threshold> <unit>”. Now consider the statement “Age below 50 kg”. It is syntactically correct as per our syntax and prototype but it does not make sense because we know from Domain Knowledge that “kg” cannot be associated with the variable “Age” or the converse of it that “Age” cannot be associated with “kg” is also equally true.
2.2. Development of Generic Framework
We started with employing the Convolutional Neural Networks that is composed of an input, an output, and many hidden layers sandwiched between the two. The general form of CNN employed is as shown in Figure 4 below.
We employed a feed-forward CNN model on the training set of ~20k embedding. We extracted the feature vectors with n features and convolve it using the weight vector W with length m into another short vector B with n-m+1 elements as:
𝑏𝑖 = ∑ 𝑎𝑖+𝑗∗ 𝑤𝑗 , 𝑤ℎ𝑒𝑟𝑒 𝑖 = [1, 𝑛 − 𝑚 + 1]
0 𝑗=𝑚−1
Extrapolating it for a ‘n’ dimensional input we can rewrite the above equation as 𝑏𝑖,𝑘,𝑙...𝑛 = ∑𝑗01= 𝑚1−1𝑎_(𝑖 + 𝑗1, 𝑘 + 𝑗2+ ⋯ , 𝑛 + 𝑗𝑛∗ 𝑤𝑗1,𝑗2,..𝑗𝑛)
𝑗2=𝑚2−1
.. 𝑗𝑛=𝑚𝑛−1
𝑤ℎ𝑒𝑟𝑒, 𝑖 = [ 1, 𝑛1− 𝑚1+ 1], 𝑘 =
[1, 𝑛2− 𝑚2+ 1]. . 𝑛 = [1, 𝑛𝑛− 𝑚𝑛+ 1]
We used 128 features with an eps of 1e-05 and used a momentum of 0.1.
As discussed in previous sections, the introduction of deep learning models has changed the way researchers look at the medical data. Applying neural networks to medical data is not something new, but many researchers have been employing it for at least 2 decades now. Baxt et al. [16] has researched on leveraging neural networks on medical data, followed by Caruana et al. [17]
Tresp & Briegel [18] brought a new wave when they started leveraging Recurrent Neural Networks (RNN) for glucose measurement. This paved way for researchers like Pollastri et al [19] to employ RNNs in solving predictive analytics problems in genomics that was then followed by the likes of Xu et al. Of late other algorithms like feedforward networks have been employed by Lasko et al. [20] for classification of leukemia.
Although, many researchers have been using Long Short-Term Memory (LSTM) for solving multi-label classification problems in the various domain including music [21], video-based applications [Yeung et al [22], we found that the literature on leveraging LSTMs for solving multi-label classification in unstructured medical data was scarce.
Performance is the most important aspect of any model and there is always a trade-off between scalability and performance. Many researchers have tried to tackle this using many different and novel ways. If we are using RNNs, it becomes very critical to be very vigilant about dropout in regularizing the RNNs to achieve better performance.
Lipton et al [23] in their phenomenal work on employing LSTMs on medical data have demonstrated that LSTMs can help achieve more accuracy in classifying multivariate time series of clinical measurements. Furthermore, they also demonstrated that their novel approach was more efficient in target replication.
In our work, we have tried to explore and experiment with LSTM and Convolutional Neural Network (CNN) architecture since the medical data is unstructured, unlike the previously mentioned works. One of the reasons for us not to leverage the RNNs is that they have a short-term memory and hence cannot be used in cases where we deal with variable length data that are in longer sequences. Fig. 5 below shows a general view of LSTM
Figure 5 General View of LSTM
We have a data set of medical notes, which consists of numeric data and comparison statements. We have built an embedding of ~25,000 frequently used string/words that are used in medical notes after filtering the stop words. The numeric data is extracted by employing [15] 4.1 Models
As discussed in previous sections, we have experimented with various models like CNN and LSTM with different embedding.
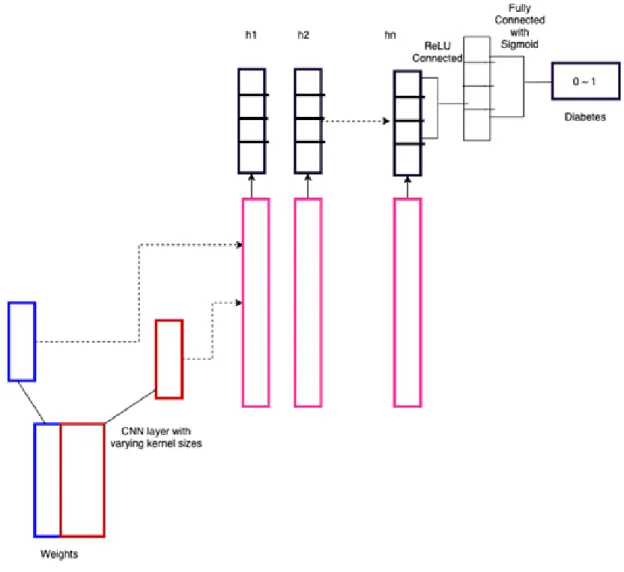
Figure 6 below depicts a general architecture of CNN based on the works by Kim et al [24]. This model demonstrates the text representations of different abstraction levels and chooses important n-grams from the unstructured medical data.
One-dimensional convolutions are performed on these n-grams and then the results are saved in the buffer over time that is then concatenated. The data is fed through single or multiple layers that are fully connected.
To preserve the concatenated n-grams we can add another layer after the pool, which is fully connected to hidden states as shown in Figure 7.
Figure 7 Implemented Neural Network Architecture
The tangible outcome of this approach is that the sequence lengths are reduced and we can capture a snapshot of the subject’s health condition in the window
In this set up each layer computes:
it=σ(Wiixt+bii+Whiht−1+bhi) ft=σ(Wifxt+bif+Whfht−1+bhf) gt=tanh(Wigxt+big+Whght−1+bhg)
ot=σ(Wioxt+bio+Whoht−1+bho) ct=ft⊙ct−1+it⊙gtht=ot⊙tanh(ct)
The parameters were quite similar to that of CNN with the sequence length as 128 and 64 features in the hidden state with 2 LSTMs stacked and using a bidirectional LSTM.
3. RESULTS AND DISCUSSION
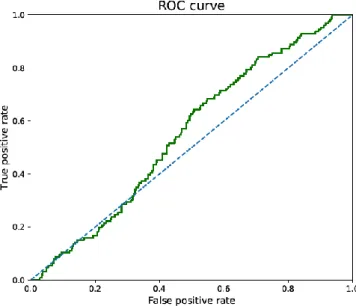
Figure 8 shows the ROC for the case where we had used CNN with 100 sequence length and 0.1 momenta without valx and lstm and the AURC was 51.8
Figure 8 Plain CNN without valx and lstm with 100 as sequence length
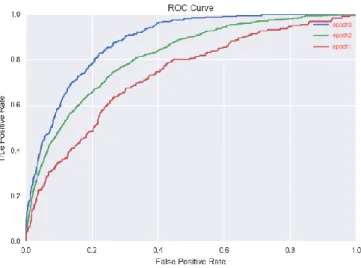
Figure 9 shows the ROC for the case where we had leveraged CNN along with Valx [15] and Figure 10 shows the results after introducing an additional layer to capture the snapshot and using LSTM. We can clearly see that we can achieve better results using the latter approach, as the AUC of the latter approach is quite high as compared to the former. The AUROC was 65.22% in the former case whereas it was 75.89 with an accuracy of 98.72%
Figure 10 Using Valx and Additional Layer + LSTM
4. CONCLUSIONS
We can see from the results that we can predict the onset while being disease agnostic. The Table1 below shows the precision of the value extraction on the data we generated. However, we believe that there is a lot of scopes to add more value to the work that we have undertaken especially by exploring more advanced models like GANs which can be leveraged to extract more insights from medical images, etc. Furthermore, the aforementioned architecture that helps us eliminate the ambiguous notations in the medical data can be further improvised to eliminate other hyper-parameter-based corrections and more efficient handling of missing values in real-world data.
Table 1 Value Extraction Results
Dataset Text Valx #Correct Precision
Diabetes Type2
Inclusion 1895 1877 99.10%
Exclusion 184 177 96.20%
Overall 2079 2054 98.80%
Diabetes Type1
Inclusion 397 396 99.7%%
Exclusion 65 64 98.5%%
Overall 462 460 99.6%%
REFERENCES
[1] Zachary C Lipton, David C Kale, Charles Elkan, and Randall Wetzell. Learning to diagnose with lstm recurrent neural networks. arXiv preprint arXiv:1511.03677, 2015
[2] Narges Razavian and David Sontag. Temporal convolutional neural networks for diagnosis from lab tests. arXiv preprint arXiv:1511.07938, 2015.
[3] Edward Choi, Mohammad Taha Bahadori, Andy Schuetz, Walter F Stewart, and Jimeng Sun. Doctor ai: Predicting clinical events via recurrent neural networks. In Machine Learning for Healthcare Conference, pages 301–318, 2016.
[4] Harini Suresh, Nathan Hunt, Alistair Edward William Johnson, Leo Anthony Celi, Peter Szolovits, and Marzyeh Ghassemi. Clinical intervention prediction and understanding using deep networks. CoRR, abs/1705.08498, 2017.
[5] Boland MR, Miotto R, Gao J, Weng C. Feasibility of feature-based indexing, clustering, and search of clinical trials. A case study of breast cancer trials from ClinicalTrials.gov. Methods Inf Med. 2013; 52(5):382–94. [PubMed: 23666475]
[6] Miotto R, Jiang S, Weng C. eTACTS: a method for dynamically filtering clinical trial search results. J Biomed Inform. 2013; 46(6):1060–7. [PubMed: 23916863]
[7] Tianyong Hao AR, Weng Chunhua. Extracting and Normalizing Temporal Expressions in Clinical Data Requests from Researchers. Lecture Notes in Computer Science. 2013; 8040:10. [8] Hao T, Rusanov A, Boland MR, Weng C. Clustering clinical trials with similar eligibility
criteria features. J Biomed Inform. 2014; 52:112–20. [PubMed: 24496068]
[9] Hao T, Weng C. Adaptive semantic tag mining from heterogeneous clinical research texts. Methods Inf Med. 2015; 54(2):164–70. [PubMed: 25327613]
[10] Bache R, Taweel A, Miles S, Delaney BC. An eligibility criteria query language for heterogeneous data warehouses. Methods Inf Med. 2015; 54(1):41–4. [PubMed: 24985949] [11] Tu M, Z Y, Zong CA. Universal Approach to Translating Numerical and Time Expressions. 9th
International Workshop on Spoken Language Translation. 2012:209–216.
[12] Tu SW, Peleg M, Carini S, Bobak M, Ross J, Rubin D, Sim I. A practical method for transforming free-text eligibility criteria into computable criteria. Journal of Biomedical Informatics. 2011; 44(2):239–250. [PubMed: 20851207]
[13] Damen D, L K, Hellebaut G, Bulcke TVD. PASTEL: A Semantic Platform for Assisted Clinical Trial Patient Recruitment. International Conference on Healthcare Informatics. 2013:269–276. [14] Murata M, S T, Torisawa K, Iwatate M, Ichii K, Ma Q, Kanamaru T. Sophisticated Text Mining System for Extracting and Visualizing Numerical and Named Entity Information from a Large Number of Documents. NTCIR-7 Workshop Meeting. 2008:555–562.
[15] Tianyong Hao, Hongfang Liu, Chunhua Weng, et al. Valx: a system for extracting and structuring numeric lab test comparison statements from text. Methods of information in medicine, 55(3):266–275, 2016.
[16] Baxt, W.G. Application of artificial neural networks to clinical medicine. The Lancet, 346(8983): 1135–1138, 1995.
[17] Caruana, Rich, Baluja, Shumeet, Mitchell, Tom, et al. Using the future to “sort out” the present: Rankprop and multitask learning for medical risk evaluation. In Advances in Neural Information Processing Systems (NIPS) 8, pp. 959–965, 1996.
[18] Tresp, Volker and Briegel, Thomas. A solution for missing data in recurrent neural networks with an application to blood glucose prediction. In Advances in Neural Information Processing Systems (NIPS) 10, pp. 971–977. 1998.
[19] Pollastri, Gianluca, Przybylski, Darisz, Rost, Burkhard, and Baldi, Pierre. Improving the prediction of protein secondary structure in three and eight classes using recurrent neural networks and profiles. Proteins: Structure, Function, and Bioinformatics, 47(2):228–235, 2002. [20] Lasko, Thomas A., Denny, Joshua C., and Levy, Mia A. Computational phenotype discovery using unsupervised feature learning over noisy, sparse, and irregular clinical data. PLoS ONE, 8(6): e66341, 06 2013.
[21] Liu, I, Ramakrishnan, Bhiksha, et al. Bach in 2014: Music composition with recurrent neural network. arXiv preprint arXiv:1412.3191, 2014.
[22] Yeung, Serena, Russakovsky, Olga, Jin, Ning, Andriluka, Mykhaylo, Mori, Greg, and Fei-Fei, Li. Every moment counts: Dense detailed labeling of actions in complex videos. arXiv preprint arXiv:1507.05738, 2015.
[23] Zachary C. Lipton, David C. Kale, Charles Elkan, Randall Wetzel LEARNING TO DIAGNOSE WITH LSTM RECURRENT NEURAL NETWORKS ICLR 2016
[24] Yoon Kim. Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882, 2014.
[25] Anand Javali et al., International Journal of Advanced Trends in Computer Science and Engineering, 9(5), September - October 2020, 7748 – 7754
![Figure 6 below depicts a general architecture of CNN based on the works by Kim et al [24]](https://thumb-us.123doks.com/thumbv2/123dok_us/8560300.2314470/9.892.278.626.669.1111/figure-depicts-general-architecture-cnn-based-works-kim.webp)