A Data Warehouse/OLAP Framework for Web Usage Mining
and Business Intelligence Reporting
Xiaohua Hu Nick Cercone
College of Information Science Faculty of Computer Science Drexel University, Philadelphia Dalhousie University
PA, USA 19104 Halifax, Nova Scotia, Canada email: [email protected] email: [email protected]
Abstract
Web usage mining is the application of data mining techniques to discover usage patterns and behaviors from web data (clickstream, purchase information, customer information etc) in order to understand and serve e-commerce customers better and improve the online business. In this paper we present a general Data Warehouse/OLAP framework for web usage mining and business intelligence reporting. We integrate the web data warehouse construction, data mining, On-Line Analytical Processing (OLAP) into the e-commerce system, this tight integration dramatically reduces the time and effort for web usage mining, business intelligence reporting and mining deployment. Our Data Warehouse/OLAP framework consists of four phases: data capture, webhouse construction (clickstream marts), pattern discovery and cube construction, pattern evaluation and deployment. We discuss data transformation operations for web usage mining and business reporting in clickstream, session and customer level, describe the problems and challenging issues in each phase in details and provide plausible solution to the issues and demonstrate with some examples from some real websites. Our Data Warehouse/OLAP framework has been integrated into some commercial e-commerce systems. We believe this Data Warehouse/OLAP framework would be very useful for developing any real-world web usage mining and business intelligence reporting systems.
1. Introduction
Knowledge about customers and understanding customer needs is essential for customer retention in a web store for online e-commerce applications, since competitors are just one click away. To maintain a successful e-commerce solution, it is necessary to collect and analyze customer click behaviors at the web store. A web site generates a large amount of reliable data and is a killer domain for data mining application. Web usage mining can help an e-commerce solution to improve up-selling, cross-selling, personalized ads, click-through rate and so on by analyzing the clickstream and customer purchase data click-through data mining techniques. Web usage mining has attracted much attention recently from research and e-business professionals and it offers many benefits to an e-commerce web site such as:
• Targeting customers based on usage behavior or profile (personalization)
• Adjusting web content and structure dynamically based on page access pattern of users (adaptive web site)
• Enhancing the service quality and delivery to the end user (cross-selling, up-selling) • Improving web server system performance based on the web traffic analysis
• Identifying hot area/killer area of the web site.
We present a general Data Warehouse/OLAP framework for web usage mining and business intelligence reporting. In our framework, data mining is tightly integrated into the E-commerce systems. Our Data Warehouse/OLAP framework consists of four phases: data capture, webhouse construction (clickstream marts), pattern discovery and pattern evaluation as shown in Figure 1. In this framework, it provides the appropriate data transformations (also called ETL: Extraction, Transformation and Loading) from the OLTP system to data warehouse, build data cubes from the data warehouse and mine the data for business analysis and finally deploy the mining results to improve the on-line business. We describe the problems and challenging issues in each phase in detail and provide a general approach and guideline to web usage mining and business intelligence reporting for e-commerce.
The rest of the paper is organized as follows: in Section 2, we discuss the various data capture methods and some of the pitfalls and challenging issues. In Section 3, we will describe the data transformation operations for web data at different level of granularity (clickstream level, session level and customer level) and show how to organize the dimensions and facts tables for the webhouse, which is the data source for the web usage mining and business intelligence reporting. We discuss the cube construction and various data mining methods for web usage mining in Section 4 and pattern evaluation (mining rules evaluation) in Section 5. We conclude in Section 6 with some insightful discussion.
Figure 1: The Data Warehouse/OLAP Data Flow Diagram
2. Data Capture
Capturing the necessary data in the data collection stage is a key step for a successful data mining task. A large part of web data is represented in the web log collected in the web server. A web log records the interactions between web server and web user (web browsers). A typical web log (Common Log format) contains information such as Internet provider IP address, ID or password for access to a restricted area, a time stamp of the URL request, method of transaction, status of error code, and size in bytes of the transaction. For the Extended Log format, it includes the extra information such as a referrer and agent. Web logs were originally designed to help debugging web server. One of the fundamental flaws of analyzing web log data is that log files contain information about the files transferred from the server to the clientnot information about people visiting the web site
Data Capture (clickstream, sale, customer, product, etc) Data Webhouse Construction ( dimensions, fact tables, aggregation table, etc) Mining, OLAP ( rules, prediction models, cubes, reports, etc) Pattern Evaluations & Deployment
[9,19]. Some of these fields are useless for data mining and are filtered in the data pre-processing step. Some of them such as IP address, referrer and agent can reveal much about the site visitors and the web site. Mining the web store often starts with the web log data. Web log data need to go through a set of transformation before data mining algorithms can be applied. In order to have a complete picture of the customers, web usage data should include the web server access log, browser logs, user profiles, registration data, user sessions, cookies, user search keywords, and user business events [1,9,14]. Based on our practice and experience in web usage mining, we believe that web usage mining requires conflation of multiple data sources. The data needed to perform the analysis should consist of five main sources:
(1) The web server logs recording the visitors’ click stream behaviors (pages template, cookie, transfer log, time stamp, IP address, agent, referrer etc.)
(2) Product information (product hierarchy, manufacturer, price, color, size etc.) (3) Content information of the web site (image, gif, video clip etc.)
(4) The customer purchase data (quantity of the products, payment amount and method, shipping address etc.)
(5) Customer demographics information (age, gender, income, education level, Lifestyle etc.)
Data collected in a typical web site categorize to different levels of granularity: page view, session, order item, order header, customer. A page view has the information such as type of the page, duration on the page. A session consists of a sequence of page views; an order contains a few order items. It is the best practice in the data collection phase to collect the finest granular and detailed data possible describing the clicks on the web server, and items sold at the web store. Each web server will potentially report different details, but at the lowest level, we should be able to obtain a record for every page hit and every item sold if we want to have a complete portfolio of the click behavior and sale situation of the web store.
There are various methods to capture and collect valuable information for visitors for e-commerce at the server level, proxy level and client level through the CGI interface, Java API, JavaScript [1,9,14]. Most of them use web log data or packet sniffers as a data source for clickstream. Web log data are not sufficient for data mining purpose for the following main reasons:
(1) Unable to identify the sessions
(2) Lack of web store transaction data; the web store transaction records all sale related information of a web store and it is necessary for business analysis and data mining in order to answer some basic and important business questions such as “which referrer site leads more product sale at my site?”, “what is the conversion rate of the web site”, “which part of my web sites are more attractive to purchaser?”.
(3) Lack of business events of web store; business events of a web store such as “add a item to shopping car”, “research key event”, “abandoning shopping cart” are very useful to analyze the user shopping and browsing behavior of a web store.
In our framework, we believe that collecting data at the web application server layer is the most effective approach, as suggested by some commercial vendors [9,14]. The web application server controls all the user activities such as registration, logging in/out, and can create a unified database to store web log data, sale transaction data and business events of
the web site. The discussion of these methods is beyond the scope of this paper. For interested readers, please refer to [9, 14].
There are challenging issues in the data capture phase for web usage mining. The following challenges illustrate three problems: (1) how to sessionize the clickstream data; (2) how to filter crawler’s sessions; and (3) how to gather customer’s information. These challenges are the most popular ones encountered in almost all the web usage mining projects. And these problems have a huge impact on the success or failure of web usage mining projects. Below we discuss each of them in detail.
2.1 Session Data
A user web session is a sequence of consecutive page views (hits) before the user explicitly logs out or times out. A user who visits a site in the morning and then again in the evening would count as two user visits (sessions). Because of the statelessness of HTTP, clickstream data is just a sequence of page hits, a page hit may be an isolated event that is hard to analyze without considering the context. To make the raw clickstream data usable in web usage mining, the clickstream needs to be collected and transformed in such a way that it has a session perspective. Thus the first task after the data collection is to identify the sessions for the clickstream stream (sessionizing the clickstream). In some web usage mining systems, during preprocessing, individual log entries are aggregated into server sessions according to the IP address and agent information. New sessions are also identified using a 30-minute intersession timeout period [23,24]. Within each session, the log entries are grouped into a separate request where each request may correspond to an individual user click or a search event. Nonetheless there are some serious problems when processing in this way. Many internet users utilize an Internet Service Provider (ISP), their IP address may be assigned dynamically, so it is very likely that the same user will have a different address in different sessions [6,7,14]. Another problem is that users behind a firewall can all have the same IP address; an IP address is not suitable as an identification variable for such sessions.
Realizing the limitations of relying on the IP address; cookies are used as a workaround to solve this problem and to sessionize the clickstream in many web sites. A cookie is a mechanism that allows the web server to store its own information about a user on the user’s hard driver. It is a small file that a web server sends to a web user and stores on his computer so that it can remember something about you at a later time. The location of the cookies depends on the browser. Internet Explorer stores each cookie as a separate file under a Window’s subdirectory. Netscape stores all cookies in a single cookies.txt file. Sites to store customization information or to store user demographic data often use this information. The main purpose of cookies is to identify users and possibly prepare customized web pages for them. If the cookie is turned on, that means the user will send the cookie back to the web server each time his browser opens one of web pages and the web server can identify the requesting users’ computer unambiguously. The browser thus puts all the hits with the same cookie as one session until the user explicitly logs out or times out. In some situations, for privacy concerns, some users choose to turn off cookies, then the web site needs to use login id, referrer and agent information, if possible, to identify user and server sessions [9,23].
2.2 Crawlers Session
A crawler is a software agent that traverses web sites based on web linkages in web pages. Search engines use crawlers to index web pages and crawlers can help users to gather information such as prices for certain products, and help web designers to diagnose web site problems (such as response time, isolated web pages etc). Most crawlers adopt a breadth-first retrieval strategy to increase their coverage of the web site. In our experience with some wet site data, at times up to 30% of site clickstream session traffic may be crawlers; these sessions are called crawler sessions. Crawler sessions may mislead data mining analysis to generate inaccurate or incorrect results if they are not filtered. For example, an associate algorithm is used to find the page click orders in a session, as pointed out in [1, 4,10,23], and an association rule mining algorithm may inadvertently generate frequent item sets involving web pages from different page categories. Such spurious patterns may lead an analyst of an e-commerce site to believe that web surfers are interested in products from various categories when in fact crawlers induce such patterns [9,23]. This problem can be avoided if web crawler sessions are removed from the data set during data preprocessing. Thus, identifying crawler sessions is very important for web usage mining. There are a few ways to identify a crawler session. In [23], they build a classification model to identify sessions. The crawler sessions may have some of the characteristics such as: images turned off, empty referrers, visit robots.txt file, page duration time is very short, pattern is a depth-first or breadth-first search of the site, never purchase [6]. Some web sites adopt the approach that creates a invisible link on a page and since only crawlers follow invisible links (regular users can’t click invisible links), the session consists of the invisible links are considered to be a crawler session.
2.3 Customer Demographics (Offline Date)
Retaining customers and increasing sales is the only way for an e-commerce web store to survive in this very competitive on-line market. To retain customers, you need to understand their needs and preferences. As pointed in [7,11,17], fostering and promoting repeated sales requires knowledge about customers’ preferences, consumption rate, behavior, and lifestyle. This knowledge generally requires knowing items such as a customer’s income, age, gender, life style and so on. To find the best way to reach its customers and increase sales, it is necessary for a company to enrich the clickstream with this offline information. The user of demographics, psychographics, property information, household characteristics, individual characteristics, lifestyle, has been used by database marketing professionals to improve their sales, retain customers and acquire new customers for bricks-and-mortar stores for decades. This information should also be used in a web store to enhance the vast amount of customer and clickstream behavior already captured at the website.
In the web store, customer information can be collected through a registration form, which is often limited. Some web site offers incentives to users to encourage them to register or answer a set of questions. The problem is that users tend not to give the information or provide inaccurate information in registration forms. Fortunately, there are many commercial marketing database vendors that collect this information based on zip code or physical addresses. This information should be integrated to web data for additional insight into the identity, attributes, lifestyles, and behaviors of the web site visitors and customers [17]. There are several sources of demographic information at various levels like CACI, Acxiom, and Experian, to name a few. CACI provides neighborhood demographics;
Acxiom gives household-level psychographics; and Experian provides the MOSAIC targeting system, which identifies consumers according to the type of neighborhood in which they live [17]. These external offline demographics can inform whom your online visitors and customers are, where they live, and subsequently how they think, behave, and are likely to react to your online offers and incentives. Database marketers have used this information for years to segment their customers and potential prospects. The demographics and socioeconomic profiles are aggregated from several sources including credit card issuers, county recorder offices, census records, and other cross-referenced statistics [17]. When analyzing and mining customer demographics data from web data, it should always be kept in mind the privacy of the customers. Profiling customers is bad when web sites fail to do it anonymously.
3. Data Webhouse Construction
A data warehouse provides the data source for online analytical processing and data mining. Designing a proper data warehouse schema and populate the data from the OLTP system to the warehouse is very time consuming and complex. A well-designed data warehouse would feed business with the right information at the right time in order to make the right decisions in e-commerce system [20,21,9]. In Section 2, we discussed data capture methods for the web site, which collect the clickstream, sales, customers, shipments, payment, and product information etc. These data are on-line transaction data and are stored in the transaction database system (OLTP). The database schemas of the OLTP are based on E-R modeling, normalized to reduce redundancy in the database and designed to maintain atomicity, consistency and integrityso as to maintain speed and efficiency for use in day-to-day business operations such as insert, update and delete a transaction. For an OLTP query, it normally only need to access a small set of records in the databases but demand very quick responses. For web usage mining purposes, it needs to have a database schema (called a data warehouse) designed to support decision-making and data analysis (On-Line Analytical Processing). Typical relational databases are designed for on-line transactional processing (OLTP) and do not meet the requirements for effective on-line analytical processing. As a result, data warehouses are designed differently than traditional relational databases.Data warehouses use OLTP data for historical, read-only analysis. The data in a data warehouse system are normally organized in multidimensional modeling with star schema (fact tables plus the surrounding dimension tables). The requirement of clickstream data in the data warehouse make the schema design even more complicated. The web challenges the current view of the data warehouse with multiple new requirements [11]. The data warehouse is required to make the customer clickstream available for analysis, so a new term webhouse was coined by Ralph Kimball [11,12]. A webhouse plays an integral role in the web revolution as the analysis platform for all the behavior data arriving from the clickstream, as well as for the many web sites that rely on the data warehouse to customize and drive the end user’s web experience in real time [11]. We use webhouse to refer to the data warehouse system for the web usage mining. The webhouse is the source data of data mining and business intelligence reporting in the Data Warehouse/OLAP framework and it contains the fundamental business content of what a web store sells with web services and capabilities. A webhouse should allow you to analyze all hits on a web site, all the products sold in the web store from many viewpoints. Many systems have developed to mine web log records, which can find association patterns and sequential patterns about web accessing, but in order to understand customers such as repeated visitors vs. single visitors, single purchase customers vs. multiple purchase customers, it is necessary to include additional information such as order information from
the web store, product information about the product, user browsing sequence from clickstream, and customers information from user table. Below we discuss the requirement analysis, and dimensional modeling technique to design the webhouse.
3.1 Requirement Analysis of the Webhouse
It is necessary to build a comprehensive view of the immerse stream of clicks arriving at web sites, including items sold thorough the site. We want to build a webhouse to provide insightful information and answer the important business questions for e-commerce. The design of a webhouse starts with the requirement analysis. We spent significant time to interview our clients, business analysts, engineers/developers and end-users to gather their requirements and what kinds of business problems they hope to get answers from the webhouse. Their questions cover a wide ranges and areas:
• Web site activity (hourly, daily, weekly, monthly, quarterly etc)
• Product sale (by region, by brand, by domain, by browser type, by time etc)
• Customers (by type, by age, by gender, by region, buyer vs. visitor, heavy buyer vs. light buyer etc)
• Vendors (by type, by region, by price range etc)
• Referrers (by domain, by sale amount, by visit numbers etc)
• Navigational behavior pattern (top entry page, top exit page, killer age, hot page etc) • Click conversion-ratio
• Shipments (by regular, by express mail etc) • Payments (by cash, by credit card, e-money etc) Some of the important questions are
• Who are my most profitable customers?
• What is the difference between buyers and non-buyers at my site? • Which parts of my site attract the most visits?
• Which part of my site is a session killer?
• Which parts of the sites lead to the most purchases? • What is the typical click path that leads to a purchase?
• What is the typical path of customers who abandoned the shopping cart? • What are the percentages of customers visiting the product section? • What is the new-visitor click profile?
• What are the top/bottom products? • What are the peak traffic hours?
We analyze these questions and determine the dimensions need to be constructed and the fact measure the business analysts are interested in. After identify the dimension and measures, we can move to the next step: webhouse schema design
3.2 Webhouse Schema Design
In the webhouse, there are one or a few fact tables and a set of small tables called dimensional tables. The fact table is where numerical measurements of the business are stored. Each of these measurements is taken at the intersection of all dimensions. The dimension tables are where the textual descriptions of the dimensions of the business are stored [11]. There are several design methodologies to design a data warehouse such as architecture-based methodology proposed by Anahory and Murraym [2], four-step methodology used by Ralph Kimball. To construct the webhouse for the Data Warehouse/OLAP framework, we adopted Kimball’s methodology to build the webhouse through dimensional modeling techniques.
The four-steps include (1) define the source of data, (2) choose the grain of the fact tables, (3) choose the dimensions appropriate for the grain, and (4) choose the facts appropriate for that grain. Below we discuss each step in detail:
3.2.1 Define the Source Data
Since we wish to analyze click behavior and the sales situation of a web site for an on-line web store, we need to have the data for every web hit on the web site and every item sold in the web site. Data collection is at the page request level (clickstream) or purchase in the order item level and all of this information is already available in the transaction database (OLTP). In the data collection phase, we have collected every web page view, purchase data and customer information in the web database system, which is the data source for our webhouse. We need to extract them from the transaction database and transform them into the webhouse according to the design of the dimension tables and fact tables, which is described later. In addition, we also need to have product, use, page, time, payment, shipping, and promotion information.
3.2.2 Choose the Grain of the Fact Tables
The fact table is the center of the webhouse. It contains a list of all measures and points to the key value of the lowest level of each dimension. The lowest level of each dimension table, business problems and domain determines the granularity of the fact table. Before the fact tables can be designed in detail, a decision must be made as to what an individual low-level record in that fact table means. This is the grain of the fact table [11]. In order to analyze the clickstream, every page hit should have a row in the clickstream fact table, which is the grain of the clickstream. To analyze the sales business of the web store, every item sold should have a row for order item fact table. Thus the grain of the item fact tables in the webhouse is every item sold.
3.2.3 Choose the Dimensions Appropriate for the Grain
Dimensions are qualifiers that give meaning to measures. They organize the data based on the what, when, and where components of a business question. Dimensions are stored in dimension tables made up of dimensional elements and attributes. Each dimension is composed of related items, or elements. Dimensions are hierarchies of related elements. Each element represents a different level of summarization. For example, products roll up to subcategories, which roll up to categories (which in turn roll up to department etc). The lowest level in the hierarchy is determined by the lowest level of detail required for the analysis. Levels higher than the base level store redundant data. This denormalized table reduces the number of joins required for a query, and makes it easier for users to start querying at a higher level and to drill down to lower levels of detail as needed. All of the elements relating to the product, for example, would comprise the product dimension. This
allows the user to query for all categories, and drill down to the subcategories or product level for more detailed information. Below we discuss some of the important dimensions in the webhouse. (The discussions of some other dimensions such as business event dimension, promotion dimension are omitted because of space limitations; these dimensions are almost the same in the webhouse compared with the traditional data warehouse)
Session Dimension
The session dimension is more than just a tag that groups together all the page events that constitute a single user's session. The session dimension is the place where we label the session and trace its activity [11], to describe the characteristics of the session. The characteristics of a session should consist of: session length, the total page requests of the session, the first pages of the session, last pages of the session, the referrer of the session, cookie id, user agent, client host, the first request time, and last request time, total browsing time of the session, average viewing time of each page of the session, session visit count. We may need to characterize sessions as “sessions with purchase”, “sessions without purchase” “random browsing”, “crawler sessions” etc. With this information, we are able to answer business questions such as which page my customer comes to my site (top first page of the sessions) and where they leave? (top last page of the session), what are the characteristic of the sessions lead to purchase?
Page Dimension
Site area analysis is very important in order to understand which part of the web site attracts most of the hits, which part leads to a purchase, which part of the site is a “killer,” which part of the site is less visited and superfluous. The page dimension should contain meaningful context that tells the analyst the user's web site location. Each web page must contain some simple descriptors identifying the location and type of page such as “Log in”, “Registration” “Hot Product”, "Product Info," "Company Info," "Frequently Asked Questions," and "Order Form." [12]. A large web site should have a hierarchical description associated with each page that gives progressively more detail about what constitutes the page. This information needs to be stored in the page dimension and be maintained consistently as we update and modify the web site. A page dimension should also contain such information as Page Template, Page Category, Number of Images, and Banners in the Page etc.
Time Dimension
The time dimension is very important in every data warehouse because every fact table in the data warehouse is a time series of observations of some sort. In traditional data warehouses, the time dimension is at a daily grain, but for the webhouse the granularity is finer. We have seen some webhouses record at the hourly grain or even minute level. Data column in a relational table normally has the format as year, month, day, hour, minute and seconds (YYYYMMDD:: HHMMSS). We need to create new attributes representing date of week, day of year, quarters from date column attributes. Since, in a web environment, we are analyzing both the click stream behavior and sales, it makes perfect sense to have two time hierarchies: One is more or less the traditional time dimension in the data warehouse: date related to day, week, month, quarter, years (may need to use data transformation function to construct new attributes and properties: weekday, weekend, holiday season etc) which is useful to compare sale across day, month, quarter, or year. The other time hierarchy is the time-of-the-day related to a specific spot within a day, hour, minute in the
day, (some derived useful attributes are early morning, late afternoon, evening, working hour, lunch break, etc). This time hierarchy is useful for site traffic analysis.
User Dimension
To obtain good customer profiles, variables describing the characteristics of the customer should be added. If available, this information is given in a data warehouse where all customer characteristics and historical information about click behavior are stored. To combine this information with the transaction data, the users must identify themselves when visiting the web site so the cookie id could be matched with their names and the transactional data can be merged with customer-relevant data. The customer dimension should contain information such as name, addresses, gender, age, demographics, and lifestyle. Identifying the user is very important to distinguish different types of visitor to the web site. In the user dimension we need to label users as “single visitors”, “repeat visitors”, “visit with single purchase”, “visitor with multiple purchases”, or “most profitable customer” based on the amount they spend. Based on the user dimension information, we should be able to answer business questions related to different user types.
Product Dimension
The product dimension describes the complete portfolio of what the web site sells on-line and the information varies from different on-line stores. For example Amazon.com has a very large product dimension than an on-line bank. Normally the product dimension should contain information such as product key, SKU description, product property (weight, size, color, package type etc), brand, sub category, department), price, manufacturer, warranty information.
3.2.4 Choose the Facts Appropriate for That Grain
Choosing the appropriate fact measures for the grain in the fact table depends on the business objective and analysis purposes. For the clickstream fact, we can choose the time (number of seconds) the user spent on each page. For the order fact table, we can choose revenue, profit, cost, quantity and other measures. The star schema for the webhouse is constructed as shown in Figure 2.
3.3 Data Transformation
Creating a warehouse is not enough because many important information are not in the data warehouse yet, for example, for the session, it is essential to know the number of pages, time spent, or the session leads to purchase or not. For the customer, it is necessary to create attributes such as whether the customers are repeat visitors, heavy-spender or occasional shoppers etc. These new attributes need to be created/derived from existing database columns to make data mining and reporting easier or even possible. There are two sets of transformations that need to take place: (1) data must be transferred from the OLTP systems to the OLAP systems, (2) data may need to go through some transformation or conversion to create some new values, which are not explicitly represented in the data warehouse. The first set of transformation is relatively stable and straightforward. There are a lot of ETL tools on the market for this purpose [10]. The second set of transformation provides a significant challenging for web usage mining since a lot of these transformations are related to the application domains and business goals. Typically in the web warehouse, the data are collected in the clickstream level. For data mining and business intelligence reporting purpose, the data in the data warehouse need to be transformed or aggregated to different level of granularity (session level, order-header level or customer level) depending on the
Session Dimension Business Event Dimension Time Dimension
Clickstream Fact Table
Page Dimension
User Dimension
Order Item Fact Table
Product Dimension Date Dimension Date Dimension Promotion Dimension
Figure 2: Star Schema of Webhouse BusinessEvent_id Session_id Time_id User_id Page_id Date_id Product_id Page_view_time Quantity_ordered …many more Order_item_id Session_id Time_id User_id Page_id Date_id Product_id Promotion_id Order_item_price QuantitySold TotalCost Profit Revenue ..many more Session_id Session_length Referrer Agent Session_host_name Session_IPAddress Cookie_id Client_host First_request_time Last_request_time Total_time_spent Average_time_per/page Session_customer_id Session_visit_count SessionWPurchase_flag RandomBrowsing_flag CrawlerSession_flag Sessiontimeout_flag …many more … Time_id Second Minute Hour EarlyMorning_flag LateAfternoon_flag LunchTime_flag DinnerTim_flag LateEvening_flag …many more … User_id City State Country Gender Age Profession Education_level Marital_status Email Phone_# Repeat_visitor_flag Frequent_purchase_flag Heavy_spender_flag Reader/Browser_flag #OfKids House_income ..many more Page_id PageTemplate PageLocation PageType PageCategory PageDescription Registration_page_flag Shipping_page_flag Checkout_page_flg NumOfProducts NumOfImage NumberOfBanner …many more Date_id Day Week Month Quarter Year Day_#_in_month Day_#_in_quarter Day_#_in_year Week_#_in_month Week_#_in_quarter Week_#_in_year Weekday_flag Weekend_flag Holiday_flag Season …many more… Product_id SKUDesciption. Brand SubCategory Dept. Size Color Weight Price Manufacturer Warranty_info .. many more Promotion_id PromitionName PriceReductionPct AdvType CoupleType BeginDate EndDate Promotion_cost Promition_region …many more… BusinessEvent_id BusinessEventType BusinessEventDesc Search_key_flag Shopping_cart_flag …many more…
mining and reporting goals. For example if the analyst is interested in the difference between session with purchase and without purchase, then the transformation/aggregation operations need to be performed to convert clickstream data into session level. If she wants to understand the customers such as what are the characteristics of the most-profitable customers, then the data need to transform/aggregated further from session level to customer level. There are 3 types of transformations in the web usage mining context:
1. Generalizing/extracting the primitive values to high level values. For example, the “referrer” column for each click session has too many different values but some useful information is embedded in it, so it is useful to create new columns from it, such as the “host” of the referrer and the “domain” of the referrer. Similarly, new columns such as “domain” and “host” from ISPs and customer emails
2. Grouping/summarizing information from multiple columns. For example, in the customer preference survey, there are columns such as “Prefer Basketball ”, “Prefer Football”, and “Prefer Baseball” corresponding to customer’s first, second, third preferred sport. For mining or reporting purpose, it’s better to increase the granularity by generating new column to indicate the customer preference philosophy.
3. The third type of new column created is for inferring information not directly available from existing database columns. For example, to have an image of a customer’s product page views, it needs to know whether a click record is a product page view from “Brands” which is not directly available. This information can be inferred from the “Template” and “Referrer” columns.
Based on our experience, below are some of the typical data transformation operations we found are very popular and useful for web usage mining and reporting.
(1) Click Level Transformation Transformation
Name
Transformation Description Result
Type Referrer indicator for a
product page Creates an indicator variable for referrer for an arbitrary product page. Product detail page views are important information for a webstore. Within a webstore, you can go to a product page from different places depending on how the webstore is designed. (e.g., ViewfromHotArea, ViewfromGifts). To analyzing the click stream data, it is helpful to know which area each product page view comes from and it is defined based on the “Type”, “Template”, and “Referrer” columns:
Boolean
Page view time The number of seconds that a person spends viewing a page Double Credit card indicator
(MasterCard, Visa, AMX etc)
Indicate whether the transaction was completed using which
type of credit card Boolean
Decode the query string The operation returns the search results of the search arguments the customers typed while they surfed the web site.
String Path of session This operation pulls the templates of the session into a long
string. String
Detailed path of the session Similar to the operation above, except you will get the detailed
dynamic generated page String
Last page of the session Return the last page of the session String First page of the session Return the first page of the session String Clickarea The column tells which area a click is on, or “None” for
click.
Click tags Check whether a click is a giftbox view or shopping cart view. String Purchases of products that
appear on Whats_hot pages It is very useful to know who bought products from the “Whats_hot” pages, or what products were bought from the “Whats_hot” pages. However, this is very hard to be done without event log. What can be done is to find purchases of products that appear on “Whats_hot” pages. Note that these products may appear on other pages and customers can buy them there.
Boolean
When did a customer fill the registration (survey) form?
Web site normally has an optional registration form that contains some survey questions. Knowing answers to these questions can help to understand customers better (before any purchases, or after purchases),
Boolean
The above transformations can capture a lot of essential information for reporting and help the business analysts understand and improve the website performance and function, increase customer satisfaction. For example, use the query decode string transformation, it can capture the top 10 failed search key words from the customers as shown in Table 1 from a real online motor store. “Fat boy”, “Chrome” are the most popular items the customers are looking for. Then the store manager can make a decision to add these items to the webstore if a lot of customers showed interests in these items.
Search String # Of Search
Fat boy 1566
Chrome 791 Motorclothes 443 Gtype Fuel tank 325
G-sportster 280 maintenance 260 C-sidecar 210 sissy bar 175 seat 169 touring 163 Table 1: Top 10 Failed Search (2) Session Level Transformation Transformation
Name
Transformation Description Result
Type Customer browser name Return a string containing browser’s name from userAgent. If
the flag is true,otherwise group all unknown browser’s names to “Others”
String Browse release The release number of the browser given the userAgent string.
The main release number is for Mozilla. It will contain the release number for MS Internet Explorer inside “()” if the browser is an IE browser. It contains “AOL” and its release number inside “[]” if the browser is an AOL browser.
String
Browse OS The OS running the browse String
Returned visitor True if the user is a returned visitor Boolean Session Length The total clicks of this session Integer
Long session Indicate whether the session is a long one or not (more than 6
clicks) Boolean
Short session Indicate whether the session is a long one or not (1 0r 2 clicks) Boolean Session duration The total time spent on this session Double
Referrer host Host of the referrer String
Referrer domain Domain of the referrer String
Url site Return the url site such as YAHOO, Excite and so on String
ISP host Internet Service Provide Host String
What day it is of the first visit
A number to indicate which day it is for the first visit Double What day it is of the last
visit A number to indicate which day it is for the last visit Double Is the visit a weekend Indicate whether the visit happen is a weekend or not Boolean Is the visit a weekday Indicate whether the visit happen is a weekday or not Boolean Any purchase on this
session Indicate whether the session leads any purchase or not Boolean Purchase amount in
different areas In addition to the numbers of product detail page views that came from different areas, it is also important to know customers’ purchase amount from each area. Since it is hard trace where a purchase come from precisely, it can be estimated by distributing the total purchase amount to each area using the proportion of the number of product detail page views from this area.
Double
Purchase quantity in
different areas Similar to customers’ purchase amount from each area, it is necessary to know customers’ purchase quantity from each area. Double HourofDayof the server Shows the visitor’s time from the first request date based on the
location of the server Double
Time period of the day Based on the HourofDay, you can add more columns to indicate whether the visit time is in the morning, or evening and so on (such as early morning, late evening, lunch time etc)
Boolean
Table 2 below shows the top 10 path of a website without any purchase. These paths can help the website understand the customer click behavior and reveal a lot of reasons why the customers left the website without purchase. For example, the top one path is main.jsp-> splash.jsp (14622 sessions). The customers visited the main.jsp and then left the website after they clicked the splash.jsp. A further analysis by the web designer found out that the splash.jsp took a while to compile and download and the effect of the animation of the spash.jsp make a huge portion of the contents of the store invisible, thus caused a lot of frustrations among the customers, so they left. After the splash.jsp was removed, the conversion rates got improved significantly
Web Path Count
main.jsp->splash.jsp 14622 main.jsp->main.jsp 3731 main.jsp->main.jsp->main.jsp 790 main.jsp->login.jsp 329 main.jsp->hot.jsp->registration.jsp 303 Login.jsp 274 main.jsp->survey.jsp 216 product.jsp 212 main.jsp->product.jsp 192 main.jsp->search.jsp 180
Table 2 : Top 10 Paths Lead to Non-Purchased Sessions (3) Customer Level Transformation
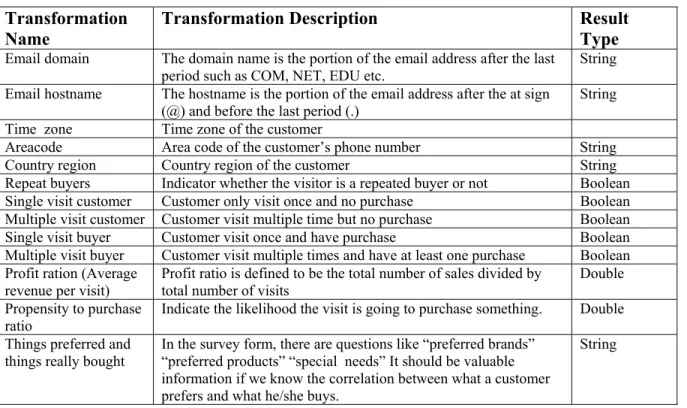
Transformation
Name Transformation Description Result Type
Email domain The domain name is the portion of the email address after the last period such as COM, NET, EDU etc.
String Email hostname The hostname is the portion of the email address after the at sign
(@) and before the last period (.) String Time zone Time zone of the customer
Areacode Area code of the customer’s phone number String Country region Country region of the customer String Repeat buyers Indicator whether the visitor is a repeated buyer or not Boolean Single visit customer Customer only visit once and no purchase Boolean Multiple visit customer Customer visit multiple time but no purchase Boolean Single visit buyer Customer visit once and have purchase Boolean Multiple visit buyer Customer visit multiple times and have at least one purchase Boolean Profit ration (Average
revenue per visit) Profit ratio is defined to be the total number of sales divided by total number of visits Double Propensity to purchase
ratio Indicate the likelihood the visit is going to purchase something. Double Things preferred and
things really bought
In the survey form, there are questions like “preferred brands” “preferred products” “special needs” It should be valuable information if we know the correlation between what a customer prefers and what he/she buys.
String
The customer level transformation created a lot of new columns in the data warehouse to make the reporting and data mining easier and more meaningful at the customer level. For example, identify whether a customer is single visitor, buyer, repeated buyers etc, is very important for the webstore. Table 3 can reveal how many customers are loyal customers, occasional shoppers, or just pure visitors.
Type Count
Single Visit 1823 Multiple Visit 37 Single Visit Buyer 269 Multiple Visit Buyer 58 Unknown 2846
Table 3: Single/Multiple visitors/buyers
After the data transformations are done, data in the web house are organized into different level. Below are some of the most useful summary tables and facts table for web usage mining and reporting.
CLICK_LINES A row for each Web page viewed SESSIONS A row for each Web session CUSTOMERS A row for each customer
GIFT_LINES A row for each gift registry item of each customer ORDER_LINE Contains a row for each order line of each order ORDER_HEADERS A row for each order of each customer
LINE_ITEMS ORDER_LINES joins with CUSTOMER, ORDER_HEADERS, PRODUCTS, ASSORTMENT, PROMOTIONS
Table 4: Some Summary and Facts Table in the Web House
4. Pattern Discovery: A Data Warehouse/OLAP Approach
Data Warehouse/OLAP (On Line Analytical Processing) is an approach of integrating data mining, data warehousing and OLAP technologies. OLAP systems pre-calculate summary information (data cubes) to enable drilling, pivoting, slicing and dicing, filtering to analyze business from multiple angles or views (dimensions). Web mining your site in the webhouse can reveal actionable and meaningful patterns for users and useful click sequence for the web site design. Below we discuss each of them in details.
4.1 Construct Cubes from Webhouse
A data cube is pre-calculated summary data organized in a way that the cells of the cube contain measured values and the edges of the cube define the natural dimensions of the data. (The data cube may have more than 3 dimensions so technically it should be called a hypercube). The dimensional elements in the cube are organized in a hierarchy and you can roll-up and/or drill down the dimension hierarchy to get a different view or understanding about the cube data. A data cube offers the benefits for data analysis such as an immediate response to a business query, the ability to drill down and roll up the multiple dimensional data in the cube, to analyze business measures such as profit, revenue, quantity from different angles, perspectives and various ancillary factors. We can create two cubes from the webhouse as shown in Figure 2, one cube for the clickstream, and another cube for the order item based on the fact table clickstream, the ordered item and session, product, user, page, and time dimension table. In the webhouse, we already have data organized based on a multiple dimensional model. All that is required is to plug into the OLAP software. There are many OLAP tools such as MS OLAP, Cognos, and Essbase to choose from to build large cubes. Cutting and dicing these cubes reveal significant information about your web site and sales situations. For example, we can find out the top pages of the sites, top domains, top browsers, the view time of top page, top exits page of the site, top referrer of the site, top products by sales, quantity, top referrers by page request, sale, quantity, users, web site activity based on day, month or even hour, minutes. We can also find out who our visitors include, how much they spend, the sale cycles etc.
From the OLAP cubes, many business intelligence reports can be derived. Business reports are the most important tool for business analysts but are unappreciated by a lot of companies. Business intelligent reports can provide many insightful information about the web store such as sales of products across different refers, best selling products/bottom products, top domains/bottom domain, top searched keywords etc.
4.2 Mining the Webhouse Data
OLAP is a key component of this approach, but OLAP alone is not good enough for e-commerce applications. Some of the challenging issues cannot be answered by examining the measured values in the cubes. For example, to answer the following question such as “Given a set of page views, will the visitor view another page on the site or will the visitor leave”, it is very difficult if not impossible to find a satisfactory answer to them based on the OLAP cube data from the webhouse. A lot of mining algorithms and methods such as association algorithm, decision tree, neural network, Bayesian algorithm, clustering method etc can be applied for web usage mining to derive insightful knowledge rules to understand
the business and customers, build prediction models for classification and generate campaign scores for product promotion. Below we discuss how these algorithms can help to solve some of the challenging problems for the e-commerce.
4.2.1 Association Rules
Association rule algorithms were originally designed to analyze market basket data to find correlations in items purchased together, like if a customer buys product A, what is the likelihood that he will buy product B. In the web usage mining, association rule algorithms can be used for two purposes. First, analyzing the on-line purchase data to determine which products are sold together by on-line customers (similar to the traditional supermarket basket data analysis). On-line shopping databases contain historical data on prior customer choices where each customer has selected a subset of products. This data can be used to generate a dynamic recommendation of new items to a customer who is in the process of making the item choice. Another use of the association rule algorithm is to analyze the page view hits in a session. Websites also display dynamically changing set of links to related sites depending on the browsing pattern during a surfing session. Use of the adapted association algorithm can find related pages that are often visited together. The pages may not have hyperlinks between them. As a result of association rule analysis, it is possible to optimize the web site structure and detect drawbacks that had not been obvious in the past. This information may help the web designer to redesign their web site (add direct link between those strong correlated pages), it may also help web server do per-fetching or pre-compiling the web pages (presently many web sites have dynamic page generation) to reduce the user waiting time. Websites also display dynamically changing set of links to related sites depending on the browsing pattern during a surfing session.
However we feel that the recommendation is inherently a different problem, the main reason for this is that preferences are due largely to the taste and interest. When a customer surf the webstore, whether purchasing or visiting web site, not all actions (put a items into shopping cart, or click thorough different web pages) are elected because of their association with some previous actions (other item already in the cart, or already went thorough some previous pages) [8]. We believe there are two behaviors: renew choice or association choice. Starting from the scratch, some need drives the customer to select the click first page/first item, which is due to some independent need that we call the renewal choice. After the first move, a customer may stop, or click another page/select another item by association or by another renewal choice, iteratively. We propose a hybrid approach (statistical association rule approach) to compute the probability of a new move becoming the next choice given the current status, and make a recommendation list based on a ranking of this probability. What makes this approach different from the usual association rule approaches, is that they account not only for the choice making, or buying associated with the items present in the shopping cart (associative buying), but also for the fact that a customer exercises an independent choice unrelated to the existing items in the shopping cart (renew buying). We compute the probability of both renewal choice and associative choice given the items in the shopping cart, and obtain the probabilities for each item given the partial basket content, and obtain the probabilities for each item given one of these two buying modes. The results from this analysis are very useful for promoting cross-sell and up-selling for the online web store. Based on this consideration, we tested on one client’s
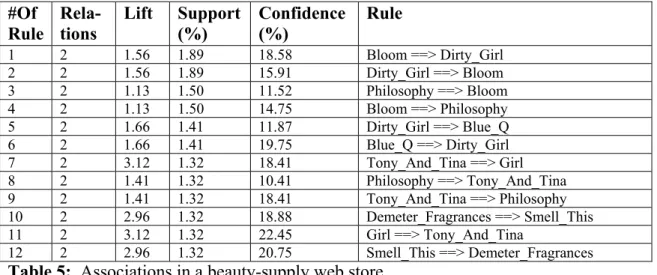
site and the association rules in Table 5 reveals that this approach generates more meaningful and actionable associations.
#Of
Rule Rela- tions Lift Support(%) Confidence(%) Rule
1 2 1.56 1.89 18.58 Bloom ==> Dirty_Girl 2 2 1.56 1.89 15.91 Dirty_Girl ==> Bloom 3 2 1.13 1.50 11.52 Philosophy ==> Bloom 4 2 1.13 1.50 14.75 Bloom ==> Philosophy 5 2 1.66 1.41 11.87 Dirty_Girl ==> Blue_Q 6 2 1.66 1.41 19.75 Blue_Q ==> Dirty_Girl 7 2 3.12 1.32 18.41 Tony_And_Tina ==> Girl 8 2 1.41 1.32 10.41 Philosophy ==> Tony_And_Tina 9 2 1.41 1.32 18.41 Tony_And_Tina ==> Philosophy 10 2 2.96 1.32 18.88 Demeter_Fragrances ==> Smell_This 11 2 3.12 1.32 22.45 Girl ==> Tony_And_Tina 12 2 2.96 1.32 20.75 Smell_This ==> Demeter_Fragrances Table 5: Associations in a beauty-supply web store
4.2.2 Classification/Prediction
Classification/prediction is a very popular data mining technique to build a model based on the training data and then apply the model to assign a new item to a certain class. There are many algorithms such as decision trees, neural networks, Bayesian networks, and probability theory for classification. For example, to understand the customers who spend more than $12 in the web site, you can use decision tree algorithm to build a model, which may reveal such pattern as: the customer spends more than $12 are the single female, age between 25-35 and make more than 35000 a year. Another application for classification/prediction is target-oriented campaign. Mass campaign has a very low response rate, typically 2-3%. In target-oriented campaign, company only send campaign message to a small portion of customer who are mostly like to respond. Even though sending emails to all on-line customer is very cheap, It is still important to target e-mail effectively as suggested by Berry and Linoff because customers might read one target-email, are less likely to read a lot of junk email messages [4,6]. And another important reason is that if the customers are fed up with these off-target email messages, they can revoke their permission to be contacted by the web store. To identify who are mostly like to respond to your campaign, avoid generating too many off-target emails and improve the service equality, we can build a prediction model based on the historical data (which has the responders vs. non-responders in the past campaigns) then apply the prediction model to the current customers and sort the customer list with a probability score, the top of the sorted list are those customers who are likely to respond the campaign.
4.3.3 Clustering
Clustering techniques are useful when there are no classes to be classified or predicted. Clustering algorithms group a set of objects into different groups based on measures so that the objects in the same group are similar to each other and objects in different groups are different. In web usage mining, clustering algorithms can be used in several ways:
(1) Profiling customers based on some features such as purchasing amount, region, purchased products. For example, we group customers into different groups such as heavy-spenders, light-spenders, or browsers based on the amount. We can extract
similar features from this cluster and find out heavy-spenders are mostly young technical professionals, single male. The results of clustering of web data can help on-line store to identify proper customer segments with common characteristics, and target these segments for campaign email or product promotion, make special offer tailored to their needs and requirements.
(2) Clustering navigational path of web hits. As shown in [7,16], clustering navigational path is very important for user segmentation, the result can help web designer understand, or predict visitors’ navigation pattern to make the web site more efficient or more close to the visitors’ preference. For example, if the clustering results shows Page P1, P2, P3 are in the same cluster, then the web server can pre-fetch Pages P2 and P3 or pre-compile Page P2, P3 while the user is still viewing Page P1 to reduce the loading time or compile time, that way it help reduce the user waiting latency. Another potential use is to find subsets of the users that would benefit from sharing a single web cache rather than using individual ones.
5. Pattern Evaluations and Deployment
In the Data Darehouse/OLAP framework, the last step is to evaluate the mining results and then adopt actionable results. After the mining algorithms are applied, many patterns may be identified but not all of them are interesting or actionable. Unlike most of the pattern evaluation approaches, which rely on an SQL statement to query the database and evaluate the results, in our Data Warehouse/OLAP framework, the data cube is an essential component in the mining procedure and we can dice and roll up the data cube to easily verify mining results. After the mining patterns are verified to be “golden nuggets,” data miners and data analysts can take proper actions based on useful actionable mining results. In traditional data mining applications, it is always challenging or time consuming to convince the organization to take actions based on the mining results to improve the business. For example, in a brick-and-mortar store, if the data mining results reveal the customers buy product A tend to buy product B, in order to create the cross-sell opportunity based on this finding, some possible actions are to put the products A and B together in the same shelf, which need to physically move the products A and B from different shelves. In a web-store, such discovery can be made easily without much cost and hassle. It is very flexible to change the web site design, layout and put relevant product information together to create cross-sell and upper-sell opportunity. Another example is customer campaign. A lot of companies send marketing campaign information such as catalog and coupon via snail mail based on data mining prediction models, the whole procedure normally takes a few months and costs of millions dollars. But in a web-store, sending campaign emails to massive customers is already a key component of E-commerce system, and target customers based on data mining findings via email to promote product is easy to implement and these data mining findings can quickly bring more revenues to the web-store.
6. Conclusion
E-commerce webstore provides a killer domain for data mining application. In this paper we have proposed a framework for web usage mining and business intelligence reporting. We address some of the key problems and issues in the web usage mining application. We use web application server to collect all the relevant data (clickstream, transaction, customer information) for the analyze purpose and provide a unified database schema for difference data source. The construction of the webhouse is an integral part of our framework, which provides an integrated environment for data collection, data
transformation. In the framework, we integrate the data warehouse construction, data mining, business intelligence reporting and pattern deployment into e-commerce system smoothly. This tight integration significantly reduces the total time and effort to build a data mining system for web usage mining. We provided a general approach and guidelines for on-line web-stores to mine their web data and generate business intelligence reports. We identify some of the challenging problems and pitfalls in each phase and provide possible solutions to them. Our framework focus on on-line web store and some of the ideas have been implemented in some commercial web usage mining system. We believe this framework can be adapted to apply in some other domain such as Business-to-Business. The framework and ideas presented in the paper have been implemented in some commercial web usage mining systems through the first author’s consulting engagement with some industry vendors. There are some other challenging problems in web usage mining such as how to scale the web mining algorithms to handle large amount of data in the 100G or even terabyte range (some of the large e-commerce site like Yahoo handle 1 billion page view a day). The scalability is crucial for a successful e-commerce system. We hope to report our findings in this research topic in the near future.
7. References
[1] Accrue Software Inc, “Driving Business Decision in Web Time”, Web Mining Whitepaper http://accrue.com/forms/webmining.html
[2] Anahory,S. and Murray,D., “Data Warehousing in the Real World”, Addison Wesley, 1997 [3] Suhail Ansari, Ron Kohavi, Llew Mason and Zijian Zheng, “Integrating E-Commerce and Data
Mining: Architecture and Challenges”, WebKDD2000 Workshop
[4] Jonathan Becher, Ronny Kahavi, “Tutorial on E-commerce and Clickstream Mining”, First SIAM International Conference on Data Mining.
[5] Michael Berry, Gordon Linoff, “Mastering Data Mining: The Art and Science of Customer Relationship Management”, John Wiley & Sons
[6] Catledge L. and Pitkow J., “Characterizing browsing behaviors on the world wide web”, Computer Networks and ISDN Systems, 27(6), 1995
[7] Domingos P., Hulten G., A General Method for Scaling Up Machine Learning Algorithms and its Application to Clustering, Prod of the ICML-2001
[8] Hong S.J., Natarajan R., Belitskaya I., A New Approach for Item Choice Recommendation
[9] Hu X., Cercone N., An OLAM approach for Web Usage Mining, Prod. o 2002 IEEE Fuzzy Systems [10] Kdnuggets.com http://www.kdnuggets.com/datasets/kdd-cup-2000.html
[11] Ralph Kimball “The Data Warehouse Toolkit”, John Willey and Sons, 1996
[12] Ralph Kimball, “Clicking with your Customer, Intelligence Enterprise”, Intelligent Enterprise, Jan 05, 1999, Vol 2, No. 1
[13] Ralph Kimball, Richard Merz, “The Data Webhouse Toolkit: Building the Web-Enabled Data Warehouse”, John Willey and Sons, 2002
[14] Ronny Kohavi, “Mining E-Commence Data: The Good, the Bad and the Ugly”, Invited paper at SIGKDD 2001 Industry track
[15] Ronny Kohavi and Foster Provost, “Application of Data Mining to Electronic Commerce”, Data Mining and Knowledge Discovery, 5(1), 2001
[16] Raymond Kosala, Hendrik Blockeel, “Web Mining Research: A Survey”, ACM SIGKDD, July 2002, Vol 2, Issue 1
[17] Jesun Mena, “Data Mining Your Website”, Digital Press, 1999.
[18] Jesus Mena, “Beyond the Shopping Cart”, Intelligent Enterprise, Jan 05, 1999, Vol 2, No. 1 [19] Sane Solution, “Analyzing Web Site Traffic”, 2002,
[20] Song I., Whang K., “Database Design for Real-World E-Commerce Systems”, IEEE Data Engineering Bulletin, March 2000, Vol. 23, No. 1, 23-28
[21] Song I., LeVan-Shultz K., “Data Warehouse Design for E-Commerce Environment”, WWWCM99
[22] Jaideep Srivastava, Robert Cooley, Mukund Deshpande, Pang-Ning Tan, “Web Usage Mining: Discovery and Application of Usage Patterns from Web Data”, SIGKDD Explorations, Vol 1,
Issue 2
[23] Pang-Ning Tan, Vipin Kumar, “Modeling of Web Robot Navigational Patterns”, WebKDD 2000 conference
[24] Chsittiane Theusinger, Klaus-Peter Huber , “Analyzing the footsteps of your customers”, WebKDD 1999 Workshop
[25] Gaul Wolfgang, Lars Schmidt-Thieme, “Mining web navigation path fragments” , WebKDD 2000 conference