6105
ESSMO: An Efficient Search Scheme on
Encrypted Cloud Data using Modular OPE
Jeevitha B K, Madurya V N, Pushpa C N, Thriveni J and Venugopal K R
Abstract— In today’s world, the number of users/research scholars is increasing day by day. The maintenance of papers and searching of papers based on user search is done using TEESs algorithm, which makes use of Text Frequency-Inverse Document Frequency (TF-IDF). The unique articles in the TF- IDF matrix are found out and then the papers are listed for an input of user query based on descending order of TF-IDF. The algorithm is better with the higher the value of TF-IDF. In this paper, Modified TEES algorithm is proposed which is built on top of TF-IDF algorithm which mines additional information on the top keywords of each page in the article on the web. The proposed method makes use of Modular Order Preserving Encryption (MOPE) algorithm that helps in searching the data on encrypted format and more secure than existing Order Preserving Encryption Scheme (OPES) algorithm. During the ranking phase, the Modified TEES method compute the relevance score, which is the combination of TF-IDF along with the mined data and resolves the issues associated with TEES [1]. The Modified TEES is compared with TEES with respect to time taken for recommendations, throughput and relevance score. The results shows the proposed algorithm is efficient as compared to the existing algorithm.
Index Terms— Cloud, Frequency, Google API, Modular OPE, Ranking, TF-IDF and Relevance Score.
—————————— ——————————
1 INTRODUCTION
C
loud Computing is associated with a new paradigm for the provision of the computing infrastructure. This paradigm shifts the location of the infrastructure to the network to reduce the costs associated with the management of hardware and software resources. Information and Communication Technology (ICT) [2] community is attacked by the cloud for set of services and characteristics provided to them. However, some of the existing technologies of the cloud draws the concepts of virtualization, utility computing or distributed computing.Cloud is based on service model, where data is maintained offloading the contribution of the device resources. Mobile Cloud Storage (MCS) [3] provides good
amount of online services and provide a file storage system based on devices [4]. The users will be allowed to store files and retrieve files from the cloud with the help of wireless communication, data availability, facilitates without losing the mobile device resources [5]. The data is encrypted, stored in cloud as mobile devices and PCs have security threats [6]. The mobile device with limited battery capacity faces the challenges of the computing power while encrypting the data [7]. The proposed method provides the security enhancement to mitigate the file leakage. The repetition of words and preserving the order of the encrypted data is done using attributes values.
There is a large volume of data set, which spans across multiple independent clouds. Data mining is a process of information aggregation from source generators and modelling of such information is done along with categorizing the data. The cloud platform will provide scalable and massive solution for data privacy and it is responsible for providing efficient trust mechanism for storing the files in a trusted manner. Before uploading the file to the server, it has to be encrypted and then decryption mechanism can be run only after downloading the files [8]. For the end users, the devices have limited battery capacity and computing power that leads to high-energy consumption. Therefore, the responsibility is transferred to the cloud in the proposed method. It performs the search of the articles and ranks them in ————————————————
Jeevitha B K is currently pursuing PhD degree program in the department of Computer Science and engineering in University Visveswaraya College of Engineering, Bangalore University, Bengaluru, India, E-mail: [email protected]
Madurya V N is currently pursuing masters degree program program in the department of Computer Science and engineering in University Visveswaraya College of Engineering, Bangalore University, Bengaluru, India, E-mail: [email protected]
Thriveni J is currently working as a Professor program in the department of Computer Science and engineering in University Visveswaraya College of Engineering, Bangalore University, Bengaluru, India, E-mail:
Pushpa C N is currently working as a Assistant Professor program in the department of Computer Science and engineering in University Visveswaraya College of Engineering, Bangalore University, Bengaluru, India, E-mail:
6106 an optimize fashion so that the accuracy is increased.
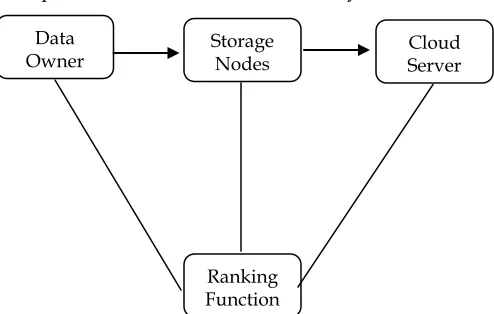
Fig 1: Traditional Encryption Scheme
Traditional cloud storage system architecture has the procedures that includes file encryption by the data owner, outsourcing the data to the cloud storage, and then encrypted data search/retrieval of the data users in cloud. Fig 1 shows the traditional encryption Scheme [8], in which the encryption of file is done and stored into the cloud server. Ranking function is used to compute the word frequency and ranks the files.
The recent research has gained much attention on how to search the encrypted data that led to the development of several algorithms on searchable encryption. A searchable encryption scheme [9] employs a pre-built encrypted search index that l e t the users with appropriate tokens securely search over the encrypted data via keywords without first decrypting it. One such scheme is Order Preserving Encryption (OPE) that preserves the numerical ordering of plain text and Modular OPE is the extension of OPE that enhances the security and the doesn’t reveal the location of the stored data.
1.1 Motivation
In the previous schemes, the single-keyword search is used to search keywords on encrypted cloud data. TF-IDF algorithm suffers from relevance score issue if multiple articles have the same TF-IDF, then it becomes difficult for TF-IDF to rank the papers in the right order. The second issue is that it does not consider the additional information of the user query to rank the articles, which can increase the TF-IDF value. Usage of hashing and wrapping process consumes more time and space.
1.2 Contributions
The proposed system has the following contributions:
1) Modular OPE reduces the risk of message leakage. 2) MOPE does not reveal the physical location of the
file stored.
3) MOPE provides the double security compared to TEES.
4) Additional suggestions are also considered from the user prospective to improve the searching.
5) Network traffic is reduced by communicating the selected index.
6) Proposed method reduces the file retrieval time and reduces the workload on mobile devices.
1.3 Organization
The organization of the paper is as follows: Section 2 describes about the Literature Survey made for this work. Section 3 briefly describes about the Proposed Model. Section 4 tells about the Performance Metrics used in the paper. Section 5 draws the Performance Analysis of the proposed work. Section 6 concludes the paper.
2 LITERATURE SURVEY
The reduction on the cost of the end user with respect to the software and hardware constraints is achieved by making use of cloud computing domain [2]. The cloud can be used in three different usages - Infrastructure as a Service, Platform-as-a-Service and Software-as-a-Service. In Infrastructure-as-a-Service, large set of devices are managed in order to provide customers the capability to deploy and run their software stacks. Platform as a Service is a layer on top of Infrastructure as a Service in which software’s are pre-installed and the hardware resources are added based on the requirements. Software as a Service is a software deployed on cloud where users can use them.
Cloud systems provide scalability in an elastic fashion. The user and the provider has an established trust and it has to be maintained. This trust can be achieved by encrypting the data before it is stored on the cloud system and hence there is no leakage. Xiaojun Yu [3] provides the algorithm of security function and Data
Owner Storage Nodes Cloud Server
6107 deployment guide.
As per the reports of Huang [4], the amount of digital content is increasing exponentially and reached 8zb in 2015. The Storage facilities are equipped with huge amount of hard- ware devices with public cloud offerings and few organizations outsource it to different company. The price calculator will take into consideration storage needs, number of hits and duration of need to make the solution less expensive [5].
Many antivirus companies exist in the market which pro- vides anti-virus software’s for laptops and mobile devices [6]. The running of this software’s on an off-line environment require significant amount of power and have huge amount of overhead with detection capabilities running low. In order to perform static analysis which is signature based also is very high. The trends of behavior detection engines require more device resources and power, which can be offloaded to cloud to reduce power capabilities.
The data storage can be done on mail servers as well as file servers with encryption in order to perform reduction in risks such as security and privacy [7]. A scheme of cryptography for searching the encrypted files and then provide search results. The results cannot be obtained without the authorization of users.
The detection and traditional way of making use of desktop-based applications for security solutions requires intensive amount of computational power [10]. The mobile as well as PC’s are exposed to virus attacks and cannot have multiple detection engines, which are costly and are limited with respect to bandwidth, CPU usage, memory computation and power. While these security solutions can be provided as part of off shore environment then complexity is reduced and less amount of power is used.
The data, which is encrypted and is stored, uses a public key. Consider two users namely Bob and Alice. Bob is sender of email and Alice is the receiver. Bob will use public key of Alice. A gateway algorithm [11] performs machine learning and looks for word named ‛urgent‛ and wants to perform priority based routing. In order to provide better security Alice will have to share the key on top of gateway which enables gateway to securely look into keyword ‛urgent‛ without any data analysis on remaining sentences.
Outsourcing of data storage into a third party server in a private fashion is done with the aid of Searchable Symmetric Encryption (SSE) [12] [13] and allows the search ability for the end user. Two solutions are provided which overcomes the disadvantages of constant round schemes. In the first approach, the time taken for returning of document depends on the size of data. In the second approach adaptive SSE is used in which queries executed on the server can be changed in an adaptive way.
When an entity or an institution allows outsources of data storage to another institution in a private way and provides the ability to search for the data information is called Searchable Symmetric Encryption (SSE) [14] [15]. The method is more efficient than constant round schemes. The admin will submit a query and then data is retrieved based on natural language processing. When a user stores the files on server in an encrypted format, later the users wants to retrieve the files in a secure manner [16].
When applications are used for doing top-k document search then inverted indexes are the best choice. Inverted index is used to provide sequence of lists and each of these lists has elements called as positing elements. Each word will have relevance score which can be used for ranking of documents [17].
In order to perform data privacy protection the data must be encrypted before storing and decrypted after downloading the file. Traditional methods perform Boolean search and have data utilization issues. When the files are searched relevance score based results helps in improving accuracy and relevance score. One-to-many mapping method is used to store the sensitive data and allows the ranking of articles without losing privacy [18].
Sensitive information are offloaded to the cloud. In order to achieve better privacy, the sensitive information are encrypted. When users don’t have the knowledge of encrypted cloud data then, they will post the query and obtain the relevant matching files. Secondly, there is a huge amount of network traffic which occurs while looking for the queried keyword. The ranking algorithm [19] will improve the current approach by providing ranked order of keyword frequency while even maintaining the data privacy.
6108 complex data in two major domains one is local site traffic
and other one is public based cloud systems. The usage of cloud by end users provides benefits of flexibility as well as economic savings. In order to have better data privacy, data is sent through an encryption function and stored. Multi keyword rank search privacy preserving algorithm [20] provides better rank search as well as secure utilization system.
The ranking of data based on multiple keywords will search files and ranks based on the highest frequency. The multi- keyword search does not tolerate spelling error or allows a single keyword to be searched. Multi-keyword fuzzy search [21] performs hashing of the data and eliminates the need of predefined dictionary and reduces complexity of search.
The number of searches performed is increasing globally. Indexing [23] reduces the retrieval time for search results. There are many innovative ideas in the field of index storage, construction of index and query execution as described by Justin and Alistair.
The input to OPES is user-provided target distribution that will be converted from plain text to encryption based target distribution. Find the P unique values from user specified target distribution; the values are then sorted and finally stored into the database in the encrypted form. ith plain value is converted into ith target value during encryption and hence reverse process must be triggered in order to perform the decryption [24].
The text corpora are the collection of discrete data. Latent Dirichlet allocation (LDA) [25] is a Bayesian model with three layers. Each collection is modelled as a set of topics. Each topic is associated with set of topic probabilities. When LDA is used for text modelling the topic probability will represent the document. These probabilities are used for classification of text as well as collaborative filtering.
Documents and queries will be defined using words based on ordered sequence in information retrieval systems used for statistical natural language processing applications. The TF- IDF weight is computed for each word in the articles which are uploaded online based on probability computation and helps in ranking of articles and is better than BM25 weight method [26].
3 PROPOSED MODEL
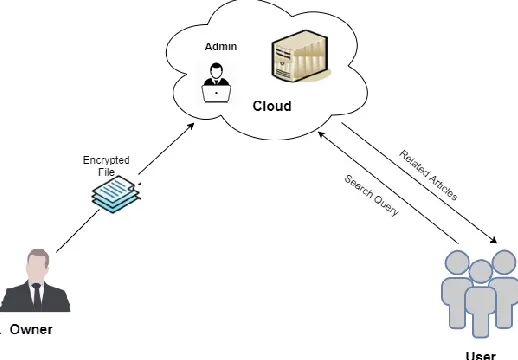
Fig 2 shows the proposed model that contains the owner, user and cloud as entities. The owner has the
Fig 2: Proposed model
authority to upload the encrypted articles after completing the processes such as stemming, tokenization, frequency computation, TF-IDF calculation. Once the articles are uploaded, the admin who resides inside the cloud has the access to view the user details, encrypted articles. The user who is in need of the article sends the search query in the encrypted form. The cloud calculates the relevance score of the keyword with the help of Google API. Then the articles which have highest relevance score value are sent to user along with few suggestion. Then the user can download the article.
3.1 PROPOSED WORKFLOW
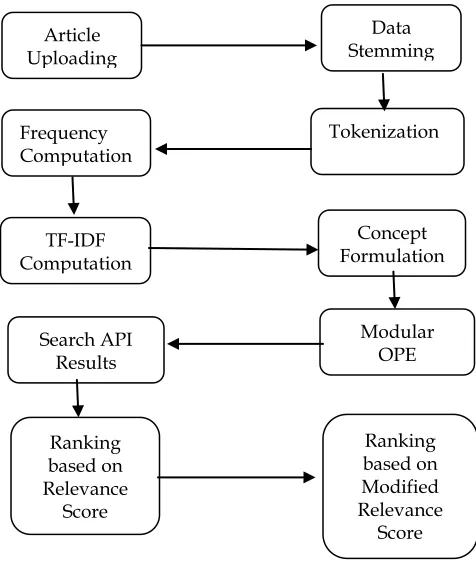
The Proposed workflow has 10 modules as shown in Fig 3: Article uploading, Data Stemming and Cleaning, Tokenization, Frequency Computation, TF-IDF Computation, Concepts Determination, Additional Feature Vector, Ranking of papers for the given search text based on relevance score and modified relevance score.
Table 1 shows the notations used for the algorithms in the paper.
3.1.1 Article Uploading
6109 password, address, city, state, pin code and email. All the
basic validations are performed and if all the basic validations are successful then a set of user names are retrieved from the application and if duplicate username exists in the application then, error message is sent to the end user otherwise user will get registered successfully.
Fig 3: Proposed Workflow
The research scholar can login into the application by providing valid username and password. If authentication is successful then research scholar will be able to upload an article. While uploading articles research scholar will provide article name, keyword list, author list, publisher list and file to be uploaded. All the fields are verified for mandatory validation and file is verified whether it is pdf file or not. If all the fields are given and file is also valid then article names which have been previously saved is retrieved and compared against the current article name. If the article name exists in the list then error message is sent to the end user otherwise the file contents are encrypted using order key encryption and then stored on the cloud system. The article details are given in Table 2.
3.1.2 Stemming and Data Cleaning of Articles
Stemming is a process of removing the affixes (usually suffixes) to arrive at a base from that may or may not necessarily constitute an actual word. Stemming process is
important in Natural Language Processing (NLP) and Natural Language Understanding (NLU). It is also a part of morphology and artificial intelligence information retrieval and extraction. It continues from very conservative to very liberal modes of stemming.
TABLE 1 Notations Used Symbols Definitions
A Article Name
Ai ith article
AiPj Cleaned article pages
CAcount Count of cleaned article pages
f Frequency of word w
fvid Unique id for word w
f v1, f v2,...,f vn Feature vector set
P1, P2,..., Pn Set of pages
Npages Number of page
WC Word count
p page number
Q Search query
Qi FIFO Queue
SW1, SW2,..., SWn Set of Stop words
W Word
W1, W2,..., Wn Set of tokenized words uw1, uw2,..., uwn Unique set of words
TABLE 2 ARTICLE DETAILS Parameter Names Parameter Description
ARTICLE ID Unique auto generated ID for the articles
ARTICLE NAME Name of the article
PUBLISHER List of publishers
ENCARTICLEFILE Modular Order key encryption of the file
Data cleaning is a pre-processing step which is responsible for removal of special symbols and stop words from the article. Stop words are list of words like is, the, about, etc. In the implementation of the proposed method, more than 1000 standard stop words with unlimited custom stop words are used to clean an article data.
Fig 4 shows the steps involved in stemming and data cleaning of articles. The Article Details are first taken out by making use of Apache POI API and converted into a list of pages. For each of the pages the words are taken out and stored into a FIFO queue with the help of FIFO Queue Article
Uploading
Data Stemming
Frequency Computation
Tokenization
Concept Formulation
Modular OPE TF-IDF
Computation
Ranking based on Relevance
Score Search API
Results
Ranking based on Modified Relevance
Score
Article details
FIFO Queue Assembler
Clean Article Details
Stop word and special Symbol Synthesizer
6110 Fig. 4: Data Cleaning and Stemming of Articles
assembler module. The length of FIFO queue is measured. Starting from the 1st word till the number of words, each word is taken out and if word is special symbol or stop word then the word is removed with the help of Stop Word and Special Symbol Synthesizer. The sequence of words are stored in a separate queue in order to obtain clean article details. The data cleaning and stemming algorithm is summarized in Algorithm 1. Table III gives the parameters of the cleaned page of an article details.
Algorithm 1: Stopword Cleaning Algorithm
Input: Article Ai
Output: Cleaned article pages AiPj
Step 1: Divide the article into number of pages P1, P2,..., Pn Step 2: for each page Pi, remove the unwanted symbols
and form a Queue Qiof the words in a page
Step 3: Measure the count of number of words Wi
in Qi. for each Wiin Qi
if Wi SW1, SW2, .. , SWn
move on to next element of Qi
else
add W to CAand move to next element of Qi
end if end for
Step 4: After the above steps are done a set of clean article pages are obtained A1P1, A1P2, ... , A1Pn
TABLE 3
DATA CLEANED ARTICLE DETAILS Parameter
Names
Parameter Description
CLEANID This is auto generated ID for the clean article
ARTICLE NAME Name of the article
CLEANED ARTICLE PAGE
This is the article page after data cleaning is applied
PAGE NO This is the page no of the article data
3.1.3 Tokenization of Articles
Tokenization is responsible for converting the clean data into a set of tokens across all the pages of the articles. The tokenization of articles will be stored in columns as described in Table 4.
The tokenization algorithm is provided in Algorithm 2.
3.1.4 Frequency Computation
Frequency computation is a process of removing the repeated words in a page and assigning the weight to each of the words. Frequency is number of times a token appears in an article. The details of the frequency
computation are presented in the Algorithm 3. After the frequency computation is done for an article, the data is stored in the format as provided in Table 5.
Algorithm 2 Tokenization Algorithm
Input: Set of cleaned article pages A1P1, A1P2, , A1Pn.
Output: Tokenized Words W1,W2,. ,Wn.
Step 1: Measure the count of FIFO Queue CAcount.
for each word in CAcount
assign ID and move to next word endf or
Measure the number of elements of FIFO queue NFIFO.
The set of words W1,W2,. ... ,Wn is the tokenized set.
TABLE 4
Tokenization of Articles Parameter
Names
Parameter Description
TOKENID unique id for the word after tokenization
TOKEN NAME Word present in the article
ARTICLE NAME Name of the article for which tokenization is performed
PAGE NO This is the page number in which the word
is present
Algorithm 3: Frequency Computation Algorithm
Input: Set of words W1,W2,. . ,Wn Output: Word Count WC
Step 1: Measure the count of set of words Nwords
Step 2: Find the unique set of words uw1, uw2,….,uwn Step 3: Measure the count of unique word uithen the set
of W1,W2,…Wn call it as WCi
Step 4: Now a map is created with key as u and value as C. Each C contains (tokenname, article name, frequency)
TABLE 5
Frequency Computation Details Parameter
Names
Parameter Description
FREID Unique Id for the frequency word
TOKEN NAME Word present in the article description
ARTICLE NAME Name of the article for which tokenization is performed
PAGE NO This is the page number in which the word is present
FREQ Number of times word is repeated in a given page
3.1.5 TF-IDF Computation
6111 computation of frequency of terms for each words present
in the articles across the pages. IDF stands for Inverse Document Frequency which is the count of number of unique pages in which word is present to the frequency of word.
Term Frequency -Inverse Document Frequency (TF-IDF) is a statistic that reflect the important word of a document and how important it is?. It helps in information retrieval by considering the weighting factor in searches. It’s value increases proportionally to the number of times a word appears in the document.
The IDF is computed using the following equation.
IDFT = logNtimes/Npages (1)
where,
Ntimes= Number of times word is repeated
Npages= Number of pages in which word is present.
The TF-IDF is computed using the following equation
TFIDF = tfi∗ idf ti (2)
where,
tfi = Text frequency.
idfti =Inverse document frequency.
TABLE 6
TF-IDF Computation Details
3.1.6 Concept Formulation
Concept are the top words which have maximum feature vector and are computed for each of the pages uniquely. The steps which are involved in the concept formation are defined as below:
1. Find the List of Unique Articles from TF-IDF. 2. Compute the number of unique articles Nunique. 3. Start from the 1st article till the number of unique
articles.
Find the list of unique words for the kth article.
Find the number of unique words for kth article Nwords.
Start from the 1st word till the number of unique words.
Measure the count of number of unique words Nu.
Sort the feature vectors.
Find the first two feature vector values.
Save the words as concept for each of the pages separately for each article.
3.1.7 Modular Order Preserving Encryption
Modular Order Preserving Encryption (MOPE) [29] is searchable encryption scheme and is an extension of Order Preserving Encryption (OPE) [30] which increases security. It doesnot leak any information about the location of plaintext. MOPE adds a secret modular shift to the encryption. The cipher text can be computed by sampling values according to the hyper-geometric distribution [31]. If DECMOPE and ENCMOPE are the decryption and
encryption function of the OPE, then
ENCMOPE(x) = ENCOPE(x + m); (3)
DECMOPE(x) = DECOPE(x) - m mod D; (4)
Where,
m is the secret offset value D is the size of the plain text.
3.1.8 Search API Results
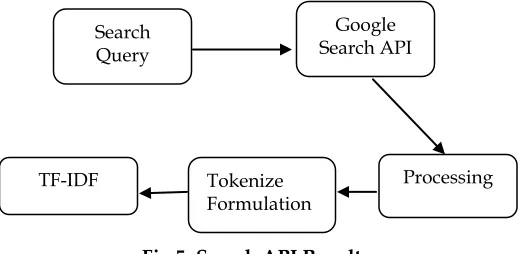
The real time data for the concepts under each pages of the articles are obtained from Google API. Once the data is obtained, the TF-IDF for each words in the search data stream is also computed for each of the words. Fig 5 shows the process involved in obtaining the search
API results.
Fig 5: Search API Results
The communication between the proposed system application and Google API is done with the help of API Parameter Names Parameter Description
FEATUREVECTORID Id for the feature vector.
TOKEN NAME Word present in the article.
ARTICLE NAME Name of the article for which tokenization is performed.
PAGE NO This is the page number in which the word
is present.
FREQ Number of times word is repeated in a
given page.
NOOFDOCS Number of pages in which word is present
in an article.
FEATUREVECTOR Feature Vector for the token.
Search Query
Google Search API
Tokenize Formulation
6112 key and Secret Key. Google Search API is called by making
use of API Key, Secret Key, Top Concept and search API returns word, URL, Hidden URL, Title, Description, Page No, Article. Search query is fed into Google Search API. The articles are obtained through Google API and is fed to the proposed model to obtain the TF-IDF of the articles.
3.1.9 Ranking Based on Relevance Score
The user enters the search query. The Articles are sorted and ranked based on highest value of relevance score. The relevance score is the summation of TF-IDF of the search words across pages of a specific article. The ranking of relevance score is shown below. Table 7 shows the relevance score of the article based on the unique keywords.
Relevance Score = tf * idft (5) where,
TFIDFij= TF-IDF for a word in an article. RSi = Relevance score for itharticle.
TABLE 7
Relevance Score Matrix
A W1 WS−1 WS RS
A1 TFIDF11 TFIDFs−1 TFIDFs RS1
A2 ... ... ... RS2
: : : : :
An TFIDFn1 TFIDFns−1 TFIDFns RSn
where,
TFIDFij= TF-IDF for a word in an article. MRSi= Relevance score for ith article
GSni= Google search based TF-IDF score for a word
in an article.
3.1.10 Ranking based on Modified Relevance Score The ranking based on Modified Relevance Score will be based on relevance score as well as the concept score computed from google API and hence providing most relevant document to the end user based on search query. The ranking of documents based on modified relevance score is as shown in Algorithm 4.
Algorithm 4 Modified Relevance Score based on Score
Input: Search Query Q
Output: List of articles A1,A2,. ,An
Step 1: Divide the searched query into a set of words W1, W2, .. , Ws.
Step 2: Find the set of unique articles which have to be ranked A1, A2, ... , An.
Step 3: for each article Ak the matrix of relevance
score is generated and stored in Table VIII.
Step 4: Sort the articles in descending order of the relevance score.
TABLE 8 Relevance Score Matrix
A W1 WS−1 WS RS
A1 TFIDF11+
GS1
TFIDFs−1+
GSs−1
TFIDFs + GS1
MRS1
A2 ... ... ... MRS2
: : : : :
An TFIDFn1+
GSn1
TFIDFns−1
GSns−1
+TFIDFns+
GSns
MRSn
where,
TFIDFij= TF-IDF for a word in an article. MRSi= Relevance score for itharticle
GSni= Google search based TF-IDF score for a
word in an article.
4. PERFORMANCE ANALYSIS
The performance metrics used while analysing the performance of the proposed method are:
Throughput: The throughput is defined as the amount of the data transferred to the total time taken for the complete execution.
Relevance Score: Relevance score is defined as a numerical value assigned to a document that indicates how relevant that document is for a given query.
Feature Vector: Feature vector is defined as the multiplication of frequency with inverse document frequency.
6113 suggestions taken from the Google API to the obtained
feature vector for the particle token. Then the search results are obtained to the end user. This helps the Modified TEES to get the higher relevance score. The higher the value of feature vector is the more relevant is the article to the particular user query.
Fig 6: Search results
Fig 6 shows the search results of CloudDataSecurity. CloudDataSecurity is on the top which has value of feature vector i.e 6003.87. When the user clicks on the titles, the PDF file is downloaded and when the user clicks on view related links then additional links are found out associated with the file. These additional suggestions are appended to the original pdf so that more accuracy and relevance score is obtained. The data is encrypted using Modular OPE that increases security compared with OPE of the existing TEES. MOPE uses a secret offset value that does not reveal any information regarding the location of the plain text.
Fig 7 shows the time taken for searching the article using the user query by both existing TEES [1] and proposed Modified TEES method. The time is less in Modified TEES because of multi-threading with spring prototype where in
after the file is divided into chunks, each chunk run independently so that the execution is done in parallel and finally the chunks are combined. The comparison of time taken to search the article in milli-seconds (ms) to the iteration number. Iteration number depends on number of times the algorithm executed.
6114
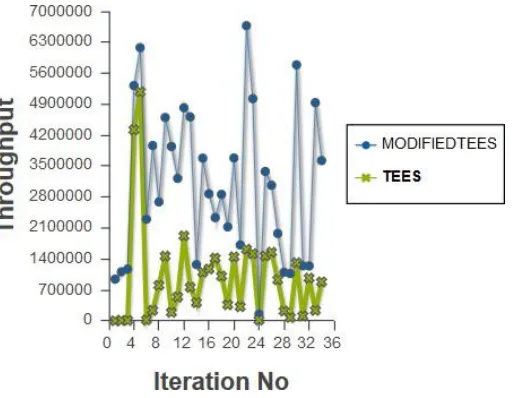
Fig 8: Throughput Comparison
Fig 8 shows the graph of throughput versus the iteration number for the TEES [1] and modified TEES algorithm. Modified TEES calculates the feature vector by considering the additional suggestions by the user along with giving the links of Google API related to the search query. This is responsible for the throughput increase in proposed method as compared to the existing system. Throughput variation depends on the network bandwidth as well as the performance of RAM and CPU cycles and number of processes running simultaneously.
5. CONCLUSIONS AND FUTURE WORK
In this paper, an introduction to cloud based search of articles is provided. The paper describes the various algorithms to remove the stop words, stemming, token generation, calculating frequency of words, computation of modified TF-IDF, ranking the articles based on relevance score that is obtained by Modified TF-IDF. This contain the TF-IDF values along with score of search results obtained for top keywords of Google for each article.
The proposed method makes use of modified OPE algorithm that helps in searching the unique query on encrypted data in providing the double security to the stored data. This combines the operations of OPE, hashing and wrapping steps of existing TEES algorithm. The proposed method is compared with TEES with respect to time comparison, feature vector computation and throughput comparison. From this, we can conclude that Modified TEES results is more efficient compared to the existing TEES in securing the data, obtaining the search results by considering additional suggestions of the user. The future enhancement is to store the value of each search keywords.
R
EFERENCES[1] Jain Li, Ruhui Ma, and Haibing Guan, ‚TEES: An Efficient Search Scheme over Encrypted Data on Mobile Cloud‛, IEEE transaction on Cloud Computing, vol. 5, issue. 1, pp. 126-139, February 2017.
[2] Luis M. Vaquero, Luis Rodero-Merino, Juan Caceres, and Maik Lindner,‚A Break in the Clouds: Towards a Cloud Definition”, ACM SIGCOMMon Computer Communication Review, vol. 39, no. 1, pp. 50-55, January2009.
[3] Xiaojun Yu and Qiaoyan Wen, ‚Design of Security Solution to Mobile Cloud Storage‛, Springer Book Title Knowledge Discovery and Data Mining, vol. 135, pp. 255-263, 2012.
[4] D. Huang, ‚Mobile cloud computing‛, IEEE COMSOC Multimedia Communications Technical Committee (MMTC) E-Letter, 2011.
[5] Oleksiy Mazhelis, Gabriella Fazekas and Pasi Tyrvinen, ‚Impact of Storage Acquisition Intervals on the Cost-Efficiency of the Private vs. Public Storage‛, IEEE Fifth International Conference on Cloud Computing,pp. 646-653, June 2012.
[6] Jon Oberheide and Farnam Jahanian, ‚When Mobile is Harder than Fixed (and vice versa): Demystifying Security Challenges in Mobile Environments, Proceedings of the Eleventh ACM Workshop on Mobile Computing Systems and Applications, pp. 43-48 , 2010.
[7] Ian Witten, Alistair Moffat and Timothy Bell, ‚Managing Gigabytes: Compressing and Indexing Documents and Images‛, Morgan Kaufmannpublication, 1999.
[8] S. Kamara and K. Lauter, ‚Cryptographic cloud storage, International Conference on Financial Cryptography and Data Security booktitle on Financial Cryptography and Data Security, Springer, pp. 136149, 2010.
[9] M. Li, S. Yu, K. Ren, W. Lou, and Y. T. Hou, ‚Toward Privacy Assured and Searchable Cloud Data Storage Services, Network, IEEE, vol. 27, no.4, pp. 5662, 2013.
[10] Jon Oberheide, Kaushik Veeraraghavan, Evan Cooke, Jason Flinn, and Farnam Jahanian, ‚Virtualized In-cloud Security Services for MobileDevices‛, Proceedings of the First Workshop on Virtualization in MobileComputing, pp. 31-35, 2008.
[11] Dawn Xiaoding Song, D. Wagner and A. Perrig, ‚Practical Techniques for Searches on Encrypted Data‛, Proceeding in IEEE Symposium onSecurity and Privacy, pp. 44-55, 2000.
[12] Dan Boneh, Giovanni Di Crescenzo, Rafail Ostrovsky and Giuseppe Persiano, ‚Public Key Encryption with Keyword Search‛, InternationalConference on the Theory and Applications of Cryptographic Techniques,vol. 3027, pp. 506-522, EUROCRYPT 2004.
[13] Zhihua Xia, Xinhui Wang, Xingming Sun, Qian Wang, ‚A Secure and Dynamic Multi-Keyword Ranked Search Scheme over Encrypted Cloud Data”, IEEE Transactions on Parallel and Distributed Systems, vol. 27,no. 2, pp. 340-352, February 2016.
[14] R. Curtmola, J. Garay, S. Kamara, and R. Ostrovsky, ‚Searchable Symmetric Encryption: Improved Definitions and Efficient Constructions‛, 13th ACM Conference on Computer and Communications Security , vol.19, no. 5, pp. 895-934, January 2011.
[15] Qi Chai and Guang Gong, ‚Verifiable Symmetric Searchable Encryption for Semi-Honest-but-Curious Cloud Servers‛, IEEE International Conference on Communications (ICC), pp. 917-922, June 2012.
6115
442-455,ACNS 2005.
[17] Sergej Zerr, Daniel Olmedilla, Wolfgang Nejdl and Wolf Siberski, ‚Zerber+r: Top-k Retrieval from a Confidential Index‛, in Proceedings of 12th International Conference on Extending Database Technology, pp. 439-449, 2009.
[18] C. Wang, N. Cao, K. Ren, and W. Lou, ‚Enabling Secure and Efficient Ranked Keyword Search over Outsourced Cloud Data, IEEE Transactions on Parallel and Distributed Systems, vol. 23, no. 8, pp. 14671479, 2012.
[19] C. Wang, N. Cao, J. Li, K. Ren, and W. Lou, ‚Secure Ranked KeywordSearch over Encrypted Cloud Data, 30th IEEE International Conference on Distributed Computing Systems (ICDCS), pp. 253262. 2010.
[20] N. Cao, C.Wang, M. Li, K. Ren, andW. Lou, ‚Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data‛, IEEE Transactions on Parallel and Distributed Systems, vol. 25, no. 1, pp. 222233, 2014.
[21] B. Wang, S. Yu, W. Lou and Y. T. Hou, ‚Privacy-Preserving Multi-Keyword Fuzzy Search over Encrypted Data in the Cloud‛, IEEE Conferenceon Computer Communications (INFOCOM), pp. 2112-2120, 2014.
[22] N. Jayashri and T Chakravarthy, ‚Efficitive Modular Order Preserving Encryption on Cloud using MHGD‛, IOSR Journal of Computer Engineering,vol. 17, issue. 4, pp. 16-25, 2015.
[23] Justin Zobel and Alistair Moffat, ‚Inverted Files for Text Search Engines‛,ACM Journal on Computing Surveys (CSUR), vol. 38, issue. 2, July 2006.
[24] Rakesh Agrawal, Jerry Kiernan, Ramakrishnan Srikant, and Yirong Xu, ‚Order Preserving Encryption for Numeric Data‛, ACM InternationalConference on Management of Data (SIGMOD), pp. 563– 574, 2004.
[25] David M. Blei, Andrew Y. Ng, and Michael I. Jordan, ‚Latent DirichletAllocation‛, Journal of Machine Learning Research, vol. 3, pp. 993-1022,2003.
[26] Juan Ramos, ‚Using TF-IDF to Determine Word Relevance in DocumentQueries‛, Technical report,Department of Computer Science, RutgersUniversity, January 2003.
[27] Djoerd Hiemstra, ‚A Probabilistic Justification for using tfidf term Weighting in Information Retrieval‛, International Journal on Digital Libraries, vol. 3, issue. 2, pp. 131139, August 2000.
[28] Karen Sparck Jones, ‚Index Term Weighting‛, International Journal on Information Storage and Retrieval, vol. 9, issue. 6, pp. 619-633, 1973.
[29] Charalampos, Nathan Chenette, Adam o‘Neill, George Kollios, and Ran Canetti, ‚Modular Order-Preserving Encryption, Revisited‛, Proceedings of the ACM SIGMOD International Conference on Management of Data,pp. 763-777, Jume 2015.
[30] Alexandra Boldyreva, Nathan Chenette, Yaunho Lee, and Adam O‘Neill, ‚Order Preserving Symmetric Encryption‛, Advances in Cryptology -EUROCRYPT, pp. 224-241, 2009.