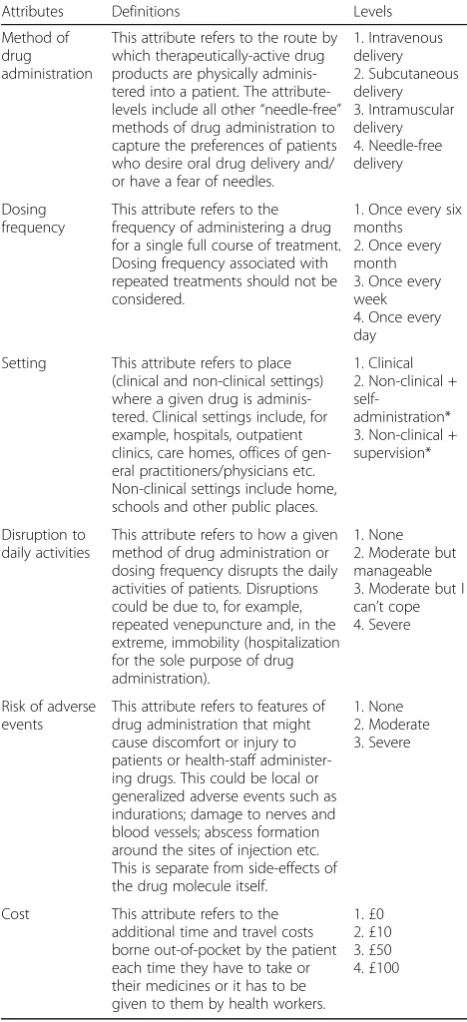
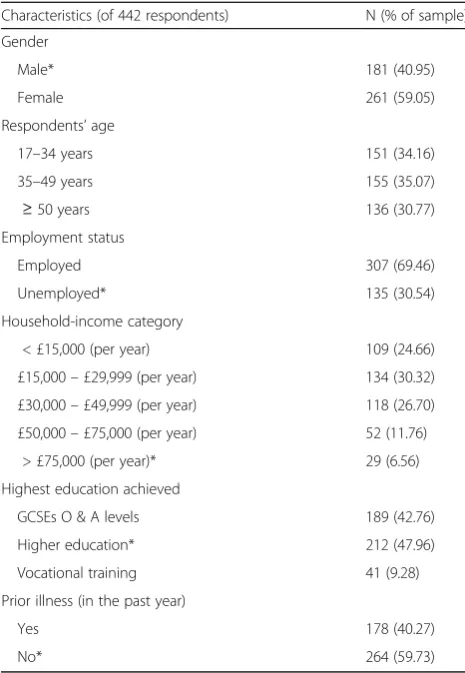
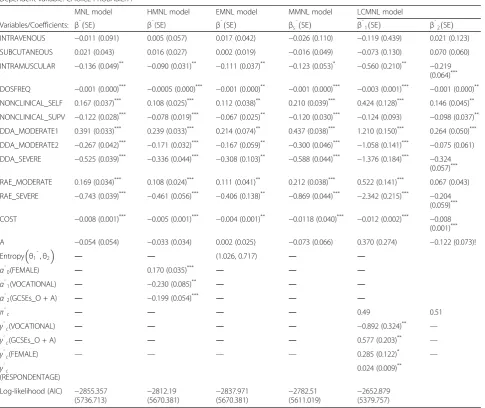
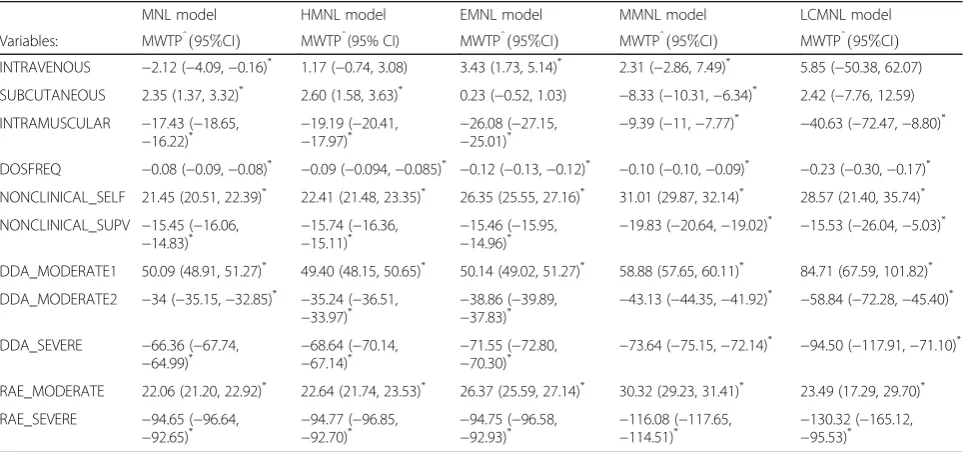
Discrete-choice modelling of patient preferences for modes of drug administration
14
0
0
Full text
Figure


+3
Related documents
