DETECTION AND REMOVAL OF
REDUNDANT WEB CONTENT
THROUGH RECTANGULAR AND
SIGNED APPROACH
G.POONKUZHALI
Department of Computer Science and Engineering, Rajalakshmi Engineering College, Anna University-Chennai,
Tamil Nadu, 602 105, India [email protected]
G.V.UMA
Department of Computer Science and Engineering, Anna University-Chennai,
Tamil Nadu, 600 025, India [email protected]
K.SARUKESI
Hindustan Institute of Technology and Science-Chennai, Tamil Nadu, 603 103, India
Abstract:
Today, Internet marks the era of information revolution and people rely on search engines for getting relevant information without replicas. As the duplicated web pages increase the indexing space and time complexity, finding and removing these pages becomes significant for search engines and other likely system. Web content outliers mining play a vital role in covering all these aspects. Existing algorithm for web content outliers mining focus attention on applying weightage to structured documents whereas in this research work, a mathematical approach based on signed and rectangular representation is developed to detect and remove the redundancy between unstructured web documents also. This method optimizes the indexing of web document as well as improves the quality of search engines.
Keywords: Matrix representation; Redundancy; Signed Approach; Similarity Computation; Web content.
1. Introduction
As the volume of information available on the web is growing dramatically, more number of duplicates of web content also grows simultaneously. Therefore, updating incoming data and retrieving relevant information without redundant data from the web quickly and efficiently becomes a growing concern among web mining research communities. Most of the web search engines typically employ conventional information retrieval and data mining techniques to discover automatically useful and previously unknown information from web content Web content mining is the process of mining, extraction and integration of useful data, information and knowledge from Web page contents.Two groups of web content mining are those that directly mine the content of documents and those that improve on the content search of other tools like search engine.
more valuable information than normal data. The usage of signed and rectangular approach makes the indexing and implementation process easier.
This paper focuses on detection and removal of noise issue, which implies outliers mining. Web pages that have different contents from the category in which they were taken constitute web content outliers. Web content outliers mining concentrates on finding outliers such as noise, irrelevant and redundant pages from the web documents.
In the proposed system, web documents are extracted; preprocessed and n x m matrix is generated for each extracted document. Each page is mined individually to detect redundant content by similarity computation of a word taken from all the 4- tuples of n x m matrix. Followed by that, redundancy between two documents is found based on signed approach. If the two documents found redundant, then one of the document is eliminated. Finally, a modified web document is obtained which contains required information catering to the user needs without redundant data.
This paper is organized as follows. Section 2 presents related works. Section 3 proposes system design. Section 4 describes generation of n x m matrix representation, Section 5 explains redundancy computation algorithm. Section 6 presents observations. Finally, Section 7 concludes with future work.
2. Related Works
3. Design of Proposed System
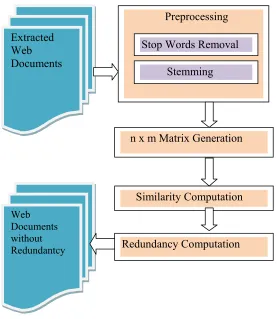
Figure 1. System Design of the proposed work
In this framework, web documents are extracted from the search engines by giving query by the user to the web. Then the obtained web documents are preprocessed, i.e., stop words, stem words and except text other data such as hyperlinks, sound, images etc are removed. Then the number of documents extracted on the web is counted. Next, n x m matrix representation are generated for all the extracted documents based on four tuples namely, number of pages, paragraphs, lines and word occurrences. Then all the elements of 4 tuples taken from n x m matrix of first two documents are compared and it s outcome is stored using signed approach. Finally, Redundancy computation is done based on the results of similarity computation.
Extracted
Web
Documents
Preprocessing
Stop Words Removal
Stemming
n x m Matrix Generation
Redundancy Computation
Similarity Computation
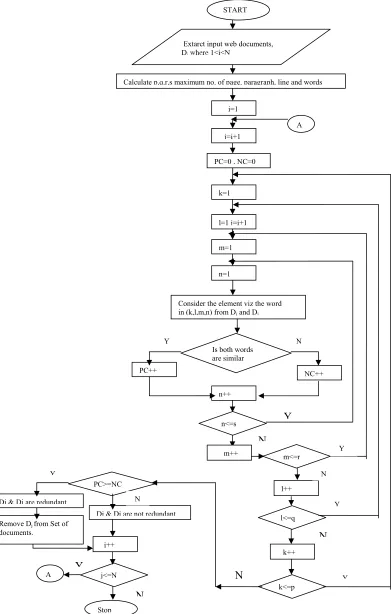
WebFigure 2. Flow of the proposed System PC++
START
Extarct input web documents, Diwhere 1<i<N
i=1
Calculate p,q,r,s maximum no. of page, paragraph, line and words
j=i+1
PC=0 , NC=0
k=1
l=1 j=i+1
m=1
n=1
Consider the element viz the word in (k,l,m,n) from Diand Dj
Is both words are similar
n++
NC++
n<=s
Y
A
Y N
m++
k<=p m<=r
l<=q l++
k++
A
Y Y
PC>=NC
Di & Dj are redundant
Di & Dj are not redundant Remove Dj from Set of
documents.
j++
j<=N
Stop
N
Y Y
N
N
N
N
Y
4. Generation of N x M Matrix
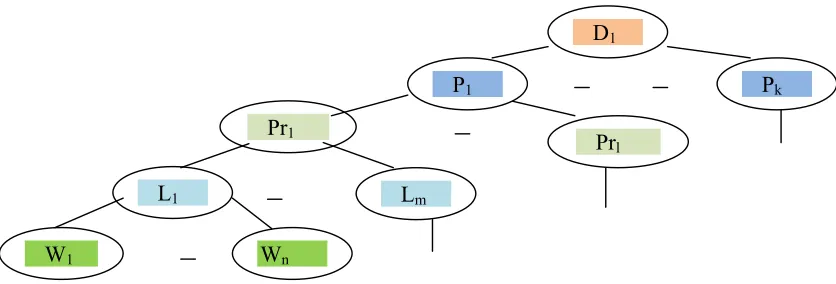
Figure 3. Tree Representation for n-tuple formation
In this phase, n x m matrix is generated for all the extracted web documents based on four tuples, namely: page, paragraph, line and word. For example to construct, n x m matrix for document D1 , first number of pages
in that document is calculated, then number of paragraphs in each page is counted, followed by that total number of lines in each paragraph is computed, finally, total number of words in each line is counted. The maximum number of pages in the document forms the row of the matrix and maximum number of words in any lines will form the column of the matrix for this document.
4.1. Nomenclature:
Di refers ith document , such that 1≤i≤N
Pk refers kth page where 1≤k≤p
Prl refers lth paragraph where 1≤l≤q
Lm refers mth line where 1≤m≤r
Wn refers nth word where 1≤n≤s
PC Positive Count NC Negative Count
Note: Here every element of Di is taken as a 4 tuple. For example a 4 tuple(3,2,5,8) refers 8th word from 5rd
line in 2nd paragraph of 3rd page.
Usage of n x m matrix representation helps easy retrieval and searching of web content. Organizing of new web content is also easy with this matrix representation even though for indexing it utilizes more storage. The redundancy computation is done quickly and accurately by comparing positive count with negative count for all the retrieved documents. This method can also be applied for performing relevancy checking of web documents in future.
5. Redundancy Computation(RC) Algorithm
Input: User Query q;
Method: Rectangular representation and Signed Approach Output: Web Document without Redundancy.
Step 1: Extract input web documents Di based on user query where 1≤ i ≤ N.
D
1W
1L
mL
1Pr
lPr
1P
1P
kStep2 : Preprocess all the extracted documents.
Step 3: Calculate maximum number of pages p, paragraph q , lines r and words s in any of the extracted Web documents.
Step 4: Generate n x m matrix for all extracted web documents with 4 tuples k, l, m and n where 1≤k ≤ p, 1≤l ≤q ,1≤m ≤ r and 1≤n ≤s respectively
Step 5: Initialize i=1. Step 7: Assign j=i+1.
Step 8: Initialize PC=0 and NC=0; (PC=Positive count, NC=Negative count).
Step 9: Consider first element in 4-tuple (k,l,m,n) from Di and Dj and perform string comparison.
Step 10: If they are similar, update PC=PC+1 else NC=NC+1
Step 11: Repeat step7 and step 8 for all the elements of 4-tuples till (p,q,r,s) taken from Di and Dj.
Step 12: If PC ≥ NC then
Di and Dj are redundant.
Remove Dj from the set of documents.
Else
Di and Dj are not redundant.
Step 13: Increment j and repeat the steps from 8 to 12 until j≤ N.
Step 14: At the termination of 13th step redundancy with first document is eliminated.
Step 15: Increment i and repeat the steps 7 to 13 until i<N.
Step 16: Finally Mined web content without redundancy is obtained.
6. Observations
As a test data, two web documents namely D1 and D2 are taken and n x m matrix is constructed. All the
elements of 4- tuples from the above documents are indexed and similarity computation is performed using string comparison. If they are similar, then positive count is incremented else negative count is incremented. Finally, redundancy computation of these two documents is performed. If the positive count is greater or equal to negative count then these two documents are redundant, otherwise not redundant. Here, out of 3200 words compared, positive count for these document results 2800 and Negative count is 400. Experimental results imply they are redundant document as the positive count is greater than negative count. The accuracy of search results gets improved, after eliminating the redundant links from the retrieved documents drastically. Also removal of redundant links makes the zipping of large data easier. As the efficiency of web content is increased, the quality of the search engines also gets increased. Precision and recall of the refined document increases considerably.
6.1. Precision
It is the ratio between the number of relevant documents returned originally and the total number of retrieved documents returned after eliminating redundant documents. Here the non redundant documents indicate the required documents which satisfy the user needs.
6.2.Recall
7. Conclusion and Future Work
Web mining is a growing research area in the mining community because of the great patronage the web continues to enjoy. The explosive growth of information sources available on the World Wide Web has necessitated the users to make use of automated tools to retrieve relevant information without duplicates
.
This paper proposes a new algorithm through rectangular representation and signed approach for improving the results of search engines by detecting and eliminating redundant web document. The beauty of this algorithm is simplicity. However, future work aims to consider random entries instead of comparing all the words for checking redundancy. Also, aims to perform experimental evaluation of web content mining in terms of reliability and to explore other mathematical tools for mining the web content.Acknowledgment
The authors would like to thank Prof. Ponnammal Natarajan worked as Director – Research, Anna University- Chennai. Currently Advisor, (Research and Development), Rajalakshmi Engineering College, for her intuitive ideas and fruitful discussions with respect to the paper’s contribution.
References
[1] G.Poonkuzhali; K.Thiagarajan; K.Sarukesi2009): Elimination of redundant links in web pages –Mathematical Approach,World Academy of Science, Engineering and Technology,V52,pp.
[2] Giuseppe Antoio Di Lucca; Massimiliano; Anna Rita Fasolina(2002): An Approach to identify Duplicated web pages, in proceedings of the 28th Annual International Computer Software and Applications Conference, IEEE computer Society press.
[3] Min-yan Wang ; Dong-Sheng Liu(2009): The Research of web page De-duplication based on web pages Re-shipment Statement, First Interrnational Workshop on Database Technology and Applications, pp.271-274
[4] Shiguang Ju; Zheng Wang; Xia Lv(2008): Improvement of page ranking algorithm based on timestamp and link, International Symposium on Information Processing, pp. 36-40.
[5] Yunhe Weng; Lei Li; Yixin Zhong(2008): Semantic keywords-based duplicated web pages removing, IEEE. [6] Zhongming Han; Qian Mo; Liu; Jianzhi(2009): Effectively and Efficiently Detect Web Page Duplication, IEEE.
G.Poonkuzhali received B.E degree in Computer Science and Engineering from University of Madras, Chennai, India, in 1998, and the M.E degree in Computer Science and Engineering from Sathyabama University, Chennai, India, in 2005. Currently she is working as an Assistant Professor in the Department of Computer Science and Engineering in Rajalakshmi Engineering College- Chennai and pursuing Ph.D programme in the Department of Information and Communication Engineering at Anna University – Chennai, India. She has presented and published 6 research papers in international conferences & journals and authored 5 books. She is a life member of ISTE (Indian Society for Technical Education) ,IAENG (International Association of Engineers) and CSI (Computer Society of India).
Dr. G.V.Uma, received her M.E. from Bharathidasan University, India in year 1994 and Ph.D. from Anna University, Chennai, India in 2002. She has rich experience in teaching and research; Currently working as a Professor and Head in the Department of Information Science and Technology in Anna University Chennai. Her research interests include Software Engineering, Genetic Privacy, Ontology, Knowledge Engineering & Management, and Natural Language Processing. She has organized many Workshops, Seminars and Conferences in national and International level