DECISION TREE ALGORITHM AND
MAPREDUCE TECHNOLOGY: A
REVIEW
BISMA BASHIR
Department Of CSE, SEST, Jamia Hamdard, New Delhi, 110062, South Delhi, India [email protected]
Farheen Siddiqui
Department Of CSE, SEST, Jamia Hamdard, New Delhi, 110062, South Delhi, India [email protected]
Abstract: In today’s era bigdata and data mining plays a very vital role. Big Data can be structured as well as unstructured. This enormous data growth has triggered development of new techniques and tools to process this data. Different algorithms are employed to classify bigdata, but the category of algorithms that are decision tree based are considered the best classifiers among all the other algorithms. Decision tree algorithms are simple and fast to implement. This paper discusses decision tree based algorithms that are based on map reduce framework. As the data grows decision tree algorithms have some limitations which need to be solved. MapReduce technology is the best solution for the bigdata processing with the decision tree algorithm.
Keywords: Big data, Decision tree algorithm, classification techniques, ID3, C4.5, MapReduce. 1. INTRODUCTION
In today’s era data is growing very fast. Data can be structured as well as unstructured. Due to the explosive growth of data, an urgent need of new techniques and tools have arrived, which can handle and process this huge amount of data into useful information. Data investigation techniques such as classification and prediction techniques can be used to extract important data out of big data. The majority of the classification techniques are memory bound, thus work properly on small datasets [1].
For classification of huge data various techniques are used such as decision tree, k-nearest neighbor, Bayesian and neural-net based classifiers. The best technique among these techniques is the decision tree classification. Decision tree algorithm has high efficiency and accuracy as compared to other classification methods [2]. Decision tree algorithms are cheap to implement. In a decision tree, there is a root node which has no incoming edges and has many internal nodes and child nodes. Each path from the root node to the child node forms a decision rule. Applying decision tree algorithm on extremely big amount of data can cause delay in tree construction [3]. With the continuously increasing data, it becomes time consuming to build a decision tree. MapReduce technique is used to solve the problem of the increasing bigdata in decision tree construction [4]. MapReduce is a programming model, which is composed of a map procedure that performs filtering and sorting and a reduce procedure that performs a summary operation [4]. For processing and analysis of large-scale data, MapReduce is the most popular framework. Big data sets are split into smaller sets by MapReduce model and each set is processed separately on various computers, then results of each sub processes is aggregated and the final results are generated. MapReduce architecture allows to process large-scale data much faster than the traditional data [5].
The paper is organized as follows; section 2 describes the literature survey of the paper. Section 3 describes the MapReduce procedure. Section 4 describes the decision tree algorithms. Section 5 gives the comparison of the ID3 and C4.5 decision tree algorithms and also presents the disadvantages of the two algorithms. Section 6 describes decision tree based on MapReduce and section 7 concludes this paper.
2. LITERATURE REVIEW
better tha available paper pro used Had ensure th proved ex the algor idea abou algorithm presented MapRedu having m framewo the incre very time in the m their pap optimizat the feasib and short paper pre recognize this. They MapRedu programm (key/valu output ar completio to proces mappers Fundame
Map
the o
Shuf
of pa key parti
Redu
Redu Fundame
an ID3 algori e datasets. Dat oposes C4.5 a doop clusters he accuracy o xperimentally rithm depends ut various dec ms and also pr
d a decision t uce. PDTSSE memory limita
rk. D. Wei et asing bigdata e consuming a
emory. The p per presented a
tion method u bility of the a ter running tim esented an ana
e and track th y concluded th
uce is a progr ming model ue pairs). In t re combined on of map tas ss data over and reducers ental phases o p phase: the in
output of Map ffle and Sort p artitions is equ that belong to itioning the M uce phase: the ucers process ental phases o
ithm in terms tasets with ma algorithm usin . The goal of of the classific y in this paper
s on entropy, cision tree algo
resented the r tree algorithm E algorithm is tions and run al 2014 [9] in , the tradition and also the in proposed algo
a study on th used MapRedu algorithm and me compared alysis of the d he results from
hat decision tr
amming mode namely map the reduce ph
into smaller d sk, the reduce
multiple node [12]. f MapReduce nput data is di pReduce is inte phase: output
ual to the num o the same div MapReduce.
e output from different in-b f MapReduce
s of classifica any instances w
ng MapReduc f the research
cation. The ef . B. R. Patel a information g orithms, decis recent issues i m called as PD s supposed to time delays. P n their paper p nal decision tr nput output co orithm improv e parallel imp uce framewor also shown t to the traditio decision tree a
m the existing ree algorithm
3. M el for distribu
task and red ase, the outpu data sets. Fro
task starts [12 es. Data proc
programming ivided into M ermediate key from the map mber of reduce
vision. Each d
m the second p etween keys a are depicted b
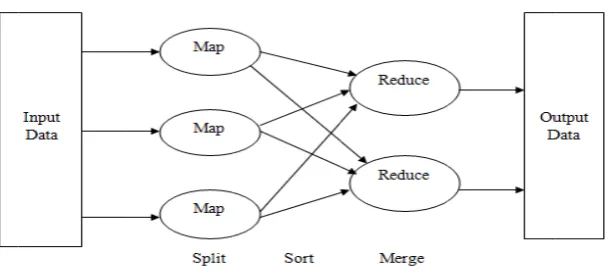
Figure 1: Fund
ation accuracy works better w ce computing h is to acceler fficiency and at al 2014 [1] gain and on th sion tree learn
in decision tre DTSSE: A Sc
o improve the PDTSSE is fo proposed a Ma ee algorithm ost of the oper ves both effici plementation o
rk. This paper that GA optim onal decision t lgorithms and g information is a vital tech MAPREDUC uted computing
duce task. In ut from the m om the name,
2]. The major cessing primit g model as sho M Map functio
y and value pa ppers is partiti ers. In the shu division is stor
phase are port and also run in below [14] :
damental phases
y. They have with C4.5 algo g model in a
rate the const scalability of in their paper he nature of d
ing software’s ee algorithm.
alable Paralle e drawbacks or large scale d apReduce imp
is not suitable rations becom iency and sca of decision tr r has proposed mization resul
tree algorithm d there use in v n, the decision hnique that can CE
g. Two main t Map task th map phase is t MapReduce, r advantage of tives under th own in Figure ns called as M airs.
ioned by hash uffle phase, al red by a key t
tioned into R n parallel.
of MapReduce
e performed t orithm. W.Da distributed en truction of de f the propose r have shown t
datasets. This s, area of appl
Y. Cui et al el Decision tre
of previous a decision tree l plementation o e. As data gro me very high a alability. F. Y ee based on g d MR-GAOT ted in higher m. S.B. Evang various fields n tree algorith n be used in ap
tasks are inclu he data sets a taken as inpu , it is clear th f MapReduce he MapReduc e 1 are [13]: Mapper. Mapp
hing the outpu ll key and valu
to merge all v
Reduce funct
the experimen ai et al 2014 [3 nvironment. T ecision tree an ed algorithm h that the perfor paper presen lication of dec 2014 [2] in th ee Algorithm algorithms wh learning in M of C4.5 algorit ows tree const as the bigdata Yuan et al 201
genetic algorit algorithm ha
classification eline 2016 [1 . To categoriz hm plays a vit pplications.
uded in the M are broken in ut in this phas
hat after the s is that it beco ce model are
pers run in pa
ut key. Here th ue pairs share values of that
tion called as
nts on the 3] in there They have nd should have been rmance of nts a basic cision tree heir paper based on hich were apReduce thm. With truction is cannot fit 15 [10] in thm (GA) ave shown n accuracy 1] in their ze, decide, tal role in
apReduce nto tuples se and the successful omes easy called as
arallel and
he number e the same key, after
Figure 2 [15].
Decision decision ID3 algo employed for classi used. Att algorithm C4.5 alg algorithm classifica values ar gain calc handling Figure 1
shows data fl
n tree algorithm tree algorithm orithm: ID3
d on the datas ification [6]. F tribute set wi m is used for m gorithm: C4.5 m is referred ation. Informa re accepted by culation [1]. A training data shows the flo
Fig
ow of MapRe 4. m is a supervi ms but here we decision tree sets in order t For determinin
ith the highes machine learni 5 algorithm w
as a statistic ation gain is u y C4.5 algorith Advantages of with missing wchart of dec
gure 2: Data flow
educe program DECISION ised learning a e consider onl e algorithm w
to test each at ng the suitable st information ing.
was develope cal classifier, used as splitti hm. Missing v f C4.5 algorith attribute valu cision tree algo
w of MapReduce p
mming model w N TREE ALG
algorithm use y ID3 and C4 was developed
tribute at each e property of n gain are sel ed by Ross Q , as the tree ing criteria by values are han hm are handlin ues [11].
orithm [17].
programming mo
which shows GORITHMS
ed in classifica 4.5 algorithm w
d by Ross Qu h node and th each node in t lected as test Quinlan as an generated by y C4.5 algorit ndled by C4.5 ng both the co
odel
that the data f
ation problem which are disc uinlan. Top d hen select the
the decision tr t attribute of n extension o y C4.5 algor thm. Both cat algorithm as ontinuous and
flow includes
ms [16]. There cussed below. down greedy
most valuable ree, informati
current node f ID3 algorit rithm can be
egorical and n they are not u d discrete attri
six steps
are many
Flowchar attribute then the attributes proceeds has no ch
The comp
Algor
ID
C4
rt in figure 3 for the tree c values are co s are the cate
. Attribute ha hild node.
parison of ID3
rithm S
C
D3 In
4.5 G
describes the construction a
ompared with egorical then aving the high
5. COMP 3 and C4.5 alg
Splitting Criteria
formation Gain. Gain ratio.
Figure 3: Flowc
complete step and also check h the given in attributes wit est informatio PARISON O gorithm is giv Table1: C
Attr
Handles o v Handles bo
nume
chart of Decision
p by step pro k the attribute ndex. Step by th the highes on gain is the F ID3 AND C ven below in th Comparison of ID
ibute Type
only Categoric values. oth categorical erical values.
n Tree Algorithm
cess of a deci e list. If the a y step all valu st index are c
root node. At C4.5 ALGOR he table1 [18] 3 and C4.5
Missi
cal Do n
missi l and Hand
v
ision tree. A d attribute list c
ues in the lis calculated and ttribute having RITHM
]:
ing Values
not handle ing values. dles missing
values.
decision tree contains nume
st are examin d the tree con g zero informa
Pruning Str
No Prunin done. Error bas pruning is u
checks an eric value, ned. If the nstruction ation gain
rategy
5.1.Disadvantages of ID3 algorithm.
Disadvantages of ID3 algorithm are given below [18]: When a small sample is tested, data may get over-fixed. For making a decision, one attribute is tested at a time.
Missing values and numeric attributes are not handled by algorithm. 5.2.Disadvantages of C4.5 algorithm.
Disadvantages of C4.5 algorithm are given below [18]: Only one variable can be split at a time.
Unbalanced trees may be formed.
6. DECISION TREE BASED ON MAPREDUCE
With the growing bigdata it becomes difficult to construct a decision tree, as tree construction takes a lot of time. With the increase in the bigdata the memory requirements are very high. Thus, MapReduce is the best solution for the bigdata challenges in the decision tree. MapReduce implementation improves the time efficiency and the scalability of the decision tree algorithm [19].
With the implementation of MapReduce in decision tree algorithm, the performance gain with the increased number of nodes and processors have been observed. The performance of the decision tree depends on various factors because of its irregular nature. In a MapReduce environment, various factors can affect the MapReduce results of a decision tree. For example, hardware layout can affect the performance of a decision tree. MapReduce implementation depends on various fields, in various cases MapReduce implementation benefits loot but on the other hand its implementation also results in various drawbacks [20].
7. CONCLUSION
Decision tree algorithm being the finest classifier is used in a variety of classification techniques. We have analyzed ID3 and C4.5 algorithm and our analysis have proved that accuracy of C4.5 algorithm is greater than ID3 algorithm. As C4.5 algorithm can handle both numerical data as well as categorical data but ID3 algorithm cannot handle numerical data. As a result of this C4.5 algorithm has greater accuracy than ID3 algorithm. As the data grows, it becomes difficult to construct a decision tree. The best way to construct a decision tree on bigdata is with the help of MapReduce technology. MapReduce is used for parallel computation of large datasets. With the help of MapReduce decision tree construction becomes easy and tree construction is accurate. MapReduce also helps to form a balanced tree with no repeated sub nodes.
REFRENCES
[1] Patel, B., & Rana, K. (2014). A Survey on Decision Tree Algorithm For Classification. IJEDR, 2(1).
[2] Cui, Y., Yang, Y., & Liao, S. (2014). PDTSSE: A Scalable Parallel Decision Tree Algorithm Based on MapReduce.
[3] Dai, W., & Ji, W. (2014). A Scalable Parallel Decision Tree Algorithm Based on MapReduce. A Scalable Parallel Decision Tree Algorithm Based On Mapreduce, 1, 49-60.
[4] Tiwari, A., & Athavale, V. (2012). A Survey on Frequently Used Decision Tree Algorithm and There Performance Analysis. International Journal Of Engineering And Innovative Technology (IJEIT), 1(6).
[5] Lakshmi, T., Martin, A., Begum, R., & Venkatesan, V. (2013). An Analysis on Performance of Decision Tree Algorithms using Student’s Qualitative Data. I.J.Modern Education And Computer Science, 5, 18-27.
[6] Chauhan, H., & Chauhan, A. (2014). Evaluating Performance of Decision Tree Algorithms. International Journal Of Scientific And Research Publications, 4(4).
[7] Yuan, F., Lian, F., Xu, X., & Ji, Z. (2015). Decision Tree Algorithm Optimization Research Based on MapReduce.
[8] Evangeline, S., & Sudhasini, P. (2016). An Introduction to Decision Tree algorithm on Various Field of Applications. International Journal Of Digital Communication And Networks (IJDCN), 3(3).
[9] Python), A., Python), A., & Team, A. (2017). A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python). Analytics Vidhya. Retrieved from https://www.analyticsvidhya.com/blog/2016/04/complete-tutorial-tree-based-modeling-scratch-in-python/#one [10] (2017). Retrieved from https://www.quora.com/What-are-the-differences-between-ID3-C4-5-and-CART
[11] Decision Tree. (2017). Saedsayad.com. Retrieved from http://www.saedsayad.com/decision_tree.htm
[12] Karim, M., & Rahman, R. (2017). Decision Tree and Nave Bayes Algorithm for Classification and Generation of Actionable Knowledge for Direct Marketing.
[13] "Mapreduce". En.wikipedia.org. N.p., 2017. Web. 4 Mar. 2017.
[14] What MapReduce can't do. (2017). Analyticbridge.com. Retrieved from http://www.analyticbridge.com/profiles/blogs/what-mapreduce-can-t-do
[15] Hadoop MapReduce. (2017). www.tutorialspoint.com. Retrieved from https://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm [16] Bisma B. An Approach of MapReduce Programming Model For Cloud Computing. International Journal of Advanced Research in
Computer Science, 8 (2), March 2017, 43-45
[17] 2017. Retrieved from https://www.google.co.in/serch?q=fundamental+phases+of+mapreduce [18] Sushant, S, N. Ashishkumar . International Journal of Science and Research (IJSR) (2013),
[19] Wei, D. Wei, J. (2014). A MapReduce implementation of C4.5 Decision Tree Algorithm. International Journal of Database Theory and Application, Vol.7, No.1.