Procedia Computer Science 17 ( 2013 ) 1032 – 1038
1877-0509 © 2013 The Authors. Published by Elsevier B.V.
Selection and peer-review under responsibility of the organizers of the 2013 International Conference on Information Technology and Quantitative Management
doi: 10.1016/j.procs.2013.05.131
Keywords: multi-class classification, twin support vector machine, decision tree, the best separating principle 1. Introduction
Support vector machines (SVMs), being computationally powerful tools for supervised learning [1–3], have already outperformed most other systems in a wide variety of applications [4–6]. As a million stone of the SVM, twin support vector machine (TWSVM) [7] determines two nonparallel hyeperplanes such that each hyperplane is closer to one of two classes and as far as possible from the other one, which has been studied wildly in recently. The preliminary TWSVMs [7–9] design for binary class classification problem. The binary TWSVMs are excellent at dealing with some certain probability model data (such as “Cross Planes” data) with less training time. Thus, the methods of constructing the nonparallel hyperplanes have been studied extensively [10–16].
TWSVM is also extended to deal with class classification problem [17–19]. More precisely, in multi-TWSVM [17], multi-TWSVM is extended straightly from binary classification to multi-class classification, in which each primal problem covers all data points except the data points of thek-th class in the constraints for the k-th (k =1,2,· · ·,K) hyperplane. In [18], the authors extended TWSVM based on the idea of ‘one-versus-rest’ (‘1-v-r’) from binary classification to multi-class classification, in which there are two quadratic programming (QP) problems for each reconstructing binary classification. However, they both have not kept the advantage of TWSVM what have lower computational complexity than that of the standard SVM. In [19], Yang et. al. proposed
∗Corresponding author. Tel.:+086-0571-87313551; fax:+086-0571-87313551 ∗∗Corresponding author. Tel.:+086-010-62736265; fax:+086-010-62736265
Email addresses:[email protected](Yuan-Hai Shao ),[email protected](Nai-Yang Deng ) © 2013 The Authors. Published by Elsevier B.V.
Selection and peer-review under responsibility of the organizers of the 2013 International Conference on Information Technology and Quantitative Management
Information Technology and Quantitative Management , ITQM 2013
The best separating decision tree twin support vector machine for
multi-class classification
Yuan-Hai Shao
a,∗, Wei-Jie Chen
a, Wen-Biao Huang
a, Zhi-Min Yang
a, Nai-Yang
Deng
b,∗∗aZhijiang College, Zhejiang University of Technology, Hangzhou, 310024, P.R.China bCollege of Science China Agricultural University, Beijing, 100083, P.R.China
Abstract
In this paper, we propose a decision tree twin support vector machine (DTTSVM) for multi-class classification. To realize our DTTSVM, there are two main steps: (1), a binary tree is constructed based on the best separating principle, which maximizing the distance between the classes. (2), in our binary tree, the binary TWSVM decision model is built for each node to obtain our DTTSVM. By using the decision tree model, our DTTSVM effectively overcomes the possible ambiguous occurred in multi-TWSVM and MBSVM. The preliminary experimental results indicate that the proposed method produces simple decision trees that generalize well with respect to multi-TWSVM and MBSVM.
Open access under CC BY-NC-ND license.
multiple birth SVM (MBSVM) with much lower computational complexity than that in both [17] and [18] by solvingK smaller size of QP problems forK-class classification. However, all above methods may appear the ambiguous problems, even for simply classified dataset(See section 3). This is a drawback of the above multi-class TWSVMs.
In this paper, different from the above multi-class TWSVMs, we propose a decision tree twin support vector machine (DTTSVM) for multi-class classification. The DTTSVM constructs a binary tree to classify the K -class problem by solving (K−1)th binary TWSVM. The advantages of our DTTSVM are: (1) By introducing the decision tree, DTTSVM overcomes the possible ambiguous occurred in multi-TWSVM and MBSVM; (2) To build the binary tree, DTTSVM just need to compute the distances between the classes, this greatly shorten the training time, making our DTTSVM has a low computational complexity; (2) Based on the best separating principle, the depiction tree to be the balanced tree, which improves the generalization ability of our DTTSVM. The preliminary experimental results indicate that the proposed method produces simple decision trees that generalize well with respect to multi-TWSVM and MBSVM.
The paper is organized as follows: Section 2 introduces the brief reviews of SVMs. Section 3 proposes our decision tree twin support vector machine (DTTSVM). Section 4 deals with experimental results and Section 5 contains concluding remarks.
2. Brief reviews of TWSVMs 2.1. Twin support vector machine
Given the following training set for the binary classification:
T ={(x1,y1),· · ·,(xl,yl)}, (1)
where (xi,yi) is thei-th data point, the inputxi∈Rnis a pattern, the outputyi∈ {1,2}is a class label,i=1,· · · ,l,
andlis the number of data points. In addition, letl1 andl2 be the number of data points in positive class and
negative class respectively andl=l1+l2. Furthermore the matrixA1∈Rl1×nandA2∈Rl2×nconsist of thel1inputs
of Class 1 and thel2inputs of Class 2 respectively.
The gaol of TWSVM [7] is to find two nonparallel hyperplanes inn-dimensional input space
f1=wT1x+b1=0 and f2=wT2x+b2=0, (2)
such that one hyperplane is close to the patterns of one class and far away from the patterns of the other class to some extent. TWSVM is in spirit of GEPSVM[20]. But both of GEPSVM and TWSVM are different from the standard SVM. For TWSVM, each hyperplane is generated by solving a QP problem looking like the primal problem of the standard SVM. The primal problems of TWSVM can be presented as follows:
min w1,b1,ξ2 1 2A1w1+e1b1 2 2+C1eT2ξ2, s.t. −(A2w1+e2b1)+ξ2≥e2, (3) ξ2 ≥0, and min w2,b2,ξ1 1 2A2w2+e2b2 2 2+C2eT1ξ1, s.t. (A1w2+e1b2)+ξ1≥e1, (4) ξ1 ≥0,
whereC1 andC2 are nonnegative parameters, ande1 ande2 are vectors of ones of appropriate dimensions. In
the QP problem (3), the objective function tends to keep hyperplane (2) close to the patterns of Class 1 and the constraints require the hyperplane (2) to be at a distance of at least 1 from the patterns of Class 2. The QP problem (4) has the similar property.
Once the solutions (w1,b1) and (w2,b2) of the problems (3) and (4) are obtained, a new pointx∈Rnis assigned
to classi(i= +1,−1), depending on which of the two hyperplanes in (2) is closer to, i.e.,
f(x)=arg min k=1,2 |wT kx+bk| wk2 , (5)
where| · |is the absolute value. As forK-class classification problem, multi-TWSVM [17] constructsK hyper-planes, each hyperplane close to one of the class, and at the same time, far from the other classes. A new points closer to which hyperplane and will be classify to which class.
2.2. Multiple birth support vector machine
Given the training set
T ={(x1,y1),· · ·,(xl,yl)}, (6)
where the inputxi ∈ Rn,i = 1,· · ·,l, is the pattern, the outputyi ∈ {1,· · ·,K}is the class label. The task of
multiple birth support vector machine (MBSVM) is to seekKhyperplanes
fk=wTkx+bk=0, k=1,· · ·,K, (7)
and assign the class label according to which hyperplanes a new pattern is farthest to.
For convenience, denote the number of data points of thek-th class in the training set (6) aslkand define the
following matrixes: the patterns belonging to thek-th class are represented by the matrixAk∈Rlk×n,k=1,· · ·,K.
In addition, define the matrix
Bk=[AT1,· · ·,ATk−1,ATk+1,· · ·,ATK]T, (8)
i.e.,Bk∈R(l−lk)×nconsists of the patterns belonging to all classes except thek-th class,k=1,· · · ,K. The primal
problems of MBSVM [19] are comprised of the followingKQP problem min wk,bk,ξk 1 2Bkwk+ek1bk 2 2+CkeTk2ξk, s.t. (Akwk+ek2bk)+ξk≥ek2, ξk≥0, (9)
whereek1 ∈ R(l−lk) andek2 ∈Rlk are the vector of ones,ξkis the slack variable,Ck >0 is the penalty parameter,
k=1,· · · ,K. The dual problem of QP problem (9) is formulated as follows
max αk eTk2αk− 1 2αkGk(H T kHk)−1GTkαk, s.t. 0≤αk≤Ck, (10)
where the penalty parameterCk >0, Hk =[Bkek1],Gk = [Akek2], andk= 1,2,· · ·,K. Similarly, in order to
avoid the possibility of the ill-conditioning of the matrixHT
kHkin some situations, one introduces a regularization
termI, where >0 is a fixed small scalar andIis the identity matrix with appropriate size. After getting the solution [wT
k bk]T=−(HTkHk+I)−1GTkαkto the above QP problem (9) withk=1,· · ·,K, a
new patternx∈Rnis assigned to classk(k∈ {1,· · ·,K}), depending on which of theKhyperplanes given by (7)
lies farthest to, i.e., the decision function is represented as
f(x)=arg max k=1,···,K |wT kx+bk| wk2 , (11) where| · |is the absolute value.
Confused area
(a) Multi-TWSVM
Decision Tree
Class Class Class
(b) Binary decision tree TWSVM
Fig. 1. Three class classification problem classified by the multi-TWSVM (a); and the binary decision tree TWSVM model(b).
3. Decision tree twin support vector machine
Firstly, we point out one problem of the multi-TWSVM by using an example. Fig. 1 gives an easily classified three-class classification problem. Fig. 1 (a) shows the results classified by multi-TWSVM, we can see that three proximal planes are built, the classification rule is that the new data point closer to which plane and will be classified to which class. In Fig. 1(a), there are one shaded area, this area is ambiguous according to the above classification rule, that is to say, multi-TWSVM may be confused on this area. This is a drawback of the multi-TWSVM. The other multi-class TWSVMs [18, 19] have the similar problem.
To overcome the above drawbacks, we propose our decision tree twin support vector machine (DTTSVM) for multi-class problem. Suppose we haveK >2 classes. Consider the binary tree strategy for constructing our DTTSVM. To realize our DTTSVM, one of the most important thing is to build a proper binary tree [21]. Note that in decision tree, the upper nodes, the greater impact of the performance of the entire classification model. Therefore, in the process of generating a binary tree, one should allow the most separate group of classes from the other classes on each node, i.e., to split the root node, it should has lowest error estimates on two group of classes.
In order to establish our binary tree, we introduce the “best separating principle”, which can be defined as: (i) We call two group of classes with the “best separating principle” when these two group of classes with the maximum distance between all classes;
(ii) We call two group of classes with the “best separating principle” when these two group of classes with the lowest misclassification rate between all classes;
Following the principle of (i) and (ii), we can build our binary tree. Then, following the principle of the (i), we introduce an easy algorithm to build the binary tree by finding the maximum distance between the classes center. To investigate all groups of classes forK-class problem, we need to calculate 2K−1−1 times. That is to say, it has
the high computational complexity. Although this may seem prohibitive to compute for a large number of classes, we derive an exact, reasonably fast algorithm for this approach.
LetGi;Gjbe groups of classes, and letD(Gi;Gj) denote the distance between the groupsGiandGj. That is to
say we wish to find the groups with the maximum distanceM(Gi;Gj) to split
M(Gi;Gj)=arg max
i,j D(Gi;Gj). (12)
There are many ways to calculate the distance between the two group of classes, here we using the center to present the corresponding group of classes, then the distance between the two group of classes can be measured by the distance between the two center. In particular, letC(Gk) be the center of the classesGk,δ(Gk) be the variance
of the classesGk, andmkbe the proportion of the points in the classesGkof the all points. Also,C(Gi);C(Gj) be
the center of theGi;Gj. Then the maximum distance can be expressed as
M(Gi;Gj)=arg max i,j (mimj C(Gi) δ(Gi) − C(Gj) δ(Gj) 2). (13)
Then the training algorithm of our DTTSVM can be conclude as:
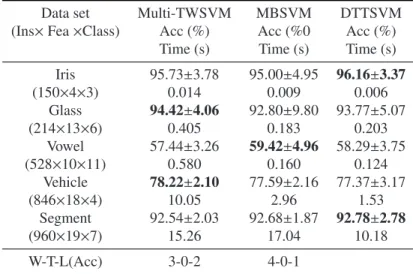
Table 1. Ten-fold testing percentage test set accuracy (%) on benchmark data sets.
Data set Multi-TWSVM MBSVM DTTSVM
(Ins×Fea×Class) Acc (%) Acc (%0 Acc (%) Time (s) Time (s) Time (s) Iris 95.73±3.78 95.00±4.95 96.16±3.37 (150×4×3) 0.014 0.009 0.006 Glass 94.42±4.06 92.80±9.80 93.77±5.07 (214×13×6) 0.405 0.183 0.203 Vowel 57.44±3.26 59.42±4.96 58.29±3.75 (528×10×11) 0.580 0.160 0.124 Vehicle 78.22±2.10 77.59±2.16 77.37±3.17 (846×18×4) 10.05 2.96 1.53 Segment 92.54±2.03 92.68±1.87 92.78±2.78 (960×19×7) 15.26 17.04 10.18 W-T-L(Acc) 3-0-2 4-0-1
step 1: Given the training data setT ={(x1,y1),(x2,y2), ...,(xl,yl)}. Construct the complete linkage binary tree
based on the “best separating principle” by using (13).
step 2: Starting with all classes at the top node of the tree, find the partition of the corresponding group of classes versus the rest by using the TWSVM [8], and also the partition that produces two group of classes in the complete linkage tree (that is, make a horizontal cut in the tree to produce two group of classes).
step 3: Repeat step 2, until all nodes has been trained by TWSVM.
step 4: Save the decision tree and return.
This algorithm is exact in that it finds the best separating principle at each node in the top-down tree building process. And in whole process, we just need to training (K−1)-th TWSVM, which make our DTTSVM has a low computational complexity.
Recall the example in Fig. 1 (a). Now we use the DTTSVM to classify this three-class classification problem. Fig. 1 (b-c) show the example of the classification results by using the DTTSVM model. From the Fig. 1 (b-c), we can see that by using the DTTSVM model, the “confused” problem happened in multi-TWSVM is overcome.
4. Numerical Experiments
In this section, we present experimental results of our DTTSVM on several UCI (http://www.ics.uci.edu/mlearn/ MLRepository.html) benchmark datasets. In experiments, we focus on the comparison between our DTTSVM and some state-of-the-art TWSVM classifiers, including multi-TWSVM and MBSVM. All the classification clas-sifiers are implemented in MATLAB 7.0 (www.mathworks.com) environment on a PC with Intel P4 processor (2.9 GHz) with 1 GB RAM. In order to give the fastest training speed, TWSVM and MBSVM are imple-mented using SOR technique. The “Accuracy” is used to evaluate methods, which is defined as: Accuracy =
(T P+T N)/(T P+FP+T N+FN), where TP, TN, FP and FN are the number of true positive, true negative, false positive and false negative, respectively. As for the problem of selecting parameters, we employ standard 10-fold cross-validation technique. Furthermore, the parameters for the all methods are selected from the set{2−8,· · ·,27}. Firstly, we show the “best separating principle” tree constructed in our DTTSVM for UCI datasets in Fig. 2. From the Fig. 2, we can see that the hight of our binary tree is not very large, that is to say, our binary tree is tend to the balanced tree. This will help to improve the classification accuracy.
In order to compare the behavior of our DTTSVM with multi-TWSVM and MBSVM, the numerical exper-imental results for multi-class UCI data sets are summarized in Table 1. In Table 1, the classification accuracy
2 1 3 (a) iris 3 5 1 2 4 6 (b) Glass 10 9 8 6 5 7 11 2 1 3 4 (c) Vowel 1 4 2 3 (d) Vehicle 2 1 7 6 5 3 4 (e) Segment Fig. 2. The “best separating principle” tree for UCI datasets.
and computation time are listed, and the best accuracy is shown by bold figures. It is easy to see that the most accuracies of our DTTSVM is better than multi-TWSVM and MBSVM on these datasets. It can also be seen that our DTTSVM is a litter faster than multi-TWSVM, and is competitive with MBSVM. A win-tie-loss (W-T-L) summarization based on Acc are also listed at the bottom of Table 1. It can be clearly seen that the proposed DTTSVM obtains the best classification performance than the others for the most cases according to the W-T-L summarization, specifically it enhances the performance of multi-TWSVM significantly.
5. Conclusions
In this paper, we have proposed a best separating principle based decision tree twin support vector machine (DTTSVM) for multi-class classification. Our DTTSVM constructs a binary tree to classify theK-class problem by using (K−1)-th TWSVM, which effectively overcome the possible ambiguous occurred in multi-TWSVM and MBSVM. Further, our DTTSVM has a low computational complexity. The preliminary results indicate that our DTTSVM produces the decision trees that generalize well with respect to multi-TWSVM and MBSVM. In the further, we concern with different way to estimate the “best separating principle” and extend it to multi-label problems.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No.11201426, No. 10971223 and No. 11071252), the Zhejiang Provincial Natural Science Foundation of China (No.LQ12A01020) and the Science and Technology Foundation of Department of Education of Zhejiang Province (No. Y201225256 and No.Y201225179).
References References
[1] V. N. Vapnik, The Nature of Statistical Learning Theory, Springer New York Inc., New York, NY, USA, 1995.
[2] N. Y. Deng, Y. J. Tian, C. H. Zhang, Support Vector Machines: Optimization Based Theory, Algorithms, and Extensions, CRC Press, 2012.
[3] Y. Tian, Y. Shi, X. Liu, Recent advances on support vector machines research, Technological and Economic Development of Economy 18 (1) (2012) 5–33.
[4] Y. Li, Y. Shao, N. Deng, Improved prediction of palmitoylation sitesusing pwms and svm, Protein and Peptide Letters 18 (2) (2011) 186–193.
[5] Y. C. Wang, Y. Wang, Z. X. Yang, N. Y. Deng, Support vector machine prediction of enzyme function with conjoint triad feature and hierarchical context, BMC systems biology 5 (Suppl 1) (2011) S6.
[6] Y. Li, Y. Shao, L. Jing, N. Deng, An efficient support vector machine approach for identifying protein s-nitrosylation sites, Protein and Peptide Letters 18 (6) (2011) 573–587.
[7] R. Jayadeva Khemchandani, S. Chandra, Twin support vector machines for pattern classification, IEEE Transactions on Pattern Analysis and Machine Intelligence 29 (2007) 905–910.
[8] Y. H. Shao, C. H. Zhang, X. B. Wang, N. Y. Deng, Improvements on twin support vector machines., IEEE Transactions on Neural Networks 22 (6) (2011) 962–968.
[9] Y. Shao, N. Deng, A novel margin-based twin support vector machine with unity norm hyperplanes, Neural Computing and Applications DOI 10.1007/s00521-012-0894-5 (2012) 1–9.
[10] Z. Qi, Y. Tian, S. Yong, Robust twin support vector machine for pattern classification, Pattern Recognition 46(1) (2012) 305–316. [11] Y. H. Shao, N. Y. Deng, Z. M. Yang, Least squares recursive projection twin support vector machine for classification, Pattern
Recogni-tion 45 (6) (2012) 2299–2307.
[12] Z. Qi, Y. Tian, S. Yong, Laplacian twin support vector machine for semi-supervised classification, Neural Networks 35 (2012) 46–53. [13] Y. Shao, N. Deng, Z. Yang, W. Chen, Z. Wang, Probabilistic outputs for twin support vector machines, Knowledge-Based Systems 33
(2012) 145–151.
[14] Z. Qi, Y. Tian, S. Yong, Twin support vector machine with universum data, Neural Networks 36C (2012) 112–119. doi:doi: 10.1016/j.neunet.2012.09.004.
[15] Y. Shao, N. Deng, W. Chen, Z. Wang, Improved generalized eigenvalue proximal support vector machine, IEEE Signal Processing Letters 20 (3) (2013) 213–216.
[16] Z. Qi, Y. Tian, Y. Shi, Structural twin support vector machine for classification, Knowledge-Based Systemsdoi:DOI: 10.1016/j.knosys.2013.01.008.
[17] Z. Wang, J. Chen, M. Qin, Non-parallel planes support vector machine for multi-class classification, in: Logistics Systems and Intelligent Management, 2010 International Conference on, Vol. 1, 2010, pp. 581–585.
[18] H. H. Cong, C. F. Yang, X. R. Pu, Efficient speaker recognition based on multi-class twin support vector machines and gmms, 2008, pp. 348–352.
[19] Z. X. Yang, Y. H. Shao, X. S. Zhang, Multiple birth support vector machine for multi-class classification, Neural Computing and Application DOI: 10.1007/s00521-012-1108-x (2012) 1–9.
[20] O. L. Mangasarian, E. W. Wild, Multisurface proximal support vector machine classification via generalized eigenvalues., IEEE Trans-actions on Pattern Analysis and Machine Intelligence 28 (1) (2006) 69–74.
[21] S. R. Safavian, D. Landgrebe, A survey of decision tree classifier methodology, IEEE Transactions on Systems, Man, andCybernetics 21 (3) (1991) 660–674.