2019 International Conference on Computer Science, Communications and Big Data (CSCBD 2019) ISBN: 978-1-60595-626-8
Prediction of
Larger-than-gestational Age
Based on Weak
Supervised Learning
Zhi-rui WANG
*and Hong-wei LI
School of Software Engineering, Beijing University of Technology, Beijing, China
*Corresponding author
Keywords: Disease prediction, Machine learning, Weak supervised learning.
Abstract. Larger-than-gestational age prone to a variety of complications, and easy to produce all kinds of maternal injuries. It is of great significance to establish a prediction model for larger-than-gestational age for early diagnosis and intervention. In this study, data records of newborn fetuses collected between 2010 and 2013 were used as samples which included some unlabeled and inaccurately labeled records. Weak supervised learning technology in machine learning was used to predict diseases of larger-than-gestational age. The recall rate of the final prediction model was 0.82, the accuracy rate was 0.965, and the area under the curve was 0.89. Experimental results show that the proposed method is effective. In addition, this study verified that indicators such as parental body mass index, smoking status, creatinine, and hemoglobin were associated with larger-than-gestational age.
Introduction
larger-than-gestational age (LGA) indicates infants with gestational weight greater than the 90th percentile of average gestational weight (about 2 standard deviations or more of average weight). LGA are prone to a variety of complications, and mothers are prone to all kinds of birth injuries. Therefore, it is of great significance to establish a prediction model for LGA for early diagnosis and intervention. Souka et al. predicted LGA by ultrasound[1]. At present, the prediction of LGA is still dependent on doctors' artificial experience. Machine learning has many applications in the medical field[2-4], which provides a new method for the establishment of the prediction model of LGA. It is helpful for doctors to diagnose LGA that predicting LGA based on the information of the prenatal examination by using machine learning method. In this study, data records of fetuses over the gestational age of 24-42 weeks born from 2010 to 2013 were selected as research objects, and machine learning was used to predict LGA. In particular, the data set contains unlabeled or labeled inaccurate samples. This paper adopts the weak supervised learning method.
Methods
Larger-than-gestational Age Data
In April 2010, the Population and Family Planning Commission (National Health and Family Planning Commission) and the Ministry of Finance in China, in order to prevent the occurrence of new fetal diseases and improve the quality of the newborn fetus, launched the “National Free Pre-pregnancy Health Check Project”. The data covers 60% of cities or districts in China. The inspection projects involve internal medicine, endocrinology, pediatrics, genetics, obstetrics, family planning, male studies, laboratory science, nutrition, epidemiology and pre-pregnancy counseling, etc.[5, 6] This article is based on data collected in this project. In this study, data records of fetuses over the gestational age of 24-42 weeks born from 2010 to 2013 were selected as research objects. Finally, the data set of this paper includes 247,672 samples and 371 features.
Data Quality Check
Fetal birth weight index, fetal gender and gestational weeks of delivery are conditions for marking whether it is greater than gestational age. We first selected the sample whose fetal birth weight index, fetal gender or gestational weeks of birth is missing as an unlabeled sample. Unlabeled samples make up an unlabeled sample set, including a total of 32,062 samples.
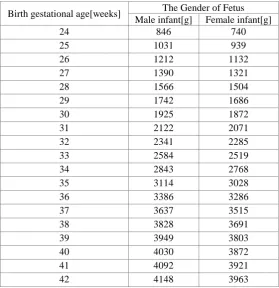
[image:2.595.158.438.409.698.2]Excluding unlabeled samples, we mark the remaining samples according to identification table of LGA. This form is calculated by referring to historical data and expert opinions based on definitions, as shown in Table 1. After the marking is completed, this part of the sample is considered as the marked data set.
Table 1. Identification table of LGA.
Birth gestational age[weeks] The Gender of Fetus Male infant[g] Female infant[g]
24 846 740
25 1031 939
26 1212 1132
27 1390 1321
28 1566 1504
29 1742 1686
30 1925 1872
31 2122 2071
32 2341 2285
33 2584 2519
34 2843 2768
35 3114 3028
36 3386 3286
37 3637 3515
38 3828 3691
39 3949 3803
40 4030 3872
41 4092 3921
42 4148 3963
normal, and are not sensitive to the specific values in the medical field. We set a number to represent the missing value, so that it can be distinguished from other values and become a separate class.
After boxing for each feature, we found many samples with the same features but different tag. If all of them are used for training, the learning of classifier will be disturbed. We extracted these samples, and only one sample with the same characteristics was retained. The average gestational age and birth weight of these data were taken. These samples are composed of inaccurately labeled sample sets. Excluding inaccurate samples, other samples make up the labeled accurate sample set.
Weak Supervised Learning
There are three types of weak supervision: incomplete supervision, only some samples have labels; Without exact supervision, training samples only have coarse-grained labels; And inaccurate monitoring, where a given label is not always true. In this paper, there are unmarked samples in the data set of LGA, and there are also samples with the same characteristics but different labels. Weak supervised learning can be used to train the prediction model of LGA to make full use of the data. Specifically, we use clustering hypothesis and graph tag transfer method respectively for unlabeled datasets and inaccurately labeled datasets.
Experiment
The problem of imbalance between positive and negative samples exists in marking accurate data sets. We undersampled negative samples, one-hot coded the whole data set, and used sparse logistic regression model for training. In particular, due to the need for iteration of the prediction model, in order to ensure the comparability of other sample data when they were added, we adopted the method of stratified sampling to undersample the accurate data set. It ensures that a certain number of samples are available for each birth gestational age. Cross validation and grid search are used to get the optimal model. The recall rate of the final prediction model was 0.827, the accuracy rate was 0.832, and the area under the curve was 0.83.
We mixed unlabeled samples with labeled accurate samples and then clustered them, and labeled the unlabeled samples according to the clustering results. Unlabeled samples are entered into the current prediction model to get the label. The results obtained by the two methods are compared, respectively. The samples with the same results are added into the samples with accurate markers as high confidence samples until all samples have been marked. In particular, before the next iteration, in order to ensure the balance of data, we re-sampled the marked-accurate samples according to the distribution of the high confidence samples in the previous step. After adding all unlabeled samples, the recall rate of the final prediction model was 0.794, the precision rate was 0.844, and the area under the curve was 0.844.
Although the label cannot be determined for the inaccurately labeled sample, it contains information about birth weight and gestational age compared to the unlabeled sample. Birth weight and gestational age information can be used to quantify the differences between accurately labeled samples and inaccurately labeled samples. Due to the comparability of samples with the same gestational age, we found the maximum and minimum fetal birth weight values in accurately labeled samples at each gestational age. For each record of the inaccurately labeled samples, the fetal birth weight was compared with the maximum and minimum values of the same gestational age of birth, and then was classified into the nearest category. The next step is the same as for the unlabeled sample. Inaccurately labeled samples are entered into the current prediction model to get the label. The results obtained by the two methods are compared, respectively. The samples with the same results are added into the samples with accurate markers as high confidence samples until all samples have been marked. After adding all inaccurately labeled samples, the recall rate of the final prediction model was 0.758, the precision rate was 0.879, and the area under the curve was 0.843.
Result
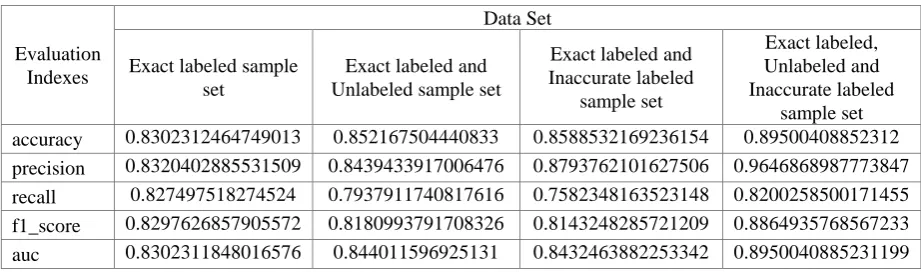
[image:4.595.67.528.157.293.2]The prediction model is first pre-trained with labeled samples and then iterated with other two sample sets using weak supervised learning. With the method of weak supervision, the effect of classifier is improved as shown in table 2.
Table 2. Comparison table of evaluation indexes of prediction model.
Evaluation Indexes
Data Set Exact labeled sample
set
Exact labeled and Unlabeled sample set
Exact labeled and Inaccurate labeled
sample set
Exact labeled, Unlabeled and Inaccurate labeled
sample set accuracy 0.8302312464749013 0.852167504440833 0.8588532169236154 0.89500408852312 precision 0.8320402885531509 0.8439433917006476 0.8793762101627506 0.9646868987773847 recall 0.827497518274524 0.7937911740817616 0.7582348163523148 0.8200258500171455 f1_score 0.8297626857905572 0.8180993791708326 0.8143248285721209 0.8864935768567233 auc 0.8302311848016576 0.844011596925131 0.8432463882253342 0.8950040885231199 Table 2 shows that, compared with the training model with only marked accurate samples, all indexes are improved by using the weak supervised learning method, which proves that the method of this experiment is effective. The accuracy of the final prediction model was 0.895, the precision rate was 0.965, the recall rate was 0.82, the f1_score was 0.886, and the area under the curve was 0.895. It means that the prediction accuracy of the model is 89.5%, and 96.5% of LGA can be identified. The area under the curve is 0.895, which proves that the prediction model has a good classification effect. Sparse logistic regression model is adopted to not only obtain classification results, but also select relevant features, which increase the interpretability of the model.
According to the coefficient of the sparse logistic regression model, we can obtain the features that are positively correlated with the gestational age of LGA. The body mass index of mother is greater than 28. The body mass index of mother is between 23.9 to 28. The body mass index of father is greater than 28. The mother has a little of life or work pressure. The father smokes. The mother touches second-hand smoking. The mother takes folic acid 1-2 months before menopause. The father drinks.
When the coefficient is negative, it shows that it has no promoting effect on the occurrence of LGA. The mother does not touch second-hand smoke. The mother does not have economic pressure. The body mass index of father is between 18.5 to 23.9. The father does not drink. The body mass index of mother is less than 18.5. The age of mother is between 18 to 25 years old. The hemoglobin of mother is normal. The mother does not have normal life or work pressure. The creatinine test of father normal. The mother ate folic acid at least 3 months before the menopause. The age of father is between 25 to 30 years.
Conclusions
We train the LGA predictive classifier by using the weak supervised learning method and sparse logistic regression model in machine learning. The accuracy of the final prediction model was 0.895, the precision rate was 0.965, the recall rate was 0.82, the f1_score was 0.886, and the area under the curve was 0.895. It means that the prediction accuracy of the model is 89.5%, and 96.5% of LGA can be identified. This model can predict LGA by using pre-pregnancy health examination items, which breaks the status that the prediction of LGA is still dependent on doctors' artificial experience. It is useful for doctors to diagnose LGA and achieves the goal of auxiliary clinic. The prediction model not only has a good classification effect, but also selects relevant characteristics. It makes the model explicable and makes the result easy for doctors and patients to understand.
high bmi were more likely to have LGA, which is consistent with previous research experience[7-10]. Fathers who smoke or mothers who are frequently exposed to secondhand smoke may have LGA. It is consistent with the findings of Surkan et al. that the smoking amount can affect the incidence rate of LGA[7]. Folic acid consumption in pregnant women may have an effect on the incidence of LGA. It is consistent with the finding that taking a certain amount of folic acid in preparation for pregnancy can enhance the physical development of baby[11].
We conclude that, in order to reduce the incidence of LGA, parents should maintain a normal weight, not smoke, not drink, and maintain normal indicators. In addition, the setting of optimal reproductive age is conducive to eugenics.
Acknowledgement
I would like to show my deepest gratitude to my teachers and classmates for their encouragement and support.
References
[1] Souka A P, Papastefanou I, Pilalis A, et al. Performance of third-trimester ultrasound for prediction of small-for-gestational-age neonates and evaluation of contingency screening policies[J]. Ultrasound in Obstetrics & Gynecology the Official Journal of the International Society of Ultrasound in Obstetrics & Gynecology. 2012, 39(5): 535-542.
[2] Tighe P, Laduzenski S, Edwards D, et al. Use of machine learning theory to predict the need for femoral nerve block following ACL repair.[J]. Pain Medicine. 2011, 12(10): 1566-1575.
[3] Austin P C, Tu J V, Ho J E, et al. Using methods from the data-mining and machine-learning literature for disease classification and prediction: a case study examining classification of heart failure subtypes[J]. Journal of clinical epidemiology. 2013, 66(4): 398-407.
[4] Jionglin W, Jason R, Stewart W F. Prediction modeling using EHR data: challenges, strategies, and a comparison of machine learning approaches[J]. Medical Care. 2010, 48(6 Suppl): S106.
[5] Haiping Shen, Xiaotian Li, Shikun Zhang, et al. Criteria for pre-pregnancy risk classification and assessment of couples of childbearing age [J]. Chinese medical journal. 2015, 95(3): 169-171.
[6] Shikun Zhang, Qiaomei Wang, Haiping Shen. Design, implementation and significance of free pre-pregnancy health examination in China [J]. Chinese medical journal. 2015, 95(3): 162-165.
[7] Surkan P J, Chung-Cheng H, Johansson A L V, et al. Reasons for increasing trends in large for gestational age births[J]. Obstetrics & Gynecology. 2004, 104(4): 720-726.
[8] Riitta L, Kinnunen T I, Minna A, et al. Primary prevention of gestational diabetes mellitus and large-for-gestational-age newborns by lifestyle counseling: a cluster-randomized controlled trial[J]. PLoS Medicine, 8, 5(2011-5-17). 2011, 8(5): e1001036.
[9] Ferraro Z M, Barrowman N, Prud'Homme D, et al. Excessive gestational weight gain predicts large for gestational age neonates independent of maternal body mass index.[J]. Journal of Maternal-Fetal Medicine. 2012, 25(5): 5.
[10] Darios G, Ananth C V, Peltier M R, et al. Changes in prepregnancy body mass index between the first and second pregnancies and risk of large-for-gestational-age birth[J]. American Journal of Obstetrics & Gynecology. 2007, 196(6): 530-531.