2018 International Conference on Information, Electronic and Communication Engineering (IECE 2018) ISBN: 978-1-60595-585-8
SMS Phishing Detection Using Oversampling and Feature
Optimization Method
Tong WU
1, Kang-feng ZHENG
1, Chun-hua WU
1,*and Xiu-juan WANG
21
School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing, China
2
School of Computer, Beijing University of Technology, Beijing, China
*Corresponding author
Keywords: Phishing detection, Mobile security, Feature optimization, Text classification.
Abstract. In this paper, a new SMS phishing detection method using oversampling and feature optimization technology is proposed to improve SMS phishing detection accuracy. Three types features are presented including token features, topic features and Linguistic Inquiry and Word Count (LIWC) features. One of the existing oversampling methods called Adaptive Synthetic Sampling Approach is applied in this paper since it has good performance. Then, Binary Particle Swarm Optimization(BPSO) algorithm is used to analyze the three types features and select the optimal combination of all the features. Finally, the detection results are achieved by Random Forest classification algorithm. Experimental results show oversampling method and feature optimization method improve the accuracy of SMS phishing detection. The best accuracy of the proposed method is 99.01% with an average of 86.6 features. The results demonstrate that the proposed method has a promising performance for SMS phishing detection.
Introduction
Phishing is a criminal mechanism employing both social engineering and technical subterfuge to steal consumers’ personal identity data and financial account credentials. According to the latest reports of Anti-Phishing Working Group (APWG), the total number of phish detected in 1Q 2018 was 263,538 which was up 46 percent from the 180,577 observed in 4Q 2017[1]. In the last few years, phishing attack grows rapidly and has become one of the most serious threats to global Internet security [2]. Phishing detection with high validity and robustness has already been an important task to protect Internet security.
The development of mobile network leads to an increasing trend of launching new phishing attacks through emerging technologies such as mobile and social media [3,4,5]. The prevalent use of social media provides fertile ground for phishing attacks due to increasing sharing of personal information but little awareness and action of protecting the information [6]. Phishing attacks increasingly focus on mobile users because of its large numbers and high probability of success [7]. The large numbers of mobile users are not matched with high levels of security awareness, and it is a matter of time before online threats such as phishing become a reality on mobile devices [8].
Many different approaches for fighting SMS phishing have been proposed, such as blacklist approach, content-based approach, etc. Blacklist approach sets a blacklist on mobile phone based on user experience which lacks inflexible to handle new phishing. Content-based approach is a promising approach for its ability of discerning phishing messages automatically [9]. The success of machine learning techniques in text categorization provides feasibility for content-based phishing detection methods. SMS phishing detection is a typical classification problem [10] in which the goal is to assign a test data one of the predefined classes (phishing, legitimate). Machine learning algorithms make use of the features extracted from phishing and legitimate messages to find patterns among them [11,12]. The detection process becomes reliable because the decisions are made based on rules discovered from historical data by learning algorithm [13].
characteristics of SMS phishing detection. For instance, most SMS messages in real environment are normal text without harm information and few phishing messages exist in our daily life. The phenomenon leads to imbalanced data problem, which means that there are lots of legitimate messages but few phishing messages to be learned using machine learning methods. On the other hand, SMS phishing messages are short text and common text modeling methods in Natural Language Processing (NLP) cannot interpret short messages primely. It is limited to improve SMS phishing detection accuracy without dealing with the existing problems.
In this paper, a new SMS phishing detection system is presented considering an approach for imbalanced data problem, a new feature framework and a feature optimization method. The approach for imbalanced data problem is aimed at handling with the huge quantity difference between normal SMS messages and phishing messages in real environment. Adaptive Synthetic Sampling Approach (ADASYN) is used in this paper for its good performance. New features framework is proposed through combining optimal features in previous researches including token features, topic features and LIWC features. And then, Binary Particle Swarm Optimization (BPSO) algorithm is applied for feature optimization combining with Random Forest (RF) classification algorithm. The SMS phishing detection system proposed in this paper completes SMS phishing detection on the basis of previous studies. Finally, the system improves the SMS phishing detection accuracy considering the characteristics of SMS phishing detection.
Related Work
There are two types of researches for SMS phishing detection in recent years, one is study of detection algorithm and the other is development of detection system. The study of detection algorithm is aimed at improving detection accuracy through various statistical learning methods and machine learning algorithms. The detection system is designed to apply in mobile phone so as to defense SMS phishing. Two types of features are generally used in previous researches including non-content features and content features. Non-content features refer to elements such as message size, time stamp and so on [14]. Content feature is a research hotspot for its promising accuracy such as special characters, function words and etc.
Most of extant researches focus on the study of detection algorithm. Several studies [15,16,17,18,19] compare various well-known algorithms such as Naive Bayes (NB), Decision Tree, Support Vector Machines (SVM), Random Forest (RF), etc. According to their experimental results, SVM and RF show the best performance in SMS phishing detection. In addition, some other researches work on developing SMS phishing detection applications. For example, Reference [20], [21] and [22] prove their proposed solution using Android platform.
The majority of existing studies apply content features in their researches, for instance, character and word features [23,24], Natural Language Processing(NLP) features [25,26,27], etc. Hidalgo et al. [15] use four types of word-based attributes including sequences of alpha-numeric characters, lowercased words, character bi-grams and tri-grams and word bi-grams in their study. Karami and Zhou [17] propose three types features including SMS Specific Features, Linguistic Inquiry and Word Count features and LDA topic features. Non-content features are also widely used in SMS phishing detection. For example, Jae Woong Joo et al.[28] distinguishes normal text message and phishing message through monitoring log, time stamp, URL and etc. Xu et al.[14] propose three types non-content features including static features, temporal features and network features using statistical method.
Methodology
SMS DB
Training Dataset
Testing Dataset
ADASYN
Token Features
Topic Features
LIWC Features
BPSO
Testing Features
Random Forest Classfication
Phishing
legitimate Random Forest
[image:3.595.81.512.77.188.2]Model Feature Extraction
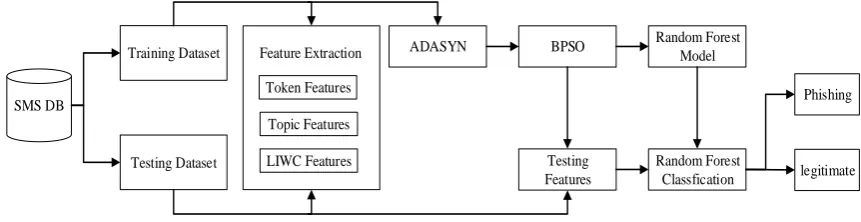
Figure 1. Framework of SMS phishing detection.
Framework for SMS phishing detection. The framework for SMS phishing detection is composed of 7 steps: Data input, Data preprocessing, Feature extraction, Oversampling, Feature optimization, Classification and Result output. Data preprocessing mainly focuses on the division of training and test dataset according to different splits. Three types features called token features, topic features and LIWC features are extracted in feature extraction step which will be introduced in detail in the following sections. One of the existing oversampling methods for dealing with the imbalanced samples problem called Adaptive Synthetic Sampling Approach(ADASYN) [29,30] is adopted to balance phishing samples and legitimate samples. Oversampling is very important for SMS phishing detection due to the imbalanced SMS data in real world. Binary Particle Swarm Optimization(BPSO) algorithm is applied to feature optimization step in order to extract optimal features and reduce feature dimension. Finally, Random Forest algorithm is used to classify whether it is phishing message or legitimate message.
Dataset. A publicly available dataset collected by Almeida et al.[16] is used in this paper. The dataset is published in UCI dataset as a commonly used standard test datasets for machine learning study. The dataset is composed of 5,574 messages which are non-encoded in English. Specially, it contains 747 phishing messages and 4,827 legitimate messages. This dataset is widely used in SMS phishing detection.
SMS phishing detection features. Three types features are presented in this paper including token features, topic features and LIWC features. Token features are collected from two parts, one is message structure and the other is function word. Focusing on the characteristics of short text, the biterm topic model(BTM) [31] for short texts is used in this paper. Linguistic Inquiry and Word Count(LIWC) features are derived from literature [17] for its good performance.
Table 1. Initial elements of function words.
Types Words
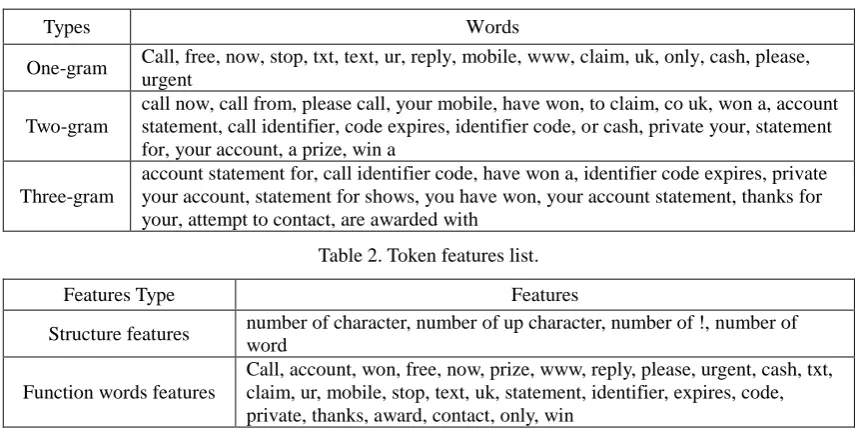
One-gram Call, free, now, stop, txt, text, ur, reply, mobile, www, claim, uk, only, cash, please, urgent
Two-gram
call now, call from, please call, your mobile, have won, to claim, co uk, won a, account statement, call identifier, code expires, identifier code, or cash, private your, statement for, your account, a prize, win a
Three-gram
[image:4.595.83.513.84.301.2]account statement for, call identifier code, have won a, identifier code expires, private your account, statement for shows, you have won, your account statement, thanks for your, attempt to contact, are awarded with
Table 2. Token features list.
Features Type Features
Structure features number of character, number of up character, number of !, number of word
Function words features
Call, account, won, free, now, prize, www, reply, please, urgent, cash, txt, claim, ur, mobile, stop, text, uk, statement, identifier, expires, code, private, thanks, award, contact, only, win
(2)Topic features. A topic model is a statistical model used to find the latent semantic structure in a series of documents which is widely used in natural language processing. Conventional topic models (e.g. LDA and PLSA) are used in Email phishing detection most frequently [3]. As a kind of short text, SMS messages differ from Emails and the other types of long texts. Directly applying those topic models on SMS phishing detection does not work well on account of the severe data sparsity in short documents [31]. Biterm topic model(BTM) models the word co-occurrence patterns and uses the aggregated patterns in the whole corpus for learning topics to solve the problem of sparse word co-occurrence patterns at document-level [31]. The topic probability distribution of each message obtained by BTM is used as topic features in this paper. Ten-fold cross validation method is adopted to determine the most appropriate number of topic and finally, 50 topics is selected through experiments using Random Forest algorithm.
(3)LIWC features. LIWC features are acquired through Linguistic Inquiry and Word Count (LIWC) tool which is a transparent text analysis program that counts words in psychologically meaningful categories [33]. LIWC can analyze text content quantitatively and calculate the percentage of different words categories in the text such as causal words, emotional words, cognitive words and the other psychological parts. LIWC is widely used in the field of natural language processing and psychology. Literature [17] firstly uses LIWC features in SMS phishing detection and achieves encouraging performance. Ninety-three LIWC features are used in this paper.
Oversampling method for imbalanced data. Mobile security reports in China indicates there are nearly 159.53 billion SMS messages in the first quarter of 2017, among which 0.18 billion messages are phishing messages. There are very few phishing samples compared to normal text messages. The huge discrepancy in the data suggests that SMS phishing detection is an imbalanced sample problem. Imbalanced samples can lead to a series of problems. The information contained in minority class is very limited and it is difficult to excavate rules internally. Many classification algorithms use the divide and conquer method, and few rules of minority class result in low classification accuracy. On the other side, improper induction bias systems tend to classify samples as the majority class when uncertainty exists. Therefore, SMS phishing detection rate will be relatively low using traditional method without dealing with the problem of imbalanced samples.
eliminate or reduce the imbalance of data by adding some samples of the minority class. Oversampling method leads to overfitting sometimes. Synthetic minority oversampling technique (SMOTE) is the most common used oversampling method for handling class imbalance. This paper uses Adaptive Synthetic Sampling Approach(ADASYN) which is an extension of SMOTE for its good performance.
[image:5.595.91.496.247.403.2]ADASYN algorithm is proposed to overcome the limitation of SMOTE algorithm which is SMOTE increases the occurrence of overlapping between classes because it generates the same number of synthetic data samples for each original minority example without considering neighbor examples [35]. The key idea of the ADASYN algorithm is to use a density distribution as a criterion to automatically decide the number of synthetic samples that need to be generated for each minority example by adaptively changing the weights of different minority examples to compensate for the skewed distributions [29,30].
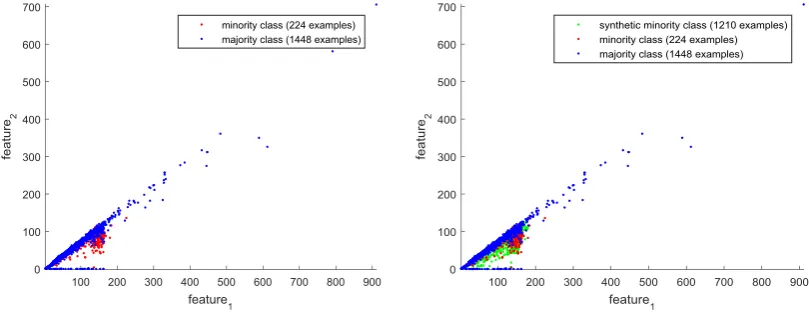
Figure 2. Samples distribution before and after using oversampling method.
Figure 2 shows the samples distribution before and after using ADASYN oversampling method through random sampling analysis. Before using ADASYN method, a big difference exists between the numbers of two classes samples. ADASYN method generates several samples belonging to the minority class so as to balance the number of two classes. The synthetic phishing messages are in accordance with the distribution of existing phishing samples. The two scatter grams present oversampling method solves the problem of imbalanced data. More minority samples improve the availability of training model for minority class which contribute to enhance the accuracy for phishing detection.
Feature optimization method based on BPSO algorithm. The particle swarm optimization algorithm (PSO), originally is proposed by Kennedy and Eberhart in 1995 [36], which has been used increasingly as an important algorithm among these population based search algorithms on solving problems in many fields, especially engineering and computer science. PSO is a bio-inspired algorithm enlightened by crowd behaviors, such as the birds in a flock and the fishes in a school cooperate while searching for food. The development of PSO is the mechanism by which each particle adjust their position by interacting information from particle’s past best position (pbest) and the global best position in all populations or neighbors (gbest). At each iteration, the pbest and
gbest are updated if a better or more dominating solution is found. This process continues iteratively, until some specific termination criteria are met and a final candidate solution is obtained. However, initially PSO is designed for continuous optimization problems, the discrete optimization problem is challenge in field of engineering and scientific applications.
The binary version of PSO (BPSO) is proposed by Kennedy and Eberhart in 1997 [37] for discrete optimization problems. Suppose that the search space is S = {0,1} for D dimension, and the objective function f is to be maximized, i.e., max f(x), then the i-th particle of the swarm can be described as vector𝑥𝑖 = (𝑥𝑖1, 𝑥𝑖2… 𝑥𝑖𝐷), 𝑥𝑖𝑑 ∈ {0,1},d = 1,2,. . . ,D. The velocity of particle can be
𝑝𝑖𝑑∈ {0,1}, d = 1,2,. . . ,D. the global best position define as 𝑔𝑏𝑒𝑠𝑡. The position and velocity of
particle i are updated using the following equations:
1
1 1( ) 2 2( )
k k k k k k
ij ij ij ij ij ij
v wv c r pbest x c r gbest x (1)
+1 1 (0,1) ( )
0
ij k
ij
if U sigm v x
otherwise
(2) where j = 1,2. . .D; i = 1,2. . .N, and N is the size of the swarm; c1 and c2 are constants, called cognitive and social scaling parameters respectively; r1 and r2 are random numbers, uniformly distributed in [0, 1]. U(0,1) is a symbol for uniformly distributed random number between 0 and 1.
sigm(vij) is a sigmoid limiting transformation. The traditional transfer function in BPSO is presented
as equation (3) and (4).
1 ( )
1 ij
ij v
T v
e
(3)
0 ( )
1 ( )
ij ij
ij
if rand T v x
if rand T v
(4)
Experiments and Results Analysis
In this section, several experiments are developed and experimental results are listed. Three types feature in this paper are analyzed through BPSO feature optimization method. In addition, the SMS phishing detection results are compared with previous researches.
Experimental results. Three experiments are designed to demonstrate the effectiveness and feasibility of the method proposed in this paper. Firstly, random forest algorithm is used to classify phishing and legitimate messages for its good performance [37]. Then, ADASYN data preprocessing method for imbalanced data is adopted to SMS phishing detection method. Finally, BPSO algorithm is taken for feature optimization in order to increase the rapidity and validity of the proposed system. The dataset introduced previously is used in the experiments. Seven measurements including accuracy (ACC), True Positives Rate(TPR), False Positives Rate(FPR), precision, recall, F1-measure and Matthews Correlation Coefficient (MCC) are listed for evaluating the performance of SMS phishing detection. In order to compare detection results with previous studies, different splits between training and testing datasets are applied in this paper such as 3:7, 5:1, 4:1, and 3:1 as well as 10-fold cross validation. The experimental parameters are assigned as follows: the trees number of random forest algorithm is t=50; the initial population number of BPSO algorithm is s=20; the maximum iteration number is I=100. The termination condition of the BPSO algorithm is that the evolution generation is equal to the maximum iteration number. All the results are the average of 10 times repeated experiments. All experiments in this paper are conducted in Matlab 2015b.
generally regarded as a balanced measure of the quality of binary classifications and +1 represents a perfect prediction. The method in this paper improves MCC value which makes the detection system close to a perfect prediction system.
Table 3. Experimental results.
Splits Method ACC(%) TPR FPR Precision Recall F1-Measure MCC
10-fold cross validation
RF 98.38173 0.94172 0.05395 0.98917 0.94172 0.96360 0.93167 ADASYN-RF 98.57920 0.95698 0.04353 0.98154 0.95698 0.96860 0.93742 ADASYN-PSO-RF 98.74418 0.96413 0.03553 0.98194 0.96413 0.97263 0.94708
3:7
RF 97.82676 0.92312 0.08013 0.98243 0.92312 0.94993 0.90257 ADASYN-RF 97.99077 0.93769 0.05322 0.97615 0.93769 0.95568 0.91779 ADASYN-PSO-RF 98.14967 0.94575 0.05473 0.97323 0.94575 0.95883 0.91802
5:1
RF 98.22785 0.93519 0.05221 0.99024 0.93519 0.96046 0.92951 ADASYN-RF 98.73418 0.95953 0.03980 0.98579 0.95953 0.97204 0.94558 ADASYN-PSO-RF 99.00844 0.97073 0.03296 0.98543 0.97073 0.97785 0.95362
4:1
RF 98.47397 0.94409 0.05188 0.99065 0.94409 0.96574 0.93539 ADASYN-RF 98.58169 0.95792 0.04884 0.98013 0.95792 0.96851 0.93699 ADASYN-PSO-RF 98.67145 0.96298 0.04110 0.97961 0.96298 0.97087 0.94277
3:1
RF 98.37877 0.94191 0.05603 0.98850 0.94191 0.96356 0.93047 ADASYN-RF 98.50789 0.95247 0.04703 0.98214 0.95247 0.96659 0.93275 ADASYN-PSO-RF 98.63702 0.96260 0.04243 0.97832 0.96260 0.97009 0.94080
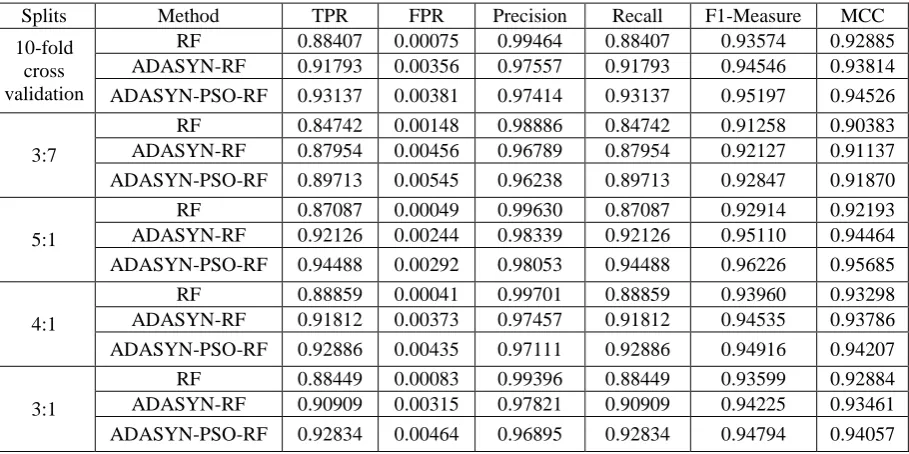
In order to show the effect of the proposed method on phishing messages detection, Table 4 presents the classfication results of phishing messages. According to the listed data, the proposed method improves TPR and Recall values and balances the detection of minority and majority class. The method solves the problem of imbalanced data and enhances the performance of SMS phishing detection. At the same time, the changes of FPR and Precision illustrate the increase of the number of misclassified legitimate messages. However, F1-Measure and MCC rise closer to 1 which shows the effectiveness of the proposed method.
Table 4. Classification results of phishing messages
Splits Method TPR FPR Precision Recall F1-Measure MCC 10-fold
cross validation
RF 0.88407 0.00075 0.99464 0.88407 0.93574 0.92885 ADASYN-RF 0.91793 0.00356 0.97557 0.91793 0.94546 0.93814 ADASYN-PSO-RF 0.93137 0.00381 0.97414 0.93137 0.95197 0.94526
3:7
RF 0.84742 0.00148 0.98886 0.84742 0.91258 0.90383 ADASYN-RF 0.87954 0.00456 0.96789 0.87954 0.92127 0.91137 ADASYN-PSO-RF 0.89713 0.00545 0.96238 0.89713 0.92847 0.91870
5:1
RF 0.87087 0.00049 0.99630 0.87087 0.92914 0.92193 ADASYN-RF 0.92126 0.00244 0.98339 0.92126 0.95110 0.94464 ADASYN-PSO-RF 0.94488 0.00292 0.98053 0.94488 0.96226 0.95685
4:1
RF 0.88859 0.00041 0.99701 0.88859 0.93960 0.93298 ADASYN-RF 0.91812 0.00373 0.97457 0.91812 0.94535 0.93786 ADASYN-PSO-RF 0.92886 0.00435 0.97111 0.92886 0.94916 0.94207
3:1
RF 0.88449 0.00083 0.99396 0.88449 0.93599 0.92884 ADASYN-RF 0.90909 0.00315 0.97821 0.90909 0.94225 0.93461 ADASYN-PSO-RF 0.92834 0.00464 0.96895 0.92834 0.94794 0.94057
[image:7.595.72.527.533.760.2]types of features present promising performance for SMS phishing detection. LIWC features display the best accuracy of 98.13% following by the accuracy of Topic features. However, the best Recall and F1 value are obtained by Topic features. This indicates that the hidden topic probability distribution of messages has a good effect on SMS phishing detection.
Table 5. Experimental results for single type features.
Features ACC(%) TPR FPR Precision Recall F1-Measure MCC Token features 97.36289 0.92700 0.06477 0.95805 0.92700 0.94148 0.88840
Topic features 98.09843 0.95562 0.04707 0.96065 0.95562 0.95791 0.91319 LIWC features 98.13427 0.94430 0.05772 0.97224 0.94430 0.95734 0.91385
[image:8.595.69.527.163.238.2]Feature optimization results analysis. BPSO feature optimization algorithm is used to reduce feature dimension and improve computational efficiency in this paper. Table 6 shows the feature optimization results with 10-fold cross validation method. The original features number is 175 and the average selected features number is 86.6 which is nearly half of the original number. The final SMS phishing detection accuracy has some improvement with half of the original features according to Table 3. For the three types features, the average selected features number is 13.4, 25.9 and 47.3. Thinking about the performance of different types features, each type of features is chosen in a different proportion. The highest chosen proportion 51.8% is presented by topic features and the second is LIWC features. This is consistent with the classification results in Table 5. Topic features and LIWC features have better performance, therefore, more associated features are chosen by features optimization algorithm. In comparison, Token features get relatively low accuracy so that a small number of features are selected. In general, BPSO feature optimization algorithm selects the optimal combination of features and show promising performance for SMS phishing detection.
Table 6. Features optimization results.
Type Original Feature Number
Average Selected
Number Proportion
All features 175 86.6 49.49%
Token features 32 13.4 41.88%
Topic features 50 25.9 51.80%
LIWC features 93 47.3 50.86%
Table 7. Results of three previous study.
Reference Results Details
[16] 97.64% With 30% samples for training
[17] 99.21% Using 480 features
[38] 99.01% Combine personality recognition and sentiment analysis
Conclusion
In this paper, a SMS phishing detection framework using oversampling and feature optimization method is presented through handling with imbalanced data problem and analyzing different types features. Three types of features are proposed including 32 token features, 50 topic features and 93 LIWC features. An oversampling method called Adaptive Synthetic Sampling (ADASYN) is applied to solve the problem of imbalanced data existing in SMS phishing detection. Then, this paper employs Binary Particle Swarm Optimization(BPSO) algorithm for reducing feature dimension and analyzing the optimal combination of features. Finally, three experiments are developed using Random Forest classification algorithm to evaluate the performance of the proposed method. Experimental results show that ADASYN and BPSO methods improve SMS phishing detection accuracy with three types of features. The highest accuracy is 99.01% with one-sixth samples as testing data and five-sixth samples as training data. For single type features, LIWC features and topic features express better performance up to 98.13%. Through BPSO feature optimization method, nearly half of original features are selected with better accuracy. LIWC features and topic features have big chosen proportion compared with token features. In general, the method proposed in this paper has a promising performance for SMS phishing detection.
Acknowledgement
This work is supported by the National Science and Technology Major Project under Grant no.2017YFB0802800 and the National Natural Science Foundation of China under Grant no.61602052.
References
[1] Phishing Activity Trends Report 1st Quarter 2018[R]. 2018. Available from: http://docs.apwg.org/reports/apwg_trends_report_q1_2018.pdf
[2] Gupta B B, Tewari A, Jain A K, et al. Fighting against phishing attacks: state of the art and future challenges[J]. Neural Computing and Applications, 2017, 28(12): 3629-3654.
[3] Aleroud A, Zhou L. Phishing environments, techniques, and countermeasures: A survey[J]. Computers & Security, 2017, 68: 160-196.
[4] Egele M, Stringhini G, Kruegel C, et al. Compa: Detecting compromised accounts on social networks[C]//NDSS. 2013.
[5] Marforio C, Masti R J, Soriente C, et al. Personalized Security Indicators to Detect Application Phishing Attacks in Mobile Platforms[J]. Computer Science, 2015, 06(3):206-212.
[6] Borsack R, Lifson M. Wire B. The Truth About Social Media Identity Theft: Perception Versus Reality[J]. Business Wire, 2010, 21.
[7] Lemos R. Phishing attacks increasingly focus on social networks, studies show; 2014. Available from:http://www.eweek.com/security/phishing-attacks-increasingly-focus-on-social-networks-studi es-show.html.
[9] Islam M R, Abawajy J, Warren M. Multi-tier phishing email classification with an impact of classifier rescheduling[C]//Pervasive Systems, Algorithms, and Networks (ISPAN), 2009 10th International Symposium on. IEEE, 2009: 789-793.
[10] Abdelhamid N, Ayesh A, Thabtah F. Associative classification mining for website phishing classification[C]//Proceedings on the International Conference on Artificial Intelligence (ICAI). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), 2013: 1.
[11] Costa G, Ortale R, Ritacco E. X-class: Associative classification of xml documents by structure[J]. ACM Transactions on Information Systems (TOIS), 2013, 31(1): 3.
[12] Thabtah F, Cowling P, Peng Y. MCAR: multi-class classification based on association rule[C]//Computer Systems and Applications, 2005. The 3rd ACS/IEEE International Conference on. IEEE, 2005: 33.
[13] Abdelhamid N, Ayesh A, Thabtah F. Phishing detection based Associative Classification data mining[J]. Expert Systems with Applications, 2014, 41(13):5948-5959.
[14] Xu Q, Xiang E W, Yang Q, et al. Sms spam detection using noncontent features[J]. IEEE Intelligent Systems, 2012, 27(6): 44-51.
[15] Gómez Hidalgo J M, Bringas G C, Sánz E P, et al. Content based SMS spam filtering[C]//Proceedings of the 2006 ACM symposium on Document engineering. ACM, 2006: 107-114.
[16] Almeida T A, Yamakami A. Contributions to the study of SMS spam filtering: new collection and results[C]// Proceedings of the 11th ACM symposium on Document engineering. ACM, 2011:259-262.
[17] Karami A, Zhou L. Exploiting latent content based features for the detection of static sms spams[J]. Proceedings of the Association for Information Science and Technology, 2014, 51(1): 1-4.
[18] Mathew K, Issac B. Intelligent spam classification for mobile text message[C]//Computer Science and Network Technology (ICCSNT), 2011 International Conference on. IEEE, 2011, 1: 101-105.
[19] Zainal K, Sulaiman N F, Jali M Z. An analysis of various algorithms for text spam classification and clustering using Rapid Miner and Weka[J]. International Journal of Computer Science and Information Security, 2015, 13(3): 66.
[20] Balubaid, M. A., Manzoor, U., Zafar, B., Qureshi, A., Ghani, N. Ontology Based SMS Controller for Smart Phones. International Journal of Advanced Computer Science and Applications, 2015, 6(1): 133–139.
[21] Sethi, G., Bhootna, V. SMS Spam Filtering Application Using Android. International Journal of Computer Science and Information Technologies (IJCSIT), 2014, 5(3): 4624–4626.
[22] Uysal A K, Gunal S, Ergin S, et al. The Impact of Feature Extraction and Selection on SMS Spam Filtering[J]. Elektronika Ir Elektrotechnika, 2013, 19(5):67-72.
[23] Uysal A K, Gunal S, Ergin S, et al. A novel framework for SMS spam filtering[C]// International Symposium on Innovations in Intelligent Systems and Applications. IEEE, 2012:1-4.
[25] Yeboah-Boateng E O, Amanor P M. Phishing, S MiShing & Vishing: an assessment of threats against mobile devices[J]. Journal of Emerging Trends in Computing and Information Sciences, 2014, 5(4): 297-307.
[26] Warade S J, Tijare P A, Sawalkar S N. An approach for SMS spam detection[J]. Int. J. Res. Advent Technol, 2014, 2(12): 8-11.
[27] Junaid M B, Farooq M. Using evolutionary learning classifiers to do MobileSpam (SMS) filtering[C]//Proceedings of the 13th annual conference on Genetic and evolutionary computation. ACM, 2011: 1795-1802.
[28] Joo J W, Moon S Y, Singh S, et al. S-Detector: an enhanced security model for detecting Smishing attack for mobile computing[J]. Telecommunications Systems, 2017, 66(1):1-10.
[29] He H, Bai Y, Garcia E A, et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning[C]//Neural Networks, 2008. IJCNN 2008.(IEEE World Congress on Computational Intelligence). IEEE International Joint Conference on. IEEE, 2008: 1322-1328.
[30] He H, Garcia E A. Learning from imbalanced data[J]. IEEE Transactions on knowledge and data engineering, 2009, 21(9): 1263-1284.
[31] Yan X, Guo J, Lan Y, et al. A biterm topic model for short texts[C]//Proceedings of the 22nd international conference on World Wide Web. ACM, 2013: 1445-1456.
[32] Cheng N, Chandramouli R, Subbalakshmi K P. Author gender identification from text[J]. Digital Investigation, 2011, 8(1): 78-88.
[33] Tausczik Y R, Pennebaker J W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods[J]. Journal of Language & Social Psychology, 2010, 29(1):24-54.
[34] More A. Survey of resampling techniques for improving classification performance in unbalanced datasets[J]. 2016.
[35] Wang B X, Japkowicz N. Imbalanced data set learning with synthetic samples[C]//Proc. IRIS Machine Learning Workshop. 2004, 19.
[36] Eberhart R, Kennedy J. A new optimizer using particle swarm theory[C]//Micro Machine and Human Science, 1995. MHS '95., Proceedings of the Sixth International Symposium on. IEEE, 1995: 39-43.
[37] Kennedy J, Eberhart R C. A discrete binary version of the particle swarm algorithm[C]//Systems, Man, and Cybernetics, 1997. Computational Cybernetics and Simulation., 1997 IEEE International Conference on. IEEE, 1997, 5: 4104-4108.