2017 2nd International Conference on Computer Science and Technology (CST 2017) ISBN: 978-1-60595-461-5
A Novel Image Annotation Method based on
Kernel Methods for Structured Prediction
Han-wen HUANG
1, Gang ZHANG
2,a*, Qiang PAN
1,
Yi-yu LIN
2, Dong LIN
2and Hua-dong LAI
21 Zhuhai City Polytechnic College, Zhuhai, 519090, China
2 School of Automation, Guangdong University of Technology, Guangzhou, 510006,
China
*Corresponding author
Keywords: Kernel methods, Structured machine learning, Image segmentation, Feature mapping.
Abstract. With the development of image processing and storage technology, rapid classification and annotation of huge volumes of digital images have been attracted much attention. However, the complex and ambiguous relationship between images and concept classes poses significant challenges on building effective annotation models. Structured machine learning methods have been studied to tackle the problem of complex relationship between concept classes for prediction, which have been proved effective for image understanding tasks. We proposed a novel image annotation model based on structured machine learning, by introducing a learned kernel function in the sample space, aiming at capturing the underlying distribution of concept classes of the training data set. The model is evaluated on two benchmark data sets and the results show that the model is promising compared to current state-of-the-art methods.
Introduction
With the development of image processing technology, more and more digital images have been produced and stored, in which there are valuable information and interesting patterns that can be used by human experts. For huge volumes of images, the tasks of classification and annotation have been attracted much attention since they may provide useful information for quick image search and content-based image retrieval (CBIR) [1]. For classification tasks, images are classified into several predefined categories by a trained model [2]. For annotation tasks, images are annotated with concerning terms to show their characteristics [3].
Large number of work has been proposed to tackle the problem of image classification and annotation. The basic idea is to represent each image as a data sample, either a single-instance or multiple-instance one [4]. Then the data sample with numerical feature representation can be processed by a machine learning model for both training and testing. Fig. 1 illustrates the annotation terms and concept labels associated with a sample image.
cannot be learned easily by the learning model. The second is that there are ambiguous relations between concept classes and regions of images.
Figure 1. Annotation terms and concept labels associated with a sample image.
And these potential relations often exist in mind and are often unavailable in training data sets. The first one prevents us from applying simple models to capture concept classes implied in image to be understood. Currently deep learning models are attracted much attention in machine learning communities and become a hot topic for image understanding [6], whose main idea is to construct complex model with multiple layers. For the second one, region-based feature representation methods are necessary to directly extract features of interested regions. However, current methods require prior knowledge for either model training or region detection, which are expensive and time-consuming for human experts. In this paper, we propose a novel method for image understanding based on kernel methods for structured prediction. We propose a multiple kernel learning (MKL) method to learn a joint kernel from a set of base kernel functions by combining them in a linear way. And then a kernel machine is trained with the learned kernel.
Structural Kernel Learning
Before going on, we give a formal definition of the traditional image annotation problem. Let be a set of images and be the corresponding annotation terms, where be a subset of the whole set of annotation terms . The problem is to learn a function according to and . When given an unseen image , predicts the most probable annotation terms. Since many annotation terms are only reflected by some local regions within an image, in many studies was regarded as a set of regions. Henceforth is designed as a multiple-instance model.
Different from previous work, we work on a joint kernel with a kernel-based helper function , where stands for the set of real. When given a test image , the annotation problem is equal to solve the following optimization problem:
(1)
To find the optimal solution of Eq. (1) is NP-hard and affected by the structure of . However, according to the idea of [7] and [8], we can solve the problem by using a SVM-like procedure, as shown in Eq. (2) and (3):
(2)
A set of slack variables have been introduced in the optimization problem to allow wrong classification. However, from the right hand side of Eq. (3) it can be seen that the wrong classified samples would be penalized according to the degree of wrong classification, i.e. the distance in the feature between it and the classification boundary. The mapping and its inner product are defined in the feature space induced by the joint kernel in this study. A proper kernel function can be used to induce a feature space that can meet the requirement as mentioned above. We apply kernel learning to achieve a good kernel function according to the training data set, following the idea of multiple kernel learning (MKL) to learn the joint kernel function. To build a general base kernel function set, let , in which is a set of RBF kernel and is a set of polynomial kernel, both with random parameters. The size of is denoted as . The MKL problem is to learn a weight vector such that the kernel performs best given a training data set and a classifier. As indicated in [9], the joint kernel functions can be defined as following:
(3)
where stands for RBF and polynomial, respectively. The function is a standard multiple-instance kernel with default parameter setting. Combined with Eq. (1), Eq. (2) and Eq. (3), we can finally get the joint kernel learning problem for structural prediction, as shown in Algorithm 1.
Algorithm 1 first randomly initializes a weight vector and then learn an optimal according to the training data set through the procedure, standing for multiple kernel learning, whose details are shown in Algorithm 2. After the optimal weight vector is achieved through , the combined kernel is obtained and it is applied to the optimization procedure to find the optimal joint kernel. Note that the classification function is obtained by maximizing the output of according to the set of annotation terms .
In Algorithm 2, a weight vector for combination is learned iteratively and at the same time the model is updated simultaneously. In Line 5, a support vector machine model is initialized randomly and L0 is obtained with the initial model. In Line 6, a Gram matrix
about a multiple-instance kernel is computed and stored in K. Line 7 is the maximizing
To make a clear presentation, we give a flow chart to summarize the aforementioned steps (See Fig. 2).
Figure 2. Main steps of the proposed method.
Evaluations
A. Dataset Description
The proposed method is evaluated on two benchmark image annotation data sets. The first one is the famous Corel Image 2000 data set (Image2000) [10], which contains 20 concept classes of 100 images, totally there are 2000 images. The second is a public image data set from ICDAR image recognition competition (ICDAR2003) [11]. The data set contain 5000 images which are represented in a multiple-instance form with real feature vectors. Table 1 gives the details of these two evaluation data sets.
Table 1. Dataset Description.
Image2000 ICDAR2003
Size 2000 561
Multiple-Class Yes Yes
Concept Classes 20 18
Reference Chen et al. [10] Lucas et al. [11]
[image:4.612.179.433.331.417.2]B. Settings
For Image2000, each class is divided into training set and test set of equal size. The size of image is and the color is 24-bit. Each image is processed by a SIFT descriptor and 256-level histogram for feature extraction. For ICDAR 2003, the sizes of images are different. Then crop and scale them manually to be for convenient processing. To show the effectiveness of the proposed method, we implement two current successful methods. The first is proposed by Zhu et al. in [12], denoted as , which constructs a generative model through a pure Bayesian procedure. The second is proposed by Wang et al. in [13], denoted as , which is a multiple-layer neural network combined with prior knowledge for better generalization ability.
C. Evaluation Results
[image:5.612.195.417.480.597.2]We report two evaluation results with comparison to two methods. The first is the overall accuracy comparison three methods on two evaluation data sets. The accuracy is defined as the ratio between model output and the ground truth annotation terms associated with an image. Table 2 shows the evaluation results.
Table 2. Overall Accuracy of 3 Methods (Accuracy/Variance)
Image2000 ICDAR2003
Our Method 86.4/1.4 84.9/1.6 79.0/2.4 81.2/1.9 80.7/1.8 80.6/2.2
From Table 2 it can be seen that the proposed method outperforms and , either at accuracy or variance. The variance is at class level. The proposed method is of relatively low variance, indicating that it is more stable among different classes than the other two methods.
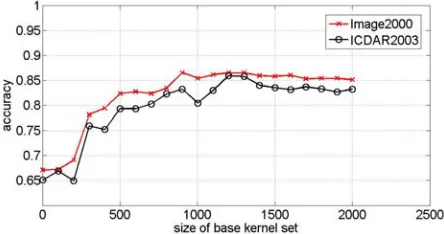
We report the parameter sensitivity of the proposed model. We vary the size of base kernel function set and record the corresponding model accuracy. For the size of base kernel function set, we vary it from 1 to 2001 with step 100. Fig. 3 shows how the size of base kernel set affects the model performance.
Figure 3. Evaluation of accuracy at different size of base kernel set.
Conclusions
two benchmark data sets, and the results are promising compared to two current successful methods.
Acknowledgement
This work is supported by National Natural Science Foundation of China (No. 81373883, 81573827), the Natural Science Foundation of Guangdong Province of China (No. 2016A030310340), the Special Fund of Cultivation of Technology Innovation for University Students (No. pdjh2016b0150), the College Student Career and Innovation Training Plan Project of Guangdong Province (yj201611845593, yj201611845074, yj201611845075, yj201611845366), the Higher Education Research Funding of Guangdong University of Technology (No. 2016GJ12), and the Zhuhai City Polytechnic Project (No. 020130311, 020141214).
References
[1] F. Fauzi and M. Belkhatir. “Image understanding and the web: A state-of-the-art review,” J. Intell. Inf. Syst., vol. 43, no. 2, pp. 271–306, Oct. 2014.
[2] Y. Su and F. Jurie. “Improving image classification using semantic attributes,” Int.
J. Comput. Vision, vol. 100, no. 1, pp. 59–77, Oct. 2012.
[3] D. Zhang, M. M. Islam, and G. Lu. “A review on automatic image annotation techniques,” Pattern Recogn., vol. 45, no. 1, pp. 346–362, Jan. 2012.
[4] Y. Li, D. M. J. Tax, R. P. W. Duin, and M. Loog. “Multiple-instance learning as a classifier combining problem,” Pattern Recogn., vol. 46, no. 3, pp. 865–874, Mar.
2013.
[5] L. Bottou. “From machine learning to machine reasoning,” Mach. Learn., vol. 94,
no. 2, pp. 133–149, Feb. 2014.
[6] J. Wan, D. Wang, S. C. H. Hoi, P. Wu, J. Zhu, Y. Zhang, and J. Li. “Deep learning for content-based image retrieval: A comprehensive study,” in Proceedings of the ACM
International Conference on Multimedia, ser. MM ’14. New York, NY, USA: ACM,
2014, pp. 157–166.
[7] D. Tuia, J. Muñoz Mar, M. Kanevski, and G. Camps-Valls. “Structured output svm for remote sensing image classification,” J. Signal Process. Syst., vol. 65, no. 3, pp.
301–310, Dec. 2011.
[8] A. Vedaldi, M. Blaschko, and A. Zisserman. “Learning equivariant structured output svm regressors,” in Proceedings of the 2011 International Conference on
Computer Vision, ser. ICCV ’11. Washington, DC, USA: IEEE Computer Society,
2011, pp. 959–966.
[9] Z.-H. Zhou, Y.-Y. Sun, and Y.-F. Li. “Multi-instance learning by treating instances as non-i.i.d. samples,” in Proceedings of the 26th Annual International Conference on
Machine Learning, ser. ICML ’09. New York, NY, USA: ACM, 2009, pp. 1249–1256.
[10] Y. Chen and J. Z. Wang. “Image categorization by learning and reasoning with regions,” J. Mach. Learn. Res., vol. 5, pp. 913–939, 2004.
[11] S. M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, and R. Young. “Icdar 2003 robust reading competitions,” in Proceedings of the Seventh International Conference
on Document Analysis and Recognition - Volume 2, ser. ICDAR ’03. Washington, DC,
USA: IEEE Computer Society, 2003, pp. 682–.
[12] N. Zhu, H. Zhang, and L. Liu. “A new method for image retrieval,” Journal of
[13] Z. Wang, Y. Hu, and L.-T. Chia. “Learning image-to-class distance metric for image classification,” ACM Trans. Intell. Syst. Technol., vol. 4, no. 2, pp. 34:1–34:22,