Topology Awareness in Unstructured P2P Networks using Accessible Bandwidth
Full text
Figure
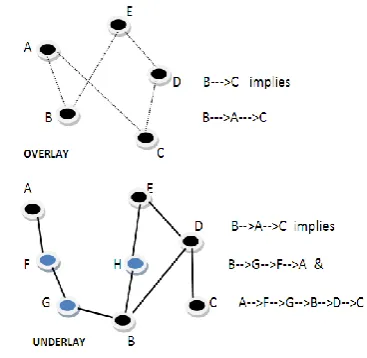
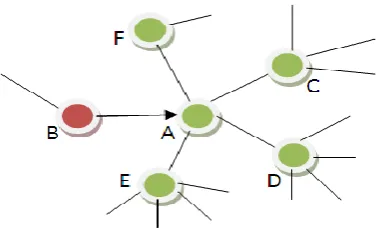
Related documents
Rhetorical scholarship on Indian boarding schools has emphasized, first, that cultural destruction was in fact the primary objective of boarding school education,
A preprocessing scheme based on linear prediction coefficient (LPC) residual is applied to higher-order statistics (HOSs) for automatic assessment of an overall pathological
Fig 4.2: Emissions of CO for combinations of biodiesel and pure diesel at 190 bar injection pressure.. from fig4.2 it is evident that at initial loads the co
Further, the coordinates of each business unit position in the matrix are determined according to the developed scales (Table 3), and they are displayed on the matrix in the form of
Most of the respondents (51.06%) noted that the process of improving liquidity positively impacts the performance hence reducing financial distress in insurance companies in
Principle 6 -- When a backflow prevention assembly passes a field test, the Backflow Assembly Tester shall submit within fifteen (15) business days of performing the field test
Instead, the data are carefully reviewed to understand the main features (e.g., center and spread) to determine what evidence this data might provide about the population.
This study is therefore focused on integrating petrophysical analysis, seismic attribute and rock physics responses for lithofacies identification and fluid fill
