© Copyright 2013. Apps Associates LLC. 1
What Next for DBAs in the Big Data Era
© Copyright 2013. Apps Associates LLC. 2
Satyendra Kumar Pasalapudi
Associate Practice Director – IMS @ Apps Associates
Co Founder & President of AIOUG
© Copyright 2014. Apps Associates LLC. 4
Agenda
•
Technology Trends
•
Big Data Overview
•
Hadoop Basics
•
NoSQL Databases
•
Big Data Sql
© Copyright 2014. Apps Associates LLC. 5
Cost effectively manage
and analyze
all available data in its
native form
unstructured,
structured, streaming
ERP
CRM RFID
Website
Network Switches Social Media
Billing
© Copyright 2014. Apps Associates LLC. 7
History of databases
Magnetic tape “flat” (sequential) files
Pre-computer technologies: Printing press Dewey decimal system Punched cards Magnetic Disk IMS Relational Model defined Indexed-Sequential Access Mechanism (ISAM) Network Model IDMS ADABAS System R Oracle V2 Ingres dBase DB2 Informix Sybase SQL Server Access Postgres MySQL Cassandra Hadoop Vertica Riak HBase Dynamo MongoDB Redis VoltDB Hana Neo4J Aerospike Hierarchical model 1960-70
Why?
•
3
rdPlatform drives
new demands on
the database:
– Global HighAvailability
– Data volumes
– Unstructured data
– Transaction rates
– Latency
•
A single
architecture cannot
meet all those
demands
Operational RDBMS (Oracle, SQL Server, …) In-memory Analytics (HANA, Exalytics …) In-memory processing (Spark) Hadoop Web DBMS (MySQL, Mongo, Cassandra)
ERP & in-house CRM
Analytic/BI software
(SAS, Tableau
Web Server Warehouse Data
RDBMS (Oracle, Terradata …)
Biggest IT inflection
point in our
generation
Cloud
Mobile
Social
Big
Data
© Copyright 2014. Apps Associates LLC. 14
The instrumented human
• Bluetooth Personal Area Network
• 3G/WiFi Wide Area Network
• GPS
• Storage
• Pulse, temp monitor
• Silent alarms
• Pedometer, sleep monitoring
• Compass
• Camera
• Mike/earphones
• Heads up display
• Emotion/Attention monitor
© Copyright 2014. Apps Associates LLC. 16
Google File System (GFS)
Map Reduce
BigTable
Google Applications
Google Software
Architecture
(circa 2005)
Start Map Reduce Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map Map
Map Reduce
© Copyright 2014. Apps Associates LLC. 19
Hadoop Design Principles
•
System shall manage and heal itself
–
Automatically and transparently route around failure
–
Speculatively execute redundant tasks if certain nodes are detected to be
slow
•
Performance shall scale linearly
–
Proportional change in capacity with resource change
•
Compute should move to data
–
Lower latency, lower bandwidth
© Copyright 2014. Apps Associates LLC. 20
Hadoop History
•
Dec 2004 – Google GFS paper published
•
July 2005 – Nutch uses MapReduce
•
Feb 2006 – Starts as a Lucene subproject
•
Apr 2007 – Yahoo! on 1000-node cluster
•
Jan 2008 – An Apache Top Level Project
•
Jul 2008 – A 4000 node test cluster
© Copyright 2014. Apps Associates LLC. 21
Hadoop Ecosystem
HDFS (Hadoop Distributed File System)
HBase
(key-value store)
MapReduce (Job Scheduling/Execution System)
Data Access
Sqoop
Flume
Client Access
Hue
Hive(Sql)
Pig(Pl/Sql)
ZooK
ee
pe
r
(Coo
rdina
ti
on)
(Streaming/Pipes APIs)
Chu
kw
a
(M
onit
ori
ng
)
Data Mining
Mahout
OS – Redhat, Suse, Ubuntu,Windows
Commodity Hardware
Java Virtual Machine Networking
Orchestration
© Copyright 2014. Apps Associates LLC. 22
© Copyright 2014. Apps Associates LLC. 23
Hadoop at Yahoo
•
2010(biggest cluster):
•
4000 nodes 16PB disk
•
64 TB of RAM
•
32,000 Cores
•
2014:
–
16 Clusters
© Copyright 2014. Apps Associates LLC. 25
© Copyright 2014. Apps Associates LLC. 27
Database Market Disruption
© Copyright 2014. Apps Associates LLC. 28
Name Site Counter
Dick Ebay 507,018
Dick Google 690,414
Jane Google 716,426
Dick Facebook 723,649
Jane Facebook 643,261
Jane ILoveLarry.com 856,767
Dick MadBillFans.com 675,230
NameId Name 1 Dick 2 Jane SiteId SiteName 1 Ebay 2 Google 3 Facebook 4 ILoveLarry.com 5 MadBillFans.com
NameId SiteId Counter
1 1 507,018
1 3 690,414
2 3 716,426
1 3 723,649
2 3 643,261
2 4 856,767
1 5 675,230
Id Name Ebay Google Facebook (other columns) MadBillFans.com
1 Dick 507,018 690,414 723,649 . . . 675,230
Id Name Google Facebook (other columns) ILoveLarry.com
2 Jane 716,426 643,261 . . . 856,767
Financial services
Discover fraud patterns based on multi-years worth of credit card transactions and in a time scale that does not allow new patterns to accumulate significant losses. Measure transaction processing latency across many business processes by processing and correlating system log data.
Internet retailer Discover fraud patterns in Internet retailing by mining Web click logs. Assess risk by product type and session/Internet Protocol (IP) address activity.
Retailers Perform sentiment analysis by analyzing social media data.
Drug discovery Perform large-scale text analytics on publicly available information sources.
Healthcare Analyze medical insurance claims data for financial analysis, fraud detection, and preferred patient treatment plans. Analyze patient electronic health records for evaluation of patient care regimes and drug safety.
Mobile telecom Discover mobile phone churn patterns based on analysis of CDRs and correlation with activity in subscribers’ networks of callers.
IT technical support Perform large-scale text analytics on help desk support data and publicly available support forums to correlate system failures with known problems.
Scientific research Analyze scientific data to extract features (e.g., identify celestial objects from telescope imagery). Internet travel Improve product ranking (e.g., of hotels) by analysis of multi-years worth of Web click logs.
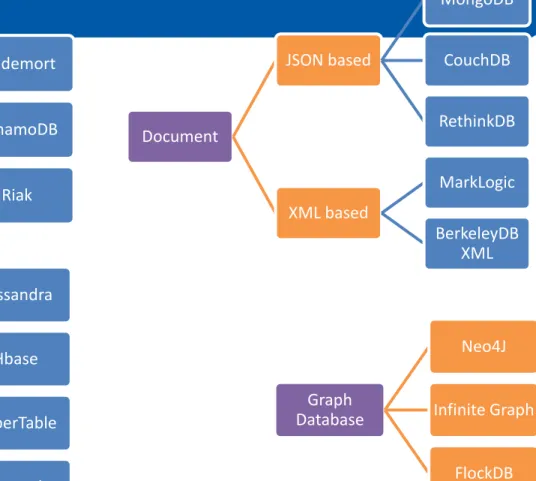
Document databases
•
Structured documents – XML and JSON (JavaScript Object Notation)
become more prevalent within applications
•
Web programmers start storing these in BLOBS in MySQL
•
Emergence of XML and JSON databases
Graph Database Neo4J Infinite Graph FlockDB Document JSON based MongoDB CouchDB RethinkDB XML based MarkLogic BerkeleyDB XML Key Value MemchacheD B Oracle NoSQL Dynamo Voldemort DynamoDB Riak
Table Based BigTable
Cassandra
Hbase
HyperTable
© Copyright 2014. Apps Associates LLC. 33
© Copyright 2014. Apps Associates LLC. 34
© Copyright 2014. Apps Associates LLC. 35
© Copyright 2014. Apps Associates LLC. 36
© Copyright 2014. Apps Associates LLC. 37
© Copyright 2014. Apps Associates LLC. 38
© Copyright 2014. Apps Associates LLC. 39
© Copyright 2014. Apps Associates LLC. 40
© Copyright 2014. Apps Associates LLC. 41
© Copyright 2013. Apps Associates LLC. 43
Big Data Architecture
D
A
T
A
S
O
U
R
C
E
S
DATA LAKE – On AWS Big Data Infra (Optrion2)
DATA CONNECTORS
A
N
A
L
Y
T
I
C
S
DATA LAKE on Oracle Big data Appliance
(Option1)
DATA LAKE – On Premise Hadoop Infra(Option3)
D
A
T
A
L
A
K
E
© Copyright 2013. Apps Associates LLC. 44
On Premise Hadoop as RDBMS “active archive
”
SALES 2013
Oracle Database
Structured Data Analytics from Apps
SALES 2012
SALES 2011
SALES 2010
SALES 2011
SALES 2010
“Hive” provides an
SQL-like query layer over
Hadoop and MapReduce
Unstructured + Structured Data Analytics from Apps
Hadoop for
Structured
Archive and
Unstructured
data
© Copyright 2013. Apps Associates LLC. 45
AWS EMR as RDBMS “active archive
”
SALES 2013
Oracle Database
Structured Data Analytics from Apps
SALES 2012
SALES 2011
SALES 2010
SALES 2011
SALES 2010
“Hive” provides an
SQL-like query layer over
Amazon EMR
Unstructured + Structured Data Analytics from Apps
AWS EMR for
Structured
Archive and
Unstructured
data
Oracle Database Support for All Data
•
Structured Data
•
Numeric, String, Date, …
•
Row and column
formats
•
Unstructured Data
•
LOB
•
Text
•
XML
•
JSON
•
Spatial
•
Graph
4
6
Run the Business
Scale-out and scale-up
Collect any data
SQL
Transactional and analytic applications for the enterprise
Secure and highly available
Relational
Oracle Support for Any Data Management System
Hadoop
Change the Business
Scale-out, low cost store
Collect any data
Map-reduce, SQL
Analytic applications
NoSQL
Scale the Business
Scale-out, low cost store
Collect key-value data
Find data by key
Big Data SQL
4
8
SELECT w.sess_id, c.name
FROM
web_logs w, customers c
WHERE w.source_country = ‘Brazil’
AND
w.cust_id = c.customer_id;
Relevant SQL runs on BDA nodes
10’s of Gigabytes of Data
Only columns and rows needed to answer query are returned
Hadoop Cluster
B B B
Big Data SQL
Oracle Database
CUSTOMERS WEB_LOGS
SQL Push Down in Big Data SQL
•
Hadoop Scans on Unstructured Data
•
WHERE Clause Evaluation
•
Column Projection
•
Bloom Filters for Better Join Performance
Data Analytics Challenge
Separate silos of information to analyze
4
9
Data Analytics Challenge
Separate data access interfaces
5
0
SQL on Hadoop is Obvious
Oracle
Confidential –
Internal/Restricte
d/Highly
Restricted
5
1
Data Analytics Challenge
No comprehensive SQL interface across Oracle, Hadoop and NoSQL
5
2
Oracle Big Data Management System
Rich, comprehensive SQL access to all enterprise data
5
3
Before
After
What Does Unified Query Mean for You?
Data Science
PhD
???
Before
After
What Does Unified Query Mean for You?
Application Development
Storage Layer
Big Data SQL : A New Hadoop Processing Engine
Filesystem (HDFS)
NoSQL Databases
(Oracle NoSQL DB, Hbase)
Resource Management (YARN, cgroups)
Processing Layer
MapReduc
e
and Hive
Spark
Impala
Search
Big Data
What Next for DBA’s in Big Data Era?
NoSQL
Hadoop
Big data Sql
12c New Features on Big data
Engineered Systems Knowledge
© Copyright 2014. Apps Associates LLC. 58