P a c k i n g o f Feature S t r u c t u r e s for
Efficient U n i f i c a t i o n o f D i s j u n c t i v e Feature S t r u c t u r e s
Y u s u k e M i y a oD e p a r t m e n t of Information Science, University of Tokyo 7-3-1 Hongo, Bunkyo-ku, Tokyo 113-0033 J a p a n
E-mail: y u s u k e ~ i s , s . u - t o k y o , a c . j p
A b s t r a c t
This paper proposes a method for packing fea- ture structures, which automatically collapses equivalent parts of lexical/phrasal feature struc- tures of HPSG into a single packed feature struc- ture. This method avoids redundant repetition of unification of those parts. Preliminary exper- iments show that this method can significantly improve a unification speed in parsing.
1 I n t r o d u c t i o n
Efficient treatment of syntactic/semantic ambi- guity is a key to making efficient parsers for wide-coverage grammars. In feature-structure- based grammars 1, such as HPSG (Pollard and Sag, 1994), ambiguity is expressed not only by manually-tailored disjunctive feature struc- tures, but also by enumerating non-disjunctive feature structures. In addition, there is ambigu- ity caused by non-determinism when applying lexical/grammar rules. As a result, a large num- ber of lexical/phrasal feature structures are re- quired to express ambiguous syntactic/semantic structures. Without efficient processing of these feature structures, a sufficient parsing speed is unattainable.
This paper proposes a method for packing feature structures, which is an automatic op- timization method for parsers based on feature structure unification. This method automati- cally extracts equivalent parts of feature struc- tures and collapses them into a single packed feature structure. A packed feature structure can be processed more efficiently because we can avoid redundant repetition of unification of the equivalent parts of original feature structures.
There have been many studies on efficient
1In this paper we consider typed feature structures
described in (Carpenter, 1992).
unification of disjunctive feature structures (Kasper and Rounds, 1986; Hasida, 1986; DSrre and Eisele, 1990; Nakano, 1991; Blache, 1997; Blache, 1998). All of them suppose that dis- junctive feature structures should be given by grammar writers or lexicographers. However, it is not practical to specify all ambiguity us- ing only manually-tailored disjunctive feature structures in grammar development. Where dis- junctive feature structures cannot be given ex- plicitly those algorithms lose their advantages. Hence, an automatic conversion method, such as the packing method described hereafter, is re- quired for further optimization of those systems. In addition, this packing method converts gen- eral feature structures to a suitable form for a simple and efficient unification algorithm which is also described in this paper.
Griffith (Griffith, 1995; Griffith, 1996) points out the same problem and proposes a compila- tion method for feature structures called mod- ularization. However, modularization is very time-consuming, and is not suitable for opti- mizing feature structures produced during pars- ing. An earlier paper of myself (Miyao et al., 1998) also discusses the same problem and pro- poses another packing method. However, that method can pack only pre-specified parts of input feature structures, and this characteris- tic limits the overall efficient gain. The new method in this paper can pack any kind of fea- ture structures as far as possible, and is more general than the previous method.
PHON <'o'ed~o'~
r
F F.E~O
verb] ]
• CArl HEAD
/
L,I r:-
[]
=_=o,,]>
/ I u~ /VAL I L
SYNSEM
ILOC~LI p ICOMP$ Am/ I L LSPR <> / ::l t v ~ . rcred.edl -I
I.
I-:'"' LA~G~ [~J
- word
PHON <'cre~eo'>
s~se~
.NONLOC I INHERISLASH ~T~
" ',~ocd
PHON <'cr~led>
r FHEAO ,,~,
I I P FCATIHEAD r.o~ - I -
/ ~ T L: I.SUm <Lco~ [] ~o~J,
! Iv"
m
; " CATI HEAD n o u n
NONLOCII~HERISLASH<[cONT [ ] nom_obJ] >
FHE~ verb "1
CATI HEAD noun
SUBJ < : >
r
[]
1/
/
>//
L LSPR < > J J
r r . ~ . ~ ] ]
• CATI HF.),D ~o~
t., I
<[co,, [] _oJ> 1//
I ''~ /VAL/coMP ~ noun - I > / / /
-1:1 /
I: L LSPR <> J J /
I
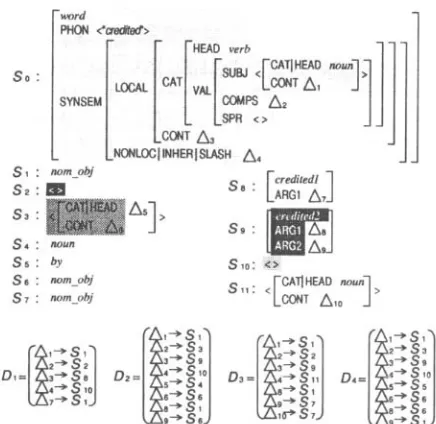
Figure 1 : 4 out of 37 lexical entries which the XHPSG system assigns to the word "credited".
Parts shaded with the same pattern are equivalent.
et al., 1998), an HPSG-based g r a m m a r for En- glish.
2.1 P a c k e d F e a t u r e S t r u c t u r e
Figure 1 shows 4 out of 37 lexical entries which the XHPSG system assigns to the word "cred-
ited". These lexical entries have various equiva-
lent parts in their respective feature structures. In Figure 1, equivalent parts are shaded with the same pattern.
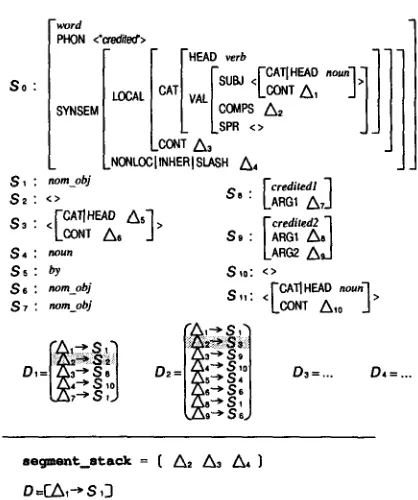
Figure 2 shows a packed feature structure for the lexical entries shown in Figure 1. Note that the equivalent parts of the original feature struc- tures are collapsed into a feature structure seg-
ment, which is denoted by Si in Figure 2. So is
a special segment called the root segment, which
"word
; PHON <'crecl~ad'>
I" ['HEAD ,~b
/
/ [SU=<[CATI"EAD"°"]
1
S o : LOCAL CAT VAL CONT A,
1
/ L LSPR o
l LCOm
LNONLOCI INHERI SLASH A ,
S , : nomobj rcreditedl
]
S= : I~] S , : LARG1 AT]
$ 4 : n o u n
i-CATIH~O no.n'l
S e : n o m o b j S 1, " < >
s,: ,o~_o~j L ~ A,o J
~ , ' - > S I'
I a 2 - * S ~/ I / % - ) S ,
D , = I z ~ s - * S s / D=_IzS,-*S,,
I ~ , ' * S,ol - I ~5c-* S ,
LL~,-* S , J I z36-~$6 kZ~o-* S e
I / % - * S 31 I ~ - - " S =/ I / % - * S o/ I A ~ - * S , | D,_IZ~,-*S,ol D~ =1 A , - * S . I
I ~5~'-* S ~/
-I ~Sr* S 5/
I ZS,-" S,/
I zSs--* S 6/
I ~Se-" S , /LZS,~ S U LZ~9_~ S , j
F i g u r e 2: A packed feature structure expressing the same information as the set of feature structures in Figure 1. Shaded parts correspond to the parts with the same pattern in Figure 1.
describes the root nodes of all original feature structures. Each segment can have disjunctive
nodes, which are denoted by Ai. For example,
53 has two disjunctive nodes, A 5 and A6. A de-
pendency function, denoted by Di, is a mapping
from a disjunctive node to a segment, and each Di corresponds to one original feature structure. We can obtain each original feature structure by replacing each disjunctive node with t h e o u t p u t of the respective dependency function.
For applying t h e unification algorithm de- scribed in Section 2.3, we introduce a con-
dition on segments: a segment cannot have
inter- or intra-segment shared nodes. For ex-
ample, the disjunctive node i 1 in Figure 2 must be introduced for satisfying this con- dition, even t h o u g h the value of this node is the same in all the original feature struc- tures. This is because this path is structure-
shared with another path
(SYNSEHILOCALJCONT
j
ARG1 and
SYNSEHJLOCALJCONTJARG2).
Structure-sharing in original feature structures is instead expressed by letting the dependency function return the same value for different inputs. For example, result values of applying D1 to A1 and A7 are b o t h S1.
The reason why we introduce this condition is to guarantee t h a t a disjunctive node in the
[image:2.612.79.294.67.437.2] [image:2.612.322.540.77.289.2]r _
IPHON <'cmd~e~>
S o : / FCAT F HEAD verb
0 T credited/
L
P" L,.o, ,,,J
$1 : John
$ 2 : Yusuke
D,=E At-~S,3
D2=EA,-~S2]
Figure 3: A sample packed feature structure. If it is unified with the top feature structure in Figure 1, a new disjunctive node must he introduced to SYNSRM I
LOCALICATJVALJSUBJ
IFIRSTICONT.
result of unification will appear only at a path where a disjunctive node appears in either of the input feature structures at the same path. For example, suppose we unify the top feature struc- ture in Figure 1 with the packed feature struc- ture in Figure 3. In the result of unification, a
new disjunctive node must appear at SYNSEM I
LOCALJCATIVALJSUBJJFIRSTJCONT , while no dis- junctive nodes appear in either of the i n p u t fea- ture structures at this path. By introducing such a disjunctive node in advance, we can sim- plify the algorithm for unification described in Section 2.3.
Below I first describe the algorithm for pack- ing feature structures, and then the algorithm for unification of packed feature structures.
2.2 A l g o r i t h m f o r P a c k i n g
The procedure pack_feature_structures in
Figure 4 describes the algorithm for packing two packed feature structures, denoted by (S',:D') and
(,9", D"). ,9'
and S" denote sets of seg- ments, and 7)' and 7)" denote sets of depen- dency functions. We start from comparing the types of the root nodes of both feature struc- tures. If either of the nodes is a disjunctive node(Case
1),
we compare the type of the other fea-ture structure with the type of each disjunct, and recursively pack nodes with the same type if they exist
(Case 1.1).
Otherwise, we just add the other feature structure to the disjunc- tive node as a new disjunct(Case 1.2).
If the types of the nodes are equivalent(Case 2),
we collapse t h e m into one node, and apply packing recursively to all of their subnodes. If they are not equivalent(Case 3),
we create a new dis- junctive node at this node, and let each originalprocedure pack.~eatureJtructures((S', Do), (S", D " ) ) begin
~o ~ s'. s~' ~ s"
7:) : = ~ ) t U "/3 II
re~ura (S, D)
end
procedure pach(F s, F H) hesin
i~ F / ( o r F Is) is d i s j z u c t i o n then
i f B G ( G E diojuncts(F').
G a . d F " ha~e e q u i v a l e n t types) 1;hen S := S U d i o j u n c t s ( F ' )
pack(G. F " )
Y~" := { D I D " E D H , D = D " U ( F ' -- F " ) } e l s e
S := S U d i s j u n c t s ( F I ) u { F / ' }
7)" := { D I D 'I E ~9", D = D " u ( F ' -- F " ) } endi:f
e l s e i:f F/ a n d F " ha~e e q u i v a l e n t t y p e s then
F' := F "
~oreach f in f e a t u r e s ( F I)
pack(:foUoe(.f, F'), :follou(.f, F " ) )
eloe
S : = S U { F ' , F " }
F := 4io3uuctiYe-node
D ' := {DID' E ~ ) ' , D = D' U ( F -- F')} D " := { D I D " 6 D " , D = D " U ( F -- F " ) }
endif cud
disjuucts: return a set of disjuncts of the disjunctive node :features: r e t u r n a set of features
:folios: r e t u r n a s u b s t r u c t u r e reached by t h e specified f e a t u r e • C u a e 1
• C a s e 1 , 1
• (:~.ue 1 . 2
• Case 2
• Cese 3
Figure 4: Algorithm for packing two packed feature structures (S',:D') and (S", $)").
feature structure from this node become a new segment.
For simplicity, Figure 4 omits the algorithm for introducing disjunctive nodes into shared nodes. We can easily create disjunctive nodes in such places by preprocessing input feature structures in the following way. First each input feature structure is converted to a packed fea- ture structure in advance by converting shared nodes to disjunctive nodes. Then the above algorithm can be applied to these converted packed feature structures.
2 . 3 A l g o r i t h m f o r U n i f i c a t i o n
Below I describe the algorithm for unification of packed feature structures, referring to the exam- ple in Figure 2. Suppose that we are unifying this packed feature structure with the feature structure in Figure 5. This example consid- ers unification of a non-packed feature structure with a packed feature structure, although this algorithm is capable of unifying two packed fea- ture structures.
The process itself is described by the pro-
cedure unify_packed_feature_structures in
[image:3.612.307.537.66.330.2] [image:3.612.65.291.68.171.2]"word
PHON <'ged#eo'>
I I -
;YNSEM LOCAL CAT / |VAL|c(:~PS [ ] ~SUBJ < ECONT [ ] -] < >
L LSPR < >
CONTI ARG1 [ ] .NONLOC I INHER I SLASH list
Figure 5: A sample feature structure to be unified with the packed feature structure in Figure 2.
procedure unify.p¢cked.te=ture.=tructuree((S e, ~)e). (Se, 7)1,))
begin
S : = ¢ . Z>:=@
fore,oh D e E ~Ot and D ee E ~ H
IEXT:
besin
push-eeSm.~-sCack(S~0 E S/, S~' E S ' )
do u n t i l seipnen~-lCack.As-emp~y
b e s t .
pop_ee~ment.o~ack(S I ,S/e)
i~ S /i e d i # j ~ c t l o n chert S* : = D ~ ( S ~) . . . ( t )
i f S H is dlsj~nction ~hen S" := DH(S//)
SEOHIIJ]IIF¥ :
if alread~-nni~ied(S/,S H) th~n ' ' . ( 2 ) S :=restore2Jnify.reeul~( st,s/I )
~' := S, S" : = S . . - (3)
e l s e
i f S : = u n i f y ( ~ , $ / I ) f a i l s then Ko~o I g l t
else
S : = ~ u { S }
s~s_unificasien.reeul~(S, S ~, ~e)
S e := 5. S" := S (a)
4ed~f endif e~d
7:' := "D u { D ~ U D ' }
e~d
recur. (S, ~))
e~d
procedure unify(F',F '~) besin
i~ F ~ or F ee le d~oj~.c~ion ~heu (6) F : = disjunctive.node
p u s h _ s e ~ n t _ s t a c k ( F / , F ¢/)
else IODB.UIIF¥ :
F := u n i f y J y p e ( F ~, F ~ )
forea©h ] ~n featureo(F)
f o l l o u ( f , F ) : = u n i f y ( f e l l o u ( f , F / ) , fellou(f,FH)) endif
re~urn F
oud
already-unified: t ~ e w h e n unification is a l r e a d y c o m p u t e d res~ere_uui~y_result: r e s t o r e t h e result of unific&tion from
the t a b l e
seS_unify.xesul~: store t h e result of unification into the t a b l e unifyJype: return the unification of b o t h t y p e s
Figure 6: Algorithm for unifying two packed fea- ture structures (S',:D'} and (S",:D"}.
fication algorithm. The only difference is the part that handles disjunctive nodes. When we reach a disjunctive node, we put it onto a stack (segment_stack), and postpone further unifi- cation from this node ((5) in Figure 6). In this example, we put A1, A2, A3, and A4 onto the stack. At the end of the entire unification, we
"word PHON <'cred/ted>
T A , SuN <
[image:4.612.327.536.57.307.2] [image:4.612.79.299.63.145.2] [image:4.612.78.302.194.564.2]S o : LOCAL CAT VAL COMPS
SYNSEM | ] L LS PR <>
| LCONT A ,
LNONLOCIINHER[ SLASH A4
S , : nom_obj ~credltedl
S = : <> Ss: LARGt ATJ
[-CA~HEAD ~ s 1 r'credited2 q
s~: <Lco.T A, ." s s: IARa~ Ael
$4 : .ou. LARG2 A*J
Ss : bY S~o: <>
S s : nom obj FCAT~HEAO noun-]
s , : .o m obj s,,: <LCoNT A,o J>
1 ~ . ] . I As--* S sl
O,=l ~s--" S e/ L,21" _-I[/k,-* S,ol]ks._. S , [ O~ .... 04 .... I/'.,-~ S ,ol I/Xs--* Sol
L~7 -> S , J I Ge-" S , /
kL~s-* S sJ
a e ~ t _ s t = ~ = ( As As A , }
D =CZ~I'* S , ]
Figure 7: Intermediate data structure after unify- ing A 1 with [ ~ . Disjunction is expressed by non- determinism when applying the dependency func- tions. When we unify a feature structure segment for A2, we unify $2 if we are applying Dz, or 53 if D2.
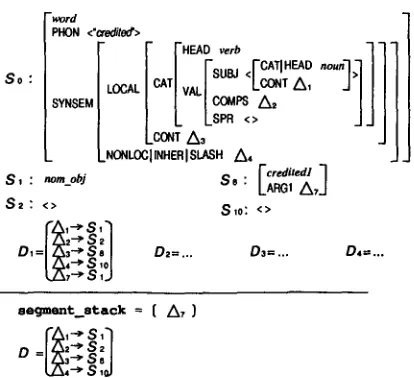
apply a dependency function to each member of the stack, and unify every resulting segment with a corresponding part of the other feature structure ((1) in Figure 6). In this example, we apply D1 to A1, which returns segment 51. We therefore unify 5z with the feature structure tagged as [~] in Figure 5.
Disjunction is expressed by non-determinism when applying the dependency functions. Fig- ure 7 shows the intermediate data structure af- ter unifying A1 with [~]. We are now focusing on the disjunctive node A2 which is now on the top of segment_stack. When we are applying Dz, we unify $2 with the corresponding feature structure [~]. Should we instead apply D2, 53 would be unified.
A benefit of this unification algorithm is that we can skip unification of feature structure seg- ments whose unification is already computed ((2) in Figure 6). For example, we unify seg- ment So with the other feature structure only once. We can also skip unification of $1 and 5z0 for /:)2, because the result is already computed
S o :
-word PHON <'credited'>
/ / / Fsu~<F c^TIHEA°"°"
[image:5.612.72.279.65.254.2] [image:5.612.313.520.65.257.2]/~OCAL/CAT/V~./ LCONT A,
WNSEM| | | | C O ~ /k=
| | L LSPR <>
/ L cONT Z~,
LNON'OCIINHERISLASH Z~,
F c'd''al 7
s , : ,,om_~j s~ : LARG~ /k,J
S = : <> S~o: <> FZ~,-, S,3
] ~ - * S =/ u, =1 4~s ''~ S ~/ I Z l , - * S ,ol LZI~-" S,J
D==... Ds=... D4=...
a e g m e a t s t a c ) : = ( A, }
F~,-- S,7 _ I A = - , S ~/ L/I, -~ S ,~1
"word
PHON <'cmditeo'>
/
/ / I-SU~<I-CATIH~O
""S o : { LOCAL /CM/V/~L/COMPS LL~TT A,
~YNSEM| / L LSPR < >
| L c-,ONT Z~
LNONLOCIiNHERISLASH /k, S i : nom obj S s : nom_obj
S ~ : <> S s : <>
F credi'ed! I rCATIHEAD noun]
S 3 : LABG I /ks_] S, : < Lco~ A , •
F credited# ]
S , : |ARG1 L ~ | LARG2 /k,J
FA,--> S ,7 [ ~=--> S , / u,=l/_~-~ S ~]
I ZM-" S e/ L/Is-* S ,J
t/k,-~ S ,7
I A s * S ~/
D,=I ]~,-> S , / I ~ , - " S , / I/k7 -~ S s/ LZI,-* S 5J
Figure 8: Intermediate data structure after the uni- fication of A4. Because the result of applying Dz to AT is already overwritten by the result of unifying 51 within], we unify this resulting feature structure with
ff]y
for D1. This operation preserves the validity of unification because each segment does not have inter- or intra-segment shared nodes, because of the condition we previously introduced.
Note that this method can correctly unify fea- ture structures with reentrancies. For example, Figure 8 shows the intermediate data structure after unifying A4, and the process currently reached A7 and E]" The result of the appli- cation of D1 to A7 is the result of unifying Sz with [~, because Sz is overwritten with the re- sult of this previous unification ((3) and (4) in Figure 6). Hence, we unify E ] with this result.
Above unification algorithm is applied to ev- ery combination of dependency functions. The result of the entire unification is shown in Fig- ure 9.
3 E x p e r i m e n t s
I implemented the algorithms for packing and unification in LiLFeS (Makino et al., 1998). LiLFeS is one of the fastest inference engines for processing feature structure logic, and effi- cient parsers have already been realized using this system. For performance evaluation I mea- sure the execution time for a part of application of grammar rules (i.e. schemata) of XHPSG.
Table 1 shows the execution time for uni- fying the resulting feature structure of apply-
Figure 9: The resulting packed feature structure of unifying the packed feature structure of Figure 2 with the feature structure of Figure 5.
ing schemata to lexical entries of "Mary" as a left daughter, with lexical entries of "cred-
ited"/"walked" as right daughters. Unification
of packed feature structures achieved a speed- up by a factor of 6.4 to 8.4, compared to the naive approach. Table 2 shows the number of unification routine calls. NODE_UNIFY shows the number of nodes for which unification of types is computed. As can be seen, it is significantly reduced. On the other hand, SEGNENT_UNIFY shows the number of check operations whether unification is already computed. It shows that the number of node unification operations is sig- nificantly reduced by the packing method, and segment unification operations account for most of the time taken by the unification.
These results indicate that a unification speed can be improved furthermore by reducing the number of the segment unification. The data structure of dependency functions has to be improved, and dependency functions can be packed. I observed that at least a quarter of the segment unification operations can be sup- pressed. This is one of the future works. 4 C o n c l u s i o n
Table 1: Execution time for unification. Test data shows the word used for the experiment. # of LEs
shows the number of lexical entries assigned to the word. Naive shows the time for unification with a naive method. PFS shows the time for unification of packed feature structures (PFS). Improvement shows the ratio ( gaive)/( PFS).
Test data # of LEs Naive (msec.) PFS (msec.) Improvement (factor)
credited 37 36.5 5.7 6.4
walked 79 77.2 9.2 8.4
Table 2: The number of calling each part of the unification routines. Naive shows the number of node unification operations in the naive unification algorithm (corresponds to NODE_UNIFY of my algorithm).
NODE_UNIFY and SEGMENT_UNIFY are specified in Figure 6.
Test data Naive NODE_UNIFY SEGMENT_UNIFY
credited 30929 256 5095
walked 65709 265 10603
equivalent parts. I implemented this m e t h o d in LiLFeS, and achieved a speed-up of the unifica- tion process by a factor of 6.4 to 8.4. For realiz- ing efficient NLP systems, I am currently build- ing an efficient parser by integrating the packing m e t h o d with t h e compilation m e t h o d for HPSG (Torisawa and Tsujii, 1996). While the compi- lation m e t h o d reduces the number of unification operations during parsing, it cannot prevent in- efficiency caused by ambiguity. The packing m e t h o d will overcome this problem, and will hopefully enable us to realize practical and effi- cient NLP systems.
R e f e r e n c e s
Philippe Blache. 1997. Disambiguating with
controlled disjunctions. In Proc. Interna-
tional Workshop on Parsing Technologies.
Philippe Blache. 1998. Parsing ambigu-
ous structures using controlled disjunctions
and unary quasi-trees. In Proc. COLING-
ACL'98, pages 124-130.
Bob Carpenter. 1992. The Logic of Typed Fea-
ture Structures. Cambridge University Press. Jochen DSrre and Andreas Eisele. 1990. Fea- ture logic with disjunctive unification. In
Proc. 13th COLING, volume 2, pages 100- 105.
John Griffith. 1995. Optimizing feature struc- ture unification with dependent disjunctions. In Proc. Workshop on Grammar Formalism for NLP at ESSLLI-94, pages 37-59.
John Griffith. 1996. Modularizing contexted
constraints. In Proc. COLING'96, pages 448-
453.
KSiti Hasida. 1986. Conditioned unification for
natural language processing. In Proc. 11th
COLING, pages 85-87.
Robert T. Kasper and William C. Rounds. 1986. A logical semantics for feature struc- tures. In Proc. 24th ACL, pages 257-266. Takaki Makino, Minoru Yoshida, Kentaro Tori-
sawa, and Jun'ichi Tsujii. 1998. LiLFeS - -
towards a practical HPSG parser. In Proc.
COLING-A CL '98, pages 807-811.
Yusuke Miyao, Kentaro Torisawa, Yuka Tateisi, and Jun'ichi Tsujii. 1998. Packing of fea- ture structures for optimizing the HPSG- style g r a m m a r translated from TAG. In Proc.
TAG+4 Workshop, pages 104-107.
Mikio Nakano. 1991. Constraint projection: A n efficient t r e a t m e n t of disjunctive feature de- scriptions. In Proc. P9th ACL, pages 307-314.
C. Pollard and I. A. Sag. 1994. Head-Driven
Phrase Structure Grammar. University of Chicago Press.
Yuka Tateisi, Kentaro Torisawa, Yusuke Miyao, and Jun'ichi Tsujii. 1998. Translating t h e
XTAG English grammar to HPSG. In Proc.
TAG+4 Workshop, pages 172-175.
Kentaro Torisawa and Jun'ichi Tsujii. 1996. C o m p u t i n g phrasal-signs in HPSG prior to
parsing. In Proc. 16th COLING, pages 949-
955.
[image:6.612.113.506.128.170.2]