Learning Subregular Classes of Languages with Factored Deterministic
Automata
Jeffrey Heinz
Dept. of Linguistics and Cognitive Science University of Delaware
James Rogers Dept. of Computer Science
Earlham College
Abstract
This paper shows how factored finite-state representations of subregular lan-guage classes are identifiable in the limit from positive data by learners which are polytime iterative and optimal. These rep-resentations are motivated in two ways. First, the size of this representation for a given regular language can be expo-nentially smaller than the size of the minimal deterministic acceptor recogniz-ing the language. Second, these rep-resentations (including the exponentially smaller ones) describe actual formal lan-guages which successfully model natural language phenomenon, notably in the sub-field of phonology.
1 Introduction
In this paper we show how to define certain sub-regular classes of languages which are identifiable in the limit from positive data (ILPD) by efficient, well-behaved learners with a lattice-structured hy-pothesis space (Heinz et al., 2012). It is shown that every finitesetof DFAs defines such an ILPD class. In this case, each DFA can be viewed as onefactor in the description of every language in the class. This factoring of language classes into multiple DFA can provide a compact, canonical representation of the grammars foreverylanguage in the class. Additionally, many subregular classes of languages can be learned by the above methods including the Locallyk-Testable, Strictlyk-Local, Piecewise k-Testable, and Strictly k-Piecewise languages (McNaughton and Papert, 1971; Rogers and Pullum, 2011; Rogers et al., 2010). From a linguistic (and cognitive) perspective, these sub-regular classes are interesting because they appear to be sufficient for modeling phonotactic patterns in human language (Heinz, 2010; Heinz et al., 2011; Rogers et al., to appear).
2 Preliminaries
For any functionfand elementain the domain of f, we writef(a)↓iff(a)is defined,f(a)↓= xif it is defined for aand its value is x, and f(a)↑
otherwise. The range of f, the set of values f takes at elements for which it is defined, is denoted range(f).
Σ∗ and Σk denote all sequences of any finite length, and of length k, over a finite alphabet Σ. The empty string is denotedλ. A languageLis a subset ofΣ∗.
For allx, ybelonging to a partially-ordered set
(S,≤), ifx ≤ z and y ≤ z then z is an upper boundofxandy. For allx, y∈S, theleastupper bound (lub)x⊔y=ziffx≤z,y≤z, and for all z′ which upper bound x andy, it is the case that z≤z′. Anupper semi-latticeis a partially ordered set(S,≤)such that every subset ofShas a lub. If S is finite, this is equivalent to the existence of x⊔yfor allx, y∈S.
A deterministic finite-state automaton (DFA) is a tuple(Q,Σ, Q0, F, δ). The states of the DFA are
Q; the input alphabet isΣ; the set of initial states isQ0; the final states areF; andδ :Q×Σ→ Q
is the transitionfunction.
We admit a set of initial states solely to accom-modate the empty DFA, which has none. Deter-ministic automata never have more than one ini-tial state. We will assume that, if the automaton is non-empty, thenQ0 ={q0};
The transition function’s domain is extended to Q×Σ∗in the usual way.
The language of a DFAAis
L(A)def={w∈Σ∗ |δ(q0, w)↓∈F}.
A DFA istrimiff it has no useless states:
(∀q ∈Q)[ ∃w, v∈Σ∗|
δ(q0, w)↓=qandδ(q, v)↓∈F].
Every DFA can be trimmed by eliminating useless states from Qand restricting the remaining com-ponents accordingly.
The empty DFA isA∅ = (∅,Σ,∅,∅,∅). This is the minimal trim DFA such thatL(A∅) =∅.
The DFA product ofA1= (Q1,Σ, Q01, F1, δ1)
andA2 = (Q2,Σ, Q02, F2, δ2)is
⊗(A1,A2) = (Q,Σ, Q0, F, δ)
where Q = Q1 × Q2, Q0 = Q01 × Q02,
F =F1×F2and
(∀q ∈Q)(∀σ∈Σ) δ (q1, q2), σ
def
= (δ1(q1, σ), δ2(q2, σ))
The DFA product of two DFA is also a DFA. It is not necessarily trim, but we will generally as-sume that in taking the product the result has been trimmed, as well.
The product operation is associative and com-mutative (up to isomorphism), and so it can be ap-plied to a finite set S of DFA, in which case we writeN
S = N
A∈SA(letting N
{A} =A). In this paper, grammars are finitesequencesof DFAs
~
A = hA1· · · Ani and we also use the N nota-tion for the product of a finite sequence of DFAs: N ~
A def= N
A∈A~A and L(A)~ def
= L N ~
A . Se-quences are used instead of sets in order to match factors in two grammars. Let DFA denote the collection of finite sequences of DFAs.
Theorem 1 is well-known.
Theorem 1 Consider a finite setS of DFA. Then
L N
A∈SA
=T
A∈SL(A).
An important consequence of Theorem 1 is that some languages are exponentially more com-pactly represented by their factors. The grammar
~
A = hA1· · · Ani has P1≤i≤ncard(Qi) states, whereas the trimmed N ~
A can have as many as Q
1≤i≤ncard(Qi) ∈ Θ(max1≤i≤n(card(Qi))n) states. An example of such a language is given in Section 4, Figures 1 and 2.
2.1 Identification in the limit
A positive text T for a language L is a total function T : N → L ∪ {#} (# is a ‘pause’) such that range(T) = L (i.e., for every w ∈ L there is at least one n ∈ N for which w = T(n)). LetT[i]denote the initial finite sequence T(0), T(1). . . T(i−1). Let SEQ denote the set of all finite initial portions of all positive texts for
all possible languages. Thecontentof an element T[i]of SEQ is
content(T[i])def=
{w∈Σ∗ |(∃j ≤i−1)[T(j) =w]}.
In this paper, learning algorithms are programs: φ : SEQ → DFA. A learnerφidentifies in the limit from positive textsa collection of languages
Lif and only if for allL∈ L, for all positive texts T forL, there exists ann∈Nsuch that
(∀m≥n)[φ(T[m]) =φ(T[n])]andL(T[n]) =L
(see Gold (1967) and Jain et al. (1999)). A class of languages is ILPD iff it is identifiable in the limit by such a learner.
3 Classes of factorable-DFA languages
In this section, classes of factorable-DFA lan-guages are introduced. The notion of sub-DFA is central to this concept. Pictorially, a sub-DFA is obtained from a DFA by removing zero or more states, transitions, and/or revoking the final status of zero or more final states.
Definition 1 For any DFAA = (Q,Σ, Q0, F, δ),
a DFAA′ = (Q′,Σ′, Q0′, F′, δ′)issub-DFAofA, writtenA′ ⊑ A, if and only ifQ′ ⊆ Q,Σ ⊆Σ′,
Q′0 ⊆Q0,F′ ⊆F,δ′ ⊆δ.
The sub-DFA relation is extended to grammars (sequences of DFA). Let A~ = hA1· · · Ani and
~
A′ =hA′
1· · · A′ni.
ThenA~′ ⊑A ⇔~ (∀0≤i≤n)[A′i⊑ Ai]. Clearly, ifA′⊑ AthenL(A′)⊆L(A).
Every grammar A~ determines a class of lan-guages: those recognized by a sub-grammar ofA~. Our interest is not inL(A)~ , itself. Indeed, this will generally be Σ∗. Rather, our interest is in
identi-fying languages relative to the class of languages recognizable by sub-grammars ofA~.
Definition 2 LetG(A)~ def={B |~ B ⊑~ A}~ , the class of grammars that are sub-grammars ofA~.
LetL(A)~ def={L(B)~ |B ⊑~ A}~ , the class of lan-guages recognized by sub-grammars ofA~.
A class of languages is a factorable-DFA class iff it isL(A)~ for someA~.
to establish that the efficient general learning algo-rithm given by Heinz et al. (2012) can be applied to every class of factorable-DFA languages, and that this class includes many of the well-known sub-regular language classes as well as classes that are, in a particular sense, mixtures of these.
4 A motivating example
This section describes the Strictly 2-Piecewise lan-guages, which motivate the factorization that is at the heart of this analysis. Strictly Piecewise (SP) languages are characterized in Rogers et al. (2010) and are a special subclass of the Piecewise Testable languages (Simon, 1975).
Every SP language is the intersection of a finite set of complements of principal shuffle ideals:
L∈SP⇐⇒def L= \
w∈S
[SI(w)], Sfinite
where
SI(w)def={v∈Σ∗ |w=σ1· · ·σkand
(∃v0, . . . , vk∈Σ∗)[v=v0·σ1·v1· · ·σk·vk]}
Sov ∈ SI(w)iffwoccurs as a subsequence ofv and L ∈ SP iff there is a finite set of strings for which L includes all and only those strings that do not include those strings as subsequences. We say thatLisgeneratedbyS. It turns out that SP is exactly the class of languages that are closed under subsequence.
A language is SPkiff it is generated by a set of strings each of which is of length less than or equal tok. Clearly, every SP language is SPkfor some kand SP=S
1≤k∈N[SPk].
Ifw ∈ Σ∗ and |w| =k, then SI(w) = L(A
w) for a DFA Aw with no more than k states. For example, ifk = 2 andΣ = {a, b, c}and, hence, w∈ {a, b, c}2, then the minimal trim DFA recog-nizing SI(w)will be a sub-DFA (in which one of the transitions from theσ1state has been removed)
of one of the three DFA of Figure 1.
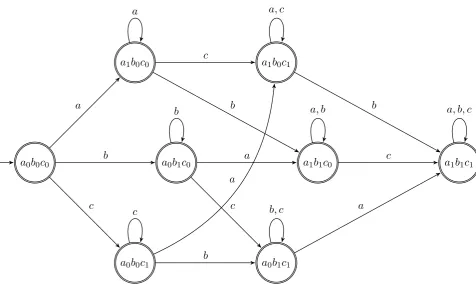
Figure 1 showsA~ = hAa, Ab, Aci, whereΣ =
{a, b, c} and each Aσ is a DFA accepting Σ∗ whose states distinguish whether σ has yet oc-curred. Figure 2 showsN ~
A.
Note that every SP2 language over{a, b, c} is
L(B)~ for some B ⊑~ A~. The class of grammars ofG(A)~ recognize a slight extension of SP2 over
{a, b, c} (which includes 1-Reverse Definite lan-guages as well).
Observe that 6 states are required to describeA~
but 8 states are required to describeN ~
A. LetA~Σ
be the sequence of DFA with one DFA for each letter in Σ, as in Figure 1. Ascard(Σ)increases the number of states of A~Σ is 2×card(Σ) but
the number of states in N ~
AΣ is 2card(Σ). The
number of states in the product, in this case, is ex-ponential in the number of its factors.
The Strictly 2-Piecewise languages are cur-rently the strongest computational characteriza-tion1 of long-distance phonotactic patterns in hu-man languages (Heinz, 2010). The size of the phonemic inventories2 in the world’s languages ranges from 11 to 140 (Maddieson, 1984). English has about 40, depending on the dialect. With an al-phabet of that sizeA~Σwould have 80 states, while
N ~
AΣ would have 240 ≈ 1×1012 states. The
fact that there are about 1011 neurons in human brains (Williams and Herrup, 1988) helps moti-vate interest in the more compact, parallel repre-sentation given byA~Σ as opposed to the singular
representation of the DFAN ~
AΣ.
5 Learning factorable classes of languages
In this section, classes of factorable-DFA lan-guages are shown to be analyzable as finite lattice spaces. By Theorem 6 of Heinz et al. (2012), ev-ery such class of languages can be identified in the limit from positive texts.
Definition 3 (Joins) Let
A = (Q,Σ, Q0, F, δ),
A1 = (Q1,Σ, Q01, F1, δ1) ⊑ A
and
A2 = (Q2,Σ, Q02, F2, δ2) ⊑ A.
ThejoinofA1andA2is
A1⊔A2
def
= (Q1∪Q2,Σ, Q01∪Q02, F1∪F2, δ1∪δ2).
Similarly, for all A~ = hA1· · · Ani and B~ =
hB1· · · Bni ⊑ A~,C~2 = hC1· · · Cni ⊑ A~, thejoin of andB~andC~isB ⊔~ C~def=hB1⊔ C1· · · Bn⊔ Cni. Note that the join of two sub-DFA of Ais also a sub-DFA ofA. SinceG(A)~ is finite, binary join suffices to define join of any set of sub-DFA of a given DFA (as iterated binary joins). LetF
[S]be the join ofS, a set of sub-DFAs of someA(orA~).
1
See Heinz et al. (2011) for competing characterizations.
2The mental representations of speech sounds are called
a0 a1 b0 b1 c0 c1
b, c
a
a, b, c a, c
b
a, b, c a, b
c
[image:4.595.80.557.382.666.2]a, b, c
Figure 1: The sequence of DFAA~ = hAa, Ab, Aci, where Σ = {a, b, c} and eachAσ acceptsΣ∗ and whose states distinguish whetherσhas yet occurred.
a0b0c0
a1b0c0
a0b1c0
a0b0c1
a1b1c0
a0b1c1
a1b0c1
a1b1c1
a
b
c
b c a
a
c b
a
b c
c a, b
a b, c
b a, c
a, b, c
Figure 2: The productN
Lemma 1 The set of sub-DFA of a DFA A, or-dered by⊑,({B | B ⊑ A},⊑), is an upper semi-lattice with the least upper bound of a set ofS sub-DFA ofAbeing their join.
Similarly the set of sub-grammars of a grammar ~
A, ordered again by⊑,({B ⊑~ A}~ ,⊑), is an upper semi-lattice with the least upper bound of a set of sub-grammars ofA~being their join.3
This follows from the fact thatQ1∪Q2(similarly
F1∪F2andδ1∪δ2) is the lub ofQ1andQ2(etc.)
in the lattice of sets ordered by subset.
5.1 Paths and Chisels
Definition 4 LetA= (Q,Σ,{q0}, F, δ)be a
non-empty DFA andw=σ0σ1· · ·σn ∈ Σ∗.
Ifδ(q0, w)↓, thepathofwinAis the sequence
π(A, w) def=
(q0, σ0), . . . ,(qn, σn),(qn+1, λ)
where(∀0≤i≤n)[qi+1=δ(qi, σi)]. Ifδ(q0, w)↑thenπ(A, w)↑.
Ifπ(A, w)↓, letQπ(A,w)denote set of states it
traverses,δπ(A,w)denote the the transitions it tra-verses, and letFπ(A,w) ={qn+1}.
Next, for any DFAA, and anyw ∈ L(A), we define thechiselofwgivenAto be the sub-DFA ofAthat exactly encompasses the path etched out inAbyw.
Definition 5 For any non-empty DFA A =
(Q,Σ,{q0}, F, δ)and allw ∈ Σ∗, ifw ∈ L(A), then thechiselofwgivenAis the sub-DFA
CA(w) = (Qπ(A,w),Σ,{q0}, Fπ(A,w), δπ(A,w)).
Ifw6∈L(A), thenCA(w) =A∅.
Consider anyA~ = hA1· · · Aniand any word w ∈ Σ∗. Thechisel of w given A~ is C
~
A(w) = hCA1(w)· · ·CAn(w)i.
Observe thatCA(w) ⊑ Afor all wordswand all
A, and thatCA(w)is trim.
Using the join, the domain of the chisel is ex-tended to sets of words: CA~(S) = Fw∈SCA~(w). Note that {CA~(w) | w ∈ Σ∗} is finite, since
{B |~ B ⊑~ A}~ is.
Theorem 2 For any grammar A~, let C(A) =~
{CA~(S) | S ⊆ Σ∗}. Then (C(A)~ ,⊑) is an up-per semi-lattice with the lub of two elements given by the join⊔.
3These are actually complete finite lattices, but we are
in-terested primarily in the joins.
Proof This follows immediately from the
finite-ness of{CA~(w)|w∈Σ∗}and Lemma 1.
Lemma 2 For all A = (Q,Σ, Q0, F, δ), there is
a finite setS ⊂ Σ∗such thatF
w∈SCA(w) =A. Similarly, for allA~=hA1· · · Ani, there is a finite setS ⊂Σ∗such thatC
~
A(S) =A~.
ProofIfAis empty, then clearlyS =∅suffices. Henceforth consider only nonemptyA.
For the first statement, letS be the set of uσv where, for each q ∈ Q and for each σ ∈ Σ, δ(q0, u)↓= q and δ(δ(q, σ), v)↓ ∈ F such that
uσvhas minimal length. By construction, S is fi-nite. Furthermore, for every state and every transi-tion inA, there is a word inSwhose path touches that state and transition. By definition of⊔it fol-lows thatCA(S) =A.
For proof of the second statement, for eachAi inA~, constructSias stated and take their union.
Heinz et al. (2012) define lattice spaces. For an upper semi-latticeV and a functionf : Σ∗ → V such thatf and⊔are (total) computable,(V, f)is called a Lattice Space (LS) iff, for each v ∈ V, there exists a finiteD⊆range(f)withF
D=v.
Theorem 3 For all grammars A~ = hA1· · · Ani,
(C(A)~ , CA~)is a lattice space.
ProofFor allA~′ ∈ C(A)~ , by Lemma 2, there is a finiteS⊆Σ∗ such thatF
w∈SCA~(w) =A~′.
For Heinz et al. (2012), elements of the lat-tice are grammars. Likewise, here, each grammar
~
A=hA1· · · Anidefines a lattice whose elements are its sub-grammars. Heinz et al. (2012) associate the languages of a grammar v in a lattice space
(V, f)with{w∈Σ∗ |f(w)⊑v}. This definition coincides with ours: for any element A~′ ofC(A)~
(noteA~′ ⊑A~), a wordwbelongs toL(A~′)if and
only if CA~(w) is a sub-DFA ofA~′. The class of languages of a LS is the collection of languages obtained by every element in the lattice. For ev-ery LS(C(A)~ , CA~), we now define a learnerφ ac-cording to the construction in Heinz et al. (2012):
∀T ∈SEQ, φ(T) =F
w∈content(T)CA~(w). Let L(C(A~),C~
A) denote the class of languages
i.e can compute the next hypothesis in polytime from the previous hypothesis alone, and opti-mal in the sense that no other learner converges more quickly on languages in L(C(A~),CG). In ad-dition, this learner is globally-consistent (every hypothesis covers the data seen so far), locally-conservative(the hypothesis never changes unless the current datum is not consistent with the cur-rent hypothesis), strongly-monotone (the current hypothesis is a superset of all prior hypotheses), andprudent(it never hypothesizes a language that is not in the target class). Formal definitions of these terms are given in Heinz et al. (2012) and can also be found elsewhere, e.g. Jain et al. (1999).
6 Complexity considerations
The space of sub-grammars of a given sequence of DFAs is necessarily finite and, thus, identifiable in the limit from positive data by a na¨ıve learner that simply enumerates the space of grammars. The lattice learning algorithm has better efficiency be-cause it works bottom-up, extending the grammar minimally, at each step, with the chisel of the cur-rent string of the text. The lattice learner never explores any part of the space of grammars that is not a sub-grammar of the correct one and, as it never moves down in the lattice, it will skip much of the space of grammars that are sub-grammars of the correct one. The space it explores will be mini-mal, given the text it is running on. Generalization is a result of the fact that in extending the gram-mar for a string the learner adds its entire Nerode equivalence class to the language.
The time complexity of either learning or recog-nition with the factored automata may actually be somewhat worse than the complexity of doing so with its product. Computing the chisel of a string w in the product machine of Figure 2 is Θ(|w|), while in the factored machine of Figure 1 one must compute the chisel in each factor and its complex-ity is, thus, Θ(|w|card(Σ)k−1). But Σand kare fixed for a given factorization, so this works out to be a constant factor.
Where the factorization makes a substantial dif-ference is in the number of features that must be learned. In the factored grammar of the example, the total number of states plus edges is Θ(kcard(Σ)k−1), while in its product it is
Θ(2(card(Σ)k−1)). This represents an exponential improvement in the space complexity of the fac-tored grammar.
Every DFA can be factored in many ways, but the factorizations do not necessarily provide an asymptotically significant improvement in space complexity. The canonical contrast is between sequences of automata hA1, . . . ,Ani that count modulo some sequence of mi ∈ N. If the mi are pairwise prime, the product will require Q
1≤i≤n[mi] = Θ((maxi[mi])n)states. If on the other hand, they are all multiples of each other it will require justΘ(maxi[mi]).
7 Examples
The fact that the class of SP2 languages is
effi-ciently identifiable in the limit from positive data is neither surprising or new. The obvious ap-proach to learning these languages simply accu-mulates the set of pairs of symbols that occur as subsequences of the strings in the text and builds a machine that accepts all and only those strings in which no other such pairs occur. This, in fact, is essentially what the lattice learner is doing.
What is significant is that the lattice learner pro-vides a general approach to learning any language class that can be captured by a factored grammar and, more importantly, any class of languages that are intersections of languages that are in classes that can be captured this way.
Factored grammars in which each factor recog-nizes Σ∗, as in the case of Figure 1, are of
par-ticular interest. Every sub-Star-Free class of lan-guages in which the parameters of the class (k, for example) are fixed can be factored in this way.4 If the parameters are not fixed and the class of lan-guages is not finite, none of these classes can be identified in the limit from positive data at all.5 So this approach is potentially useful at least for all sub-Star-Free classes. The learners for non-strict classes are practical, however, only for small val-ues of the parameters. So that leaves the Strictly Local SLk and Strictly Piecewise SPk languages as the obvious targets.
The SLk languages are those that are deter-mined by the substrings of length no greater than kthat occur within the string (including
endmark-4We conjecture that there is a parameterized class of
lan-guages that is equivalent to the Star-Free lanlan-guages, which would make that class learnable in this way as well.
5
ers). These can be factored on the basis of those substrings, just as the SPklanguages can, although the construction is somewhat more complex. (See the Knuth-Morris-Pratt algorithm (Knuth et al., 1977) for a way of doing this.) But SLkis a case in which there is no complexity advantage in factor-ing the DFA. This is because every SLk language is recognized by a DFA that is a Myhill graph: with a state for each string ofΣ<k(i.e., of length less than k). Such a graph has Θ(card(Σ)k−1)
states, asymptotically the same as the number of states in the factored grammar, which is actually marginally worse.
Therefore, factored SLk grammars are not, in themselves, interesting. But they are interesting as factors of other grammars. Let(SL+SP)k,l(resp.
(LT+SP)k,l, (SL+PT)k,l) be the class of lan-guages that are intersections of SLkand SPl(resp. LTk and SPl, SLk and PTl) languages. Where LT (PT) languages are determined by the set of substrings (subsequences) that occur in the string (see Rogers and Pullum (2011) and Rogers et al. (2010)).
These classes capture co-occurrence of lo-cal constraints (based on adjacency) and long-distance constraints (based on precedence). These are of particular interest in phonotactics, as they are linguistically well-motivated approaches to modeling phonotactics and they are sufficiently powerful to model most phonotactic patterns. The results of Heinz (2007) and Heinz (2010) strongly suggest that nearly all segmental patterns are
(SL+SP)k,lfor smallkandl. Moreover, roughly 72% of the stress patterns that are included in Heinz’s database (Heinz, 2009; Phonology Lab, 2012) of patterns that have been attested in nat-ural language can be modeled with SLkgrammars withk≤6. Of the rest, all but four are LT1+SP4
and all but two are LT2+SP4. Both of these last
two are properly regular (Wibel et al., in prep).
8 Conclusion
We have shown how subregular classes of lan-guages can be learned over factored representa-tions, which can be exponentially more compact than representations with a single DFA. Essen-tially, words in the data presentation are passed through each factor, “activating” the parts touched. This approach immediately allows one to natu-rally “mix” well-characterized learnable subreg-ular classes in such a way that the resulting
lan-guage class is also learnable. While this mixing is partly motivated by the different kinds of phono-tactic patterns in natural language, it also suggests a very interesting theoretical possibility. Specifi-cally, we anticipate that the right parameterization of these well-studied subregular classes will cover the class of star-free languages. Future work could also include extending the current analysis to fac-toring stochastic languages, perhaps in a way that connects with earlier research on factored HMMs (Ghahramani and Jordan, 1997).
Acknowledgments
This paper has benefited from the insightful com-ments of three anonymous reviewers, for which the authors are grateful. The authors also thank Jie Fu and Herbert G. Tanner for useful discus-sion. This research was supported by NSF grant 1035577 to the first author, and the work was com-pleted while the second author was on sabbatical at the Department of Linguistics and Cognitive Sci-ence at the University of Delaware.
References
Zoubin Ghahramani and Michael I. Jordan. 1997. Fac-torial hidden markov models. Machine Learning, 29(2):245–273.
E.M. Gold. 1967. Language identification in the limit.
Information and Control, 10:447–474.
Bruce Hayes. 2009. Introductory Phonology. Wiley-Blackwell.
Jeffrey Heinz, Chetan Rawal, and Herbert G. Tan-ner. 2011. Tier-based strictly local constraints for phonology. InProceedings of the 49th Annual Meet-ing of the Association for Computational LMeet-inguis- Linguis-tics, pages 58–64, Portland, Oregon, USA, June. As-sociation for Computational Linguistics.
Jeffrey Heinz, Anna Kasprzik, and Timo K¨otzing. 2012. Learning with lattice-structured hypothesis spaces. Theoretical Computer Science, 457:111– 127, October.
Jeffrey Heinz. 2007. The Inductive Learning of Phonotactic Patterns. Ph.D. thesis, University of California, Los Angeles.
Jeffrey Heinz. 2009. On the role of locality in learning stress patterns.Phonology, 26(2):303–351.
Sanjay Jain, Daniel Osherson, James S. Royer, and Arun Sharma. 1999. Systems That Learn: An In-troduction to Learning Theory (Learning, Develop-ment and Conceptual Change). The MIT Press, 2nd edition.
Donald Knuth, James H Morris, and Vaughn Pratt. 1977. Fast pattern matching in strings. SIAM Jour-nal on Computing, 6(2):323–350.
Ian Maddieson. 1984. Patterns of Sounds. Cambridge University Press, Cambridge, UK.
Robert McNaughton and Seymour Papert. 1971.
Counter-Free Automata. MIT Press.
UD Phonology Lab. 2012. UD phonology lab stress pattern database. http://phonology.
cogsci.udel.edu/dbs/stress. Accessed
December 2012.
James Rogers and Geoffrey Pullum. 2011. Aural pat-tern recognition experiments and the subregular hi-erarchy. Journal of Logic, Language and Informa-tion, 20:329–342.
James Rogers, Jeffrey Heinz, Gil Bailey, Matt Edlef-sen, Molly Visscher, David Wellcome, and Sean Wibel. 2010. On languages piecewise testable in the strict sense. In Christian Ebert, Gerhard J¨ager, and Jens Michaelis, editors, The Mathematics of Lan-guage, volume 6149 ofLecture Notes in Artifical In-telligence, pages 255–265. Springer.
James Rogers, Jeffrey Heinz, Margaret Fero, Jeremy Hurst, Dakotah Lambert, and Sean Wibel. to appear. Cognitive and sub-regular complexity. In Proceed-ings of the 17th Conference on Formal Grammar.
Imre Simon. 1975. Piecewise testable events. In
Automata Theory and Formal Languages: 2nd Grammatical Inference conference, pages 214–222, Berlin. Springer-Verlag.
Sean Wibel, James Rogers, and Jeffery Heinz. Factor-ing of stress patterns. In preparation.