Improving Statistical Machine Translation with a Multilingual Paraphrase Database
Full text
Figure

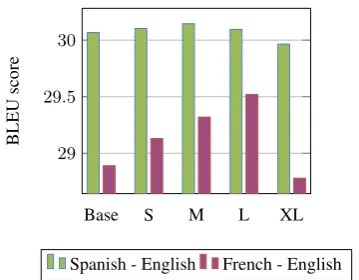


Related documents
The dominant practice of statistical machine translation (SMT) uses the same Chinese word segmentation specification in both alignment and translation rule induction steps
We build parallel FDA5 (ParFDA) Moses statistical machine translation (SMT) sys- tems for all language pairs in the workshop on statistical machine translation (Bojar et al.,
The system presented in this paper uses phrase-based statistical machine translation (SMT) techniques to directly transliterate be- tween all language pairs in this shared task..
Phrase tables trained on parallel corpora that were translated in the same direction as the translation task perform better than ones trained on corpora translated in the
In contrast to previous attempts at using para- phrases to improve Statistical Machine Translation, which require external data in the form of additional parallel bilingual
A statistical machine translation (SMT) model that uses hierarchical phrases (HPBT) that contain sub-phrases. The model is formally a synchronous context-free grammar but is
We build parallel FDA5 (ParFDA) Moses statistical machine translation (SMT) sys- tems for all language pairs in the workshop on statistical machine translation (Bojar et al.,
RQ1 In a domain-awareness scenario, how can we further improve the cur- rent domain adaptation method of an Statistical Machine Translation (SMT) by availing of the domain-likeness
