Evania Lina Fasya
Master of Science Human Media Interaction
Graduation committee: dr. Mari¨et Theune (1st supervisor) dr.ir. Rieks op den Akker (2nd supervisor)
ABSTRACT
Alice, a virtual human that is created based on the ARIA-VALUSPA framework, is a representation of the main character from a classic novel Alice’s Adventures in Wonderland. Alice needs the domain knowledge of the Alice in Wonderland story in order to talk about the story with its users. However, the current domain knowledge of Alice is still created manually, and it can be difficult to create more virtual humans in other domains or to extend the knowledge of Alice.
This research aims to prepare the domain knowledge of Alice in a more automated process by developing an automatic question generation system. The system is called Alice Question Generation (AQG) and it makes use of two semantic tasks; Semantic Role Labeling (SRL) and Stanford Dependency. The main task of the AQG system is to generate questions and answers (QAs) about Alice in Wonderland. The generated QAs will be stored in the QAMatcher, which is a tool that stores the domain knowledge of Alice in a QA pair format. The QAMatcher works by matching a user’s question with a number of prepared questions using text processing algorithms, and then gives the answer that is linked to the matched question.
ACKNOWLEDGMENTS
The author would like to thank dr. Mari¨et Theune for all the reviews and feedbacks that enable the thoughtful and critical discussion from the research topic until the final project; dr.ir. Rieks op den Akker for the feedback on the final project and the inspiration about natural language processing; and Jelte van Waterschoot for the update on ARIA-VALUSPA project and the discussion about retrieving information from a narrative.
The author would also like to thank the Ministry of Communication and Informatics of Indonesia for granting a scholarship in Human Media Interaction at the University of Twente and giving the chance of pursuing the master education based on the author’s passion and competence.
TABLE OF CONTENTS
Page
ABSTRACT . . . ii
1 Introduction . . . 1
2 Conversational Agents . . . 3
2.1 Dialogue Systems . . . 3
2.2 Virtual Humans. . . 5
2.3 Dialogue Management . . . 7
2.3.1 Finite-State . . . 7
2.3.2 Form-based . . . 7
2.3.3 Information-State . . . 8
2.3.4 Plan-Based . . . 9
3 ARIA-VALUSPA . . . 12
3.1 The Dialogue Manager of Alice . . . 12
3.2 The Domain Knowledge of Alice . . . 14
4 Question Generation . . . 15
4.1 Implementation of Question Generation . . . 15
4.2 Approaches in Question Generation. . . 17
4.2.1 Heilman and Smith. . . 17
4.2.2 Mazidi and Nielsen . . . 19
4.3 Discussion . . . 24
5 Alice Question Generation . . . 26
5.1 Pattern Observation . . . 28
5.2 Template Creation . . . 31
6 Initial Evaluation and Improvement . . . 36
6.1 Pre-Initial Evaluation . . . 36
Page
6.3 Error Analysis and Template Improvement . . . 39
6.3.1 MADV . . . 39
6.3.2 MMNR . . . 41
6.3.3 MLOC. . . 43
6.3.4 MTMP . . . 44
6.3.5 ARGU . . . 46
6.3.6 DCNJ . . . 47
6.4 Evaluation After Template Improvements . . . 49
7 User Evaluation of Alice Question Generation . . . 51
7.1 Evaluation Measurement . . . 51
7.2 Evaluation Setup . . . 52
7.3 Error Analysis and Template Improvement . . . 53
7.3.1 MADV . . . 54
7.3.2 MMNR . . . 55
7.3.3 MLOC. . . 56
7.3.4 MTMP . . . 57
7.3.5 ARGU . . . 58
7.3.6 DCNJ . . . 59
8 User Study using QA Matcher. . . 61
8.1 Preparing the QAMatcher . . . 61
8.1.1 Follow-Up Question Strategy . . . 61
8.1.2 Risks on the Follow-Up Question Strategy . . . 63
8.1.3 Pilot Evaluation . . . 65
8.1.4 Improvement . . . 68
8.2 User Study Setup . . . 69
8.3 User Study Result and Discussion. . . 70
8.3.1 Result from the First Evaluator. . . 71
8.3.2 Result from the Second Evaluator . . . 73
8.3.3 Result from the Third Evaluator . . . 76
Page
8.4 User Study Conclusion . . . 79
9 Conclusion and Future Work . . . 81
9.1 Summary . . . 81
9.2 Conclusion and Future Work . . . 83
9.2.1 Automatic Question Generation for Virtual Humans . . . 83
9.2.2 User Study using QA Matcher . . . 85
REFERENCES . . . 87
A Appendix: Alice Question Generation . . . 90
B Appendix: User Evaluation . . . 96
1. INTRODUCTION
ARIA-VALUSPA, an abbreviation for the Artificial Retrieval of Information Assistants Virtual Humans with Linguistic Understanding, Social skills, and Personalized Aspects, is a project of the Horizon 2020 research programme of the European Union. The project intends to create a framework of virtual humans which are capable of conducting multimodal interaction with their users in challenging situations, such as facing an interruption, or reacting appropriately according to emotion and gesture changes. One virtual human that is being developed is called Alice, representing the main character of the classic novel written by Lewis Carroll, Alice’s Adventures in Wonderland. There are several work packages that are involved in the ARIA-VALUSPA project. But the specific work package that is being carried out at the University of Twente is called Multi-Modal Dialogue Management for Information Retrieval.
There are some challenges in developing multi-modal dialogue management for informa-tion retrieval. One of them is preparing the domain knowledge for the virtual human. As the representation of the character Alice in the story of Alice in Wonderland, the virtual human - Alice - needs to have the domain knowledge of the story. However, the current domain knowledge for Alice is still created manually, and it can be difficult to create more virtual humans in other domains or to extend the knowledge of Alice (e.g. extending the knowledge from only knowing the story of the novel into knowing the story of the writer).
There are two other approaches that were considered to prepare the knowledge of Alice. The first one is collecting question and answer pairs from the internet. The benefit of this approach is that the questions from the internet are usually asked by real people. Implementing this approach allows Alice to have some insights of what kind of Alice-in-Wonderland-questions do people in general are curious about. The second approach is question answering. Question answering lets the virtual human search the answer of a question directly in a resource that is made available through a prepared “knowledge base” [1].
The automatic question generation approach is finally chosen because the developing time is reasonable compared to question answering approach. In addition to that, it can be easily adapted for other virtual humans in other domains, compared to collecting question and answer pairs from the internet which require more manual process.
As a virtual human that is based on the ARIA-VALUSPA framework, Alice is expected to be able to respond accordingly to the users in challenging situations, such as asking for a confirmation when Alice could not hear the user well. This research, however, only explores the domain knowledge of Alice, which is the story of Alice in Wonderland. Therefore, the other conversation elements such as handling interruptions, greetings, etc., are not the focus of this research.
2. CONVERSATIONAL AGENTS
A conversational agent is a system that can communicate with its users by understanding spoken or textual language. Most conversational agents in the beginning of 2000s, however, are intended to communicate through speech rather than text, and so they are also known as spoken dialogue system [2]. Similar with spoken dialogue systems, virtual humans are also a type of conversational agents. Virtual humans are able to carry a conversation with their users through speech like spoken dialogue systems. However, a noticeable difference of spoken dialogue systems and virtual humans is that virtual humans have visual represen-tations. These visualizations are expected to be able to generate nonverbal behaviors just like real humans.
Dialogue systems and virtual humans are described in more detail in section 2.1 and section 2.2 below. Furthermore, a specific component of conversational agents, dialogue manager, is described separately in section 2.3 because the dialogue manager component is related with the focus of this research.
2.1 Dialogue Systems
A dialogue system is a computer system that is able to have a conversation with humans. One implementation of dialogue systems is spoken dialogue systems used in commercial applications such as travel arrangement system and call routing. How May I Help You [3] is an example of a spoken dialogue system whose task is automatically routing telephone calls based on a user’s spoken response to the question “How may I help you?”. Figure 2.1 shows an example of a conversation between a user and the How May I Help You (HMIHY) system [3].
System : How may I help you?
User : Can you tell me how much it is to Tokyo? System : You want to know the cost of a call? User : Yes, that’s right.
System : Please hold on for rate information.
Fig. 2.1.: A conversation between a user and the HMIHY system [3]
Fig. 2.2.: An architecture of the components of a spoken dialogue system [2]
2.2 Virtual Humans
Virtual humans are different from spoken dialogue systems because virtual humans have visualizations, such as a body or a face. Beside of that, virtual humans that are created based on the ARIA-VALUSPA framework are not only expected to understand the spoken and written language, but also expected to understand nonverbal human behaviors.
Because of their human likeness, virtual humans can be used to train real human’s social skills when facing stressful situations by simulating the scenario in a safe virtual world. An example of this implementation is Mission Rehearsal Exercise system [4] which trains the user’s leadership skills in a warzone. Virtual humans can also be implemented in museums to increase the interest and engagement of the visitors (e.g. Ada and Grace [5]); or to do interviews with patients for healthcare support (e.g. Ellie [6]).
[image:11.612.153.493.383.606.2]The architecture of a virtual human is more complex than the typical architecture of spoken dialogue systems because it involves more modules such as nonverbal behavior understanding and nonverbal behavior generation.
Fig. 2.3.: Virtual Human Architecture [7]
in figure 2.3, the virtual human architecture also involves Audio-Visual Sensing, Nonverbal Behavior Understanding, Nonverbal Behavior Generation, and Behavior Realization.
When a human user talks to the virtual human, his speech is transformed into a tex-tual representation by the Speech Recognition module. The text is then translated into semantic representation by the Natural Language Understanding module. This process is similar to the spoken dialogue system’s process except that the human user’s expression and nonverbal communication are also recognized by the Audio-Visual Sensing module in the virtual human. The Nonverbal Behavior Understanding module takes the information from the Audio-Visual Sensing module and links certain observations to higher-level nonverbal communicative behaviors (e.g. attention value, head position). Based on the nonverbal communicative behavior values and the semantic representation of the speech, the Dialogue Manager replies back with the most appropriate response. The Dialogue Manager, which is labeled as the Agent in [7], manages all the dialogues, similar to the Dialogue Manager module in the spoken dialogue system architecture 2.2. The responses from the dialogue manager are sent to the Natural Language Generation and Nonverbal Behavior Generation so that they can generate the appropriate response using speech and behavior. The response can be produced by the Speech Generation module using text-to-speech or pre-recorded au-dio. The Behavior Realization module synchronizes all behaviors such as speech, gestures, and facial expressions, and gives them for a renderer to show.
2.3 Dialogue Management
Dialogue Management is a task which is carried out after the behavior understanding and the natural language understanding tasks. The tasks of a Dialogue Manager are to take the semantic representation of words from the NLU module and the output from the Nonverbal Behavior Understanding module, manage the dialogues, and give back the appropriate response to the verbal/nonverbal generation modules. There are different types of dialogue managers based on the goal of the conversational agents. The common dialogue managers can be separated into four types [2] as follows.
2.3.1 Finite-State
Finite-state is the simplest architecture where the system completely controls the con-versation with the user. It asks the user a series of questions, ignoring anything that is not a direct answer to the question and then going on to the next question. For example, the system will always ask the question “What city are you leaving from?” until the system recognizes a city name from the user’s response, and then the system continues to the next question. Figure 2.4 illustrates a simple finite-state automation architecture of a dialogue manager in a spoken dialogue system [2].
2.3.2 Form-based
Fig. 2.4.: A simple finite-state automation architecture [2]
Table 2.1.: Example of slots and questions in a form-based dialogue manager
Slot Question
ORIGIN CITY “What city are you leaving from?” DEPARTURE DATE “Which date do you want to leave?” DESTINATION CITY “Where are you going?”
ARRIVAL TIME “When do you want to arrive?”
2.3.3 Information-State
the information-state architecture is able to decide whether the user has asked a question, made a suggestion, or accepted a suggestion. This architecture thus can be more useful than just form-filling applications that are usually the implementation of the finite-state and form-based architecture. An information-state based dialogue management can assign tags to the dialogues, for example, a response “Hello” can be interpreted as a greeting, thus it can be tagged with the attribute GREET. Another example, a response “There is one flight in the morning at 9.15” can be tagged with the attribute SUGGEST. Table 2.2 illustrates some dialogue acts in an information-state based architecture adapted from [2].
Table 2.2.: Some dialogue acts used in an information-state based dialogue manager called Verbmobil-1
Tag Example
GREET Hello Ron
INTRODUCE It’s me again
REQUEST-COMMENT How does that look?
SUGGEST From thirteenth through seventeenth June
ACCEPT Saturday sounds fine
2.3.4 Plan-Based
Plan-based dialogue management is also a more sophisticated architecture compared to the finite-state and form-based. The plan-based model allows the system to know the underlying intention of utterances. The model can be further explained using the dialogues in Figure 2.5.
U1 I need to travel in May.
S1 And, what day in May do you want to travel?
U2 OK uh I need to be there for a meeting that’s from the 12th to the 15th. S2 And you’re flying into what city?
U3 Seattle.
S3 And what time would you like to leave Pittsburgh? U4 Uh hmm I don’t think there’s many options for non-stop. S4 Right. There’s three non-stops today.
U5 What are they?
S5 The first one departs from Pittsburgh Airport at 10:00am, arrives at Seattle Airport at 12:05 their time. The second flight departs from Pittsburgh Airport at 5:55pm, arrives at Seattle Airport at 8pm. And the last flight departs from Pittsburgh Airport at 5:55pm, arrives at Seattle Airport at 10:28pm.
U6 OK I’ll take the 5ish flight on the night before on the 11th.
S6 On the 11th? OK. Departing at 5:55pm arrives at Seattle Airport at 8pm, U.S. Air flight 115.
U7 OK.
Fig. 2.5.: A discourse example from a telephone conversation between a user (U) and a travel agent system (S)
satisfaction-precedes DSP2, it means that DSP1 must be satisfied before DSP2. Therefore, the structure of the discourse in Figure 2.5 can be summarized in Figure 2.6.
The explanation of Figure 2.6 is as follows: 1. DSP1: Intend U (S finds a flight for U)
Fig. 2.6.: The discourse structure of the discourse in Figure 2.5.
5. DSP5: Intend U (S finds a nonstop flight for U)
Since DS2 - DS5 are all subordinate to DS1, Figure 2.5 can be reflected in the dominance relationship: DS1 dominates DS2 Λ DS1 dominates DS3 Λ DS1 dominates DS4 Λ DS1 dominates DS5. Moreover, since DS2 and DS3 need to be satisfied before DS5, thus they can be reflected in the satisfaction-precedence relationship: DS2 satisfaction-precedes DS5 Λ DS3 satisfaction-precedes DS5.
3. ARIA-VALUSPA
ARIA-VALUSPA is a project that intends to develop a framework of virtual humans that allows a robust interaction between a virtual human and a user in the most natural way. As described in the beginning of the introduction, Alice is one virtual human that is de-veloped based on the ARIA-VALUSPA framework. The architecture of Alice is based on the common virtual human architecture described in section 2.2. Alice has an Audio-Visual Sensing and Speech Recognition module, as well as the Nonverbal Behavior Understanding and Natural Language Understanding. Alice also has the Natural Language Generation, Speech Generation, Nonverbal Behavior Generation, and the Behavior Realization. The focus on each module is to create the most natural interaction as possible by considering some common elements in a conversation such as facial expressions of emotions, gestures, interruption, etc.
The focus of this research topic is, however, the knowledge of Alice - which is more related to the Dialogue Manager in the architecture. In section 3.1, the current state of the Alice’s Dialogue Manager is described. Furthermore, an overview of Alice’s domain knowledge is discussed in section 3.2.
3.1 The Dialogue Manager of Alice
Alice is developed using the information-state based architecture dialogue manager [9]. As described in section 2.3, an information-state based architecture allows Alice to interpret the intent of the utterance. For example, when a user asks “What do you think of the Mad Hatter?”, Alice categorizes this utterance as intent “setQuestion”. Alice assigns an intent based on some rules (e.g. assign setQuestion intent if the utterance consists of the word “think”,“Mad”, and “Hatter”). By having these categories, Alice can respond appropriately to an utterance by an intent “inform”, for example.
These templates are called FML templates [9]. When a response has been decided, Flipper sends a the response to the Behavioral Generation. Besides the nonverbal behavior han-dling, an extension of Flipper has been developed to enable Alice to handle dialogues. The dialogue handling and the nonverbal behavior handling can be processed simultaneously. The complete overview of Alice’s dialogue manager is shown in Figure 3.1.
Fig. 3.1.: The overview of Alice’s Dialogue Manager [9]
The scope of the Dialogue Manager is marked with the dashed outline. It takes the output from middleware, such as the output from Social Signal Interpretation (SSI) module [11] that is used by Alice to understand the user’s behavior. The Dialogue Manager also sends a user utterance to the Pre-Processing Module and takes the output which consists of the intent of an utterance, such as “setQuestion”.
Information State to the Behavioral Planner, as well as receiving feedback of whether the response has been delivered successfully to the user. The Turn Manager module manages the turns in the dialogue. For example, when the user speaks the turn is marked as “user” while when Alice speaks, the turn is marked as “Alice”. The system also notices when the user has been silent for a while, then the turn will be changed to Alice. The Discourse/Intent Manager takes the intent from a user’s utterance and return an appropriate agent’s intent. The discourse part specifies the phase of the discourse, such as opening phase, information retrieval phase, or closing phase. The FML Manager decides the most appropriate FML template from the agent’s intent that has been returned by Discourse/Intent Manager mod-ule. FML template consists of parameters such as subjects, objects, or emotions. Finally, the Domain Knowledge is retrieved by the Discourse/Intent Manager based on the current intent. For example, when the intent is asking an information about the white rabbit, the returned information from the Domain Knowledge is “The white rabbit is a strange rabbit with a watch inside his waistcoat-pocket”.
3.2 The Domain Knowledge of Alice
The domain knowledge of Alice is stored in a system called QAMatcher and is formed in a question and answer pair format. When a user asks a question to Alice, the QAMatcher matches the user’s question with a list of questions by using a text processing algorithm. When a matched question has been found, the answer to the matched question is returned back to the user. The question and answer pairs are prepared before-hand and are stored in the QAMatcher’s resource directory. Automatic question generation is the approach that is used to prepare these question and answer pairs in the QAMatcher.
4. QUESTION GENERATION
Automatic question generation, or more simply known as question generation, is an activity that takes a text resource as an input and generates possible questions (and answers) that can be asked from the resource. This approach allows the generation of the questions and answers that can be used in the QAMatcher.
Recent research shows that there are several applications of a question generation sys-tem, such as education, social media security, and conversational agent. These applications are explained in more detail in section 4.1. Despite the application of question generation systems, a question generation system can be developed using several approaches. The common approaches are explained in section 4.2. The discussion of the implementation of a question generation system and what approach can it be developed for Alice is provided in section 4.3.
4.1 Implementation of Question Generation
Many question generation (QG) systems are used in educational applications, such as skill development assessment and knowledge assessment [13]. G-Asks is an example of QG implementation in skill development assessments [14]. G-Asks generates trigger questions that can support students to learn through writing. For example, students are encouraged to learn varied opinions from other research. However, when a student cite an opinion from other research in his own writing, a new follow-up question can be formed from this citation, such as “Which statements of the other research that form this opinion?”. G-Asks is able to generate this “evidence support” type of question to support the academic writing.
Another QG system that is developed for knowledge assessment was conducted by Mazidi and Nielsen [19]. They managed to construct deeper questions than factoid questions and outperformed the result from Heilman and Smith.
Besides the common applications of QG in educational applications, QG can also be used in the social media security domain. For example, getting personal information from a user’s social media account, and generate questions from it [20]. The questions then are asked back to the user for authentication when a user forgets his password.
A research of QG that is done in a conversational agent domain was conducted by Yao et al. [1]. They used two QG tools to create question and answer pairs to be used as the knowledge base for a conversational character that can communicate with real humans. They used 14 Wikipedia articles as the topic and the question and answer pairs that have been generated from the tools are then stored in question and answer matching tool called NPCEditor [21]. The first QG tool that they used is the QG system that was developed by Heilman and Smith [15]. The second tool that they used is called OpenAryhpe which was developed by Yao et al. themselves based on a Question Answering framework called OpenEphyra [22]. The difference between OpenAryhpe and the Question Transducer is that OpenAryhpe expands some components so that the tool can recognize new synonyms and is able to recognize time, distance, and measurement more precisely.
4.2 Approaches in Question Generation
The recent approaches in question generation (QG) are varied based on the Natural Language Processing (NLP) tools available to the researchers [23]. However, the direction of the approaches can be classified into two categories, syntactic or semantic [19]. Syntactic approach explores the use of syntactic tools such as Stanford Parser and Tregex and uses them as the foundation of its QG system. On the other hand, the semantic approach explores the semantic tools such as Stanford Dependency and Semantic Role Labels (SRL) as the foundation of its QG system. Either approach that is implemented as the foundation of the QG system, however, does not limit the system to make use the opposite approach. For example, a QG system that uses syntactic tools as its foundation can still make use of semantic tools to make the QG system perform better. The syntactic and the semantic approaches are explained in more detail in this section using two prior research from Heilman and Smith, and Mazidi and Nielsen.
4.2.1 Heilman and Smith
The QG research of Heilman and Smith [15] [16] [17] can represent the syntactic ap-proach. There are several syntactic tools that Heilman and Smith used for their QG system. For example, they used Stanford Phrase Structure Parser to automatically sentence-split, tokenize, and parse input texts resulting in a Penn Treebank structure (e.g. Alice = NNP, watched = VBD, the = DT, white = NNP, rabbit = NNP). They also used the Tregex tree searching language to identify the syntactic elements of the sentence (e.g. subject and object of the sentence). They used Supersense Tagger to generate the answer phrase mainly for who, what, and where types of question (e.g. Alice = PERSON, garden = LOCATION). Heilman and Smith made use of syntactic tools as their main tools for the QG system. However, they also used a semantic-related tool called the Supersense Tagger to generate higher level semantic tags.
1. Transformations of Declarative Input Sentences 2. Question Creation
3. Question Ranking
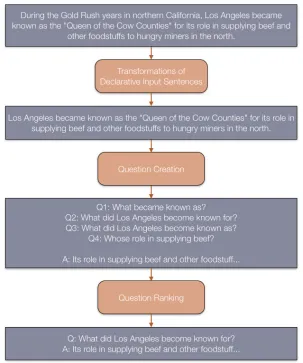
Fig. 4.1.: Steps in the QG System of Heilman and Smith [16] summarized in [18]
Figure 4.2 shows an example of a simplified sentence taken from [18]. In Figure 4.2, the sentence is simplified by removing the discourse marker “however” and the relative clause “which restricted trade with Europe.”
Original Sentence:
However, Jefferson did not believe the Embargo Act, which restricted trade with Europe, would hurt the American economy.
Simplified Sentence:
Jefferson did not believe the Embargo Act would hurt the American economy. Fig. 4.2.: Example of a simplified sentence
The second step in the QG System of Heilman and Smith is Question Creation. The summary of the question creation phase is shown in Figure 4.3.
1. Marking unmovable phrases
2. Generating possible question phrases 3. Decomposition of the main verb 4. Subject-auxiliary inversion
5. Removing answers and inserting question phrases 6. Post processing
Fig. 4.3.: The question creation phase of Heilman and Smith [16] summarized in [18]
<< PP=unmv to mark prepositional phrases that are nested within other prepositional phrases. Thus, from a sentence “Alice saw the rabbit in the room of hats,” the question “What did Alice see the rabbit in the room of?” can be avoided because “the room of hats” cannot be separated. Another example of the rule is NP $ VP << PP=unmv to mark prepositional phrases in subjects. Thus, from a sentence “The capital of Germany is Berlin,” the question “What is the capital of Berlin?” can be avoided and instead, the question “What is the capital of Germany?” can be created.
In generating the possible question phrase step, 6 conditions were used to create WH questions (e.g. to create “Where” question, the object of the must be tagged as noun.location with any of the preposition: on, in, at, over, to). The next step, decomposition of the main verb, has several purposes, such as to identify the main clause for subject-auxiliary in-version, and to identify the main verb so that the system can decompose a do or a does form followed by the base form of the verb. The fourth step, subject-auxiliary inversion, is done to generate yes-no questions (e.g. Does Alice like the rabbit?) or when the answer phrase is a non-subject noun phrase (e.g. Who likes the rabbit?) from the sentence “Alice likes the rabbit.” In the fifth step, a selected answer phrase is removed and each possible question phrase is inserted into a separate tree. Finally, a post processing step is done to ensure proper formatting such as changing sentences’ final periods with question marks, and removing extra white space).
Finally, they included question ranking as the last step in the QG system. They used statistical ranking to the candidates and generate questions with higher ranks. The ranking was done by learning a training set which were prepared by 15 native English-speaking university students.
Figure 4.4 shows the overall process by using a sentence from a Wikipedia article about the history of Los Angeles [18].
4.2.2 Mazidi and Nielsen
Fig. 4.4.: An example of a generated question and answer pair from the QG system of Heilman and Smith.
simplifies a sentence into several clauses and produces the SRL that identify patterns in the source text.
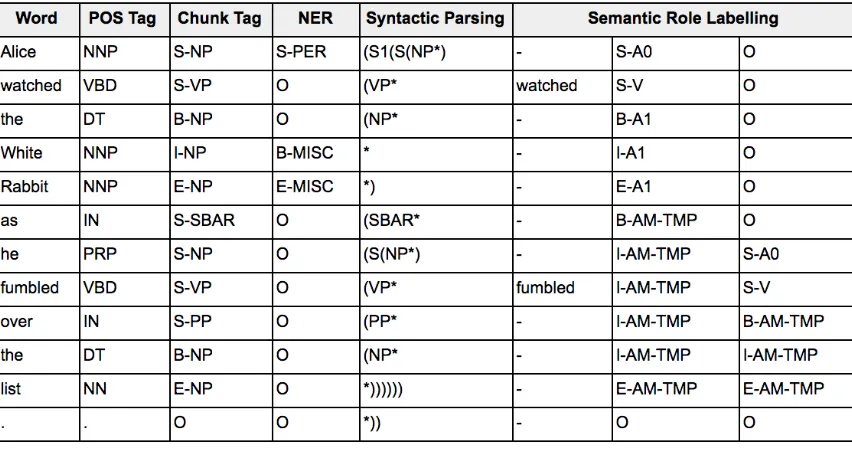
Besides providing the SRL, SENNA is able to provide POS tagging, chunking, Named Entity Recognition (NER), and syntactic parsing. Figure 4.5 shows the result of SENNA by using a sentence taken from Alice’s Adventures in Wonderland chapter 9: “Alice watched the White Rabbit as he fumbled over the list.”
The first column shown in figure 19 represents each word in the input, while the second column consists of the Penn Treebank POS tagset [25] of each word:
Fig. 4.5.: The result of POS tagging, chunking, NER, SRL, and syntactic parsing from SENNA
VBD: Verb, past tense. DT: Determiner.
IN: Preposition or subordinating conjunction. PRP: Personal pronoun.
NN: Noun, singular or mass.
The third column consists of the chunk tag based on Penn Treebank syntactic tagset [25] with four different prefixes which mark the word position in the segment:
NP: Noun Phrase. VP: Verb Phrase.
SBAR: Clause introduced by a (possibly empty) subordinating conjunction. B: beginning.
I: intermediate. E: ending.
O: not a member of a chunk.
The fourth column consists of the NER tags - persons, locations, organizations and names of miscellaneous entities - which is assigned on each recognizable named entity. The NER tags also use similar prefixes with the chunk tags to mark the position of the word in the NER phrase. The fifth column consists of the representation of the treebank annota-tion of the word in the tree. The sixth, seventh, and eighth columns represent sequentially the verb (predicate) of the sentence, and then the predicate-argument structures for each sentence that can be found in the input. The SRL also use similar prefixes with the chunk tags and the NER tags. The predicates in the sentence are labeled as V and the arguments are labeled as A with numbers according to PropBank Frames scheme [26]:
V: verb
A0: agents/causers
A1: patient (the argument which is affected by the action) AM-TMP: temporal markers
For the question generation process, Mazidi and Nielsen [24] prepared 42 patterns which were based on the PropBank Frames scheme [26]. An example of a pattern that is taken from [26] is shown in Figure 4.6.
Rel: like Arg0: you
Arg1: [?T?] ->What
Fig. 4.6.: A Propbank annotation for a WH-phrase
In the work of Mazidi and Nielsen [24], they prepared a matcher function to match the source sentence’s predicate-argument structure - that was previously produced by SENNA - with the list of prepared patterns. Then, they generate questions based on these matched patterns by restructuring the patterns.
[image:29.612.197.448.243.486.2]In 2015, Mazidi and Nielsen updated their question generation system by combining multiple views of different parsers [23]. The updates involved dependency parsing, SRL, and discourse cues. In order to give a better sense of dependency parsing, an example of a dependency parsing tree is shown in Figure [27].
Fig. 4.7.: A dependency parsing tree from the sentence “Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas” taken from [27].
In their updated system, Mazidi and Nielsen [23] generate the dependency of the source text using the Stanford Parser [27]. They also generate the SRL using SENNA. The results from both the dependency parser and the SRL are then combined.
nsubj(watched-2, Alice-1) root(ROOT-0, watched-2) det(Rabbit-5, the-3)
compound(Rabbit-5, White-4) dobj(watched-2, Rabbit-5) mark(fumbled-8, as-6) nsubj(fumbled-8, he-7) advcl(watched-2, fumbled-8) case(list-11, over-9)
det(list-11, the-10)
[image:30.612.244.404.70.297.2]nmod:over(fumbled-8, list-11)
Fig. 4.8.: The dependency parsing result of “Alice watched the White Rabbit as he fumbled over the list.” using Stanford Parser
outperform their previous question generation system by involving the dependency parsing with 21% more semantically-oriented questions versus factoid questions.
4.3 Discussion
Although the initial research on QG focused on the educational or teaching area, recent research has proved that QG can be used for other domains, including the conversational character or virtual human. It can save a lot of time to fill in the domain knowledge for the virtual human rather than manually creating question and answer pairs. It is also good for ARIA-VALUSPA project especially because there are more than one virtual humans that can be developed based on the ARIA-VALUSPA framework. Therefore, a faster and automated process in filling in the domain knowledge is desirable.
the information that is provided in the source text. Therefore questions about something that is not in the source text, even if it is still related to the story of Alice in Wonderland, might not be covered using this approach.
Another thing that needs to be considered when using QG is that the generated questions can be too specific. For example: “she soon made out that it was only a mouse that had slipped in like herself”. A possible generated question from this sentence could be “What did Alice find that slipped in like herself?”. For a user to ask this question, he must have a knowledge that Alice is trapped somewhere with someone else.
5. ALICE QUESTION GENERATION
Alice Question Generation (AQG) is a question generation (QG) system that is developed to generate question and answer pairs about Alice in Wonderland. The generated QA pairs are intended to be stored in the QAMatcher tool (see section 3.2) that can match the stored questions with the questions from the users when they talk with Alice the virtual human. AQG carries the semantic views of text as the main approach for developing the algorithm. However, it also applies the syntactic views to improve the quality of the generated QA pairs. Combining multiple views of text is proven to reduce the error rate of the generated questions [23].
AQG uses semantic role label (SRL) as the main tool to retrieve the semantic meaning of Alice in Wonderland story. SRL is used as the semantic tool because it provides enough information for a sentence to be altered into questions by parsing a sentence into a predicate-argument structure [26]. SENNA is used to retrieve the SRL because the tool can be used easily and it assigns the labels quickly for a number of sentences.
Besides SRL, Stanford Dependency is also used to retrieve the semantic meaning of Alice in Wonderland story. Stanford Dependency is used because it keeps a sentence as a whole without dividing it into clauses, which helps to keep the complete information in a sentence. PyStanfordDependencies is the Stanford Dependency tool that is used for the AQG system. PyStanfordDependencies is used because the library is written in Python, which is the same language as the AQG system, and it is simple enough to be processed by the AQG system.
process, AQG takes the SENNA “output” file and adds the “Semantic Representation” file with the SRL result.
[image:33.612.132.515.246.534.2]Next, AQG runs the “Template Matching” function which matches the “Semantic Rep-resentation” with a number of QA templates. The QA templates are created based on the observation of SRL, which is the main tool that is used as the foundation of AQG. A QA pair is produced every time there is a matching template and is stored in an XML file called “Generated QA”. The process of observing the patterns and creating the templates are explained in more detail in the rest of this chapter.
5.1 Pattern Observation
The QA templates in AQG are created based on two pattern considerations [28]: the fre-quency of the pattern occurrences and the consistency of the semantic information conveyed by the pattern across different instances.
Since SRL is used as the main tool to retrieve the semantic meaning of the input, the pattern observation is based on the SRL result. SRL parses a sentence into a predicate-argument structure with consistent predicate-argument labels. For example, “the rabbit” is labeled as Arg1 both in “Alice calls the rabbit” and in “The rabbit is called”. It also gives labels to all modifiers of the verb, such as temporal (TMP) and locative (LOC).
SENNA [29] is used to determine the SRL of the text input. SENNA divides a sentence into one or more clauses. For example, SENNA divides the sentence “While she is tiny, she slips and falls into a pool of water.” into two clauses (see Figure 5.2). The pattern of the first clause “While she is tiny, she slips into a pool of water” is TMP-A1-V-A3, and the pattern of the second clause “While she is tiny, she falls into a pool of water” is TMP-A1-V-A4.
Fig. 5.2.: SRL Representations for “While she is tiny, she slips and falls into a pool of water.”
as the training data. The first summary is from GradeSaver1 and it has 47 sentences, while the second summary is from SparkNotes2 and it has 56 sentences.
[image:35.612.113.540.329.634.2]A pattern in a clause always has a verb (V) and at least an argument. The argument can either be a basic argument (Arg, e.g. A0, A1, A2) or a modifier argument (ArgM, e.g. TMP, LOC). Almost all of the clauses in the training data have a V and an Arg; there is only one clause that has a V and an ArgM, without an Arg. Therefore, the algorithm does not include a pattern that has no Arg because it is not frequent. The number of Arg can be one (e.g. only an A0), two (e.g. an A0 and an A1), or even more. In summary, Table 5.1 shows the number of clauses within three conditions of the Arg (Arg>=2, Arg==1, Arg==0).
Table 5.1.: The number of clauses within three conditions of the basic arguments
No Pattern Number Example of Clause of
Clau-ses
1 Arg>=2 222 - Alice (A1) sitting (V) with her sister outdoors (A2) ArgM>=0 when she spies a White Rabbit with a pocket watch
V==1 (TMP).
- Alice (A0) gets (V) herself (A1) down to normal proportions (A2)
2 Arg==1 64 - She (A0) cried (V) while a giant (TMP).
ArgM>=0 - In the wood (LOC) again (TMP) she (A1) comes (V) V==1 across a Caterpillar sitting on a mushroom (LOC) 3 Arg==0 1 - get (V) through the door or too small (DIR) to reach
ArgM>=1 the key (PNC)
V==1
1
Borey, Eddie. “Alice in Wonderland Summary”. GradeSaver, 2 January 2001 Web. (accessed April, 24 2017).
2
The first pattern (Arg>=2, ArgM>0, V==1) is included in the algorithm because it is the most frequent pattern in the two summaries. The clauses behind this pattern communicate clear information consistently across the sentences in both summaries. Besides these reasons, two or more Args can make better questions than just one Arg. For example, there are three clauses created from the sentence “Suddenly, the cards all rise up and attack her, at which point she wakes up.” Figure 5.3 shows that this sentence creates three clauses with different information:
First clause : Suddenly (ADV) the cards all (A1) rise up (V)
Second clause : the cards all (A0) attack (V) her (A1) at which point she wakes up (TMP) Third clause : she (A0) wakes (V) up (A2)
Fig. 5.3.: SRL Representations for “Suddenly, the cards all rise up and attack her, at which point she wakes up.”
Even though all three clauses give information, the second clause gives more information than the two other clauses because it has more Args in it, compared to the first and the third clause which only has one Arg. Therefore, the first pattern “Arg>=2, ArgMs>=0, V==1” is chosen to be included in the algorithm.
LOC, ADV, and MNR. In conclusion, the patterns that are included in the template creation step is “Arg>=2, ArgM>=0, V==1”, and the ArgMs are TMP, LOC, ADV, and MNR. This means that a QA pair can be created when there are 2 or more Args, 0 or more ArgMs (TMP/LOC/ADV/MNR), and a V.
Table 5.2.: Occurrences of the Argument Modifiers
ArgM GradeSaver SparkNotes
TMP (Temporal Markers) 22 16
LOC (Locatives) 8 12
ADV (Adverbials) 9 8
MNR (Manner Markers) 7 17
DIR (Directionals) 6 7
PNC (Purpose, not cause) 2 6
DIS (Discourse Markers) 2
-MOD (Modals) 1 5
5.2 Template Creation
Based on the pattern observation step, the required elements that can create a QA pair are 2 or more Args, 0 or more ArgMs (TMP/LOC/ADV/MNR), and a V. To make a better QA pair, 4 categories are prepared to group the clauses that have ArgMs. The categories are based on the ArgM because one ArgM can really differ from the other ArgMs. For example, a clause with an ArgM TMP may expect a question word “When”, while a clause with an ArgM LOC may need a question word “Where”. There is also 1 category created to group the clauses that do not have any ArgMs.
the template, the subject character is represented as the lower argument, while the object character is represented as the higher argument.
[image:38.612.113.539.352.679.2]As a narrative, Alice in Wonderland has the elements that are described in the Ele-ments of a Narrative Theory [30]. Events (actions, happenings) and existents (characters, settings) are the main elements that included in the question generation algorithm. In the implementation, the templates ask about the action that a subject does, the subject char-acter, the object charchar-acter, and the argument modifier. Based on these narrative elements, there are 5 QA templates that are created for each category that has an ArgM and 4 QA templates that are created for the category without an ArgM. The categories are called MADV, MMNR, MLOC, MTMP, and ARGU. The template names are started with the category name and added with a number.
Table 5.3.: Templates for the category that has an ArgM LOC
Template Template Structure Generated QA Pair
MLOC1 Q: What + aux + lower Arg + do Q: What does she do to herself in to + higher Arg + ArgM LOC + ? a long hallway full of doors? A: lower Arg + V + higher Arg A: She finds herself
MLOC2 Q: Who + V + higher Arg + ArgM Q: Who finds herself in a long
LOC + ? hallway full of doors?
A: lower Arg A: She
MLOC3 Q: What + aux + lower Arg + V + Q: What does she finds in a long
ArgM LOC + ? hallway full of doors?
A: lower Arg + V + higher Arg A: She finds herself
MLOC4 Q: What happens to + lower Arg + Q: What happens to she in a long
ArgM LOC + ? hallway full of doors?
A: lower Arg + V + higher Arg A: She finds herself
Table 5.3 shows the 5 QA templates that have been created for MLOC category. The generated QA pairs use the input sentence “She falls for a long time, and finds herself in a long hallway full of doors”. This sentence is divided into two clauses by SENNA:
• She (A1) falls (V) for a long time (TMP)
• She (A0) finds (V) herself (A1) in a long hallway full of doors (LOC)
All of the templates shown in Table 5.3 are created based on the following intentions: MLOC1: asks about the predicate
MLOC2: asks about the subject MLOC3: asks about the object
MLOC4: asks about the predicate and the object MLOC5: asks about the modifier location
The question phrase “What ... do to ...” shown in Table 5.3 is formed for the MLOC1 template because the template asks about the predicate. The lower Arg is located before the phrase “do to” (as the subject) because a lower argument is an agent or a causer. The higher Arg is located after the phrase “do to” (as the object) because a higher argument is the patient or the argument which is affected by the action [26]. The question word “Who” is chosen for the template MLOC2 because most of the subjects in the training data is a character. Moreover, the QAMatcher usually still matches a question correctly even though it uses a different question word. Figure 5.4 shows this example.
Fig. 5.4.: Two different question words are given a same answer
small syntax error. There is another error that is shown in the generated QA pair from the template MLOC4. The object in the question “what happens to she” is supposed to use an objective pronoun “her” instead of a subjective pronoun “she”. The handle for the subjective and objective pronoun is implemented in the next version of the templates.
SENNA usually divides a sentence into several clauses. This makes some information in a sentence missing, especially in a sentence with conjunctions. Using the previous example, there will not be a QA pair that gives an information about how she finds herself in a long hallway full of doors all of a sudden, despite the fact that the reason “she falls for a long time” is given in the same sentence. This creates a new situation in which a dependency parse can be useful. Therefore, a new template under a new category is created. The template uses dependency parsing and requires a conjunction in the sentence. A Python interface called PyStanfordDependencies is used to provide the Stanford Dependencies in AQG. Based on the observations of dependency labels on sentences with conjunctions, the new template is as follows:
Question = ’What happens when ’ + Subj + V + Dobj + Nmod + ’ ?’ Answer = Subj + V + Dobj + Nmod + Cc + Conjs
For example, the sentence “She falls for a long time, and finds herself in a long hallway full of doors” has the dependency result which is shown in Figure 5.5.
Fig. 5.5.: Dependency Parse Result for the Sentence “She falls for a long time, and finds herself in a long hallway full of doors”
Therefore, a new question and answer pair that is generated by the algorithm is: Q: What happens when she falls for a long time?
A: She falls for a long time and finds herself in a long hallway full of doors
categories. The structures of initial templates for all categories are displayed in Table A.1 in the Appendix.
Table 5.4.: Categories and Templates
Category Name Required Elements Total Templates
MADV Arg>=2, ArgM==ADV, V==1 5
MMNR Arg>=2, ArgM==MNR, V==1 5
MLOC Arg>=2, ArgM==LOC, V==1 5
MTMP Arg>=2, ArgM==TMP, V==1 5
ARGU Arg>=2, ArgM==0, V==1 4
6. INITIAL EVALUATION AND IMPROVEMENT
First of all, a simple “QA Grouping” algorithm is created to group all the generated QA pairs based on their categories and to store each category in a CSV file. There are 6 CSV files generated based on the training data and can be viewed and analyzed easily using spreadsheet applications. Next, a pre-initial evaluation is conducted to see if the program works and if all the templates do not create too much error. The pre-initial evaluation is explained in section 6.1. Next, an initial evaluation is conducted to measure the quality of the initial templates. The initial evaluation is explained in section 6.2. The pre-initial evaluation and the initial evaluation are conducted by the author. Finally, an error analysis and improvements are next conducted based on the result of the initial evaluation. The error analysis and improvements are explained in section 6.3.
6.1 Pre-Initial Evaluation
A quick pre-initial evaluation is conducted by using one summary from the training data, the GradeSaver summary. There are 435 QA pairs that are generated from 47 sentences of the summary. Based on the observation of the generated question and answer of this initial version, there are 6 templates that create too many strange results.
Table 6.1.: Templates that Creates Too Many Errors
Template Description Examples
MMNR1 Asks about the action/ Q: What does she do to herself down
verb enough ?
A: she shrinks herself
MMNR3 Asks about the object Q: What does she finds with a note that asks her to drink it ?
A: she finds a drink
MMNR4 Asks about both the action Q: What happens to she through this door ? /verb and the object A: she spies a beautiful garden
ARGU1 Asks about the action/ Q: What does He do to her?
verb A: He mistakes her
Q: What does He do to her? A: He sends her
ARGU3 Asks about the object Q: What does she get? A: she get a handle Q: What does she get? A: she get herself
ARGU4 Asks about both the action Q: What happens to Alice? /verb and the object A: Alice grow larger and smaller
Q: What happens to Alice? A: Alice takes the baby
There is another error that can be seen from the generated QA pairs from the Table 6.1, which is the objective pronoun. The objective pronoun error “what happens to she” instead of “what happens toher” is fixed in the next version of the template.
For the ARGU category, the error that can be found is that the category only provides two Args and one V and makes the generated questions too vague. For example, the question “what does she get” is generated 5 times with different answers according to different scenarios in the story. Since there is no ArgM in ARGU category, the case for the generated QA is not specific enough. In conclusion, these 6 templates are removed from AQG.
6.2 Initial Evaluation
The evaluation that is conducted for the AQG system uses a rating scheme which is developed to be easy for novice annotators [18]. This is because the users who will interact with the virtual human can be general people without advanced knowledge in linguistic. For this evaluation, each question and answer pair is rated by the author on a 1 to 5 scale as displayed in Table 6.2.
Table 6.2.: 5 Scale Acceptability Score Adapted from [18]
Scale Score Explanation
Good (5) The QA pair does not have any problems, and it is a good as the one that a person might ask and the virtual human might answer. Acceptable (4) The QA does not have any problems..
Borderline (3) The QA might have a problem, but I’m not sure. Unacceptable (2) The QA definitely has a minor problem.
Bad (1) The QA has major problems.
of 56 sentences. The score for the question and answer pair acceptability is displayed in Figure 6.1.
Fig. 6.1.: Initial Evaluation Result
As shown in Figure 6.1, the overall question and answer pairs are still below the border-line scale (3), which are 2.790 and 2.885. Next, an error analysis is conducted and continued by template improvements.
6.3 Error Analysis and Template Improvement
After conducting the initial evaluation, the errors from each category are analyzed. The templates are then improved based on the result of the error analysis. The list of the improved templates are displayed in Table A.2 in the Appendix. The error analysis and the template improvements are explained in the rest of this section.
6.3.1 MADV
Fig. 6.2.: The Initial Evaluation Result for the MADV Category
Figure 6.2 shows the template name, the clauses which were used as the input of the AQG system, and the generated questions and answers of the clauses. The first clause explains about how Alice follows a white rabbit when she was fascinated by the sight. Therefore, a word “when” would be better added before “fascinated by the sight” to make the question clearer. The same solution can also apply for the second clause. For the second clause, the question “What does she do through the woodwhenshe was left alone?” would sound better.
“What does she do when she was left alone” would be a better generated question that can still be used for the first example as well: “What does she do when she was fascinated by the sight”.
Using the conjunction “when” before the ArgM apparently can cause a problem for the third clause, despite the fact that it would be good for the first and the second clause. The phrase “as she cries” is labeled as the ArgM ADV. It means that when using “when” the question will become “What does Alice into the pool of tears when as she cries?”. In order to handle this problem, the syntax is checked further. If the ArgM ADV starts with “as”, then the conjunction “when” is changed into “as” instead. This also applies to other ArgM ADV that start with “while”, “to”, and “into”.
Adding the “when” conjunctions, or having the first word of the ArgM as the conjunc-tions for the word “as”, “while”, “to”, and “into” applies to quesconjunc-tions in the templates MADV1, MADV2, MADV3, and MADV4, and also applies to the answer in the template MADV5. Based on the changes for the QA template under MADV category, the new result from the clauses in Figure 6.2 is displayed in Figure 6.3.
6.3.2 MMNR
The average score for the MMNR category is higher compared to the MADV category. This is because on the pre-initial evaluation, the templates MMNR1, MMNR3, MMNR4 were removed. Therefore, only the generated QA pairs from MMNR2 and MMNR5 category still remain and their quality is pretty good.
Despite their high score when compared to the other categories, there are two improve-ments done for the MMNR category. They can be explained using the generated QA pairs shown in Figure 6.4.
Fig. 6.3.: The Generated QA Pairs of the MADV Category After the Improvements
Fig. 6.4.: Errors on the Initial Evaluation Result of the MMNR Category
Question: How does she sees a beautiful garden ? Answer: Through the door
Considering this problem, therefore this template is still kept as it is; however, this template will not generate a QA pair when the ArgM MNR starts with “with”.
Another change that is done for the MMNR category is that on the MMNR2 template, the answer is added with an auxiliary, instead of just a “higher Arg”. Therefore, the answer for “Who sees a beautiful garden through the door” is “she does.”
6.3.3 MLOC
[image:49.612.129.517.381.599.2]The average score for the MLOC category is above the borderline, 3.267 and 3.1 for the GradeSaver and the SparkNotes summary respectively. However, there are still some improvements conducted for this category which can be explained using 5 generated QA pairs displayed in Figure 6.5.
Fig. 6.5.: Errors on the Initial Evaluation Result of the MLOC Category
question “What does she do to herself” on the first example in Figure 6.5 therefore can turn into other interpretations instead of the actual fact that she only finds herself, and not doing anything to herself. The second question, “What does she do to a key” also not the best question given the phrase “she discovers a key” as the source sentence. Based on this problem, “do to” and the object are removed from the template, leaving only the subject and the ArgM LOC on the question template.
Next, “what does she meets the forest” lacks a preposition before the ArgM LOC. This is because “the forest” is referred by the relative adverb “where” which is left out by AQG. To handle this problem, a preposition “in” is added to every ArgM LOC that does not have any prepositions.
Another problem can be found on the fifth question. The question “what happens to her giant tears at her feet” given the answer “her giant tears form a pool” can be made less strange. On this MLOC4 template, the subject is left out for the improved version of the template. Therefore, the generated question from the clause “Her giant tears form a pool at her feet” becomes “What happens at her feet?”. After improving the MLOC4 template, other clauses can still have good results, for example:
Clause: A key (A1) she (A0) discovers (V) on a nearby table (LOC) Question: What happens on a nearby table ?
Answer: she discovers a key
Finally, a small improvement is done for MLOC2 template. The answer template is extended with an auxiliary. Therefore, the answer “she does” is generated, with a question pair “Who finds herself in a long hallway full of doors”. Figure 6.6 displays the result after the template improvements.
6.3.4 MTMP
Fig. 6.6.: The Result After the Improvement on the MLOC Category
Fig. 6.7.: Errors on the Initial Evaluation Result of the MTMP Category
phrases with a same number of arguments. This condition is also implemented in all the templates in all categories.
For the template MTMP3, the question word “What” is changed into “Whom” since most of the objects in the clauses in the training data are characters. Therefore, a “who” is more suitable for the objects.
Another improvement is also done for the template MTMP4, in which the subject is left out after the question “What happens”. Therefore, the new question template is “What happens + ArgM TMP?”. This improvement is similar with the one for MLOC4 question template.
6.3.5 ARGU
The generated QA pairs that are displayed in Figure 6.8 somehow imply incorrect infor-mation according to the given clause. For example, the generated question from the second clause, “Who make Alice” sounds like it asks about how Alice existed today. However, the original clause talks about how two mushrooms can make Alice grow larger and smaller.
Fig. 6.8.: Errors on the Initial Evaluation Result of the ARGU Category
Fig. 6.9.: The Result After the Improvement on the ARGU Category
6.3.6 DCNJ
The category DCNJ has high average scores too for the two summaries, compared to the other categories. However, some improvements are still made for this category.
Fig. 6.10.: Errors on the Initial Evaluation Result of the DCNJ Category
“What happens when longs get?”. To generate a better question, “She” should be the NSUBJ while “longs” should be the root, as parsed by another Stanford Dependency Parser that is visualized by the Brat tool1 illustrated in Figure 6.12.
Fig. 6.11.: Incorrect Dependency Parsing Result for the sentence “She longs to get there, but the door is too small”
Fig. 6.12.: Correct Dependency Parsing Result for the sentence “She longs to get there, but the door is too small”
Another mistake with parsing the dependency also happens on the third clause “Present are the March Hare, the Hatter, and the Dormouse”. In the dependency result, “Hare” is labeled as the root, despite of the fact that “the March Hare” is a character.
The fourth clause in Figure 6.10 also has been incorrectly parsed by PyStanfordDepen-dencies. “This time” is parsed as NSUBJ to the root “prepared”, as well as the NSUBJ “she”. This makes the AQG pick a strange subject for the generated question “this she” (“this” is a determiner before the NSUBJ “time”).
Another improvement is conducted for the problem in the second clause shown in Figure 6.10. The generated question “what happens when she pokes head” lacks the possession modifier, despite its existence in the clause “she pokes her head”. This is, however, included in the improved version of the template. After the improvement, the generated QA from the second clause is:
Question: What happens when she pokes herhead into the branches tree? Answer: she pokesherhead into the branches tree and meets a Pigeon
Finally, “the Knave of Hearts” is not included in the generated question as shown in Figure 6.10. However, the initial version of the template leaves out passive phrases. The initial template does not check for the passive dependency labels NSUBJPASS, which is the label for “Knave”. Therefore, this is included in the improved version of the template. After the improvement, the generated QA from the fifth clause is:
Question: What happens whenthe Knave of Hearts accused?
Answer: The Knave of Heartsaccused but the evidence against him is very bad
6.4 Evaluation After Template Improvements
After error analysis and template improvement, another evaluation is conducted by the author using the 5-Score Scale explained in Table 6.2. The input source are still the same, they are the GradeSaver and the SparkNotes summary. The number of input sentences are thus the same with the initial evaluation. However, fewer QA pairs are generated than the initial one because of the template improvement. Such as, not generating a QA pair when there is a clause with more than one Args with the same number.
7. USER EVALUATION OF ALICE QUESTION GENERATION
After the initial evaluation and the improvements, an evaluation with external annotators is conducted. The evaluation measurement is explained in section 7.1. The evaluation setup is explained in section 7.2. Finally, error analysis and improvements for the templates are again conducted based on the result. The error analysis and improvements are explained in section 7.3
7.1 Evaluation Measurement
An evaluation with external annotators are conducted to rate the generated QA pairs from the improved templates. The 5-scale rating system displayed in Table 6.2 is again used for the evaluation. When a QA pair is rated as unacceptable (2) or bad (1), the annotator can choose one or both of the reasons that are shown in Table 7.1.
Table 7.1.: Reasons for an Unacceptable or a Bad Score
Reason Reason Explanation
Incorrect Information (a) The Q&A implies something that is obviously incorrect according to the context
Awkwardness/Other (b) The Q&A is awkwardly phrased or has some other problem (e.g., no native speaker of English would say it this way, or the question word is wrong).
through the door or too small to reach the key” generates the following QA pair: Question: Who get a handle on things ?
Answer: she does
An Unacceptable score (2) can be assigned to the above QA pair because the correct infor-mation from the sentence is “but she cannot seem to get a handle on things”. A question “Who cannot get a handle on things?” or an answer “nobody” should have been generated for this case.
The second reason, awkwardness/other, is more related to the structure of the generated QA. Therefore, it can be assigned when the phrase of the generated QA is strange or when the question word is wrong. For example, the sentence “She longs to get there, but the door is too small” generates the following QA pair:
Question: What happens when She longs get ? Answer: She longs get but the door is too small
A bad score (1) can be assigned to above QA pair because the structure of the question and answer is strange and they are difficult to understand.
7.2 Evaluation Setup
A summary of Alice in Wonderland from Litcharts1 is used as the test data. This summary consists of 69 sentences. There are 6 annotators involved in this evaluation. All annotators are students or recently graduated students from English taught programmes at the University of Twente, and one from the Saxion University of Applied Sciences. All annotators are not native speakers, however, they understand English well and speak English almost in daily life.
The test data is separated into two parts. The first half consists of 35 sentences and the second half consists of 34 sentences. The first half of the QA pairs is evaluated by 3 annotators. The second half of the QA pairs is also evaluated by 3 annotators. The annotators are assigned randomly to either the first half group or the second half group. The 35 sentences from the first half group have 137 generated QA pairs, and the 34 sentences
1
from the second half group have 131 generated QA pairs. The generated QA pairs in each group are also randomized.
Fig. 7.1.: User’s Evaluation Form
First, the annotators are given an instruction, an explanation of the 5-scale scoring system, an explanation of both reasons for the unacceptable or bad score, and some examples of rated QA (see Appendix chapter B). In the instruction, the annotators are told to not focus on the grammars and pronoun resolution for the current evaluation. The grammar errors and pronouns are not handled in the AQG because the QAMatcher can still correctly match the questions. However, when they find the generated QA pairs have grammars or pronoun resolutions that are too much for them to understand the generated QA pairs, then they can include them in their judgments.
Next, the annotators give a score for each QA pair. The time that the annotators take to finish the task is about one hour. Figure 7.1 shows 5 examples of generated QA pairs that have been rated by an annotator.
7.3 Error Analysis and Template Improvement
Fig. 7.2.: User Evaluation Score Result of the Question and Answer Rating
or sentence ambiguities. However, several minor errors on generated questions are not fixed if the QAMatcher can still match the questions well (such as a wrong question word).
7.3.1 MADV
The majority of the problems that exist in the MADV category are caused by strange parsing results. An example of parsing error is displayed in Figure 7.3.
Clause: The White Rabbit returns (A0) having lost his gloves, and, mistaking Alice for his maid (ADV) asks (V) her fetch them (A1)
Question: When does The White Rabbit returns asks her fetch them ?
Answer: when The White Rabbit returns is having lost his gloves , and , mistaking Alice for his maid
Fig. 7.3.: SRL Labeling Error from the MADV Category
question and answer sound strange. Beside of the parsing error, the clause also has a grammar mistake by not including the preposition “to” before “fetch them”.
Another problem that can be seen from the evaluation result, which was also pointed out by an annotator, is a causality problem in one of the sentences that falls under the MADV category. The sentence and the generated QA are displayed in Figure 7.4.
Clause: The Queen (A0) gets (V) very irate (A1) calling for mass executions (ADV) Question: Who gets very irate when calling for mass executions ?
Answer: The Queen gets very irate
Fig. 7.4.: Causality Problem in a Generated QA from the MADV Category
What the clause in Figure 7.4 trying to say is the queen gets very irate, and then she calls for mass executions. However, this clause can also mean that the queen gets very irate when she calls for mass executions. Unfortunately, the parser gets the latter meaning of the clause which makes the clause fall into the MADC category and generates a question that implies incorrect information.
7.3.2 MMNR
A parsing error also occurs in a clause under the MMNR category as displayed in Figure 7.5. The complete sentence of the clause is “She tries one side of the mushroom and finds it makes her smaller so quickly eats the other side, which makes her grow taller, but mostly in the neck”. The phrase “her smaller” is incorrectly labeled as the subject (Arg 0) which creates a strange answer as shown in Figure 7.5.
Clause: her smaller (A0) so quickly (MNR) eats (V) the other side, which makes her grow taller, but mostly in the neck (A1)
Question: Who eats the other side , which makes her grow taller , but mostly in the neck so quickly ?
Answer: her smaller does
Besides parsing errors, sentence ambiguity is another source of low scores in two QA pairs which are generated from the same sentence, as shown in Figure 7.6. The generated QA pairs are correct. Playing card is actually a character in the story. The parser labeled the playing cards correctly as the subject, however, it might be confusing for the annotators since the test data do not have this character written in capitals. The average score for the generated QA from template MMNR2 is 1.6 and the average score for the pair from template MMNR5 is 2, with “incorrect information” as the major reason for the unacceptable or bad score.
Clause: Playing cards (A0) annoy (V) her (A1) in any way (MNR) Question (Template MMNR2): Who annoy her in any way ? Answer(Template MMNR2): playing cards does
Question (Template MMNR5): How does playing cards annoy her? Answer(Template MMNR5): in any way
Fig. 7.6.: Correct Generated QA Pairs that Got Unacceptable Scores
7.3.3 MLOC
The average score for MLOC is relatively good compared to the results for other cat-egories. However, there is one error that is fixed for the templates in this category. The error is found on the generated QA pairs from the sentence “Inside this house, the Duchess is nursing a pig baby and a cook is having a temper tantrum”. Figure 7.7 shows this error. In a previous improvement, a generalized preposition “in” is added when a location does not have a preposition2. But the check misses prepositions that start with an “in”. After this improvement, the generated question from template MLOC1 becomes “what does the Duchess do inside this house?” while the generated answer from template MLOC5 becomes “Inside this house”.
2
![Fig. 2.3.: Virtual Human Architecture [7]](https://thumb-us.123doks.com/thumbv2/123dok_us/9730645.473944/11.612.153.493.383.606/fig-virtual-human-architecture.webp)
![Fig. 3.1.: The overview of Alice’s Dialogue Manager [9]](https://thumb-us.123doks.com/thumbv2/123dok_us/9730645.473944/19.612.145.502.199.448/fig-overview-alice-s-dialogue-manager.webp)