Association Rules Extraction using Multi-objective Feature of Genetic Algorithm
Full text
Figure
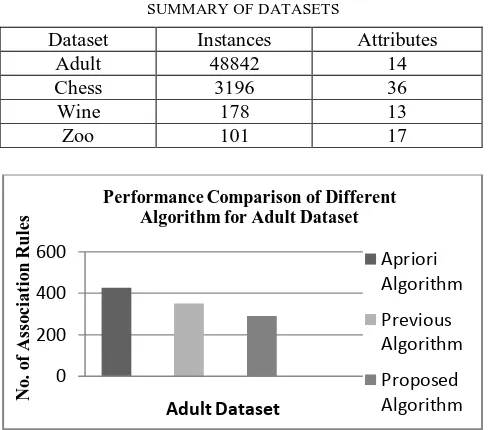
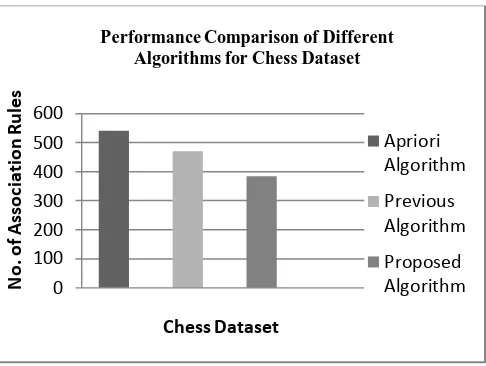
Related documents
Items describing stereotypes related to lack of capacity for exercise included items pertaining to exercise self- efficacy in PLHIV, treatment side effects, as well as per- ceptions
This paper proposes a tolerant control for the open- circuit fault of the outer switches in three-level rectifiers (both 3L-NPC and T-type topologies) used in
The process of iris texture classification typically involves the following stages: (a) estimation of fractal dimension of each resized iris template (b) decomposition of template
Various functions of the digital device can process as human interactions through interaction between the user and 3D digital actor, by setting questions
Other six apparently healthy female rabbits in Gr- IV after induction of septic arthritis were administered ethanolic extract of Tamarindus indica L.. leaves (EETIL) at 1000 mg kg −
The reduced feed intake on the 0.25 % unripe noni powder and subsequent improvement on the 0.25 % ripe powder was not clear but palatability problems due to possible compos-
henselae at the strain level, with 39 genotypes identified among 126 studied isolates using a com- bination of nine intergenic spacer sequences.. Prior to our study, the
Experiences and preferences of care among Swedish immigrants following a prenatal diagnosis of congenital heart defect in the fetus a qualitative interview study RESEARCH ARTICLE Open
