Object Counts! Bringing Explicit Detections Back into Image Captioning
14
0
0
Full text
Figure
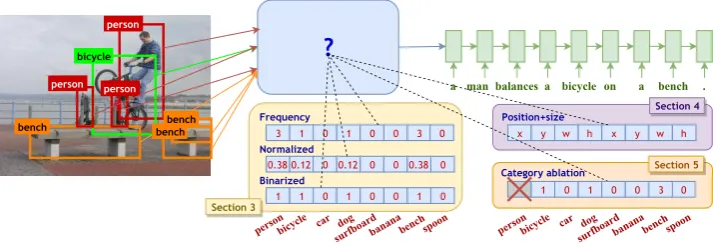
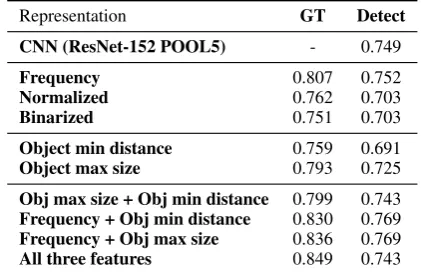


+7


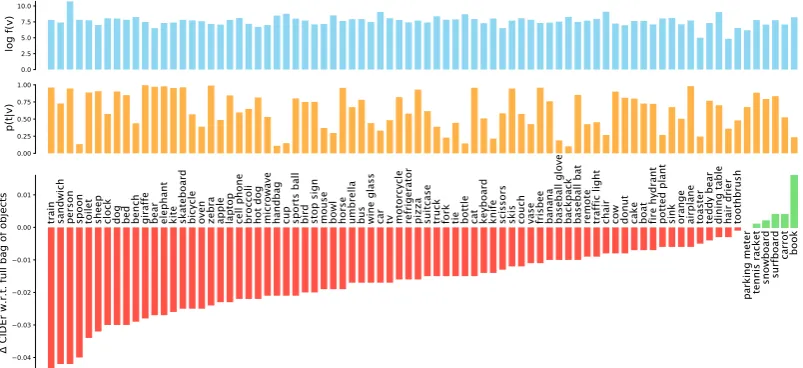
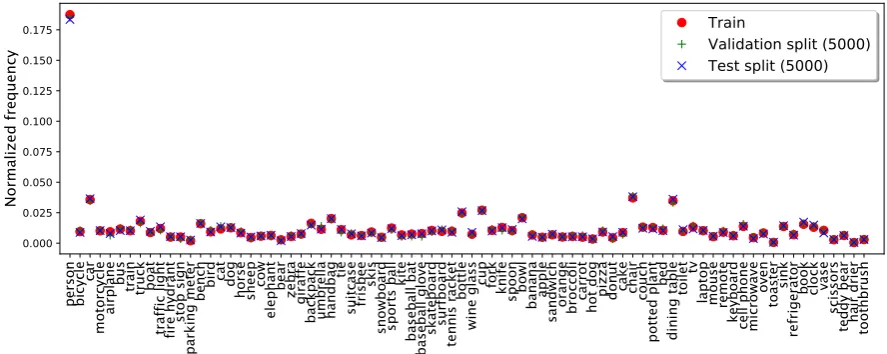

Related documents